研发设计资源大规模领域本体构建方法
2022-09-14杜丽峰
栗 统,杜丽峰,王 磊
(1.天津大学 机械工程学院,天津 300350;2.天津市天锻压力机有限公司,天津 300232)
对于现代复杂装备制造研制企业来说,研发设计等知识资源已经成为仅次于核心研发人员的最重要的资产,是开展产品正向创新设计的基础性资源,企业已经开始越来越重视这些资源的管理与应用。由于这些资源来源于不同的业务系统,客观上造成了分散在不同系统或不同组织中的现状,缺乏统一的组织和管理,共享效率低,与研发流程融合不足,无法在产品全生命周期中发挥核心价值。集团企业之中,由于数据地域上分散,形式上异构,储存上分布的原因,各个企业之间的信息形成了孤岛。
为解决上述难题,本文运用资源空间模型的概念在集团企业之间建立集信息资源整合、共享的应用软件平台,解决资源分散化、异构化,建立资源空间模型,实现研发设计资源统一建模开发资源共享模式。其中设计资源空间模型通过对集团企业设计资源内容进行分类,从而对分散在不同组织系统中的设计资源进行规范化整理,实现统一管理,促进不同资源间的共享,提高与研发活动的融合程度,高效发挥集团企业研发设计资源的核心作用。构建设计资源空间模型按照自底向上的顺序分为5 个层级,分别为分类层、元数据层、本体层和图谱层,资源空间框架如图1 所示。其中,分类层包含了设计资源的分类信息,从不同维度和特征对设计资源进行分类,便于设计资源的快速定位;元数据层描述了设计资源的属性信息,包含设计资源的基本信息、功能、状态等各方面的属性;本体层对设计资源的内容进行了规范性描述,便于设计资源的统一规范管理、准确查找;图谱层体现了不同设计资源之间的联系,提高了设计资源的搜索和关联资源查找效率。

图1 资源空间框架
本体词语最早不是在计算机领域出现的词汇。本体最早在哲学中被用于规范存在论的定义,用来系统性地描述事物,表达一切抽象事物的本质。如今,将本体的理论延伸到计算机领域,可以将某个知识作详尽的语义描述,在计算机领域,本体被用于知识的描述,在语义层次上建立知识模型,以供人们学习。目前学术界对于本体的定义有很多种,被国内外学者所广泛接受的是Studer 对本体的定义:“本体是共享概念模型的明确的形式化规范说明”[1]。本文通过对领域本体构建方法的研究来解决资源空间本体层构建问题。
1 研究现状
Jorg-Uwe Kietz 等人在研究基础上提出了一种从文本中提取有关要素生成领域本体构建方法[2];Chang-Shing Lee 构思了基于事件的本体构建方法,使用模糊数概念的相似度计算做本体的概念聚类和分类关系定义方面,以此构建领域本体[3];Ana B等通过建立领域概念层次,改进层次关系的获取,从非结构化文本中获得的特定的领域知识信息[4]。D.Gregor 研究了交通运输领域的本体构建方法[5];官莹莹对本体中概念的抽取做了相关研究,提出了循环处理思想,通过对分词的领域词典的不断增添与修正,结合TF-IDF 算法更加准确地提取相关概念,后用凝聚层次聚类算法提取概念关系[6];王学厚根据车间业务活动知识的分析与建立的业务活动领域本体元模型,建立了车间业务活动领域本体,以解决车间业务活动领域中的术语以及概念在语义上的歧义问题[7]。Chen RC,Bau CT,Yeh CJ 基于概念格的相关理论,用形式概念分析FCA 进行本体构建[8];李军莲等从叙词表等级结构还有叙词表中包含的本体中概念的关系出发,研究了基于叙词表的本体构建方法,但是适合应用领域较为局限[9];刘磊提出一种全新的本体自动构建方法,采用了模板识别的SSE_CMM技术,实现了领域本体自动构建[10];王向前等使用TF-IDF 公式改良了概念获取的方法,在之前的基础上增加了相关性的判断,通过统计概念在领域的相关程度,设置合适的阈值过滤出相关性高的概念[11]。
本文采用了LDA(Latent Dirichlet Allocation)模型[12]抽取出文本中隐藏的本体核心概念,通过层次聚类等算法进行关系的提取包括:同义语义、上下位关系和相关关系,最后建立本体。
2 研究思路
本文所建立的领域本体构建流程如图2 所示。
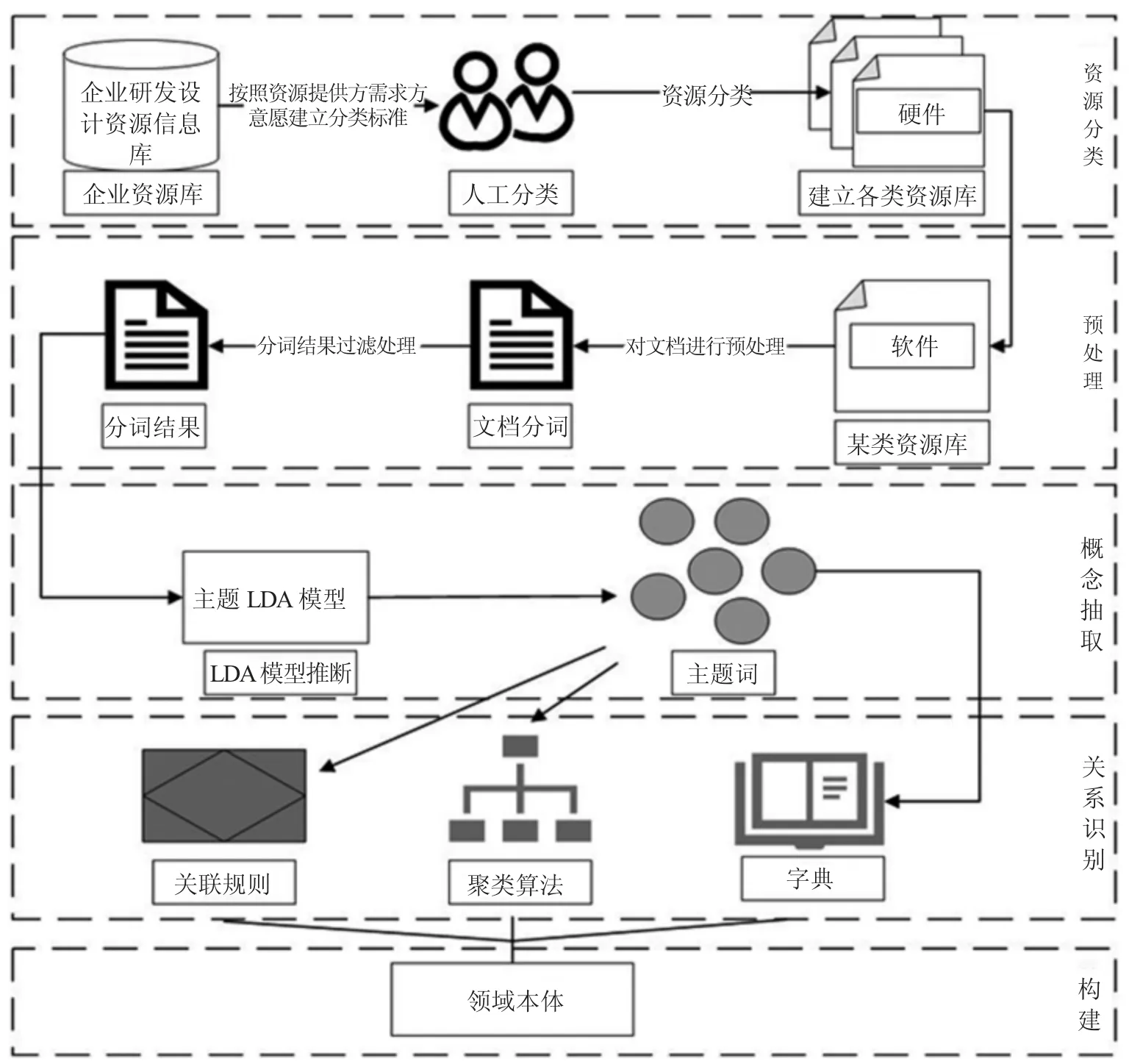
图2 研究思路
资源分类:对集团企业的研发设计资源进行定义,并且以集团企业的研发设计过程为基准,从资源的不同维度和特征出发对设计资源进行动态归类,通过资源的功能和特征对研发设计资源进行区分。
预处理:针对非结构化的文本信息,使用Jieba分词系统,在普通的分词词典中加入通用的机械术语以及集团企业领域中常用的词汇,形成领域本体概念的语料库。
领域本体核心概念提取:将处理好的文本语料库作为输入,设置相应的参数,通过训练过的LDA模型进行主题的推断,将文本文档中隐藏的主题作为本体的核心概念提取出来。
基本语义关系识别:通过NLP 相关技术处理三种语义关系:同义关系、上下位关系、相关关系。分别采用双语词典语言策略、基于word2vec 的层次聚类以及关联规则的方法识别关系。
将构建出的每个分类的资源本体融合,完成企业研发设计资源的领域本体构建。
3 资源分类
研发设计资源领域本体构建的目标是将其分类并表达,但集团企业研发设计资源数量巨大且种类繁多,直接进行本体构建相对较为繁琐。因此,构建本体之前,需将资源进行分类。根据设计资源的性质和特点对资源进行层次划分,划分结果的形式为树状结构。
设计资源的分类方法并不统一,根据行业标准的不同以及企业实际情况及要求,设计资源可以有多重分类方法:Hitt,Ireland 和Hosikisson 把企业资源定义为七类资源。财务资源、物化资源、技术资源、创新资源、商誉资源、人力资源以及组织资源[13]。罗辉道总结前人研究的成果,将广义的资源粗粒化,将企业作为定义的核心,将企业资源定义为可以带来优势或劣势的东西[14]。国家标准在网络化制造环境下,对企业资源进行分类分层,逐层细化,根据资源的物理特性进行细分,将企业的制造资源分为物能资源(包括物料、设备、产品、能源等)、信息资源、技术资源、人力资源、资金资源和其他资源等6 类资源[15];高伟增从管理角度,将资源分为人力资源、生产资源、财务资源、市场资源以及开发设计资源[16]。以集团企业中新产品的研发设计过程作为分类基准,在上述文献中提及的分类基础上,结合资源提供方、需求方以及集团企业的需求(不涉及生产过程),从资源的功能维度,专业领域维度,以及业务活动维度等角度出发,将集团企业研发设计资源分为六类,如表1 所示。
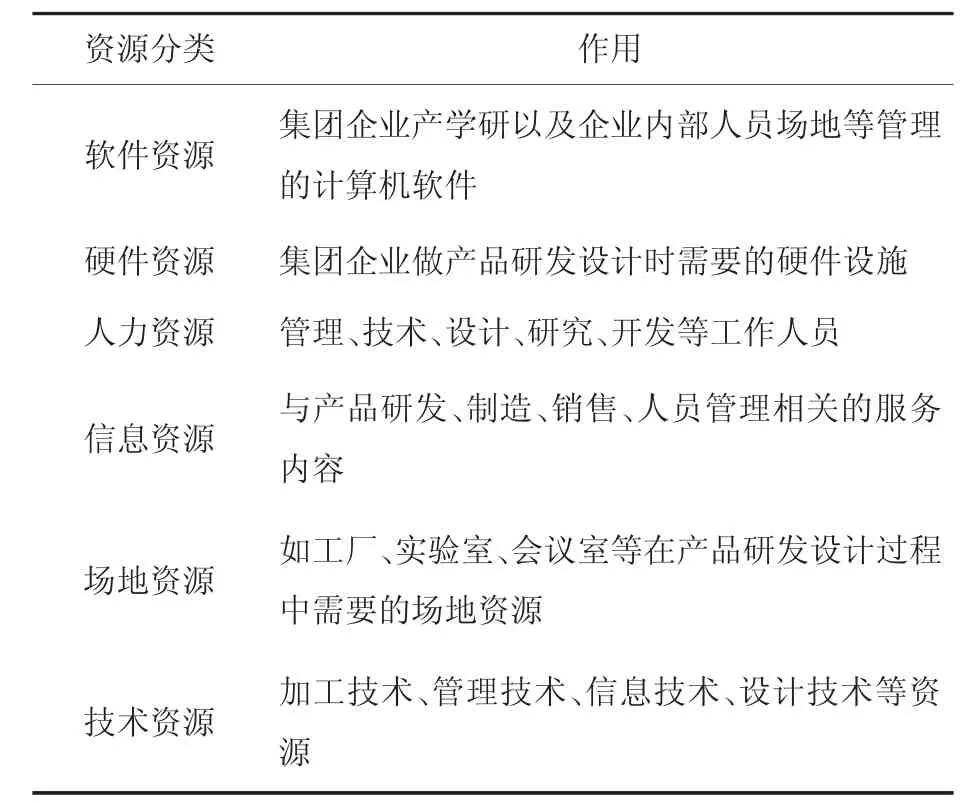
表1 资源分类
4 本体构建
领域本体由一个四元组组成,其中包含领域相关概念、领域概念间关系、公理规则以及领域概念的实例。
4.1 数据预处理
集团企业积淀了大量的知识资源,比如设计文档、设计模型、分析数据、试验数据、测试报告以及收集到的专利、标准规范、设计手册、情报文献等资源,这些信息具有多种信息形态,其中包含了极其丰富的领域知识。提取识别大量文本中的领域知识需要将文本数据进行分词与过滤处理,即获取语料库的过程。
非结构化的文本需要进行分词等处理方式使计算机准确地识别词语,但是由于中文文本的特殊性,词与词之间模糊的界限如果不加规则来限制,机器很难准确识别到在领域文集中的专业领域词汇,进而无法保证准确得到领域术语。本文采用Jieba 分词系统,添加机械术语以及集团企业所特有的领域词汇到分词词典,在使用少量文本分词结束后,检查分词结果对照原文检查分词词汇,之后检查出新的词汇结果添加到分词词典,遍历领域文集分词,分词结果形成语料库。
分词结束对文本语料库进行过滤处理。停用词过滤使用所有公认的中文停用词表组成的停用词表对语料库进行过滤,删去语料库中的停用词。本体构建中能够成为文本文档中主题词的词语一定是高频词,所以对语料库中的低频词需要进行过滤处理,设定频率最小阈值过滤出现频率过低的术语;主题词是名词、名词性短语以及动名词,最后利用词性标注功能,只保留术语集中的名词、名词性短语和动名词,进行词性过滤。
4.2 概念抽取
领域主题表达的核心概念是领域概念,即文本的核心主题。国内外的众多学者对核心概念的抽取方法研究众多,主要分为直接提取以及间接提取两种。直接提取是指基于现有的资源直接在文本中提取领域概念,如基于WordNet 等资源的直接提取以及直接将基于TF-IDF、句法分析等方法提取的领域术语作为领域概念;间接提取则是在文本抽取核心概念的基础上,再进行聚类形成更为准确可靠的领域概念。本文选择LDA 模型完成设计研发资源本体核心概念抽取任务。
非监督机器学习技术中的文档主题生成模型LDA 挖掘文本中潜藏的主题信息,该模型用主题概率分布对所输入的文档进行描述,在保留了统计信息的同时较好地完成了分类,非常适合用于自然文本的处理工作。
4.2.1 LDA 模型建立
主题LDA 模型设计了很多数学知识,本文只介绍LDA 模型的基本知识,不作详细的讲解,在数学本质上可以用三层贝叶斯概率模型表达,如图3 所示。

图3 贝叶斯概率模型
LDA 模型建立在词袋化模型的基础上,将文本数据转化为纯数字信息,对一个词语出现的位置以及其上下文的关系暂且忽略,考虑词语出现的频率,将文档集中的文档分别转化为词频向量。
LDA 主题模型不仅仅是一种三层贝叶斯模型,在一种理解中,其也属于典型的有向概率图模型,如图4 所示。
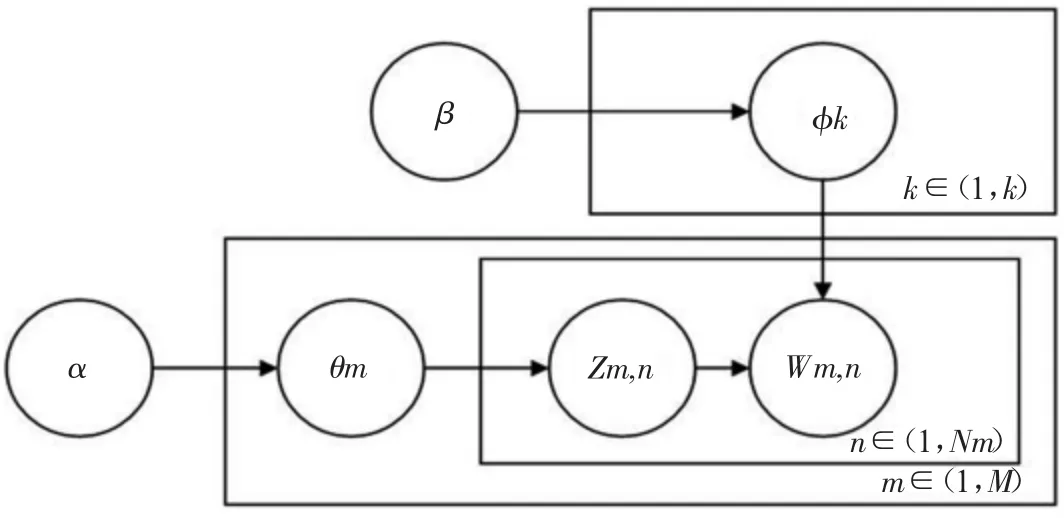
图4 LDA 模型有向概率图
图中的圆形图案均代表一种变量,Wm,n 在模型中是唯一一种可观测变量,其他均为潜在变量,两两变量之间皆存在一种条件依赖性,图中使用箭头表示。方框在图中表示抽样方式,抽样采取重复抽样的办法,抽样次数标记在方框右下角。图中α、β 为两个超参数,θm、φk表示两种概率分布,Zm,n表示主题概率分布下的主题。
计算某领域术语在文档中出现的概率,主题作为中间层时计算的公式为:
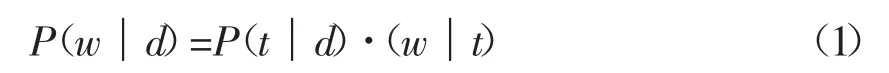
即通过主题在文档中出现的概率与领域术语在主题中出现的概率乘积表达为领域术语在文档中出现的概率。
4.2.2 LDA 模型概念抽取
LDA 主题模型进行概念抽取任务,首先需要对模型进行训练,模型的输入为预处理后的语料库以及超参数α,β 以及主题数K。
根据以前学者的研究,超参数α 与β 的值设定为50/K 和0.01时,模型的预测分类效果最佳,主题数量关系模型的运算,主题数对模型困惑度影响很大,根据语料库的大小对主题数量设置一个区间,计算LDA 模型困惑度,通过曲线取局部最优规定最优参数。
抽取概念流程如下。
Step1:将过滤后的语料库作模型训练使用,语料库中的所有词语按照LDA 模型随机生成一个主题,将主题统计完全,生成文档对应主题的计数矩阵表达主题概率分布,生成主题对应词语的计数矩阵表达词频率分布;
Step2:对语料库中的所有单词所对应的主题进行采样,之后按照吉布斯采样公式从头采样其中每一个词对应的概念主题,之后按照重新采样的结果同步更新主题概率分布以及词频率分布矩阵,其公式如下:
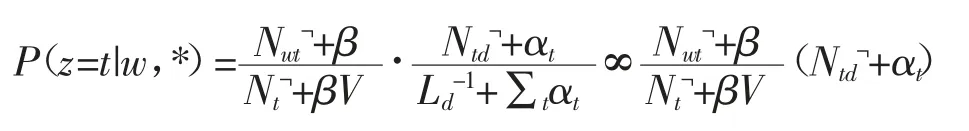
式中:超参数αt和β 是Ntd和Nwt的先验指导;V 表示词表大小;Ld表示文档d 的词总量;Nwt表示文档中主题t 中词w 的频次;Nt表示文档中主题t 的频次;Ntd表示文档d 中主题t 总共出现的次数;﹁的意思是排除当前采样词w 的影响,即当前采样词w 不计入频数统计。
Step3:重复Step2,直到词频率分布矩阵收敛;
Step4:将训练好的模型存储好,并将语料库重新输入进行求解,得到文档集的主题分布,推断出的所有主题词构成概念集合。
4.3 关系识别
如何有效并且快速识别在前述章节中获取的领域本体核心概念之间的语义关系是本文中的关键。
本文将本题中概念语义关系定义为三类:同义关系、上下位关系以及相关关系。
4.3.1 同义关系抽取
本文将同义词关系描述为同义关系,即词语表达的含义为相同时,将两个词语定义为同义词,在词库中即可剔除其中一个,这样可以提高关系识别的准确性。综合之前学者的相关研究,本文使用基于双语词典的方法来识别词语的同义关系。这种方法简单有效,此方法是基于语言转换的策略,将汉语词语转换为英语翻译将英汉大词典作为算法调取的知识库,借此实现同义关系抽取。其过程叙述如下。
Step1:将语料库中的每个中文概念通过英汉词典进行中英文转换,得到此概念所有的英文解释,将所有的单词或者短语放入一个集合中,得到Wi={w1,w2,…wn};
Step2:从Step1 中得到的单词或者短语集合两两相交,如果集合相交后不是空集,则说明概念是同义词;
Step3:验证所有概念后结束。
4.3.2 上下位关系
根据文献调查等方法,本文确定使用层次聚类方法实现上下位关系的抽取。
层次聚类算法分为分类的聚类以及凝聚的聚类两种,本文采取凝聚的聚类方法,将每个初始点作为一类,计算距离后依次聚类到一个中心,将所有层次关系抽取出来。
使用word2vec 模块把语料库中的所有中文概念词语转换为一个词向量,在进行上下位关系识别之前计算两两词向量之间的语义相似度。
簇间平均距离计算公式:
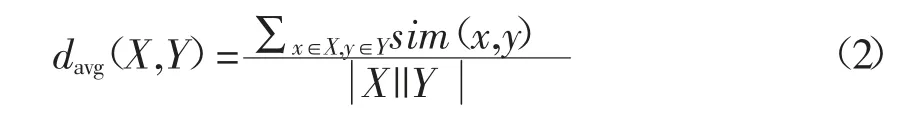
式中:X,Y 表示两个簇,绝对值则表示相应簇中的元素个数;sim(x,y)表示概念间的相似度。
抽取上下文关系的算法流程如下。
Step1:将语料库输入算法中,把语料库中的每个概念单独作为一个初始簇;
Step2:簇间距离使用上文中word2vec 模型计算词向量之间的距离代替,分别计算所有簇;
Step3:将词语之间的距离作为合并基准,不断取词向量之间距离最小的两个簇进行合并,直到算法结束所有的词语合并为一个簇。
这样的算法进行到最后无法确定簇中哪个概念为父类概念,根据本体中的定义,父类概念在簇内应该与每个概念都具有很高的相似度,所以,本文规定一种平均相似度表达簇中概念与其他概念的相似程度,平均相似度高的概念即为簇中的父概念,平均相似度定义:
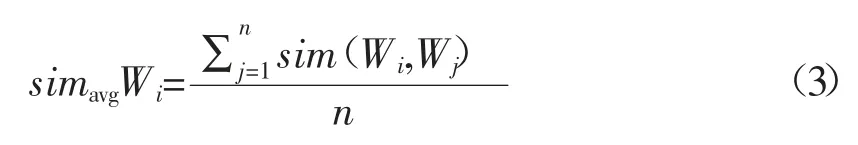
式中:sim(Wi,Wj)为两个概念之间的相似度;n 表达簇中的概念个数。
4.3.3 相关关系
相关关系复杂且重要,本体中概念关系很大一部分都是相关关系,本文拟采用基于关联规则统计的方法识别概念之间的相关关系。
关联规则的运用根据词语间的支持度与置信度来计算,有关于关联度与置信度的讲解本文不详细介绍。
抽取相关关系的算法流程如下。
Step1:将分词后的语料库按照每份文档(文档数量多)或者每个句子(文档数量少)分开输入;
Step2:依照模型以及实际的需求来设置关联规则算法的最小置信度以及最小支持度的阈值;
Step3:计算语料库中所有词语集合中所有概念元之间的置信度与支持度,如果得出支持度与置信度均大于最小支持度与最小置信度,则说明概念两个概念之间具有非层次关系;
Step4:验证所有词组之后结束。
5 实验验证
为了验证本文提出的集团企业研发设计资源领域本体构建方法的可行性,本文使用企业资源档案中软件资源的部分文档做测试,具体实例验证如下。
5.1 概念抽取
通过对企业研发设计资源相关语料的分词及干扰项消除后运用LDA 模型进行概念的抽取。部分3分词结果如表2 所示。

表2 部分分词结果
模型困惑度是选取最佳主题数的标准,绘制模型困惑度曲线选取合适的拐点对应的主题数量作为最佳主题数,根据实验验证最佳主题数T=8。
困惑度计算公式如下:
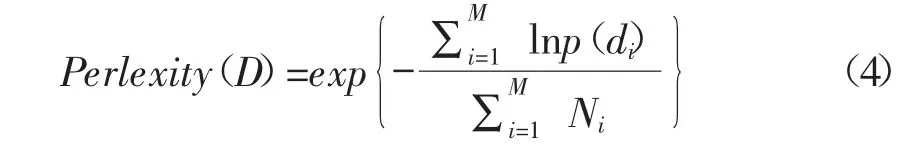
式中:D 为测试集;M 为文本数量;Ni为文档d 的单词数目。
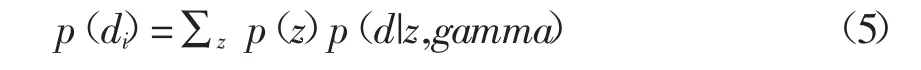
式中:z 是主题;d 是文档;gamma 是训练集学出来的主题文本的概率分布,设置阈值过滤后,将主题词抽取出来以便进行关系识别。
5.2 关系识别
同义关系识别,使用有道词典外部链接将词语翻译成英文合集,将所有词汇翻译后生成的每个集合做交集处理,如若交集后不是空集则判断两个词汇是同义关系。
判断同义词汇如表3 所示。

表3 同义关系
上下层关系判断,将词语使用word2vec 转换为词向量后使用层次聚类的方法,将所有的概念聚合到一个中心,以此识别概念间的上下层关系。抽取后的部分上下层关系如图5 所示。
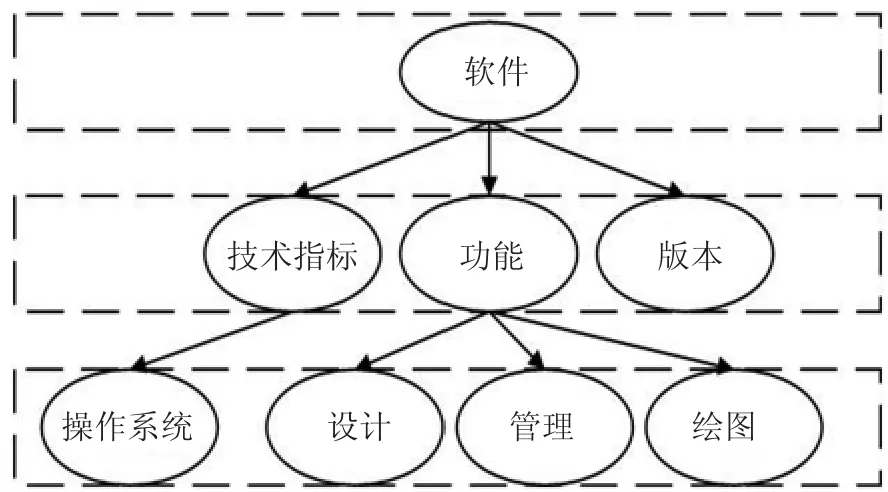
图5 部分上下层关系
抽取部分相关关系如表4 所示。

表4 部分相关关系
6 结语
本文对于企业设计研发资源统一管理分享的需求,提出了一种研发设计资源空间中本体层的构建方法,分析了现有本体构建方法后,针对文本数据到领域本体概念的抽取选择LDA 主题模型,将概念之间的关系分类并进行相应的识别,分别选择了不同的抽取策略,并用企业的部分软件数据进行了案例验证证明本方法的可行性。
在本体构建的过程中,发现了本文提出方法中的一些不足,字典的缺乏导致分词结果不准确,以至以后的概念抽取以及关系识别均存在一定程度的影响。但本体提出的本体层中领域本体的构建方法可行有效,为以后企业资源本体建模奠定了基础。
