基于区块链的城轨客流预测方法
2022-09-07陈园园
陈园园
(北京城建设计发展集团股份有限公司 北京 100037)
0 引 言
与公路交通相比,城市轨道交通系统凭借自身优势正在快速发展[1-2].然而,随着城市轨道交通网的不断扩张,城市轨道交通运营商面临着提高列车运行安全性和乘客舒适度的巨大压力.客流量的准确预测是设计城市轨道系统的关键部分,可以帮助运营商优化运营计划,提高运营效率.
对于短期客流预测,现已有许多研究.Lee等[3]将差分整合移动平均自回归模型应用于铁路短期客流预测,并验证了模型的有效性.Chen等[4]提出了一种结合SVR回归和小波变换的北京地铁客流预测模型,预测精度较高.随着深度神经网络发展迅速.Li等[5]提出了一种结合Elman神经网络的分段客流预测模型.崔洪涛等[6]提出了一种混合EMD-BPN预测方法,该方法有效地将经验模态分解(EMD)与反向传播神经网络(BPN)相结合,用于地铁短期客流预测.李科君等[7]提出了一种基于神经网络和起点-终点矩阵的高速铁路系统短期客流预测模型.但与传统模型相比,深度神经网络往往能取得更好的效果.但训练深度神经网络模型往往需要大量数据.
由于城市轨道交通运营商之间独立运营,缺乏共享数据的激励机制,目前用于客流预测的学习模型受限于样本数据的特征维度和数量.但如果能够城市间相似车站的客流数据结合起来,模型预测结果就会更加准确.
文中将原始自动检票系统(automated fare collection, AFC)数据预处理并建模为一维时间序列数据,使用分布式长短期记忆(long and short term memory, LSTM)网络作为监督学习模型进行客流预测.建立激励机制,鼓励轨道交通运营商共享当地客流数据,建立基于区块链的分布式联合学习(federated learning,FL)模型,用于准确预测客流.并用真实数据对所提模型进行评估,结果证明了所提模型的有效性.
1 基于区块链的联合学习模型
1.1 两种隐私保护方式
为了保护数据隐私而提出的分布式机器学习算法.一个典型的分布式系统见图1.数据所有者在本地计算数据的模型参数,然后将模型的权重上传到中央服务器,而不是直接上传原始数据.中央服务器对所有者上传的所有权重进行聚合[8-10].然而,这种集中式结构虽然数据所有者避免将具体数据直接上传到中央服务器,但上传的权重可能会提取部分私人信息.并且中心服务器有被攻击和崩溃的可能,这将导致整个系统停机.
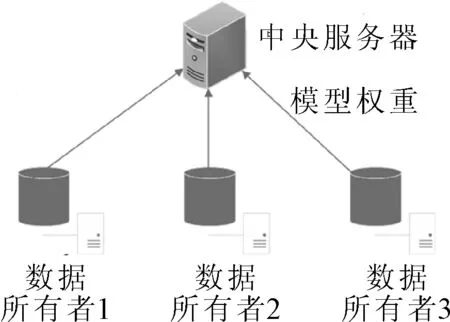
图1 集中化结构图
针对上述问题,引入了去中心化结构,见图2.去中心化分布式网能够解决中心化结构的隐私保护问题,但该系统仍可能面临Byzantine攻击等安全威胁.恶意节点可能会提供虚假信息来破坏机器学习的过程.
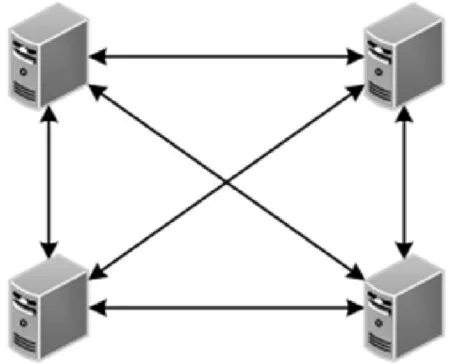
图2 去中心化结构图
1.2 基于区块链的联合学习模型
为了建立一个隐私保护和安全的分布式框架,将区块链技术引入去中心化结构[11-13].基于区块链的联合学习模型框架见图3.将客流数据存储在相应的站点中,每个站点使用其本地数据训练LSTM模型并计算模型的错误率和梯度,每个站的梯度和错误率以交易的形式上传到区块链上,区块链上的智能协议将比较所有站模型的错误率并共享合适的模型.
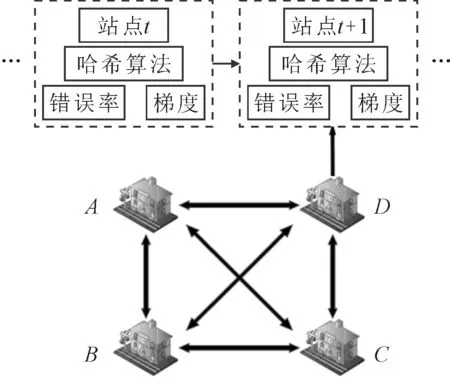
图3 基于区块链的联合学习框架
选择错误率最低的模型站作为初始模型进行共享.其他站点从区块链下载模型并使用它来训练本地数据,计算每个站点的错误率并上传到区块链上.由于Boosting框架算法概念,包含使用当前局部模型无法精确预测的数据的站点很可能比其他站点包含更多的信息,这对模型的改进具有重要意义[14-15].因此,优先考虑错误率最高的站.
选择错误率最高的模型站使用错误率最低的模型来训练其本地数据.目标函数为
(1)
式中:w为模型站;xi,yi为用于训练模型的数据;N为数据量.
采用小批量梯度下降算法(MBGD)作为优化算法,模型站wt的梯度形成为
(2)
更新区块链上的wt,为
wt+1=wt+ηJ(wt)
(3)
以上不断迭代,直到训练模型的错误率低于预设值,或者迭代次数超过设定值.
1.3 基于区块链的联合学习模型中的激励机制
在客流预测模型的训练过程中,发现该模型缺乏有效的激励机制.导致某些站由于缺乏信任和利益而拒绝参与模型的训练.针对上述问题,文中提出了一种激励机制,鼓励那些没有足够数据的站点使用本地数据一起训练模型,最终建立一个准确的预测模型.
为了描述激励机制,用Vf代表几个站一起训练的最终模型的价值,用Ci代表训练局部模型梯度i时站的成本.一般假设Vf大于Ci.
假设Pi表示每个站点的收益:
(4)
式中:γ为收益系数;m为迭代次数;E为模型错误率;n为梯度下降的次数;Mi为每个站点提供的数据数量;αi为额外奖励.
如果某站不完全诚实,设置Pf来表示某站不诚实并被抓到的概率.失信站应扣减其奖励,惩罚系数用fc表示.
因此,站点从训练预测模型中获得的最终奖励Pr为
Pr=Pi*(1-Pf)-fc*Pf-Ci
(5)
2 LSTM神经网络模型
2.1 数据预处理
LSTM模型是处理时间序列数据的专家,因此将原始数据预处理成一维时间序列数据.考虑到预测效果,文中采用单步预测来预测客流.
原始数据为2014年3月1—31日北京地铁各线路全天客流AFC数据.为保证模型训练时的时间一致,结合北京地铁实际运行时间(05:00—23:00)进行统一筛选训练.
客流数据每隔5min进行一次统计和预测.由于同一天内不同时间段的客流值差异较大,需要将客流数据归一化到同一范围内.为了提高预测效果,文中选择了min-max归一化,为
(6)
式中:X为样本值;Xmin为所有样本中的最小值;Xmax为所有样本中的最大值.
考虑到地铁的实际运营,以车站为单位预测客流比以线路为单位更有意义. 因此,文中以北京地铁13号线西二旗站的AFC客流数据为例,使用LSTM模型进行训练和预测.
2.2 模型构建
LSTM模型通常包括四层:输入层、LSTM层、全连接层和输出层.在LSTM模型的结构过程中,需要指定模型的损失函数.选择平方损失函数来建立LSTM深度神经网络模型,其形成为
(7)

文中采用随机失活正则化来避免过拟合.图4为LSTM模型在LSTM层使用随机失活正则化后的结构图,模型中随机失活的概率设置为0.2,即神经元以20%的概率失活.

图4 LSTM模型神经网络结构图
文中使用小批量梯度下降算法(MBGD)来优化目标函数,即:使用部分样本来更新参数,为
(8)
式中:θi为参数;α为更新步长;x为样本值;y为标签值.
LSTM模型每一层的输出维度见图5.步长设置为7,用7个历史数据预测下一时刻的客流.LSTM层的神经元个数设置100个,全连接层的神经元个数为50个.LSTM层的输出神经元个数为1个,负责输出预测的客流数据.
3 算例验证
以平均绝对误差作为指标来评价LSTM模型在客流测试集上的表现,并分析平均绝对误差随训练迭代次数的增加而变化的趋势.将所提出的FL模型的预测客流和无FL模型的预测客流与真实客流进行比较.
区块链网络运行在四个主机上,包括四个区块链节点和四个联合学习业务节点.测试平台采用Linux操作系统,区块链平台使用EOS,测试脚本使用Node.js.不同交易发送频率下系统的平均吞吐量见图6.由图6可知:在发送频率为125 TPS时吞吐量达到最大值,最大吞吐量为109 TPS,其中TPS表示每秒交易数.也就是说,当计算节点每秒向平台发送125笔交易时,区块链平台每秒可以更新权重109次,达到最大值.
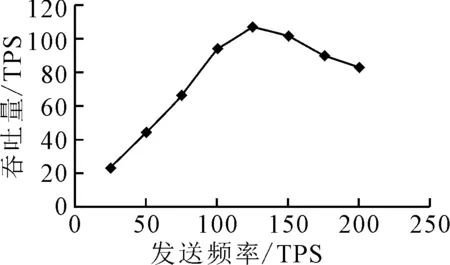
图6 系统在不同交易发送频率下的平均吞吐量
客流预测使用2014年3月29—30日2 d的客流数据作为测试集,其他客流数据作为训练集.网格搜索用于搜索模型的最优参数,结果表明,当训练数量为150,batch数量为15,LSTM层的神经元数量为100,步长为7时,LSTM模型的预测性能最优.
图7为不同日期150次迭代的平均绝对误差. 由图7可知:平均绝对误差先是迅速减小,然后逐渐平缓,经过150次迭代后相对稳定.
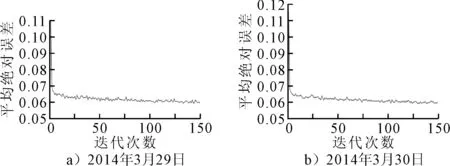
图7 150次迭代的平均绝对误差
图8为LSTM模型客流预测曲线.由图8可知:文中所提出的FL模型的预测客流比没有FL模型的预测客流更接近真实的预测客流,证明了数据量决定预测模型的性能.没有FL模型用于短期客流预测时,一天内96个时刻的预测值的最大相对误差不超过4%;而文中所提FL模型进行预测时,各个时刻预测值的相对误差整体上有所减少,且均控制在2.3%以内.结果证明了文中所提FL模型的有效性.
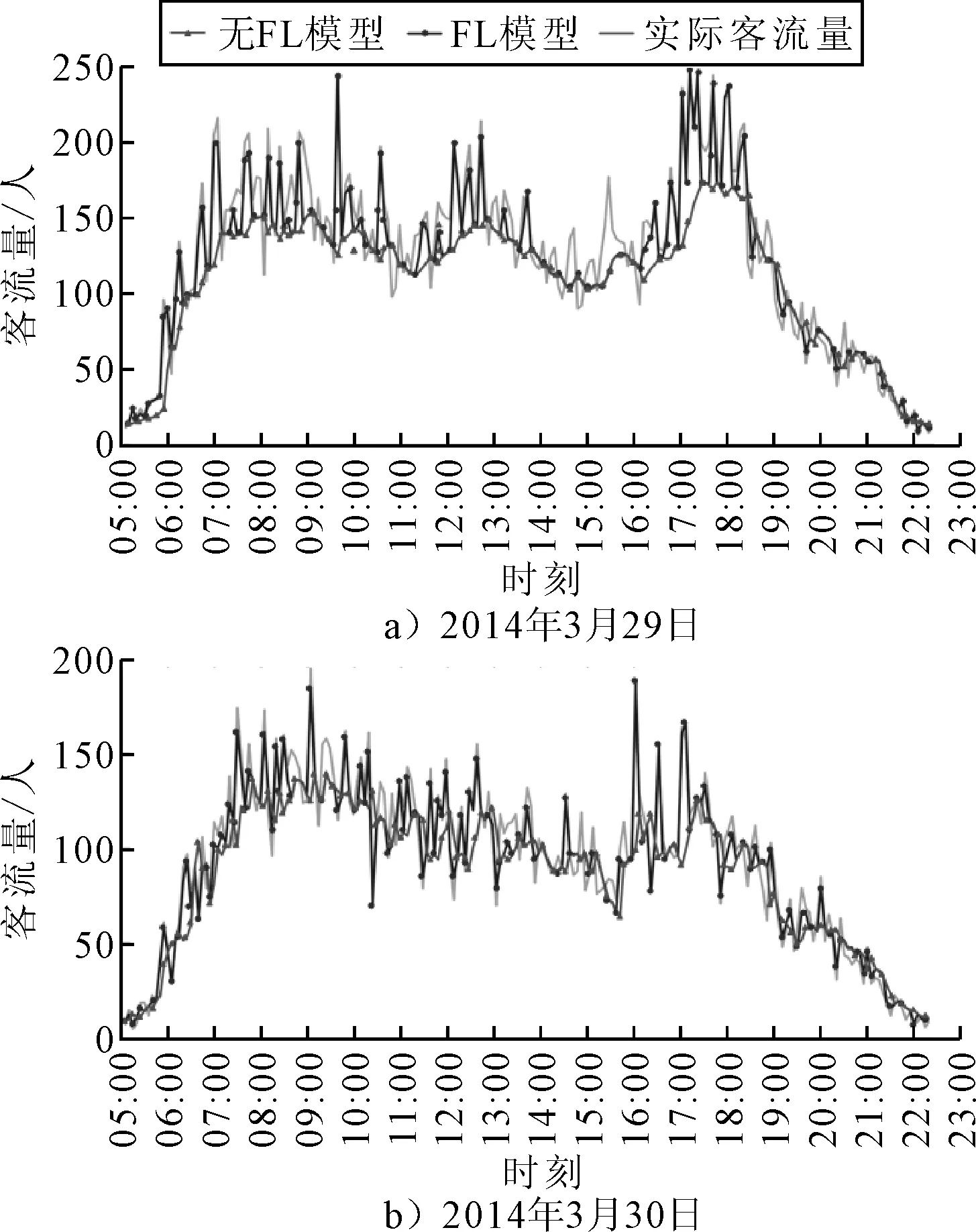
图8 客流预测曲线图
4 结 束 语
在海量客流数据的支持下,准确的轨道交通短期客流预测能够提升轨道交通系统的运营效率.文中提出了一种基于区块链的联合学习模型,并建立了激励机制,鼓励参与者参与训练模型,用于城市轨道交通客流预测.结果表明:该模型具有很小平均绝对误差,可以显著提高客流预测的准确性.
