面向飞机电源系统故障诊断的知识图谱构建技术及应用
2022-09-07聂同攀曾继炎程玉杰马梁
聂同攀,曾继炎,程玉杰,*,马梁
1. 北京航空航天大学 可靠性工程研究所,北京 100083 2. 航空工业第一飞机设计研究院,西安 710089 3. 可靠性与环境工程技术国防科技重点实验室,北京 100083 4. 北京航空航天大学 可靠性与系统工程学院,北京 100083
随科技水平日益发展,飞机系统的复杂程度日益上升,其故障的严重性也不断提高。一次严重的飞机系统故障往往会造成巨大的财产损失乃至人员伤亡。为减轻飞机系统故障带来的严重后果,需在故障早期进行快速、准确的故障诊断并予以排除。
飞机电源系统是飞机最重要的系统部件之一,承担着为飞行控制、导航和无线电通信等装置提供电力的功能,关系着飞机上各种用电设备的正常运行和飞行安全。近年来,飞机机载设备的电气化程度越来越高,对作为机载设备能量来源的飞机电源系统提出了越来越高的可靠性要求。目前,飞机电源系统故障诊断方法主要可分为基于数据的方法和基于知识的方法。目前学者们广泛研究的是基于数据的方法,即通过传统机器学习或深度学习等方法挖掘数据中的信息,训练模型以进行故障诊断。基于数据的方法不需要很多的专家知识,在数据充足的情况下模型通常能取得较高的准确度。然而基于数据的方法也存在两个问题:一个问题是可解释性,传统机器学习和深度学习模型对于使用者来说是一个黑盒,无法就输出的故障诊断结果给出解释,降低了在实际工程应用中的可信度;另一个问题则是无法有效地利用已有的先验知识,如故障隔离手册(Fault Isolation Manual,FIM)等非结构化知识,造成了非结构化数据资源的浪费。
知识图谱由谷歌公司于2012年提出,是一种从非结构化知识中抽取实体和关系并以有向图的形式存储实体及其间关系的知识库,能实现对非结构化知识的统一规范化表达。知识图谱是一个由多个节点和多条边组成的语义图。每个节点代表一个概念或事物。概念指一类事物的总称,如学生等;事物是指一个具体的人、事或物,如学生的具体名字。每条边代表两个节点之间的语义关系。
知识图谱自诞生以来得到了广泛的应用,其应用形式主要包括搜索、问答、推理和推荐等。王萌等考虑到用户在不能给出明确的查询意图时搜索系统难以精准捕获用户兴趣的问题,提出了人机混合的知识图谱主动搜索。曹明宇等设计了基于知识图谱的原发性肝癌知识问答系统,针对成人中常见的原发性肝癌构建了原发性肝癌知识图谱。张鹏举等提出了一种新的基于多特征实体消歧的中文知识图谱问答系统。于娟等提出了基于图数据库的人物关系知识图谱推理方法,以此发现隐含人物关系并检测人物关系数据中存在的不一致,进而支持组织基于人物关系的管理决策。吴运兵等提出了一种基于路径张量分解的知识图谱推理算法。余敦辉等提出了基于知识图谱和重启随机游走的跨平台用户推荐方法。李浩等将外部评分和电影自身知识相结合,提出了一种基于循环知识图谱和协同过滤的电影推荐模型。
借鉴知识图谱在医疗、社交和影评等诸多领域的成功应用,国外已有相关文献将知识图谱引入故障诊断领域,辅助实现系统故障诊断。Liu等指出多种铁路操作故障及危害因其间的联系构成了因果网络;该研究针对铁路操作故障因果网络使用知识图谱探索铁路操作故障,在异构网络中描述了故障和危害,揭示了故障的潜在规则并据此提出预防措施。Ou等指出随电网规模的持续增长和智慧电网的快速发展,电力无线专网的覆盖率逐渐上升;在这个过程中,如何有效使用电网智慧终端的信息实现无人值守网络监控和自动运维成为当前需要解决的问题;该研究针对电力无线专网,使用终端信息和故障信息等构建了知识图谱,以此实现了电力无线专网故障诊断和决策制定。Feng等指出随着国家电网的物联网建设,大量异构终端的接入使电网的采集和操作压力骤增,用电信息采集系统故障运维知识库(FOM-KB)将难以满足大量运维信息条件下高效智能决策制定的需求;该研究提出了一种用电信息采集系统的知识问答系统,实现了节点与边的高效遍历搜索,提高了推理效率并支持实现高效和智能化的采集与维护故障诊断。在中国,目前知识图谱在故障诊断领域中的应用尚处于起步阶段。刘瑞宏等提出了电信领域的知识图谱构建方法,该方法将电信网络领域零散的专家知识及产品、案例知识和故障数据进行了有效关联,构建了电信领域知识图谱;他们使用该知识图谱开展网络故障智能诊断,辅助解决网络运维领域的故障问题。李乐乐等研究了面向飞机维修与维护的知识图谱构建和应用方法,该方法利用知识图谱和SQLite数据库构建了飞机维护维修知识库;他们使用某航空公司提供的相关数据集建立了知识库,并利用数据库对飞机故障进行了时间维度和空间维度的分析。然而,这些研究主要集中在知识图谱构建层面,涉及应用的也只是提出了实现方法,而未能实际应用,尤其是关于飞机电源系统的知识图谱构建方法及应用尚鲜见报道。
考虑到飞机电源系统在研制生产和运行使用阶段会产生包括设计生产数据、运行使用数据、维修保障数据等大量非结构化文本数据,利用知识图谱技术可从上述非结构化文本中提取知识,实现非结构化知识的统一规范化表达,进而支持电源系统的故障诊断,提高基于知识的故障诊断自主化程度、可解释性和诊断精度,本文提出了一套面向飞机电源系统故障诊断的知识图谱构建及应用流程,以利用上述非结构化文本。首先,根据所用飞机电源系统非结构化文本特性及专家知识构建知识图谱本体;然后,利用BMEO标注后的文本训练基于双向长短期记忆网络模型,实现实体抽取;进一步,利用关系标注后的文本训练基于注意力机制的双向长短期记忆网络模型,实现关系抽取;在此基础上,根据本体和实体抽取与关系抽取结果构建面向飞机电源系统故障诊断的知识图谱;最后,基于构建的知识图谱实现包括搜索、推荐和问答等的智能应用。
1 知识图谱构建的通用方法流程
知识图谱的构建可分为自顶向下(Top-down)和自底向上(Bottom-up)两种方式,其中自顶向下的方式指先构建本体,而后根据本体进行实体和关系的抽取;自底向上的方式指先进行实体和关系的抽取,而后根据抽取结果归纳聚类,抽象出本体。自顶向下的构建方法适合拥有明确知识范围的专业领域知识图谱,自底向上的构建方法适合知识覆盖范围较广的通用知识图谱。由于在故障诊断领域通常具有较为明确的专业领域知识,因此主要针对自顶向下的知识图谱构建方法进行介绍。
自顶向下的知识图谱构建方法包含4个步骤:本体构建、实体抽取、关系抽取和图谱构建,如图1所示。

图1 知识图谱自顶向下构建流程图Fig.1 Flowchart of top-down knowledge graph construction
1.1 本体构建
本体是对概念建模的规则,是对客观世界的抽象描述,是针对概念及概念间的联系以形式化方式给出的明确定义。在自顶向下的知识图谱构建流程中,本体构建是从最顶层的概念开始构建本体,细化为实体和关系。本体构建包括确定实体类型和确定关系类型。其中确定关系类型包括确定两个实体类型之间是否存在关系、确定两个实体类型之间为何种关系和两个实体类型中头尾实体分别是哪个。
1.2 实体抽取
实体指现实中的具体事物或概念,在完成本体构建后,根据本体进行实体抽取。实体抽取一般方法为采用机器学习技术,从数据源中自动或半自动抽取实体。将原始数据中一部分划为训练集,进行标注后用于训练实体抽取模型。常用的实体抽取方法包括基于隐马尔可夫模型(Hidden Markov Model,HMM)的方法、基于条件随机场(Conditional Random Field,CRF)的方法和基于双向长短期记忆网络(Long Short-Term Memory,LSTM)的方法。实体抽取模型的有效性一般通过准确率和召回率等指标进行评判。
1.3 关系抽取
关系指实体间的联系,在完成实体抽取后,根据实体进行关系抽取。关系抽取一般方法为采用机器学习技术从数据源中自动或半自动地抽取关系。常用的关系抽取方法包括基于卷积神经网络(Convolutional Neural Network,CNN)的关系抽取和基于注意力机制的双向长短期记忆网络(Attention-Based Bi-directional LSTM)的关系抽取。关系抽取模型的有效性一般通过准确率和召回率等指标进行评判。
1.4 图谱构建
根据抽取出的实体、关系构建图数据库完成知识图谱的构建。常用的构建知识图谱工具包括Neo4j、ArangoDB和OrientDB。
在构建好的图谱基础上,可实现搜索、问答、推理和推荐等知识图谱应用。
2 面向飞机电源系统故障诊断的知识图谱构建及应用流程
2.1 总体方法流程
如图2所示,面向飞机电源系统故障诊断的知识图谱构建及应用流程包括本体构建、基于双向长短期记忆网络算法的实体抽取、基于注意力机制的双向长短期记忆网络算法的关系抽取、基于Neo4j的知识图谱构建及基于知识图谱的智能应用。

图2 面向飞机电源系统故障诊断的知识图谱构建及 应用流程图Fig.2 Flowchart of knowledge graph construction and application for fault diagnosis of aircraft power system
首先,根据飞机电源系统故障诊断语料情况和图谱需求构建本体,确定实体类型和关系类型。
构建本体后,将飞机电源系统故障诊断手册中部分语料分为训练集和测试集,对训练集和测试集进行实体标注。使用训练集训练基于双向LSTM的实体抽取模型,并使用测试集测试实体抽取模型效果。使用训练好的实体抽取模型抽取故障诊断手册语料中的实体。
最后,对训练集和测试集进行关系标注。使用训练集训练基于注意力机制的双向LSTM的关系抽取模型,并使用测试集测试关系抽取模型效果。结合实体抽取结果,使用训练好的关系抽取模型抽取故障诊断手册语料中的关系。
完成实体抽取和关系抽取后,使用知识图谱构建工具Neo4j,利用抽取出的飞机电源系统故障诊断知识构建面向飞机电源系统故障诊断的知识图谱。
在上述工作基础上,基于构建的飞机电源系统知识图谱,以智慧搜索与推荐及智能问答等形式实现基于知识图谱的智能应用。
2.2 本体构建
在构建针对某一专业领域的图谱时,应根据专家知识先行构建该图谱的本体,为后续的实体抽取和关系抽取提供规范。本方法为针对特定领域,即飞机电源系统故障诊断的知识图谱,因而选择使用专家知识人工构建本体。
构建本体包括规定实体类型、规定关系类型和规定关系类型的头尾实体类型。
对于飞机电源系统故障诊断知识图谱,可用的实体类型主要为排故手册和维修手册等故障信息,包括故障类型、故障表现、故障原因、故障影响、解决措施等。
2.3 基于双向长短期记忆网络算法的实体抽取
在知识图谱中,实体是其中的一个个节点。使用非结构化数据构建一个知识图谱需先根据本体对数据进行实体抽取。常用的实体抽取算法中,双向长短期记忆网络算法能像长短期记忆网络算法一样处理长期依赖问题,对于文字这样字符之间相互影响在距离上跨度较大的数据有较好的效果。
2.3.1 双向长短期记忆网络算法
双向LSTM算法是一种常用的实体抽取算法。其原理是将时序方向相反的两个LSTM连接到同一个输出。在进行实体抽取时,会同时用到上文和下文的信息。传统的LSTM算法只能使用上文信息,而无法利用下文信息,难以用于实现准确的实体抽取。双向LSTM算法通过将时序方向相反的两个LSTM连接到同一个输出,实现了上下文信息的利用,解决了LSTM算法无法使用下文信息的问题,改善了实体抽取的效果。双向LSTM结构图如图3所示。

图3 双向LSTM结构示意图Fig.3 Schematic diagram of bi-directional LSTM
构成双向LSTM的两个不同方向的LSTM之间不共用状态,即正向LSTM的输出状态只会对正向LSTM产生影响,反向LSTM的输出状态只会对反向LSTM产生影响,它们之间没有直接的连接,不会互相影响。
每一个时间节点的输入会分别传到正向和反向LSTM,根据各自的状态产生输出,这两份输出会一起连接到双向LSTM的输出节点,共同组合成最终输出。双向LSTM中虽然两个方向的LSTM基本没有交集,但因它们共同合成了输出,所以对当前时间节点输出的贡献和造成的损失就可以在训练中计算出来,并且它们的参数也会根据梯度被优化到合适的值。
双向LSTM在训练时和普通单向LSTM非常类似,因为两个不同方向的LSTM之间几乎没有交集,因此可分别展开为普通的前馈网络。不过在使用反向传播算法训练时,无法同时更新状态和输出。同时正向状态在时未知,且反向状态在时未知,即状态在各自方向的开始处都是未知的,在这里就需要进行人工设置。此外,正向状态的导数在时未知,且反向状态的导数在时未知,即状态的导数在结尾处未知,这里一般需设为0,代表此时对参数更新不重要,然后开始正式训练步骤:
对数据做前向迭代操作,先沿着到方向计算正向LSTM的状态,再沿着到方向计算反向LSTM的状态,最后获得输出。
进行反向迭代操作,即对目标函数求导的操作,先对输出求导,然后沿着到方向计算正向LSTM的状态导数,再沿着到方向计算反向LSTM的导数。
根据求得的梯度值更新模型的参数,完成一次迭代训练。
输出层是将双向LSTM神经网络各个时刻的输出进行求和取平均,最终得到了对象词在当前句子环境下的语义表示,这个向量将作为编码器的输出传递给分类器。
2.3.2 基于双向长短期记忆网络算法的实体抽取流程
基于双向长短期记忆网络算法的实体抽取流程分为数据集划分、实体标注、模型训练、模型测试和实体抽取。基于双向长短期记忆网络算法的实体抽取流程图如图4所示。

图4 基于双向LSTM算法的实体抽取流程图Fig.4 Flowchart of entity extraction based on bi-directional LSTM
选取部分原始语料,以8∶2的比例划分为训练集和测试集。对训练集和测试集进行BMEO标注。BMEO标注是一种常用的实体标注方法,该方法通过给语料中的每一个字符添加表征其所在实体的位置和实体类型而标注实体。例如:语料中存在“故障模式”实体类型,则标签“B-故障模式”代表该字符是一个故障模式实体的首字符,B为“Begin”的缩写;标签“M-故障模式”代表该字符是一个故障模式实体的中间字符,M为“Middle”的缩写;标签“E-故障模式”代表该字符是一个故障模式实体的尾字符,E为“End”的缩写;标签“O”代表该字符不在实体中,O为“Outside”的缩写。
在完成实体标注后,以训练集语料为输入,训练集标注结果为标签,训练基于双向长短期记忆网络的实体抽取模型。
使用测试集测试训练好的模型实体抽取效果,将模型从测试集语料中抽取出的标签与人工标注的标签进行对比,计算准确率和召回率:
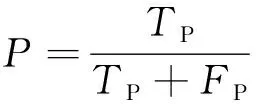
(1)

(2)
式中:为准确率(Precision);为召回率(Recall);为正类预测为正类(True Positive)的数量,即被实际抽取结果为某一标签,且人工标注也是该标签的字符数量;为负类预测为正类(False Positive)的数量,即实际抽取结果为某一标签,但人工标注不是该标签的字符数量;为正类预测为负类(False Negative)的数量,即人工标注为某一标签,但实际抽取结果不是该标签的字符数量。此外为负类预测为负类(True Negative),即实际抽取结果不是某一标签,且人工标注也不是该标签的字符数量。、、、的关系如图5所示。
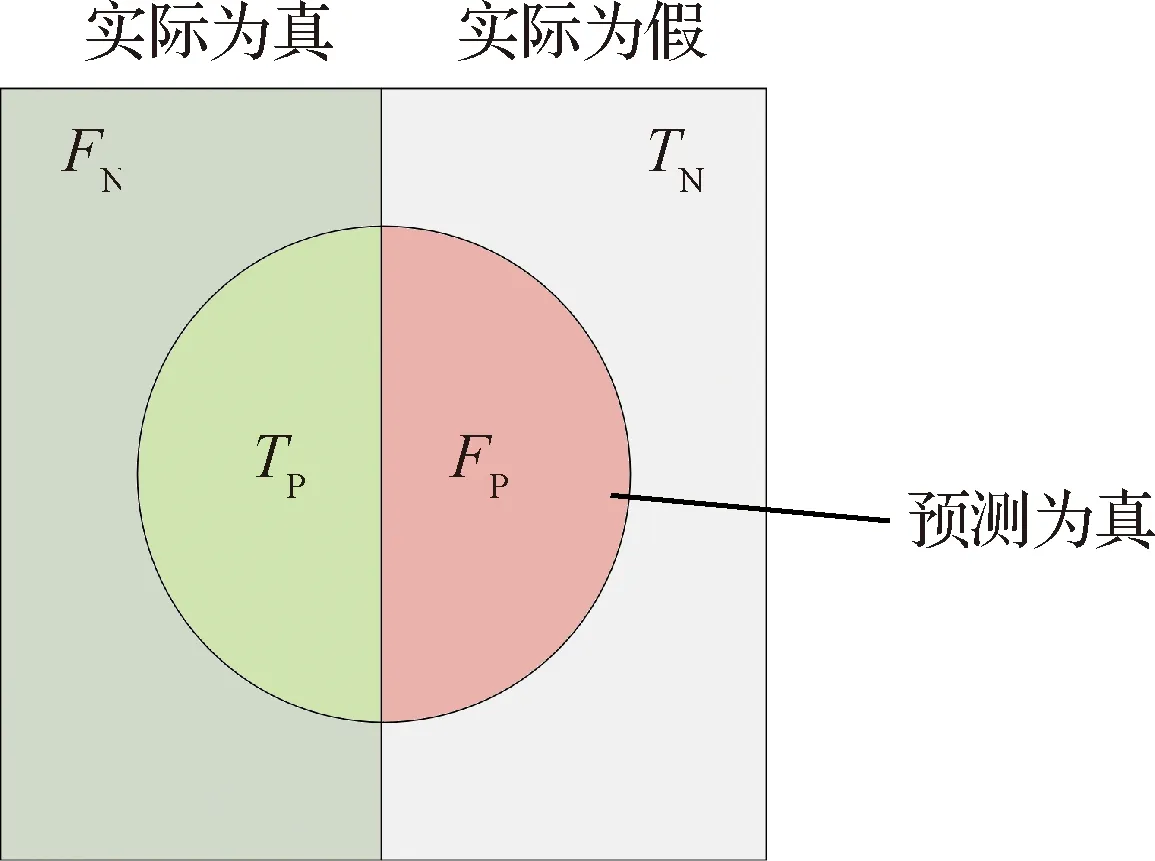
图5 TP、FP、TN、FN之间的关系Fig.5 Relationship between TP, FP, TN, FN
使用经测试后训练好的模型抽取剩余原始语料中的实体,完成基于双向长短期记忆网络算法的实体抽取。
2.4 基于注意力机制的双向长短期记忆网络算法的关系抽取
在知识图谱中,关系是连接两个实体之间的边。在对非结构化数据进行实体抽取后,需根据实体抽取结果再进行关系抽取。在常用的关系抽取算法中,基于注意力机制的双向长短期记忆网络因引入了注意力机制,可更好地分配计算资源,提高模型训练的效果。基于注意力机制的双向长短期记忆网络关系抽取算法是由Zhou等于2016年在自然语言处理(Natural Language Processing,NLP)领域的国际顶级会议Association for Computational Linguistics (ACL)上提出的。Zhou等指出传统的关系抽取算法需词性和最短依赖路径等高阶特征,导致计算量的消耗,同时注意到在待进行关系抽取的一个句子中,存在对关系有决定性影响的词汇,而引入注意力机制可用于找到这个词语,以此获取句子中最重要的语义信息。相比于传统关系抽取算法,基于注意力机制的双向LSTM算法可在不使用词性和最短依赖路径等高阶特征的情况下实现关系抽取,减少计算资源的消耗。因此选取基于注意力机制的双向LSTM算法进行关系抽取。
2.4.1 基于注意力机制的双向长短期记忆网络算法
基于注意力机制的双向LSTM算法是将注意力模型引入双向LSTM中得到的算法。注意力模型是一种模拟人脑注意力的模型,其核心在于借鉴了人脑在特定时刻对事物的注意力会集中在某一特定的地方、忽略其他部分的特点。注意力模型是一种影响资源分配的模型,其原理是对于关键部分分配较多的注意力,对于其他部分分配较少的注意力,合理利用有限的计算资源,并且还可以去除非关键因素的影响。
基于注意力机制的双向LSTM为在输出层和隐藏层之间加入了注意力层,调整隐藏层输出的权重。其结构如图6所示。
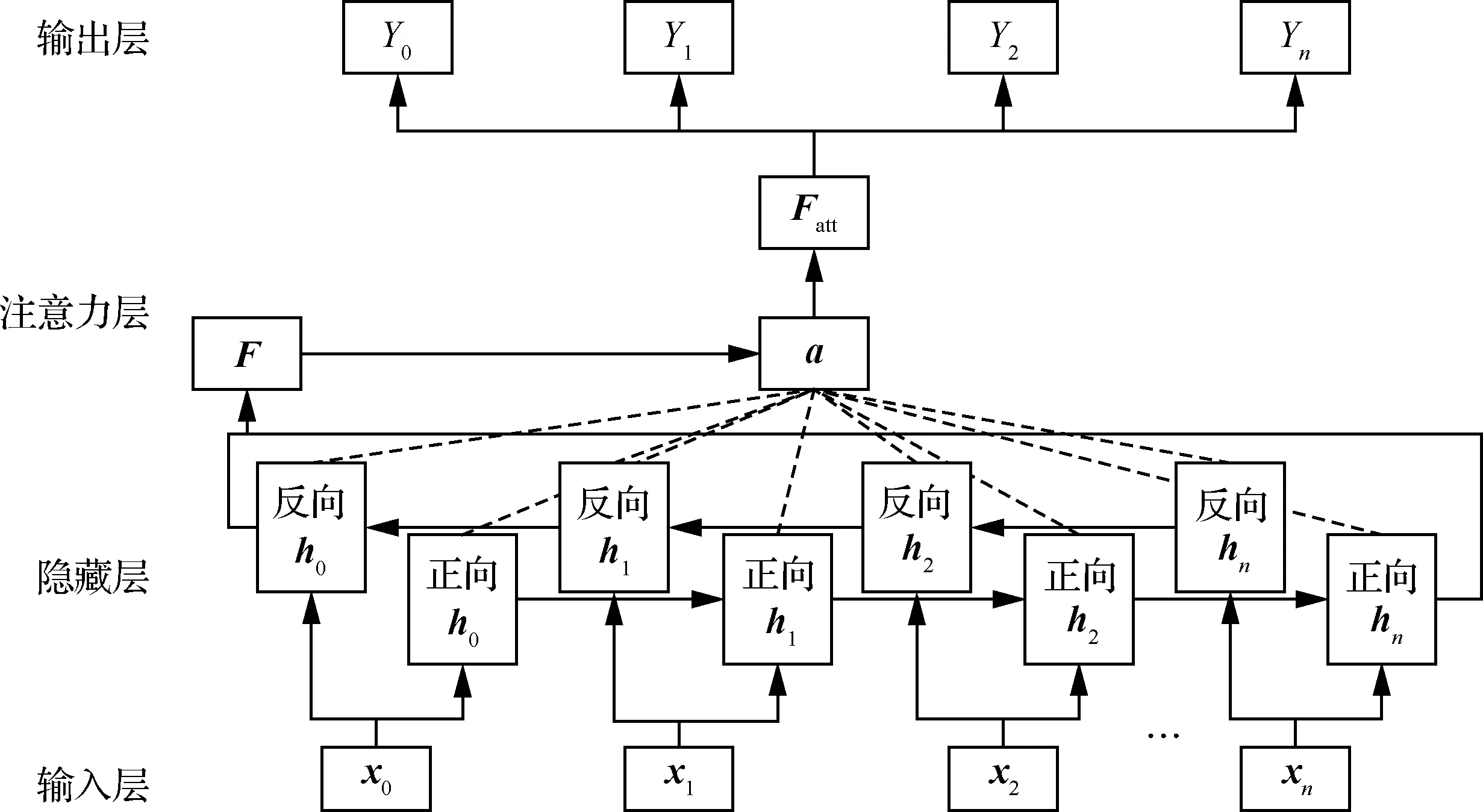
图6 基于注意力机制的双向LSTM结构示意图Fig.6 Schematic diagram of structure of attention-based bi-directional LSTM
图6中,为双向LSTM中各自独立方向最终隐藏层状态值的和,称为双向LSTM的最终状态;为所有时刻下隐藏层单元状态对于最终状态的注意力概率分布,其中的分量表示时刻下双向LSTM状态对最终状态的注意力概率,由该时刻下各自独立方向的状态相加而得,为经注意力加权后的文本特征向量。
基于注意力机制的模型一般都包含了两部分计算过程,一是关于注意力概率分布的计算过程,二是基于注意力分布的最终特征计算过程。
为时刻下的输出数据对于最终状态的注意力概率,其表达式为
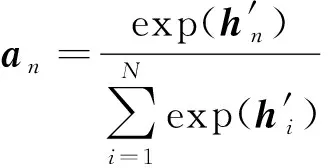
(3)

(4)
式中:为时刻下的双向的隐藏层状态值的和;为输入序列元素的个数;为类别标签的数量;为权重矩阵。式(4)利用softmax函数作为注意力概率分布的计算方式。
基于注意力分布的最终特征计算公式为

(5)
在得到基于注意力机制的文本特征向量后,通过输出层的softmax函数,计算得出分类标签的概率分布,计算过程表示为

(6)
′=
(7)
式中:为模型预测出的类别的概率分布;为模型输出层的权重矩阵;′att()为向量′中第个分量值,向量长度与分类标签的数量相等。经过softmax函数分类可得基于注意力机制下文本类别概率分布,并与真实类别分布求取交叉熵损失,表示为
(,)=-lg()
(8)
2.4.2 基于注意力机制的双向长短期记忆网络算法的关系抽取流程
基于注意力机制的双向长短期记忆网络算法的关系抽取分为实体抽取、数据集划分、关系标注、模型训练、模型测试和关系抽取。图7为基于注意力机制的双向长短期记忆网络算法的关系抽取流程图。
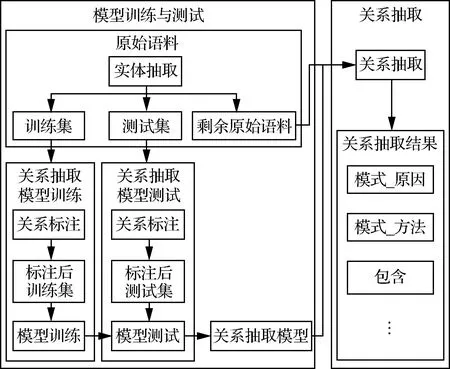
图7 基于注意力机制的双向LSTM的关系抽取流程图Fig.7 Flowchart of relation extraction based on attention-based bi-directional LSTM
使用基于双向长短期记忆网络算法的实体抽取模型抽取原始语料中的实体,生成“头实体 尾实体 关系 所在句子”形式的语料,其中因为关系是有向的,需要区分头实体与尾实体,二者在语料中的位置不可互换。如“小明在天安门”中实体“小明”和“天安门”之间的关系为“所在地点”,则生成的语料为“小明 天安门 所在地点 小明在天安门”。
选取部分生成的语料,以8∶2的比例划分为训练集和测试集。对训练集和测试集进行关系标注。
完成标注后,以训练集语料中头实体、尾实体和所在句子为输入,关系为标签,训练基于注意力机制的双向长短期记忆网络的关系抽取模型。
使用测试集测试训练后模型的关系抽取效果,将模型从测试集语料中抽取出的关系与人工标注的关系进行对比计算准确率和召回率,计算方法同实体抽取。
使用测试后训练好的模型抽取剩余语料中的关系,完成基于注意力机制的双向长短期记忆网络算法的关系抽取。
2.5 基于Neo4j的知识图谱构建
在抽取非结构化知识中的实体和其间关系后,需根据这些抽取的知识构建知识图谱。
在诸多图谱构建工具中,Neo4j拥有多种优点,包括高性能、设计的灵活性和开发的敏捷性。
Neo4j存储了原生的图数据,可使用图结构的自然伸展特性设计免索引邻近节点遍历的查询算法。图的遍历是图数据结构具有的独特算法,即从一个节点开始,根据其连接的关系可快速、方便地找出它的邻近节点。这种查找数据的方法并不受数据量的影响,因此在面对大量数据时查找效率更高。
一个系统对数据的需求会随事件和条件的改变而改变。图数据结构的自然伸展特性及其非结构化的数据格式使Neo4j的数据库设计可具有很大的伸缩性和灵活性。随需求的变化而增加的节点、关系及其属性并不会影响原来数据的正常使用。
Neo4j数据模型设计直观明了,以其为工具构建的知识图谱更容易进行迭代。
基于以上优点,选择Neo4j作为图谱构建工具。
2.6 基于知识图谱的智能应用
完成知识图谱的构建后,可通过知识图谱实现智能应用,包括智慧搜索与推荐及智能问答。
2.6.1 基于知识图谱的智慧搜索与推荐
智慧搜索指用户向系统输入实体名,系统输出有无该实体。在搜索过程中,用户输入的实体名中可能存在错别字。为解决该问题,本图谱采用基于相似度的搜索,在没有完全匹配的实体时,将输出与输入实体名相似度较高的实体。常用的相似度算法包括余弦相似度、欧氏距离相似度和最长公共子序列(Longest Common Subsequence,LCS)相似度等。最长公共子序列相似度与两个字符串间同顺序相同字符数量有关,相同字符越多,相似度越高,因而能更好地处理用户输入中存在错别字的问题。
子序列指一个序列删除若干个元素得到的新序列,两个序列的公共子序列指同时是两个序列子序列的序列,而最长公共子序列则是两个序列所有公共子序列中最长的序列。
最长公共子序列指将两个序列分别删除若干个字符,得到两个子序列,在所有可能的子序列中相同且最长的一组子序列。计算两个序列之间的最长公共子序列可使用枚举法和动态规划法。枚举法先列举两个序列各自所有的子序列,然后将这两组子序列相互之间一一比较,得到最长公共子序列。枚举法的算法复杂度与两个字符串长度之和成指数关系,随序列长度增加运算次数显著增加。字符串普遍较长,因此枚举法不适用于字符串相似度的计算。
动态规划法解决了枚举法难以解决寻找长字符串最长公共子序列的问题。动态规划法求解两个字符串之间最长公共子序列示意图如图8所示。
利用动态规划法求解字符串“BDCABA”和“ABCBDAB”之间的最长公共子序列的过程如下:
1) 根据字符串长度,生成7×8的矩阵,令0,=,0=0。计算矩阵中每个位置的数值,若两个字符串位置和位置对应字符相同,则,=-1,-1+1;若对应字符不同,则,=max(-1,,,-1)。如位置对应的和两个字符串的字符均为“B”,则=+1=1;若位置两字符串对应字符分别为“D”和“B”,则=max(,)=1。
2) 两字符串间最长公共子序列长度为矩阵右下角位置的值,图8中长度为4。
3) 从矩阵中位置开始回溯。回溯规则为若当前位置为,,选择-1,、,-1、-1,-1中数值最大的位置;当最大值有多个时可随机选取。
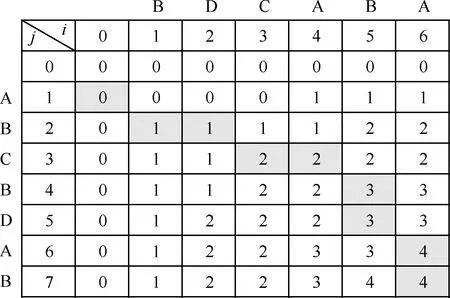
图8 动态规划法示意图Fig.8 Schematic diagram of dynamic programming
4) 根据回溯规则,得到一条回溯路径→→→→→→→→,=0,回溯结束。
5) 选取回溯路径上所有数值发生变化前的矩阵位置,即、、、,将这些位置对应的字符按顺序排列即可得两字符串的最长公共子序列“BCBA”。回溯路径可能不止一条,对应的最长公共子序列不止一个。
推荐功能指在进行智慧搜索的同时,图谱会根据相似度输出与其拥有相似关联实体的其他实体。相似度计算方法与智慧搜索相同,为基于最长公共子序列相似度的方法。
2.6.2 基于知识图谱的智能问答
智能问答指用户向知识图谱输入问题,知识图谱输出该问题的答案。智能问答的关键在于问题分类,即用户需要什么类型的结果。常用的问题分类算法包括K均值聚类、贝叶斯分类和朴素贝叶斯分类。朴素贝叶斯分类器具有较高的效率和良好的泛化能力,故选择朴素贝叶斯分类器作为搜索和问答的方法。
朴素贝叶斯分类器是概率分类器中最简单的分类器,在很多情况下具有相当高的分类准确率,以高效率和良好的泛化能力而著称。该分类器假设在给定类变量时属性变量之间条件独立,即

(9)
式中:()为类边缘概率;为种不同的问题分类,={,,…,};为从问句中提取的维特征,={,,…,}。在条件独立性假设下,朴素贝叶斯分类器具有简单的星形结构,如图9所示。
在朴素贝叶斯分类器结构基础上的联合概率分解形式为
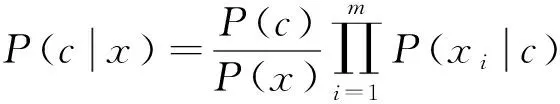
(10)

图9 朴素贝叶斯分类器结构示意图Fig.9 Schematic diagram of structure of naive Bayesian classifier
式中:(|)为条件概率。
依据联合概率的分解形式,得到朴素贝叶斯分类器的表示形式为
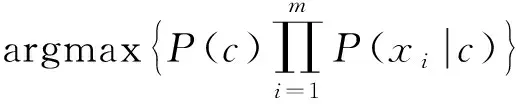
(11)
使式(11)取最大值的问题分类即为问句所属问题分类。
在利用朴素贝叶斯分类器完成问题分类后,结合与知识图谱中实体匹配得到的问句关键词,在知识图谱中进行检索将得到的答案输出给用户,完成智能问答。
3 知识图谱在飞机电源系统故障诊断中的应用
3.1 数 据
案例使用的数据来自飞机电源系统故障手册文档。该文档包含飞机电源系统可能发生的故障、故障表现、故障原因和解决措施。该文档部分内容为
“电源参数显示系统显示发电机输出电压为0V或只有几伏电压
可能原因:① 副励磁机绕组短路。使用万用表检查绕组电阻为0,或者用兆欧表检查绝缘电阻为0;② 主发电机激磁绕组断路。
排除方法:① 将发电机从发动机上取下来,送往修理厂修理,更换副励磁机定子组件;② 将发电机从发动机上取下来,送往修理厂修理,更换主转子组件。”
其中“电源参数显示系统显示发电机输出电压为0V或只有几伏电压”是故障模式“无刷交流发电机故障”的故障表现;“副励磁机绕组断路”为故障模式“无刷交流发电机故障”的故障原因;“将发电机…更换主转子组件”为故障模式“无刷交流发电机故障”的解决措施。
对飞机电源系统故障手册中的内容进行数据预处理。具体地,将“可能原因”“故障现象”“排除方法”之后编号项中每一项与其对应的故障模式单独成句。经数据预处理后的飞机电源系统故障手册部分内容为
“无刷交流发电机故障的故障表现为电源参数显示系统显示发电机输出电压为0V或只有几伏电压。
无刷交流发电机故障的可能原因为副励磁机绕组短路。使用万用表检查绕组电阻为0,或者用兆欧表检查绝缘电阻为0。
无刷交流发电机故障的可能原因为主发电机激磁绕组断路。
无刷交流发电机故障的排除方法为将发电机从发动机上取下来,送往修理厂修理,更换副励磁机定子组件。
无刷交流发电机故障的排除方法为将发电机从发动机上取下来,送往修理厂修理,更换主转子组件。”
将该文档中部分语料划分为训练集和测试集,用于实体抽取和关系抽取模型的训练和测试。
3.2 本体构建
基于专家知识,案例构建飞机电源系统故障诊断知识图谱的本体,共包含实体类型4个,关系类型3个。
实体类型包含故障模式、故障原因、故障现象和解决方法。关系类型及其头、尾实体类型如表1 所示。构建完成的本体可视化结果如图10所示。

表1 关系类型、头实体和尾实体类型Table 1 Relation types, head entity and tail entity types

图10 本体可视化结果Fig.10 Visualization result of ontology
3.3 实体抽取结果
飞机电源系统故障手册文档原始语料划分出的训练集共有137句,4 344字;测试集共有31句,910字。
根据构建的本体,使用BMEO格式标注训练集中的实体。共标注实体267个,实体标注结果如表2所示。
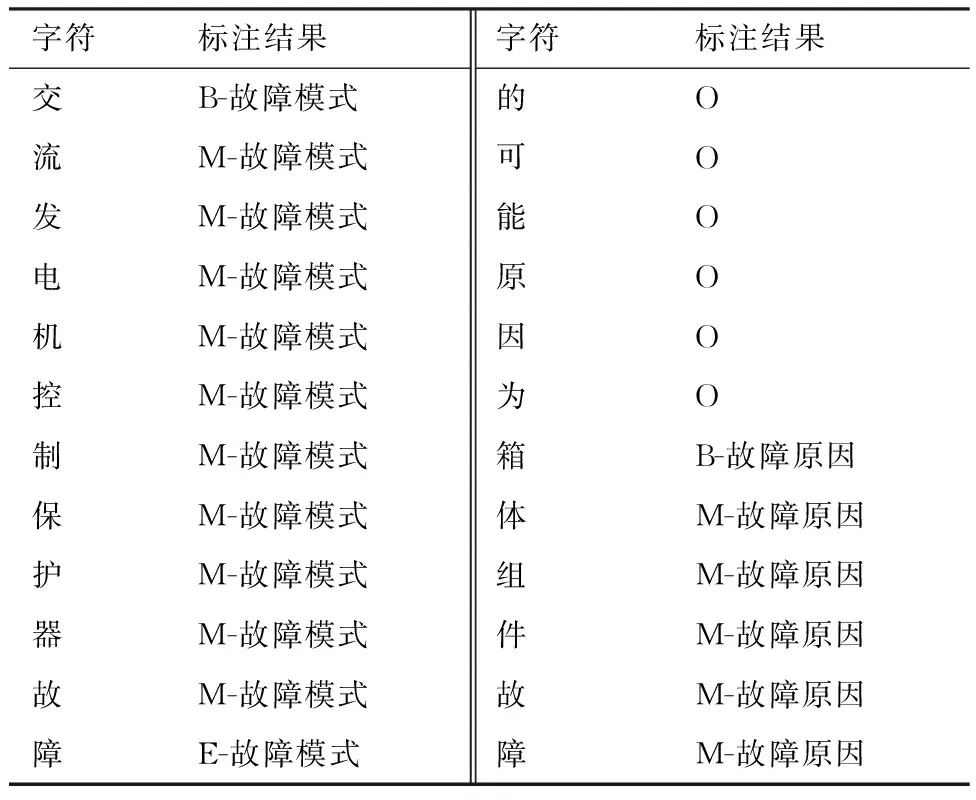
表2 实体标注结果Table 2 Entity tagging results
例如,“交流发电机控制保护器故障”的实体类型为故障模式 (Failure Mode),因此其第一个字符“交”对应标签为“B-故障模式”,最后一个字符“障”对应标签为“E-故障模式”。
对飞机电源系统故障手册文档进行实体标注后,使用开源标注工具brat进行可视化展示,效果如图11所示。
例如,在图11原始语料中的句子“交流发电机控制保护器故障的故障表现为调压输出为0”中,标注出了故障模式实体“交流发电机控制保护器故障”和故障现象实体“调压输出为0”。
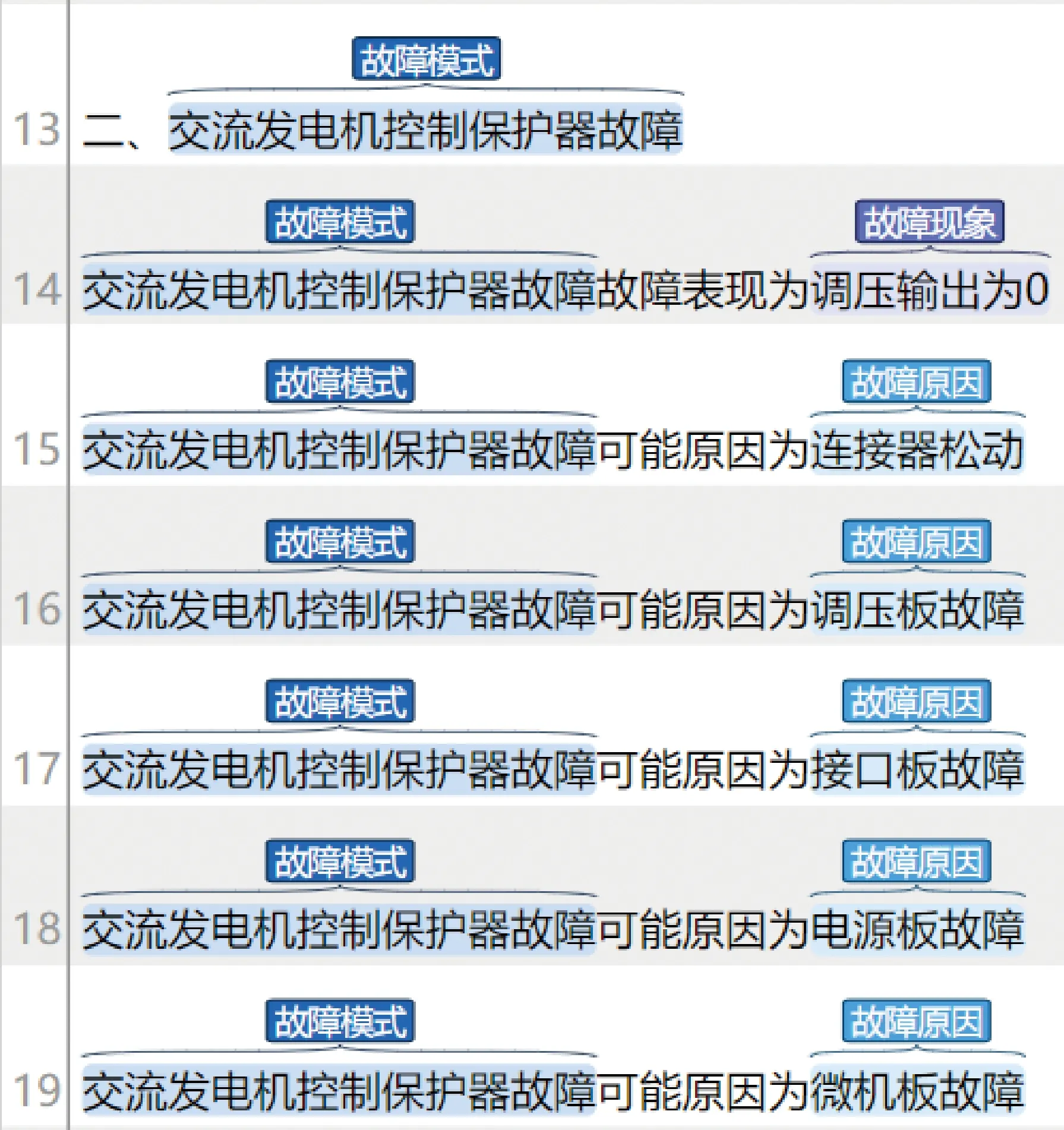
图11 实体抽取模型训练集文本标注可视化Fig.11 Visualization of training text annotation for entity extraction model
使用标注后的训练集文本训练双向LSTM实体抽取模型,模型由一个embedding层、一个双向LSTM层和一个全连接层组成。实体抽取模型参数如表3所示;模型配置如图12所示,图中为语料中最长句子的字符数;为所有BMEO实体标签的种类数加2,增加的两项为双向LSTM实体抽取所需的标签〈unk〉和〈pad〉。

表3 实体抽取模型参数Table 3 Parameters of entity extraction model

图12 实体抽取模型配置Fig.12 Configuration of entity extraction model
模型输入为句子中所有的字符,模型输出为个维向量,每个字符对应一个向量。若某字符对应的向量中数值最大的维度为,则该字符对应第个实体标签。根据每个字符对应的实体标签提取实体。
进而将测试集文本送入训练好的模型抽取实体,并与人工标注的实体进行对比。实体抽取模型测试结果如图13所示,可看出利用基于双向长短期记忆网络的算法成功实现了对测试集文本语料的实体抽取,共910条知识,准确率为99.63%,召回率为71.58%。
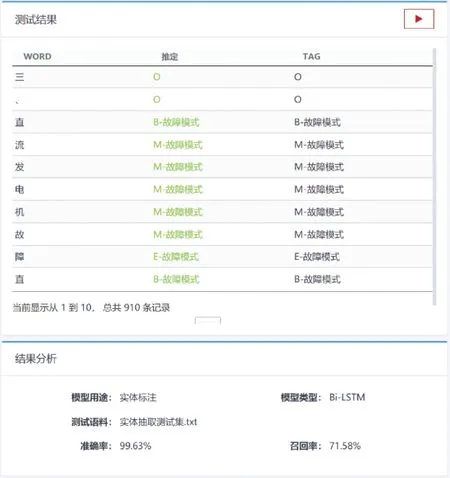
图13 实体抽取模型测试结果Fig.13 Test results of entity extraction model
完成测试后,使用实体抽取模型抽取原始文档中的实体,用于知识图谱构建。
3.4 关系抽取结果
关系抽取训练集和测试集划分与实体抽取相同。表4展示了用于进行关系抽取的训练集语料。根据构建的本体,以“头实体 尾实体 关系 所在句子”的格式整理训练集中的语料,如表5所示。
例如,在表4中的句子“主交流电源系统故障的故障表现为‘主交流’告警”中,实体“主交流电源系统故障”与实体“‘主交流’告警”之间的关系为“模式_现象”,因此生成的语料为“主交流电源系统故障‘主交流’告警 模式_现象 主交流电源系统故障表现为‘主交流’告警”。表5展示了关系抽取语料文本整理结果。

表4 关系抽取模型语料Table 4 Corpus of relation extraction model

表5 关系抽取模型语料文本整理结果Table 5 Text arrangement results for corpus of relation extraction model
使用开源标注工具brat对飞机电源系统故障手册文档中的关系进行标注,可视化展示效果如图14所示。
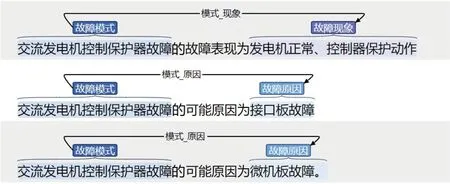
图14 关系抽取模型训练集文本标注可视化效果Fig.14 Visualization of training text annotation for relation extraction model
图14原始语料中的句子“交流发电机控制保护器故障的可能原因为接口板故障”中,标注出了实体“交流发电机控制保护器故障”和实体“接口板故障”之间的关系“模式_原因”。
使用处理后的训练集文本训练基于注意力机制的双向LSTM关系抽取模型,模型由1个词向量embedding层、2个位置向量embedding层、1个双向LSTM层、1个Attention层、1个关系向量embedding层和1个softmax层组成。关系抽取模型参数如表6所示,模型配置如图15所示,图中为本体中关系类型的数量。

表6 关系抽取模型参数Table 6 Parameters of relation extraction model

图15 关系抽取模型配置Fig.15 Configuration of relation extraction model
对于关系抽取语料中的每个句子,以一个实体的第一个字符在句中的位置为坐标原点,词向量Embedding层输入为句子中所有的字符,位置向量Embedding层1输入为句子的头实体位置向量,位置向量Embedding层2输入为句子的尾实体位置向量。其中,实体的位置向量指其所在句子中每个字符距该实体首字符的距离。关系向量Embedding层输入为所有关系类型,每个关系类型对应一个数字。
模型输出为维向量,每个句子对应一个向量。若某句对应的向量中数值最大的维度为,则该句中头尾实体之间的关系为第个关系。
根据实体标注结果,将测试集文本组织成“头实体 尾实体 所在句子”的格式,将处理后的测试集文本送入训练好的模型抽取实体关系,并与人工标注的关系进行对比。关系抽取模型测试结果如图16所示,可看出利用基于注意力机制的双向长短期记忆网络算法成功实现了对测试集文本的关系抽取,共31条知识,准确率为75.00%,召回率为75.00%。
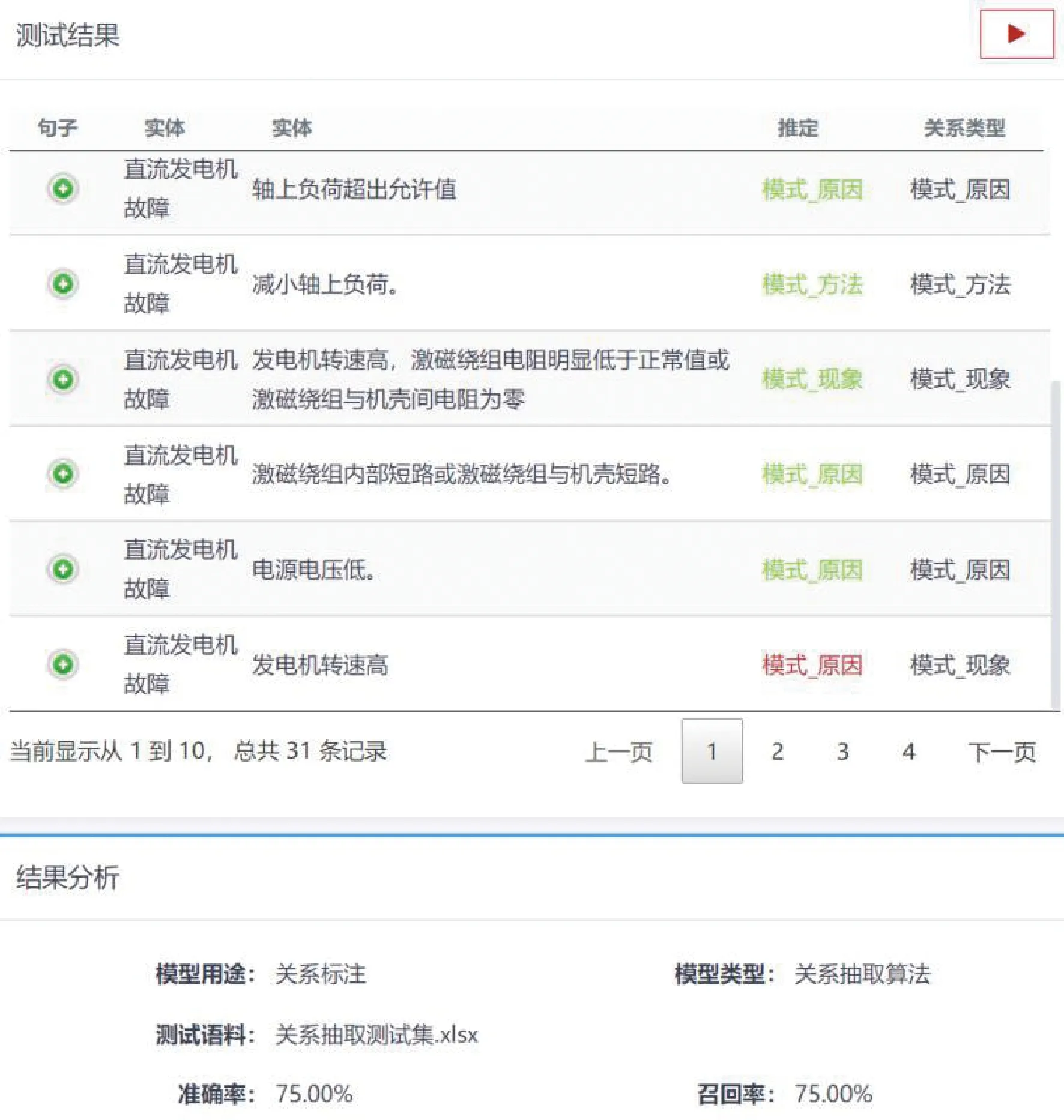
图16 关系抽取模型测试结果Fig.16 Test result of relation extraction model
完成测试后,使用原始文本的实体抽取结果将原始文本组织成“头实体 尾实体 所在句子”的格式,并使用关系抽取模型抽取原始文档中的关系,用于图谱构建。
3.5 知识图谱构建结果
原始语料中每个实体作为一个节点,每个关系作为一条连接其头实体和尾实体的边。使用Neo4j将原始文本中人工标注和模型抽取的结果构建为飞机电源系统故障诊断知识图谱。由于构建的知识图谱整体包含的内容较多,为更清晰地展示效果,选取部分知识图谱内容进行可视化展示,如图17所示。
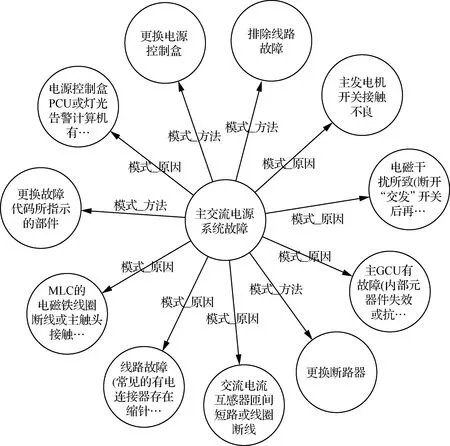
图17 飞机电源系统故障诊断知识图谱部分内容可视化展示Fig.17 Visualization of part of knowledge graph for aircraft power system fault diagnosis
构建的图谱共包含实体74个,其中故障模式16个、故障原因34个、故障现象7个、解决方法17个。关系98条,其中模式_原因76条、模式_现象6条、模式_方法16条。构建的知识图谱详情如图18所示。

图18 飞机电源系统故障诊断知识图谱详情Fig.18 Details of knowledge graph for aircraft power system fault diagnosis
经人工审核可知,该知识图谱已将原始文档中大部分知识抽取并存储,实现了飞机电源系统故障诊断知识图谱的构建。
3.6 智能应用结果
完成知识图谱构建后,可通过智能问答系统和智慧搜索与推荐系统进行基于飞机电源系统故障诊断知识图谱的搜索、推荐和问答。
3.6.1 智慧搜索与推荐结果
智慧搜索与推荐系统支持对于某一实体的搜索,在知识库中对该实体的相关信息进行检索并输出;同时还会根据相关实体的相似度进行推荐。智慧搜索与推荐效果如图19所示,可看出智慧搜索与推荐系统能实现对于实体“直流电源系统故障”的搜索及相关信息展示,并能根据相似度匹配算法实现具有相同故障原因和相同解决方法的故障模式推荐。
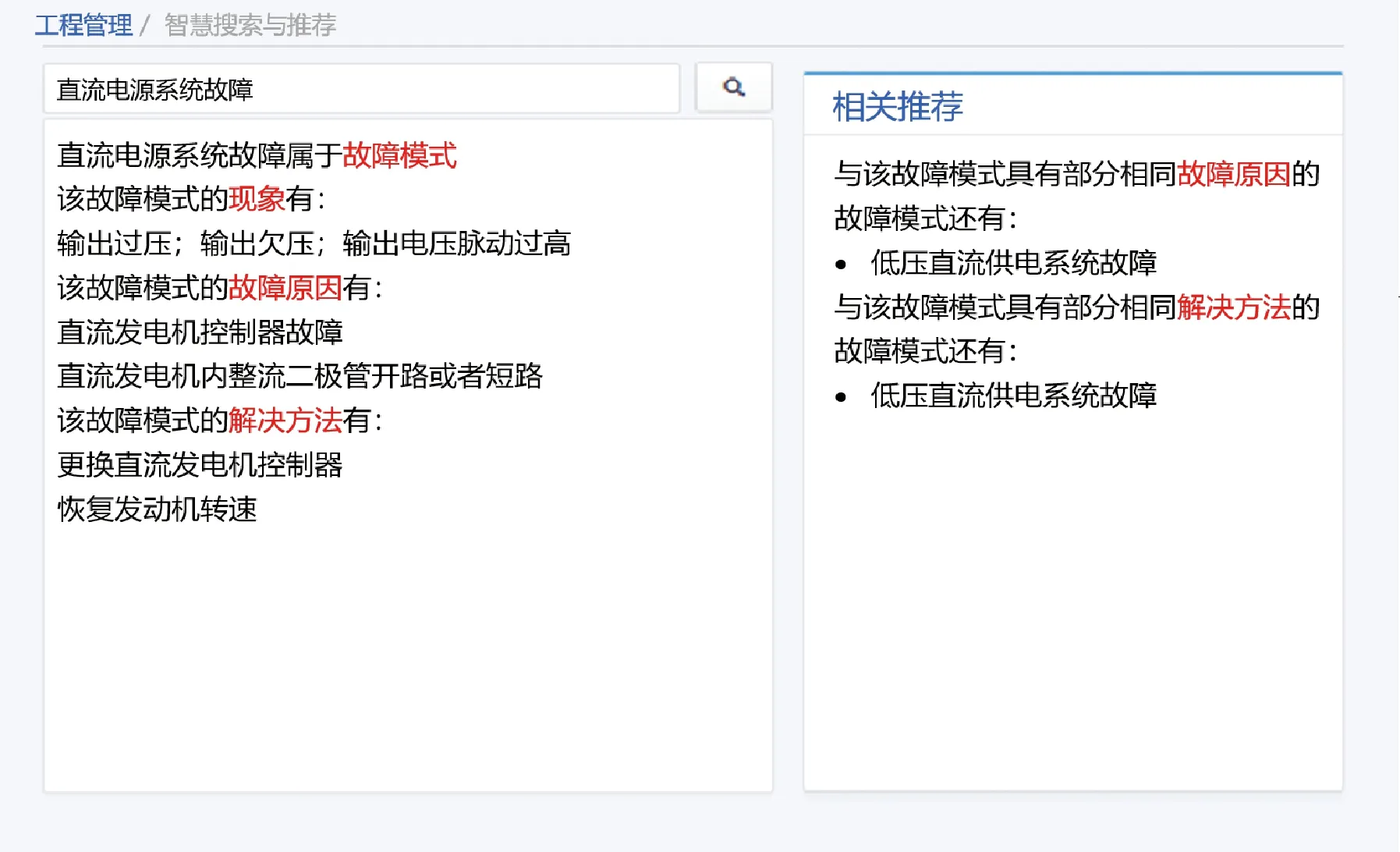
图19 基于知识图谱的智慧搜索与推荐Fig.19 Intelligent search and recommendation based on knowledge graph
3.6.2 智能问答结果
问答系统支持有关实体数量、关系数量、某一实体相关信息等的提问。智能问答效果如图20所示,可看出智能问答系统对于实体数量、关系数量、实体“应急交流电源故障”相关信息等的提问能给出相关问题的有效答案。
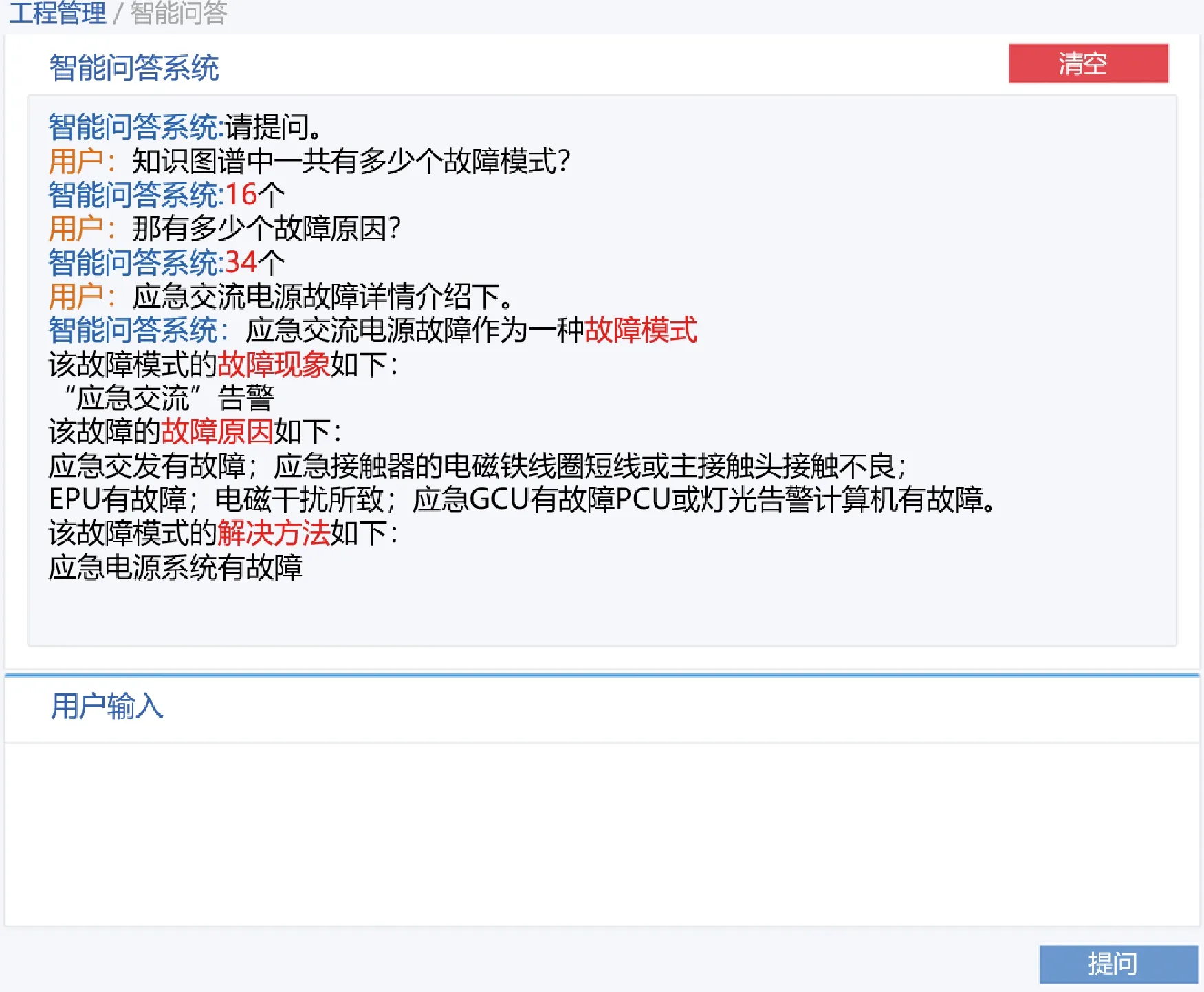
图20 基于知识图谱的智能问答Fig.20 Intelligent Q & A based on knowledge graph
4 结 论
针对现有故障诊断方法对非结构化知识资源利用效率低的问题,借鉴知识图谱技术在其他领域成功应用的经验,提出了一套面向飞机电源系统故障诊断的知识图谱构建及应用全流程方法。利用所提方法能对飞机电源系统设计、研制、使用等阶段产生的非结构化知识数据进行充分挖掘,构建的知识图谱能为故障知识搜索、问答、推理诊断等任务提供丰富的知识基础。以真实飞机电源系统故障手册语料为例,对提出的知识图谱构建及应用方法进行了案例验证,实现了非结构化飞机电源系统故障诊断知识的结构化存储、基于知识图谱的智慧搜索与推荐以及智能问答等应用,为知识图谱技术在中国故障诊断领域的实际应用提供了有力支撑。
此外,由于航空故障诊断领域语料来源较少,模型训练语料不充分,仅以飞机电源系统排故手册作为数据源构建的知识图谱体量较小。未来笔者将在飞机的运行使用过程中,利用不断产生的语料数据进一步提高知识抽取模型的精度,并对构建的知识图谱进行动态知识更新,从而更好地服务于飞机电源系统故障诊断。
