基于改进YOLOv3的铁路关键作业流程自动鉴别系统
2022-09-06张志晨郑文静王昱凯
张志晨,李 军*,何 波,郑文静,王昱凯
1.齐鲁工业大学(山东省科学院)信息与自动化学院,山东 济南 250353;2.山东大学 信息科学与工程学院,山东 青岛 266000
随着科技进步,“以视频可视化推动作业标准化”的目的指日可待。目前,为积极落实 “可视化设备管理和规范应用”相关要求,济南铁路集团公司济南车辆段落实了视频录制、采集、分析等相关的基础设施、配备专业人员并建立了管理制度。但局限于各车间人员紧缺且视频分析数据量大,全段月均产生视频数据量近60 TB,有大量作业视频需要人工审查,此方法不仅工作量巨大,且容易漏掉关键信息。现以济南地区为试点,通过研发关键作业流程自动鉴别技术,使作业视频分析速度大大提升。
目前,目标检测领域已和深度学习紧密相连,其主要方法有基于分类[1]和基于回归[2]的检测方法,相比传统的机器学习领域,YOLOv3在目标检测领域对物体的检测精度和检测速度方面进行了提升,但对于较小的物体和关键特征的识别精度仍无法满足列车安全检查中的要求。基于此类情况,设计出一种基于改进YOLOv3的铁路作业流程自动鉴别系统。对于改进的YOLOv3网络,主要是在网络结构、检测分支等角度进行优化和扩展,提高列车安全检查中小目标的关键特征的精度。
1 YOLOv3实现
1.1 网络结构
YOLOv3的网络结构由三部分组成,其结构图如图1所示,分别是darknet53构成主干部分,FPN构成加强特征提取网络,YOLO_Head利用卷积的方式构成特征融合网络[3],其中darknet53网络中使用了连续的1×1卷积和3×3卷积。YOLOv3处理信息的原理可理解为一张图片经过尺寸调整,统一为416×416×3的大小,作为输入,经过darknet53骨干,进行5次下采样,通过残差模块和卷积模块处理以后,得到大小为13×13的检测分支。随后在传输路径中分离出一次上采样操作,与darknet53中的第四次下采样的输出进行相连,得到大小为26×26的检测分支[4]。和以上过程类似,在形成大小为26×26的检测分支时的传输路径中分离出一次上采样操作,与darknet53中的第三次下采样的输出进行拼接,得到大小为52×52的检测分支,至此YOLOv3网络搭建完成。以上部分构成了YOLOv3的大组件,相比YOLOv2而言,增添了残差网络,并利用残差结构加深网络结构的深度。
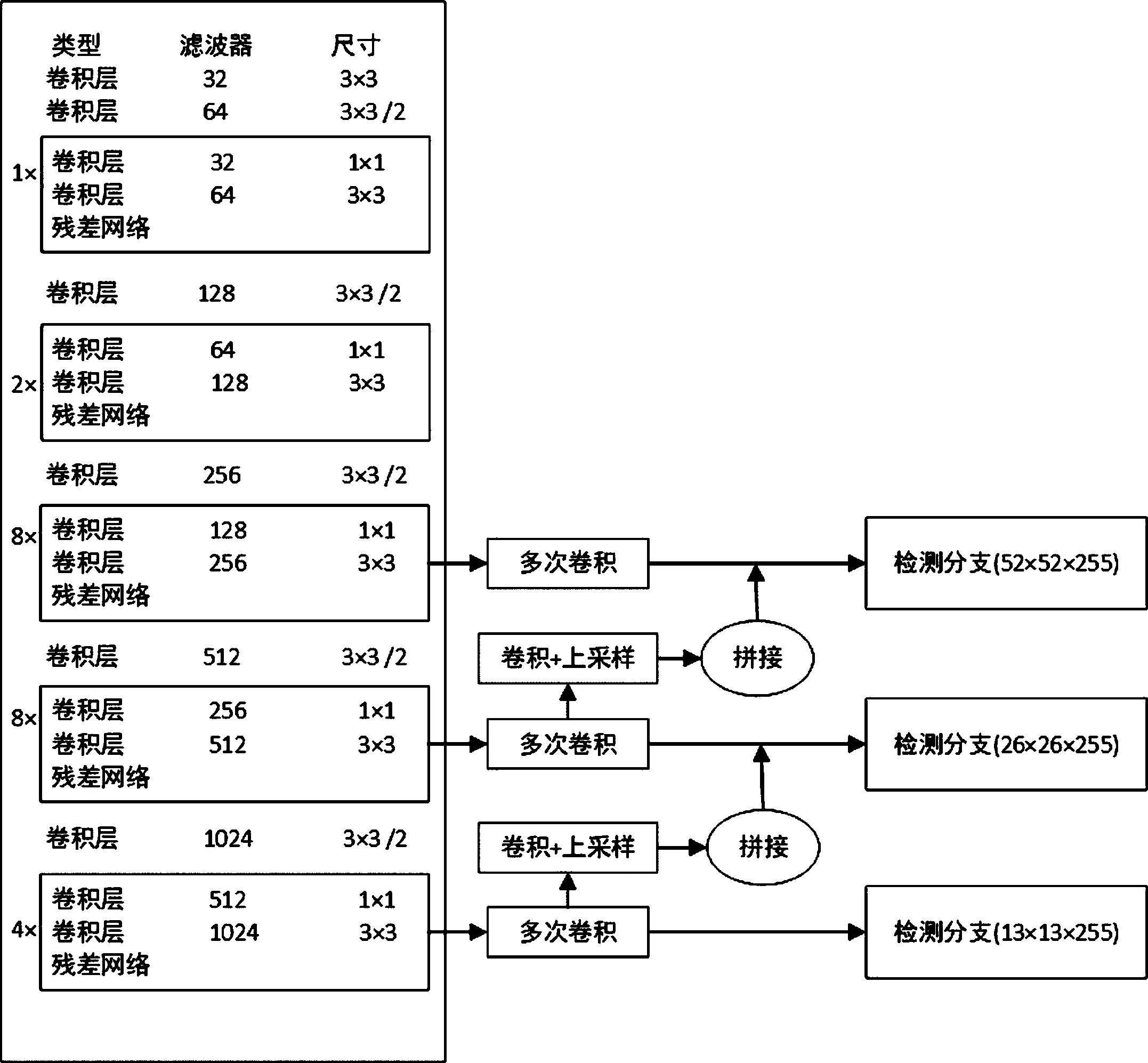
图1 YOLOv3网络结构
1.2 YOLOv3方法
YOLOv3将特征图划分成13×13、26×26以及52×52的网格,每个网格预测3个先验框,每个先验框会对边界框进行预测以及对设定类别进行识别和检测[5]。YOLOv3中每3个边界框由1个锚框负责,而每3个锚框由1个网格单元负责,故每个网格单元负责9个边界框,边界框会负责4个值,分别是tx、ty、tw、th,这4个值分别是预测出的x值、y值、宽和高。如图2所示,若网格中的预测物体与图像左上角有偏移(cx,cy),则会进行更正,更正的方法由式(1)给出[6]:

图2 锚框更正
bx=σ(tx)+cx,
by=σ(ty)+cy,
bw=pwetw,
bh=pheth,
(1)
其中,σ()代表经过sigmoid的预测值,经过sigmoid函数后,tx和ty取值范围限定在[0,1],不仅降低了偏移过多的概率,还保证负责预测的网格中包含物体中心;bh为更正后的中心值和宽高;pw、ph为锚框的宽和高;cx、cy为偏移量。
图3为13×13的先验框可视化到原图上的一幅图,左边为原始的先验框,右边为先验框调整后的结果。黑色的是原始中心点,红色的是中心点进行右下方的调整,范围在0和1之间。13×13的先验框图像相当于13×13的特征层映射到了原图上,将原图划分成13×13的网格,即图中每一个点就是一个网格。每个特征点的先验框位于网格左上角。先验框中心的调整受网络预测结果的影响,首先会将先验框中心缩小到最小范围之内,其次对其宽高进行调整,最后使其成为预测框。若有一个物体中心落在特征点的右下角方框之内的话,那么此物体则由这个特征点进行预测。相当于在原图上进行了一次密集采样,这个采样会将整个图片都包含进去,网络预测结果会对这个先验框进行调整,并且判断先验框内部是否包含物体以及物体种类。26×26和 52×52的特征层的先验框与13×13的类似。先验框为获得较大的交并比,使用了不同的长宽比以及尺寸,对目标宽高的设定进行辅助,从而提升网络的检测效果,获取损失函数所需的交并比,同时使得模型的学习过程更加轻松。

图3 先验框原始图像(左)与调整后图像(右)
1.3 YOLOv3损失函数
YOLOv3损失函数由中心损失(Lcen)、宽高损失(Lwh)、置信度损失(Lcon)以及分类损失(Lc)组成[7],损失函数(L)由式(2)给出:
L=λcoordLcen+λcoordLwh+Lcon+Lc,
(2)
其中,λcoord与λnoobj都是惩罚系数,λcoord由坐标预测,代表包含检测目标时的置信度的惩罚系数,λnoobj是不包含检测目标时的置信度的惩罚系数;YOLOv3损失函数为上述所述的四部分损失和,其中,中心损失由式(3)给出:
(3)
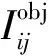
宽高损失由式(4)给出:
(4)

置信度损失由式(5)给出:
(5)

分类损失由式(6)给出:
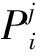
1.4 评测指标
本系统的评测指标由mAP、precision、recall、F1组成,其中,mAP为均值平均精度。precision为精度,其反应的为检测的目标准不准,精度公式由式(7)给出:
其中,TP为正样本被正确识别为正样本;FP为负样本被错误识别为正样本。
recall为召回率,表示检测的目标全不全,召回率公式由式(8)给出:
其TP含义同式(7),FN为正样本被错误识别为负样本。
精度与召回率的调和均值用F1表示,其公式由式(9)给出:
其中precision和recall代表精度和召回率。
1.5 改进YOLOv3网络
YOLOv3虽然目标检测领域中有所突破,但应用于铁路安全关键点检测的时候,不满足较小特征点的检测精度,由此对其结构进行改造。为使主干的输入与输出相结合,darknet53利用了残差网络进行特征提取,但冗余分量较多,因此删除了3层残差网络,原始YOLOv3残差网络层次分别为1、2、8、8、4,改造后层次为2、6、6、4、2,由23层降低为20层,使得特征图划分为低频和高频特征图,通过池化层使低频特征图压缩,减少冗余分量;对于darknet53过渡层而言,在原始YOLOv3基础上增添了1×1的卷积层,并与3×3/2的卷积层交替使用,不仅减少了下采样过程中特征信息丢失的可能性,还提高了关键特征的平滑提取。
本系统改进的YOLOv3网络结构如图4所示。除以上改进外,还扩展了多尺度YOLO_Head模块,将原有的3个YOLO_Head模块扩展为4个,增添104×104的YOLO_Head模块,改进后的YOLOv3拥有4个特征层,且分别位于darknet53的中上层、中间层、中下层以及底层,四个特征层为(104,104,128)、(52,52,256)、(26,26,512)以及(13,13,1024),残差网络中提取到的特征对4个YOLO_Head模块共同开放,在对原有的3个YOLO_Head模块进行上采样的时候,添加了输出为52×52的上采样过程,实现和104×104特征层级联,并从前一阶段的特征图里获得更具体的信息。第4尺度的预测结合了早期全部的计算以及YOLOv3网络的前期细粒度特征。在4个YOLO_Head模块上分别对大、中、小、极小的物体进行独立检测,使得特征提取相对平滑,有助于提高小物体检测效果。

图4 改进YOLOv3网络结构
2 关键作业流程自动鉴别系统实现
2.1 系统模块
铁路关键作业流程自动鉴别系统包括以下六部分,分别为关键特征获取模块、特征图区分模块、预训练模块、模型输出模块、识别检测模块、数据记录模块。系统流程为:首先根据系统的关键特征获取模块输入特征图,进行图片格式转换以及尺寸调整操作,统一为RGB格式和416×416大小,随后对图像实现归一化,设置epoch,对比冻结阶段的epoch和解冻阶段的epoch,若前者小于后者,则进行前向传播,获取预测值,通过系统的高频特征图与低频特征图区分模块来减少分量冗余。随后利用预训练模块将特征图传入分类器与回归器,利用反向传播更新网络参数,直到冻结阶段的epoch大于解冻阶段的epoch,通过模型输出模块输出模型并保存对应的权重。通过识别检测模块输入视频,视频将被逐帧提取,加载权重后,构建检测网络,对视频进行分析检测,完成后通过数据记录模块保存检测结果,记录信息。
2.2 仿真平台配置
操作系统:Windows10 64位;处理器:Intel(R)Core(TM)i9-9820X CPU @3.30GHZ 3.31GHZ;GPU:NVIDIA GeForce RTX 2080 Ti;CUDA:10.1;cuDNN:7.6;深度学习框架:tensorflow-gpu=2.1.0;语言:python=3.7。
2.3 数据集搭建
此数据集源于铁路安全检查中人工作业流程的视频,检测目标为大型连接器、中型连接器以及电箱锁,将视频中包含关键特征点的部分进行逐帧提取,获取3 158张图片,对其进行降噪处理[8],例如相同的目标图像和不清晰的目标图像,经过删除和筛选操作获取2 000张图片,采用labelimg软件对每张图片进行标记,同时生成对应的xml文件,在标签文件中,有以下几个关键信息,图片的宽、高、深度,是否用于语义分割,识别难度以及坐标等。本系统按照VOC2007数据集格式进行整理,并按照8∶2的比例将数据划分为训练集和测试集。本数据集有用3类标签,分别为大型连接器connector A、中型连接器connector B以及电箱锁lock。
2.4 模型训练
基于以上所述的数据集,将图像格式调整为RGB,转成RGB形式的图像有预训练权重且训练效果更好;随后,会对输入图片进行不失真的尺寸调整,具体过程为将图像的主体部分放在新图片的中心区域,在图像周围添加上灰条,保证图像主体不发生失真;其次对输入的图像进行归一化,并添加batch_size维度,将图片传入到网络当中进行预测,此过程中会将所有特征层的预测结果进行堆叠,调整加入灰度条图像的中心坐标,通过预测框置信度与预测种类置信度相乘计算得分,目的是判断得分是否大于confidence,取得满足门限的框的坐标和得分,进行非极大抑制处理,最终进行图像绘制。
将数据输入改进后的darknet53网络,残差网络将主干的输入与输出结合,进行特征提取,通过下采样操作,获取四个有效特征层并在加强特征网络FPN中进行特征融合,把获取的结果传入分类器与回归器,预测特征点对应物体的情况,通过梯度下降法计算关键点对应的四种损失;进行冻结和解冻训练,对冻结阶段训练次数进行设置,并进行训练计算;其中,第一次进行训练时Freeze epoch=1;判断当前训练次数是否小于解冻阶段迭代训练次数,若所述当前训练次数小于解冻阶段训练次数,利用多尺度模块将特征图划分为低频和高频特征图;若所述当前训练次数不小于解冻阶段训练次数,则结束训练;在冻结阶段,模型的主干被冻结,此时模型的特征提取网络不发生改变,由于训练参数较少,模型占用的显存较小,仅对网络进行微调,此时设置的学习率为1×10-3,帮助模型跳出局部最优解。在解冻阶段,此时模型的主干不被冻结,特征提取网络会发生改变,由于训练参数较多,占用的显存较大,整个模型都会发生改变,因此进行以下修改,设置batch_size为8、学习率为1×10-4,以便保证训练模型的稳定性。随后利用1×1的卷积调整通道数,利用3×3的卷积进行特征整合,分别处理改进后的网络得到的4个特征层,在此数据集中种类数为3类,故输出层的维度分别为(13,13,24)、(26,26,24)、(52,52,24)、(104,104,24)。在改进的残差网络中结合4种不同尺度的特征层提取关键特征,采用原有的3种卷积特征层和新增添的卷积特征层预测目标坐标和位置,保存每个epoch的结果,至此,模型训练完成。
3 实验结果分析
系统测试效果如图5所示。初始YOLOv3识别效果与改进YOLOv3识别效果对比如图6所示。其中,图6中左图为初始YOLOv3识别的效果图,置信度为0.60,右图为改进YOLOv3识别的效果图,置信度为0.78,改进后的YOLOv3利用(13,13,24)、(26,26,24)、(52,52,24)、(104,104,24)的检测分支检测大型连接器、中型连接器以及电箱锁,其中(104,104,24)的检测分支在对电箱锁的检测上取得了较大突破。

图5 测试效果图

图6 初始YOLOv3识别效果与改进YOLOv3识别效果对比图
图7为初始YOLOv3与改进YOLOv3评测指标的对比,左侧一列为初始YOLOv3的评测指标,右侧一列为改进YOLOv3评测指标。其中,第一行中的图为mAP指标,提升了12.05%,电箱锁置信度提升了0.33;第二行中的图为电箱锁的精准度曲线图,可见,电箱锁的精度提升了21.39%;第三行中的图为电箱锁的召回率,提升了10.34%;第四行中的图为电箱锁的F1值,提升了0.16。在2 000张图片的训练过程中,所用时间为41 min,相比改进前的YOLOv3网络的训练时间、mAP、召回率、精度以及F1值而言,改进的YOLOv3网络在训练时间上和检测精度上取得了较大的突破。

图7 初始YOLOv3(左)与改进YOLOv3(右)指标对比
4 总 结
本系统提供的基于改进YOLOv3铁路关键作业流程自动鉴别的方法,优化了darknet53部分,简化了残差结构,减少了计算量;过渡层在原有的基础上引入了1×1的卷积层,有效降低了下采样过程中特征信息的丢失现象;划分了特征图的高频特性和低频特性,使得冗余程度有所下降;扩展了维度为(104,104,24)的YOLO_Head模块,提高了对于铁路安全检查中较小关键点的检测精度;增加了52×52特征层上采样的过程,结合特征金字塔的多尺度融合,实现了与104×104特征层拼接,提高了此方法在铁路作业流程安全检查场景中的使用性。
但改进后的算法仍有不足之处。首先,对于检测的视频,要求其分辨率为1 920×1 080,若低于1 080 p,则关键特征的置信度会有所下降。其次,本系统检测时无法倍速检测,只能以原视频的速率进行检测。最后,检测效果受到外界环境影响,例如,人工作业时视频录制的关键点停留时间、光线等等。未来所做工作应为减少外界环境的影响,同时可以倍速检测视频。
