基于语义特征的视觉定位研究
2022-09-06张梦珠黄劲松
张梦珠 黄劲松
1武汉大学测绘学院,湖北 武汉,430079
视觉定位的基本流程一般包含特征提取、特征匹配及运动估计等步骤,其中,传统方法中特征提取是提取图像的角点特征,如SIFT特征点、ORB特征点等。然而这种基于角点特征的定位方式存在一定的局限性,一方面,有些角点特征容易受到视角、光照等因素的影响,导致在某些场景下不可用。另一方面,角点这种像素级的特征缺乏对场景的理解,很难与人类和现有地图进行交互。
所谓语义,就是将低级特征进一步归纳组织,达到人所理解的分类层面。语义特征相较于角点特征更接近人类认知世界的方式,语义在图像认知、环境感知和定位领域已经越来越得到重视。为了获取更加丰富的环境信息,在SLAM(simultaneous localization and mapping)技术上增加语义的理解显得尤为重要,相较于典型的低级特征,语义特征能够更好的表示所处的环境是什么,环境中包含哪些物体。
近年来,随着深度学习与计算机硬件的迅速发展,目标检测与深度学习的结合,物体识别和分割的可用性不断提高,语义特征的提取不再遥不可及。目前典型的基于深度学习的目标检测,有以YOLO系列[1-3]为代表的One-stage方法和以Faster RCNN系列[4-7]为代表的Two-Stage方法。随着优秀语义信息提取框架的不断涌现,语义特征在定位中也有许多尝试,不断有研究用语义信息来优化传统的SLAM。文 献[8]中SalientDSO在DSO(direct sparse odometry)基础上利用语义信息来调整选取特征点的权重,文献[9]中利用语义信息选择具有更大信息量的特征点。除了利用语义信息改进特征点选取策略的研究,利用语义信息来去除动态点的干扰、闭环检测等的研究也不断涌现[10-13]。
语义信息在建图中也有很多应用,早期的SLAM++是将物体识别与基于尺度不变特征变换(scale invariant feature transform,SIFT)特征点的视觉定位结合[14],利用SIFT特征点识别物体,然后生成局部语义地图。后来Fioraio等[15]将3D物体的识别加入到SLAM构建的地图中。在原本SLAM建图的基础上加入语义信息的方案在逐步完善[16-20]。然而,在目前常见的地图中,存储传统SLAM中特征点的代价是巨大的。因此,本文提出一种基于语义特征的视觉定位方法,通过语义特征和地图实现定位。
1 语义定位的基本原理
1.1 系统概述
本文基于语义特征的视觉定位的系统流程图如图1所示。首先,在对采集的图像进行预处理后,训练卷积神经网络,使其能提取训练过的语义特征,并利用训练好的神经网络实现对图像中的静态语义特征的提取,得到图像中包含的语义及其在图像中的位置;然后,根据视觉几何原理恢复图像中语义的点云,并进一步恢复其几何模型以确定语义特征的位置;最后结合语义地图,对语义特征进行匹配,从而实现定位。

图1 语义特征定位算法流程图Fig.1 Flow Chart of Localization Algorithm Based on Semantic Characteristics
1.2 提取语义特征
对于一幅图像,人类的视觉系统可以直接将图像内容识别为语义对象,而计算机则是以底层的像素特征为依据,即计算机中对图像的存储是以像素为单位的矩阵形式。图像的语义特征即图像中包含的物体对象,提取语义特征,即识别图像中的语义并确定其在图像中的位置。本文采用基于卷积神经网络的方法进行语义特征的提取,选取实现效果和计算效率比较理想的YOLOv3目标检测算法作为语义特征提取的方案。
图2是YOLOv3的网络结构框架图,图像通过该网络可一步实现对图像中目标的识别及目标预测框位置的确定。这种算法的主要特点有两点:①采用Darknet-53这种层数较多的卷积神经网络做为特征提取网络,通过有效训练能较好地提取出想要的特征。②分别在3个尺度上进行目标检测,能够更加准确地检测出目标。
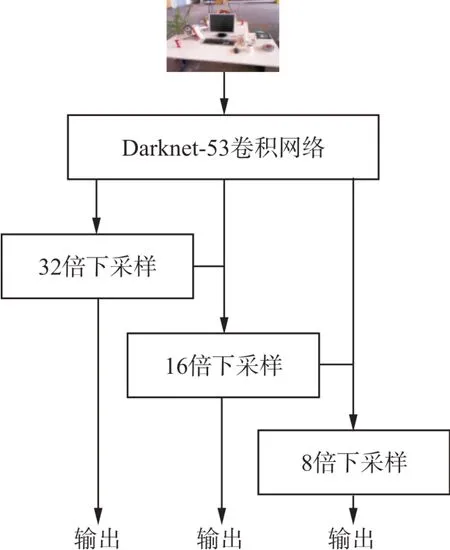
图2 网络结构图Fig.2 Network Structure Diagram
1.3 语义特征位置确定
在基于传统像素级的角点特征的视觉定位中,完成特征点的检测后特征点的位置就相当于已经确定了,这时特征的位置即为其像素坐标,因而可直接进入匹配定位的过程,而语义特征则不然。通过提取语义特征已经检测出图像中的语义特征在图像中的位置,但是检测出的语义是以矩形框的形式表示其在图像中的位置,而矩形框中包含许许多多的像素点,为了更好地描述语义特征的位置并实现和已知地图的结合,本文提出一种基于点云确定几何模型的策略来确定语义特征的位置,首先对于检测出的每个语义特征均进行点云的恢复并判断其几何模型,然后计算模型参数,最后确定出位置坐标。
在针孔相机下,空间一点P映射到图像平面上一点P1,其几何投影模型如图3所示。
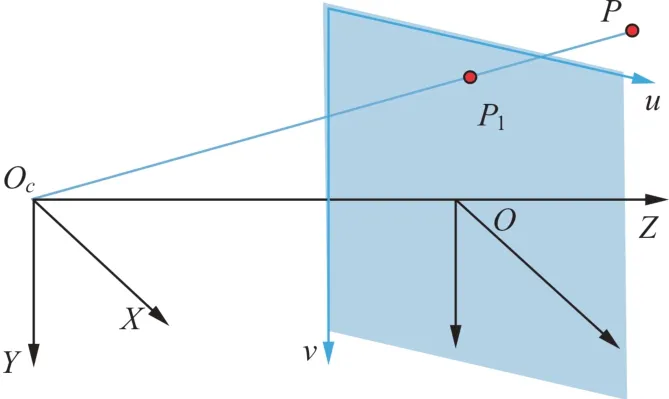
图3 几何投影示意图Fig.3 Geometric Projection Diagram
根据几何关系可知:

在深度相机中,深度图中的深度即为相机坐标系下Z轴的坐标。而对于双目相机,首先需要获取视差图,本文使用运算速度较快的BM(block matching)算法进行双目匹配,从而获取双目的视差图,然后根据式(2)求得Z坐标。

式中,b是双目相机的基线长;D为双目的视差。上述过程描述了如何恢复图像中一个像素点对应的相机坐标,对于一个完整的语义特征,只需根据目标检测中得到的语义特征在图像中的所有点的像素坐标即可恢复出语义特征的点云。
在恢复的点云中,可能包含了少部分并非是目标上的点,若直接根据所有点最小二乘来拟合语义的几何模型,这些噪声点可能会影响几何模型计算的效果,因此本文采用随机抽样一致算法(random sample consensus,RANSAC)来求解语义特征对应的几何模型。其基本思想是随机抽取若干样本计算模型,判断模型对样本数据的符合情况,不断迭代直至计算出合适的模型。
已知点云图集,求解几何模型表达式算法的具体步骤如下:
1)随机选取若干点集Ji,根据这些点集计算模型M i;
2)根据距离判断模型M i对点云中所有点的符合情况,DisP<Threshoid;P符合M i;
3)如果有足够的点符合该模型,则采用该模型,否则重新选取点,重复步骤1)~步骤2)过程,直至找到合适模型或到达最大迭代次数。
上述基于RANSAC的求解几何模型步骤中,随机选取点的个数与模型相关,模型最少需要多少点能唯一确定就选取多少个点进行求解,如平面需要不共线的3个点,直线则需要不同的两个点确定。
如图4所示,为图像中语义特征(显示器)经过目标检测、恢复点云、求解平面模型的过程,其中红色的平面为确定出的平面模型。

图4 几何恢复过程Fig.4 Flow Chart of the Geometric Recovery
图5为将点状语义(植物)恢复点云,垂直投影到二维平面,然后根据上述算法选取参考点的过程,图5中红色点为最终确定的语义特征的位置。可见该算法可有效地提取语义特征的位置,并且具有一定的鲁棒性,不会受少量噪声点的影响,因此本文选用此算法。

图5 参考点选取过程Fig.5 Reference Point Selection
1.4 匹配及定位
通过上述语义特征的提取,已经得到当前位置图像中的语义信息,具体包含其几何模型、语义类型及位置坐标信息,接下来需要结合地图中的信息进行语义匹配,进而求解出当前相机在世界坐标系下的位置。
在传统的三维点云匹配中,常用的匹配算法是迭代最近点(iterative closest point,ICP)[21-23],其基本思想是:通过找到两组点云集合中距离最近的点对,根据估计的变换关系(R和t)来计算距离最近点对在经过变换之后的误差,通过不断的迭代直至误差小于某一阈值或者达到最大迭代次数,从而确定最终的变换关系。对于传统的具有描述子的特征点来说,可以根据描述子来对点进行匹配。而对于语义特征来说,一方面,这种语义描述信息并非像传统特征点的描述子那般精细,传统特征点的描述子通过很复杂的计算方式来尽可能使得描述子和特征点几乎是一一对应的,而语义特征仅以语义特征所对应的物体标签进行描述。另一方面,其点不仅具有位置信息,还具有语义描述信息。因此,本文提出采用考虑语义约束的ICP算法,使用图像中的语义点坐标和地图中的地物坐标即毫无目的的匹配,也不会使匹配计算过程过于复杂。已知图像中语义点P及其相机坐标,地图中语义点Q及其世界坐标,求解相机的位姿T的具体步骤如下。
1)求图像中的各个点P i在地图中的最近点Q j两语义点之间距离公式:

2)将上述Qj看作Pi的对应点,求解转换矩阵T k;
3)重新计算图像中的各个Pi在经过T k转换之后的点,更新赋值给Pi;
4)重复步骤1)~步骤3)直至迭代次数或误差满足收敛条件。
在将地图和图像中的语义点匹配上后,本文采取基于奇异值分解(singular value decomposition,SVD)的方法求解转换矩阵即位姿。若图像中的语义点P i和地图中的语义点Q j相互匹配即为同一语义点,则其坐标应该满足P i=RQ j+t,问题可转化为求合适的R、t,使得点集P经过R、t的旋转平移后距离其匹配点集Q的距离最小,即:

对式(3)关于t求导,逐步化简最终可求得R和t,如式(4)~式(6)所示,其中H为点集P和Q之间的协方差矩阵,和为点集P和Q的中心点。
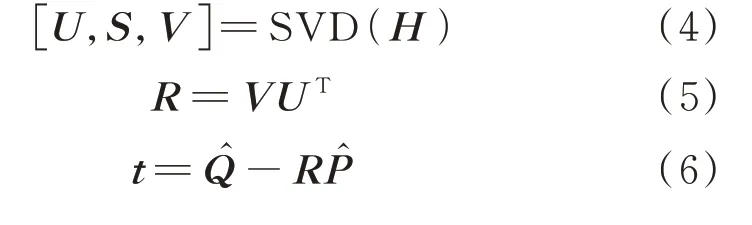
2 实验及结论
本文的实验数据选自慕尼黑工业大学(Technische Universität München,TUM)的Computer Vision Lab公布的RGB-D数据集中的一部分。
本文实验场景为图6所示的室内场景,按照上述中讲过的算法,对图像进行语义检测并恢复其在二维坐标下的坐标,然后结合二维地图进行匹配定位。本文选取用于定位的语义特征在图6中用矩形框标出,选取图像中“显示器(Monitor)”垂直投影后的两个端点和两颗“植物(Plant)”作为语义特征点与二维地图进行匹配定位。

图6 实验场景Fig.6 Experimental Scene
图7为图像中恢复的语义在二维平面坐标系下的坐标,这里的二维坐标系是以当前相机位置为原点,相机光轴方向为Y轴,垂直Y轴水平向右为X轴,其中圆形点为“显示器”两个端点的位置,星形点为“植物”的位置。图8为在地图中(世界坐标系中)相对应语义特征的位置,其中图中直线为“显示器”的位置,闭合的折线为桌子(Table)边缘位置,圆形点为“植物”的位置。
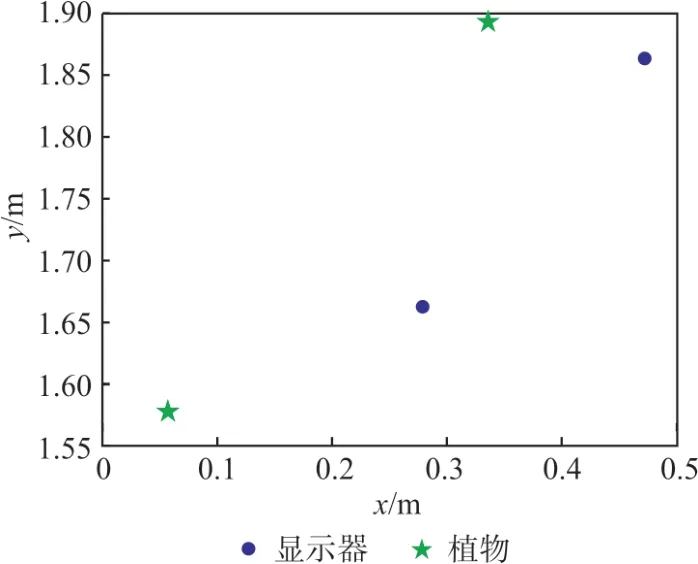
图7 语义点位置恢复Fig.7 Semantic Poinst Position Restoration
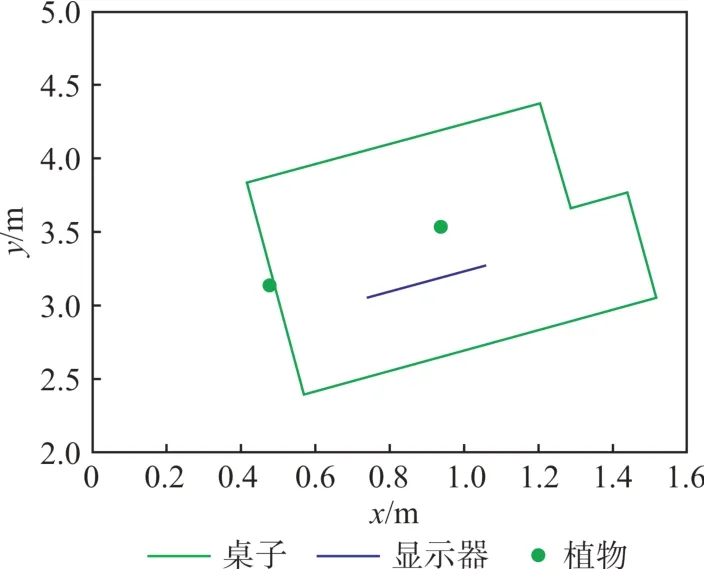
图8 地图中各目标的位置Fig.8 Location of Objects in the Map
实验定位结果与真值对比情况如表1所示,其中,真值是指相机位置在地图中真实的坐标,误差由估计值减去真值所得。由实验结果可见,按照本文方法,通过提取语义特征,可以利用地图实现定位。

表1 定位结果/mTab.1 Positioning Results/m
3 结束语
语义特征作为一种更加抽象的特征,弥补了传统角点特征的不足,并且能更好的表达周围环境。本文将语义特征引入到视觉定位中,设计了语义视觉定位系统的框架组成,从视觉图像出发,以语义特征为切入点,以语义地图为依据,实现对相机位置的确定。针对语义特征位置确定的问题,提出了一套行之有效的方案,针对语义特征的匹配问题,提出一种适用于本文的有效的匹配算法。最后实现本文所提算法,并通过实验验证了其可行性。
