一种基于语义地图的激光雷达定位方法
2022-09-06金泰宇黄劲松
金泰宇 黄劲松
1武汉大学测绘学院,湖北 武汉,430079
SLAM(simultaneous localization and mapping)技术能够解决机器人在未知环境下的定位、导航和建图问题,但是SLAM算法是基于马尔科夫性质的,即后一时刻的位姿由前一时刻的位姿推算而来,那么多次位置推算后,定位误差会越来越大,不能满足机器人的定位需求。此外,SLAM属于局部定位的方式,只能提供一个相对位置,在没有位姿初值的情况下无法确定自身在真实空间的绝对坐标,而当有额外的地图辅助时,利用地图绝对位置信息进行全局匹配定位能够帮助机器人获得更精确的位置。
语义地图是一种面向环境理解的地图模型,不似传统的栅格地图、拓扑地图等,它不仅包含周围环境的空间几何结构信息,同时也可提供环境的语义信息,即环境中物体的类别及位置信息等,能够使机器人完成高水平的人机交互。Vasudevan等[1]首先提出认知地图的思想,在拓扑地图上融合环境目标的语义信息,提升机器人理解、解释和表示环境的能力;Nietogranda等[2]基于语义信息对空间,区域进行分类并用于拓扑地图的构建;Dube等[3]提出Segmap算法,使用区域增长法分割点云并用数据驱动描述子进行语义信息提取,完成定位和地图重构。
目前市场上有丰富成熟的导航电子地图资源如高德地图等,这种地图可提供环境的语义信息如目标的类别、位置信息等。假如能把LiDAR单帧扫描到的树木、电线杆等目标的平面位置信息提取出来,就能与现成的电子地图语义配准,给机器人平面位置上的约束,帮助机器人更鲁棒的定位[4]。
因此,本文基于使用语义地图完成LiDAR定位的思想,利用语义提取算法提取出激光点云中静态目标的语义信息(包含类别和平面位置信息),与事先已知的包含同类型目标的语义信息的全局语义地图进行配准实现定位。该方法使用静态目标语义特征,配准稳定性高,运行所需的计算资源较小,且能给出一个可靠的绝对参考位置。
1 基于语义地图定位
1.1 定位流程
语义地图定位流程如图1所示。单帧点云处理部分,采用多线激光雷达作为数据输入端,利用滤波算法[5-9]去除点云的离群点与空洞,利用形态学滤波算法[7,10]剔除背景信息,然后利用语义提取算法[8,11]提取目标语义信息,并确定语义参考点,生成语义帧;语义地图定位部分,将单帧语义点云和事先已知的全局语义地图进行配准[12-15]完成定位,确定Li-DAR在全局坐标系下的位置。
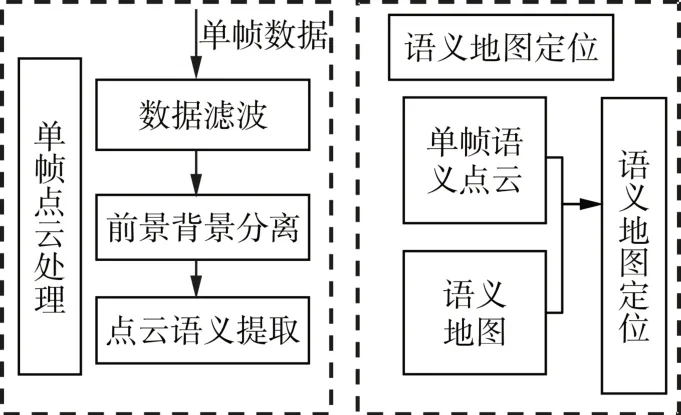
图1 定位流程Fig.1 Positioning Process
1.2 数据滤波
针对3种点云噪声进行处理:①离群点剔除(由遮挡等问题造成);②数据下采样(海量数据);③点云密度不规则。
采用统计滤波去除离群点,其方法为:对查询点的邻域进行统计分析,计算它到近邻点的距离。距离分布特性符合高斯分布N(u,σ2),u和σ2决定一个标准范围,距离在标准范围之外的点为离群点,从数据中去除。
采用体素栅格下采样法简化海量点云。该方法构造m×n×l的三维体素栅格,将点云数据填充至对应的小体素栅格,用每个体素内的所有点的重心替代该体素的其他点,减少了数据量,提高了程序的运行速度。
激光雷达的点云密度有距离中心点越远的地方越稀疏的特点,本文采用直通滤波剔除远处的、稀疏的部分,保留密集的、包含绝大部分特征的点云,节省计算资源。
1.3 前景背景信息分离
采集的点云含有大量的地面点(即背景信息,高达40%),应尽可能分离点云中的地面点,保留感兴趣的地物点即前景信息。
本文采用形态学滤波算法剔除地面点云。首先将LiDAR点云内插成二维网格数据,然后用形态学算子即腐蚀算子和膨胀算子依次处理网格数据。
腐蚀算子ep和膨胀算子d p满足关系:
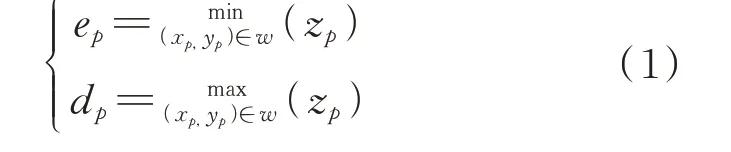
式中,w为形态学算子的尺寸;(x p,y p,zp)为网格化后的数据。
利用形态学算子过滤地面点时,首先必须合理设置算子的尺寸,如尺寸过大则建筑物点云和突起的地形点云可能同时被滤除;其次,滤除后的点云仍可能含部分的地物点,给定合适的高程阈值避免树木等地物点被判为地面点。
图2为利用形态学算子滤波操作滤除点云的效果。图中红色部分为地面点,占42%;灰色部分为地物点,占58%。
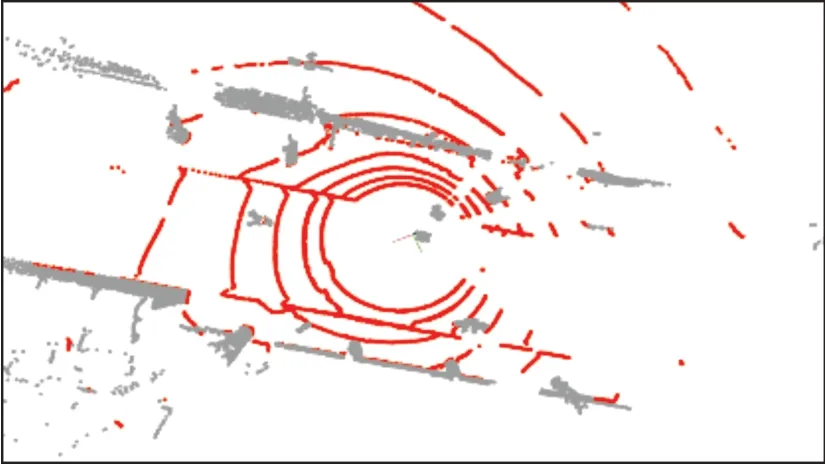
图2 地面提取Fig.2 Ground Extraction
1.4 点云语义提取
本文基于实验环境的关系,选取树木作为语义提取对象,需要用到点云分割算法。
首先,采用欧氏聚类算法基于欧氏距离将点云分割成多个子簇。欧式距离满足的关系式为:
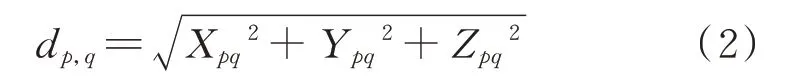
式 中,p的 位 置 为(X p,Y p,Z p);q的 位 置 为(X q,Y q,Z q);X pq、Y pq、Zpq分 别 为p、q两 点 的 坐 标差值。
然后,采用随机采样一致性分割算法[16]的圆柱面模型遍历所有子簇,找出含有树木的子簇。圆柱的模型表达式为:
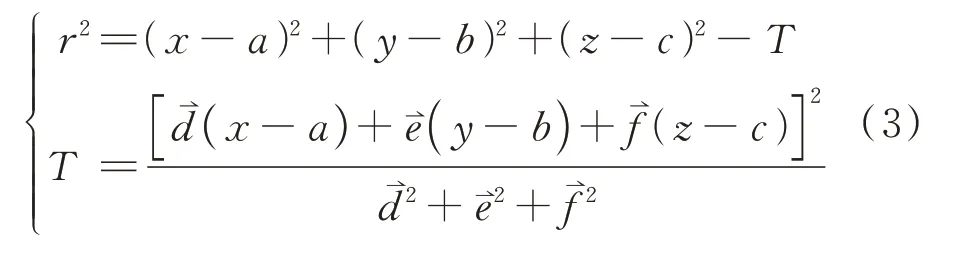
式中,(a,b,c)是轴线上的一点;(d⇀,e⇀,f⇀)为轴线的方向向量;r为半径;(x,y,z)为圆柱面上任一点。
提取点云中的树木之后,还需设置语义参考点,确定其位置信息。假设轴线与水平方向的夹角无限接近90°时,可统一选取轴线上z=0的点(即树木中心)作为语义参考点,其平面坐标(x,y)为:
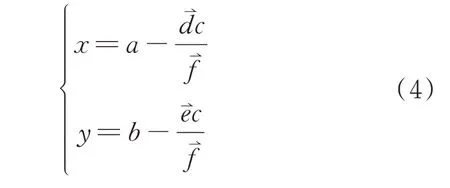
式(4)中各量的意义与式(3)相同。
语义提取出的参考点具有精确的位置信息,完成了从三维的、无序的、不规则的稀疏点云到二维的位置信息的树木中心的语义抽象。
三维稀疏点云转换成二维的位置信息,从信息多样性角度来看会造成信息的少量损失,但从配准的角度看,本文的静态目标特征稳定,配准效率能大幅提升,同时保持可靠的位置精度。因为LiDAR数据采集技术的局限性造成LiDAR不会在连续两个时刻扫描到同一点,但LiDAR的测程大及垂直方向的视场角宽,相邻时刻扫描到同一颗静止的树的概率远高于扫描到单个点的概率,因此基于静态的树木中心的配准稳定性非常高。点云语义提取处理结果如图3所示,树木提取准确率可达90%。

图3 语义提取结果Fig.3 Semantic Extraction Results
1.5 语义地图定位
基于语义地图的定位方法属于全局语义定位方式。语义地图中存储着树木(路标)中心的平面位置信息,并对LiDAR当前位置上扫描的点云进行语义提取得到语义帧,语义帧中存储的也是树木中心平面位置。将全局语义地图和当前位置生成的语义帧进行配准,得出两者之间的旋转平移关系,即可确定当前时刻LiDAR在全局坐标系下的位置。
配准算法是语义地图定位的关键一步。考虑到语义帧中语义目标特征比较稀疏,本文在配准时采用迭代最近点(iterative closset point,ICP)算法进行配准定位[17]。ICP算法根据已知的全局语义地图和当前时刻的语义帧,基于最小二乘法及距离误差最小的收敛准则,重复选择两者的对应关系点对,直到找出满足收敛准则的最优旋转矩阵R和平移矩阵t。误差函数E(R,t)为:
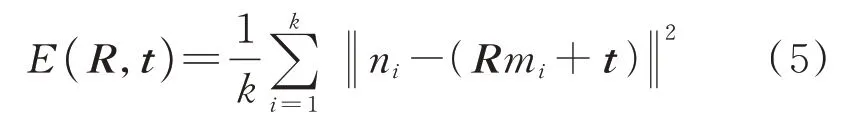
式中,mi、ni为全局语义地图和语义帧的对应点对;k为对应点对的个数。
根据ICP配准得到两者的旋转和平移关系,能将语义帧的位姿转换到全局语义地图的坐标基准下,数学关系为:

式中,X s为当前时刻的位姿;X m为LiDAR在全局坐标系下的位姿。
选取两帧点云,本文做了对比实验:①基于原始点云的ICP配准(见图4);②基于二维树中心的ICP配准(见图5)。比较其配准的(平移)结果和耗时,结果如表1、表2所示。

图4 基于原始点云的ICP配准Fig.4 ICP Registration Based on Original Point Cloud

图5 基于二维树中心的ICP配准Fig.5 ICP Registration Based on Two-Dimensional Tree Center

表1 配准结果/mTab.1 Registration Results/m

表2 耗时结果/sTab.2 Time-Consuming Results/s
由实验结果可知,实验②相比于实验①在静态环境下的配准耗时减少了46.1%;配准结果方面,可看出两者在X和Y两个维度的平移(定位)误差控制在0.2 m之内。由此可知,本文提出的定位方法在算法耗时上有显著提升,这对数据的实时处理有着较大的优势,同时也能给出可靠的定位结果。
2 实验结果及分析
本文使用的语义地图是在开源SLAM框架-hdl_graph_slam[4]基础上,编写语义提取模块,构建的全局语义地图。本文选取的实验场景为武汉大学信息学部求是一路旁田径场四周的林荫大道。数据采集设备为镭神16线混合固态激光雷达,数据采集路程全长共544.62 m。图6为实验场景,红色箭头方向代表数据采集方向。

图6 实验场景及路径Fig.6 Experimental Scene and Path
本文基于语义地图定位的思想和方法,选取3个实验算例进行定位结果分析。3个算例对应的位置分别为:①求是一路体育场旁;②求是二路学生宿舍二舍旁;③一号教学楼正面靠近求是二路旁。定位结果如图7所示。
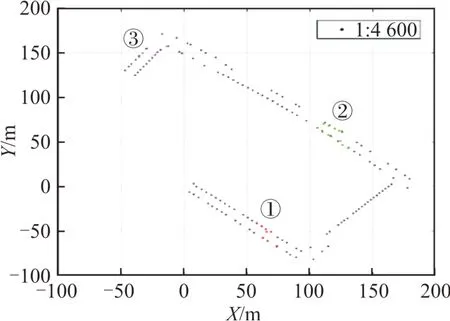
图7 3个算例定位结果Fig.7 Positioning Results of Three Examples
图7中,黑色点为地图点,每个点对应相应树木中心的平面坐标,共计142个点。
算例①,在该扫描位置上进行语义提取,共提取到8个点(图7中红色点),其中7个点为树木的平面坐标,且与地图点一一对应。在全局坐标系下,该位置坐标的真值为(61.843,-53.776)m,本文的定位结果为(61.544,-53.685)m。
算例②,共提取到11个点(图7中绿色点),其中9个点为树木的平面目标并与地图点对应。在全局坐标系下,该位置坐标真值为(121.958,60.712)m,本文的定位结果为(122.646,60.476)m。
算例③,共提取到7个点(图7中洋红色点),这7个点为树木的平面目标并与地图点对应。在全局坐标系下,该位置坐标真值为(-24.793,154.33)m,本文的定位结果为(-24.848,154.431)m。
3个算例的语义提取结果如表3所示,定位结果与真值的误差如表4所示。

表3 3个算例语义提取结果Tab.3 Semantic Extraction Results ofThree Examples
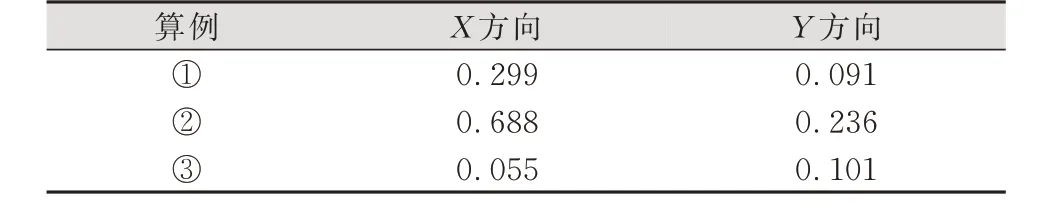
表4 3个算例定位误差/mTab.4 Positioning Errors of Three Examples/m
由实验结果可知,本文的方法是可行的,且使用到的静态特征是稳定的,能够提供一个稳定的全局绝对位置。未来若要提高定位精度,可从两个方向进行优化:
1)使用更高精度的并且包含更丰富语义信息的地图。现阶段使用的语义地图,是借助语义激光SLAM构建的,它存在误差积累问题,长时间会影响环境地图的精度。另外,地图包含的语义信息更丰富,那么一定程度上语义定位精度也会增加。
2)优化语义提取算法。本文虽已成功实现提取树木的中心的平面位置,但此种方法还有一定的局限性,例如当树木的轴线与水平面的夹角是锐角时,提取到的树心平面位置就会存在误差,未来还需要找出方法进行约束。此外,语义提取算法的结果对阈值(角度阈值、距离阈值等)比较敏感,阈值的波动也会影响语义提取出的树木的数量和中心坐标的数据质量,进而影响定位结果的精度。
3 结束语
本文提出利用全局语义地图进行LiDAR定位,利用形态学滤波算法进行地面点云分离,利用欧式分割算法和采样一致性分割算法提取出稳定的静态目标语义信息,与已知的全局语义地图配准,得到LiDAR的绝对位置信息,同时也可以发挥传统地图资源的使用价值。实验结果表明,该方法是可行的并且能够提供可靠的全局定位结果。本文是语义地图应用于智能移动机器人自主定位领域的一个探索,未来随着点云算法的优化,语义地图将表达更丰富多样的场景语义信息,智能移动机器人也就能应对更具挑战化的自主定位和导航任务。
