基于遗传算法的封装式特征选择研究
2022-08-31张照硕侯能
张照硕 侯能

摘要:在机器学习中,特征选择在数据预处理阶段被用来剔除数据集中的冗余特征。特征选择分为嵌入式、过滤式、封装式。其中,封装式特征选择在监督学习中应用广泛。本文主要研究将遗传算法用于封装式特征选择时,不同的个体选择策略与种群更新策略的结合对监督学习算法预测准确率的影响。实验结果表明,锦标赛选择法与精英个体参与遗传操作的精英保留策略相结合的方式,能够得到最好的效果。通过在所有数据集上的计算总平均准确率发现,这种结合方式比将所有特征用于学习的平均准确率高出1.2%。
关键词: 特征选择; 遗传算法; 个体选择; 精英保留; 预测准确率
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2022)19-0094-03
1 引言
现如今,机器学习已广泛应用在大数据分析、无人驾驶、人脸识别、自然语言处理等领域。作为人工智能研究的主要方向之一,机器学习将大量数据样本与目标算法模型相结合,使计算机处理问题的能力能够随着样本数量,即学习经验的增加而增强。根据学习模式的不同,机器学习的定义也有所区别。其中,监督学习是最基础,也是最重要的任务。监督学习中,数据集的样本包含特征和标签两部分。已知监督学习算法的前提下,监督学习就是通过训练样本构造出与具体算法对应的模型,该模型隨后用于预测未知标签值的样本对应的标签。预测准确率是评价模型预测能力的主要指标。为了构造预测能力更强的模型,除了需要更强的学习算法外,数据集的样本数量和特征数量也是影响模型性能的主要因素。需要注意的是,模型的预测能力并不会随着特征的增多而提高。相反过多的特征会引发“维度灾难”现象。这一现象反而会使模型过拟合导致模型的预测能力下降。
为了缓解样本的“维度灾难”,如何剔除样本中的冗余特征是数据预处理阶段关注的主要问题。关于样本的特征降维,特征选择是一种重要的技术[1]。特征选择有过滤式、选择式、封装式三大类。其中,过滤式特征选择较简单,对数据的理解有较好的表现,但对于特征优化、提升分类模型的泛化能力方面表现普通;嵌入式特征选择将特征选择算法嵌入学习算法中,学习结束时特征选择算法也随之结束;封装式特征选择从数据集的初始特征中不断选择子集,利用样本的特征子集训练目标学习器,然后根据学习器的性能评价特征子集的优劣。整个过程以不断迭代的方式找到和目标学习算法最匹配的特征子集。三类特征选择方法中,封装式特征选择是被广泛使用的一种,也是目前的主要研究方法。
假设样本的特征有M个,每个特征有被选择、不被选择两种可能,特征子集的可能组合方式可达2M种。封装式特征选择就是从可能的2M组合中找到最优的特征子集组合的过程。这是一个NP难问题[2]。求解封装式特征选择问题的方法主要有穷举法、启发式方法、元启发式方法。其中,穷举法会评价所有的特征子集。然而,这种方式会导致计算开销随着特征数量的增加而非线性增加,因此仅适用于特征数量较少的数据集;启发式通过人工制定的规则,从空特征子集开始逐步添加新未被选中的特征,或从全部特征开始逐步删除一个特征,或者两种方式结合。停止添加或删除特征的依据都是监督算法的预测准确率不再提高为止。启发式方法的特点是能高效地找到一个特征子集,但找到的特征子集距最优子集的评价指标较远。元启发式特征选择利用进化算法或群体智能算法(如遗传算法[3]、模拟退火[4]、蚁群算法[5]、粒子群算法[6])搜索最优解的框架,通过将机器学习算法的预测能力作为评价指标,来引导最优子集的搜索。相对于启发式方法,元启发式方法能得到更好的近似最优解。
本文主要研究将遗传算法用于封装式特征选择时,不同的个体选择策略与种群更新策略的结合对监督学习算法预测准确率的影响。通过在标准数据集上进行实验数据对比,发现采用锦标赛选择策略和最佳父代参与后代产生的精英保留策略这一组合,能够得到最好的优化效果。
2 问题描述和算法原理
2.1 问题描述
特征选择问题可以描述为:假设某数据集有N个样本,每个样本包含M个特征。特征选择的目标是从M个特征中选择m个特征(m≤M)的组合,使目标监督学习算法的预测能力达到尽可能最优的同时,m的取值也越小越好(m>0)。因此,在设计用于评价的目标函数时,不仅要考虑模型的预测能力,还要考虑被选中的特征数量。本文的优化目标除了模型的预测误差率,还包括被选择特征的数量占总特征数量的比值。具体地,目标函数形式化如下:
f(error, m)=α*error+(1-α)*(m/M) (1)
其中,error表示监督算法的预测误差率,(1-error)表示预测准确率。m表示被选择特征的个数,M为样本数据的特征总数。因此,m/M表示选中的特征数量占总特征数量的比重。α表示误差率与特征占比之间的权重。本文中,α取值0.99。这意味着,监督学习算法的预测能力仍然主要评价因素[7]。
2.2 遗传算法原理
遗传算法是一种基于自然选择和群体遗传机理的搜索算法,它模拟了自然界生物中的“适者生存”的进化过程[8-9]。在利用遗传算法求解问题时,每一个解都被编码成一个“染色体”,即个体。若干个个体构成了种群(所有可能解的子集)。遗传算法开始时会先随机地产生一定数量的个体(即初始解),然后根据预定的目标函数对个体进行评估,给出相应的适应度值。基于此适应度值,遗传算法通过选择、杂交和突变产生下一代个体。经过每代的进化,使种群中的个体朝着最优解的方向前进。
3 遗传算法求解封装式特征选择
将遗传算法用于封装式特征选择的求解时,个体解的编码方式,遗传操作中的个体选择、交叉、变异和种群更新过程如下所述:
2.1 编码方式
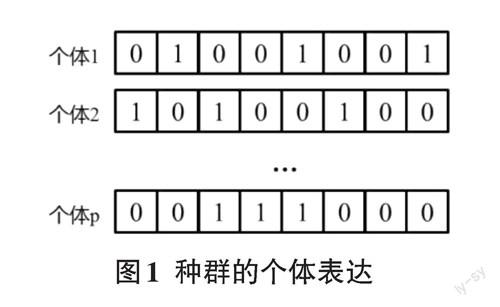
就本问题而言,每个特征有两种状态,即选择和未被选择。用1表示被选中,0表示未被选择,考虑所有M个特征,个体就可被表示成是长度为M的0-1串,该0-1串可代表一种特征选择方案。每种方案都会对应一个目标函数值,即公式(1)的结果,用以评价方案的优劣。当个体数量为P时,遗传算法的种群由P个0-1串及对应的目标函数值构成。种群的构成如图1所示:
2.2 选择策略
遗传算法在每代进化时,会先从父代种群中选择两个个体。典型的选择策略包括随机选择、轮盘赌选择和锦标赛选择。其中:
1)随机选择完全不考虑个体的适应度优劣,每个个体被选择的概率是相等的。虽然公平,但难以保证优势个体会被传递给下一代。
2)轮盘赌选择法考虑了个体的适应度值,最优的个体,被选中的概率就越大。同时,适应度值较差的个体仍然有机会被选择。
3)锦标赛选择法是每次等概率地从种群中抽取一定数量的个体,对于被抽中的个体,再根据适应度值选择出值最优的个体作为父代。该策略中,参与竞赛的个体数量是需要考虑的因素。本文采用2个个体参与竞赛的方式。
对比三种选择策略的特点可以发现,随机选择挑选父代是完全盲目的;轮盘赌策略中,如果某个个体的适应度过于优秀,该个体被反复地选择的概率就会大大增加,这会影响其他相对较优的个体被选中的概率;锦标赛选择既考慮了个体的平等性,也考虑了适应度值的优劣。本文中的选择策略主要考虑轮盘赌和2个体锦标赛选择。
2.3 交叉、 变异策略
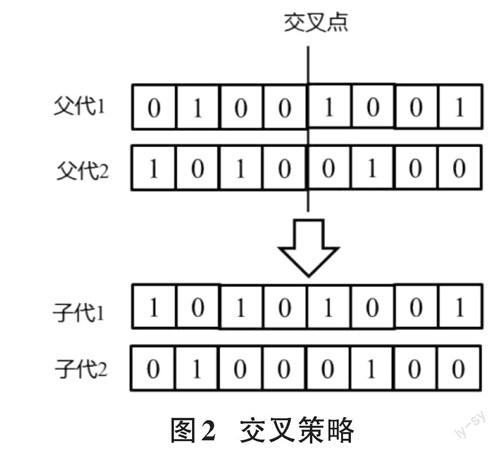
经过选择策略决定了两个父代个体后,接下来的交叉和变异策略用于产生新的子代。其中,交叉策略把两个父代个体的部分基因进行替换、重组,从而产生新的个体,即子代。遗传算法中的交叉操作有多种不同的做法。本文采用典型的单点交叉,如图2所示:
通过交叉操作产生新的个体,使搜索能继续进行,从而发现更优的个体。
然而,当进化过程持续到一定代数后,会使搜索过程停滞,表明搜索过程陷入了局部最优。为避免这种情况,遗传算法采用变异操作,使个体能以较低概率改变某个位置的状态。这种策略能在一定程度上使搜索过程跳出局部最优。
2.4 种群更新
经过前述的选择、交叉、变异操作后,在当前进化代中,算法产生了与父代个体数量相同的子代种群。接下来的种群更新考虑如何用新个体替换父代个体。常规做法是用新个体完全替换父代个体。然而,这种替换没有考虑子代个体没有比父代最优个体更好的情况。相对地,另一种替换策略被称为精英保留策略。该策略把父代中的最优个体(精英个体)在不经过交叉、变异的情况下直接复制到下一代中。为了保持种群的规模不变,精英个体用于替换新种群中适应度最小的个体。
2.5 算法总流程
基于前述步骤,遗传算法求解封装式特征选择问题的主要流程如下:
输入:数据集、目标监督算法
输出:分类准确率
Step1:初始化种群。
Step2: 将表示个体的特征子集用于剔除数据集中的部分特征。然后将剔除部分特征的数据集用于KNN分类器的训练和预测。采用10折交叉验证计算分类器的平均预测准确率。基于该准确率和个体被选中的特征数量,利用公式(1)得到每个体的适应度。
Step3: 根据适应度利用选择策略挑选两个父代。
Step4: 通过交叉、变异操作产生新的子代。
Step5: 利用精英保留策略来更新种群。
Step6:重复step2-5,若达到迭代终止条件,则输出最优个体的分类准确率。
4 实验
为了测试遗传算法在特征选择问题中的性能,本文选用了UCI数据库的部分数据集用于测试,数据集的具体参数如表1所示:
表1 算法运行时间
[数据集名称 特征数 样本数 类别数 BreastEW 30 569 2 BreastTissue 9 106 6 Climate 18 540 2 Glass 9 214 7 ionosphere 34 351 2 seeds 7 210 3 sonar 60 208 2 SyntheticControl 60 600 6 waveform 21 5000 3 wine-data 13 178 3 yeast 8 1484 10 ]
以上选用的数据集中,所有特征的取值都是数值型。为使算法不受样本特征的数据分布的干扰,在特征选择之前,对每个样本的特征值都进行了零均值规范化,使得所特征值的均值为0,标准差为1。对于机器学习算法,本文采用的是KNN算法。该算法实现选用sklearn库中的实现,且采用默认参数(邻域k=5,欧式距离计算样本间的相似度)。
实验中,遗传算法的主要参数设置如表2所示:
对于遗传算法,每个环节(种群初始化、选择、交叉、变异、种群更新)有多种不同的做法,从各种组合中找出最佳组合是一个非常烦琐且耗时的过程。本次实验把重点放在了测试遗传算法的三种选择策略结合精英保留策略对KNN算法预测准确度的比较上。由于遗传算法的随机特性,每次运行的结果都会不同。实验时,不同的算法在同一个数据集上运行10次,然后计算平均值。
实验分别对比了不采用特征选择,即全部特征用于学习的分类准确率,以及采用遗传算法进行特征选择后的分类准确率之间的优劣。其中,遗传算法又分为基本遗传算法GA1(随机选择,完全替换父代种群)、GA2(轮盘赌,精英保留)、GA3(锦标赛,精英保留)三种。根据不同的选择策略,GA2的精英保留中的最优父代个体没有参与后代产生的选择、交叉和变异;而GA3的精英保留中的最优父代参与了后代产生的选择、交叉和变异。GA2和GA3的精英保留策略有所区别的原因是轮盘赌会导致高质量个体被重复选择的概率增大,这会导致种群多样性的丧失。
测试结果如表3所示,采用基于GA3的特征选择,KNN算法能在4个数据集上取得最好的预测准确率。比较突出的结果总结如下:
1)在Sonar数据集上,采用GA3对特征组合进行优化后,比全部特征用于分类的准确度要高出10%;在Ionosphere数据集上,采用GA3对特征组合进行优化后,比全部特征用于分类的准确度要高出5.4%。
2)对于GA2,比较突出的是在Sonar数据集上,比使用全部特征分类准确度高出5.6%;在Ionosphere数据集上比使用全部特征分类准确度高出3.5%;
3)对于GA1,在Sonar数据集上比使用全部特征分类准确度高出3.7%;在Ionosphere数据集上比使用全部特征分类准确度高出2.9%,Seeds数据集上比使用全部特征分类准确度高出2.1%。
从整体上对比三种遗传算法的表现可以发现,采用GA3优化数据集的特征组合,可以使KNN方法在所有数据集上的平均预测准率,要比完全不使用特征选择方法高出1.2%。
3 结论
本文对遗传算法用于特征选择问题时,不同的个体选择策略和种群更新策略的组合展开了研究。在11个数据集上测试了不同结合方式的性能。实验结果表明,锦标赛选择法与精英父代个体参与遗传算子操作的精英保留策略在总体上表现最好。在今后的工作中,将继续对其他的智能算法在特征选择的应用展开研究。
参考文献:
[1] 李郅琴,杜建强,聂斌,等.特征选择方法综述[J].计算机工程与应用,2019,55(24):10-19.
[2] 刘飞飞.特征选择算法及应用综述[J].办公自动化,2018,23(21):47-49.
[3] 陈倩茹,李雅丽,许科全,等.自调优自适应遗传算法的WKNN特征选择方法[J].计算机工程与应用,2021,57(20):164-171.
[4] 王晗,刘维生,李辉,等.基于模拟退火算法特征选择软件的设计与实现[J].电子元器件与信息技术,2021,5(3):144-146.
[5] 周金容,罗建.基于聚类和二元蚂蚁系统的高维数据特征选择算法[J].计算机应用与软件,2021,38(10):304-309,349.
[6] 邓秀勤,李文洲,武继刚,等.融合Shapley值和粒子群优化算法的混合特征选择算法[J].计算机应用,2018,38(5):1245-1249.
[7] Mafarja M M,Mirjalili S.Hybrid Whale Optimization Algorithm with simulated annealing for feature selection[J].Neurocomputing,2017,260:302-312.
[8] 张鑫源,胡晓敏,林盈.遗传算法和粒子群优化算法的性能对比分析[J].计算机科学与探索,2014,8(1):90-102.
[9] 张青雷,党文君,段建國.基于自适应遗传算法的大型关重件车间布局优化[J].机械设计与制造,2021(1):236-239.
收稿日期:2022-02-25
基金项目:长江大学大学生创新创业训练项目(Yz2020162)
作者简介:张照硕(2001—),男,河北邢台人,本科生,主要研究方向为机器学习应用;侯能,讲师,博士。
