基于数据驱动的转炉二吹阶段钢水温度动态预测模型
2022-08-29谷茂强徐安军王慧贤
谷茂强,徐安军,刘 旋,王慧贤
北京科技大学冶金与生态工程学院,北京 100083
转炉炼钢是一个非常复杂的高温物理化学变化过程,具有生产效率高、能耗少、成本低等特点.转炉终点控制是指控制钢水的成分和温度达到合理的范围内,然而,转炉冶炼过程中熔池温度太高,现有的检测手段无法实现对熔池内的成分和温度的连续检测,导致目前大多数钢厂的转炉终点控制大多还是依靠人工经验,控制精度低且不稳定,因此建立精确的转炉终点预测模型对转炉终点控制具有重大意义.
目前转炉终点预测模型可以分为静态预测模型和动态预测模型,其中静态预测模型可以分为理论模型和数据驱动模型.理论模型是以物料平衡和热平衡为基础而建立的,但由于模型中存在大量假设条件,导致无法真实反映转炉实际生产过程,所以控制精度较差.而数据驱动模型是利用历史生产数据进行学习和建模,因此更能有效反映出转炉生产过程,目前已经有很多学者对此进行了深入的研究.
高放等[1]基于因子分析法和极限学习机算法(Extreme learning machine, ELM)建立了转炉终点磷含量预测模型,Feng等[2]基于机理模型相似度的改进案例推理算法建立了专用脱磷转炉终点磷含量预测模型,Gu等[3]基于时序数据改进的案例推理算法建立了转炉终点碳温预测模型.Gao等[4]提出了基于改进的孪生支持向量回归机算法建立转炉终点预测模型.Sala等[5]基于数据驱动算法建立转炉终点预测模型.He与Zhang[6]基于主成分分析和误差反向传播(Back propagation,BP)神经网络算法建立了转炉终点磷含量预测模型.程进和王坚[7]基于多任务学习算法建立转炉终点预测模型.杨晓猛等[8]基于极度梯度提升树(XGboost)算法的转炉吹炼终点预报模型.铉明涛等[9]基于果蝇算法和广义回归神经网络算法(General regression neural network,GRNN)建立的转炉炼钢终点预报模型.韩敏等[10]基于鲁棒相关向量机的转炉炼钢终点预报模型.刘闯等[11]基于膜算法进化极限学习机建立了转炉终点预报模型.严良涛等[12]基于遗传算法和核偏最小二乘回归算法建立了转炉终点碳含量预测模型.此外,也有学者通过提取炉口火焰光谱和图像特征数据建立了转炉终点预测模型[13-15].
上述数据驱动模型虽然在预测精度上有所提高,但模型只能预测吹炼终点时的温度和碳含量,无法实现对吹炼过程的碳含量和温度变化的计算,也就无法进一步在吹炼过程中进行动态调整,因此一次命中率是有限的.
而对于动态预测模型可以分为基于副枪的控制模型和基于炉气分析的控制模型.基于副枪的控制模型方面,岳峰等[16]利用转炉吹炼末期脱碳指数方程、热平衡和热力学方程分别建立了转炉终点碳、温度、磷和锰的预报模型.Wang等[17]建立了基于数据驱动的转炉炼钢终点碳含量实时预测模型.基于炉气分析控制的模型方面,胡志刚等[18-19]利用炉气分析技术基于碳积分模型进行了转炉钢水连续定碳和定温.刘锟等[20]提出了基于烟气分析转炉终点碳含量控制的新算法,实现了动态推算吹炼后期熔池碳含量.加拿大Dofasco公司采用转炉烟气分析吹炼控制系统后,已经不再使用副枪,冶炼全部炉次直接出钢,烟气分析系统作业率为100%,补吹率小于1%[21-22].林文辉等[23]提出了基于“极限碳含量拟合+曲线同步更新”算法的改进指数模型预测转炉吹炼后期碳含量.李南等[24]在传统指数模型的基础上,充分考虑了枪位、顶吹流量、底吹流量等操作参数对熔池脱碳速率的影响,建立了基于熔池混匀度的指数模型.
上述两种动态控制方法在一定程度上提高了转炉终点控制的命中率,但还存在以下问题,副枪无法实现连续测量且以往基于副枪的控制模型只能拟合出供氧量或时间与碳含量和温度变化关系,没有考虑枪位和底吹流量对碳含量和温度的影响,而基于炉气分析的控制模型,炉气的检测设备远离熔池反应区,因此炉气数据存在一定的延迟,导致模型虽然能够实现碳温的动态预测却无法实现实时预测,而且研究主要集中在碳含量的动态预测上,对于温度的动态预测研究较少.
针对目前转炉终点静态预测模型和动态预测模型存在的问题,本文提出了一种新的转炉动态预测模型来实现对转炉二吹阶段钢水温度的动态预测,为操作人员提高终点命中率提供参考.
1 转炉炼钢过程简介
1.1 转炉冶炼过程
基于副枪控制的转炉的冶炼过程还可以分为3个阶段:主吹阶段、二吹阶段和出钢阶段,如图1所示.
(1)主吹阶段:废钢和铁水被依次装入转炉之后,氧气通过氧枪以一定流量吹入熔池中,与此同时,向炉内分批次添加一定重量辅料(石灰、轻烧白云石和烧结矿等),在吹炼后期(供氧量达到总供氧量的85%左右),插入副枪以测定熔池中碳含量和温度(TSC);
(2)二吹阶段:根据TSC的碳温测量结果,调整达到终点时所需的供氧量或冷却剂加入量,并在吹炼结束后,再次插入副枪以测定熔池中碳含量和温度(TSO),如果TSO测量结果符合终点控制目标要求,则进行出钢,反之,需要重新补吹;
(3)出钢阶段:在钢水的成分和温度都达到控制要求后,就可以进行出钢,在出钢过程中还需要加入一定量的脱氧剂和合金.
1.2 转炉冶炼过程的工艺参数
转炉冶炼过程涉及的工艺参数根据数据类型可以分为两类,如图2所示,分别为单值型工艺参数和时序型工艺参数[25].

图2 转炉炼钢的工艺参数Fig.2 Technical parameters for converter steelmaking
(1)单值型工艺参数.
单值型工艺参数主要包括:铁水成分(C、Si、Mn、P和S)、铁水重量、铁水温度、废钢种类及重量、造渣剂(石灰、白云石、铁矿石)种类及加入量、供氧量、底吹氩气/氮气量、铁矿石及补热剂加入量.
(2)时序型工艺参数.
时序型工艺参数根据自动化采集的延迟性,可以进一步分为无延迟的时序型工艺参数和有延迟的时序型工艺参数,前者主要包括:枪位变化、供氧流量和底吹气体流量.后者主要为炉气的成分及流量,因为检测设备远离转炉熔池,所以存在一定延迟,因此一般情况下无法直接参与控制,主要用于脱碳过程阶段的判断.
2 模型原理
2.1 案例推理法
基于案例推理是人工智能领域一项重要的推理方法,它是在遇到新问题时,在案例库中检索过去解决的类似问题及其解决方案,并比较新、旧问题发生的背景和时间差异,对旧案例解决方案进行调整和修改以解决新的问题的一种推理模式[26].案例推理算法流程如图3所示:
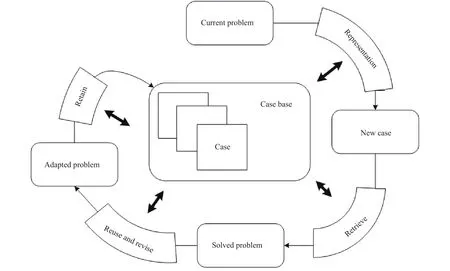
图3 案例推理算法流程图Fig.3 Process of the case-based reasoning (CBR) model
(1)案例描述.
案例描述也称为案例表示,是案例推理的基础.案例描述主要是通过一定的方法将案例描述出来,案例描述一般包括案例特征描述以及案例的解决方案描述.

其中,xi为案例的第i个特征,m为特征的个数,s为案例的解决方案.
(2)案例检索.
案例检索是根据待解决案例的问题描述在案例库中找到该案例或情况最相似的案例.当案例的特征属性比较多的时候,一般情况下案例库中没有完全与之相同的案例,所以需要一定的计算方法来找出与之最相似的案例.
本文采用欧式距离相似度.假设案例的影响因素个数为m,案例库中案例的第j个因素是yj,在问题案例中第j个影响因素为xj,则问题案例X和案例库中案例Y之间的欧氏距离公式如公式(1)所示:

其中,m为案例的影响因素个数;xj为新案例的第j个影响因素;yj为案例库中案例的第j个影响因素.
则案例与案例之间的相似度为:

2.2 长短期记忆网络
长短期记忆网络(LSTM神经网络)由Sepp Hochreiter和Jurgen Schmidhuber于1997年首次提出.不同于传统神经网络,其隐含层的基本单元被称为记忆块(Memory block),记忆块的结构如图4所示.

图4 LSTM记忆块结构Fig.4 Memory block structure of LSTM
记忆块包含3个门(遗忘门f、输入门i、输出门o和记忆单元c,符号 ⊗ 代表两个向量的加法运算,符号 ⊗ 代表两个向量的点乘运算,σ代表sigmoid激活函数,tanh为双曲正切激活函数,模型的计算公式如下:

其中,ft为t时刻的遗忘门输出;σ为sigmoid函数;ht-1为上一时刻细胞单元最终的输出;xt为当前t时刻的输入;it为t时刻的输入门输出;C˜t为t时刻的输入的单元状态;Ct为t时刻的记忆单元状态;ht为t时刻的最终输出;.Wf、Wi、Wo和Wc分别为遗忘门、输入门、输出门和记忆单元对应的系数矩阵.bf、bi、bo和bc分别为遗忘门、输入门、输出门和记忆单元对应的偏置项.
2.3 转炉二吹阶段钢水温度动态预测模型
在转炉二吹阶段,钢水温度的主要影响因素包括单值型工艺参数(冷却剂和补热剂加入量)和时序型工艺参数(供氧流量、枪位变化和底吹气体流量).对于冷却剂和补热剂等单值型工艺参数,本文通过冷却剂和补热剂的热效应确定;而对于供氧流量和枪位变化等时序型工艺参数,本文基于案例推理和长短期记忆网络(CBR_LSTM)模型确定.最后,综合考虑两类工艺参数对钢水温度的影响,实现对二吹阶段的钢水温度的动态预测,整个模型的公式如下所示:

其中,Ti为 二吹阶段第i个时刻的钢水温度;Ti-1为二吹阶段第i-1个时刻的钢水温度;Hi(w)为二吹阶段第i时刻单值型工艺参数造成的温度变化,w为冷却剂或补热剂的加入量,Fi(x)为二吹阶段第i时刻时序类型工艺参数造成的温度变化,x为二吹阶段第i时刻的供氧流量、枪位变化和底吹气体流量.
针对单值型工艺参数,根据热平衡原理,利用冷却剂和补热剂的热效应计算其造成的钢水温度变化.本文中,补热剂造成的升温效果为60 ℃·t-1,冷却剂造成的降温效果为8 ℃·t-1.
针对时序型工艺参数,通过CBR_LSTM模型进行计算,模型可以分为三个部分,分别为相似案例检索、模型训练和模型验证(图5).

图5 模型流程图Fig.5 Process of the model
(1)相似案例检索.
相似案例检索的目的是利用新案例主吹阶段的单值型工艺参数(入炉铁水成分、温度和重量、废钢种类和重量以及TSC检测的碳含量和温度结果等信息)在历史案例库中检索到n个相似案例对应的二吹阶段时序型工艺参数(枪位变化、供氧流量、底吹气体流量和钢水温度变化),如图6所示.本文中n是模型的超参数,通过实验确定.

图6 相似案例检索流程图Fig.6 Process of similar case retrieval
由于历史数据中并没有TSC到TSO阶段钢水温度的真实测量数据,本文首先利用炉气数据拟合得到案例对应的碳含量变化,再通过碳含量变化趋势拟合钢水温度变化.钢水温度变化拟合公式如下:
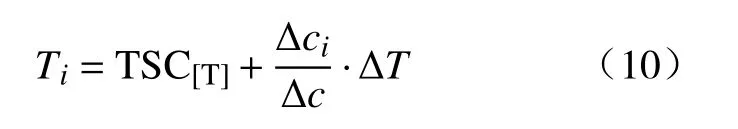
其中,Ti为 二吹阶段第i个时刻的钢水温度;TSC[T]为TSC检测的钢水温度; Δci为二吹阶段第i时刻的累计脱碳量; Δc为二吹阶段TSC到TSO的总脱碳量; ΔT为二吹阶段TSC到TSO总的钢水温度变化(除去冷却剂和补热剂造成的温度变化).
(2)模型训练.
模型训练是利用检索出来的相似案例的二吹阶段的时序型工艺参数(枪位变化、供氧流量、底吹气体流量和钢水温度变化)进行LSTM模型的训练.
模型训练过程如图7所示:将相似案例的上一时刻的枪位、供氧流量、底吹气体流量和钢水温度作为输入,下一时刻的钢水温度作为输出.

图7 模型训练流程图Fig.7 Process of model training
图中Pn(i)为第n个案例在第i个时刻的工艺参数(枪位、供氧流量、底吹气体流量、钢水温度),Tn(i)为第n个案例在第i个时刻的钢水温度.
(3)模型验证.
模型验证的过程如图8所示:将新案例吹炼二吹阶段中上一时刻的枪位变化、供氧流量、底吹气体流量和钢水温度输入到训练好的LSTM模型,得到下一时刻的钢水温度变化,然后将得到的下一时刻钢水温度预测值作为再下一时刻的输入,以此类推,逐步得到新案例的钢水温度变化曲线.

图8 模型验证流程图Fig.8 Process of model validation
3 模型应用实例
3.1 模型数据集
为了验证模型的预测精度,本文利用B钢厂的1209个炉次热轧钢板(Steel plate heat commerical,SPHC) 钢种转炉实际生产数据进行了仿真实验.转炉吹炼过程的单值类型和时序类型工艺参数统计结果如表1 和表 2 所示,其中:TSC[C]、TSC[T]、TSO[C]和TSO[T]分别为TSC和TSO检测的碳含量和温度.
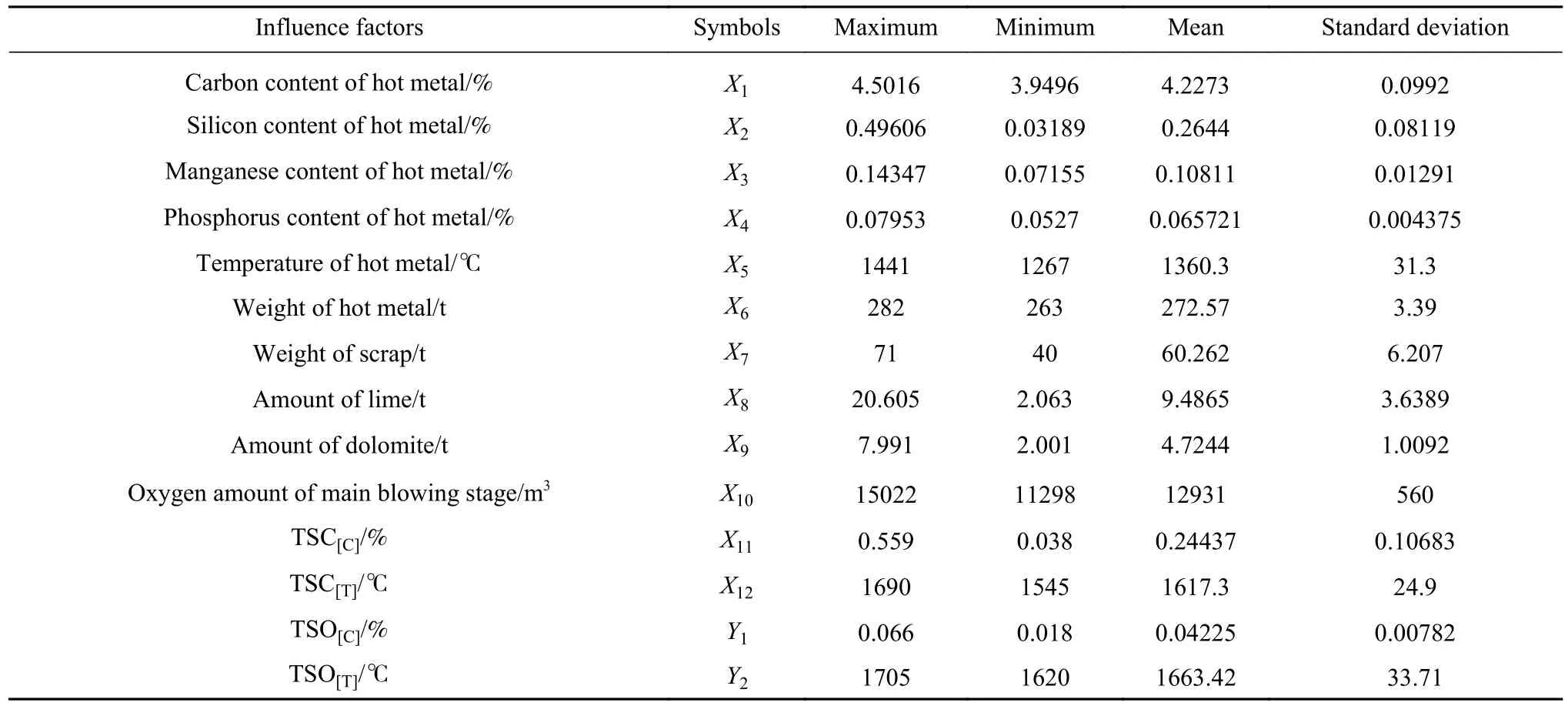
表 1 转炉主吹阶段单值型工艺参数统计结果Table 1 Statistical results of single-value type process parameters in main blowing stage of converter
3.2 相似案例检索
由于转炉炼钢过程是一个远离平衡态的体系,副枪检测的结果无法完全反映出转炉熔池内的状态,本文在相似案例检索过程中的影响因素还包括了转炉入炉原料条件和转炉吹炼前中期的工艺操作.具体包括:铁水温度、铁水重量、铁水碳含量、铁水硅含量、铁水锰含量、铁水磷含量、废钢量、石灰加入量、白云石加入量、主吹阶段供氧量、TSC[C]和TSC[T].
3.2.1 CBR模型参数设置
CBR模型中,相似度计算方法采用欧式距离相似度,案例重用规则是选取相似度最高的n个案例作为重用案例,本文中n作为模型汇总的超参数,经实验确定n为4时预测精度最高.
3.2.2 案例检索结果
以某一炉次为例,CBR检索出的相似案例结果如表3所示,其中炉次1为测试案例,炉次2、3、4、5为案例库中检索出的相似案例.
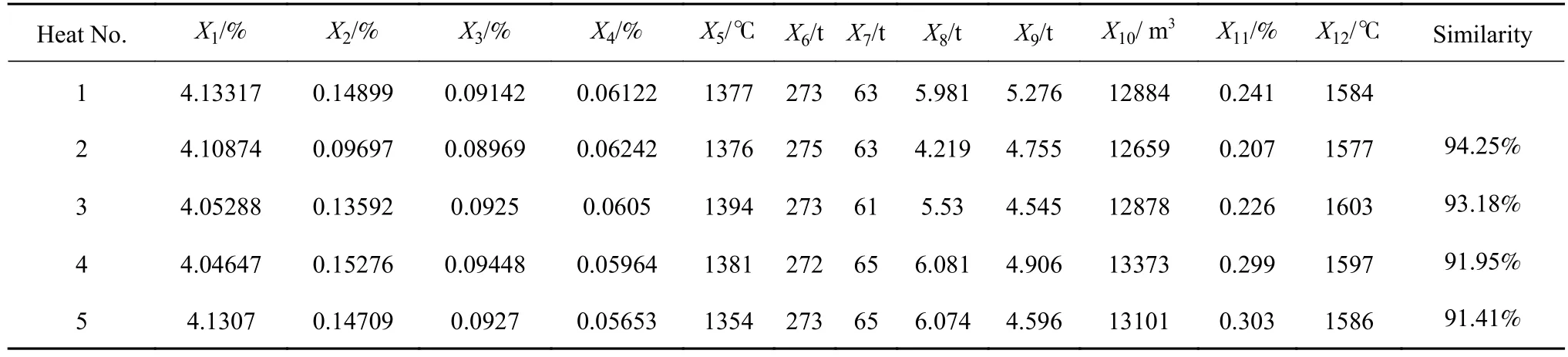
表 3 相似案例检索结果Table 3 Similarity between the new case and similar cases
相似案例对应的后吹阶段的枪位变化、供氧流量、底吹气体流量及碳含量变化如图9所示,其中钢水温度变化曲线按照公式(10)拟合得到.

图9 相似案例对应的二吹阶段工艺参数图.(a)炉次 2;(b)炉次 3;(c)炉次 4;(d)炉次 5Fig.9 Process parameters for the second blowing stage of similar cases: (a) Heat 2; (b) Heat 3; (c) Heat 4; (d) Heat 5

3.3 钢水温度动态预测模型
3.3.1 模型训练
模型参数中的批(batch)为1,每个案例训练的轮次(epoch)为 500,损失函数为 mae,优化求解器为Adam,本文将神经元个数k作为模型的超参数进行优化.
不同神经元个数下模型训练的误差变化曲线如图10所示.
图10 模型训练误差变化曲线Fig.10 Training error curve of each model
3.3.2 模型验证
利用训练好的模型对新案例炉次1进行验证,模型的预测结果如图11所示.

图11 钢水温度动态预测模型的预测结果Fig.11 Prediction result for the application example
从图11可知,炉次1的实际终点温度为1650 ℃,模型在k= 5, 10, 15, 20时对炉次1的终点温度预测值分别为 1658.7,1656.7,1657.6和 1658.8 ℃,因此,模型的预测误差分别为8.7,6.7,7.6和8.8 ℃.
为了进一步验证模型的准确性,将全部1209炉次数据划分为5等份,每一次将其中一份作为测试集,其余作为训练集,分别测试k= 5, 10, 15,20情况下模型的预测精度.预测结果如图12所示,模型在k=10时的预测精度最高,预测误差在[-15 ℃, 15 ℃]范围内命中率为88.33%.
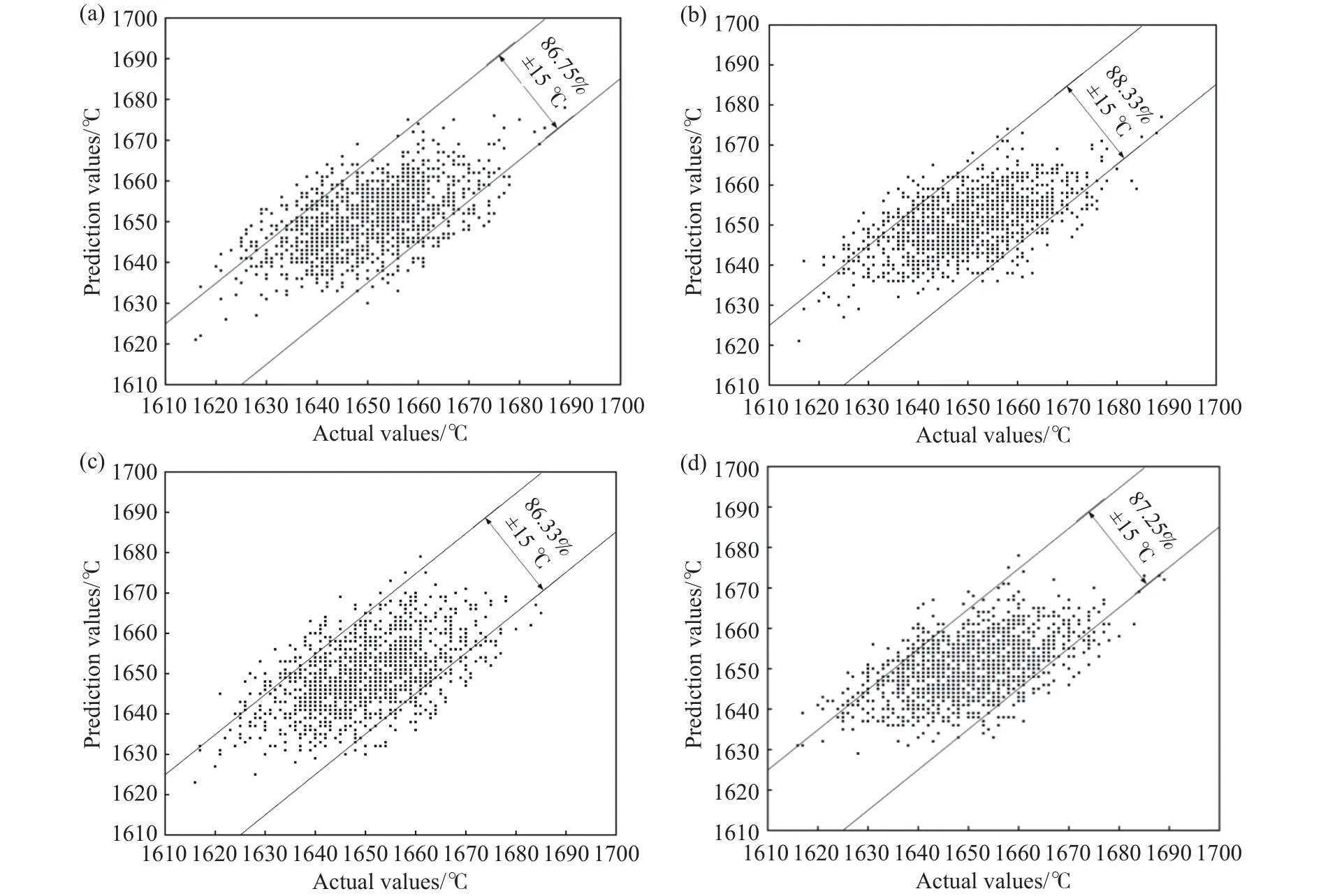
图12 CBR_LSTM模型预测结果.(a) k=5; (b) k=10; (c) k=15; (d) k=20Fig.12 Prediction result of the model CBR_LSTM: (a) k = 5; (b) k = 10; (c) k = 15; (d) k = 20
本文还研究了不同案例个数对预测精度的影响,结果如图13所示.

图13 案例个数对预测精度的影响Fig.13 Influence of hyperparameter n on the prediction accuracy
从图13可以看出,模型的预测精度随着案例个数的增加,呈现先增加后下降的趋势,并在案例个数n为4时,模型的预测精度最高,说明训练模型时增加案例个数有利于提高模型的预测精度,但随着案例相似度的下降,案例的参考价值降低,反而会降低模型的预测精度.
3.4 其他模型对比
为了进一步验证本文所建立模型的预测精度,本文还建立了二次方模型和三次方模型.模型假设二吹阶段钢水温度与供氧量成二次和三次多项式关系.
各模型拟合公式如表4所示,其中,T为钢水温度,x为供氧量.

表 4 模型拟合结果Table 4 Model fitting results
各模型预测结果对比如表5所示.
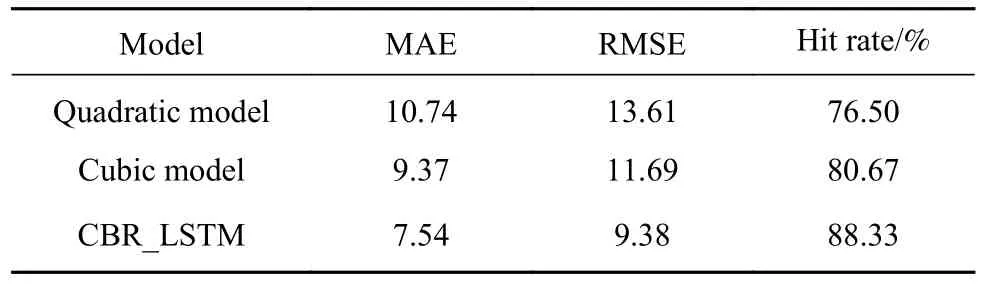
表 5 各模型预测精度对比Table 5 Prediction accuracies of each model
从表5中可知,CBR_LSTM模型在平均绝对误差(MAE)和均方根误差(RMSE)两项指标上均低于二次方模型和三次方模型,预测误差在[-15 ℃,15 ℃]的命中率高于二次方模型和三次方模型,表明本文所建立的钢水温度预测模型能够有效地动态预测二吹阶段的钢水温度,模型对现场操作人员有一定的指导意义.
4 结论
(1)本文建立了基于CBR_LSTM的转炉二吹阶段钢水温度动态预测模型,模型实现了对转炉二吹阶段钢水温度的动态预测.
(2)本文研究了不同重用案例个数和神经元个数对模型预测精度的影响,实验结果表明:模型在重用案例个数为4,神经元个数为10时模型的预测精度最高,此时模型对钢水温度的预测误差在 [-5 ℃, 5 ℃]、[-10 ℃, 10 ℃]和 [-15 ℃, 15 ℃]的命中率分别达到40.33%、68.92%和88.33%.
(3)本文还分别建立了传统的二次方模型和三次方模型,通过对比模型的RMSE、MSE和命中率三个指标,进一步证明了模型的有效性.
