基于YOLOv5的红外目标检测算法*
2022-08-27张巍巍
林 健,张巍巍,张 凯,杨 尧
(1.西北工业大学 无人系统技术研究院·西安·710000;2.上海航天控制技术研究所·上海·201109)
0 引 言
目标检测是机器视觉领域最具挑战性的任务之一,在现实世界中有着深远的意义。在自动驾驶、导航制导等任务中,要求检测算法能够在各种照明和环境条件(包括白天、夜间、雨中、雾中等)下都具有鲁棒性。然而在这些情况下,基于可见光的系统一般无法发挥作用,导致上述任务无法完成,红外成像系统通过接收目标的热辐射成像,对复杂天气、光照情况有较强的适应性,可以全天候工作,探测距离远。同时相较于可见光数据的采集,红外数据拥有更强的隐私保护性,在当前人们对隐私保护越来越重视的背景下,足以获得更多的学习数据,用于优化模型。
红外成像系统具有上述全天候、远距离、抗干扰的特性,被广泛地应用在民用、军用领域。虽然红外目标检测跟踪算法的需求日益增长,但是红外图像普遍存在纹理信息差、低分辨率、高噪声的特点,对目标原有的灰度信息破坏严重,给红外目标检测算法带来严峻挑战。经典的目标检测算法模板匹配、HOG-SVM,以及当前主流的深度学习算法等,在设计之初都是针对可见光图像,在目标细节、特征明显的RGB图像上可以获得较好的性能,但在红外图像目标检测上,算法性能均有不同程度下降。

基于深度学习的目标检测算法——YOLO,在学术界和工业界都取得了许多显著的成果,下面简要介绍YOLO系列算法的发展历程。J.Redmon等在2015年6月提出了YOLOv1算法,该算法不仅具有良好的识别性能,而且具有较高的实时性。此外,该算法具有良好的泛化能力,易于训练,收敛速度较快。在接下来的5年里,YOLO算法得到了更新,5个版本融合了目标检测社区的许多创新想法。在前3个版本中,YOLOv3是一个里程碑,通过引入多尺度特征(Feature Pyramid Networks,FPN)、更好的骨干网络(Darknet53)以及将Softmax分类损失函数替换为Logic损失函数,在性能和速度方面取得了较大改进。2020年初,在原YOLO作者从研究领域离开之后,YOLOv4由不同的研究团队发布。YOLOv4团队对YOLO算法的几乎所有方面进行了探索,改进了主干网络,以及提出了很多在目标检测领域实用的技巧。YOLOv4在Tesla V100上以65 FPS的实时速度实现了MSCOCO数据集65.7%的平均准确率。1个月后,另一个不同的研究团队发布了YOLOv5,该算法具有更小的模型尺寸、更快的速度、与YOLOv4相似的性能,以及在Python中的完整实现,使得YOLOv5在目标检测社区得到了广泛关注。
为解决红外图像普遍存在的纹理信息差、低分辨率、高噪声带来的检测难题,本文改进了YOLOv5算法的特征提取网络,选择了具有残差特性的ResNet50网络。针对红外场景中存在大量的小目标,避免过大采样率导致目标被过滤,改进了YOLOv5检测头方案,使用了更为密集的特征融合网络提升检测效果。本文的主要工作如下:
1)构建了基于ResNet50的骨干特征提取网络,改进了YOLOv5的3个检测头方案,增加了下样率为4的检测头。
2)重新设计了特征融合网络,提出了一个Detection Block模块,提升了红外目标的检测能力,同时获得了较小的模型参数。
3)在FLIR红外自动驾驶数据集上,相比原始的YOLOv5m模型,在平均精度上提升4%。
1 算法描述
本文提出了一种基于YOLOv5的红外目标检测算法(Target Detection Based on YOLOv5, YOLOv5-IF),具体结构如图1所示。本文所提算法和现有的大多数目标检测算法一致,结构上分为三部分:特征提取(Backbone),特征整合(Neck),检测头(Head)。输入的红外图像,经过特征提取网络得到目标不同尺度上的语义信息,并将特征图(FeatureMap)划分为不同大小的网格。同时,红外图像经过特征提取网络之后,特征信息被映射在不同尺度的特征图上,红外图像中存在大量的小目标,而过大的采样率会导致目标特征经多次采样之后难以在特征图上体现。出于这方面的考虑,增加了下采样率为4的特征输出。在Neck部分将前一级得到的特征信息进一步加工处理,利用FPN和路径聚合网络(Path Aggregation Network,PAN)实现不同尺度特征信息的融合。网络的最后一部分为Head,即输出预测部分,利用卷积层得到前级特征图上每一网格内包含目标信息(目标位置,置信度)的预测值。这些预测值为事先设定的锚框的调整参数,在后处理部分根据网络的输出信息对预先设定的锚框做相应的调整,最后通过非极大抑制(Non-Maximum Suppression,NMS)操作得到最可能包含目标的预测框。

图1 YOLOv5-IF算法总体框图Fig.1 The architecture of YOLOv5-IF
1.1 YOLOv5算法
这一部分简要分析YOLOv5算法的改进之处,以及YOLOv5算法在解决红外图像识别上存在的问题。
(1)YOLOv5改进点:
基于锚框目标检测算法的先天不足,导致了正负样本不均衡,为了缓解这种缺陷带来的问题,研究者提出了Focal LOSS等算法。YOLOv5在算法设计时提供了另一种解决思路,通过采用跨邻域网格匹配,有效增加了正样本数量,使得YOLOv5算法整体的精度得到了巨大提升,具体边界框回归公式为式(1),式(2)为YOLOv2、v3、v4回归公式。

(1)

(2)
式中,、、、为目标真实的中心点坐标以及宽高;、为目标中心所属网格的左上角坐标值;、为预设锚框的宽高值;、、、为算法输出的锚框的中心点及宽高的调整值;为Sigmoid函数。
(2)不足之处:
Focus模块:YOLOv5创新性地引入了一个全新的模块Focus,具体的实现流程为:将特征图切分为4份,每份数据量都是相当于2倍下采样得到的,然后在通道维度进行拼接。这种操作可以在不增加计算量的同时使得特征图减半,通道增加4倍。相比采用最大池化或步长为2的卷积操作,Focus模块带来的计算量更小,对YOLOv5的快速推理起到了重要作用。然而,由于Focus会造成图像上的空洞,这种操作必然会导致图像信息的丢失,对于红外图像中的小目标检测是不利的, 因此在本文中抛弃了这种结构。
SPP模块:YOLOv4中提出了一个全新的SPP,在经典的SPP模块中,特征地图在进行多尺度最大池化之后被转换为一维向量。新的SPP将3个尺寸为××5124的特征图分别使用∈(5,9,13)的池化核池化,再将输入特征图与池化后的特征图相连形成××2048的特征图。有效避免了在3个尺度最大池化的情况下丢失图像的重要特征,输入不仅提取了使训练更容易的重要特征,而且保持了空间维度。大量的实验证明,SPP模块能有效提升可见光图像的检测率,因此这种结构在YOLOv5中也被保留了下来。Qi D.等提出了针对小目标可采用较小的池化核,然而在针对红外图像的测试中,不论是原始的池化核还是采用较小的池化核,对于检测结果都没有提升,因此在本文中抛弃了这种结构。
1.2 YOLOv5-IF算法
基于上述分析,本文针对YOLOv5算法在解决红外目标识别方面的不足,提出了一种改进的YOLOv5-IF算法。原始的YOLOv5中,沿用了YOLOv3版本中的骨干网络CSPDarkNet53作为特征提取网络, CSP 跨阶段连接受残差连接启发,在不同层之间实现特征复用,在实际测试中发现CSPDarkNet53并不能很好地提升红外图像中目标的特征信息。基于残差连接的ResNet网络可以解决深层模型梯度消失的问题,同时加入了一定的正则项可以加速模型收敛,一定程度上也减少了模型参数。针对红外图像存在的分辨率低、细节特征不明显、高噪声等问题,本文选择ResNet50作为特征提取网络。
为了提升算法对红外小目标的检测能力,本文在骨干网络上增加了4倍下采样的特征图,即输入图像为416×416时,对应特征图大小为104×104,依旧采用每个网格生成3个先验锚框的策略。这种情况下,会给输出增加104×104×3=32448个预测结果,相比原始的(13×13×3+26×26×3+52×52×3=10647)增加了3倍之多。为了解决这一问题,必然需要一个轻量高效的Neck。本文将Neck部分拆分为FPN和PAN两部分,具体结构如图2所示。图中(∈(2,3,4,5))为骨干网络输出的不同下采样倍率的特征图,上采样通过线性插值实现,特征叠加则是在通道维度上合并特征图,卷积操作均为1×1卷积用于调节特征图通道,Head(∈(1,2,3,4))对应不同尺度的检测头,同时替换原始的CSPBottleNet为更高效的Detection Block,在不影响模型精度的情况下,极大缩减了模型规模,结构如图3所示。
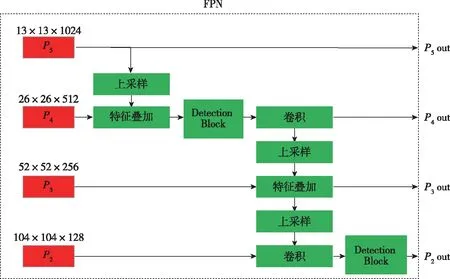
(a) FPN模块网络结构

(b) PAN模块网络结构图2 Neck模块网络结构Fig.2 Neck module network structure
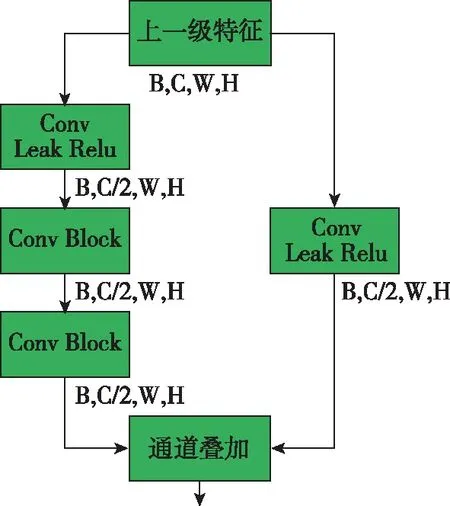
图3 Detection Block模块Fig.3 Detection Block module
Detection Block设计之初就是为了得到一个轻量化的网络,同时能够有效融合红外目标的特征,将目标从背景中凸显出来,如图3所示。具体实现流程为:对输入的特征图通过两个卷积实现通道减半,其中一侧首先会经过一个卷积和Leak Relu激活函数,接着通过两个堆叠的Conv Block模块,该模块使用了卷积加深度可分离卷积的配置,如图4所示,借助深度可分离卷积,在保证不影响感受野的同时,极大减小了模型参数,其中卷积核大小为3,步长为2;另一侧则采用了卷积加Leak Relu激活函数的配置,形成了一个残差连接。
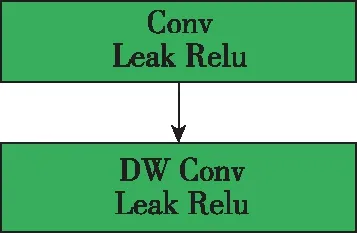
图4 Conv Block模块Fig.4 Conv Block module
本文在骨干网络上增加了一个输出,对应4倍下采样的特征图,经过上述的Neck部分融合,最终得到预期的4检测头检测结构,有效提升了红外弱小目标的检测能力。
4倍下采样的检测头能够输出细粒度更高的特征图,并准确保留红外图像上的小目标特征信息。各个检测头的输出可视化如图5所示,将各个检测头输出得分和类别融合后,可以看到更高细粒度的检测头能关注到图像中的弱小目标。

图5 检测头热图Fig.5 Heat map of detection head
2 实验及结果分析
2.1 实验设置及评价指标
本文使用FLIR提供的红外场景数据集。该数据集是在美国加利福尼亚州圣塔芭芭拉市的街道和高速公路上拍摄的,包括从5月~11月不同时间的各种天气变化,例如雾和雨。图像的背景包括城市、山脉、隧道、树木、建筑物等,背景比较复杂。训练集共包含7659幅红外场景图像,采用COCO数据格式进行标注。类别包括人、自行车、汽车和狗。本次实验仅选取人、自行车、汽车作为检测目标,其中行人22356个、自行车3986辆、汽车41247辆,共67589个目标,图6展示了不同类别的目标占比分布。测试集包含1360幅红外场景图像,包括5579个行人、471辆自行车、5432辆汽车,共计11482个目标。数据集的目标尺度分布如图7所示,其中目标的宽高比为目标高/宽与图像高/宽的比值。由图8可见,数据集中包含了大量小目标,同时场景中目标的模糊程度不同,增加了检测的难度。

图6 目标占比分布Fig.6 Target proportion distribution

图7 目标尺度分布图Fig.7 Target scale distribution map

图8 部分数据集样例Fig.8 Part of the sample datasets
网络训练时采用了如下配置:Batch-Size为16,采用Adam优化器,初始学习速率为0.01,训练数据和测试数据均采用FLIR提供的训练和验证集。使用YOLOv5提供的数据增强策略,采用NVIDIAGTFORCE 1080TI显卡,pytorch 1.8深度学习框架,操作系统为Ubuntu20.04,共训练100个Epoch。对数据集采用K-means聚类算法得到了4组锚框,分别为:[9,10,10,19,17,14],[13,29,26,21,18,44],[40,31,30,70,60,45],[92,66,55,120,142,105]。
本文通过平均准确率(mean Average Precision,mAP),即各个类别的平均值(Average Precision,AP)来评价算法的性能,在计算mAP之前首先需要计算查准率(Precision)和召回率(Recall)。查准率是实际是正样本且模型预测也是正样本数量与模型所有预测的正样本数量的比值。令代表实际的正样本,模型预测也是正样本的数量;代表实际的负样本,但预测是正样本的数量。计算精度的公式为
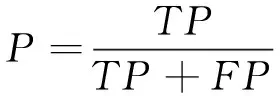
(3)
召回率是实际为正且正确预测的样本数量与所有实际为正样本的数量之比。令代表实际的正样本但模型预测的是负样本,召回率的公式为
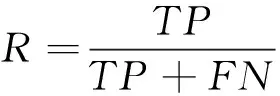
(4)
AP的计算公式如下

(5)
mAP就是不同种类的AP求平均值,mAP0.5表示预测框与真值框的交并比(Intersection-over-Union,IoU)大于等于0.5情况下准确预测的概率;mAP 0.5 0.95表示预测框与真值框的IoU大于等于0.5小于等于0.95情况下准确预测的概率均值。
YOLOv5的损失函数包括:分类损失(classification loss)、定位损失( localization loss)(预测边界框与真实框之间的误差)、置信度损失(confid-ence loss)。因此,总的损失函数为: classification loss+localization loss+confidence loss。YOLOv5使用二元交叉熵损失函数计算类别概率和目标置信度得分的损失。图9和图10分别展示了训练过程中各种损失(loss)和评价指标的变化趋势。

图9 Loss变化曲线Fig.9 Loss curve

图10 评价指标变化曲线Fig.10 Curve of evaluation
2.2 消融实验
为了验证所提的4检测头方案、Detection Block,设计了如下消融实验。如表1所示,√表示当前网络中包含此模块或改进,×表示当前网络中不包含此模块,↑表示该指标越大越好,↓表示该指标越小越好,红色代表算法表现最佳,蓝色表示算法表现最差。使用mAP和模型参量作为评价指标。模型的训练参数配置参照2.1节的实验设置。
正如表1所示,仅仅在模型上增加输出对YOLOv5m的检测精度并无明显提升。同时由于在骨干网络上增加输出,导致输出结果增加3倍之多,使得模型的检测速度下降。因此,替换了原始的CSPDarkNet53,采用ResNet50作为特征提取网络,使得检测精度和推理速度得到了提升。由表1可见,Detection Block模块的加入不仅使得模型精度提升,而且模型规模得到了缩减,这对于后续部署模型工业化应用是十分有利的。

表1 消融实验Tab.1 Ablation experiments
图11展示了消融实验中不同模块的检测效果图,分别是小目标、行人遮挡、多尺度变化等场景, 可以看到V5-IF(图中绿色框线算法)相比其他算法出现误检的情况最少。

图11 消融实验效果图Fig.11 Effect of ablation experiment
2.3 对比实验
选取了当前主流的目标检测算法CenterNet、SSD、EfficientDet、YOLOv5m、Faster R-CNN,在FLIR数据集上进行测试,对比结果如表2所示。以上算法均训练100Epoch,红色、蓝色分别对应算法结果最优和次优,FPS为每秒处理图像帧数。
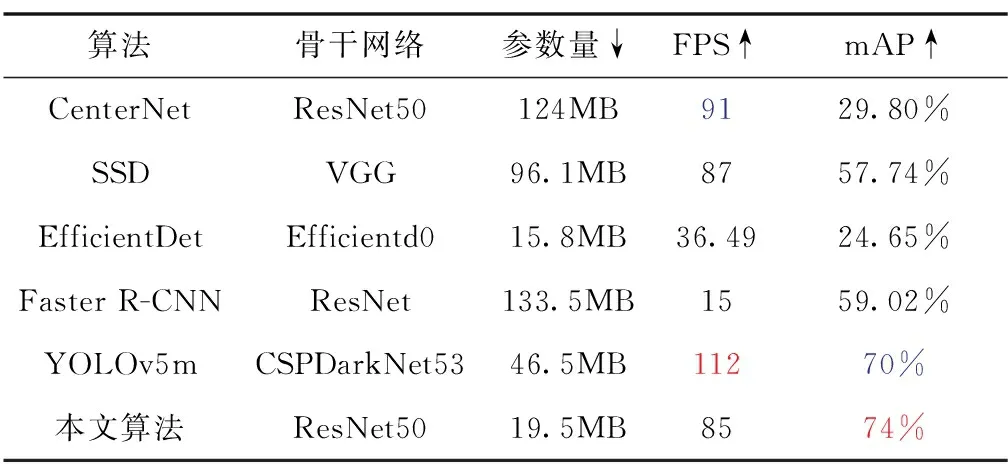
表2 SOTA算法对比结果图Tab.2 Comparison results of SOTA methods
如表2所示,改进的YOLOv5-IF算法相比最新的YOLOv5m算法能够保证一定运行实时性,同时在mAP检测精度上提升了4%,模型参数量减少了68%。基于Anchor-Free的CenterNet使用了ResNet50作为特征提取网络,但在模型规模和检测精度上都不及YOLOv5-IF。SSD算法中引入了多尺度检测头,但是没有加入FPN和PANet,因此没有实现尺度融合,检测效率也表现一般。两阶段的目标检测算法Faster R-CNN,在推理速度上明显低于其他算法。
3 结 论
本文针对通用目标检测算法在红外场景下的不足,考虑到红外图像普遍存在的低分辨率、高噪声、低对比度以及小目标等问题,提出了一种YOLOv5-IF算法,主要创新点有:
1)使用了ResNet50作为骨干特征提取网络,该骨干网络基于残差机制构建,实现了特征图通道信息的高效交互,能够更加有效地获取红外图像中的目标信息,得到更加丰富的语义信息。同时考虑到红外图像中存在大量小目标的问题,在Backbone上增加了一个输出,并由此构建了一个4检测头的算法,使得模型的检测精度得到了提升。
2)考虑到模型规模对模型在边缘移动设备部署和推理速度的影响,提出了一个高效特征整合网络,通过构建Detection Block模块,使得模型的检测精度得到了小范围提升,同时获得了更小的模型规模。最后在红外自动驾驶数据集FLIR上,与现有SOTA算法进行对比,本文所提算法的mAP为74%,参数量仅19.5MB,优于现有的算法。
YOLOv5-IF算法在精度和参数量方面取得了较好的效果,同时也存在一些问题:由于4检测头的引入,输出结果的增加导致模型的推理速度并不是最优,如何均衡算法精度和模型推理速度是后续研究的重点方向,同时模型在边缘设备上的部署问题也是后续的研究方向。
