一种结合深度学习的运动去模糊视觉SLAM方法*
2022-08-27瞿安朝钱伟行苏晓林
袁 珊,瞿安朝,钱伟行,吕 昊,苏晓林
(南京师范大学 电气与自动化工程学院·南京·210023)
0 引 言
感知与导航定位是地面无人平台(Unmanned Ground Vehicle,UGA)在变化环境中实现运动控制和协同作业等任务的有效基础功能之一。在山区峡谷等无线信号的盲区,卫星定位和基站定位无法正常使用,而视觉同步定位与地图构建(Simultaneous Localization and Mapping,SLAM)可以在无线信号失效状态下实时估计传感器的位姿并建立环境的三维地图。视觉传感器以较高的分辨率和相对较快的速度感知丰富的外部环境信息,但也存在着对运动变化敏感等问题。在基于特征提取的视觉SLAM框架下,特征检测器难以从运动模糊图像中提取足够的特征点,降低了帧间特征匹配的准确性,进而影响最终的定位精度和建图效果。
为了消除或减少运动模糊对视觉SLAM定位造成的不利影响,现主要有两类方法:图像防模糊和图像去模糊。S.Osswald等通过机器学习的方法优化机器人的导航动作以避免图像模糊,该类方法不直接处理视觉里程计(Visual Odometry,VO)中的模糊图像,在复杂运动环境下应用受到限制。近年来,图像去模糊化取得了一定的研究进展,研究者引入基于数据关联的方法来加速图像去模糊,以降低图像模糊对VO的影响。A.Pretto等通过估计运动引起的模糊图像的核参数,并将这些参数结合至基于尺度不变特征变换(Scale Invariant Feature Transform,SITF)的特征检测框架中,以提高特征点提取的准确性。该方法在一定程度上降低了运动模糊图像对VO的影响,但仅限于直线运动模糊检测,曲线行进时应用受到较大限制。应对模糊图像问题的另一种思路是筛除部分图像帧,郭科等利用相邻图像匹配点之间的位置关系计算图像模糊程度数值,并在SLAM过程中筛除模糊较大的图像帧以应对运动模糊,然而直接进行图像帧筛除可能会丢失很多有效信息。
针对以上研究现状,本文提出了一种无参考图像质量评价算法,在图像客观度量算法的基础上,引入加速版多尺度二维特征检测和描述(Accelerated KAZE,AKAZE)特征点质量评价算法作为图像模糊度评判标准,同时设计了一种多帧输入的基于生成对抗网络(Generative Adversarial Networks,GAN)的图像去模糊模型,将评判为模糊的图像输入网络,以端对端方式恢复清晰图像并重新送入视觉SLAM系统。在TUM数据集上进行运动去模糊视觉SLAM系统性能测试,验证了本文方法在动态环境下能取得良好的定位精度和鲁棒性。
1 基于AKAZE特征点的图像模糊度评价算法
地面无人平台往往处于复杂多变的动态随机场景中,很难保证图像序列的质量。因此,在进行SLAM的过程中,有必要对输入图像进行模糊程度评估以及对模糊图像进行去模糊化,以保证定位结果的准确性。本文针对视觉SLAM过程设计的图像质量评价算法,主要是基于AKAZE特征点和图像灰度方差函数估计图像模糊程度,从模糊产生原理出发,合理利用图像特征点与模糊误差的对应关系,使模糊参数的计算不会影响SLAM的正常运行,又能对图像的模糊程度有精确的表达。
1.1 AKAZE特征点的提取与匹配
基于点特征的影像匹配算法主要是提取图像的不变特征,加速版鲁棒性特征点(Speeded Up Robust Features,SURF)、快速特征点提取和描述算法(Oriented FAST and Rotated BRIEF,ORB)等常用点特征提取方法,都是基于线性的高斯金字塔进行多尺度分解,以消除噪声和提取显著特征点,但高斯分解牺牲了局部精度,易造成边缘信息弱化和细节模糊,不利于SLAM系统的特征提取。而本文选用的基于非线性尺度空间的AKAZE特征点检测方法可以保证图像边缘在尺度变化中拥有更小的信息损失量,极大地保持了图像细节信息,在低分辨率模糊图像中具有更强的适应性与稳定性。
为了进行AKAZE特征点检测,首先构建非线性尺度空间,与SIFT类似,非线性尺度空间分为组金字塔影像,每组有层,各层采用的分辨率与原始输入图像相同。尺度参数与影像组数、子层级数的关系满足式(1)。

(1)
式中,为尺度初始值;为尺度空间影像总数目。
对原始图像重复降采样,获取组金字塔影像,再对每组影像按照不同参数滤波生成层尺度影像,按式(2)计算进化时间。

(2)
为了定位特征点,求解不同尺度归一化后的Hessian局部极大值点,如式(3)。

(3)
式中,、、分别表示输入图像进行高斯滤波后的二阶微分值。利用尺度空间函数在特征点处使用二阶泰勒展开式得到的内插值,精确定位AKAZE特征点位置。
使用二进制描述符的汉明距离对特征点进行粗匹配,并选取边缘采样一致化方法对粗匹配得到的特征点进行精匹配,剔除错误匹配点。在输入数据点集中选择5对特征点进行计算,得到模型和单应性矩阵。模型质量函数(,,)的期望用于评估模型质量,根据模型的质量函数判断当前模型是否为最优模型,计算正确匹配点对,质量函数如式(4)所示。



(4)
式中,为阈值;为最大阈值;为模型常数;为特征点数量;为特征点的投影误差;为函数残差。
1.2 图像模糊度评价算法设计
图像特征通常使用稳定的局部极值点表示,可以有效检测图像的边缘和纹理信息。根据图像极值点及其变化情况设计计算模型,模拟视觉系统的图像感知过程,从而判断图像质量 。
首先,对图像进行分块处理,并进行特征点提取,如图1所示,依次将图像从左至右,从上至下划分为×的小图块。且为降低后续SLAM特征匹配阶段的计算复杂程度,本文算法仅保留子图像块中对比度较大的前50%的特征点,图中条纹图块为弱纹理区域,不参与模糊分数的计算。

图1 分块提取特征点Fig.1 Extracting feature points by blocks
根据AKAZE特征点的位置,区分出感兴趣的块,并将这些感兴趣图像块用集合表示,式(5)为集合中元素-1,-1(下标为图像块的位置坐标)。
={,,…,-1,-1}
(5)
统计每个图像块中AKAZE特征点数量,如式(6)所示,用集合表示,下标表示感兴趣块的数量,与集合中的图像块元素一一对应。
={,,…,}
(6)
通过图像块AKAZE特征点的检测数量进行权重分配,结合基于空间域特征的图像评价函数,最终产生模糊分数,权重的计算如式(7)所示。

(7)
其中,∈{1,2,3,…,};∈{1,2,3,…,};为一个实验决定的常数。
图像的清晰度与相机聚焦程度成正比,当完全聚焦时,图像最清晰且具有大量高频分量,因此可将灰度变化作为聚焦程度的评判依据。图像块的灰度方差函数和Vollath函数分别如式(8)和式(9)所示。

(8)

(9)
其中,(,)表示对应像素点(,)的灰度值;为图像的平均灰度值;和分别为图像的高度值和宽度值。
最终研究的图像模糊分数的计算如式(10)所示,为尺度因子。
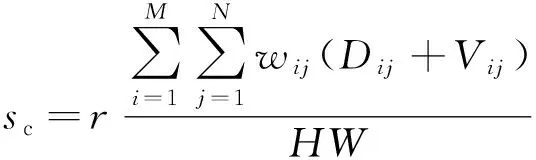
(10)
1.3 图像模糊度评价算法验证
采用标准图像库测试本节提出的图像质量评价算法。图像质量评价算法常用数据库包括LIVE、TID2008、TID2013、CSIQ和CID2013,图库同时还给出人类主观评价分数MOS值,该参考值越大表示图像越清晰。图2(a)~图2(e)所示为LIVE图像库中随机挑选的模糊失真对应的5张图像,且这5张图像的MOS值单调递减,即表示模糊程度在增加。

(a) 模糊图像1

(b) 模糊图像2

(c) 模糊图像3

(d) 模糊图像4

(e) 模糊图像5图2 模糊程度递增的图像Fig.2 Images with increasing blur
在实验中,图像划分为7×7的小图块,尺度因子设置为10,权重函数中的设置为10。表1所示为不同算法产生的模糊分数对比,以主观评价MOS值变化趋势作为评判标准,可以看出主观评价MOS值遵循单调递减的顺序,代表图像的模糊程度逐渐增加,良好的算法应该与MOS值的趋势一致,产生一个单调递减的分数。对比算法分别为局部相位相干(Local Phase Coherence,LPC)以及NR-SAD,均为图像模糊程度越大分数越低。由表1可以看出,本文模糊度评价算法与MOS值变化趋势一致,而当图像间的模糊程度相近时,LPC和NR-SAD算法并不能总是做出准确的评价,如LPC算法中图2(c)和图2(d)的分数变化以及NR-SAD算法中图2(b)和图2(c)的分数变化不符合模糊评判分数单调递减的趋势。

表1 不同算法产生的模糊分数对比Tab.1 Comparison of fuzzy scores generated by different algorithms
进一步地,为了验证本文研究的图像模糊度评价算法在真实模糊图像库上的整体性能,采用皮尔逊线性相关系数(Pearson Linear Correlation Coefficient, PLCC)描述预测值与主观评分之间的相关性与衡量算法的准确性,如表2所示。PLCC取值范围为[-1,1],绝对值越接近于1,说明图像质量评价算法的准确度越高。
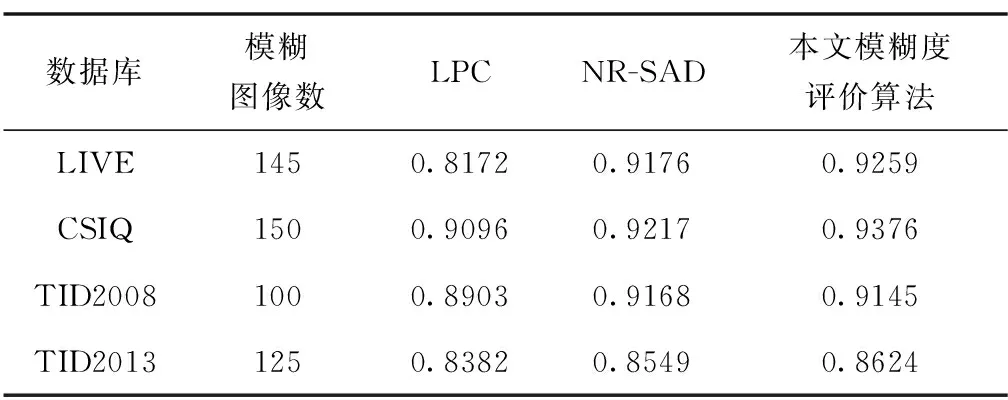
表2 模型PLCC线性相关性Tab.2 Model PLCC correlation
由表2可以看出,四种数据集对应的PLCC值均在0.8~1.0之间,说明模糊评价分数与主观评价分数之间呈强相关,故LPC算法、NR-SAD算法和本文算法均可以较好地预测图像的模糊程度。本文研究的模糊评价算法在LIVE、CSIQ和TID2013库中的表现均优于LPC和NR-SAD算法,而在TID2008数据库性能测试中分数略低于NR-SAD算法,综合看来,本文模糊图像评价算法实现了较高的准确率和较强的鲁棒性。
2 基于GAN的图像去模糊网络模型
将判定为模糊的图像帧输入至端对端的去模糊化网络,输出的清晰图像再与前后帧进行特征点匹配并进行位姿估计,参与视觉SLAM的后端优化过程。本文研究了一种以3个相邻帧作为输入的去模糊化GAN模型,建立了一种双向的时间转移特征,模糊帧的潜在特征向后转移至上一帧,向前转移至下一帧。2个相邻帧由分组卷积后的集成编码器同时编码,之后由混合解码器联合解码,以生成相对于中心模糊帧更清晰的图像帧。
2.1 网络结构
本文研究的基于GAN的生成器网络结构如图3所示,假设图像模糊评价算法评测的模糊帧为,通过结合前一帧和后一帧,实现相对于恢复潜在清晰图像的目标。设计了一个完全卷积的生成网络,所有卷积层均利用数据规范化对卷积结果进行归一化处理,以加快网络的训练速度,除网络的最后一个卷积块使用tanh作为激活函数外,其余所有卷积块均使用Relu作为激活函数。按照由粗到细的过程可将生成器分成两个去模糊阶段,两个阶段均采用类似于VDHNet的编解码结构,基于相邻帧间的时间和空间信息,建立双向时间转移特征,转移特征通过合并子网络与相邻帧的直接特征,由一组编码器编码,然后由混合解码器解码。

图3 生成器网络结构Fig.3 Generator network architecture
生成器学习的内容为清晰图像和模糊图像之间的残差,相较于让生成器网络学习模糊图像到清晰图像的映射,只让网络学习两者间的残差可以大大降低网络的学习量,使其在训练过程中收敛得更快。
采用Patch GAN作为本文判别器网络结构,普通鉴别器计算将输入映射到真实样本的概率值,而Patch GAN将输入图像映射到×的矩阵,的值表示真实样本的概率,的平均值是鉴别器的最终输出结果,可以从特征矩阵中跟踪原始图像中的某个位置。鉴别器使原始图像的每个部分都影响最终的输出。在这项工作中,Patch-GAN由3组卷积单元组成,前2组卷积单元包括2个用于特征提取的卷积层,其内核大小为3×3,步长为1。在每个卷积层之后,有BN、ReLU和池化层,在最后一次卷积中对最大池化层进行删除。在3个卷积单元之后,存在一个卷积核尺寸为1×1的卷积层。Patch GAN输出一个大小为80×80的矩阵,矩阵中元素的平均值是最终判断结果。
2.2 损失函数
传统GAN是基于JS散度和KL散度的方式进行优化,在训练阶段会出现梯度消失和模式崩溃的问题,针对该问题,本文的判别器在Patch-GAN架构的基础上采用WGAN-GP,以Wasserstein距离表示网络的对抗损失,使训练更加稳定。模型训练过程中的损失函数由对抗损失和内容损失加权组成,内容损失包括基于像素空间的内容损失函数和基于特征空间的内容损失函数,表达式如式(11)所示。
=++
(11)
式中,和为像素损失和特征损失相对于对抗损失函数的权重系数,本文设置=100和=10。
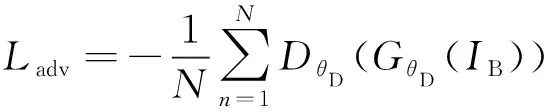
(12)
式中,表示模糊图像;为一个批次的图片训练数量;表示判别器,其下标为判别器参数;表示生成器,其下标为判别器参数。
像素空间损失函数主要用于保证复原图像与真实图像具有更加相似的图像特征,相应的计算表达式为

(13)
式中,为样本清晰图像,和为像素坐标值。为了进一步对图像纹理信息进行细节上的复原,将复原生成的图像与真实图像送入训练好的VGG19,通过计算生成图像特征图与原始图像特征图之间的欧氏距离来计算特征空间损失函数,即

,(()),)
(14)
式中,,表示VGG19网络中第次最大池化层之前,第个卷积层激活后输出的特征图;,和,分别表示特征图的宽度和高度。
2.3 基于GAN的图像去模糊网络模型性能验证
本文的实验训练环境基于64位Ubuntu18.04操作系统,深度学习计算机中央处理器(Central Processing Unit,CPU)型号为Intel Xeon E5-2678 v3,显卡为NVIDIA GeForce RTX 2080 Ti,网络模型的构建与训练是基于TensorFlow深度学习框架实现的。
网络的训练数据集为GOPOR数据集,包含来自多个街道的模糊图像及其对应的清晰图像,在其基础上自制训练和测试样本,预处理后训练集共1865张,测试集共150张。如图4所示,每个样本包含三帧连续模糊帧和相对于中间帧的清晰帧。生成网络选用Adam优化器,初始学习率为10,最大epoch设置为300,在前200个epoch结束后,学习率线性衰减直至为0。

图4 预处理训练样本数据Fig.4 Preprocessing training sample data
为了更加客观地评价去模糊网络,采用当前图像去模糊领域认可度最高的峰值信噪比(Peak Signal to Noise Ratio, PSNR)和结构相似性(Structural Similarity, SSIM)指标作为评判标准,对150张测试数据集进行实验,结果如表3所示,这两项指标的数值越高表示网络模型的去模糊效果越好。从表3的结果可以看出,本文TDGAN去模糊算法在性能上较MS-CNN、DeblurGAN和CLD-SR有了一定程度的提升,模型在实时性方面也表现良好,综合看来,本文研究的去模糊GAN模型在评价指标和网络性能上均优于其他三种方法。

表3 算法指标与单帧平均运行时间对比Tab.3 Comparison of algorithm index and running time
3 运动去模糊视觉SLAM系统
3.1 系统结构与流程
本文研究的运动去模糊视觉SLAM算法在经典ORB-SLAM2算法的基础上进行改进,去模糊算法整体实验流程如图5所示。将相机采集的图像序列送入VO,结合AKAZE特征点的提取过程逐帧进行模糊程度判断,筛选出模糊程度过高的图像,其他图像继续进行特征匹配与位姿估计。另一方面,将模糊图像送入GAN进行去模糊化,输出的清晰图像与系统保存的关键帧进行匹配,或将当前图像的关键点与场景中的点建立对应关系以估计相机位姿信息,并将该信息送入视觉SLAM的后端优化部分进行联合优化。基于词袋模型的回环检测提供当前数据与所有历史数据的关联,当跟踪算法丢失,可以利用回环检测进行重定位,同时确定路标点的位置,完成视觉SLAM的建图功能。
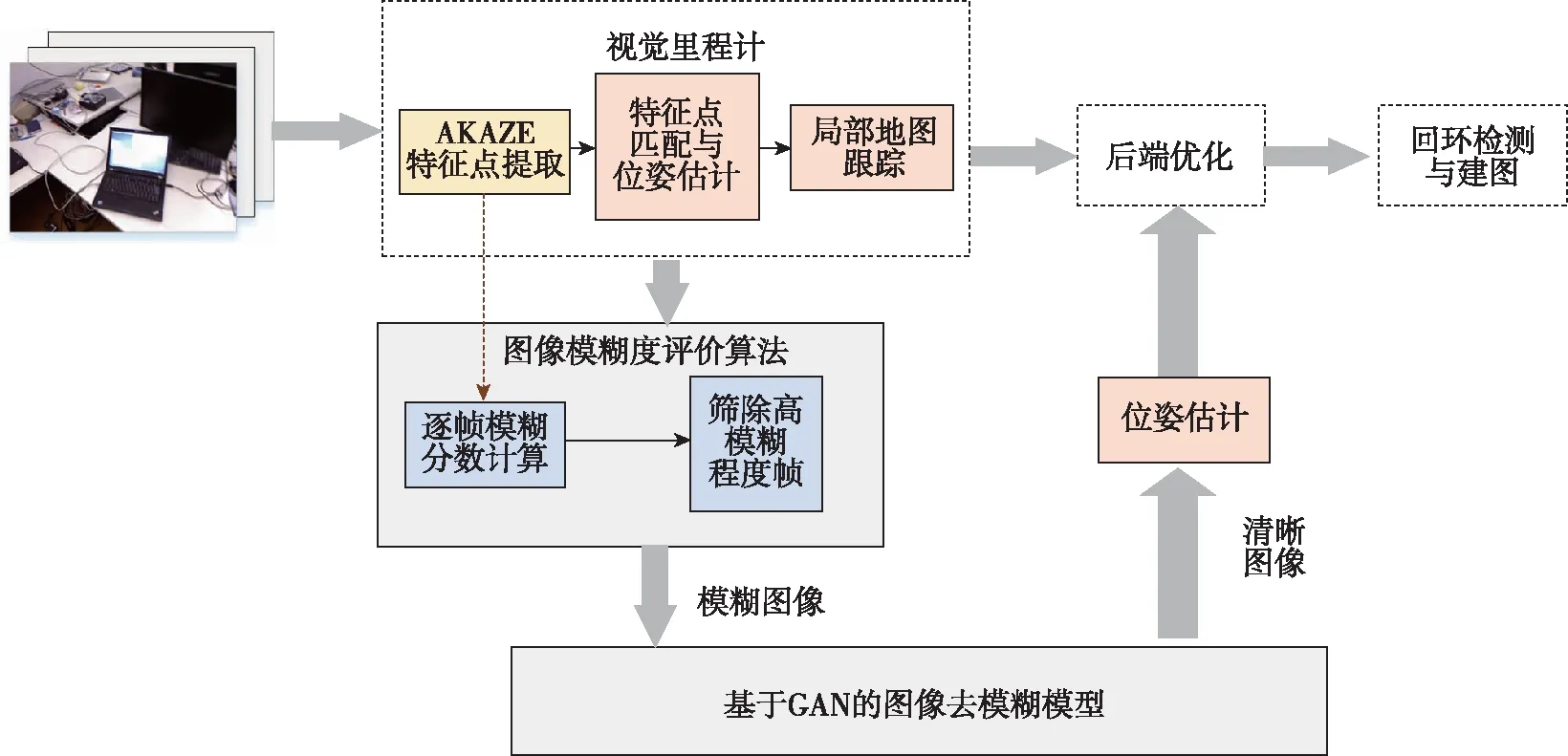
图5 运动去模糊视觉SLAM系统Fig.5 Motion deblurring vision SLAM system
3.2 运动去模糊视觉SLAM系统性能验证
采用TUM数据对本文视觉SLAM算法进行评估,TUM数据集涵盖十几个室内数据场景,通过Kinect采集图像RGB-D数据。选取几个发生运动模糊、动态物体等典型状况的图像序列进行测试,数据集中均提供由运动捕捉系统获取的真实轨迹数据。将图像序列输入至视觉SLAM系统,在进行特征提取与匹配的过程中,基于AKAZE特征点迅速对图像的模糊程度进行判断,将模糊程度较大的图像送入去模糊化GAN,输出清晰的图像再参与后续的SLAM过程。如图6所示,本文网络模型可以恢复图像丰富的纹理信息,获得更高的特征点提取质量。

(a) 模糊图像

(b) 去模糊图像图6 去模糊前后AKAZE特征提取Fig.6 AKAZE feature extraction before and after deblurring
图7所示为TUM数据集下部分序列ORB-SLAM2算法和本文算法的实验结果,数据集给出标准轨迹groundtruth,图中用黑色虚线绘出,ORB-SLAM2运动轨迹由蓝色曲线绘出,本文运动去模糊算法轨迹由绿色曲线绘出。图7(a)展示了在序列freiburg1_desk2中,两种算法均能复现真实轨迹的走势,其中ORB-SLAM2算法在跟踪过程中轨迹偏移较大,而本文运动去模糊视觉SLAM算法定位精度较高。由于序列freiburg2_360_hemisphre运动程度较为剧烈,含有大量模糊图像,如图7(b)所示,ORB-SLAM2算法在跟踪较短的距离后便失效且无法恢复,本文算法在该高动态环境下保持了一定的定位精度和鲁棒性。

(a) freiburg1_desk2序列

(b) freiburg2_360_hemisphere序列图7 TUM数据集测试结果Fig.7 Experimental result on TUM dataset
采用均方根误差(Root Mean Squared Error, RMSE)和标准偏差(Standard Deviation ,STD)评判算法位姿估计的准确度,其中RMSE描述观测值与真实值之间的偏差,易受偶发错误影响,因此可以更好地反映系统的鲁棒性;STD用于评估轨迹相较于真实轨迹的离散程度,可以更好地反映系统的稳定性。将本文研究的运动去模糊视觉SLAM系统与具有代表性的视觉SLAM算法进行对比,包括开源算法ORB-SLAM2以及基于深度学习的算法GCN-SLAM和SurfCNN,每种算法对同一段序列进行10次实验后提出异常数据取平均值,在TUM数据集中的最终结果如表4所示,“-”表示跟踪失败,对于所有测试序列,本文算法的位姿估计精度均高于ORB-SLAM2、GCN-SLAM和SurfCNN。在相对稳定的序列fr1_desk 、fr1_desk2和fr3_office中,本文算法相较于ORB-SLAM2提升幅度较小,分析原因是ORB-SLAM2使用的随机抽样一致性(Random Sample Consensus, RANSAC)算法能将部分小幅度移动的动态特征点作为噪声剔除,一定程度上降低了低动态场景中运动物体对算法精度的影响。而对于包含大量快速运动和快速旋转的动态序列fr1_room、fr1_floor 和fr2_hem,由于相机快速旋转和移动而导致出现大面积运动模糊,本文算法可精准定位模糊图像并进行解模糊操作,如fr2_hem序列中,相较于改进前的ORB-SLAM2算法,本文算法能够将精度提高59.4%,而在fr1_room和fr1_floor序列中精度提升幅度也在20%以上,一定程度上提升了SLAM算法的定位精度与鲁棒性。总体而言,对于6个不同的轨迹序列,本文算法的绝对轨迹误差均小于其他三种对比算法,其中相较于ORB-SLAM2误差平均下降35.3%,相较于GCN-SLAM误差平均下降51.3%,相较于SurfCNN误差平均下降41.5%。

表4 不同算法轨迹误差对比Tab.4 Comparison of the trajectory error among different algorithms
4 结 论
如何在高动态和强干扰的复杂室外环境下实现快速精准定位仍是地面无人平台急需解决的问题。针对无人平台快速运动造成的运动模糊会影响视觉SLAM位姿估计精度的问题,提出了一种基于AKAZE特征点的运动去模糊SLAM系统。在多类数据集上进行实验,分别验证了本文研究的图像模糊度评价算法和去模糊GAN模型的有效性,并在此基础上,进一步验证了最终提出的运动去模糊SLAM方案。结果表明,本文方法在运动模糊程度较高的动态场景下,绝对轨迹误差和相对路径误差比ORB-SLAM2 算法精度至少提高了50%,在模糊程度较低的动态序列中,精度平均提高了20%以上,说明本文方法可以有效提高运动模糊状态下VO的位姿估计精度,具有良好的鲁棒性。
在未来的工作中,将进一步研究与深度学习相结合的动态视觉SLAM方法的实时性问题,对图像进行模糊度判断并完成去模糊化的分步式处理步骤,类似于多传感器信息融合中的松耦合,需要精准的模糊度判定和去除方法才能确保后续SLAM系统的可靠性。这种存在优先级的优化方式使得精度会受到其中一种优化结果的制约,而且额外的处理步骤会降低系统的运算效率。因此,将里程计任务与去模糊任务以一种紧耦合的方式呈现,是未来SLAM应对运动模糊环境的一种新尝试。
