基于OpenCV的芯片IMEI码的检测与识别
2022-08-23朱德意孙晴艺董思凡麻胜恒王耀雄
朱德意,孙晴艺,董思凡,麻胜恒,王耀雄,高 放*
(1.广西大学 电气工程学院,广西 南宁 530004;2.广西中科阿尔法科技有限公司,广西 南宁 530201;3.中国科学院合肥智能机械研究所,安徽 合肥 230031)
0 引 言
运动目标检测与跟踪是计算机视觉领域的一个研究热点,其核心主要包括目标检测、提取及跟踪三个部分。工业生产流水线上芯片IMEI[1]码的检测与识别是一个典型的运动目标检测与跟踪问题。识别并写入IMEI码是芯片制造流水线上的重要一环,传统的依靠人工记录IMEI码的方式枯燥乏味且效率低下,因此有必要开发智能算法自动识别流水线上芯片的IMEI码。
目前还没有关于芯片IMEI码检测与识别的相关研究,但是关于检测其他字符的研究有很多。通常识别字符主要有深度学习和图像处理两种方式。胡逸龙等[2]通过改进的YOLO算法检测中文车牌位置,再通过改进的CRNN算法识别车牌;张瑞红等[3]基于HOG特征的级联检测器结合多角度检测方法实现对奶牛标牌定位,通过神经网络训练字符实现对奶牛标牌识别;李荣远等[4]通过KNN对电子秤数码管字符进行识别。国外也有相关的字符识别研究。L. T. Akin Sherly等[5]利用HOG和LIFT提取场景字符信息特征,利用贝叶斯交互搜索算法(BISA)对基于AdaBoost的卷积神经网络(BISA和AdaBoost-CNN)进行场景字符识别;Faisel Mushtaq等[6]提出了一种用于识别手写乌尔都语字符与数字的算法,通过大量的训练,在识别的两万多的手写字符中,准确率近99%。这类通过深度学习对字符进行识别的方法识别结果的准确率高但是需要大量的时间和大量的训练样本,且需要用图像处理的方法对训练样本和待识别的样本图像进行预处理。
通过图像处理来识别字符的研究也很多。杨新年等[7]通过高斯去噪和灰度化等方式处理车牌,通过垂直和水平投影结合割车牌字符成功识别车牌;Ravi Kiran Varma P等[8]通过高斯滤波、形态学处理等处理印度车牌,同时通过边界跟踪分割字符轮廓,并根据字符尺寸、空间定位处理感兴趣区,识别了印度车牌;Minhuz Uddin Ahmed Abu Jar等[9]也用类似方法对孟加拉的山地车车牌进行识别。常江等[10]使用全局阈值分割方法对塑料袋上的印刷字符进行分割,其对大字符的识别效果较为准确,但对小字符的识别提取有待提高;杨蕊等[11]在Web端插入OpenCV.js开源图形数据库对发票图像进行灰度二值化、降噪、矫正以及分割等图片在线预处理操作,引入Tesseract.js字符库用于训练和识别操作,从而将发票信息电子化;牛智星等[12]对水尺图像进行处理,通过识别水尺上的字符实现水位监控。通过图像处理对字符进行识别的方法处理时间短、速度快,但是识别的准确率偏低。
针对芯片字符识别,该文提出一种基于OpenCV[13-14]的芯片IMEI码的检测与识别的方法。该方法流程简洁,对视频进行简单的处理后,利用Tesseract-OCR实现对芯片IMEI识别。识别之后的芯片IMEI码出现在编译框内,也可以将其保存在文本文件之中。
1 算法流程
该文识别芯片IMEI码,最主要的是识别并提取芯片的IMEI码区域。只有提取了区域才能够合成包含芯片IMEI码的视频。
由于识别视频背景复杂且一直处于移动状态,常规的目标提取算法如帧间差分法和背景分离法需要保持背景不变,而本视频的背景(如黑色底架、芯片等)一直处于移动状态,所以不能够有效地提取芯片IMEI码,而光流法对每个点都进行标记,通过计算对点前后的比较可以得到移动的部分,但是该视频移动部分远大于静止部分且光流法对计算能力要求过高,难以应用到实际的芯片IMEI码识别。因此后续的对比实验采用CRNN神经网络进行芯片IMEI码识别。
该文使用的方法不同于主流的算法。主流的算法是将运动目标与背景分离,从而达到提取运动目标的目的。而该文的想法是提取运动目标区域与原视频合成,从而获得运动目标。识别芯片IMEI码的大致流程分为三步,具体步骤如图1所示:①图像预处理部分;②筛选芯片IMEI码部分;③芯片IMEI码识别部分。先对视频进行预处理,得到只含有芯片IMEI码的区域的视频,再将该视频与原视频合成,得到一个新的包含少量干扰的芯片IMEI码的视频。之后将新的视频灰度化、二值化后,使用Tesseract-OCR识别芯片IMEI码。Tesseract-OCR处理所得到的字符,即芯片IMEI码,提取芯片IMEI码的特征信息,根据特征信息与语言包中的字符进行比较,将最符合特征信息的字符作为识别结果。
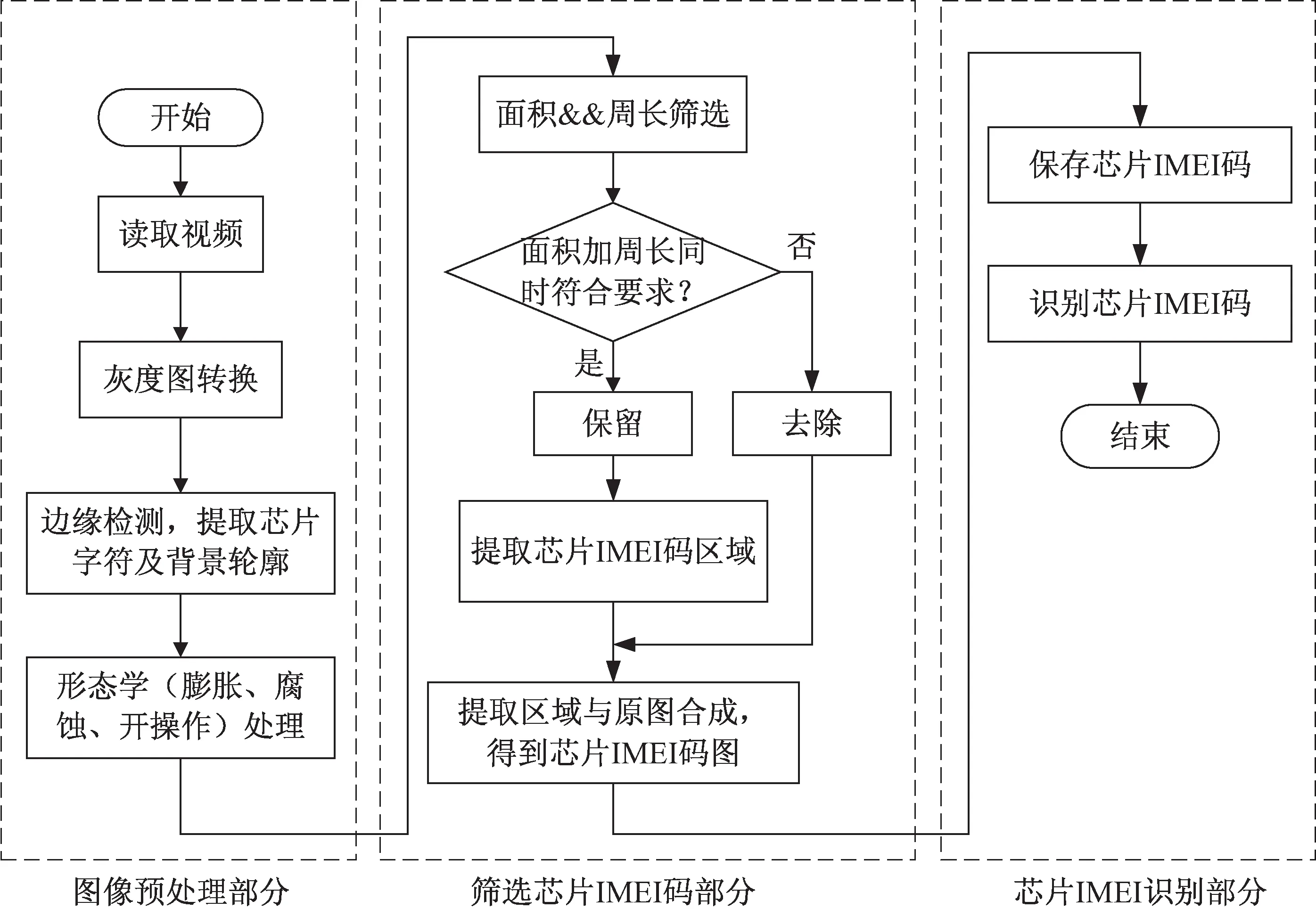
图1 芯片IMEI码识别流程
2 图像预处理
2.1 预处理流程
本次识别的视频为实际流水线上生产芯片的视频,时长39秒,视频中物体包括三块芯片,黑色底架及桌子。为了识别芯片的IMEI码,需要对视频进行预处理,其主要作用是提取芯片IMEI码区域。具体见图1中的图像预处理部分。首先读取视频并将其灰度化,然后对视频进行边缘检测,视频中的边缘包括:芯片轮廓、黑色底架、桌面、芯片IMEI码及各种印在芯片上的字符。边缘检测之后进行形态学处理,便于提取芯片IMEI码的轮廓。
2.2 灰度图转换
该文处理的视频共有39秒,其中包含三块芯片(并不是同时出现的芯片),芯片装载在的流水线的黑色底架上,每两块芯片之间存在间隔。由于拍摄场景光线变化问题,图像中会存在一定的噪声干扰。芯片如图2(a)所示,黑色底架如图2(b)所示。

图2 灰度图
读取视频之后,将视频灰度化。把图像中白色与黑色之间按对数关系分为若干等级,称为灰度。灰度分为256阶。灰度转换通常有四种方法,取平均法、取分量法、取最大值法、取加权平均法[15]。现分别介绍如下:
取平均值法是将RGB的值相加除以三取平均值,公式如下:
(1)
取分量法即取RGB中其中的一种颜色的强度值作为其灰度值,公式如下:
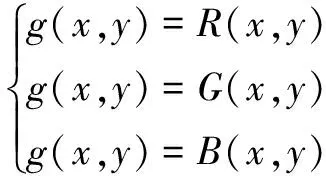
(2)
取最大值法即取RGB三种颜色中强度值最大的作为其灰度值,公式如下:
g(x,y)=max[R(x,y),G(x,y),B(x,y)]
(3)
取权平均值法即取RGB三种颜色中强度值的加权平均值作为其灰度值,公式如下:
g(x,y)=0.30R(x,y)+0.59G(x,y)+
0.11B(x,y)
(4)
上述四种方法都可实现图像灰度化,具体使用那种需根据具体情况而定。因为OpenCV函数默认为第四种方法,为了使程序简洁,所以使用了第四种方法。
图像转化为灰度图后,可通过框选轮廓和边缘检测进行轮廓提取。框选轮廓采用编码的思想,给不同的边界赋予不同的整数值,从而可以确定边界类型及层次关系。输入的二值图像的像素值用f(i,j)表示。每次行扫描遇到以下两种情况终止:
(1)外边界的开始点,满足f(i,j-1)=0,f(i,j)=1;
(2)孔边界的开始点,满足f(i,j)≥1,f(i,j+1)=0。
终止后从起始点开始,标记边界上像素。记新发现的边界为NBD(number of borders,边界数),初始时NBD=1,每次发现一个新边界其数值加1。在此过程中,遇到f(i,j)=1;f(i,j+1)=0时,将f(i,j)置为NBD。就是右边边界的终止点。
整个芯片制造流水线中存在很多的轮廓,包括①各类字符的轮廓如LOGO、制造商、IMEI码、型号、名称、二维码等;②芯片的轮廓;③黑色底架的轮廓;④噪声。芯片轮廓如图3(a)所示,黑色底架轮廓如图3(b)所示。

图3 轮廓图
2.3 形态学处理
从轮廓图可以看出图像的背景度已经消失,但同时出现了各种小斑点、小噪声。通过图像膨胀和腐蚀的形态学处理在剔除小噪声的同时保持IMEI码区域联通且独立,即IMEI码不会与其他图形混搭在一起。
图像膨胀,是将设定的膨胀结构在二值化图像中逐点扫描,当在某个点时膨胀结构与二值化图像有一个点重叠就可保留该点,否则删除该点。图像膨胀会使图像目标变大,但边界会清晰。与轮廓图相比较,膨胀图变的整齐了很多,同时小噪声去除了很多。但整个轮廓膨胀了几乎一圈,使得整体布局拥挤,不同轮廓之间出现明显的连接现象,这对提取目标IMEI码更加是个挑战。
为了减少这种牵连现象,可将图片腐蚀。图像腐蚀是将设定的腐蚀结构在二值化图像中逐点扫描,当在某个点时腐蚀结构与二值化图像完全重叠,保留该点,否则删除该点。图像腐蚀后,目标会变小,边界可能会消失。通过腐蚀操作可以消除小噪声,但会使边界模糊。由于不少小噪声本身就是字符的一部分,贸然消除可能会出现问题。因此,将图像腐蚀,既能消除小噪声,又能维持字符本身。
经过腐蚀的图片整体相对暗淡,不同轮廓边界大致分明,且各类字符轮廓依旧完好保存在图像中。但由于存在各种线条干扰,需要通过多次开操作来消除线条。开操作是形态学操作中的一种,其原理是将图像先腐蚀后膨胀。形态处理后图像如图4所示。

图4 芯片3开操作图
形态学操作之后,图像效果明显增强,同时噪声也消除了很多,余留下的噪声也是呈规则的矩形,同时芯片的IMEI码依旧保留在图像中。因此,图像预处理基本完成,后续需要对形状规则的矩形噪声及除芯片IMEI码之外的区域进行筛除,只留下芯片的IMEI码区域。
3 筛选芯片IMEI码
3.1 芯片IMEI码区域提取
芯片IMEI码区域并未能够被提取出来,因此需要将其他干扰排除。为了能够得到更好的筛选效果,需要对各个轮廓筛选,尽可能多地排除干扰。
由于图像各区域形状基本类似于矩形(也存在不规则图形),因此可以以面积作为筛选条件将面积太大、面积太小的部分先排除;同时由于图像存在一定的不规则图像,只是面积筛选无法准确筛选出芯片IMEI码部分。因此需要进行面积筛选,将周长太短、周长太长的部分进行筛选排除以选到合适图形(即芯片的IMEI码)。经过多次尝试,最终面积筛选的条件为:面积最小值为4 700,面积最大值定为5 100;面积加周长的筛选条件为:面积最小值为4 700,面积最大值为5 100,周长最小值为580,周长最大值为640。此条件下芯片的IMEI被全部提取,但是存在部分干扰项,干扰主要是筛选时未能排除掉的干扰,其中主要的干扰分为四类,如图5所示:①芯片上的制造商字符;②芯片的IMEI码与制造商字符二者同时存在;③芯片高光背景;④黑色底架的轮廓。

图5 四种干扰类型
为比较效果,将两种条件筛选后的每一帧保存并统计只含有芯片IMEI干扰的图形,结果如表1所示。
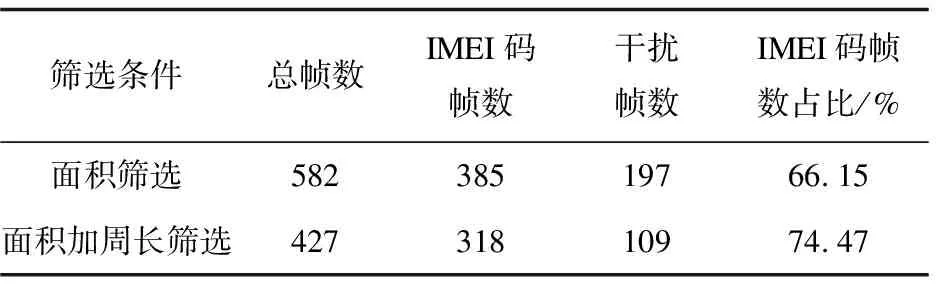
表1 两种筛选结果比较
从表1可知,面积加周长筛选在排除大多干扰的同时只减少了一些芯片IMEI码的图像,所以选择面积加周长筛选作为筛选方式。
3.2 提取芯片IMEI码
在以上处理中,IMEI区域被成功提取出来,然后将原视频帧与芯片IMEI码区域合成只含有芯片IMEI码的视频。从图6(a)可知有且仅有芯片的IMEI码被提取出来,因此芯片IMEI码提取成功。

图6 芯片处理图
芯片IMEI码被提取后,需要将其灰度化并转为二值化以便于芯片IMEI码的识别。因为芯片IMEI码是竖向的,所以需要将芯片IMEI码旋转,使其尽可能与水平面平行,为此统一向右旋转90°。芯片旋转处理后的图形如图6(b)所示。
4 识别芯片IMEI码
4.1 Tesseract-OCR介绍
在OpenCV中并不存在已经训练好的OCR(opti-cal character recognition),光学字符识别。若想识别芯片的IMEI码,要么自己训练并使用OCR对字符识别;要么运用现有的OCR软件对字符进行识别。该文使用后一种方法。OpenCV是一款开源软件,它可以运用很多的开源OCR软件,如:Tesseract-OCR、百度paddle、easy-ocr等。该文使用了比较成熟的Tesseract-OCR。
三个芯片IMEI码分别是 : 866431040005356、866431040005720和866431040005316。
4.2 识别结果
识别的图像为3.2节所旋转后的图像,即图6(b)。视频需通过自适应阈值分割。自适应阈值分割能够根据图像不同区域亮度分布,计算其局部阈值,所以对于图像不同区域,能够自适应计算不同的阈值,可以尽量多地提取到视频特征信息。但是自适应阈值分割并不能保证每一帧图像都十分清晰,只能使整体清晰。所以有一些图像上的字符并不能完全识别,识别的过程中会出现一些乱码。因为对视频的每一帧都会进行识别,所以挑选部分具有代表性(多次识别为同一个结果)的识别进行分析。三块芯片识别结果如表2典型识别所示。

表2 芯片识别结果
由于空间有限,便只选部分具有代表性的结果进行展示。从前面的图像预处理的过程中可以清晰地看到芯片的IMEI码,芯片1的IMEI码为:866431040005356,芯片2的IMEI码为:866431040005720,芯片3的IMEI码为:866431040005316。从表2中可以看出,在芯片IMEI码的识别过程中,尽管部分识别结果的准确率不高,但是数字部分完全识别成功。准确率不高的原因是字母部分识别不是很准确。可能是图像预处理时没有处理好,导致字母部分出现了一些残缺。
作为对比,利用CRNN神经网络来识别字符[16]。CRNN可以进行端到端训练,并且可以识别较长的文本。首先用生成器函数构造了一个由不同字母、数字和冒号组成的数据集(如图7(a)所示)来模拟IMEI码的序列,该数据集有12 800张图片,图片尺寸为512×32,按照8∶1∶1比例随机分成训练集、验证集、测试集。在TITAN V显卡上训练了200个epoch,学习率为1e-2,在生成数据集中识别精度为95.7%。在之前预训练模型的基础上,将学习率设置成1e-3,用图7(b)所示的IMEI码的小样本数据集(包含15张IMEI码的图片)进行迁移学习。识别结果如表2中CRNN识别结果所示。
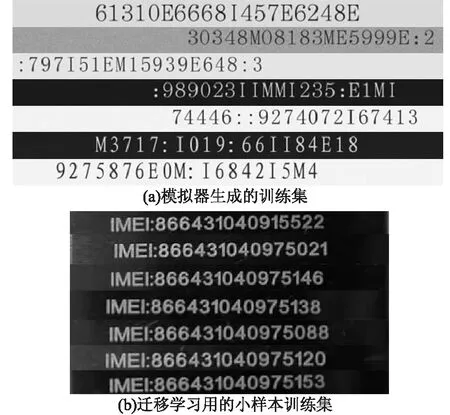
图7 CRNN神经网络用到的数据集
使用CRNN网络识别的芯片IMEI码,准确率并不高,不仅在字母部分识别不全,甚至在数字部分也识别有误。与该文的方法相比较,使用CRNN网络识别芯片IMEI码,会出现多种问题。如:①识别不全,部分字母及冒号未被识别;②识别有误,数字及字母均出现识别错误的现象,甚至字母被识别为数字。所以该文提出来的方法再识别芯片IMEI码优于CRNN网络。
5 结束语
通过提取芯片IMEI码区域,将其与原视频合成,得到只含有芯片IMEI码的视频,变相实现了目标的检测与跟踪,在此基础上通过处理含有芯片的IMEI码视频实现了对流水线上的IMEI码的检测与识别。由于没有训练识别芯片IMEI码的OCR,识别准确率有待提高,故识别IMEI码的程序不能直接应用于生产,需要进一步优化强化。深度学习方法方面结合预训练和迁移学习测试了CRNN网络,发现准确率不如该文提出的方法。今后可以在以下几个方面进行进一步的工作。
(1)图像处理的筛选条件。
芯片的IMEI码与制造商的名称相似。芯片的IMEI码与制造商的名称长度相似,在提取芯片IMEI码区域容易错误提取到制造商的名称。由于该文的筛选条件为面积加周长,后续处理的过程中为避免错误提取目标可以选用不同的筛选条件。
(2)芯片字库的建立。
由于该文没有训练芯片IMEI码对应的字库,只是使用Tesseract-OCR本身自带的英文及中文语言包,只是能够识别,但是由于缺少专业性,故会出现字母“IMEI”错误识别、乱码及空格等问题。后续研究为了提高识别芯片IMEI码的准确率,可以建立专属于芯片IMEI码字符的字库,实现“术业有专攻”,提高识别。
(3)建立并扩充真实环境下IMEI码的数据集。
众所周知,神经网络拥有着强大的计算能力。由于深度学习缺少芯片IMEI码的数据集,训练所用的图片和真实环境下采集的IMEI码图片差距过大,而迁移学习用的真实IMEI码数据集中只含有15张IMEI码图片,导致神经网络识别IMEI码的结果较差。以后可以通过建立并扩充IMEI码在真实环境下的数据集来提高深度学习方法在识别IMEI码上的精确度。
