知识融合研究方法
2022-08-23林硕,赵震
林 硕,赵 震
(渤海大学 信息科学与技术学院,辽宁 锦州 121013)
0 引 言
传统的知识融合一般是静态的,在固定的应用场景下,以人为应用主体的知识融合的过程。然而21世纪是一个信息爆炸的时代,每天都有无数条信息流入网络中,传播较为迅速。这些传递的信息是多元化的,而且缺乏统一的描述规则,给不同领域的信息获取和管理带来了很多挑战。通过信息抽取,实现了从非结构化和半结构化数据中获取实体关系及属性,然而,这些结果中可能存在大量的冗余和错误信息,因此,需要对其进行清理和融合。如何快速、准确地获取信息,让融合后的知识可以更好地满足不同需求的用户,且形成特定问题的领域知识库已成为现阶段研究的重点。知识融合是在信息融合的基础上发展起来的一个新的概念,它可以看成是信息融合的高级领域。该文的主要贡献如下:
(1)对国内外研究现状进行了归纳整理并对语义规则、贝叶斯网络等知识融合算法进行了总结,对所用算法的目的和未来研究方向进行了描述。
(2)对知识融合模式及框架进行了综述,并详细讨论了机器学习方法、深度学习方法等知识融合的前沿方法。
(3)深入分析知识融合应用状况及现阶段面临的挑战,提出未来研究方向,为知识融合相关研究提供参考。
总体框架如图1所示。
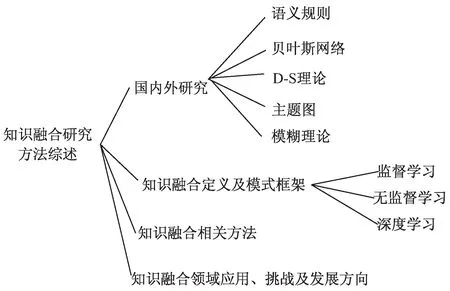
图1 总体框架
1 知识融合发展现状
如图2所示,在中国知网数据库中,对关键词“知识融合”进行模糊检索,共检索1 721篇文献。自从2002年中国首次发表知识融合的论文以来,关于知识融合的相关研究不多,说明很长一段时间学者们对此的研究不够。2015年至今,知识融合的相关研究已经引起了学者们的关注,文献数量逐渐增加,但还没有到达顶峰,说明现阶段知识融合已成为热门的研究方向。国外知识融合的研究最早出现在20世纪80年代后期。语义规则、贝叶斯网络、D-S理论方面的融合算法是国外研究的重点。国内研究主题图、模糊理论等方面,除此之外还对国外研究的各个方面进行了深入分析。
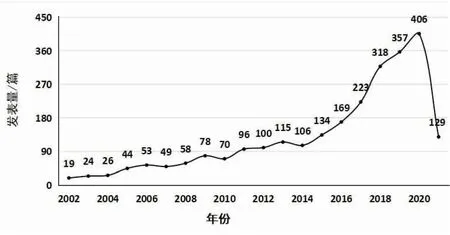
图2 知识融合研究趋势
1.1 基于语义规则
G Jin等[1]在语义规则方面提出一种基于GA和语义规则的知识融合算法,提出调整参数和优化融合的反馈机制,融合的结果被结构化地存储在一个知识空间中。缑锦等[2]利用语义规则将知识对象分类处理,将其转换为对应的本体描述和元知识集。整个框架总体采用分布式结构,具有很好的可扩充性、很强的安全性和实用性以及比较低的误警率。结果表明,提高了知识对象的可重用性和融合的正确率。
1.2 基于贝叶斯网络
贝叶斯网络是研究不确定性知识表达和推理的有效方法,已成为人工智能领域研究的热点之一。基于贝叶斯模型的方法在知识为真时的先验概率和从数据源观察到的条件概率都已知的情况下,求出知识为真的后验概率。后验概率最大时对应的知识就是要找的正确知识[3]。Santosl等人[4]在贝叶斯网络方面,将多个贝叶斯融合成单个贝叶斯,更容易聚合和分解多个源的信息,解决了专家对关系权重意见不一致的问题。张玉洁[5]提出了一种不需要原始数据的贝叶斯网络融合方法,在已有的贝叶斯网络融合方法的基础上,利用评分机制,得到最终的融合结果。张振海等[6]使用K2算法来学习贝叶斯网络结构。根据贝叶斯定理,如公式(1):
(1)
其中,p(Sh)表示网络结构的先验概率,p(C)表示与结构无关的常数,p(Sh|C)表示边界似然。通过收集不同专家的意见,使用证据理论排除无意义的因果关系,减小搜索空间,提高算法的学习效率。结果表明,基于专家知识融合的贝叶斯网络构造方法利用专家知识限制学习算法的搜索条件,有效地缩小了搜索空间。
1.3 基于D-S理论
D-S证据理论的方法是融合不同观测结果的信任函数,得到基础概率分配后,再选择最大支持度的假设作为最优判断,从而选择认为正确的知识。D.Andrade等[7]在D-S理论方面研究了3个组合规则,包括原始的D-S规则、墨菲规则和基于非精确狄利克模型的规则。结果表明,前两者有汇聚的能力,而后者具有数据挖掘的能力。Sun等[8]利用知识融合方法D-S理论,对野生鸟类禽流感H5N1病毒全球空间的风险估计进行整合。韩立岩等[9]提出一种新的融合方法:D2S(Dempster2Shafer)证据理论。利用模糊的概念,选择一个函数,根据估计方法将计算出的数值与阈值的差值,转换为[0,1]之间的数字,此数字代表企业失败的概率。结果表明,提高了企业失败估计的准确性。
1.4 基于主题图
简单来说,就是根据图上的一组现有的边,预测其他边存在的可能性。王海栋等人[10]提出了一种置信度理论知识融合模型,使用自动校正机制,更好地表现置信度的客观性,加强了在不确定性方面处理的缺点,解决了实体融合过程中信息歧义的问题。鲁慧民等[11]提出一种面向多源知识的融合算法。从语法、语义和语用三个方面计算相似度,并考虑了概念结构和语境的相似性。结果表明算法在查准率(Precision)、查全率(Recall)和F值(F-measure)均有所提升。评价标准如公式(2)所示:
(2)
其中,PN是通过人工比对认为应该融合的元素对数,AN是算法判定应该融合的元素对数,RN是各元素中正确的元素对。模糊集理论的方法是在D-S证据理论的基础上工作的。
1.5 基于模糊理论
模糊集理论的方法在D-S证据理论的基础上,进一步放宽了贝叶斯模型的限制条件[12-13]。目前应用较为广泛的方法是基于模糊积分的方法[14]。模糊积分是一个非线性函数,可以完成质量评估,找到置信度最高的知识作为正确的知识。Yin等人[15]设计一种基于粗糙集算法的知识融合模型,可以自动实现复杂表面零件制造过程的质量预测。模型降低了数据的不确定性,从而提高了产品的质量。周芳等[16]在知识融合中借鉴了信息融合的想法,用基于模糊集理论的方法对多源知识进行融合。结果表明,该工作提高了企业失败预警判别的确定性。
国内外研究现状对比如表1所示。虽然学者们对知识融合有着不同的出发点,但是本质都是为了使知识能够最大化的被利用。

表1 国内外研究汇总
2 知识融合定义及模式框架
2.1 知识融合
知识融合是实时地融合和处理多源的信息来创造新的知识的过程,包括实体链接和知识合并两部分。一个典型的知识融合系统应该提供以下三种基本服务[10]:
(1)知识定位服务:供用户或其他组件在网络上定位相关知识。
(2)知识转换服务:将异构知识资源转换为统一的语言或本体表示。
(3)知识融合服务:对知识资源进行组合和处理,合并、简化知识,找出满足某种条件限制的解决方案。
其中具有代表性的框架是Preece AD的KRAFT(Knowledge Reuse and Fusion/Transform)[17],如图3所示。将知识融合定义为从多个异构的资源中对相关的知识进行定位和提取,将其转换为统一的知识模式,使融合的知识能够解决实际问题。
(1)UA:用户为消费者。
(2)W:为系统和KRAFT代理接口提供桥梁。例如:关系数据库的传统接口是SQL/ODBC,KRAFT中的W会接受来自KRAFT中其他代理的请求信息,将其转换为SQL语句并在数据库上运行,最后返回结果。
(3)M:每个M从其他代理获取知识,是知识融合的核心。
(4)F:建立服务请求,每个KRAFT网络中至少有一个F。
(5)R:服务资源,包括数据库和知识库。
F根据W提供的信息去寻找匹配的M进行连接。当连接是从W到M时,M进行知识转换;当一条路径上有多个M,或同一M在多条路径上时,进行知识融合。当连接是从UA对应的从W到M时,M会用统一的知识模式提供给UA[18]。
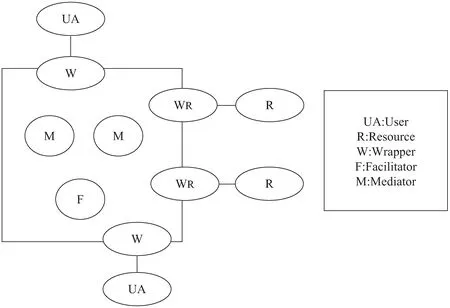
图3 KRAFT结构
2.1.1 实体链接
实体链接是指通过对本体库中名字是否具有相同含义来判断实体是否相对应,或者名字不同的实体是否能够表达同一个含义。实体链接又包含实体消歧和共指消解两部分[19]。
(1)实体消歧。
例如“张蓝心”这个单词(指称项)可以对应于作为演员身份的张蓝心这个实体,也可以对应于模特身份的张蓝心这个实体,还可以作为国家跆拳道选手身份的张蓝心这个实体。通过具体语境,对实体进行消歧。重点在于计算描述的词汇与实体之间的相似度。
(2)共指消解。
共指消解是解决多个词汇(指称项)对应同一个实体的问题。例如某文中提到“唐纳德·特朗普”,“川普”,“特朗普”指向的是同一个实体,其中如“他”、“他的”,都有可能指向这个实体。将这些指称项通过共指消解,合并到正确的实体对象中。
2.1.2 知识合并
知识合并包括外部知识库和关系数据库。
(1)外部知识库:包括数据层面和模式层面。
(2)关系数据库:将关系数据库的数据转换成三元组。
2.2 知识融合模式
为了解决知识共享问题,将知识融合分为多个层次,可以更好地解决实体的属性、关系以及概念的重复等问题。周利琴[20]从知识表示的角度,将网络知识模式分为实例、关系、域集、属性和概念融合。其中实例融合是对实体对象进行去重与合并,从而产生新的实例。域集融合是在实例融合的基础上产生的。关系融合是对多源知识的关系进行对比分析,与属性融合是相互作用的。概念融合则是根据每一次产生新的知识概念来实现的。
2.3 知识融合框架
知识融合框架是进行知识融合的开端,为各个模块提供方向。因为知识融合的复杂性,需要对特定问题制定专门的框架,现在国内还没有统一的知识融合框架。徐赐军等[21]设计了基于本体的知识融合框架,实现对元知识集进行构建、知识的测量标准、包含融合算法的设计以及融合后处理等功能。可以减少融合的规模,提高准确性。陈思华等[22]提出一种文化算法框架,采用两阶段遗传算法,包括编码阶段和融合阶段。从两个层面对知识进行优化的知识融合策略,用启发式规则进行表示。谢能付[23]提出的框架包括知识聚类模块、评估模块和融合模块。
JointDirectors of Laboratories (JDL)由美国国防部在1986年首次提出[24],主要用于军事领域。JDL的融合框架如图4所示。
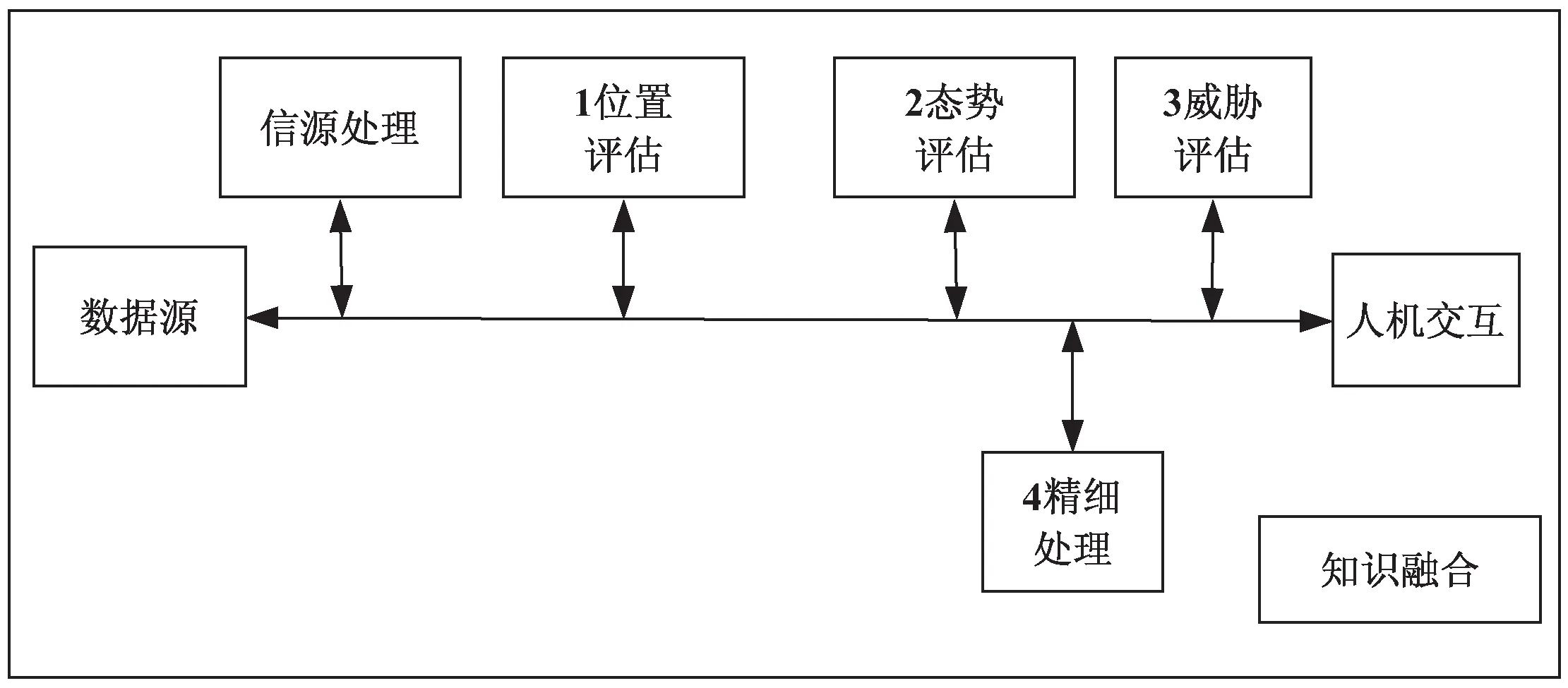
图4 JDL的融合框架
3 知识融合相关方法
3.1 机器学习
机器学习方法是一个比较热门的研究主题,是计算机科学和人工智能的一个分支学科。在知识融合领域也可以应用各种机器学习方法。可以根据训练样本是否有输出值,将机器学习方法分为监督学习、无监督学习、半监督学习。监督学习是机器学习中的一种训练方式,监督学习(Supervised Learning)中的常用方法为SVM、决策树、集成学习等。
3.1.1 监督学习3.1.1.1 SVM
SVM(Support Vector Machine)是一种二分类模型,通过找到间隔最大的超平面来对数据进行分类,可以转换为一个凸二次规划问题进行求解。Park等人[25]提出了一种基于分数级融合的虹膜识别方法。使用两个Gabor波滤器用于局部和全局虹膜处理,用SVM融合了由Gabor波滤器计算出的HD(Hamming Distance)。SVM表示成公式(3):
(3)
其中,k表示数据的数量,yi∈{-1,1}表示训练样本xi的类标,∂i表示求解二次规划问题的线性约束条件,b表示偏置。利用核函数将SVM扩展到非线性决策面。结果表明,降低了由此产生的认证误差。
一般来说,虹膜识别精度取决于Gabor波滤器的大小、频率和振幅的选择。文中为了减少时间和复杂的操作,使用了传统的1D Gabor,如公式(4)、公式(5):
(4)
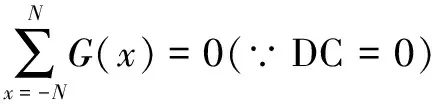
(5)
其中,A表示Gabor过滤器(G(x))的振幅,σ和u0分别表示Gabor波滤器的大小和频率,x0表示移动量,DC=0表示将波滤系数归一化为0。
3.1.1.2 决策树
决策树(Decision Tree)有分类树和回归树。根据损失函数最小化原则建立决策树模型。Elfeky等[26]在TAILOR工具包中实现了一种ID3决策树算法,TALOR是一个记录链接工具箱。用户可以调整系统参数和插入工具来构建自己的实体对齐模型。结果表明,算法匹配效果高于传统的概率模型方法。张晓丹等[27]利用ID3算法分析和处理测试空间中的多源数据,建立准确的评估模型。最后的结果表明,该方法在解决多源数据问题,并且在处理大量无序和不确定数据方面非常有效。
袁雅萍[28]用决策树模型作为土壤与环境关系中知识融合和抽取的方法。使用一致性分析等统计方法,实现多源知识的互补和融合。利用混淆矩阵运算出生产精度(PA)和用户精度(UA),用于表示每个分类的精度指标。总精度(OA),用于表示总体分类的精度指标,通过这些指标共同检验预测土壤图的精度。三种指标的计算公式如下:
(6)
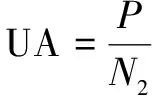
(7)
(8)
其中,n表示土壤图所有准确分类的样本数量,N1表示野外该类土壤的样本总数,N2表示土壤图中划分到该类土壤的样本总数,N表示样本总数。
3.1.1.3 集成学习
集成学习通过使用一些规则将各个学习器学到的结果整合,从而得到比较好的效果。Chen等[29]提出了统一的决策模型,使用Context-Extended和Context-Weight方法,将两个部分用两种组合方法进行融合。实验结果表明,集成学习框架在不同领域的应用上,实现了更高的匹配质量,也证明了所提出的方法相对于其他方法的优势,提高了实体的消歧质量。
3.1.2 无监督学习
当训练样本数量不足时,可以通过无监督学习完成知识融合中的实体对齐。常用方法是聚类。聚类根据相似度或距离来判断,将相似的样本聚集在相同的类,不相似的样本分散在不同的类。Zhang等[30]采用基于实例的无监督学习方法,该方法提供了一个MBL框架。结果表明,能够对实体之间的多种关系进行精确的识别,获得了很好的结果。Bhattacharya等[31]提出一种关于实体的属性和关系信息的聚类算法。研究了不同关系相似性影响对实体质量的解决办法。结果表明,当数据中存在模糊引用时,关系聚类算法的效果优于属性相似度。Verykios等人[32]使用聚类方法,通过少量标记样本推断聚类中其他样本的情况,使用属性和关系的信息来确定实体。结果表明,通在相似性搜索,在知识获取方面有很大提高。
3.1.3 半监督学习
半监督学习是监督学习与无监督学习相结合的一种学习方法。使用大量的未标记数据,同时使用标记样本,来进行模式识别工作。常用的方法是留一验证法和交叉验证法。Carlson等人[33]从网页中提取类别和关系,使用半监督学习方法和CPL(Coupled Pattern Learner)和CSEAL(Coupled SEAL)耦合的方式,证明了这种方法可以提高多种类型的提取器的准确性。
3.2 深度学习方法
严格来讲,深度学习属于机器学习范畴。但深度学习可以更好地处理大规模数据,所以将深度学习方法单独列出来。
神经网络(Neural Network)也叫做人工神经网络(Artificial Neural Network),由大量的节点(或神经元)直接相互关联而构成,是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。神经网络包括监督学习和无监督学习。
Gabriel等[34]将不同分类方法和神经网络集成在一起,形成代理虚拟组织,用于从E-nose 检索的参数中进行信息融合,该系统模拟人脑如何分类。利用PCA作为一种降维方法,对初始数据进行预处理,然后利用反向传播神经网络BPNN对E-nose进行分类,结果表明组合分类器的结果和精度均大于单个分类器。
Wang L等[35]通过对反向传播(BP)神经网络使用遗传算法(GA)来优化,评估创新生态系统中知识融合的风险。使用预处理后的数据作为神经网络的输入值,确定种群大小和最大迭代次数,选择交叉概率,设置权重和阈值的上下限。结果表明,GA-BP神经网络具有更快的收敛速度和更高的稳定性,可以更快地实现目标。
Zeng等[36]利用分段卷积神经网络和多实例学习进行远程监督关系提取。其使用分段最大池化来自动学习特征,结合多实例学习来解决错误的标签问题。Santos等[37]提出一种排名分类模型CR-CNN,使用单词嵌入作为输入要素,利用卷积神经网络来处理关系分类任务。使用新的成对排名损失函数,可以有效减少人工分类的影响。
3.3 其他方法
Hka B[38]提出一种基于机器学习和知识图谱的AM(Additive Manufacturing)框架,对来自国家标准和技术研究所的测量数据,采用分类和回归树的机器学习方法来解决AM相关的问题。Wang[39]提出一种新的知识融合方法HCCKF(Human-Computer Cooperative Genetic Algorithm),利用进化计算(Evolutionary Computation)融合了人类知识、先验知识和计算知识。
George[40]提出CKF(Collaborative Knowledge Fusion)方法,想要了解和控制信息的传播,如何促进真实信息的传播。Balemans[41]提出了传感器融合方法,为了提高不同环境的感知精度,传感器提供关于相同特性的互补信息,通过结合两个传感器的信息来提高检测精度。
各类知识融合方法特点的总结如表2所示。

表2 知识融合方法总结
4 知识融合领域应用、挑战及发展方向
知识融合应用领域十分广泛,覆盖自动问答、银行、企业发展等领域。其中由清华大学、清华同方发起的中国知识基础设施工程(CNKI),集成了各个学科的公共知识和各学科专家的个人知识,建立了一个庞大的共享知识库,旨在为科研、教学和知识服务提供基础。知识融合现在有了一定的发展,但仍不能满足人们的需求。现阶段知识融合依旧是一项具有挑战的工作,仍有很多问题需要解决。
(1)知识的不一致性。如何在异构知识情况下,对特定知识进行融合,为用户提供需求是一个艰巨的任务。
(2)知识的复杂关系。存在大规模语义表达相似的知识,导致关系的难理解。这需要更健壮的技术,并能够消除噪声。
(3)实体链接实现的准确性。目前,如何在上下文信息受到限制的情况下,准确地将实体与知识库中的实体链接成为现在普遍关注的问题。
未来知识融合领域也有更多的发展方向:
(1)实时融合大规模知识,进行多种语言的融合。
(2)建立一个统一、专门的知识融合体系结构。
(3)将深度学习应用到知识融合中。可以获得更高的性能和预测精度。深度学习能够从大数据中获取实体之间复杂、模糊的关系,是很有效率的方法。
未来的研究应该更加投入到图书情报中,将知识融合充分运用到其中。知识图谱成为智能搜索的关键技术,具有很深远的价值。知识融合是知识图谱中的一个重要环节,期待更多的研究人员可以对此进行深入研究,促进知识融合领域的发展。
