基于自注意力机制的视频超分辨率重建
2022-08-23秦昊宇张力波吴学致任卫军
秦昊宇,葛 瑶,张力波,吴学致,任卫军
(长安大学 信息工程学院,陕西 西安 710064)
0 引 言
随着智能手机及各类摄影摄像设备的普及,图像、视频在人们生活中占据着越来越重要的地位。同时,人们对于图像、视频清晰度的需求也在逐渐提高。自Harris和Goodman首次提出图像超分辨率重建的概念与方法[1]以来,超分辨率方法作为计算机视觉领域中图像处理的一项技术,能够提高已经拍摄出的图像视频的分辨率,已经广泛应用到人们生活中的各个方面,具有重要的研究价值。
超分辨的核心在于寻找低分辨率图像与高分辨率图像特征之间的映射关系[2]。Dong Chao等人在2014年首次将深度卷积网络CNN融入图像超分辨重建,提出了一种全卷积网络模型SRCNN[3]。随着深度学习的不断深入研究及其在图像处理应用范围的扩大,更多基于深度学习方法的超分辨率重建网络模型正在进一步发挥作用[4],而超分辨率技术也不再局限于图像,而是开始向视频领域发展。视频超分辨率重建可分别在时间域和空间域上进行重建[5]。空间视频超分辨率重建通过引入更多的相邻帧,将帧间互补信息对齐融合到关键帧以提高关键帧重建效果。时间可变形的对齐网络(temporally deformable alignment network,TDAN)[6]对从原始帧提取的特征使用可变形卷积网络,自适应地完成当前帧与相邻帧的对齐,并动态地根据估计出的特征空间补偿信息进行隐式运动补偿,从而通过重建模块得到高分辨率的视频帧。EDVR[7](enhanced deformable convolutional networks)在TDAN模型的基础上提出了多尺度特征图对齐模块,更好地完成了帧间互补信息对齐。时间域的视频超分辨率重建主要是通过给定当前帧图像和下一帧图像,从而生成中间帧的视频插帧技术来实现。目前,通过深度神经网络学习现有帧与未知帧的映射关系存在一定困难,因此常用通过学习得到的中间帧的光流信息来进行传统插值,进而生成中间帧。该文是在现有的算法研究基础上对视频超分辨率重建进行深入研究,构建了一种融合时间与空间域的视频超分辨率重建模型VTSSR,实验证明,该模型充分考虑到了视频帧间运动时间与空间的关联性,提高了视频超分辨率的重建效果。
1 超分辨率重建理论
现实生活中,各种外在影响会使得采样得到低分辨率图像,这一现象称为图像退化[8]。逆向处理图像退化,从而恢复出高分辨率图像和视频的技术就称为超分辨率重建技术。
视频超分辨率重建分为时间域和空间域的视频超分辨率重建。时间域超分辨率重建主要是将由于采样设备、视频压缩等造成高频信息丢失的低帧率视频帧重构成高帧率[9],重构过程主要使用视频插帧的方法。常用的视频插帧方法主要是基于运动补偿的视频插帧,其主要思想是通过运动估计和运动补偿在原视频序列连续的两帧之间插入图像帧,基于运动补偿的插帧方法步骤如图1所示。
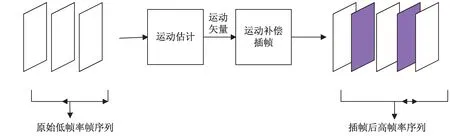
图1 基于运动补偿插帧
如图1所示,该过程将输入的原始低帧率视频序列经过运动估计得到相邻帧之间的运动矢量,再将这些运动矢量经过运动补偿插帧等操作生成插帧后的高帧率序列。其中,运动估计是计算视频帧上同一个像素点在相邻图像帧之间运动时发生的空间偏移量[10],而运动补偿就是根据这些偏移量计算该像素点在中间帧的对应位置,从而补偿差值生成中间帧。
空间域超分辨率重建是从连续的低分辨视频帧序列中重建得到对应的高分辨率帧序列,其中重构过程使用多帧图像超分辨率重建方法实现,其关键在于多帧帧间信息的配准。这些由视频得到的多帧图像在亮度和像素上存在细微差别,能够通过捕获帧间差异信息完成超分辨率重建[11],方法过程如图2所示。

图2 视频超分辨率重建
由图2可知,该过程首先将输入的原始低分辨率视频帧序列利用运动估计算法预测帧间运动矢量,再对本段序列帧中的关键帧进行运动补偿,接着将相邻帧图像与当前关键帧图像进行对齐配准,使两帧位于同一坐标系中,最后经过重建网络将多个特征图像融合得到关键帧的高分辨率图像。
2 融合时间域与空间域的视频超分辨率重建模型
2.1 模型框架
融合时间域和空间域的视频超分辨率重建模型中的重建网络由特征提取、特征插值、自注意力机制融合以及亚像素卷积上采样和残差块四部分组成,能够同时对视频进行时间域和空间域超分辨率重建,最后输出高帧率的高分辨率视频。由于视频帧间互补信息在时间和空间上具有一定的关联性,该模型采用可变形卷积对齐、自注意力融合技术增强了这一关联性,从而进一步提升了视频超分辨率重建的效果。模型框架如图3所示。
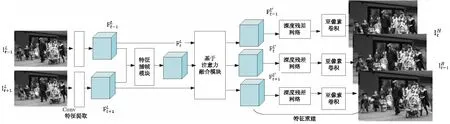
图3 VTSSR模型结构
2.2 特征提取
基于深度学习的视频超分辨率重建使用卷积神经网络,区别于光流法复杂的假设条件和公式推理,直接通过卷积运算来学习相邻帧之间的运动信息,降低了特征提取的复杂度,提高了特征的语义性。此外,引入残差块能够加深卷积结构,从而增强模型重建能力并提高重建视频质量。该文使用卷积神经网络进行特征提取的模块如图4所示。
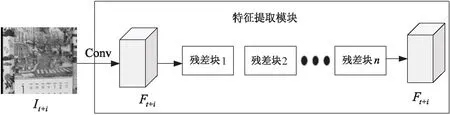
图4 特征提取模块
图4中展示了该特征提取模块的操作流程,该模块由一个卷积层和多个残差块组成。首先,输入的相邻奇数帧It+i经过卷积网络提取出其特征图Ft+i,再将提取的特征图Ft+i经过残差块提高模型重建能力,最后将其用于特征插帧模块的输入。
2.3 特征插值
由于该模型是融合了时间域和空间域的视频超分辨率重建模型,模型关键在于增强视频帧间互补信息在时间和空间上的关联性,因此特征时间插值模块在相邻帧的特征图上直接对齐得到中间帧特征图,而不是先重建生成中间帧再得到中间帧的特征图。TDAN[12]基于可变形卷积的对齐模块,利用卷积网络学习帧间运动进行信息建模代替了光流预测法,能够更好地对齐相邻特征图。融合了时间域和空间域的视频超分辨率重建模型参考了TDAN提出的原理,采用同模型不同方向的卷积,并加入了特征时间插值模块的设计,如图5所示。
图5中,模块输入为相邻的两帧特征图Ft+1和Ft-1,待插中间帧的特征图为Ft,通过学习一个特征时间插值函数f(·)并利用相邻的两帧特征图Ft+1和Ft-1直接合成和待插中间帧的特征图Ft,它们之间的关系用公式表示为:
Ft=f(Ft-1,Ft+1)=H(Ft-1→t,Ft+1→t),t∈2N
(1)
其中,Ft+1→t为Ft+1到中间帧特征图Ft的对齐特征,Ft-1→t为Ft-1到中间帧特征图Ft的对齐特征,H(·)为一聚合采样特征的混合函数。

图5 特征时间插值模块
由于中间帧特征图Ft还未合成,无法直接计算Ft与Ft-1、Ft与Ft+1之间的运动信息,因此使用可变形采样函数来隐式地获取Ft-1与Ft+1之间的运动信息,以此来近似代替。首先输入Ft+1和Ft-1合并Concat后经过3*3的卷积层,目的是减少通道数降低参数量。然后通过一个卷积层去预测输出通道数量为|R|的采样参数θ1,如式(2)所示:
θ1=g1(Ft-1,Ft+1)
(2)
其中,采样参数θ1为可偏移学习量,g1表示多个卷积层的一般函数。同理,输入Ft-1和Ft+1,Concat后经过3*3的卷积层,然后通过一个卷积层去预测输出通道数量为|R|的采样参数θ2,如式(3)所示:
θ2=g2(Ft-1,Ft+1)
(3)
接着使用可变形卷积计算出Ft+1到中间帧特征图Ft的对齐特征Ft+1→t和Ft-1到中间帧特征图Ft的对齐特征Ft-1→t,如式(4)所示:
Ft+1→t=T(Ft+1,θ1)=DConv(Ft+1,θ1)
Ft-1→t=T(Ft-1,θ1)=DConv(Ft-1,θ2)
(4)
最后,得到的两个对齐特征通过H(·)混合函数分别相乘1*1卷积层再对位相加得到了最终中间帧的特征图Ft。
2.4 特征融合
该模型在特征融合模块中引入自注意力机制,将通过联合学习对齐得到的多特征图的时间、空间维度特征信息赋予新的权重并重新分配,能够自适应地学习特征信息在不同维度之间的关联性。基于这种方法的特征融合,能够增强有用特征而抑制无用特征,从而更好地处理特征的帧间运动并利用帧内信息在时间和空间上挖掘特征信息。其结构如图6所示。
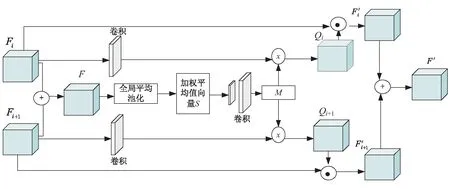
图6 基于自注意力融合模块
如图6所示,首先将需要融合的特征图序列Fi合并concat后得到全部特征图的和F,然后将特征图通过全局池化层得到全部通道数的加权平均值向量S,其中S的通道数为C个,计算公式如式(5)所示:
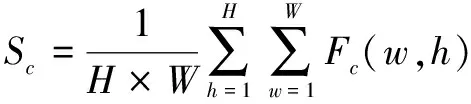
(5)
接着使用两个全连接层学习全部通道间的相关性,前一个全连接层使用压缩因子r压缩通道数C/r,后一个全连接层将通道数扩为原始的通道数C,计算得到F的特征向量矩阵M,计算公式如式(6)所示:
M=W2(σ(W1·F))
(6)
其中,W1和W2是两个全连接层的权重矩阵。这样先压缩后扩充通道的方法能够给各通道分配各自的注意力,从而可以达到增强有用特征而抑制无用特征的目的。接着使用卷积核为1*1的卷积层来卷积压缩特征图的时间维,将Fi的尺寸从C*H*W变为H*W,学习每个输入特征矩阵在空间维度上的内部相关性得到序列{qi}计算公式如式(7)所示:
qi=CNN(W3·Fi)
(7)
式中,W3是卷积层的权重矩阵。
将得到的{qi}和特征向量矩阵M进行向量点乘得到通道和空间的相关性{Pi}计算公式,如式(8)所示:
Pi=qi·M
(8)
使用激活函数sigmod得到更加突出重要元素的权重矩阵{gi},如式(9)所示:
(9)
式中,(w,h,c)指像素的空间坐标和通道位置。最后将权重矩阵和输入特征Fi对位求和得到最终的融合特征图:
(10)
2.5 重建模块
现有常见的基于深度学习的重建网络主要是提取出低分辨率图像中的特征,并通过学习这些特征将它们扩大成高分辨率图像,从而实现超分辨率重建。该文提出的融合时间域与空间域的视频超分辨率重建模型在重建时使用高分辨率图像HR重建模块,该模块输入来自低分辨率图像中提取深层特征后构成的特征图序列,使用多个堆叠残差块和两个卷积网络将输入的低分辨、高帧率的特征图像序列转为高分辨、高帧率图像输出。
由图7可知,HR重建模块对输入的特征图序列使用残差块组成的网络来继续学习特征,这种方法能够更好地利用图像高频信息[13],减小运算量。最后利用亚像素卷积上采样扩大特征图尺寸,输出重建的目标分辨率图像。
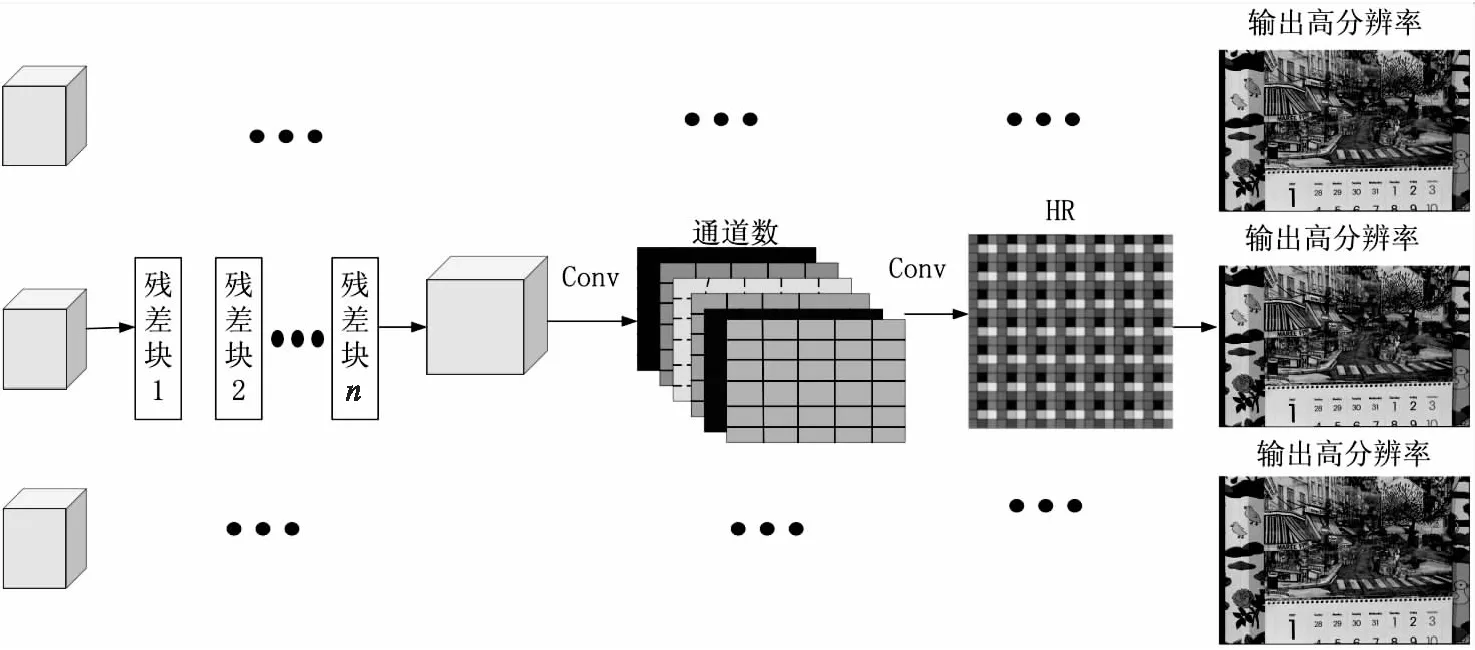
图7 HR重建模块
3 实验结果与分析
3.1 实验数据集
为了验证该文提出的融合时间域与空间域的视频超分辨重建模型的有效性,使用视频超分辨领域主流的数据集Vimeo-90k[14]、Vid4[15]对模型进行实验验证,并将实验结果和目前的视频超分辨算法模型进行比较。本模型在获取低分辨率图像数据集时采用双三次插值下采样方法,测试时对放大4倍的图像进行模型重建,并使用主观视觉和客观指标峰值信噪比PSNR、结构相似性SSIM[16]对模型重建效果进行评价。
3.2 实验处理及参数设置
由于下载的公开数据集主要是高分辨率视频,而训练时需要与之对应的低分辨率视频,因此使用Matlab工具将高分辨率视频下采样缩小成与之对应的低分辨率图像,再分别将这些高分辨率图像和低分辨率图像生成lmdb格式以便作为输入数据。本次实验使用视频序列中奇数标签作为输入,训练模型配置文件参数如表1所示。
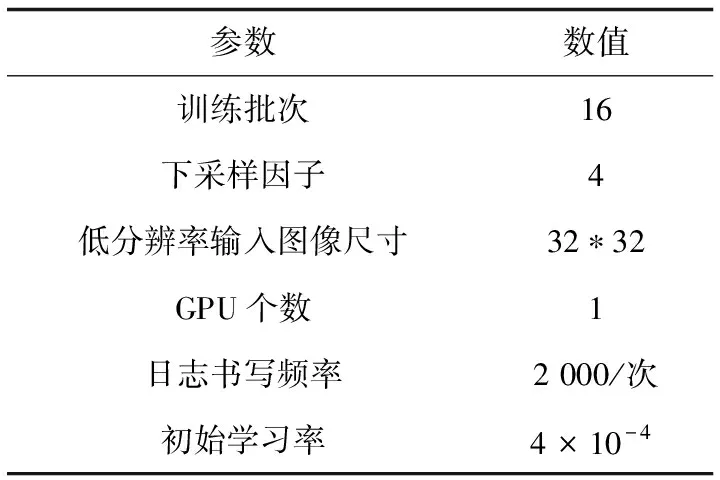
表1 配置文件参数设置
模型中使用的损失函数如式(11)所示:
(11)
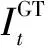
3.3 实验结果分析
训练完成后,在Vid4和Vimeo-90k数据集上对构建的融合时间域和空间域视频超分辨率重建模型VTSSR的可行性和有效性进行验证。
3.3.1 PSNR和SSIM指标值
从Vid4数据集和Vimeo-90k训练集中抽取测试集,对超分辨倍数为4的样本进行实验,与两种时间插帧模型Sepconv[17]、DAIN[18]和三种空间超分辨模型Biubic[19]、RCAN[19]、EDVR[6]联合的方法进行对比。VTSSR是该文构建的融合时间域和空间域的视频超分辨率重建模型。通过对比可以看出,该模型在一定程度上优于其他模型,各自模型的峰值信噪比PSNR和结构相似性SSIM指标对比如表2所示。
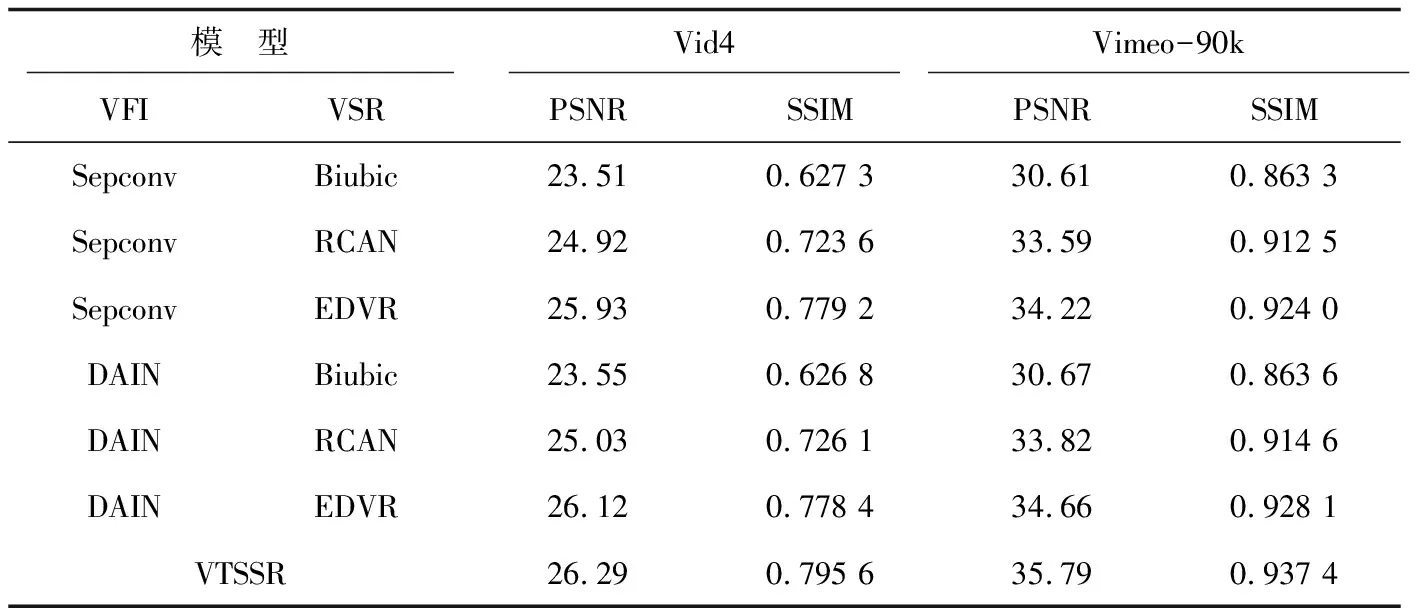
表2 模型客观指标对比(PSNR(DB)/SSIM)
3.3.2 主观对比
为了进一步对比重建效果,在Vimeo-90ktest数据集选取多个不同的视频片段的图像,对这些图像进行模型重建,并在主观视觉上对高分辨率图像、下采样低分辨率图像、SepConv+EDVR、DAIN+Bicubic、DAIN+RCAN与构建的模型VTSSR的重建结果进行评价对比;在Vid4数据集上将高分辨率图像、下采样低分辨率图像与构建的模型VTSSR的重建结果进行评价对比。对比结果如图8所示。

图8 Vimeo-90ktest和Vid4测试集主观视觉对比
图8中,选取了Vimeo-90ktest和Vid4数据集中各一个视频片段图像,通过对比可以看出VTSSR模型主观视觉优于其他模型重建的效果。
通过比较不同重建模型在相同测试集上的结果,提出的融合时间域和空间域的视频超分辨率重建模型VTSSR在量化指标和观察主观效果上都有一定的优势。
4 结束语
为提高视频分辨率,构建了一种融合时间域和空间域的视频超分辨率重建模型VTSSR,可以在同一个网络模型中同时对视频进行时间域和空间域超分辨率重建。该模型以低帧率的低分辨率视频作为输入,首先,使用卷积层和多个残差块进行特征提取,使用帧特征插值生成中间帧的特征图;其次,采用改进的基于自注意力机制模块,融合特征图时间和空间信息;最后,采用亚像素卷积上采样重建,输出高帧率的高分辨率视频。在Vimeo-90ktest和Vid4测试集上的测试表明,该模型能够克服光流预测难以处理遮挡、复杂运动的局限性、解决不同相邻帧对于关键帧重建贡献不同的问题。在Vimeo-90ktest测试集上其峰值信噪比为35.79 dB,结构相似性为0.937 4;在Vid4测试集上其峰值信噪比为26.29 dB,结构相似性为0.795 6,与其他重建模型相比均有提高。
