基于BERT的服务网站Web攻击检测研究
2022-08-23范禹辰刘相坤朱建生蒋秋华徐东平
范禹辰,刘相坤,朱建生,蒋秋华,李 琪,徐东平
(1.中国铁道科学研究院研究生部,北京 100081;2.中国铁道科学研究院集团有限公司电子计算技术研究所,北京 100081)
0 引 言
随着互联网技术的不断发展,web应用及网站正在给越来越多的人提供服务。提供大规模服务的同时意味着需要传输和保存大量的用户数据,而这会招致一些恶意攻击者对网站及web应用进行恶意攻击、渗透,以窃取用户数据或破坏系统正常运行。该文的服务网站作为在线售票服务提供网站,每年都会受到大量恶意攻击,其中SQLi攻击数量最多、XSS攻击其次,因此需要部署WAF来检测经CDN到内网服务器的http请求,过滤掉恶意的http请求。
基于上述背景,提出一种基于BERT[1]的web攻击检测方法,并选择攻击样本数量较多的SQLi和XSS跨站脚本攻击作为研究对象,通过对BERT改进使其支持长文本输入来实现对http头的全量检测。由于服务网站互联网出口流量较大,为了保证web服务的时延在可接受的范围内,采用参数量小的BERT-mini[2]预训练模型训练该任务,在保证检测准确率的同时,提高模型的检测速度。
1 相关研究
传统基于规则的WAF只能通过人工添加规则匹配已出现过的攻击类型,无法检测未知的攻击,且匹配规则大多基于正则引擎,添加大量规则会增加计算资源的消耗,降低检测效率。近年基于深度学习的web攻击检测的方向中,文献[3]基于抽象语法树及BP神经网络提出了一种语义分析与神经网络结合的WebShell检测方法;文献[4]提出了一种基于CNN的web攻击检测方法,将web流量转化为流量图像,并构建基于空间金字塔池化的卷积神经网络,将web攻击检测问题转化为图像分类问题进行分类;文献[5]提出了一种基于ResNet的web攻击检测方法,使用CSIC2010、FWAF、HttpParams三个公开数据集,将数据正则化后使用word2vec[6]和TF-IDF进行特征提取并分类;文献[7]使用CSIC2010数据集和WAF产生的数据,对url进行word embedding,并采用LSTM[8]和GRU[9]两种方式评估检测结果;文献[10]提出了一种Locate-Then-Detect的实时检测方法,对每个url使用payload检测定位网络提取多个候选区域,再将其送入基于隐式马尔可夫模型[11]的payload分类网络进行分类。Gong Xinyu等人[12]提出了一种基于字符级卷积网络[13]的web攻击检测方法,使用LSTM及多层感知机进行特征提取,并在CSIC数据集下验证效果。
目前大多基于深度学习的web攻击检测方法为了提高检测效率及降低样本的复杂度,都仅针对http get请求的url字段及其参数,而不对http头内的其余字段进行检测,这将会使所有存在于http头其余字段内的user-agent字段注入、cookie注入恶意攻击等无法被有效统计到,从而导致漏报或误报。基于深度学习的web攻击检测可以被看作一个NLP中的文本分类任务,而上述几种方法采用的模型并不是近年来在NLP任务上得分较好的模型,近年在NLP领域表现较好的模型有GPT[14]、ERNIE[15]、XLNet[16]、BERT等,该文基于预训练模型BERT-mini设计检测模型。
2 基于BERT+LSTM/Transformer的检测模型
本节将讨论http请求的预处理、检测模型的设计以及数据集的构建、选取。将长文本分片,送入BERT得到各片段的表征输出,设计了基于LSTM和Transformer[17]两种模型进行特征融合的方法并使用融合后的特征进行分类。
2.1 BERT简介
BERT对应的全称为Bidirectional Encoder Representations from Transformers,即基于Transformer的双向编码器表征,该模型由google AI研究院在2018年提出,曾刷新11个NLP任务的纪录,是近年用途最广泛的NLP模型之一。该文采用的BERT-mini模型由4个Transformer结构组成,每个Transformer包含6个Encoder,BERT网络模型结构和Transformer的结构如图1所示。

图1 BERT网络结构
BERT模型的训练分为预训练(pretraining)和微调(finetuning),预训练模型采用谷歌公布的BERT-mini,无需额外预训练,故该文仅考虑模型微调部分,对于文本分类任务,进行一次检测的流程如下:
(1)输入的原始数据的头部会增加一个[CLS]标志位,尾部添加一个[SEP]标志位,经embedding层计算每个分词的token embedding、segment embedding、position embedding。其中token embedding是每个单词映射到固定长度的一维向量表示,[CLS]的token embedding可以理解为一个不包含特定语义信息,并在模型训练过程中自动学习输入数据全局的语义信息的向量,用于特定的分类任务;segment embedding是在输入序列为句子对的情况下,用于区分两个句子的向量表示;position embedding是每个单词的位置信息,用于解决token embedding无法编码输入序列位置信息的问题,即给不同位置的相同单词赋予不同的语义。将这三种embedding结合作为Transformer Encoder层的输入。
(2)如图2所示,将embeddings作为Encoder的输入,送入multi-head attention层,通过线性变换矩阵Wq、Wk、Wv计算输入的查询向量q(queries)、键值向量k(keys)、值向量v(values)的值,并根据这三个向量进一步计算得到attention向量。接下来对Attention向量与Transformer的输入进行残差连接,并进行层归一化,将归一化得到的结果送入由两个全连接层构成的前馈神经网络,将其输出与attention向量残差连接并再进行一次层归一化,得到Encoder的输出,共经过6个Encoder后得到最终的Encoder层输出。

图2 Encoder内部结构
(3)对于文本分类任务,不需要Decoder层的参与,故最后一层Encoder的输出即是Transformer的最终输出,输出[CLS]标志位对应的向量用于文本分类。
BERT所采用的Transformer结构综合了RNN和CNN的优点,同时拥有捕获长距离特征及并行计算的能力,且在语义特征提取方面Transformer的效果远超RNN和CNN,使其在运算速度较快的同时拥有较高的检测精度。
2.2 预处理
部分攻击载荷会隐藏在url编码或base64编码中,如请求片段“c2VsZWN0IChleHRyYWN0dm FsdWUoMSxjb25jYXQoMHg3ZSxkYXRhYmFzZSgpKSkpO w==”,经base64解码后为“select (extractvalue(1,concat(0x7e,database())));”。故第一步先对每条http请求尝试进行url解码及base64解码。
大部分http请求长度都超过了BERT的最大输入限制512,因此采用滑动窗口的思想对http请求进行切片,若一个片段内不存在攻击载荷,则将其划为正样本,反之划为负样本。若攻击载荷被分到了两个不同的片段中,则重新对该http请求进行分割,保证攻击载荷在一个片段中。
BERT的Basic Tokenizer和Wordpiece Tokenizer会对http请求进行进一步处理。Basic Tokenizer首先对http请求片段进行unicode编码,去除多余的空格、乱码及非法字符,然后根据空格进行一遍分词,最后替换变音字符并根据标点进行分词;Wordpiece Tokenize在Basic Tokenizer的分词基础上,将单词分割为多个子词,并得到分词结果,即BERT的原始输入。
2.3 模型设计
考虑http请求实际长度和服务网站的流量强度,针对实时检测需求,提出两种对流量进行检测的方法,用于降低服务网站受到恶意攻击的风险。
2.3.1 基于BERT+LSTM的检测方法
该方法基于BERT模型的表征输出,在下游设计检测模型,如图3所示,在将http请求分片时,增加index标志位记录其原本属于的http请求,送入BERT后得到其表征输出,将属于同一http请求的表征输出放到一起送入LSTM网络得到融合结果,再经过全连接层及softmax分类器得到最终的分类结果。

图3 基于LSTM的后续检测网络结构
Web攻击检测是一个多分类任务,故LSTM的损失函数选择交叉熵损失函数,并使用Adam优化器进行优化,交叉熵损失函数公式如下:
(1)
其中,N为样本总数,k为标签类别总数,pxk为样本x的实际类别,qxk为模型计算得到的样本x属于类别k的概率。
2.3.2 基于BERT+Transformer的检测方法
该方法同样在BERT模型后增加一个额外的Transformer,利用Transformer的Encoder层来融合BERT的表征输出,但融合方式与LSTM不同,对于一条完整的长http请求,将分片后的送入BERT得到的表征输出,令第i个片段的表征输出为CLSi,把所有的表征输出连接到一起,并在头部增加额外的[CLS]标志位,得到Transformer的输入为:
c=([CLS],CLS1,CLS2,…,CLSn)
(2)
输入c经Transformer得到输出后,经一层全连接层及softmax分类器得到最终分类结果。整个检测网络结构如图4所示。
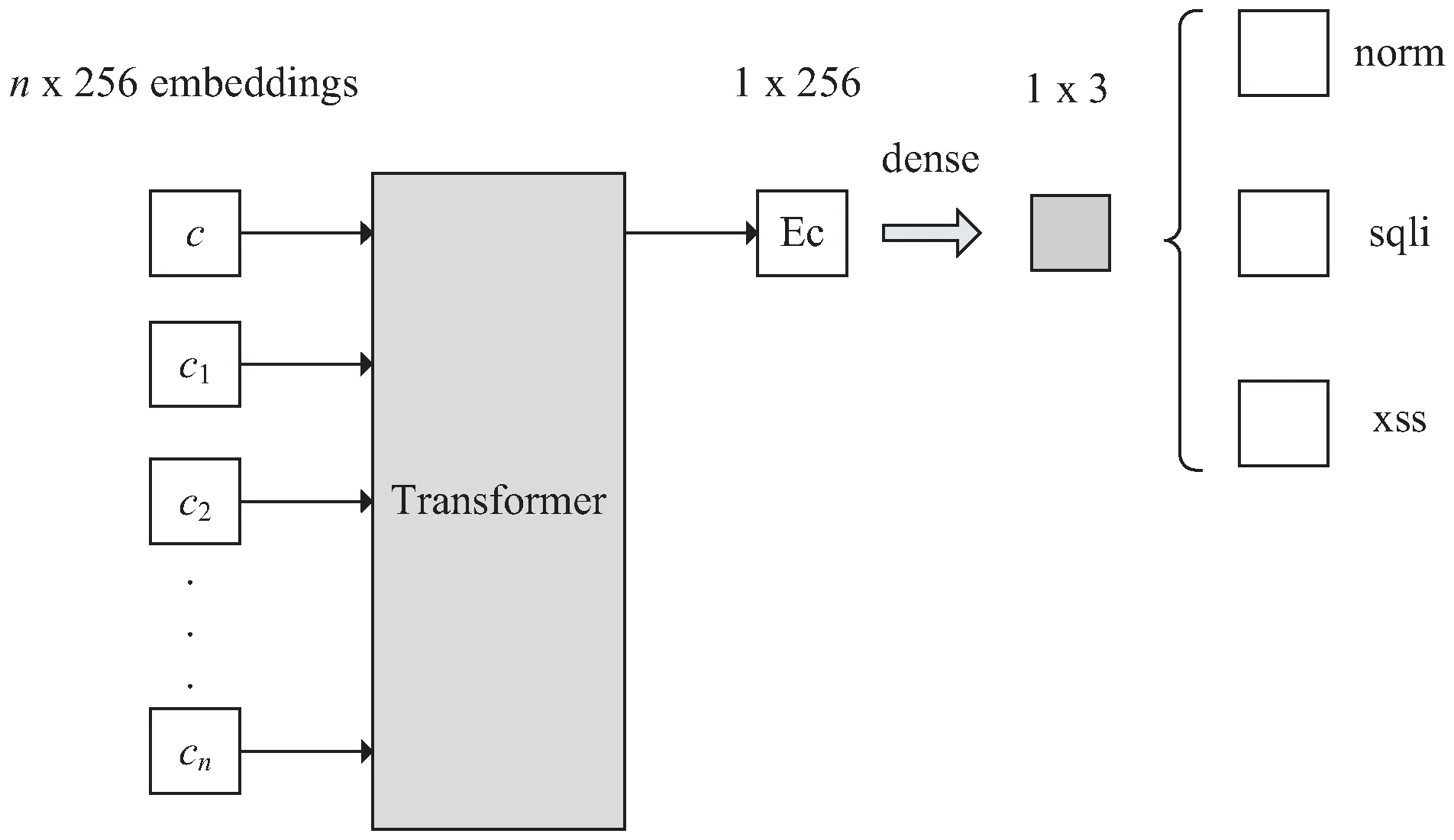
图4 基于Transformer的后续网络结构
3 实验及结果分析
3.1 数据集
选取公共数据集和服务网站真实数据集来训练并验证模型效果。公共数据集使用 CSIC 2010,网站真实数据集的正常流量部分由互联网出口核心交换机镜像导出,异常流量部分从旁路部署的攻击溯源系统中提取。
3.1.1 公开数据集
大多用于web攻击检测的公开数据集仅提供url或攻击载荷的关键词,不符合对http请求全量检测的需求,因此该文选取的公开数据集为CSIC 2010,该数据集是西班牙高等科研理事会于2010年公布的由正常和异常web流量组成的数据集,并被广泛用于web攻击检测的研究。
其中每条数据都是完整的http请求,且POST请求包含请求体。标签分为正常和异常流量两类,异常流量中包括SQLi、目录遍历、XSS跨站脚本、CRLF注入等多种攻击类型。该文选用CSIC2010数据集中的正常流量以及属于SQLi和XSS跨站脚本的异常流量,对异常流量样本重新标注,来验证设计模型的泛化能力。
3.1.2 服务网站真实数据集
服务网站真实数据集最初收集了100万条正常请求,6万条异常请求作为全部样本,经测试发现无法有效检测异常请求,后经调整各类别样本所占比例进行测试,最终确定网站真实数据集共128 756条数据,其中,NORM类65 933条,SQLi类46 824条,XSS类15 999条。
3.2 评价指标与参数设置
该文使用上述数据集对所设计方法进行测试,为了关注检测的准确性以及误报率、漏报率,模型的评估指标选用Accuracy、TPR、TNR。各评估指标计算方式如下:
(3)
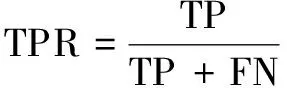
(4)
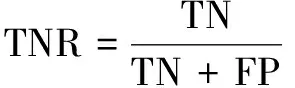
(5)
其中,TP表示正确分类的正样本,TN表示正确分类的负样本,FP表示错误分类的正样本,FN表示错误分类的负样本。Accuracy反映了模型识别的准确率;TPR也被称作Recall,代表所有正样本中被正确预测的比例,可以反映出模型检测时的误报率;TNR代表所有负样本中被正确预测的比例,可以反映出模型检测时的漏报率。基于上述三种指标,可以对模型的检测能力进行较为全面的评估。
经多次实验,选取实验结果最佳一次的参数,给出实验参数如下:Epoch=3,Learning Rate=1e-4,Dropout=0.1,Batchsize=16,滑动窗口大小=400。
3.3 性能分析
基于该文所设计的两种模型,不使用CSIC2010数据集作为训练集,仅作为测试集,使用服务网站真实数据集中的70%当作训练集,验证集和测试集各占15%。选取实验结果最佳的参数,使用训练集在网络模型上训练3个epoch后,用CSIC2010数据集以及服务网站真实数据集中的测试集部分,分别对训练好的模型进行测试,测试完成得到模型的评估指标如表1、表2所示。

表1 使用BERT+LSTM模型的实验结果

表2 使用BERT+Transformer模型的实验结果
根据实验结果可以看出,使用Transformer的检测模型融合特征的效果比LSTM要好,且泛化能力更强,使用Transformer模型检测得到的几种评估指标均高于使用LSTM的模型。基于实验结果分析性能差异的原因,Transformer与LSTM相比,能够更有效地提取语义信息,但在长距离依赖捕获方面不如属于RNN类结构的LSTM,在web攻击检测的具体任务下,由于大部分攻击载荷长度不会太高,所以LSTM的优势体现的不明显,而Transformer能够更有效地提取出含有攻击特征的语义,故在文中环境下,BERT+Transformer检测模型的表现要优于BERT+LSTM模型。
3.4 对比实验及结果分析
为了评估模型的检测能力与检测效率,选用原生BERT模型及XLNet模型与文中所设计模型进行对比,比较模型的Accuracy指标以及检测时间,由于BERT不支持长度超过512位的输入,使用http请求的切片对模型进行评估,每个切片对应一个标签。XLNet为2019年提出的预训练模型,与BERT相比,引入了自编码语言模型,并使用更多的数据对模型进行预训练,在多项NLP任务中得分超过BERT,参数量为BERT-mini的十倍以上。
使用服务网站真实数据集的训练集对XLNet训练3个epoch,训练完成后使用服务网站测试集对XLNet进行测试,得到的实验结果与文中模型的对比如表3所示。
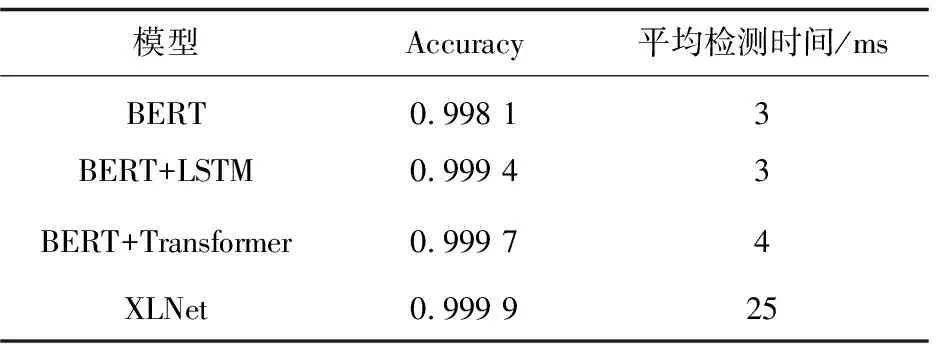
表3 对照实验
基于实验结果分析模型性能差异的原因,该文设计的两种检测模型融合属于同一http请求的切片的表征输出,对http请求进行全量检测,与不支持长度超过512位输入的原生BERT相比,能更有效地提取语义信息并捕获更长距离的特征,故在检测准确率方面高于原生BERT;由于XLNet本身支持超长文本的输入,预训练时使用的语料库比BERT更加庞大,且模型的参数量远大于该文所选用的BERT,故检测准确率比文中设计模型更高一些。而模型的参数量越大,进行一次运算所消耗的计算资源也越高,检测时间也就越长,该文用到的BERT模型以及设计的检测模型参数量差距不大,处于同一数量级,均在1 000万左右,而XLNet的参数量在1亿左右,故检测时间方面,XLNet的平均检测时间远高于表3中的其余三种模型。
XLNet的准确率虽高,但因为模型参数量巨大,平均检测时间达到了25 ms,是BERT+Transformer模型平均检测时间的6倍以上,对于流量强度较大的服务网站,过高的检测时间会对业务造成一定影响,故综合准确率及平均检测时间,BERT+Transformer是更加适合业务场景的检测模型。
3.5 超参数对模型影响分析
基于BERT+LSTM检测模型研究不同大小的滑动窗口对检测结果的影响,分别选取滑动窗口大小为100、200、300、400、500时训练模型并测试检测效果,实验结果如表4所示。

表4 不同大小的滑动窗口下模型的检测结果
根据实验结果,随滑动窗口不断增大模型的准确率略微降低,但是滑动窗口过小时会严重降低模型的检测效率,滑动窗口大小在300到500之间时,对检测模型是一个比较合适的范围。
为了方便日后数据集及模型的更新,研究学习率及Epoch次数对模型准确率的影响,在学习率为1e-4的条件下,分别选取epoch=1,2,3,4,5时的模型,使用服务网站数据集的测试集部分进行测试。并在epoch=3,4,5的条件下,分别测试学习率为1e-4、1e-5、1e-6检测模型的准确率。
图5(a)给出了Epoch与准确率之间关系的实验结果。根据实验结果,Epoch=3时,两种模型均达到了最佳检测效果,说明较大的学习率下,模型的收敛速度很快,当数据集更新时,可以较快训练出新的检测模型。图5的(b)、(c)、(d)给出了不同Epoch次数下学
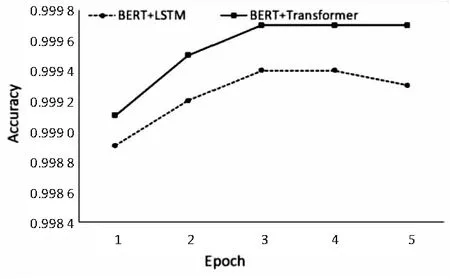
(a)Learning Rate=1e-4
习率与准确率之间关系的实验结果,可以得到学习率为1e-4时模型能够在最小的Epoch次数中获得最佳的检测效果。
4 结束语
该文提出了一种基于BERT的web攻击检测方法,基于轻量级预训练模型BERT-mini,通过改进其网络结构,设计了两种不同的表征输出融合方法,使其支持长文本的检测,来对http请求进行全量检测,识别url及其余字段的恶意攻击载荷。其中BERT+Transformer模型在服务网站真实数据集下的检测准确率达到了99.97%,平均检测时间4 ms,基本实现了在保证模型检测准确率的同时,保证模型的检测效率;在CSIC2010数据集下的检测准确率达到了95.83%,说明了模型具有一定的泛化能力,但基于各网站业务及提供服务的差异性,数据集之间的流量特征不全部相同,无法通过一个数据集训练出的模型正确识别全部的http请求。
后续研究方向致力于研究web攻击检测与http请求语义之间的关系以及更多的攻击类型分类,使模型能够学习正常http请求以及恶意攻击的语义特征,理解http请求,实现基于语义来识别web攻击检测的模型,能够分辨出同一特征在不同应用场景、排列顺序下的不同语义,进一步提高模型的检测能力、泛化能力,以实现一个基于深度学习的语义级WAF。
