基于YOLO v3的落水人员检测
2022-08-23许晓峰陈姚节
许晓峰,陈姚节,2,刘 恒
(1.武汉科技大学 计算机科学与技术学院,湖北 武汉 430065;2.智能信息处理与实时工业系统湖北省重点实验室,湖北 武汉 430065)
0 引 言
国内公园人工湖、河流、湖泊、水库以及海洋水域面积巨大,难以对所有水域实现全时全面的监管检测,而且由于安全措施不到位、监控存在盲区和死角等等原因,导致溺水死亡事故频繁发生。据报道,全国每年有超过5.7万人死于溺水,而放到全球,有超过37万人因溺水而死。人员落水以后进行救援的黄金时间只有5分钟,而落水事件事发突然,依靠人力往往不能在第一时间发现落水人员,造成了大量落水人员的伤亡。为了避免悲剧的发生,有些场景中已实现了水域状态的全天候监控,但是仍然需要有人对监控画面进行看守,这样做不仅费时费力,而且充满了不确定性,无法保证对落水人员的检测,故对落水人员的实时自动监测变得尤为重要。
近年来,基于深度学习的目标检测[1]算法在检测效果方面突飞猛进,同传统方法相比检测性能取得了质的飞跃。目前主要分为两种:一种是两阶段目标检测算法[2],如:R-CNN[3]、Fast R-CNN[4]、Faster R-CNN[5]、Mask R-CNN[6]、R-FCN[7]等,两阶段目标检测算法将整个检测过程分为两个阶段,第一个阶段是先生成候选目标框,第二个阶段是进行分类和回归,两阶段目标检测算法的精度相对较高,但速度较单阶段检测算法慢了很多。另一种是以YOLO系列[8-11]、SSD[12]为代表的直接回归物体的类别概率和空间位置坐标的单阶段目标检测算法,单次检测就能得到最终检测结果,检测速度较双阶段目标检测更快,很好地满足了实时检测的要求。但SSD会随着图片规格的增加使得运行效率显著下降,因此YOLO系列应用更加广泛。
1 YOLO v3目标检测
1.1 YOLO v3模型
YOLO v3是Joseph Redmon,Ali Farhadi[10]在YOLO v2算法的基础上,用Darknet-53替换Darknet-19作为backbone,借鉴了Resnet[13]残差结构、金字塔特征图[14]等方法提出的单阶段目标检测算法。YOLO v3模型主要包括基础网络部分和检测部分,基础网络部分是使用Darknet-53作为整个网络的backbone部分来进行特征提取,Darknet-53特征提取网络没有池化层和全连接层,特征图的缩小是通过增加卷积核的步长实现的;为了有效解决深层次网络的梯度问题,Darknet-53采用了残差的思想,在网络中加入了残差模块;检测部分借鉴了特征金字塔的思想,通过三个分支来对不同尺度的目标进行检测。
YOLO v3的网络结构如图1所示,其采用尺寸为416×416×3 的图像作为输入,利用Darknet-53网络提取图像特征,得到3个尺度分别为52×52、26×26、13×13的特征图,越小的特征图代表下采样的倍数高,而感受野也大,所以13×13的y1特征图对应检测大物体,26×26的y2特征图对应检测中物体,52×52的y3特征图对应检测小物体。
1.2 YOLO v3检测原理
YOLO v3把图片划分为13×13,26×26和52×52的网格,每个网格都会预测3个边界框,所以总共有(52×52+26×26+13×13)×3=10 647个预测。每个边界框输出特征图的通道数包括位置信息、置信度、类别预测,所以输出张量的维度为N×N×3×(4+1+M),1表示置信度,4表示目标位置输出,M表示类别数目。
使用k-means[15]聚类方法对数据集聚类,得到9个不同尺寸的框,作为先验框,接着就可以解码检测框。以图2为例,虚线框表示先验框,其宽高分别为pw和ph,(cx,cy)为偏移量,(tx,ty,tw,th)为网络输出值,其中(tx,ty)表示该点所在框的左上角点到目标中心点的距离大小,(tw,th)为直接预测的宽和高,实线框表示中间网格输出的值经过运算后得到的最终预测框,其预测框位置信息为(bx,by,bw,bh),计算公式为:
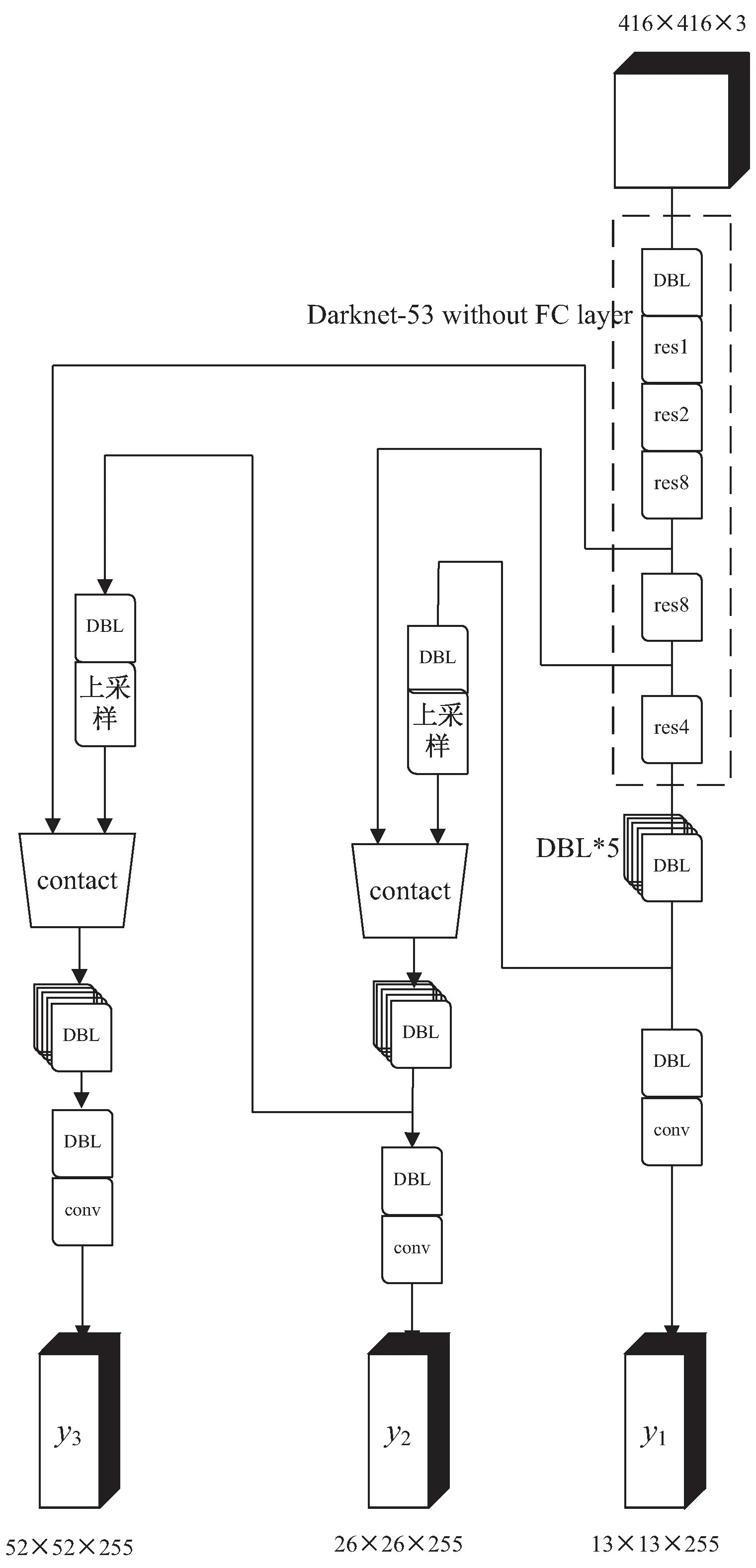
图1 YOLO v3网络结构
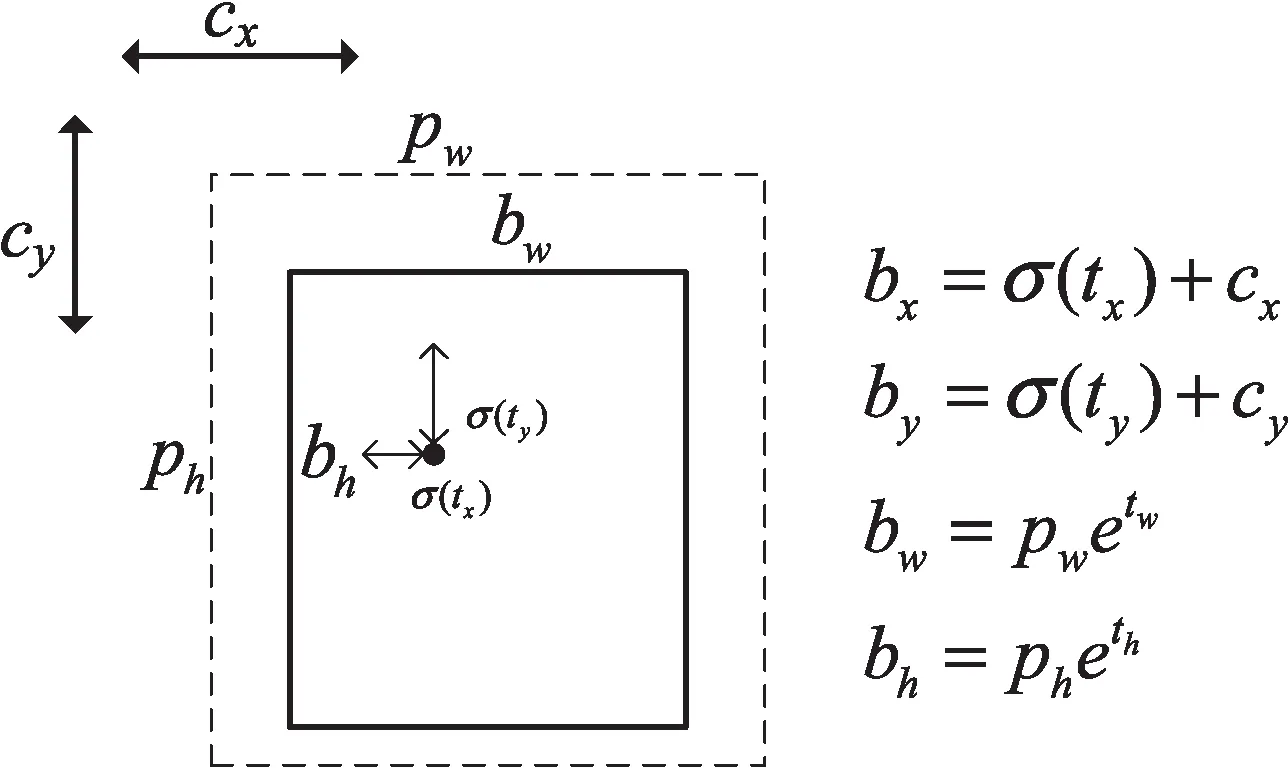
图2 YOLO v3检测原理框图
bx=σ(tx)+cx
(1)
by=σ(ty)+cy
(2)
bw=pwetw
(3)
bh=pheth
(4)
其中,(bx,by)为最终预测框的中心点的横纵坐标,(bw,bh)为最终预测框的宽高,σ为sigmod激活函数,使tx和ty为输出0-1之间的偏移量。
通过阈值[16]设定,过滤掉得分较低的预测框,对剩下的进行非极大值抑制(non maximum suppression)[17]处理得到最终预测结果。
2 算法改进
在目标检测任务中,合适的锚点框Anchor Box能够提高检测任务的精度和速度,原始YOLO v3采用k-means算法对coco数据集聚类得到锚点框的尺寸,该文通过对自有落水人员数据集利用k-means++聚类算法对Anchor重新聚类,获得更符合落水者的Anchor框。
通道注意力机制是根据各个特征通道的重要性的不同分配不同的权重,然后让网络根据权重的不同,更加关注权重比较大的特征通道,这样网络就可以加强包含有用信息的特征并抑制无用特征,使得目标更好地被检测出来。
YOLO v3虽然通过特征融合输出三个尺度的特征图,提高了小目标检测能力,但是对于以小目标检测为主的目标检测任务,YOLO v3的检测精度仍然有待提升;RFB利用拥有不同尺寸卷积核的卷积层构成多分支结构,再引入空洞卷积增加感受野,提高了小目标检测精度。
2.1 基于数据集的k-means++聚类改进
在YOLO v3中,为高效地预测不同尺度与宽高比的物体边界框,采用锚点框Anchor机制,合适的Anchor值可以实现更快速、准确的定位,同时减少损失值与计算量,提高检测速度与精度。YOLO v3原始的Anchor值是在coco数据集利用k-means算法聚类而得,每个特征图对应的特征点采用3个不同比例(1∶2,1∶1,2∶1)的Anchor框,考虑到原YOLO v3有三个不同尺度的特征图,故聚类9个不同尺度的Anchor框来预测大小不同的目标。
该文沿用YOLO v3中的Anchor思想,提出的改进YOLO v3通过三个不同尺度大小的特征图来进行预测,按照每一个特征点需要聚类3个不同比例的Anchor框的原则,利用k-means++聚类算法对落水人员数据集聚类9个不同尺度的Anchor。原始的k-means聚类算法随机选取k个数据点作为原始的聚类质心,这种聚类方法对初值敏感,不利于寻找全局最优解,因此该文采用k-means++算法对原算法进行优化,k-means++能显著地改善分类结果的最终误差。k-means++聚类算法与k-means聚类算法的不同之处在于,后者在初始选取质心时,是随机选取的聚类中心,而前者不是,其遵循在聚类中心选取时,让各中心的间距尽量远的原则。k-means++聚类算法的步骤如下:
步骤一:随机选取一个点作为第一个聚类中心;
步骤二:计算每一个点与当前已有聚类中心的最短距离(即与最近一个聚类中心的距离),这个值越大,表示其被选取作为聚类中心的概率值越大,采用轮盘赌法依据概率大小进行抽选,选出下一个聚类中心;
步骤三:重复步骤二,直到选出k个聚类中心;
步骤四:选出聚类中心后,继续使用k-means 算法进行聚类。
该文使用上述聚类方法,对自有落水人员数据集进行聚类,得到的9个不同尺寸的Anchor Box框的宽高分别为:(7,15)、(10,23)、(12,34)、(13,19)、(15,27)、(18,36)、(20,26)、(29,47)、(54,88)。为了验证基于数据集的k-means++聚类算法能提高对落水人员的检测效果,同时对原始YOLO v3与只改进了基于落水人员数据集的聚类算法的YOLO v3的检测结果进行对比,如表1所示。可以看出,使用了基于落水人员数据集的k-means++聚类算法的YOLO v3对目标的检测效果有明显的提升。

表1 只改进聚类的YOLO v3与原始YOLO v3对比
2.2 SE_Block
因为目标被遮挡、环境复杂或者天气环境等因素,输入的特征图在神经网络中语义信息不丰富导致目标不能被很好地识别检测出来。所以在改进YOLO v3中加入通道注意力机制模块SE_Block(Squeeze-and-Excitation),其关注通道信息,可以自动学习到不同通道特征的重要程度,然后分配相应权重,有效解决各个通道的不同重要性所带来的损失问题,提高对于重要特征的表征能力。
SE_Block通过对各个特征通道的重要性的不同分配不同的权重,然后让网络根据权重的不同,更加关注权重比较大的特征通道,让其占的比重更大,从而进行参数的更新。首先对输入的特征图进行全局平均池化,全局平均池化不同于平均池化和最大池化,通常用来聚集空间信息,它是对特征图全局平均后输出一个值,使其具有全局感受野,让浅层网络也可以利用全局信息,然后再连接两个全连接层,进行降维再升维操作,增加更多的非线性处理过程,拟合通道之间复杂的相关性。
在原始YOLO v3的网络中含有很多的残差连接,所以在残差块中加入SE_Block,其主要分为两个部分:挤压操作和激活操作。挤压操作Fsq,就是将长度H、宽度W、通道数C的H×W×C输入特征图转换为1×1×C的输出,具体操作如下式:
(5)
激活操作就是在得到挤压操作的1×1×C的表示后,学习各通道的依赖程度,并根据依赖程度对不同的特征图进行调整,得到最后的输出,公式如下:
s=Sigmoid(FC2×ReLU(FC1×Zc))
(6)
式中,FC1×Zc是一个全连接操作,进行降维处理,再经过一个ReLU进行非线性操作,输出维度不变,然后再进行一个全连接操作进行升维,最后使用一个sigmoid函数激活,得到输出s,s是特征图的权重。用对应的权重来激活每一层通道,即用不同通道的值乘上对应权重,从而提高重要特征的表征能力,尺度函数为:
(7)
相对之前的YOLO v3,由于引入了注意力机制,增加了两个全连接层和一个全局平均池化以及特征加权,大大增加了算法的计算量,在速度上会比原YOLO v3低。其算法流程如图3所示。
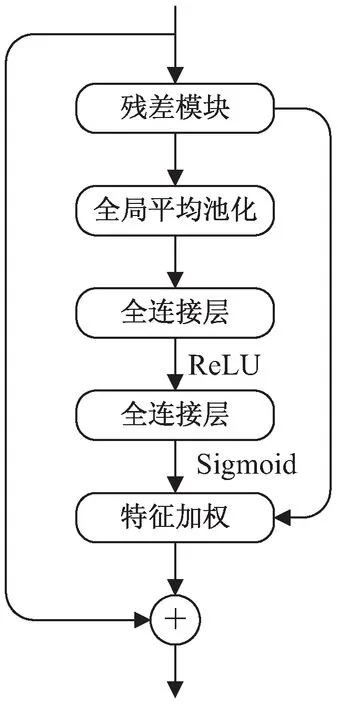
图3 SE模块流程
为了验证改进后加入SE_Block的有效性,同时对原始YOLO v3与只加入通道注意力机制模块的改进YOLO v3在落水人员数据集上进行落水人员的目标检测,结果表明,加入通道注意力机制模块的YOLO v3在落水人员数据集上进行检测的AP和F1 score有明显的提高,检测对比结果如表2所示。
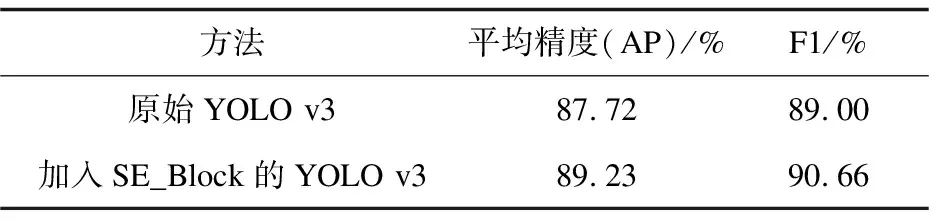
表2 原始YOLO v3与只加入SE_Block的YOLO v3的对比
2.3 感受野模块
在卷积神经网络中,浅层特征分辨率高,细节信息比较丰富,对检测图像小目标有很大的帮助,但感受野小无法包含足够的上下文信息。为了增大特征图的感受野,在YOLO v3中引入RFB模块。RFB是模仿了人类的视觉系统,通过模拟RF的大小和偏心率之间的关系,来增强特征的可辨性和模型的鲁棒性。RFB的结构主要包括两个部分:多分支结构和空洞卷积层。
不同尺寸卷积核的卷积层构成了多分支结构,卷积核分别为1×1、3×3和5×5,这些不同的卷积核模拟大小不同的群体感受野,然后分别在卷积层之后加入对应间隔跨度的空洞卷积,间隔跨度分别为1、3、5,构成了空洞卷积层,这些空洞卷积用来模拟群体感受野的大小和偏心率之间的关系。再将三个分支的输出连接在一起,达到融合不同特征的目的,从而增大感受野,增加特征提取的能力。
该文在52×52×255的特征图前的浅层特征后连接RFB-s模块来加强网络的特征提取功能,然后再与深层特征进行融合,最后输出52×52的特征图。RFB-s的RFB不同之处在于:一是RFB使用5×5的卷积层,而RFB-s对应的是使用3×3的卷积层;另一处是RFB使用的是3×3的卷积,而RFB-s对应使用的是1×3和3×1卷积,RFB-s使用更多具有较小核的分支,减少了计算量,两种感受野模块的结构如图4所示。
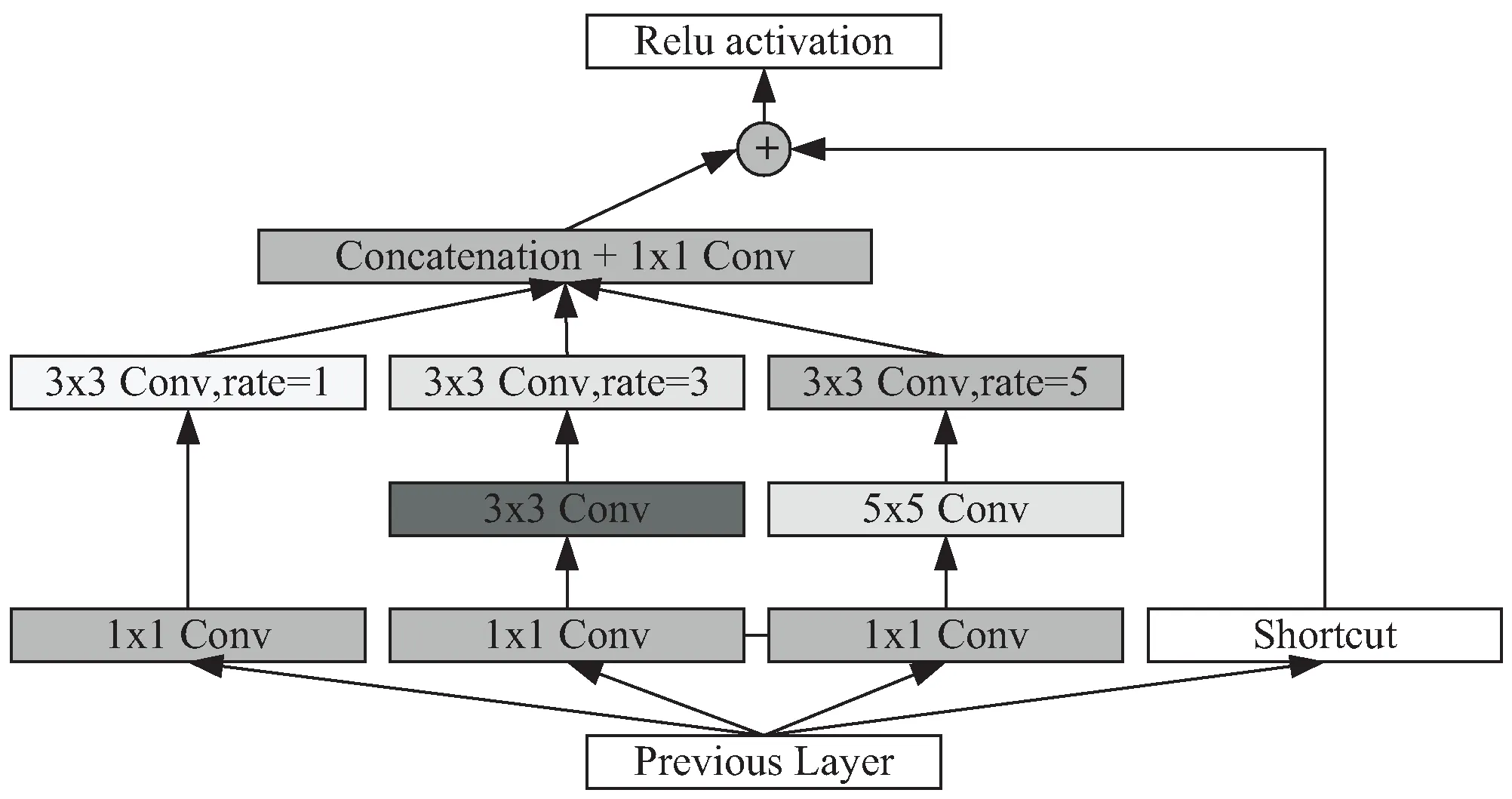
(a)RFB结构
为了验证改进后,在小目标检测分支加入RFB-s模块的有效性,同时对加入了RFB-s模块的改进YOLO v3与原始YOLO v3在落水人员数据集上进行落水人员的目标检测,结果对比如表3。结果表明,加入RFB-s模块的YOLO v3在落水人员数据集上进行目标检测时,平均精度AP提升了2.27%,F1提高了2.56%。因此,加入RFB-s模块可以提高检测落水人员的检测精度。

表3 只加入RFB-s模块的YOLO v3与原始YOLO v3检测结果对比
3 实验结果及分析
3.1 实验条件
模型的训练与测试都在同一设备进行,实验设备配置为:操作系统为Windows 10,CPU为Intel® i3-8100,GPU为NVIDIA GTX 1660 SUPER,内存为16 GB,开发环境为Python 3.8、Pytorch 1.5、Cuda 10.1、Cudnn 7.6。
使用Adam优化器对网络进行优化,使用固定步长衰减进行学习率的调整,实验中的学习率设为0.001,step_size取为2,gamma取0.95,批处理大小设为16,衰减系数设为0.000 5,动量设为0.9。
3.2 实验数据集
实验使用的数据集是一个包含1 014张落水人员的小规模图像数据集,其中图像包括单人落水以及多人落水情况。数据是在长江边以及湖边拍摄所得,将不同场景下的拍摄所得视频提取单帧图像作为数据集,通过YOLO系列算法常用的数据集标注工具LabelImg手工标注图像中目标的矩形框坐标以及标签值,并生成相对应的xml配置文件。为保证训练的数据尽可能多以及测试集的普遍性,将数据集按9∶1的比例划分为训练集与测试集。
3.3 模型评估指标
采用的模型评估指标主要包括:调和均值和平均精确度。平均精确度与调和均值是同时考虑精确率和召回率的量化指标,它们的数值越大,识别效果越好。
(1)平均精确度AP衡量的是学出来的模型在每个类别上的好坏。理想的检测网络的精确率和召回率应当都保持在较高的水平,但实际上随着阈值变化两个值并不都是正相关变化的,召回率与精确率呈现负相关变化,所以通常采取的方法是将精确率和召回率所形成的PR(Precision-Recall)所围成的最大面积作为最优解,而围成的面积使用AP来衡量。AP的计算公式为:

(8)
其中精确率和召回率的计算公式如下:
(9)
(10)
(2)调和均值F1,能同时兼顾模型的精确率和召回率,取值在0~1之间,F1越大,模型效果越好。F1的计算公式为:
(11)
3.4 实验结果
将改进的YOLO v3算法在自由落水人员的数据集上进行目标检测任务的训练与测试,得到该模型的评估指标,评估指标结果如图5所示。

(a)改进YOLO v3的AP
同时对原始YOLO V3与改进的YOLO v3算法均在自由落水人员数据集上进行训练与测试,然后进行对比,图6为检测效果对比情况。从效果图来看,改进的YOLO v3将全部目标都检测出来,而原始YOLO v3有一个目标没有检测出来,并且存在误检的情况。

图6 检测效果对比
实验结果表明,改进的YOLO v3算法在落水人员检测任务中相较于原始YOLO v3,平均精确度提高了3.83%,F1提高了3.66%。从检测结果来看,改进的YOLO v3在检测准确率上有了较大的提升,对小目标的漏检率也有所下降,性能要强于原算法。改进的YOLO v3与原始YOLO v3对比如表4所示。
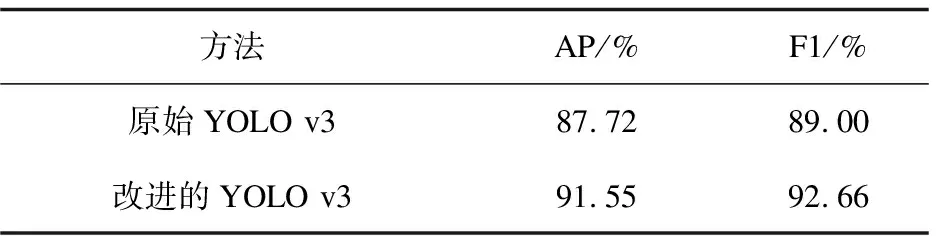
表4 改进YOLO v3与原始YOLO v3的对比
4 结束语
通过对YOLO v3算法进行改进,使其更适合完成对落水人员的检测任务。以原始YOLO v3为基础,通过k-means++算法聚类初始候选框的大小,提升候选框的精度,加入RFB模块加强网络的特征提取能力,将SE注意力模块嵌入原始的网络中,提高网络对有用特征的敏感度。实验表明,文中算法提高了检测的准确率,检测精度更高,具有一定的优越性。
