基于高光谱成像技术的烟叶田间成熟度判别模型
2022-08-22汤卫荣张永辉吴润生陈相君曾淑华
李 鑫,汤卫荣,张永辉,谢 强,张 凡,吴润生,陈相君,夏 春,曾淑华,刘 雷*
1. 四川农业大学农学院,成都市温江区惠民路211号 6111302. 四川省烟草公司泸州市公司,四川省泸州市龙马潭区南光路374号 646600
烟叶田间成熟度是指烟叶的生长发育达到的成熟状态满足后续加工环节对原料要求的程度,适宜的田间成熟度是保证烤后烟叶品质的前提[1]。目前,生产中通常采用基于鲜烟叶外观特征的人工判别方法判断烟叶田间成熟度,但该方法难以量化且受主观因素影响,易导致采收时烟叶成熟度控制不当,严重影响了烟叶品质[2-3]。烟叶叶绿素含量[4]、SPAD值[5-6]、丙二醛、过氧化物酶和其他一些生理生化指标[7-8]等量化信息可作为判别烟叶田间成熟度的客观依据,然而烟叶生理指标的测定多费时费力,难以在生产中推广应用,因此仍需探索更加客观、准确、快速且易行的判别方法。
高光谱成像技术通过采集被测物体的电磁光谱反射信号获取研究对象的特征信息[9],具有测定快速、对样品无损伤、数据信息量大、分辨精度高等优点[10]。研究表明,烟叶光谱信息可反映其颜色、色素含量、叶片组织结构、叶片生理指标等烟叶田间成熟特征[8]。王建伟等[11]分析不同成熟度烟叶光谱反射率、位置变量、面积变量和植被指数变量等光谱参数,明确了不同田间成熟度烟叶的高光谱特征差异;刁航等[12]用可见光范围内的连续光谱、特征波段和光谱特征参数建立了烟叶田间成熟度判别模型;李佛琳等[13]发现不同成熟度鲜烟叶的反射光谱在503~651 nm间差异显著。然而,烟叶田间成熟度判别模型构建的研究目前还鲜见报道。为此,比较了不同光谱数据预处理方法和机器学习算法在构建烟叶田间成熟度判别模型中的适用性,并采用遗传算法优选出对烟叶田间成熟度响应最灵敏的特征光谱波段作为建模输入变量,以期构建基于高光谱信息的烟叶田间成熟度判别模型,客观且准确判断烟叶田间成熟度,为烤烟智能采收方法的建立提供参考。
1 材料与方法
1.1 试验材料
试验于2020年在四川省泸州市古蔺县大寨乡进行,试验地为黑色砂壤土,土壤肥力中等,供试品种为中川208,按优质烤烟栽培规范进行田间管理。自烤烟移栽后100 d 开始,每隔3 d 取1 次样,于早上8∶00对烟株中部叶(从下往上第10~12叶位)进行随机取样,直到过熟叶片采集完毕。由烟站技术人员参照当地生产实践经验和相关文献[2-3]制定鲜烟叶田间成熟度档次划分依据(表1)。

表1 鲜烟叶田间成熟度档次划分依据Tab.1 Basis of field maturity classification for fresh tobacco leaves
1.2 光谱信息采集
将评定田间成熟度档次后的烟叶带回室内,使用Pika XC2成像仪(美国Resonon公司)采集其光谱信息,采集软件为Spectronon Pro,选用波长范围为400~1000 nm,光谱分辨率为1.3 nm,光谱通道数为448个。由于烟叶过宽,成像仪载物台无法承载完整的烟叶样本,故选取烟叶中段作为样本扫描区域(图1)。每片烟叶扫描1 次,使用Spectronon Pro 软件中ROI(Region of interest)工具计算叶片的反射光谱平均值作为该样本的光谱数据。

图1 烟叶光谱信息采集Fig.1 Information collection of tobacco leaf spectra
信息采集前调节焦距至图像最清晰,随后进行标准白板和暗电流校正[14]。使用均匀白板进行白板数据的测量,获得白板数据(W)之后将黑色盖帽盖在摄像头上,保证没有光源透入,获得暗电流数据(B)。按公式(1)进行校正:

式中:I是校正后的图像数据;I0是样本的原始图像数据;B是全黑环境下的标定图像数据(反射率接近0);W是标准白板图像数据。
试验采集M1、M2、M3 和M4 档次的烟叶样品各80 个,共计320 个样本的高光谱数据。分别从各成熟度档次的烟叶样本群体中随机选取总样本的3/4 作为训练集(共240 个样本),余下1/4 为测试集(共80 个样本,其中生青样本、尚熟样本、适熟样本和过熟样本各20个)。
1.3 光谱数据预处理
应用MATLAB软件,分别采用一阶导数(1stD)、多元散射校正(MSC)、标准正态变量变换(SNV)、Savitzky-Golay(SG)卷积平滑、一阶导数+SG平滑对烟叶原始高光谱数据进行预处理,去除无关信息(如电噪音、样品背景和杂散光等),提高分辨率和灵敏度,提升模型的精确度与稳定性[15-16]。
1.4 特征变量筛选
预处理后的全波长光谱数据共有448个变量,其中包含较多冗余信息,影响算法学习性能及模型的精确度[17]。因此,将这448 个变量分割成为45 个区间,第1到44区间每个区间内包含10个光谱变量,第45 区间内包含剩余的8 个变量。使用遗传算法[18](GA)对45个光谱波段区间进行优选,设置初始种群个数为20,迭代进化次数为100。通过适应度值的计算、个体选择、交叉、变异等操作完成遗传算法的一轮迭代,经过一定次数的迭代进化使遗传个体达到最佳适应度。
1.5 模型建立方法
分别使用BP 神经网络(BPNN)和支持向量机(SVM)两种算法建立全波段模型,选择全波段建模效果最佳的数据预处理方法和建模算法建立鲜烟叶田间成熟度判别模型。
BPNN 拓扑结构采用典型的3 层结构(输入层、隐含层、输出层)设计,其中输入层节点个数为模型输入变量的个数;输出层为模型输出成熟度类别个数;隐含层的神经元个数根据公式(2)确定:

式中:m为隐含层节点数;n为输入层节点数,l为输出层节点数;α为常数,在1~10的范围内取值。
模型建立时采用newff函数创建网络,输入层至隐含层的连接函数设置为tan-sigmoid 饱和正切函数,隐含层到输出层采用purelin 线性转换函数。SVM在MATLAB R2019b软件中调用林智仁教授开发设计的LIBSVM[19]工具箱。使用网格参数寻优法对SVM模型的惩罚参数c和径向基核函数参数g进行优化选取。
2 结果与分析
2.1 光谱曲线分析
由图2 可知,不同成熟度档次的烟叶在400 ~1000 nm波长内的平均光谱曲线的整体变化趋势相似,在550 nm 处有波峰、675 nm 处有波谷;在400 ~725 nm 间,烟叶光谱反射率随烟叶田间成熟度的增加而升高,在725 ~ 1000 nm 间平均光谱曲线起伏平缓,烟叶的光谱反射率随田间成熟度的增加反而降低,这与烟叶成熟过程中的外观特征变化规律相符合。

图2 不同成熟度档次鲜烟叶平均光谱反射率Fig.2 Average spectral reflectances of fresh tobacco leaves of different maturity grades
2.2 数据预处理结果
使用一阶导数、多元散射校正、标准正态变量变换、Savitzky-Golay平滑、一阶导数+SG平滑5种光谱预处理方法对光谱数据进行预处理,如图3所示。

图3 4个成熟度档次烟叶预处理后平均光谱曲线Fig.3 Average spectral curves of tobacco leaves of four maturity grades after pretreatment
为比较不同预处理方法的降噪效果,同时确定最佳建模途径,在MATLAB 软件中分别使用SVM和BPNN两种不同建模算法进行全波段建模。
由表2 可见,基于不同预处理方法建立的SVM模型中,MSC-SVM 和SG-SVM 模型的综合准确率最低,仅87.19%,而SNV-SVM 模型的综合准确率达93.13%,相比MSC-SVM 和SG-SVM 模型增加了5.94 百分点;基于不同预处理方法建立的BPNN 模型中,SG-BPNN模型的综合准确率最低,为87.50%,1stD-BPNN 模型的综合准确率最高,达92.19%。对比所有模型,SNV-SVM模型的综合准确率最高。因此,在后续研究中采用SNV 预处理的光谱数据建立鲜烟叶田间成熟度判别的SVM模型。
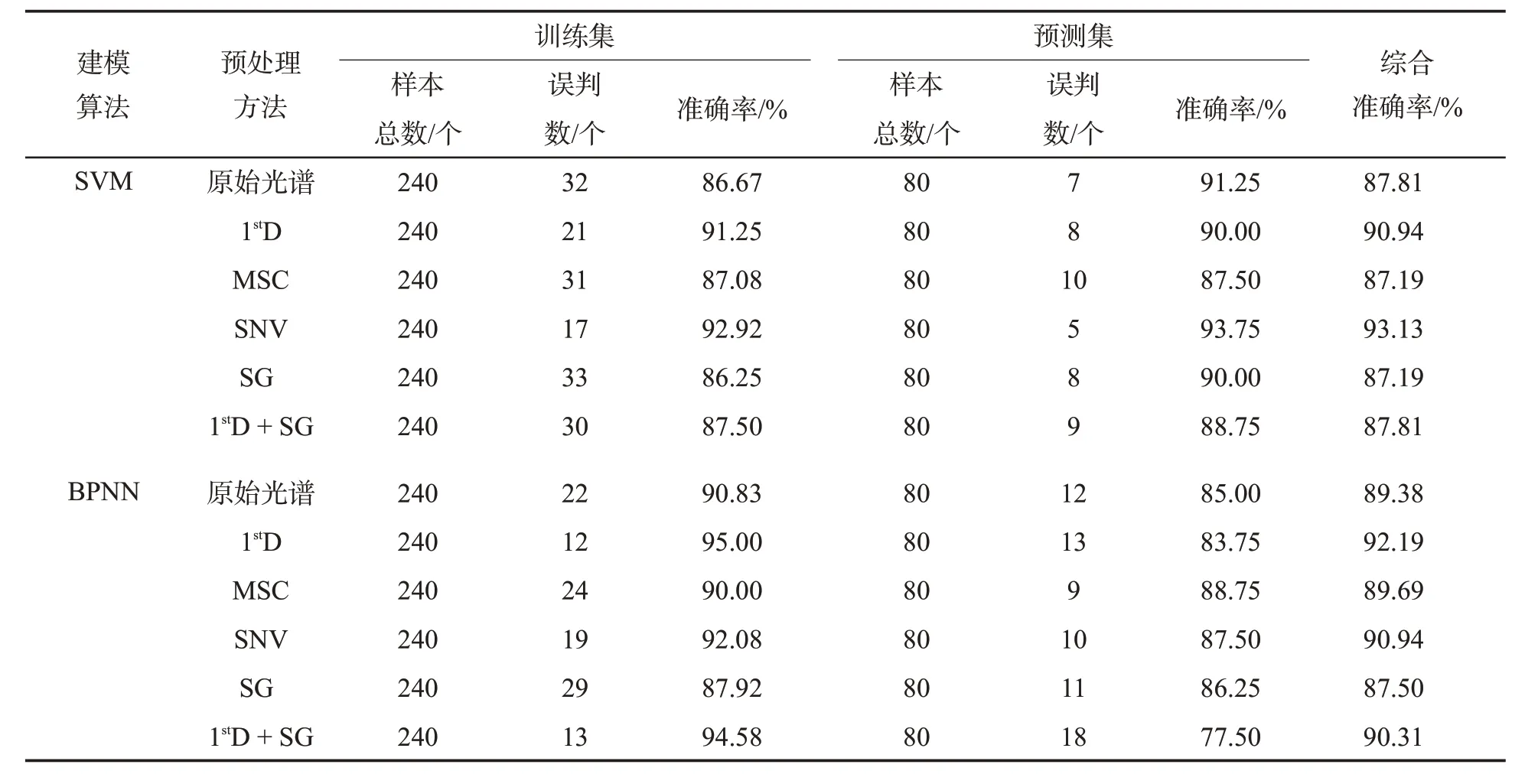
表2 基于不同预处理方法的SVM和BPNN模型结果Tab.2 Results of SVM and BPNN models based on different pretreatment methods
2.3 光谱特征波长区间的筛选
由图4可知,经过10次遗传迭代后,各代平均适应度曲线在0.95附近波动,各代平均适应度与各代最佳适应度的曲线波动较小,几乎重叠。最终从45个波段区间中优选出19个区间,将这19个区间作为建模输入变量。由图5可知,经GA优选后的特征变量区间大多分布在可见光范围内,且大多分布在400 ~ 550 nm 与630 ~ 700 nm 这两个波段内,在780 ~ 1000 nm的近红外波段内只有少量分布,且分布较为零散。

图4 GA变量寻优过程图Fig.4 Optimization process of GA variable
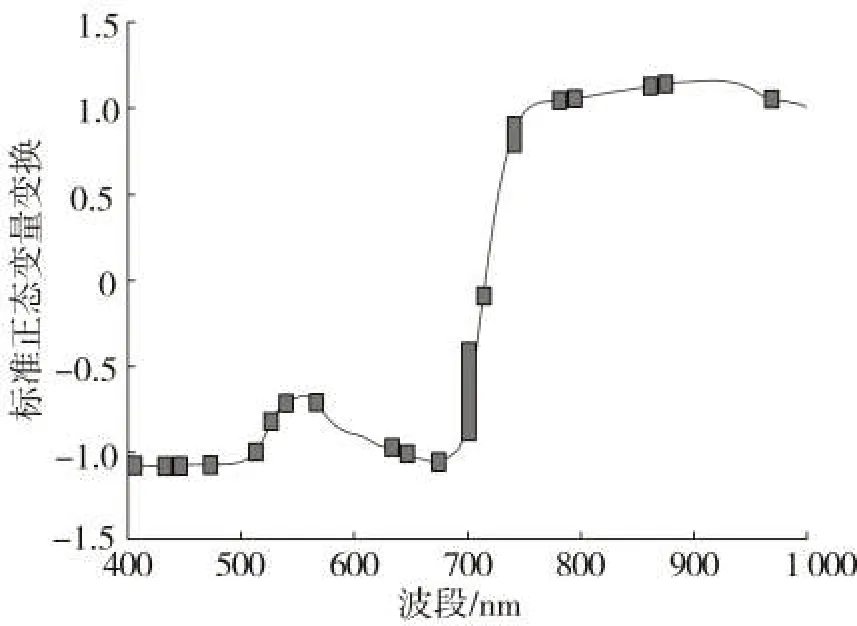
图5 GA优选的波段区间分布图Fig.5 Map of band interval distribution optimized by GA
2.4 模型建立
训练集样本的原始光谱数据经SNV 预处理后,选取GA 优选出的19 个特征波段区间作为输入变量,并对输入变量数据进行归一化处理,以样本类别为模型输出,采用径向基(RBF)函数作为模型核函数。使用带有交互验证的网格搜索法对SVM 的惩罚参数c和径向基核函数参数g进行优化,得到参数c的最佳值为2.83,参数g的最佳值为1,并基于最佳值建立SNV-GA-SVM 模型。使用80 个预测集样本对模型进行测试,由图6可知,该模型预测准确率达95%,且对过熟样本的预测效果最佳。

图6 测试集的实际分类与预测分类图Fig.6 Actual classification and predicted classification of test set
为进一步对模型进行全面、直观的评价,根据预测结果绘制混淆矩阵。由图7 可知,预测集20 个生青样本中有2 个被错误预测为尚熟;20 个尚熟样本中有1个被错误预测为生青;20个适熟样本中有1个被错误预测为尚熟;20个过熟样本全部预测正确。

图7 测试集的实际分类与预测分类混淆矩阵图Fig.7 Confusion matrix diagram of actual classification and predicted classification of test set
根据混淆矩阵计算模型精确率、召回率和F1分数。由表3可知,虽然模型平均精确率达95.28%,但对尚熟样本的识别精确率仅86.36%,而其他样本的识别率都达90%以上,说明模型对不同成熟度档次样本的识别能力存在差异。从4种样本的综合F1分数来看,模型对生青和尚熟样本的分类能力较弱,只有0.92和0.90,对过熟样本的分类能力最强,达1.00,其次是适熟样本,达0.97。整体来看,该模型能够对烟叶田间成熟度档次进行快速判别。

表3 SNV-GA-SVM模型评价指标分析Tab.3 Evaluation indexes of SNV-GA-SVM model
3 讨论
本研究中,烟叶高光谱反射曲线在550 nm处有波峰、675 nm 处有波谷,与余志虹等[20]研究结果一致,这可能是因为550 nm附近是叶绿素对光的强反射区域,675 nm 处是叶绿素对光的强吸收波段,在700 ~ 750 nm 处烟叶光谱反射率急剧上升,这些都是典型的绿色植物光谱特性。不同成熟度档次烟叶光谱反射率在550 ~ 675 nm 间差异明显,烟叶光谱反射率随田间成熟度的增加而升高,这与戴培刚等[21]的研究结果吻合。本研究中通过GA 优选出的特征变量区间主要分布在400 ~ 550 nm和630 ~ 700 nm波段,这两个波段均是烟叶中质体色素的光谱特征吸收峰[22]。可见与烟叶质体色素密切相关的光谱波段更能反映烟叶田间成熟特征,色素是造成烟叶高光谱反射率差异的重要因素。在人眼可见光波长范围外的780 ~1000 nm中也选出了特征变量区间,说明借助高光谱技术可获取人眼无法识别的特征信息,还说明除质体色素外烟叶中其他物质也与田间成熟密切相关,这些物质本身及其光谱特性可反映烟叶田间成熟度,但其具体成分有待进一步探索。
本研究中基于高光谱信息建立的判别模型对过熟和适熟烟叶的识别能力较强,F1 分数分别达到了1和0.97,但对生青和尚熟烟叶的识别能力稍低。这可能是因为烟叶由生青到过熟是一个连续渐变的生理生化过程,生青到尚熟阶段为烟叶的衰老初期,烟叶生理状态和化学成分变化都较缓慢,样本的成熟状态较接近,因而加大了识别难度。烟叶由适熟到过熟处于成熟进程的中后期,叶内成分及其光谱特征的变化较前期更明显,导致模型对不同成熟度档次样本的识别能力有差异。
因所用高光谱扫描设备不便在田间安装、移动和操作,本研究中烟叶的光谱数据皆在室内采集,降低了环境因素的影响,有利于提高模型的识别正确率,但也降低了模型使用的环境现实性,为接近生产实际还需在不同天气条件下采集烟叶田间原位高光谱信息。另外,研究中涉及的烤烟产地和品种单一,还需要在后继研究中采集更多产区和品种的样品进一步验证模型的普适性和实用性。
4 结论
基于不同成熟档次鲜烟叶的高光谱信息,采用机器学习方法建立了鲜烟叶成熟度的判别模型。结果表明,高光谱信息可敏锐、准确地反映烟叶田间成熟度的特征性差异,在550 ~ 675 nm波段内最突出,光谱反射率随烟叶田间成熟度的增加而增大。利用GA 可从全波段信息中优选出与烟叶田间成熟度相关的特征变量信息。采取SNV-GA-SVM 途径建立的烟叶田间成熟度判别模型性能优良,模型识别准确率达95%,且对适熟和过熟样本的识别能力最突出,对尚熟烟叶的正确识别率稍低,但也高于86%。
