结构化数据存储结构的索引方法研究仿真
2022-08-22张天一张杰松
张天一,张杰松
(1. 清华大学微电子与纳电子学系,北京 100084;2. 大连理工大学电子信息与电气工程学部,辽宁 大连 116024)
1 引言
目前数据的存储工作是通过半结构化路由完成的,同时存储对象为文件,采用文件名或者文件ID进行标识,同时构建对应的逻辑拓扑结构,并且借助DHT对关键字进行索引[1,2],利用随机哈希函数将结构化数据映射到Overlay Network相同的ID空间中。现阶段,在DHT上进行关键字索引的技术还需要进一步完善,尤其是无序数据的索引更是重中之重。
国内外相关专家针对结构化数据存储索引方面的内容进行了大量的研究,例如刘良桂等人[3]根据类属性提取关键字,构建分组索引,通过分组加密的形式降低索引和查询请求的加密时间,获取各个组分量的类别信息,更好实现分组索引。朱庆等人[4]将多模态场景数据抽象为图的节点和边,将稀疏矩阵采用时空索引的方式进行存储和描述,最终结合多维树实现索引。由于上述两种方法未能采用模糊聚类算法对数据进行分割处理,导致查询时间、索引构建时间以及通信开销上升,查询准确率下降等。为了有效解决上述问题,提出一种基于查询采样的结构化数据存储索引方法,经实验测试证明,所提方法能够有效提升查询正确率,同时还能够降低查询时间、索引构建时间以及通信开销,以更快的速度完成查询采样。
2 结构化数据存储索引方法
2.1 结构化数据划分和树状索引结构的建立
采用模糊聚类算法对全部数据进行预处理[5,6],同时确保每一个需要分割的数据是通过网格进行连通的。其中,算法的详细操作步骤如下所示:
1)对网格模型优先进行预处理;
2)计算网格每对面片的最短距离权值Dist(facei,facej);
3)为不同的面片分配对应的分割片,同时得到对应的可能性值;
4)计算模糊分解,同时将其划分为三个部分;
5)在模糊分解中获取准确的分界线,将网格划分为精确的两部分。
计算网络S中两个邻近面片facei和facej之间的加权距离Weight(facei,facej),以此为基础计算测地线距离和夹角距离,最终得到两个面片之间的最短距离。
计算相邻面片facei和facej之间的夹角距离Ang-Dist(αij),如式(1)所示
Ang-Dist(αij)=η(1-cosαij)
(1)
式中,η代表凹凸面角的取值;αij代表法向量夹角。
接下来计算相邻两个面片facei和facej之间的测地线距离Geod(facei,facej)
Geod(facei,facej)=dis(centeri,v)+dis(centerj,v)
(2)
式中,v代表公共顶点;centeri和centerj代表面片的中心点。
通过式(1)和式(2)求解出的夹角距离和测地线距离,并计算对应的加权处理后距离Weight(facei,facej),对应的计算公式为
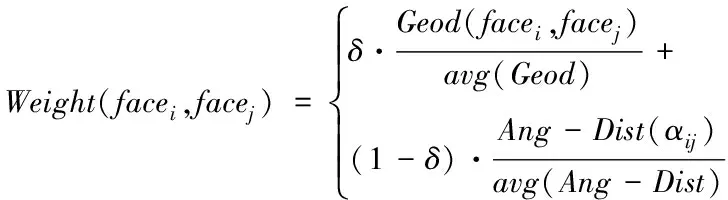
(3)
式中,avg(Geod)代表全部相邻面片中全部测地线距离平均值;avg(Ang-Dist)代表全部相邻平面夹角距离平均值;δ代表夹角距离和测试线距离经过加权后的比重值。
当结构化数据完成预处理后,无法直接通过原始模型进行连通,首先需要对原始模型进行简化处理,即网格模型预处理,详细的操作流程如下所示:
1)计算任意两个面片之间的最短路径Dist(facei,facej);
2)假设Dist(facei,facej)的取值存在∞,则说明网格不连通,跳转至步骤3);假设不存在∞,则说明网格连通,则继续进行分割即可;
3)如果网格模型中随机两个面片是连通的,则说明两者不在同一网格内。
在模糊聚类算法计算的过程中,选取面片之间距离值Dist(facei,facej)最大的面片,同时选取一对代表点采用REPA和REPB表示。通过式(4)和式(5)计算分割面片SA和SB的可能性值PA(facei)和PB(facei):
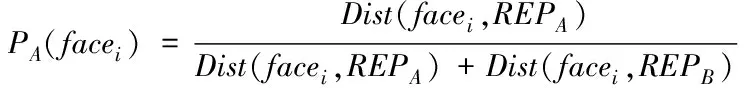
(4)
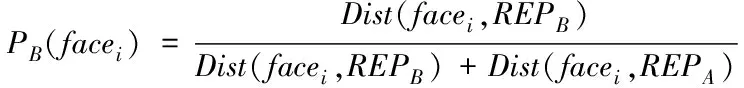
(5)
通过模糊聚类算法获取模糊分割结果[7,8],进而获取分解模型需要分解的两个部分,其中两部分的边界都是模糊边界,将模糊边界设定为模糊部分。
设定p代表分割片patch的面片,进行聚类的主要目的就是将面片聚类划分为两个部分,通过式(6)对其进行最小化处理

(6)
式中,pA和pB代表不同的分割片面片。
获取分解结果需要优先在模糊部分SC区域构建一个边界,当边界确定后,则SC中的面片就能够分配到对应的分割片中。
通过上述分析,主要使用模糊聚类算法对数据进行分割[9,10],并且深入分析全部数据的组成结构,得到结构化数据的详细分布信息。当数据完成分割处理后,需要借助B+树构建树状索引。由于单位为距离,需要对各个类别的聚类环进行编号和排序操作,然后将其放置到B+树中,以获取最优参考点。
2.2 基于查询采样的结构化数据分布情况估计
当结构化数据被访问时,将平均访问概率设定为数据存储的重要依据,然后通过最小聚类环判定数据是否为边缘数据。
为了全面掌握结构化数据分布情况和策略索引之间的关联性,采用查询采样方法进行分析和研究。设定聚类环为单位,得到结构化数据的平均访问概率。在此基础上,进一步分析数据分布情况对索引概率的影响,简化数据存储和扫描流程。
聚类环可索引能力ICi的计算公式为
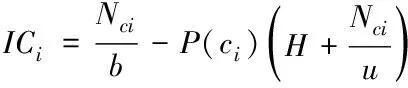
(7)
式中,ci代表第i个聚类环,P(ci)代表聚类环i被访问的平均概率;Nci代表聚类环i中全部数据的总数;b代表节点的数据容纳量;u代表树中的节点总数;H代表树中间节点的高度。
当ICi的取值小于或者等于0,则说明聚类环为边缘聚类环,对应的数据则为边缘数据。
当完成结构化数据的分割后建立树状索引,以此为依据构建查询集合Q,利用Q在B+树中对结构化数据进行存储索引,同时计算数据的平均访问概率P。其中,聚类环内的数据过滤能力和P值存在密切关联,P值越大,则过滤能力越差。另外,聚类环的可索引能力是通过查询概率和索引计算式得到的。最终,还需要通过中心权限定理以及设定的置信度控制采样次数,确保算法能够以最快的速度和最少的次数完成采样。
各个聚类环被访问的期望主要将聚类环是否为边缘环作为边缘环的判定依据,同时也能够完成采样目标的查询。对于被访问概率为p的聚类环而言,设定各个聚类环中的变量是随机且独立分布的,在n次采样过程中,聚类环被访问的频率ηn需要满足n和p的二次分布条件。结合中心极限定理,能够获取参数的标准正态分布。
根据置信度的查询采样控制,需要借助置信度的调节实现采样频率和精度两者的均衡。进行查询采样的主要目的就是估算不同聚类环的可索引能力,为了确保估算结果的准确性,在计算时需要及时对树状索引结构进行修正,确保ICi不会发生任何变化,同时还能够提前终止采样,降低采样数量。
2.3 结构化数据存储索引
为了有效提升高维数据库的查询效率,需要通过数据的分布情况来选择合适的索引策略。其中,结构化数据存储索引的组成结构如图1所示。

图1 结构化数据存储索引结构图
为了加快结构化数据存储速度和索引效率,需要设定一个专门的缓存系统,系统中主要包含一个用户跟踪的缓存帧描述器。同时,在以块为单位的存储系统中,加入B+树索引,以全面提升检索效率。
在采用B+树实现索引的过程中,需要在原始结构的基础上增加一些全新的页结构。其中,新增页结构也能够划分为多个页节点。详细的操作过程如下所示:
1)对各个分支页进行初始化处理;
2)假设层数为1,跳转至步骤3);
3)假设当前页有可用空间,则直接插入当前页,同时输出分支页记录;
4)假设当前页没有可用空间,分裂当前页,假设当前页为根节点,则树长高一层,分配一个全新的根节点;反之,则跳转至步骤3);
5)假设层数不为1,则跳转至步骤7);
6)通过当前页和键值Key获取当前页节点对应子树的页号,利用子树的页号在缓存区中读取对应的子节点;
7)将当前层数减1设定为全新的输入值,通过递归调用算法进行调节,输出结果赋值;
8)如果当前页未满,则直接跳转至步骤2);
9)假设当前页已满,则对当前页进行分裂处理;反之,则跳转至步骤2)。
由于树型索引具有较强的过滤性能,所以优先通过顺序扫描方法对结构化数据进行稀疏处理;然后将全部结构化数据自动存储到树型索引中继续进行关键字查询,为后续的研究奠定一定的理论依据,同时也确保查询结果的准确性。
采用最优KNN查询策略对结构化数据进行检索时[11,12],按照顺序对文件中的全部数据进行扫描,确保聚类环内的全部查询半径和查询结果会实时更新。针对B+树索引而言,全部的聚类环主要通过数据距离查询点的距离长短进行排序,并且放置到对应的序列中。同时还需要进一步判定聚类环区域和查询区域是否相交,假设两者是相交关系,则对聚类环内的数据进行搜索,并且在树状索引中裁剪出稀疏数据,根据顺序搜索策略达到结构化数据存储索引的目的。
3 仿真研究
为了验证所提基于查询采样的结构化数据存储索引方法的有效性,需要进行仿真测试。
1)结构化数据存储索引构建效率测试
在相同的数据集中,实验重点分析采用模糊聚类分解前后的结构化数据存储索引构建效率变化情况,将索引构建时间设定为测试指标,分析采用传统聚类算法和模糊聚类算法后的索引构建时间变化情况,如图2所示。
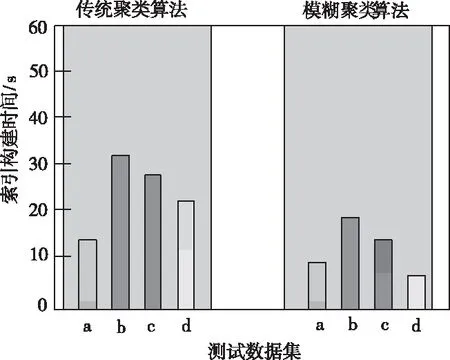
图2 传统聚类和模糊聚类算法的索引构建时间对比结果
分析图2中的实验数据可知,当通过传统聚类算法和模糊聚类算法分别进行结构化数据分割处理后,其中采用模糊聚类算法后的索引构建时间明显低于传统聚类方法,同时也能够在查询过程中有效避免整体聚类搜索,进而使所提方法的索引构建时间得到明显降低,索引构建效率大幅度提升。
选取文献[3]方法和文献[4]方法作为测试对象,分析各个方法的索引构建时间变化情况,详细的实验结果如图3所示。
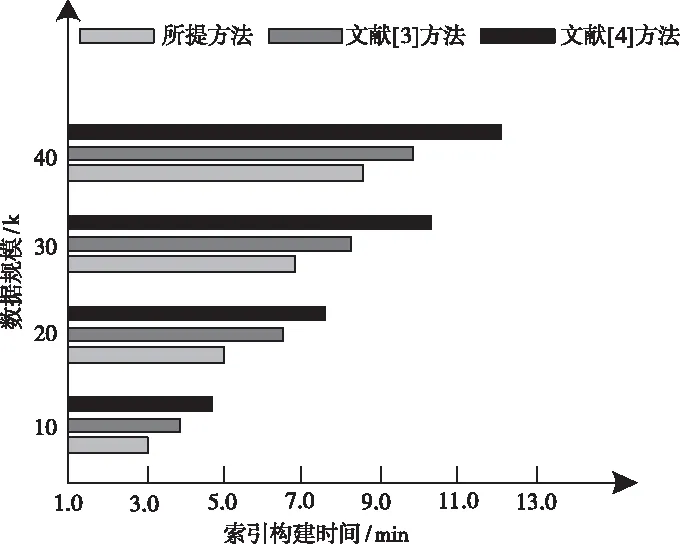
图3 不同方法的索引构建时间测试结果
由图3中的实验数据可知,当数据规模开始持续增加,各个方法对应的索引构建时间也开始飞速增加。但是相比另外两种方法,所提方法的索引构建时间明显更低一些,充分证明在所提方法中加入模糊聚类算法的可行性和正确性。
2)通信开销和查询时间测试分析
实验分别模拟三种不同方法在复杂查询条件下的通信开销和查询时间变化情况,具体实验结果如图4和图5所示。
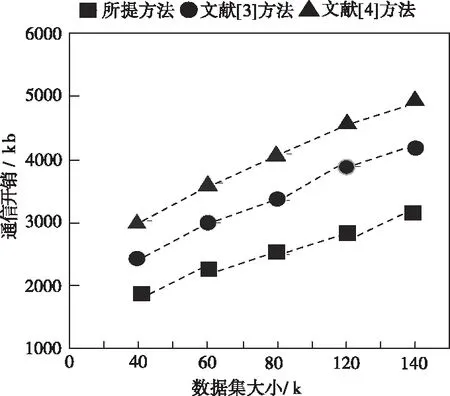
图4 不同方法的通信开销测试结果

图5 不同方法的查询时间测试结果
分析图4和图5中的实验数据可知,当数据集的大小开始增加,三种方法的通信开销和查询时间也开始呈直线上升趋势。相比另外两种方法,所提方法的通信开销和查询时间明显更低一些,充分证明了所提方法的优越性。
3)查询正确率测试分析
为了测试不同方法的可用性,实验将查询正确率设定为测试指标,详细的实验结果如表1所示。
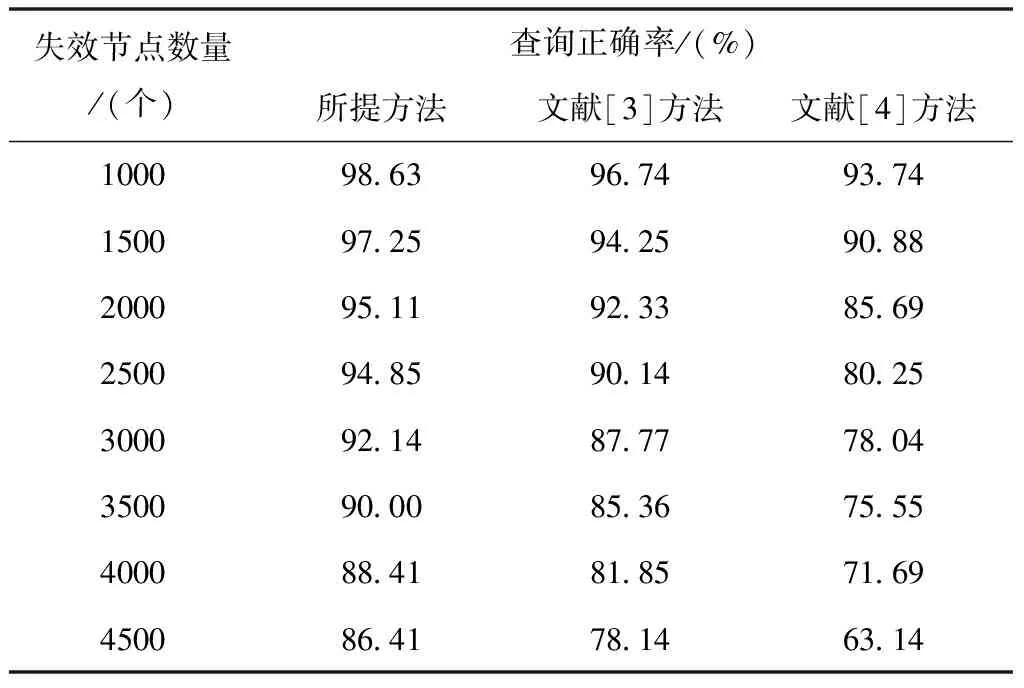
表1 不同方法的查询正确率测试结果
分析表1中的实验数据可知,查询正确率会随着失效节点的增加而降低,而且各个方法的下降幅度十分明显。但是相比另外两种方法,所提方法的查询正确率还是更高一些。
4 结束语
为了更好实现结构化数据存储索引,结合查询采样算法提出一种基于查询采样的结构化数据存储索引方法。经实验测试证明,所提方法能够有效降低查询时间、索引构建时间以及通信开销,提升查询准确率,具有较强的可用性。
