模块化网络主题语义分类算法的设计与仿真
2022-08-22刘仁芬
周 瑛,刘仁芬,李 娜
(石家庄铁道大学四方学院,河北 石家庄 051132)
1 引言
互联网应用的迅猛发展,使各种各样的网络主题呈爆炸式增加。在当前的移动社交网络中,每天都会出现大量的新信息。其中含有很多不规范的文本,这些文本具有组合灵活以及容易创作和发布等特点,成为人类发布和获取信息的重要手段。但是如何在这些数据中挖掘出有意义的内容成为当前研究的一大难题,其中网络主题语义分类更是关键[1,2]。虽然现阶段有关于网络主题语义分类方面的研究不断出现,但是取得的效果并不是十分理想,无法更好应对新出现的词汇或者奇异短语。
为了更好地解决上述问题,国内外相关专家展开了更深层次的研究。例如杨锐等人[3]在不同环境下通过字符级和词级卷积神经网络两者相结合完成网络文本分类。范国凤等人[4]优先对语义依存关系进行分析,同时对语义依存关系中的节点进行词嵌入和编码;然后通过信息传递的方式对节点和边进行更新,挖掘语义依存信息,通过分类模型对其分类。在以上两种算法的基础上,本文提出一种基于特征序列的模块化网络主题语义分类算法。实验结果表明,所提算法能够获取满意的分类结果,还能够有效减少算法的运行时间。
2 模块化网络主题语义分类算法
2.1 模块化网络主题语义相似性计算
将数据库中的全部时间序列通过一个顶点进行描述,通过Ochiia系数方法计算模块化网络主题语义之间的相似性,同时将其进行连接。
假设有两个特征序列,分别为X={x1,x2,…,xm}和Y={y1,y2,…,ym},滑动窗口的长度为l。通过计算获取对应的两个子序列集,表示为X′和Y′,其中,两个子序列之间的最小距离MPX′Y′能够表示为

(1)
式中,m代表特征序列的长度。
特征序列X和Y两者之间的相关关系SX,Y能够表示为
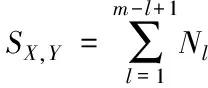
(2)
式中,Nl代表矩阵剖面中的子序列数量。
对于各个特征序列的子序列而言,需要计算其中一条特征序列和剩余全部子序列之间的距离,获取距离最小的特征序列,同时将两个特征序列的相似度加1。为了更加详细描述不同序列之间的关系,需要组建一个网络图
G={V,E,W}
(3)
式中,V代表网络节点集合;E代表网络的有向边集合;W代表边的权值集合。
为了全面掌握特征序列的建立过程,需要优先组建一个子序列网络。其中,特征序列是由四个不同的子序列集构成的,其中每个子序列均采用一个节点进行表示,颜色相同的节点即来自同一个特征序列。对节点之间的有向边进行定向,代表该边的目标和源节点对应子序列的最小距离。
通过Louvain社区检测算法将序列划分为两个不同的类,详细的操作步骤如下所示:
1)求解特征序列数据集的大小和对应的序列长度。
2)将数据集中的全部特征序列进行遍历,通过滑动窗口将其划分为长度为I的子序列;Ti′代表特征序列Ti对应的子序列集合。
3)对于特征序列中的各个子序列,通过调用算法计算特征序列和其它子序列之间的矩阵剖面。
4)通过矩阵剖面计算两个特征序列之间的相似性,即计算不同模块化网络主题语义之间的相似性[5,6]。
2.2 构建主题簇
在得到不同主题之间的相似性后,为了能够更加精准分析不同主题之间的语义关系,将整个关系通过图的方式进行描述,将主题设定为网络图的顶点,其中各个主题之间的关系能够看作是一个边。对于不同的网络主题而言,通过主题能够更好地反映研究的主要内容。
优先提取不同网络主题中的关键词,同时统计各个关键词出现的次数,将无利用价值或者出现次数较少的关键词删除。组建高频主题共现矩阵,经过转换形成相似性矩阵,结合近邻传播算法将全部网络主题进行聚集,划分为多个不同的簇。
近邻传播算法(AP)是一种全新的聚类算法,和传统方法存在的主要区别为:AP算法将已知的数据点均设定为潜在的聚类关系,主要通过消息传递的方式完成聚类[7,8]。
假设数据集中含有n个数据集,设定在网络主题语义的特征空间中存在一些比较紧密的簇C,各个数据点对应一个簇。其中,xc(i)代表随机点对应的簇代表点。当模块化网络主题语义经过聚类后,能够获取对应的误差函数J(C),具体的表达形式为
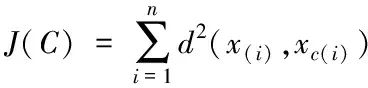
(4)
式中,d代表网络主题语义的类型总数;x(i)代表任意簇点。
AP算法主要目的就是通过计算得到最优簇代表点集合,同时将误差函数的取值降至最低,即
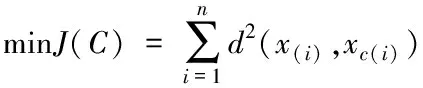
(5)
AP算法中主要包含两种不同类型的信息,分别为:可靠性信息和安全性信息。为了有效避免算法在计算的过程中出现振荡,需要在算法更新信息素的过程中加入衰减系数λ,其为介于0到1之间的实数。
利用图1给出AP算法的具体操作流程:
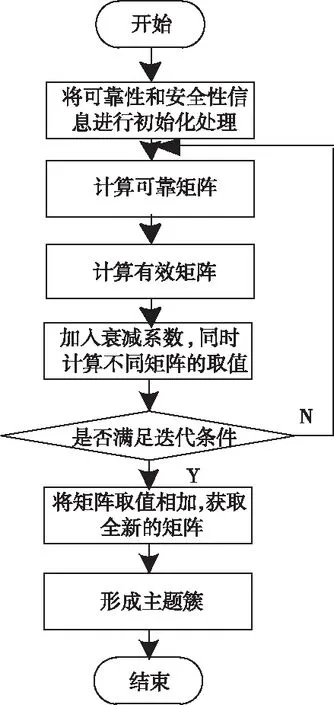
图1 AP算法的操作流程图
1)将可靠性和安全性信息进行初始化处理;
2)计算可靠矩阵r;
3)计算有效矩阵a,同时计算矩阵对角线上的元素,剩余元素采用其它方式进行计算;
4)加入衰减系数,同时对矩阵a和r进行实时更新计算;
5)重复步骤2)到步骤4),直到迭代次数满足最大值或者当前聚类中心连续多次迭代不发生时,停止计算;
6)将矩阵a和r相加获取全新的矩阵g;
7)将含有簇中心的模块化网络主题语义对象放置到一个类中,获取主题簇。
2.3 模块化网络主题语义分类
利用图2给出模块化网络主题语义分类的详细操作流程。
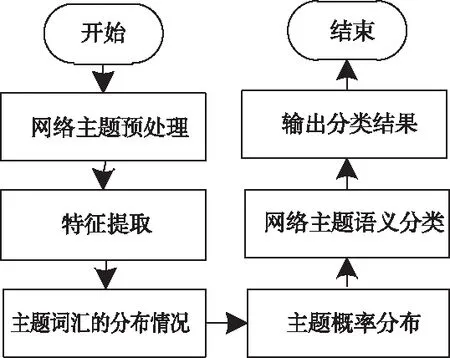
图2 模块化网络主题语义分类流程图
进行网络主题语义预处理的目的是对主题进行分析,当完成文本的分类工作之后,需要进行去停用词操作。因为经过分词之后,网络主题语义中会不可避免地出现一些价值不大的词汇,即虚词,需要将其剔除。
其中,模块化网络主题语义的采样过程如下所示:
1)将全部参数进行初始化处理,同时设定最大迭代次数;
2)将全部网络主题语义进行遍历操作;
3)根据不同词对的分布情况,及时更新语料库中的主题矩阵和词对矩阵;
4)是否满足迭代次数,假设满足,则直接进行步骤5);反之,则跳转至步骤2);
5)保留网络主题语义文件;
6)判断迭代次数是否达到设定的需求;假设满足条件,则跳转至步骤2);反之,则跳转至步骤7);
7)保留通过主题矩阵获取的最终文件。
传统的网络主题语义主要是采用向量空间模型表示,模型主要是将文本映射为一个特征向量V(d),ωi(d)代表词汇在语料库中的权值。由于模型为主题模型,所以模型可以通过主题的概率分布进行描述,具体的计算式如下
di=(p(z0|di),p(z1|di),…,p(zk-1|di))
(6)
式中,di代表主题分布概率,p代表参考度。
由于模型为主题模型,其中文本以主题概率分布呈现的形式进行表示,借助2.1小节计算得到的各个网络主题语义相似性,同时采用主题的概率分布向量进行计算,具体的计算式如下
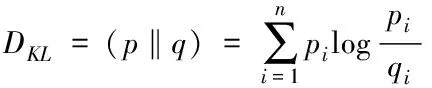
(7)
式中,DKL代表两个网络主题语义的概率分布情况;q代表分布概率的取值范围;pi和qi代表不同类型的网络主题。
在上述分析的基础上,结合特征序列,获取网络主题的平均热度和描述词,以此为基础,组建网络主题语义流行度序列。
根据不同网络主题语义出现的时间顺序,统计各个主题簇中全部关键词在设定时间段内出现的次数。其中网络主题流行度计算式如下
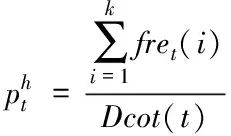
(8)
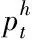

(9)
式中,year代表时间序列长度。
其中两个网络主题语义相似性越高,说明两者的发展趋势越一致。以下主要通过DTW算法对各个特征序列的相似性进行计算,根据计算结果构建相似性矩阵。根据k-means算法对全部主题序列进行聚类[9,10],详细的操作过程如下所示:
k-means算法是一种简单的聚类算法,根据计算不同聚类对象的维度距离获取“中心对象”,即质心[11,12]。将质心靠近的对象划分到相同的主题簇中。其中,k-means算法的计算过程为:
1)设定K个点将其放置到要被聚类的数据对象所表示的空间内,即初始聚类簇质心;
2)将各个对象划分到最接近的质心聚簇中;
3)当全部对象完成分类之后,获取W个聚簇,同时在各个聚簇中计算聚簇对应的质心位置,获取W′个新的质心;
4)重复步骤2)和步骤3),直至质心的位置不再发生任何改变,同时形成稳定且独立的聚簇;
通过k-means算法将全部特征序列进行分类,实现模块化网络主题语义分类,即
1)将模块化网络主题语义进行遍历处理,获取全部网络主题中概率值最大的主题;
2)统计不同聚簇下各个主题所占据的比例,获取出现次数最多的主题;
3)在网络主题库中,通过步骤2)统计出现次数最多的主题,然后将排名前10的词汇作为聚簇进行描述;
4)通过k-means对全部特征序列进行聚类,实现模块化网络主题语义分类。
3 仿真研究
为了验证所提基于特征序列的模块化网络主题语义分类算法的有效性,需要进行仿真测试。
为了验证融合主题信息的卷积神经网络文本分类方法(文献[3]方法)、基于语义依存分析的图网络文本分类模型(文献[4]方法)以及所提算法性能的好坏,选取精确率、召回率和两者的加权调和平均值作为评价指标,具体的计算公式如下所示

(10)
式中,P代表精确率;R代表召回率;α代表权重因子;F代表P和R之间的加权调和平均值,即F=F1,F1值的大小和分类结果准确性存在密切的关联,F1的取值越大,则说明得到的分类结果准确率越高,具有更好的分类性能,具体的计算公式如下所示
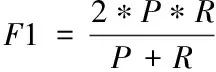
(11)
通过上述评价指标对各个算法的分类性能进行测试分析,具体实验结果如图3所示。
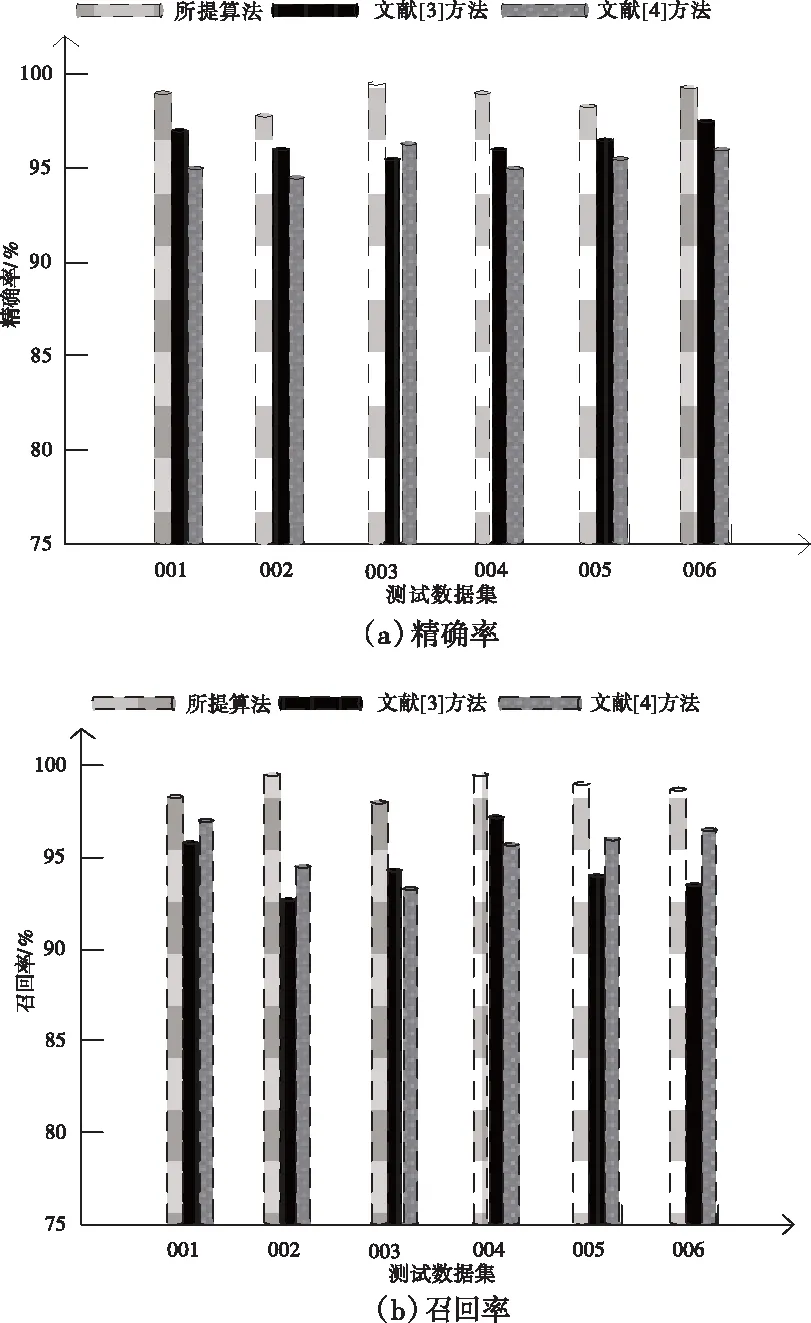
图3 不同算法的分类性能测试
由图3中的实验数据可知,相比另外两种分类方法,所提算法的精确率、召回率以及F1值均高于另外两种算法,说明所提算法具有更好的分类效果。
为了更进一步验证所提算法的优越性能,分别在不同的主题环境下进行实验测试,具体实验结果如表1所示:
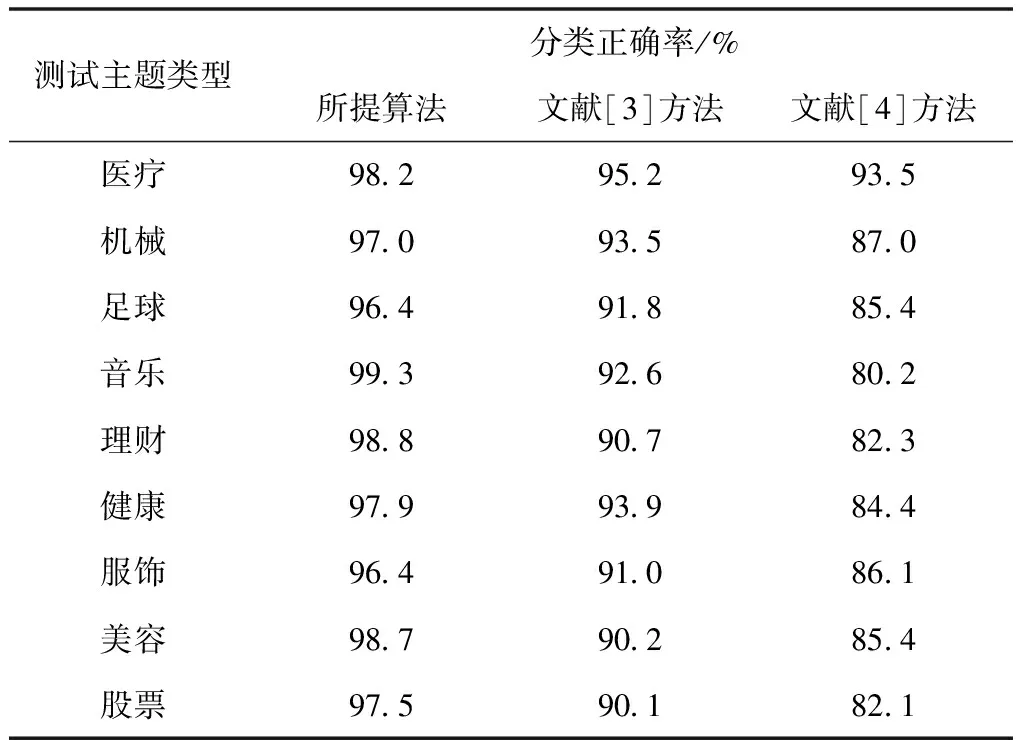
表1 不同测试主题下各个算法的分类正确率测试分析
分析表1中的实验数据可知,即使在不同的测试主题下,所提算法的分类正确率还是优于另外两种算法,更进一步说明了所提算法的优越性。
以下实验将运行时间作为测试指标,其中运行时间越短,则说明分类速度越快。利用图4给出三种不同分类算法的运行时间。

图4 不同算法的运行时间测试分析
分析图4中的实验数据可知,所提算法的运行时间明显更低一些,主要是其对不同网络主题的流行度进行计算,同时构建流行度序列。将流行度序列作为划分依据,将相似的网络主题语义划分到同一个主题簇中,能够更好地完成分类,同时还能够简化分类流程,有效降低分类时间。
4 结束语
为了更好完成网络主题语义分类,结合特征序列,提出一种基于特征序列的模块化网络主题语义分类算法。经过仿真测试证明,所提方法能够全面提升分类结果的准确性,同时还能够有效减少运行时间,全面提升算法的运行速度。
