基于人工蜂群的移动终端大数据半监督推荐
2022-08-22杨兴耀
郑 捷,杨兴耀,于 炯,李 想
(新疆大学软件学院,新疆 乌鲁木齐 830046)
1 引言
科学技术的发展使人们进入到大数据时代,移动终端大数据正以指数趋势增长。无论是生产者还是用户均面对海量数据,作为普通用户,难以准确获取感兴趣的信息,降低了有效信息利用的率,大量无效信息对生活也造成困扰。为解决该问题,推荐系统得到了充分发展和广泛利用,该系统具有一定被动性优势,用户无需花费大量时间了解信息内容,系统会结合用户行为特征主动推荐他们想要的信息。现阶段,推荐系统在人们生活中无处不在,为进一步提高推荐系统性能,相关学者也已经得到了一些较好的推荐算法。
文献[1]利用协同过滤算法完成推荐。综合分析项目评分情况与用户喜好,建立相似度矩阵;使用协同过滤方法实现用户打分,将打分结果当作训练信息,引入Top-N算法形成推荐集合。文献[2]将深度学习过程引入到推荐算法中,对数据进行预处理,获取上下文信息特点,利用变分自编码器建立一个能够感知上下文的推荐模型。
但以上方法对用户相似度的考虑不够深入,无法获取数据项目类间与类内分布信息熵,样本标记出现偏差,容易出现用户相似度单一问题,导致推荐精度偏低。为此,本文提出一种半监督推荐算法。将半监督方法当作机器学习中的重点内容,融合完全监督和无监督两种算法各自优势。人工蜂群算法是半监督方法的典型代表,利用此种方法重构目标函数,实现用户聚类,通过计算用户之间的相似度,获得近邻数量,再对项目作出合理评分,将评分较高的数据推荐给用户。仿真结果证明半监督方法能够在数据推荐中得到很好地应用效果,进一步提高了推荐精度。
2 用户喜好模型构建
建立偏好模型[3]是用户聚类的基础,利用项目评分与项目属性矩阵,构建用户偏好权重矩阵。分析具有m个用户与n个项目的推荐系统,设定用户集与项目集的表达式分别如下
U={U1,U2,…,Um}(i=1,2,…,m)
(1)
I={I1,I2,…,In}(j=1,2,…,n)
(2)
则建立的项目评分矩阵见表1,元素rij代表用户i对项目j的评分情况。

表1 评分矩阵
项目属性集通过F={f1,f2,…,fs}描述,其矩阵形式见表2,元素ajk代表项目Ij特征属性。

表2 属性矩阵
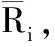
由此可知,属性fi在Li中出现的频率越高,表明该属性的用户偏好程度越高,与其相对的权值也较大,偏好权重计算公式如下
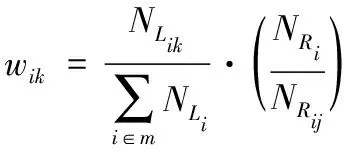
(3)
式中,NLi代表集合Li内包括属性fj的项目数量。

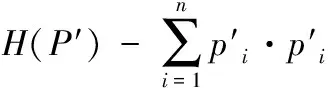
(4)


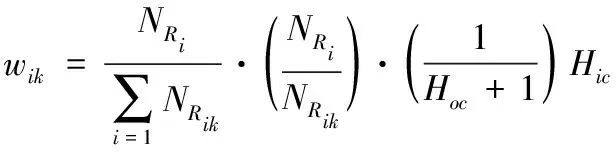
(5)
利用式(5)建立表3所示的矩阵。

表3 用户偏好矩阵
分析该矩阵能够得出用户对不同项目的喜爱度,建立偏好模型,为用户聚类提供依据。
3 基于半监督推荐的移动终端大数据推荐
3.1 半监督人工蜂群用户聚类
用户聚类的主要目的是减少计算用户相似度所用时间,缩小近邻查找区间[5],将通过偏好矩阵得出的具有相似性的用户划分在同一个聚类簇内,保证相同簇内用户存在较高相似度。
本文利用了人工蜂群半监督算法,该方法能够从多个角度分析用户属性,更加精准的建立相似用户集合,改善相似度单一现象[6],有利于推荐效果的提高。
1)聚类数学模型
对于聚类问题,构建下述数学模型:
已知样本集合为X={x1,x2,…,xn},将其分割成多种类别C={C1,C2,…,Cκ},且xi(i=1,2,…,n)是d维矢量,κ属于类别数量,同时满足以下公式要求
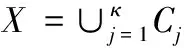
(6)
Cj(j=1,2,…,κ)≠∅
(7)
Ci∩Cj(i,j,…,κ,i≠j)=∅
(8)
通常情况下,聚类目标函数[7]如式(9)所示,其中d(xi,Cj)代表样本xi和对应类别中心Cj之间存在的距离,f则是全部样本和对应类别距离之和的均值,该值越小说明类内间距也随之减小,聚类效果越佳。
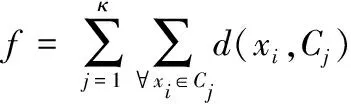
(9)
2)目标函数优化
半监督学习算法需同时使用有标签和无标签的数据[8],且聚类是半监督众多学习方式中的一种,它可以根据一少部分先验知识引导聚类过程,依次改善聚类效果。
在人工蜂群半监督算法中,目标函数取值会影响聚类效果,上述目标函数通过计算样本与聚类中心的距离来划分所属类别,只使用了无标记样本,导致存在一定局限性。因此,有必要充分使用标记数据来改善聚类效果,本文将对目标函数作出改进,引入标记数据约束聚类过程[9]。
根据聚类数学模型可知,样本集合表示为
S=LS∪ULS
(10)

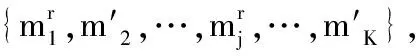

(11)
式中,α代表参数,作为带标记数据在聚类过程中的权重值,可体现出算法对标记样本的重要程度,参数(1-α)则是没有标记的样本在聚类时占有的权重。若α=1,人工蜂群算法只对于有标记的样本运算,找出所有类别质心;若α=0,则该算法是在无标记数据基础上实现聚类的。
结合上述改进的目标函数,聚类过程可描述为:设置最大迭代与最大搜索次数[11];结合有标记的样本设置聚类数量;利用式(11)所示的目标函数生成多个聚类中心簇[12],获取每个簇的适应度值,此值能描述各簇质量;通过计算得出每个聚类中心的选取几率,使用概率值选择需改善的中心簇;若某聚类中心簇质量在经过多次搜索后并没有出现变化,则去除该簇,通过式(11)生成新簇;选择最佳聚类中心簇,将其保存;反复进行上述操作,直到到达设置的最大搜索次数,输出最佳聚类中心簇。
3.2 推荐实现
1)用户相似度计算与近邻数量获取
完成上述聚类后,实现了具有相同偏好的用户集结,还需进一步计算用户之间存在的相似度,确定近邻数量。对于用户相似度的计算包括余弦法以及相关性等计算方法。本文利用余弦法获取用户之间存在的相似度,计算公式如下
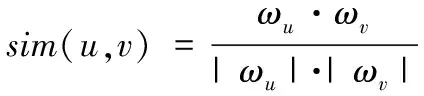
(12)
式中,ωu与ωv代表用户u与v的偏好矢量。根据该相似度计算结果,获取近邻数量,公式为

(13)
式中,Mij代表项目有用户评分的集合。
2)评分预测
确定目标用户对项目的近邻集合后,利用此集合中的用户对项目Iij打分,采用加权平均值的表示最终打分结果:

(14)
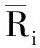
3)推荐结果生成
重复打分操作,预测用户对全部项目的打分结果,对打分结果按照由高到低顺序排列,选取其中前N′个项目推荐给用户。
4 仿真数据分析与研究
为验证半监督推荐算法在移动终端大数据推荐中的可行性,需进行仿真。首先对该方法的聚类效果进行测试。设置聚类原始置信度为96%,测试样本为四种具有不同偏好特征的用户,样本数据初始分布情况见图图1(a)。假设四种类型数据分别以(0.7,0.6)、(0.7,0.4)、(1.1,0.6)和(0.3,0.6)为聚类中心。利用基于协同过滤和深度学习的大数据推荐算法与本文算法进行对比,聚类结果如图1所示。

图1 不同算法的数据聚类效果对比图
如图1所示,本文算法能够按照聚类要求将相同类型的样本数据集合在一起;协同过滤算法虽然也能够实现数据聚类,但同一类数据间较为分散,若数据量增多,会造成错误聚类现象;深度学习算法则出现聚类错误情况。这是因为,本文使用的半监督方法改进了目标函数,能够引导聚类结果向最优结果收敛。


(15)
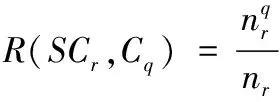
(16)

(17)
因此,能够获得每次迭代时产生的F-Score值,将该值变化趋势与最佳目标函数变化趋势进行对比,得到如图所示的结果。
由图2可知,随迭代次数的不断增加,目标函数值逐渐降低,而F-Score值越来越大。这种现象表明聚类中心簇和最佳聚类结果越来越相近,且收敛过程平稳。进一步证明了半监督聚类算法在处理连续优化问题时,可避免陷入局部最优解。
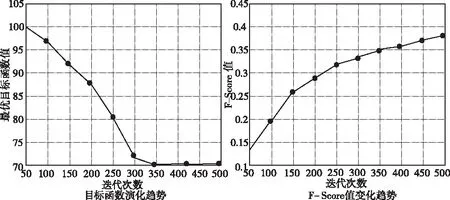
图2 目标函数与F-Score值的变化趋势图
最后,利用平均绝对误差(MAE)评价三种算法的推荐准确度,该值越小表明推荐结果越好。若利用推荐算法计算得出的用户对项目的评分集合表示为p={p1,p2,…,px′}而实际评分利用q={q1,q2,…,qx}描述,则平均绝对误差表达式如下
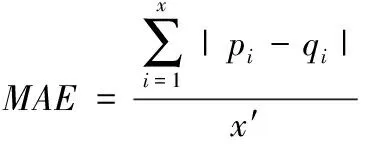
(18)
假设推荐次数为20次,每一次都有新的数据增加,数据集合会不断扩大,记录三种方法每一次测试情况,结果如图3所示。
由图3能够看出,随着数据量的不断增加,所提算法的推荐误差并没有表现出明显上升趋势;而其它两种算法的推荐误差均有不同程度提高,整体上本文算法的误差最低。这主要依赖于本文算法建立了用户偏好模型,无论数据量多还是少,总能准确挖掘出用户感兴趣的内容,并将其推荐给用户,提高满意度。
5 结论
本文在大数据推荐过程中引入了基于人工蜂群的半监督算法,通过构建用户偏好模型,为聚类过程奠定良好基础;使用半监督聚类算法提取具有相似偏好的用户,有利于推荐精度的提高,再通过相似度计算、近邻数量确定、评分预测等过程输出最优推荐结果。但该算法还存在一定不足,在探究用户偏好过程中,应使用相关语言处理方法更加深入地获取用户偏好,可附加更多性别、职业等信息,使模型更加精确,改善推荐效果。
