基于改进PSO-TSFNN的汽车保险欺诈检测模型
2022-08-22迟萧颖刘新红
闫 春,迟萧颖,刘新红
(1. 山东科技大学数学与系统科学学院,山东 青岛 266590;2. 北京石油化工学院数理系,北京 102617)
1 引言
近年来,我国保险业发展迅速,据国家统计局发布的保险业年度数据,我国截至2018年年底保险机构数量235家,原保费收入3.80万亿,规模达到世界第二,成为了全球最重要的新兴保险市场大国。据我国保监会的统计数据以及保险业内部估算,至少含有20%的车险赔付属于欺诈,我国车险欺诈赔付额占索赔总额比率远远高于全球的平均水平[1]。车险欺诈不仅破坏了保险制度的正常秩序,也危害到我国保险行业健康发展。因此,建立有效的保险反欺诈模型来快速准确的识别欺诈案件,对于我国保险行业是一项至关重要的工作。国内外学者进行了车险欺诈识别的多种尝试[2]-[7],如BP神经网络(BPNN)、随机森林(RF)、支持向量机(SVM)等建立预测模型,但这些方法识别准确率仍然不高。因此,车险业亟需引入新的技术,而T-S模糊神经网络是一个非常好的选择。
与Logistic 回归、BP神经网络等学习技术相比,模糊神经网络结合了模糊理论和神经网络,汇集了二者的优点,集信息处理、联想、学习、识别于一体。因此,理论上,T-S模糊神经网络方法十分适合车险欺诈识别。无论国内还是国外,许多学者将糊神经网络应用于水质评价、信用评估等领域[7]-[12],但是,很少有学者研究基于T-S模糊神经网络的车险欺诈识别模型。T-S模糊神经网络具有初始的隶属函数中心值和宽度以及模糊网络系数随机的特点,因此模型会存在训练误差较大,人工设置参数较多,对初始值依赖较强的固有缺点。而粒子群算法具有良好的寻优能力,能够优化T-S模糊神经网络的参数,实现对T-S模糊神经网络的优化。根据上述本文提出一种改进粒子群优化T-S模糊神经网络的算法,改进的粒子群算法采用混沌映射提高初始种群的多样性,在位置更新过程中引入非线性时变惯性权重和自然选择机理提高算法的全局搜索能力。最后,建立车险欺诈检测模型,为检验期预测效果,与未优化的TSFNN、PSO-TSFNN,LDWPSO-TSFNN三种模型相比较,结果表明:相对于传统算法而言,改进PSO-TSFNN能够有效地识别索赔数据中的欺诈信息,且该模型易于实现,具有更高的识别率、预测精度以及良好的鲁棒性。
2 算法描述
2.1 T-S模糊神经网络算法


图1 T-S模糊神经网络算法流程图
T-S模糊神经网络每层表达如下。
1)第一层(输入层):这一层连接输入向量xi,输入向量的维数与节点数相同。故输入层具有n个节点,这些节点将输入值直接传递到第二层。
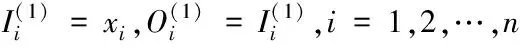
(1)
2)第二层(模糊化层):这一层共有n×m个节点,共有n组。模糊隶属度值确定了输入变量的模糊集成度,为了得到模糊隶属度值,采用Gaussian隶属度函数(2)模糊化输入值。
(2)

3)第三层(模糊规则计算层):这一层共有m个节点,采用模糊连乘式(3)计算得到ω

(3)
4)第四层(输出层):这一层共1个节点,采用式(4)根据模糊计算结果计算模糊神经网络模型的输出值yi:
O(4)=I(4)
(4)
2.2 标准粒子群算法
标准粒子群(Particle Swarm Optimization,PSO)算法是一群初始化的粒子,每个粒子都代表问题的一个潜在最优解,其中每个粒子分别用速度、位置和适应度值三项指标表示,适应度值的大小表示粒子的优劣,其值根据适应度函数计算得到[13]。
假设种群X=(X1,X2,…,Xn)在D维的搜索空间中,其中第i个粒子在D维的目标搜索空间中的位置表示为Xi=[xi1,xi2,…,xiD]T。根据目标函数可计算出每个粒子位置Xi所对应的适应度值。令Vi=[Vi1,Vi2,…,ViD]T为第i个粒子的速度,Pi=[Pi1,Pi2,…,PiD]T为其个体极值,Pg=[Pg1,Pg2,…,PgD]T为种群的全局极值。
在每一次迭代过程中,粒子通过个体极值和全局极值更新自身的速度和位置,更新速度和位置公式如式(5)、(6)所示

(5)
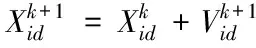
(6)
式中,ω为惯性权重;d=1,2,…,n;i=1,2,…,n;k为当前迭代次数;c1和c2为加速度因子,均为非负的常数;γ1和γ2为分布于[0,1]的随机数。Vid为粒子的速度;Xid为粒子的位置。为了防止粒子的盲目搜索,将其速度和位置分别限制在区间[-Vmax,Vmax]、[-Xmax,Xmax],Xmax和Vmax均为常数。
具体流程图如图2所示。

图2 标准粒子群算法流程图
3 改进PSO-TSFNN车险欺诈检测模型构建
3. 1 改进粒子群算法
3.1.1 混沌映射初始化种群
PSO算法的寻优能力与种群的多样性有着密切的联系。因此本文采用Logistic混沌映射对PSO算法种群进行初始化,增加初始种群的多样性。改进后算法初始化公式如式(7)所示
Xn+1=Xn×μ×(1-Xn)
(7)
其中,μ∈[0,4]称为Logistic参数;Xn为混沌序列的第n个值,并且Xn∈[0,1]。
3.1.2 非线性时变惯性权重
惯性权重ω的选取对PSO算法搜索能力的影响显著。当ω较大时,保证了算法全局搜索能力;当ω较小时,保证了算法局部开采能力和收敛速度[14]。本文提出了一种非线性时变惯性权重,其公式如式(8)所示

(8)
其中,ωmin为初始惯性权重;ωmax为迭代至最大次数时的惯性权重;Tmax为最大迭代次数;t为当前迭代次数。
3.1.3 自然选择机理
PSO算法在搜寻最优解时表现良好的优化效果,但也存在一些不足,例如PSO算法在容易过早陷入局部最优解,影响搜索全局最优解。本文针对PSO算法存在的缺点,引入自然选择的原理,在每一次迭代的过程中,根据粒子种群适应度值重新排列粒子群顺序,用群体中50%较好的粒子替换50%较差的粒子,同时对原来所有个体记忆的历史最优值进行保留。
改进粒子群算法的计算步骤如下。
1)设置种群规模M,学习因子c1、c2,最大迭代次数Tmax,惯性权重ωmin、ωmax,以及搜索空间维度D等参数。
2)运用混沌映射初始化种群,迭代生成M个粒子。
3)并根据适应度函数计算每个粒子的适应度值并进行排序,选出最好的m个个体作为初始群体。
4)将粒子的位置和适应度值保存于粒子的个体极值pbest,将所有pbest中最优适应值的个体位置和适应度值储存在全局极值gbest中。
5)根据式(5)和式(6)更新粒子位移和速度。
6)根据式(8)更新权重。
7)比较每个粒子的适应度值和粒子的最优位置,如果两者相近,则粒子最优的位置为当前值。将当前所有的Pbest和gbest进行比较,更新gbest。
8)根据粒子种群适应度值重新排列粒子群顺序,用群体中50%较好的粒子替换50%较差的粒子,同时对原来所有个体记忆的历史最优值进行保留。
9)当算法达到最大迭代次数时,停止搜索并输出结果;否则返回到第5)步继续搜索。
3.2 改进PSO-TSFNN车险欺诈检测模型
为了获得更好的车险欺诈识别准确度,本文尝试采用改进粒子群算法优化模糊神经网络的参数。在本文中,设T-S模糊神经网络的输入层和隐含层的节点数分别为n和m,而输出层为最后的车险评价结果,故输出层只存在一个节点。则T-S模糊神经网络模型的结构可表示为n-m-1。
改进粒子群算法优化模糊神经网络算法的基本计算步骤如下。
1)在改进粒子群算法中设置初始值。在所有的数据进行处理前,先将数据划分为训练集和测试集,并进行归一化,以确保输出结果的准确性。

3)运行模型,将适应度函数设置为期望结果和输出结果之间的均方误差(Mean Square Error,MSE),并根据适应度函数计算每个粒子的适应度值。其中均方误差表达式如式(9)所示。

(9)

4)运行各个粒子的个体极值pbest和全局极值gbest。
5)计算每个训练样本的输出值,直至达到最大迭代次数T。最后将测试样本运用训练后的T-S模糊神经网络参数进行预测。
具体流程图如图3所示。
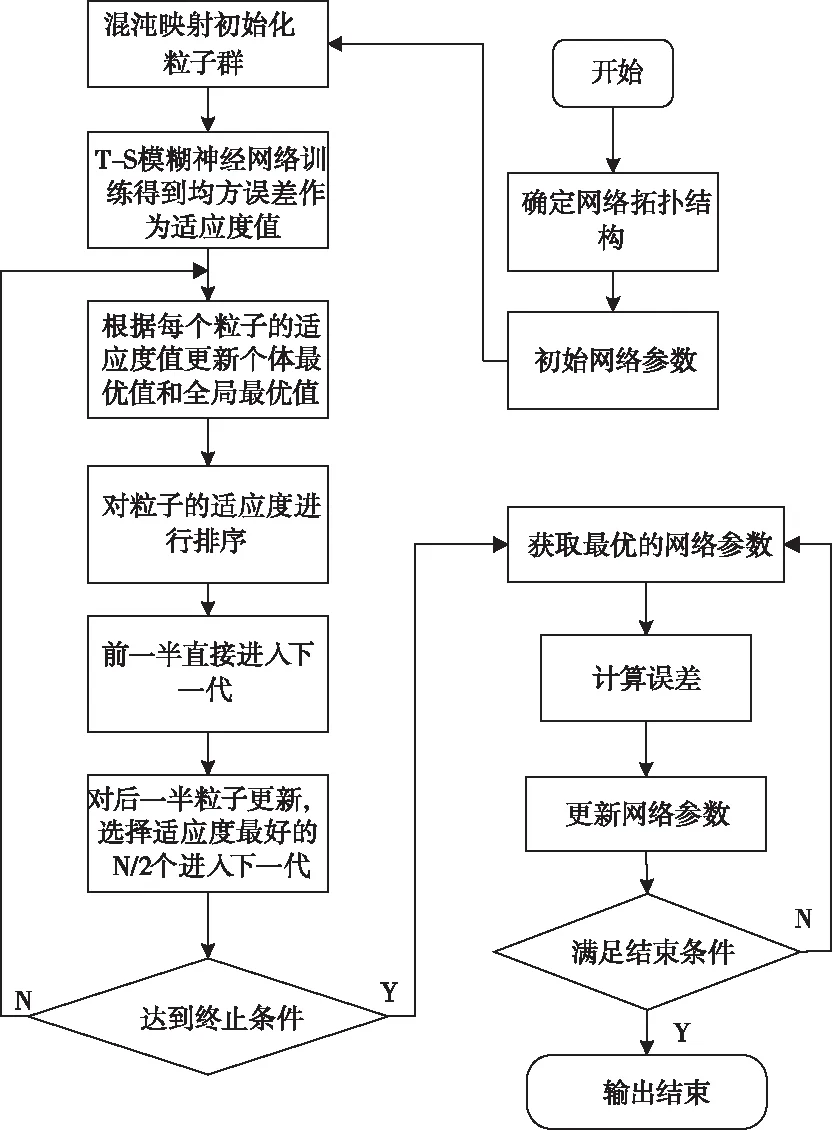
图3 改进PSO-TSFNN算法流程图
4 实验及结果分析
4.1 数据与处理
本文使用的数据为某保险公司汽车保险历史索赔数据,选取了部分个投保人信息作为存在影响的指标因子。各变量类型说明如表1所示。

表1 数据指标描述
在车险索赔数据中,存在非数值型数据,需要分层并量化将非数值型数据转变为数值型数据,如表2属性概念分层所示。

表2 变量概念分层
本文研究的车险欺诈问题为典型的二分类问题,而欺诈样本数量明显少于正常样本数量,数据不平衡的问题极大地影响了欺诈检测方法的检测效果。因此针对数据不平衡问题,本文采用SMOTE算法对少数类样本进行过采样,在一定程度上避免了过拟合现象。
4.2 模型参数与评估标准选取
将10个指标作为模糊神经网络的输入,即T-S模糊神经网络输入层具有10个节点,将模糊层节点数设置为20,将输出结果设置为是否欺诈,其中1为欺诈索赔,0为诚信索赔,因此输出层节点数为1。在本次实验中,经过SMOTE算法平衡后的数据集共有2122份车险索赔样本,取80%样本作为训练样本,剩下的20%样本作为测实验本样本进行实验。
为了充分评估模型的表现,本文选取确率(Accuracy)、查准率(Precision)、特异度(Precision)作为第一层次细致性模型性能评价指标,同时选取AUC值、F1值、均方误差作为模型整体性能评价指标。分类结果的“混淆矩阵”(confusion matrix)如表4所示。

表4 分类结果混淆矩阵
准确率、特异性、查准率、召回率、F1值分别定义如式(10)—(14)所示。均方误差表达式如式(9)所示。评估指标AUC值为ROC曲线所覆盖面积,其中AUC越大,模型的分类性能越好。

(10)

(11)

(12)

(13)

(14)
其中,TP表示实际值与预测值均为0,FN表示实际值为0预测值为1,FP表示实际值为1预测值为0,TN表示实际值与预测值均为1。
4.3 模型预测结果及分析
本文通过训练好的DPSO-TSFNN(改进粒子群算法优化T-S模糊神经网络)车险欺诈识别模型测试数据,模型的分类误差如图4所示。

图4 DPSO-TSFNN车险欺诈识别模型分类误差
从图4可以看出,基于改进PSO-TSFNN的车险欺诈识别模型分类误差相对较低,具有较高的准确率。
DPSO-TSFNN模型在测试集上的分类结果如下:TP类为203个样本;FP类为22个样本;TN类为191个样本;FN类为10个样本。根据式(12)—(14)分别计算出每一类的查准率、召回率和F1值,并计算出查准率均值为0.926,召回率和F1值得均值均为0.925,见表5 DPSO-TSFNN模型分类报告。
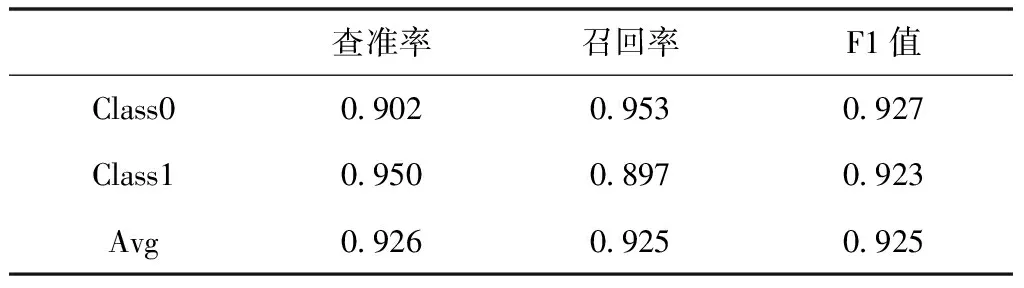
表5 DPSO-TSFNN模型分类报告
对比TSFNN、PSO-TSFNN、LDWPSO-TSFNN和DPSO-TSFNN 四种算法,选取预测集中前一百个样本数据绘制了四种算法的预测误差图像,见图5。其中,经过PSO优化过的TSFNN相比于未优化TSFNN的预测误差更小,误差基本控制在-0.3~0.2之间,LDWPSO优化的TSFNN的预测误差基本控制在-0.3~0.1之间,而DPSO优化的TSFNN的预测误差基本控制在-0.1~0之间,经分析发现DPSO-TSFNN算法预测误差更小,精度更高。

图5 四种算法误差对比
通过上述分析发现,经过PSO优化的TSFNN相比于传统的TSFNN表现更优,为了更进一步的分析改进的PSO算法的优化性能,对比了DPSO-TSFNN、LDWPSO-TSFNN、PSO-TSFNN三种算法的适应度值变化,图6可以看出,三种算法的适应度值随着迭代次数的增加不断减小,最后在一定范围内趋于稳定,其中,DPSO-TSFNN模型的适应度最小,搜索结果达到更优,并收敛速度个人更快。

图6 三种算法适应度值对比
为了更加全面评估对比不同模型的性能,从两个方面分别建立评估体系。一方面,对于本文研究的车险欺诈检测问题,准确地识别客户类型,对减少保险公司不必要的损失具有重大的指导意义,因此选取有效区别正负样本的评估指标对模型进行第一层次评估;另一方面需要利用整体性能评估指标对不同模型进行综合评估,使得模型评估更加客观公正。
从表6可以看出,在查准率变现上,即对正类样本的识别情况,DPSO-TSFNN算法变现最优,查准率达到0.950。在特异性表现上,即对负类样本的识别情况,LDWPSO-TSFNN算法表现最优,特异度达到0.911,其次是DPSO-TSFNN算法为0.897,两者相差不大,且在准确率表现上,即对总体样本识别情况,与TSFNN、PSO-TSFNN和LDWPSO-TSFNN相比,DPSO-TSFNN预测模型的准确度分别提高了24.7%、2.9%、1.4%。故相比于传统模型,本文模型具有更好的样本区分度和更高的实际应用价值。
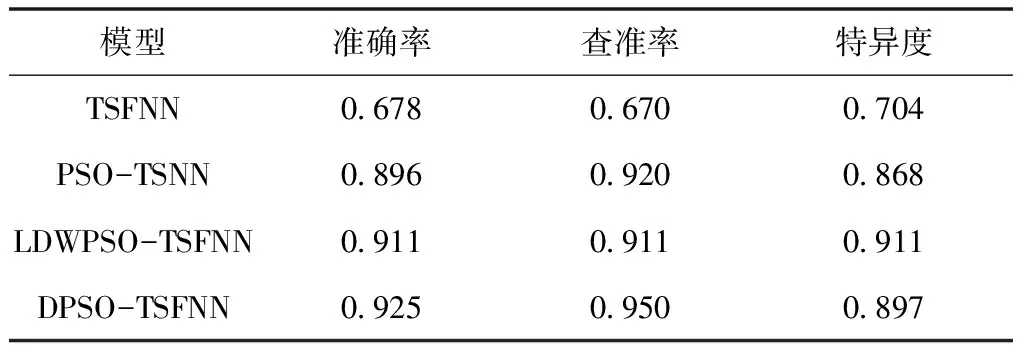
表6 模型正负样本识别性能
由表7可知,传统的TSFNN算法的各评价指标均为最低,经过PSO优化后的TSFNN的F1值、AUC值均有提升,而本文提出的DPSO-TSFNN算法表现最优,分别实现F1值达到0.925、AUC值达到0.983。且在均方误差方面,DPSO-TSFNN算法的预测均方误差也相对TSFNN算法降低了3%,表现出更好的预测精度。

表7 模型综合性能评估对比
为了更直观的对比DPSO-TSFNN算法与其它三种算法的AUC值,绘制了四种算法的ROC曲线,如图7所示,DPSO-TSFNN算法的ROC曲线覆盖面积最大,说明该算法具有更好的分类性能。所以根据上述分析可以看出,相比于TSFNN、PSO-TSFNN,LDWPSO-TSFNN三种算法,本文提出的DPSO-TSFNN的算法易于实现,具有更高的欺诈识别率、预测精度以及良好的鲁棒性。

图7 对比算法的ROC曲线
5 结论
保险欺诈检测难以识别欺诈样本以及各影响因素存在复杂的非线性关系的问题,首先通过SMOTE算法对数据集少数类样本进行过采样,有效地防止了预测过拟合现象。针对汽车保险欺诈检测存在的弊端选择了T-S模糊神经网络检测模型。为了改善检测准确率不高误差大的缺点,提出了一种改进PSO-TSFNN的汽车保险欺诈检测模型,使用改进PSO算法对TSFNN的网络系数和隶属度函数参数进行迭代寻优。并通过结合实际数据仿真对比发现:与传统的TSFNN、PSO-TSFNN和LDWPSO-TSFNN相比,DPSO-TSFNN预测模型的准确度分别提高了24.7%、2.9%、1.4%。综合考虑本文提出的DPSO-TSFNN检测算法的预测准确率更高,具有更高的欺诈识别率、预测精度以及良好的鲁棒性。
