结合多尺度特征与掩码图网络的小样本学习
2022-08-19董博文汪荣贵薛丽霞
董博文,汪荣贵,杨 娟,薛丽霞
合肥工业大学 计算机与信息学院,合肥 230601
近年来深度学习取得飞跃性进展,在计算机视觉方向,如语义分割[1]、目标检测[2-3]、图像分类[4]等领域,以及自然语言处理方向[5-6]的研究中的表现越来越好,其中以ResNet[7]为代表的一些深度网络在图像分类任务中的准确率甚至超过了人类。但是,这些网络达到这样的准确率所需要的训练样本数量是非常庞大的,而在一些情况下,人们无法获得大量样本,或者获得所需样本的代价过高,这时就要求深度网络能够通过少量样本的学习实现较好的分类能力。虽然对于人们来说这一点很容易实现,但对深度网络来说很难。主要原因是,首先深度网络参数量过大,训练这些参数理所应当地需要足够数量的样本;其次,深度网络模型结构复杂,对已有样本有着很强的表达能力,但是对未知样本的表达能力不足,因此需要有大量可用于学习的样本,尽量使这些样本的分布覆盖整体样本的分布,以避免深度网络在训练集上效果好、测试集上效果差的现象,即过拟合现象。对此,一些学者开始研究如何让机器实现人类的这种少样本学习能力,即“小样本学习问题”[8-9]。
小样本学习的研究中主要使用迁移学习的思想,即先使用相似任务的大量样本预训练深度网络,以此模拟人类积累经验的过程,然后利用得到的少量的当前任务样本进行网络模型参数的微调。迁移学习的方法虽然提高了网络模型的泛化能力,但是预训练样本与当前任务的样本分布可能差别较大,因此在研究中需要尽可能提高模型快速学习能力。据此迁移学习的思想又出现了几类主要方法:数据增强、注意力机制、元学习、度量学习。对于当前任务样本过少的问题,数据增强[10-11]是最直观的解决方法,但是虚拟样本的生成并不能覆盖真正的样本空间,因此数据增强的方法只能在一定程度上提升模型效果;注意力机制[12-13]则是让网络模型将学习的重心放在样本更重要的区域,提高了网络模型学习样本的效率;元学习[14-15]是一种让机器模仿人类根据已有经验进行快速学习的策略,这种学习策略很适合在小样本的情况下有效学习;而度量学习[16]的方法简单有效,其旨在找到一个适用于具体任务的距离度量方法,使相似样本的距离更近。
度量学习已经在小样本研究中取得了很好的效果,但是传统度量模型[17-18]利用神经网络进行分类时,存在两个问题:首先,用于分类的深度网络仅使用顶层特征进行度量学习,从特征提取的角度来看,顶层样本特征分辨率低,学习的更多是语义特征,而忽略了样本很多细节信息[19]。其次,在获得样本特征后,传统度量学习方法在求解每个类表达的过程中并未考虑到训练集中样本类间与类内的信息关联。针对以上两个问题,基于度量学习思想,本文提出以下创新点:
(1)利用多尺度特征[20]可以有效缓解单一尺度特征信息片面化的问题,基于多尺度特征的目标识别是计算机视觉领域的一个基本挑战,其应用可以有效提升智能体目标识别能力。因此本文设计了包含卷积与全局平均池化以及跳跃连接的最小残差神经网络块,并基于最小残差神经网络块设计跨尺度连接的多尺度特征提取器结构,使得提取到的特征有丰富语义信息,且减少随卷积网络深度增加而丢失的特征细节信息。
(2)图神经网络可以充分挖掘数据之间的丰富关系,并且图结构可以很容易对样本数据进行聚类,进而使数据簇更易于分类。本文提出了一种掩码图模型,通过元学习策略生成掩码,在每次结点更新的过程中从相邻结点中屏蔽掉不利于更新的结点;此外,本文图模型信息传播过程使用一种更有效的点乘注意力机制[21]而非使用带有注意力的L1距离度量。
(3)在使用融合的多尺度特征计算原型过程中,提出了特征贡献度,反映特征在嵌入空间分布与该类原型之间的位置关系,并提出了一种互斥损失,这两个创新促使模型生成更靠近真实分布中心的原型。
1 小样本学习方法
小样本学习是由Li等人[9]在2006年首次提出,研究如何使模型完成一个新任务而仅使用极少量训练样本。从仿生学的角度,小样本学习发展主要模仿人类快速学习的过程,即迁移学习的过程。Zamir等人[22]和Yu等人[23]通过多个任务之间相互迁移学习,得到多任务之间的迁移效率矩阵,以此来进行任务相似性判断以及寻求更高效的迁移。但是,即使是相似任务的高效迁移,其效果也并不能满足人们对分类的要求。因此,迁移学习又衍生出几类提升迁移效果的方法,主要有数据增强、元学习、度量学习。
1.1 数据增强
数据增强的方法旨在增加小样本任务的样本数量,以平衡任务样本数量与预训练样本数量。数据增强的实现中,Tremblay 等人[10]基于域随机化理论,使用专业的三维软件,通过在软件中调整虚拟目标的角度、光照、纹理等,以及改变目标在背景中的位置来生成需要的样本。该方法虽然可以生成大量样本,但需提前获取目标三维模型,实现过程复杂,故只能应用于特定任务。而Hariharan 等人[11]提出的模型通过模仿训练样本之间的映射关系生成新的样本,不需获取样本目标的额外信息,适用性更广。有一些数据增强的方法则结合语义信息,从另一个角度扩充了样本。Chen等人[24]使用编码器将样本映射到语义空间,在语义空间中分别根据两种语义分布(语义高斯和语义近邻)找到相近的语义,并将其通过解码器转回到图片空间从而进行数据增强。同样是利用语义信息进行数据增强,Alfassy等人[25]搭建用于对图片进行交、并、差操作的神经网络,图片的交、并、差依据图片语义所含元素,在进行端到端的训练后可以利用该网络生成新样本。数据增强需要依赖诸如目标三维模型、训练样本之间的关系以及语义等信息,但是利用这些信息进行的数据增强,只是对真实样本的模仿,这种模仿不可能实现无偏差,因此只能尽力而为。
1.2 元学习
元学习的方法是在多个任务之上进行模型的训练,学习任务之间的共性,以增强模型泛化能力,使模型在训练数据不充足的情况下提高性能。这种思想一般是通过设置元学习器、基础学习器实现,元学习器用来积累模型执行的多任务之间的共性,而基础学习器则聚焦于模型处理单一任务的性能。Munkhdalai 等人[14]和Wang 等人[26]使用CNN(convolutional neural network)作为元学习器和基础学习器并构建出元学习模型,而Ravi 等人[27]则使用了长短时记忆网络(long short-term memory network,LSTM)作为元学习器,其中LSTM 的细胞状态为元学习器的参数。更简单一点的,Sun 等人[28]和Keshari 等人[29]设置用于放缩和偏移基础学习器卷积核参数的参数作为元学习器参数。还有些元学习的实现偏重于模型快速适应能力,典型的模型为MAML(model-agnostic meta-learning)[15],它在训练时将每个任务对模型初始参数的优化结果通过梯度求和的形式综合在一起,进行梯度的反向传播,使模型有很好的泛化能力,从而在新任务到来时仅进行少量样本的学习就可以达到较好的效果。Boney 等人[30]将MAML 算法应用到半监督任务中,也取得了不错的效果。MAML 虽然有很强的泛化能力,但在一些任务中,元学习阶段会出现过拟合现象。Jamal等人[31]提出的模型扩展了MAML,提出了两种新范式避免模型元学习阶段训练过拟合,同时提升模型的泛化能力。元学习能够有效进行“经验和知识”的积累,并指导模型对任务进行快速学习,但元学习器的设置会增加模型复杂度,因此本文设计了一个元学习器仅用于生成掩码,而使用更加简单有效的度量学习方法作为基础学习器。
1.3 度量学习
度量学习的方法是模型将样本映射到特征空间,并进行相似性度量,以找到和测试样本最相似的标注样本,从而实现分类。其中度量方法的选取有两种情况:(1)使用传统固定的距离度量方法,如欧式距离度量、余弦距离度量等。Koch等人[16]提出的孪生网络和Snell等人[18]提出的原型网络(prototypical networks,PN)分别使用了L1距离与欧式距离,Vinyals 等人[17]提出的匹配网络(matching networks,MN)则使用了余弦距离作为度量方法,这些模型中由于度量方法是固定的,他们将研究的重心放在如何更好地获得用于度量的特征向量。孪生网络设计了一种对称的网络结构,将要比较的两个样本分别输入到这个网络对称的两部分中,在网络的输出端将两部分提取到的特征进行L1距离度量,得到两个样本属于同一类的概率;MN则将提取到的支持集特征输入到一个双向LSTM 中,整个支持集作为上下文,以消除每个任务随机选择支持集而产生的差异性。而PN是通过找出每个类在特征空间中的原型即类在嵌入空间中的特征表达,用于度量。(2)使用参数可学习的度量方法。这类方法过去如Xing 等人[32]的研究一样通过在度量函数中设置可学习参数而实现,而现在更多的是搭建专门用于距离度量的神经网络,如Sung 等人提出的关系网络[33]等。度量学习模型在设计时原理清晰,结构相对简单,同时,通过寻找相似样本而实现归类的思想使少样本学习更有效。而最近,很多度量学习的方法,通过图神经网络(graph neural network,GNN)[34-35]来组织和挖掘样本关系并用于距离度量,这些研究取得了不错的效果。但是这些传统图模型在结点更新时使用无差别的更新策略,会造成无用信息传播,干扰分类。针对这个问题,本文设计一个包含掩码的新的GNN网络,通过掩码筛选边来指导图中结点更新,实现特征更好的信息交互,从而有更好的分类效果。
2 方法
这部分首先介绍小样本学习的问题定义,然后介绍本文方法的整体架构以及详细的实现过程。
2.1 问题定义
小样本学习问题在计算机视觉领域的任务T中,一般将数据集划分为训练集Tra、支持集Sup以及查询集Que。其中训练集来自单独的样本空间,与支持集和查询集样本类别互斥,用于训练阶段预训练网络模型。支持集与查询集的样本类别完全相同,但是样本互斥,其中支持集只有少量样本,用来在测试阶段训练网络模型,查询集用来测试模型使用支持集训练后对其中新类别的识别准确率。由于支持集只含有少量样本且样本类别未出现在训练集中,这样就可以检测模型在少样本情况下的学习能力。一般,如果支持集中有N类的样本,且每类有K张样本图片,则称这个小样本任务为“N-wayK-shot”任务。
Vinyals 等人[17]提出了周期性的策略以在训练阶段模拟小样本任务的设定,这种训练策略由于融入元学习思想,在小样本分类任务中十分有效,也因此被广泛使用。具体的,如果小样本任务为N-wayK-shot任务,则在训练阶段的每个周期,从训练集中随机选择N个类别的样本,并从这N个类别样本每一类中随机挑选出K个训练样本模拟支持集;再从这N个类别剩下的样本中随机挑选C个样本作为查询集,则有。训练阶段使用这样模拟测试阶段的数据设定进行周期性迭代训练,直到收敛。
2.2 整体架构
本文方法主要分为以下几部分:(1)用于提取多尺度特征的,基于最小残差神经网络块与卷积块的多尺度特征提取器;(2)用于增强多尺度特征的掩码图网络;(3)样本分类及损失函数部分。如图1所示,为本文方法在小样本学习“5-way 1-shot”分类问题上的整体流程。
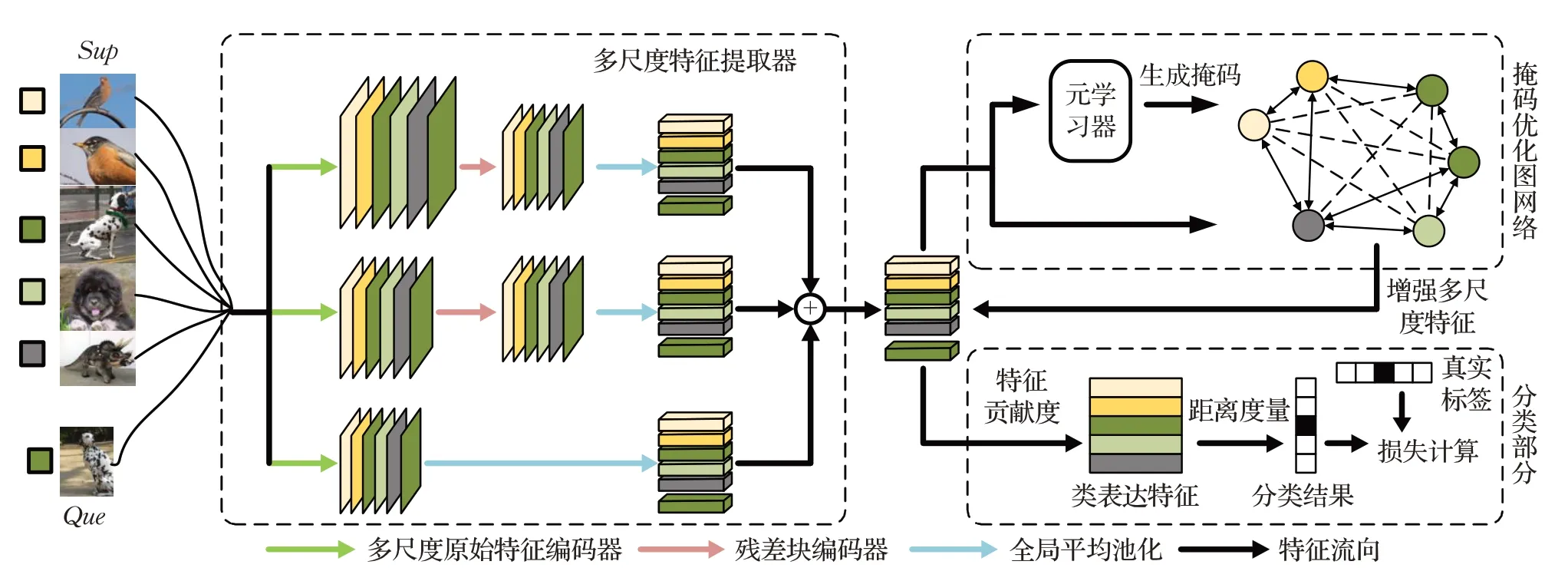
图1 本文方法的整体流程Fig.1 Overall framework of proposed method
2.3 多尺度特征提取器
匹配网络[17]和原型网络[18]等小样本学习的经典网络模型采用由4个卷积块组成的四层卷积网络(ConvNet)提取特征,但是单一尺度的特征对样本信息利用不充分[20],本文基于四层卷积神经网络,设计多尺度特征提取器。如图2所示,多尺度特征提取器共有3个分支,每个分支前半部分为卷积块组成的原始特征编码器,卷积块的结构如图3(a)所示;后半部分为最小残差神经网络块组成的残差块编码器。
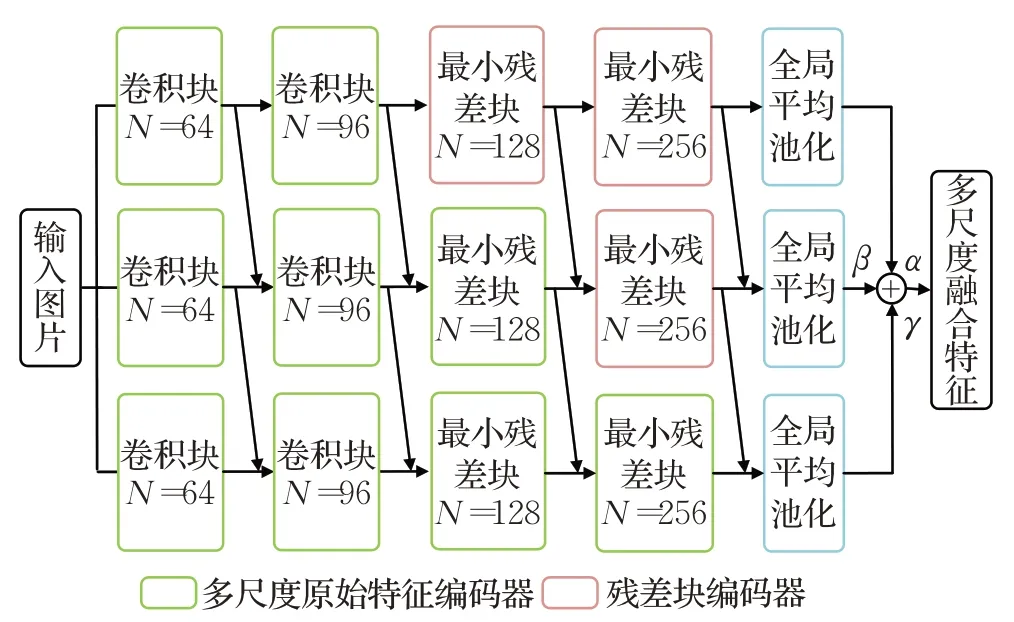
图2 多尺度特征提取器结构Fig.2 Architecture of multi-scale feature extractor
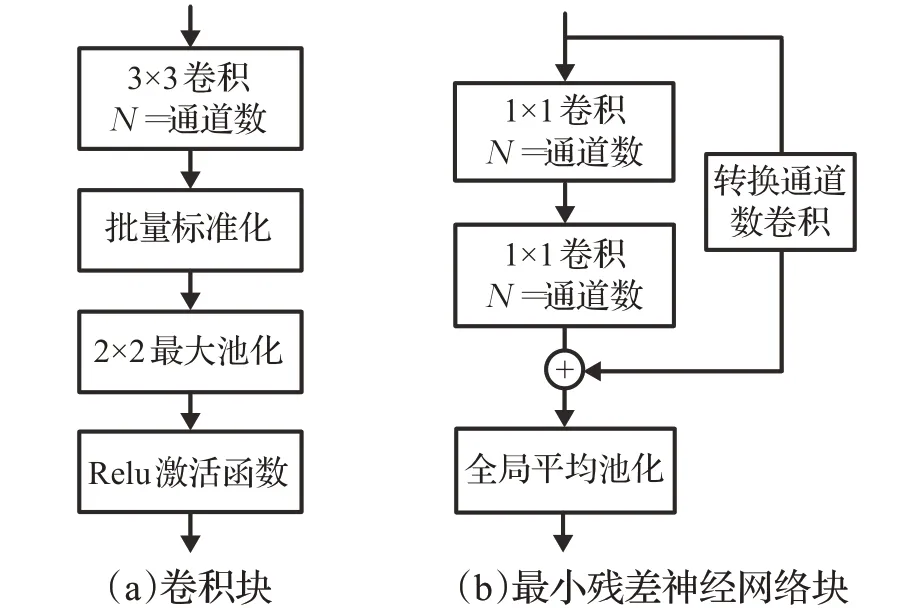
图3 最小残差神经网络块与卷积块Fig.3 Smallest residual block and convolutional block
最小残差神经网络块由1×1 卷积与全局平均池化层(global average pool,GAP)组成,如图3(b)所示。在最小残差神经网络块中加入转换通道的跳跃连接,以确保特征细节信息的充分提取。对于输入x,经过最小残差神经网络块得到的输出如式(1):
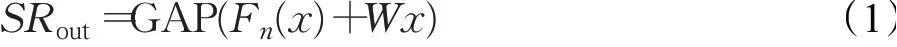
其中,Fn是输出通道为N的两层1×1 卷积,W是将x转换成通道数为N的卷积操作,GAP 采样尺寸为2×2。多尺度特征提取器相邻分支之间通过跨尺度连接对特征按元素求和,将他们联系在一起,避免同一样本的多尺度特征割裂,同时将细节信息从浅层特征流向深层,增强深层特征的表达能力。
任务T={xi|xi∈Sup⋃Que}提取得到第l级尺度特征f l(xi),如式(2):
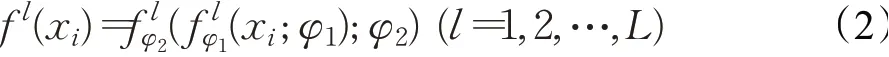
在每个分支网络最后使用全局平均池化代替全连接将特征图转化为特征向量,通过设置可学习参数作为注意力进行L个尺度特征的融合,得到多尺度融合特征,如式(3):

多尺度特征提取器的3个分支分别使用2、3、4个卷积块作为原始特征编码器,提取到大小为20×20、10×10以及5×5 像素的原始特征图。深度学习网络中,不同深度的特征编码器提取到的特征携带不同比例的细节信息和语义信息[19-20],浅层编码器提取到的特征分辨率高,图片细节保留较多,细节信息丰富;而深层编码器的特征分辨率低,特征更为抽象,含有更多语义信息。对多尺度原始特征使用最小残差网络块组成的残差块编码器进行信息提取。通过残差块中的1×1 卷积对原始特征进行跨通道信息交互[4,36],提取信息的同时较大程度保留了原始特征的细节特性和语义特性。最后通过GAP将提取到的多尺度特征采样为相同大小,进行多尺度特征融合,得到语义与细节信息兼具的多尺度融合特征。
在网络增加分支带来的实现难度方面,本文提出的多尺度特征提取器,基于ConvNet的卷积块以及设计的最小残差神经网络块,搭建网络时,将四层卷积网络的卷积块的数目从4提升到9,同时加入了3个最小残差神经网络块,使网络卷积核参数增加了529 856个,提升了网络过拟合的风险。但是另一方面,受文献[36]的启发,将ConvNet中与最后一个卷积邻接的全连接层替换为全局平均池化层,在不影响网络分类性能的基础上,使其减少了全连接层的819 328 个参数,最终使多尺度特征提取器所有分支参数量之和维持在小于ConvNet的水平,从而避免了多尺度特征提取器难以训练的情况。多尺度特征提取器与ConvNet 网络块参数量对比如表1 所示。但是多尺度特征提取器在实际实现时会加大显存占用量,并且其中添加的跨尺度连接,增加了网络的运算量,一定程度降低了效率,因此在实验部分验证了网络的实时性。
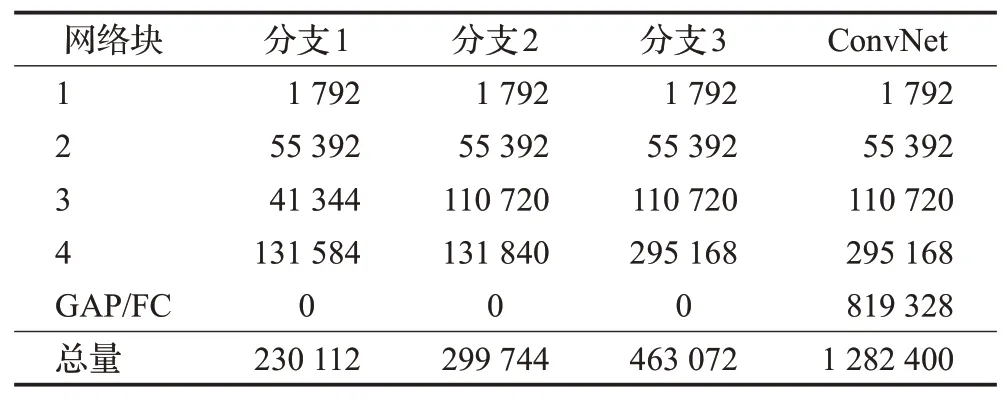
表1 本文特征提取器与四层卷积网络参数量对比Table 1 Parameters comparison of proposed feature extractor with ConvNet
2.4 掩码图网络
大部分小样本模型在分类过程中仅考虑特征的标签信息,并未考虑到特征之间的信息关联,而图结构可以充分挖掘数据之间的丰富关系,通过图结点间信息交互增强多尺度融合特征。但是传统图更新时采用无差别更新策略,在更新一个结点时无选择地使用相邻结点。图神经网络最早由Gori等人[37]提出,他们构建的图神经网络中结点的状态取决于3个因素:结点自身的标签、相邻结点状态和相邻结点标签。而无差别的更新策略忽略了相邻结点标签这一因素,导致非同类信息在同类结点之间传播。本文提出选择性更新策略,通过筛选边,区分结点相似度,实现在更新时考虑相邻结点标签这一因素。本节将介绍本文提出的掩码图网络,其结构如图4。
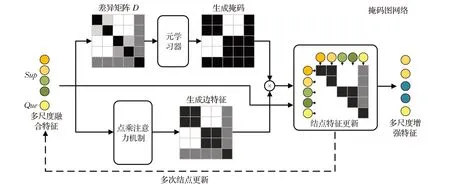
图4 掩码图网络框架在“2-way 2-shot”分类问题上的流程Fig.4 Framework of mask GNN on“2-way 2-shot”classification
首先是图网络的构建。将特征提取器输出的多尺度融合特征构建为图的原始结点V0i =F(xi),并通过比较标签获得初始化边的值e0ij,如式(4)所示。
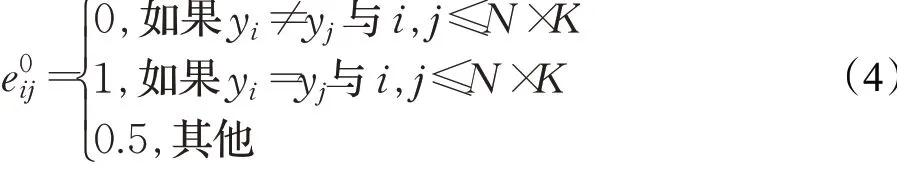
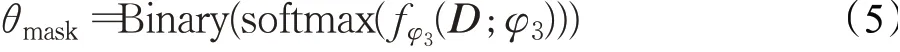
使用生成的掩码与边矩阵按元素相乘,置零冗余和负增益的边,从而筛出对图的更新有增益的边。根据边特征计算出结点间需要传播的信息Inf n Nei→i,如式(6):

将增益信息融入结点完成一次结点更新,得到新的结点,如式(7)所示:
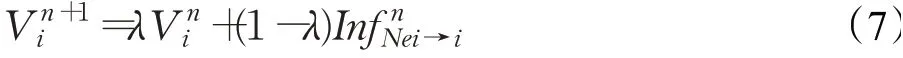
式中,λ为超参数。每一次结点更新过后,使用点乘注意力[21]重新计算边特征用于新一次结点更新,如式(8)所示:
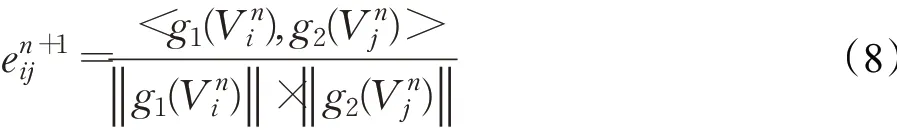
式中,g1与g2是用于特征转换以更好地度量结点相似性的线性变换。
传统图模型将结点间的L1距离输入多层感知机得到边特征[35]。这种度量方式通过引入额外的卷积神经网络或全连接层,让网络自己学习输入结点特征各个维度上的权重,达到添加注意力的目的。而本文使用的点乘注意力机制[21],属于一种乘法注意力,通过结点特征向量点乘即可求得注意力。由于未引入额外神经网络进行权重学习,同时,点乘的计算在网络模型实施中可批处理为矩阵运算,进而可以通过高度优化的矩阵乘法库并行地计算,加快了图模型推理的速度。此外,本文使用的点乘注意力在传统乘法注意力的基础上增加了缩放因子,避免输出边特征过大造成的归一化之后的梯度过小问题。实验表明,本文的掩码图在达到较高的分类准确率的同时有较好的时间性能。
2.5 分类损失
本文使用增强的多尺度特征计算类表达特征,即类原型,并通过距离度量的方式进行分类。在类表达特征的计算中,原型网络[18]基于伯格曼散度思想提出均值类原型,Banerjee 等人[38]证明一组点在特定的空间中如果满足任意概率分布,这些点的均值点是这个特定空间中距离这些点平均距离的最小值点。本文认为在小样本情况下,当支持集仅有极少数样本时,不满足任意概率分布,不能简单地通过求均值得到类表达,而应评估嵌入特征与真实类原型之间的距离再计算。如样本中存在目标遮挡、目标仅有部分在图片中、目标过小或过大等,将导致样本特征远离类原型。因此提出一种预估机制,通过特征贡献度改进均值型原型,生成更接近真实分布中心的类原型。
对于类别为m的支持集Supm中的样本Vi,比较该样本与Supm中其他样本的分布情况来获取贡献度。具体的,先通过求均值的方法计算出类Supm在特征空间的伪原型Pm′,如式(9):

使用SoftMax 函数,归一化类中样本Vi到所属类伪原型的距离与其他伪原型距离,得到贡献度Ci,如式(10):
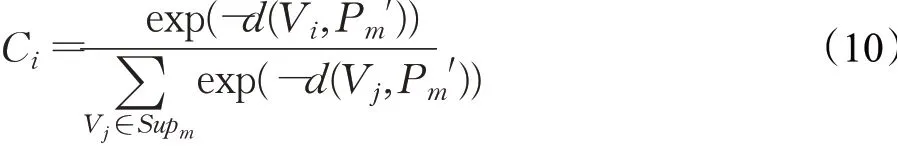
根据计算得到的样本特征贡献度,计算优化的类原型Pm,如式(11):

实验表明,使用特征贡献度求出的原型可以更好地表达类特征,效果示意如图5 所示。图中共有大象、骆驼和麋鹿3个类别,分别用绿色、黄色和红色区分,每个类别5个支持集样本,1个测试集样本。由图可以看出,当部分样本由于目标不明显或不完整导致其嵌入向量偏离类原型较远时,本文利用特征贡献度求出的类原型相比于均值原型更有代表性,可以避免一些测试样本分类错误,如图中大象、骆驼类别。图中虚线表示使用均值原型分类时通过度量最近距离得到的分类结果,实线为使用本文改进原型时的分类结果。
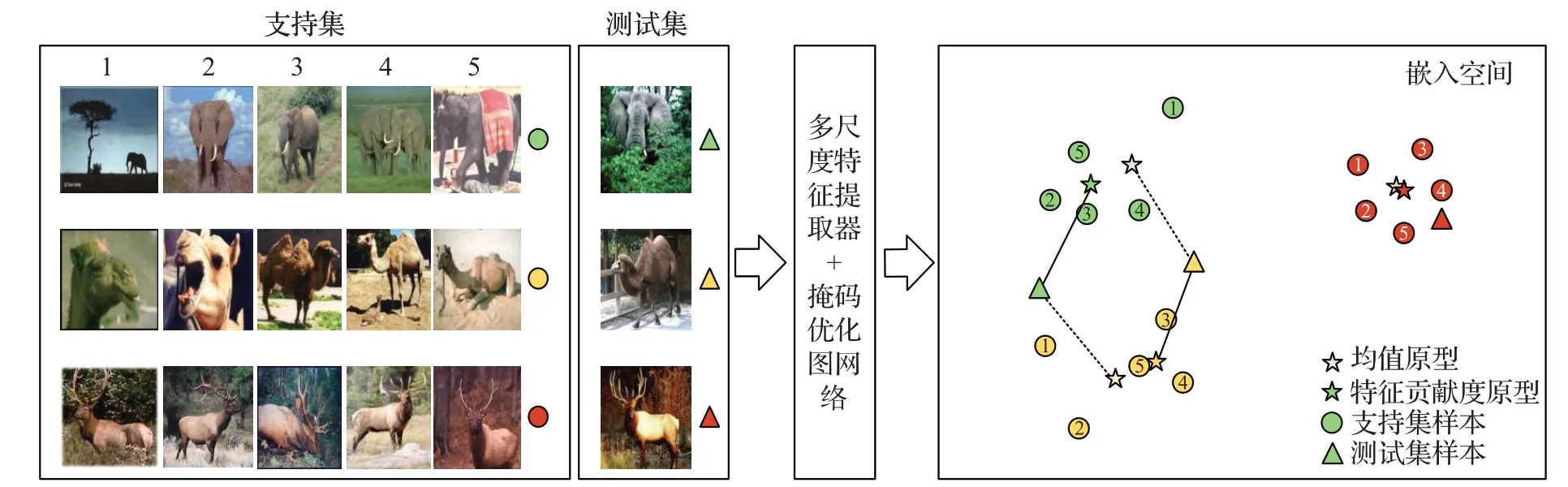
图5 特征贡献度计算原型效果示意图Fig.5 Effect diagram of prototypes computed with feature contribution degree
同时,本文提出了一个新的互斥损失,在模型学习的过程中,促使原型互斥地生成,从而提高度量学习能力。损失计算过程中,使用式(12)的度量机制度量样本到原型的距离:

式中,f1与f2是特征转换神经网络。所属类别为Supm的样本Vi的互斥损失,通过度量其与非本类原型的平均距离获得,如式(13):
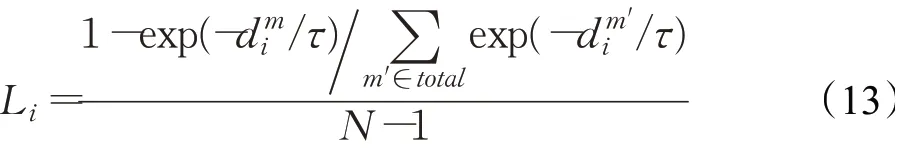
式中,N为类别总数,m′表示m之外的类别,τ为温度参数,用于控制不同样本损失差异及大小。
当前批次所有支持集样本损失和如式(14):

式中,B为批大小。
支持集样本与其他类原型之间的距离越小,损失越大;距离越大,损失越小。因此这个损失使原型尽可能远离其他类样本簇,促使原型互斥。
对测试样本进行分类,计算查询集样本与各类原型的距离,最小的进行标签传播。使用交叉熵损失作为分类损失,每一次反向传播损失的分类损失为一次迭代的所有批次样本的交叉熵损失和,如式(15)所示:

式中,Yb和Y^b分别表示第b批次查询集样本的真实标签和预测标签。最终模型每个训练周期反向传播总损失为互斥损失与分类损失之和,见式(16):

3 实验与结果分析
3.1 数据集
本文在MiniImagenet、Cifar-100和Caltech-256数据集进行了5-way 1-shot 与5-way 5-shot 分类任务的实验,下面分别介绍这3个数据集。
MiniImagenet 数 据 集 由Vinyals 等[17]提 出,是 从Imagenet中抽出的子集,专用于小样本学习研究。数据集共包含100个类别,每个类别包含600张84×84 的彩色图片。将数据集按Ravi等人[27]的设定划分:64个类别用作训练集,16个用于验证集,20个用于测试集。
Cifar-100 包含100 个类别的样本,每个类别600 张32×32 的彩色图片,另外,这100 个类别来自于20 个超类。在研究时,划分60个类别作为训练集,16个作为验证集,20个作为测试集。由于其中样本分辨率被调整为32×32,分类任务难度增大。
Caltech-256 数据集包含256 个类别,共计30 607 张图片,这些图片都下载自谷歌图片,并手工筛除了不合类别要求的图片。数据集中每个类别最少80 个样本,并引入了一个新的更大的复杂类别来测试背景误判能力。
3.2 实验设置
实验中,对于一些超参数以及其他实验设置如下:模型训练阶段,使用自适应矩估计算法(adaptive moment estimation)优化模型参数,并设置初始学习率为1×10-3,权重衰减为1×10-6。对MiniImagenet和Cifar-100数据集,每经过15 000 个训练周期学习率衰减为一半,共训练100 000个周期,Caltech-256数据集则由于样本较少,设置为12 000个周期学习率衰减一半,共训练84 000个周期。本文进行了5-way 1-shot实验与5-way 5-shot实验,训练时批大小分别设置为40 与20,即分别将40 与20个任务同时计算损失,用于反向传播。掩码图网络进行3次更新且更新超参数λ取值0.5,互斥损失中温度参数τ设置为0.8。在验证与测试阶段,随机抽取每类15个样本作为查询集。所有实验均在NvidiaRTX 2080Ti上完成。
3.3 小样本分类结果与分析
3.3.1 与基于度量学习方法进行对比
将本文方法和基于度量学习的经典模型MN[17]、PN[18]、TEAM(transductive episodic-wise adaptive metric)[39]在MiniImagenet、Cifar-100、Caltech-256 数据集上进行5-way 1-shot 和5-way 5-shot 任务的对比实验,结果如表2 所示。实验结果表明,与经典的度量方法比较,本文在5-way 1-shot和5-way 5-shot分类任务上都有较大的分类准确率提升,说明本文方法优化了度量学习的结果,能有效用于小样本学习的分类任务。
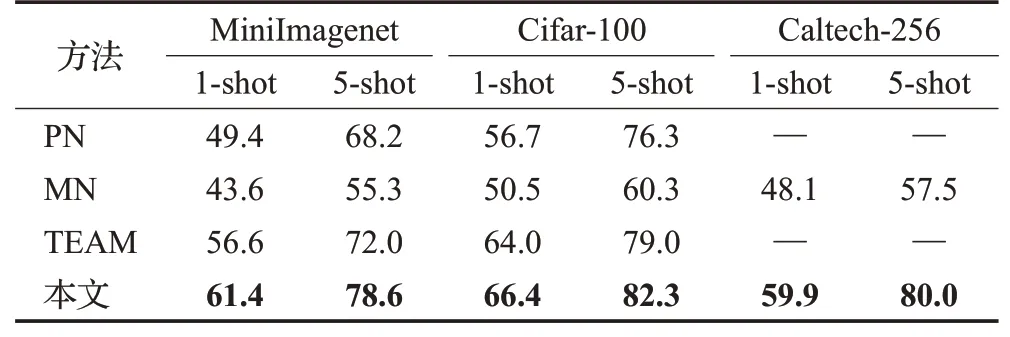
表2 度量学习方法在各数据集上的5-way分类结果Table 2 5-way classification results of metric learning methods on different datasets %
为了更直观地显示本文各部分对度量学习的优化效果,使用t-SNE(t-distributed stochastic neighbor embedding)[40]可视化了初始测试样本、多尺度特征提取器提取到的多尺度融合特征以及掩码图优化后的多尺度融合特征,如图6所示。
图中圆点表示支持集样本,叉号表示查询集样本,不同颜色表示不同的标签,图6(a)、(b)、(c)依次为初始样本、多尺度融合特征和掩码图优化后的特征。由图可以看出原始样本映射到二维空间后,不同类别样本混杂在一起,无法进行有效区分;多尺度融合特征相比于原始样本已经有一定程度的聚类,说明本文的多尺度特征提取器有利于度量学习的进行;掩码图增强的特征则在二维空间中分簇明显,并且增强的查询集样本距离所属类别的支持集簇很近,能很好地用于分类,证明了方法的有效性。
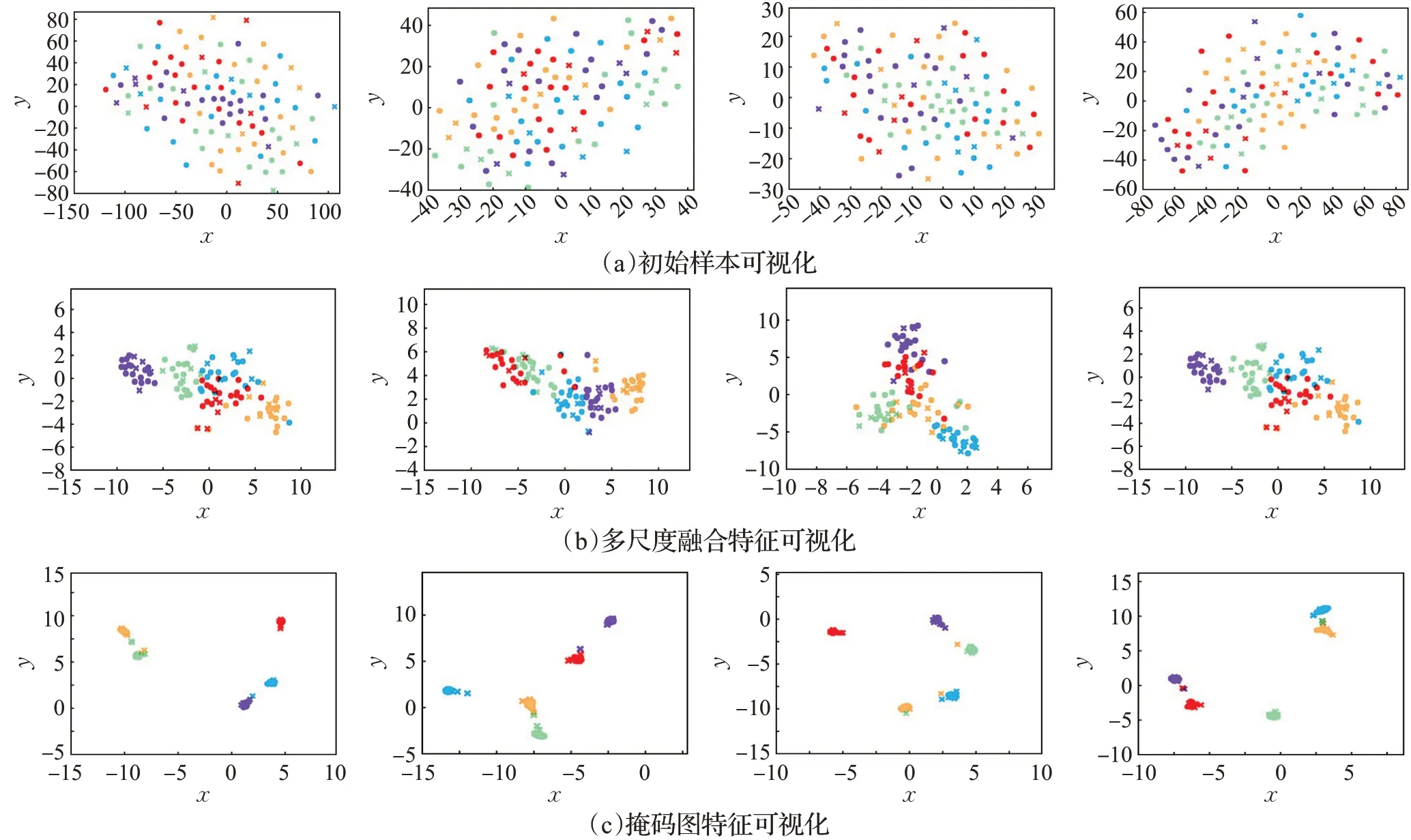
图6 样本(特征)的t-SNE可视化Fig.6 t-SNE visualization of samples(features)
3.3.2 与基于图方法进行对比
基于图的方法比较经典的有Liu 等人提出的TPN(transductive propagation network)[34]和Kim 等 人 提 出 的EGNN(edge-labeling graph neural network)[35]。TPN通过ConvNet 提取所有样本特征并用这些特征构建出一个图结构,在标签传播阶段通过转导推理的方式完成标签传播。EGNN提取特征的过程与TPN相同,而EGNN构建出的图结构中加入了边特征来表示边连接的两个结点的相似程度。构建好这种图结构后,在其上进行数次结点和边的更新,根据最终获得的边特征来判断两个样本属于同一类的概率。
本文和TPN、EGNN在不同数据集上进行5-way 1-shot和5-way 5-shot 任务的对比实验,结果如表3 所示。由表3 可以看出,本文方法在MiniImagenet 和Caltech-256数据集上提升明显;而在Cifar-100 数据集上,相比于EGNN 的分类性能提升不明显。这是由于该训练集中样本尺寸过小,使用多尺度特征提取器与ConvNet相比优势不明显。说明本文方法在样本原始特征充足情况下,可以更充分提取并利用丰富的特征信息,有效提高分类准确率;而在样本本身特征不够充裕的情况下,仅能较小提升特征的提取,略优于传统图模型。
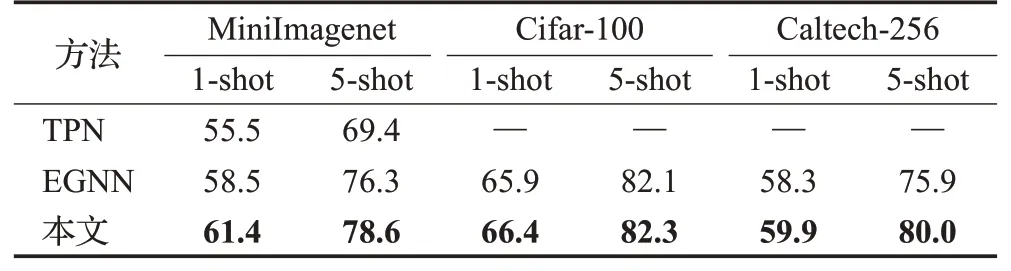
表3 基于图的方法在不同数据集上的5-way分类准确率Table 3 5-way classification accuracies of GNN methods on different datasets %
此外,在二维空间可视化了本文掩码图经过选择性更新得到的特征,并与EGNN无差别更新策略得到的特征进行了对比,如图7 所示。图7(a)为EGNN 的特征,图7(b)为本文增强特征。由图可以看出,EGNN中支持集样本的簇相互之间的距离较近,查询集样本离对应支持集样本簇比较远;而本文中支持集样本的簇相互之间的距离大,查询集样本大部分都在同一类别支持集的簇中。这说明本文的选择性更新策略缓解了类内信息的类间传播问题,使不同类特征易于区分。
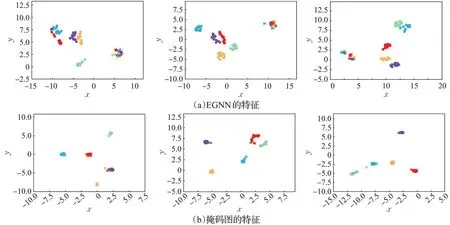
图7 选择性更新与无差别更新策略对比Fig.7 Comparision of selective update with undifferentiated update strategies
3.3.3 与其他方法进行对比
除了基于度量学习和基于图的方法,常用于小样本学习研究的还有元学习和数据增强方法。其中元学习效果较好的有FEAT(few-shot embedding adaptation with transformer)[41]和DTN(diversity transfer network)[42]。FEAT 提出了一种自适应转换特征的方法,使特征变为任务相关,增强泛化能力。DTN 通过新的有效的元分类损失进行类间样本多样性的学习。数据增强方法中,效果较好的有通过语义进行增强的Dual TriNet[24]。
将本文方法与这些经典方法在不同数据集上进行5-way 1-shot 和5-way 5-shot 任务的对比实验,结果如表4所示。实验结果显示,与基于元学习的模型MAML[15]、DTN、FEAT相比,本文方法的性能都有较大提升。由于数据增强的模型Dual TriNet使用更深的ResNet作为骨干网络,使其在训练样本较少的Caltech-256数据集上有更好的分类效果。
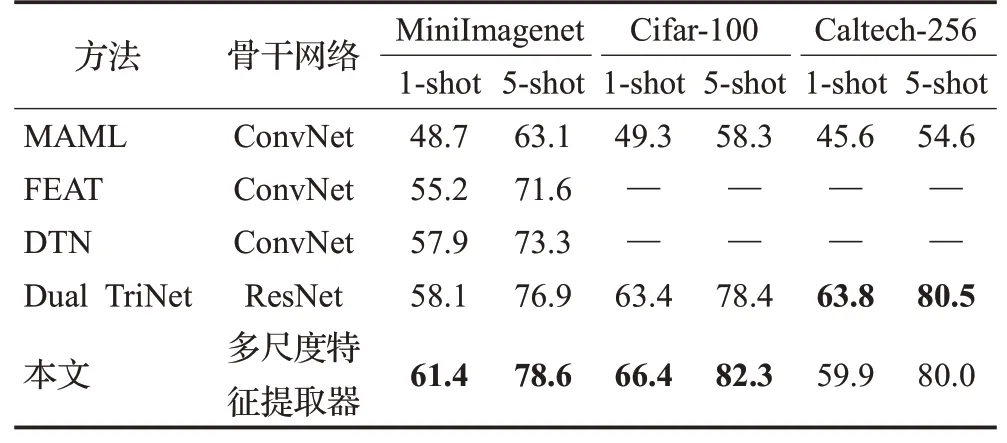
表4 与其他方法在各数据集上的5-way分类结果对比Table 4 Comparison of 5-way classification results with other methods on different datasets %
值得注意的是,本文方法在部分数据集上结果优于Dual TriNet,在MniImagenet 上5-way 1-shot 与5-way 5-shot 分类结果分别提高3.3 个百分点与1.7 个百分点,在Cifar-100 上分别提升3.0 个百分点与3.9 个百分点。证明了本文方法对特征信息的提取能力与ResNet模型有较强竞争力。
3.3.4 效率分析
由于本文在传统度量学习的基础上,构建了较为复杂的图神经网络,并且在图中添加了元学习器,增加了网络的参数量,提高了网络复杂度。为验证本文方法的执行效率,对其参数进行了分析,对其运行速度进行了实验,并与不同方法进行对比分析。
本文采用5-way 1-shot的设定进行对比实验,每类随机抽取15个样本作为查询集,批大小设置为40,结果如表5 所示。MN[17]和PN[18]使用四层卷积做嵌入网络,参数量低(1.2×106),方法实时性好。RN[33]使用了更复杂的嵌入神经网络,运算复杂度较高,效率较低。EGNN[35]使用四层卷积作为特征提取器,其构建的图神经网络中结点与边的更新通过卷积神经网络和全连接层实现,模型参数量大,效率较低。本文方法多尺度特征提取器参数量(9.0×105)小于四层卷积,而掩码图部分,更新时使用的点乘注意力未增加参数量,元学习器参数量为4.0×105。整个网络参数量为1.3×106,与PN相近,但是本文跨尺度连接、图更新、掩码生成等操作增加了计算量。实验时发现掩码图更新次数的改变对分类准确率的影响较大,但是对耗时的影响轻微,因此采用分类效果最好的3次更新与其他方法进行对比,此时本文方法耗时约为PN的1.2倍,但是分类准确率相比于PN提升明显。此外,本文方法在获得更高准确率时的效率仍高于EGNN,说明本文方法在达到较高分类性能的情况下保持较高效率。

表5 不同方法效率对比Table 5 Efficiency comparison of different methods
3.4 消融实验与分析
为了验证本文方法的有效性,并对本文方法中多尺度特征提取器、掩码图网络、特征贡献度和互斥损失三部分的效果有进一步了解,在MiniImagenet、Cifar-100、Caltech-256 数据集上进行了消融实验的研究,结果如表6 所示。本文模型在原型类度量网络的基础上融入多尺度特征模块以及掩码图模块,因此消融实验采用PN[18]作为对比的基准方法。
3.4.1 多尺度特征提取器的效果
如表6 所示,使用“PN+多尺度特征”的分类准确率与PN 相比在MiniImagenet 上1-shot 与5-shot 分别提升5.1 个百分点与6.1 个百分点,在Cifar-100 上分别提升4.7个百分点与1.4个百分点,证明多尺度特征提取模块提取到的特征比单一尺度特征更为有效。类似的,“PN+多尺度特征+掩码图”与仅使用掩码图相比,在MiniImagenet上1-shot与5-shot都提升了1.6个百分点,在Cifar-100上分别提升1.6个百分点与1.7个百分点,这说明多尺度特征提取器提取到的信息在图结构中是可传播的,并且这些信息对分类起到了积极作用。
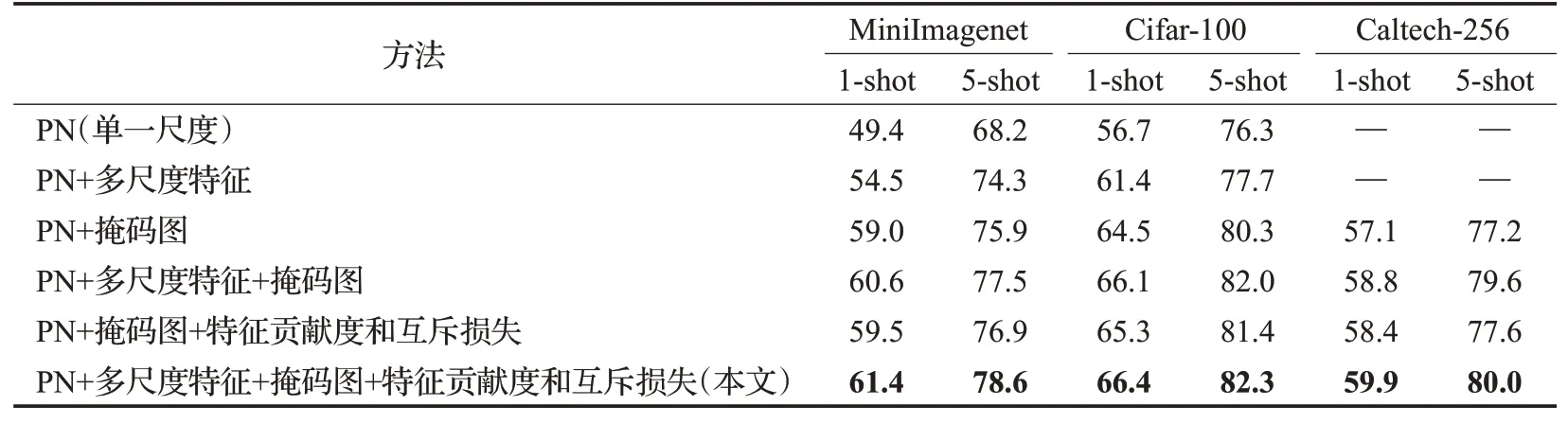
表6 本文方法在不同数据集上的5-way消融实验Table 6 5-way abalation experiment of our methods on different datasets %
3.4.2 掩码图网络的效果
如表6 所示,使用“PN+掩码图”与PN 相比,1-shot和5-shot 在MiniImagenet 上分别提升了9.6 个百分点与7.7 个百分点,在Cifar-100 上分别提升7.8 个百分点与4.0 个百分点;“PN+多尺度特征+掩码图”与仅使用多尺度特征相比,1-shot 和5-shot 在MiniImagenet 上分别提升了6.1个百分点与3.2个百分点,在Cifar-100上分别提升4.7 个百分点与4.3 个百分点。这表明掩码图对特征信息挖掘以及对特征的增强具有很好的效果。
为了进一步了解本文掩码图网络的有效性,本文可视化了掩码图中的边特征,如图8 所示。图中矩阵为5个支持集样本与对应类别的5 个查询集样本两两之间的边特征,图8(a)~(d)分别为第1、2、3次掩码图更新后的边和边的真实值。矩阵中不同颜色表示不同边特征值,样本越相似,边特征值越大越接近红色,反之,边特征越小越接近蓝色。如图所示,经过掩码图的更新,边特征快速向真值变化,并且每次更新过后,边特征的差异程度也发生变化,需要元学习器动态学习这种变化,增强泛化能力。
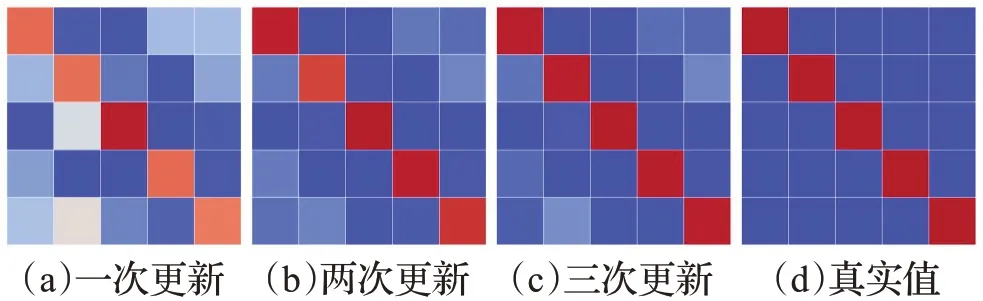
图8 掩码图中边特征的可视化Fig.8 Visualization of edge features in mask GNN
但是当同类样本差异较大的情况下,本文的元学习器在生成边掩码时会将同类样本判断为不同类别,从而切断它们之间的信息传播,造成掩码图网络失效,如图9所示。图9(a)为支持集样本,图9(b)为查询集样本,图9(c)为它们对应边特征矩阵的可视化。同一列样本属于同一类,由左至右分别为键盘、蚌、电脑显示屏、笔记本电脑、保龄球。由图9 可以看出,当同类样本不相似,而不同类样本相似时,边特征更新结果与真值相差较大。说明本文元学习器区分结点间信息能否用于传播时对样本差异度有很强的依赖性,这是由于元学习器的输入为样本差异矩阵导致的。
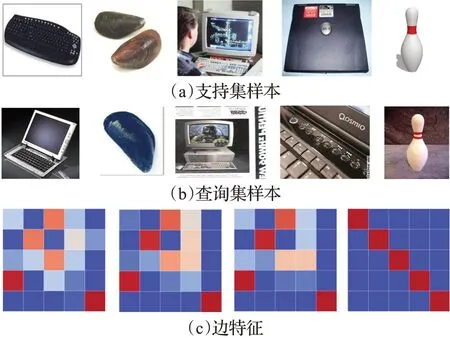
图9 困难任务边特征的可视化Fig.9 Visualization of edge features of difficult task
3.4.3 特征贡献度和互斥损失的效果
特征贡献度和互斥损失应用于“PN+掩码图”与“PN+多尺度特征+掩码图”,模型分类效果也都有提升,证明了本文对均值类原型计算方法改进的有效性。图10是本文互斥损失添加前后模型训练阶段损失的变化情况。
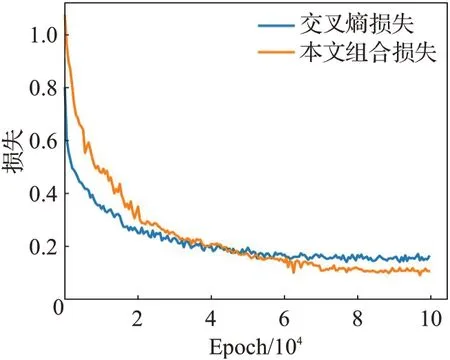
图10 损失函数曲线Fig.10 Loss curves
由图10 可以看出,本文组合损失在训练初始阶段为1.3,高于交叉熵损失的0.8。这是由于本文组合损失在交叉熵损失的基础上加上了互斥损失,训练开始阶段交叉熵损失相差不大的情况下本文组合损失的值更大。随后两者都开始下降,在42 000个Epoch时本文组合损失开始低于交叉熵损失,并在之后的训练中保持较低值直到收敛。这是由于本文的互斥损失促进了原型互斥地生成,提升分类准确率,降低了交叉熵损失,使总损失维持在较低水平。本文组合损失在70 000 个Epoch 时开始收敛,而交叉熵损失在50 000 个Epoch 时开始收敛,相比于本文收敛更快。分析原因,是由于组合损失更为复杂,在模型参数量不变的情况下,加入的互斥损失在模型训练的前中期维持在较高值,延缓了收敛速度,在模型训练后期降到较低值。消融实验结果及损失曲线表明提出的互斥损失优化了模型训练,使模型分类性能提高。
4 结束语
本文提出的模型基于度量学习与元学习方法,致力于解决小样本分类训练样本过少导致的可用于模型训练信息不足的问题。传统度量学习存在仅使用顶层特征造成的信息单一的问题,对此本文设计了一种多尺度特征提取器,使模型提取到样本信息更为丰富的多尺度融合特征,用于模型后续分类;传统基于图神经网络的方法在处理小样本分类时存在结点无差别更新的问题,对此本文结合元学习机制以生成掩码的方式进行图结点的选择性更新,掩码图通过结点间更为有效的信息交互进一步增强了多尺度融合特征;此外,本文提出特征贡献度和互斥损失对均值类原型求解过程进行改进,以更好地利用增强的多尺度特征进行分类。本文在Mini-Imagenet、Caltech-256和Cifar-100数据集上与传统模型及较先进模型进行比较,在MiniImagenet 上,传统方法1-shot 准确率为49.4%,5-shot 准确率为68.2%,本文方法分别为61.4%和78.6%,分别超过传统方法12.0 个百分点与10.4 个百分点。实验表明本文方法相比于传统方法有了较大提升,并达到了先进水平。
本文方法还存在以下不足需要进一步研究:(1)多尺度特征在融合时在各尺度使用了单一的可学习参数作为注意力机制进行多尺度特征的融合,导致各尺度部分关键信息被弱化,部分干扰信息被强化,影响分类效果。后续考虑实现能区分单一尺度上信息重要性的注意力机制。(2)元学习器识别结点间信息有效性时对样本差异度有过强的依赖性。为了进一步提高元学习器识别有效信息的能力,减弱其对样本差异度的依赖,考虑改进元学习器的结构。强化学习可以通过反馈机制来训练智能体,未来的研究中,考虑将本文元学习器与强化学习结合到一起,并通过困难样本的强化训练,增强元学习器对困难任务的处理能力。
