基于图神经网络的多模态视觉表征技术研究
2022-08-18张晨
张 晨
(合肥城市学院 机械与电气学院,合肥 238076)
随着多媒体及相关技术的发展,图像分析(尤其是画作分析)成为了当前热门的研究领域.画作分析主要任务包括从艺术风格分类、创作周期估计、风格转移、物体检测和检索以识别画作之间的语义关系[1-4].但是,大多数现有的研究几乎完全集中在视觉内容分析,而本文则专注于捕捉和建模作者与画作之间复杂的视觉和语义关系,以更深入、更全面地了解画作.虽然视觉内容是图像的主要特征,但是艺术领域中的基础理论以及与画作相关的丰富语义信息也是画作分析的关键因素.画家之间的联系、画作的风格等属性是构成关系网络的重要元素,通过连接代表这种网络关系的视觉内容和语义信息,可以更好地理解画作创新和影响的过程.图神经网络(Graph Neural Network,GNN)的出现使我们能够对有趣的属性和关系进行建模[5].然而,大多数早期的 GNN 无法扩展到由具有数千个节点和边的大型图组成的域.本文采用了高效的GNN方法,以扩展到具有数千个节点和数百万条边的大型图,并优于传统的卷积神经网络的预测性能和计算效率.提出了GNNMMVisRe,这是一种扩展GNN 和卷积神经网络的新方法,可使用图像的视觉内容及其各自的语义关系来共同学习视觉和语义表征.GNNMMVisRe采用多任务学习方法来学习画作的视觉表征,多任务学习除了在计算效率方面具有优势之外,模型还可以从各个学习任务之间的相互依赖的表征中获益.
1 GNNMMVisRe模型设计
采用多模态机器学习技术来改善基于视觉内容CNN的性能,联合CNN和GNN模型来学习图像的视觉表征.所提出模型的流程如图1所示.

图1 GNNMMVisRe模型流程
1.1 视觉表征和图表征学习
对于给定的图像,可以获得如下所示的视觉表示vi:
vi=FGAP(fCNN(P;θCNN))
(1)
提出了一种按照节点分类范式对图像属性进行分类的新方法,即将每个图像视为一个节点,并根据图像的语义属性发掘其与其他节点的关系.传统的GNN模型采用邻接矩阵A对节点之间的关系进行编码.这样一来,随着图规模的增加,模型的计算复杂性也将大大增大.因此,使用采用的方法来提高模型的扩展性.
在训练GNN之前,需要构建一个预定义邻接矩阵A.构建的规则如下所示:
(2)
提出的GNNMMVisRe使用艺术流派来链接画作节点,对原始图中的边进行下采样,以确保节点的度数不超过128.本文使用GraphSAGE来获得上下文感知的节点表征[6].给定一个节点,从其h跳邻居中采样k个邻居节点,并聚合邻居的节点特征向量以获得节点表征.使用均值聚合器并获得节点表征ni如下:
ni=W1xi+W2fAGGxj
(3)
其中xi是节点特征向量,xj是邻居j的节点特征向量,fAGG是邻居特征向量聚合器,而W1和W2是权重.将h的值设置为2,邻居采样大小k1的值是25,k2的值是10.
提出的GNNMMVisRe采用了下述的视觉特征表示技术和词袋标签特征向量技术这两种方法来获得节点特征向量:
(1)视觉特征表示技术.GNNMMVisRe以多模态融合方式利用视觉表征作为所提出模型的节点特征.在训练 GNN之前,利用预训练的ImageNet和冻结的ResNet-34架构作为主干来提取512维绘画视觉特征向量,提取了最后一个卷积层的特征.随后,使用图像级别的视觉特征向量vi训练GNN模型.
(2)词袋标签特征向量技术.对于稀疏的特征,使用词袋技术将图像标签作为节点特征向量,即将每个节点表示为基于其属性标签的one-hot编码向量.从WikiArt在线收藏中收集了与画作相关的标签,本文仅考虑了WikiArt集合中出现10次以上的标签,并为没有可用标签的绘画引入了一个特殊的未知标签.
(4)临时工程。高速公路及地方道路都会受到施工过程的影响,这是为了保证通常的交通,需要设置临时便桥和便道。另外,在交通组织方案实施过程中,为了保证行车安全,可设置必要的临时交通工程设置。
1.2 嵌入生成
嵌入生成算法利用节点特征信息有效地生成节点嵌入,如算法1所示.假设已经学习了K个采样函数的参数(表示为SAMPLEk),它采样来自节点邻居的信息,以及一组权重矩阵Wk,用于在模型的不同层或“搜索深度”之间传播信息.算法1在每次迭代时,节点对来自其本地邻居的信息进行采样,随着迭代的进行,节点能从远处的节点获得越来越多的信息.
算法1 嵌入生成算法
输入:图G(V,E),输入的特征xv,∀v∈V,搜索深度K,权重矩阵Wk,激活函数σ,SAMPLEk,∀k∈K,
输出:节点表示zv,∀v∈V
2: For each k in K do
3: For eachv in V do

1.3 多模态嵌入和多任务学习
给予学习到的视觉和上下文感知嵌入,使用合并操作来获得视觉表征.使用视觉和语义嵌入的串联来形成视觉表征,即:
xi=vi⊕ni
(4)
使用多任务学习来学习艺术作品的风格运动、艺术家和创作时期.这三个特定任务是高度协作的任务.因此,多任务学习可以提高本模型的性能.训练的损失函数具有以下的形式:
(5)
其中wt表示任务t的权重,Lt表示任务t的损失函数,LT是总损失函数.对于多类别分类,使用分类交叉熵作为损失函数:
(6)

2 实验评估
实验评估部分将所提出的模型与常用的CNN模型和GNN模型进行对比,使用风格分类、艺术家归因、创作时期估计和标签预测这四个下游任务来评估提出的方法.实验使用了完整视觉艺术数据集和艺术家视觉艺术数据集,其中,完整视觉艺术数据集包含超过七万幅画作,艺术家视觉艺术数据集包含23位最具代表性艺术家作品.此外,对于创作时期估计任务,实验部分还使用了包含从 1850 年到 1999 年艺术作品的现代视觉艺术数据集.对于这个回归问题,采用平均绝对误差作为指标(MAE)进行训练,并使用累积分数(CS)作为评估指标,其定义如下:
(7)
其中,N是测试集中画作的总数,Nθ是绝对误差小于θ年的绘画数量.对于CNN模型,将AlexNet和 ResNet模型作为基准,使用PyTorch 库进行模型实现、训练和评估.另外,对于GNN模型,采用了GraphSAGE[6]、GraphSAINT[5]和 SIGN[7]作为基准算法.对于GNN架构的实现,使用了PyTorch几何库.为每个 GNN 试验了几种配置,并选择性能最佳的配置.
传统的CNN 模型在视觉艺术分析方面的性能非常强大,尤其是在风格分类和艺术家归属任务.如表1所示,CNN模型的准确率都很高,最好的CNN模型是 ResNet-152,其次是ResNet-34,而AlexNet的表现却是不尽如人意.

表1 各个模型的准确度对比
此外,发现多任务学习可以提高CNN模型的性能.例如,如表1所示,在完整视觉艺术数据集上进行样式分类的工作,多任务的ResNet-152比单任务ResNet-152的性能提高了6%.多任务学习方法提高了CNN模型在大部分任务中的性能.
对于GNN模型,观察到在某些情况下多任务学习会降低 GNN模型的性能,因此仅展示单任务GNN模型的结果.各个GNN模型的性能与单任务CNN模型较为接近.而GNN模型能够在较小的数据集艺术家视觉艺术数据集上获得了最好的性能.
注意到GNN模型在艺术家视觉艺术数据集的艺术家归因任务上取得了出色的表现.假设这种行为是由于使用继承的艺术学校属性的任务的简单性.
提出的GNNMMVisRe能够在三个数据集上的大部分任务获得最好的性能.如表1所示,GNNMMVisRe在风格分类和创作时期估计方面始终优于所有其他模型.此外,GNNMMVisRe在 完整视觉艺术数据集和现代视觉艺术数据集数据集上的艺术家归因任务表现优于所有模型.还必须注意,使用密集节点视觉特征向量比依赖标签的稀疏对应物产生更好的性能.接下来,使用标签预测任务来评估本模型的性能.展示了每一种标签类别的F1分数、总体F1分数和平均精度,结果如表2所示.GNNMMVisRe的表现仍然是最好的.另外,CNN模型比GNN模型的表现更好.
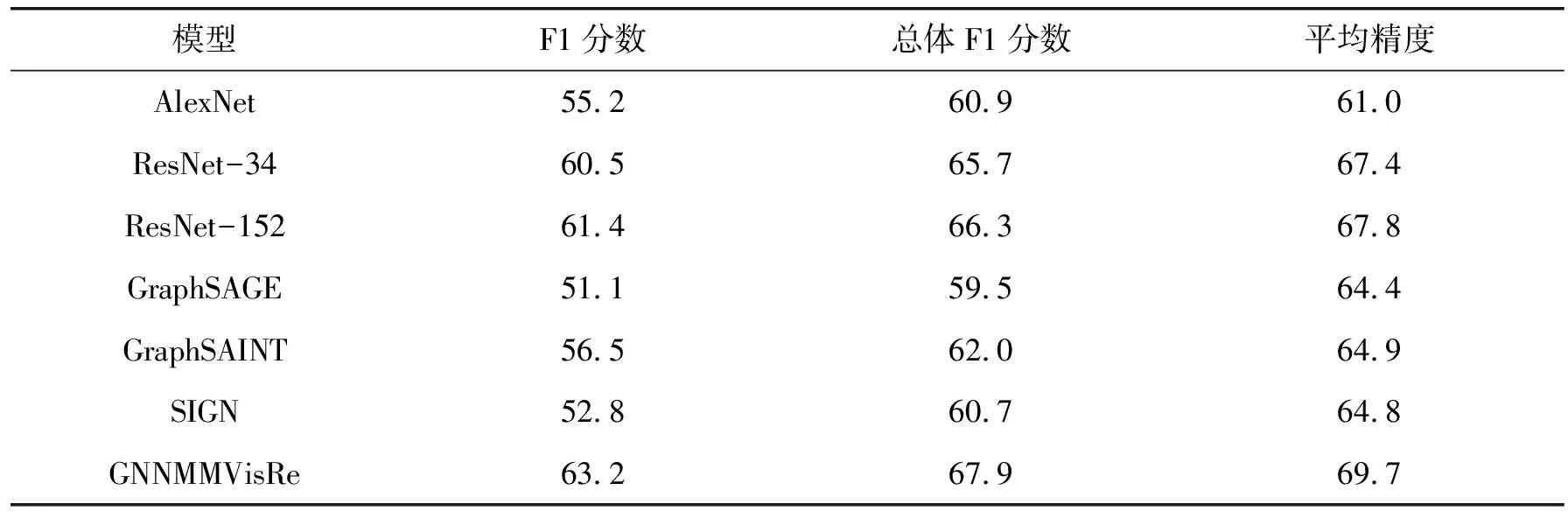
表2 标签预测任务性能对比
表3展示了各个模型训练和推理所需的时间.由于GNN的计算运行时间处于相同的数量级,因此此处仅展示GraphSAGE的时间.最后,观察到 GNNMMVisRe只需要比它依赖的 ResNet-152 多一点时间.

表3 模型计算效率
3 结论
本文提出的GNNMMVisRe是用来图像视觉表征的多模态模型,GNNMMVisRe整合视觉和语义内容.实验结果表明,与目前主流的CNN模型和GNN模型相比,提出的GNNMMVisRe在分类任务中实现了最先进的性能.未来的研究工作在于采用定性分析对提出的模型进行评估,更直观地观察到本模型的性能.
