基于深度学习的煤矿防尘口罩佩戴检测
2022-08-18李浩宇杨超宇
李浩宇,杨超宇
(安徽理工大学 经济与管理学院,安徽 淮南 232000)
煤矿井下工作环境复杂且存在大量煤炭粉尘,井下工作人员长期吸入煤炭粉尘会对身体健康造成巨大危害,因此佩戴防尘口罩是非常必要的.但因为矿井下高温的原因,一些煤矿员工经常不佩戴防尘口罩,此种行为违反了煤矿安全规章.人工24小时监视违规行为并不现实,因此需要将深度学习技术与视频监控相结合,对违章行为进行实时检测.一些学者对口罩佩戴检测做出了研究,丁洪伟等[1]将改进的空间金字塔赤化结构引入YOLOV3中,并对DarkNet53骨干网络进行改进,对口罩的检测速度为39FPS,检测精度精度为90.2%.秦亚亭等[2]针对目前几种主要的轻量级检测模型:Pyram模型、基于SSD算法的Keras模型和基于CenterFace的口罩检测模型,在不同数据集下做综合测试,最后分析了各种方法的优劣以及口罩检测技术的优化方案.从目前的研究成果来看,口罩检测效率不能达到实际应用需求.因此,本文提出一种基于YOLOV5算法的煤矿防尘口罩检测方法[3],最终实现了对防尘口罩的精确检测.
1 YOLOV5模型
YOLOV5目标检测模型是基于Pytorch实现的[4],由Ultralytics在2020年6月25日正式发布的,是现今最先进的对象检测技术[5],并在推理速度上是目前最快的.YOLOV5官方代码中,给出的权重文件一共有四个版本,分别是YOLOV5S、YOLOV5M、YOLOV5L、YOLOV5X,其中YOLOV5S是深度最小[6],特征图宽度最小的权重,后面三种权重在此基础上深度不断加深,特征图宽度不断加宽.本文使用YOLOV5S权重后的检测速度最快可达0.012 s[7].YOLOV5采用GIOU_LOSS做Bounding Box的损失函数,GIOU_Loss计算公式如下,出现众多目标框的筛选采用NMS加权方式获得最优目标框.
(1)
YOLOV5模型使用Sigmoid函数为网络激活函数,使用LeakyReLU函数处理深度学习中网络阶梯消失的问题.[8]Sigmoid函数及LeakyReLU函数公式如下:
(2)
F(x)=max(0.1x,x)
(3)
2 算法流程
2.1 流程概述
本文的目标检测流程如图1所示,通过煤矿井下工作面监控摄像头获取视频流.使用OpenCV对视频进行单帧提取,建立数据集后进行预处理,并利用K-means算法自适应优化anchor box,利用YOLOV5算法的网格法分割图像,分别输出特征图.学习图像中防尘口罩深层语义信息及浅层位置信息,利用特征尺度融合后实现对防尘口罩的精确实时检测[9],最后输出实验结果.

图1 算法工作流程图
2.2 数据集建立及预处理
(1)数据集建立
本文的数据集通过淮南某煤矿井下摄像头获取,包括不同工作环境、不同光照等多种情况下的视频.分析数据特点后从视频流中截取3 000张图片作为训练数据集,其中2 000张图片作为训练集,500张图片作为测试集,500张图片作为验证集并将数据集标注为mask和none两类,图片标注软件使用labelImg.YOLOV5算法的下采样为32倍,因此输入图片的宽高要能被32整除.在多尺度训练中一般最小尺寸为320×320,最大为640×640,在模型训练之前将数据集尺寸调整为640×640,对小目标物体检测的准确性可提升2%.最后可通过修改datasets.py文件中的letterbox函数,使YOLOV5模型可适应图片的缩放,较好地处理了因图像缩放后两端产生的黑边过多而导致信息冗杂等问题.[10]
(2)预处理数据
在实际的应用场景下,采集的数据集并不能完全满足模型训练的需求,重新获取更多的数据则会增加成本和工作量.为解决这一问题,本文在模型训练之前进行数据预处理,包括标签平滑处理和数据增强两部分.[11]
标签平滑处理的本质是正则化处理,通过减少过拟合训练提升分类器性能,从而使得训练模型对数据集的预测概率更加接近真实情况.数据增强的主要目标是通过增加训练基础数据和噪声来提高模型的泛化能力和鲁棒性.数据增强方法包括:图像缩放、图像裁剪、图像平移、数据旋转、数据翻转、覆盖噪声、修改对比度等.原始数据经过数据增强拓展后可获得大量新的数据集,可有效提升目标检测效果.本文提出一种马赛克拼接法,即截取多个图像的可有效检测部分合并成一张新的待检测图像,这种方法能够有效降低微小或大量扰动数据对目标检测精度的影响.
2.3 K-means算法自适应计算anchor box
YOLOV5算法将输入的图像分成若干网格,检测目标中心区域处于某个网格中,此网格就负责预测这个目标,如图2所示.

图2 目标预测示意图
在实际目标识别环境中,目标实际尺寸和默认anchor box尺寸存在差异,如果使用默认anchor box尺寸可能会导致损失函数下降方向发生偏离.使用K-means聚类算法可有效解决上述问题,K-means聚类算法的流程如下:
(1)防尘口罩的数据集像素大小为n,设置迭代的次数为m,聚类个数为K,并会随机产生K个初始聚类中心Cj(r).YOLOV5网络对每个网格的预测需要9个先验框,因此K=9.
(2)计算数据集样本与初始聚类中心Cj(r)相似度D(Xi,Cj(r)),进而形成空间簇Wj,如果(4)成立,则存在Xi∈Wj,本文阀值设置为0.005,即ε=0.005.
(4)
(3)根据K得到新的聚类中心,计算公式如下:
(5)
(4)中心簇的收敛情况如下:
(6)
(5)判断聚类是否可达到最小收敛条件:
|E(r+1)-E(r)|<0.005
(7)
(5)最小收敛条件成立时停止迭代,否则重新返回步骤(2)重新进行迭代,输出防尘口罩分割图.
最后经计算得到适合防尘口罩检测的先验框的尺寸如下:22×27,59×86,76×70,100×110,108×127,111×98,113×94,229×207,231×205.
3 实验及结果
3.1 实验环境及模型训练
本文的实验平台为Linux,采用的深度学习框架为Tensorflow19.0,OpenCV版本为3.3.0,使用NVIDIA GeForce RTX 2060显卡进行运算,并使用Cuda10.0对训练过程进行加速.在模型训练阶段,网络参数配置设置如下:epochs设置为100,batch-size设置为16,初始学习率为0.02,权重衰减设为0.000 5,动量设为0.95.
3.2 实验结果
模型训练结束后目标识别结果如图3所示.从识别结果可以看出,本文算法对单目标和多目标检测都能获得不错的效果[12],并准确地区分出有无口罩佩戴的情况.

图3 检测结果
利用mAP评估本文算法检测准确度,因本文的检测目标只有防尘口罩一类物体,所以在数值上mAP等于AP,AP的计算公式如式(8)所示,即算法对每张图片各类别检测的准确率(Accuracy)求和后除以该图片中各类别检测目标和N.模型训练结束后使用Tensorboard可视化工具查看训练过程中损失函数收敛曲线、mAP曲线、recall曲线,如图4所示.

图4 模型性能评估
(8)
将本文算法与其他算法进行对比,结果如表1所示,从对比结果可以看出本文算法的检测准确率为92.5%.检测精度高于其他算法的同时,得益于YOLOV5S较小的权重数据,使得检测速度有大幅度提升,能够满足实际应用需求.
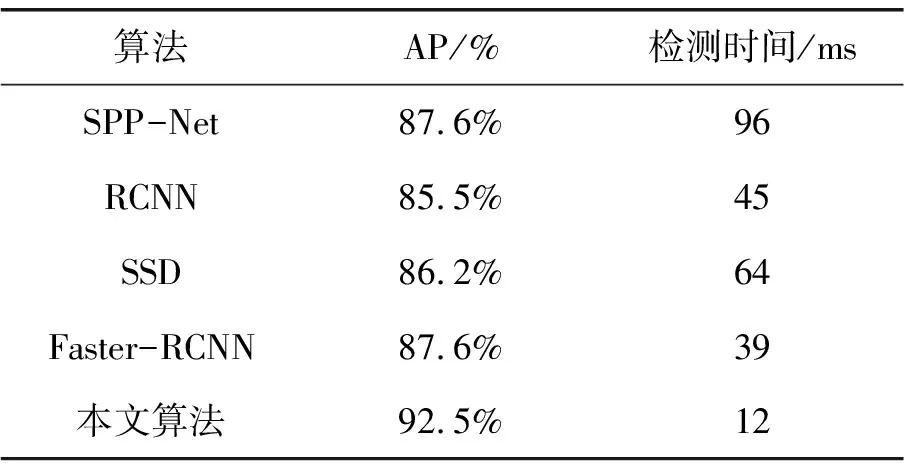
表1 不同网络模型的检测效果对比
4 结语
本文提出一种基于YOLO算法的煤矿井下员工防尘口罩佩戴实时检测方法,加强了算法对不同尺寸防尘口罩的识别能力.从实验结果可以看出对防尘口罩具有很好的识别效果,且算法检测速度较快,能够满足实际应用需求.另一方面,本文的研究也存在着不足,存在人员或者物体遮挡面部的情况时,对防尘口罩的识别较为困难.未来将对算法进一步改进使其更加适用于实际应用场景.
