基于语义融合和多重相似性学习的跨模态检索
2022-08-18曾奕斌
曾奕斌,葛 红
(华南师范大学计算机学院,广东 广州 510631)
0 引 言
跨模态检索(Cross-Modal Retrieval)旨在解决将一种模态数据作为查询去检索另一种相关模态数据的问题。例如,对于一个给定的图像(文本),查询与其相关文本(图像)。目前,跨模态检索的挑战主要集中在如何处理不同模态空间中的数据,对其内容进行相似性度量,即如何解决“异构鸿沟”。为此,许多论文提出基于公共子空间的表示学习方法,试图寻求一个函数,将不同模态空间中的数据映射到公共子空间中进行模态对齐,再通过欧氏距离、余弦距离等度量方式比较特征之间的相似性,最终按相似性大小排序得到检索结果[1]。
根据特征表示进行划分,现有的公共子空间方法主要可以划分为2大类:1)基于实值表示学习的方法;2)基于二进制值表示学习的方法,也称哈希方法,该方法更多考虑的是计算效率,但由于使用二进制编码,部分信息在编码过程中丢失,导致检索精度有所下降[2-3]。
本文探究的是基于实值表示学习的方法,该方法主要可以划分为无监督学习方法和有监督学习方法。无监督学习方法主要代表是典型相关分析(CCA)[4]和基于核函数方法的KCCA模型[5]。随着深度神经网络的发展,学者们通过神经网络捕获相关语义信息进行特征提取,如Andrew等人[6]结合深度神经网络提出DCCA模型,提高了网络的学习能力。
相比有监督学习方法,无监督方法在学习跨模态数据的公共表示时,仅仅利用了模态数据间共存的信息,而没有充分利用多媒体内容中丰富的标签信息。文献[7-11]提出有监督学习方法充分利用类别信息,通过区分不同样本的语义类别,使得相同类别的样本特征尽可能相互靠近,不同类别的样本特征尽可能相互远离,进而增强公共子空间特征表示的语义可区分性。除了公共子空间方法,Wang等人[7]首次引入深度关系网络进行相似性学习,通过融合特征得到相似性打分矩阵,取得了不错的性能,表明深度关系网络和特征融合在提取模态信息中有一定的作用。
值得注意的是,这些方法或缺少对不同模态空间的特征进行交互,不能充分挖掘模态特征间的关联信息;或在进行特征融合时,缺少考虑融合特征和单模态特征间的关系。为此,本文提出一种基于语义融合和多重相似性学习的方法(Context Fusion and Multi-Similarity Learning, CFMSL),利用样本对的标签学习不同模态数据的相似性信息,同时通过混合融合方法提升跨模态检索的性能。本文的主要工作如下:1)构建模型将不同的模态特征进行融合,并投影到公共子空间中,然后在计算样本对的相似性时,除了考虑不同模态特征在公共子空间的相似性外,还考虑单模态特征与融合特征在公共子空间的相似性,进一步挖掘不同模态间的相似性信息;2)提出基于单模态特征和融合模态特征的多重相似性判别损失函数,同时考虑正负样本对,使得不同模态样本在公共子空间中具有明显的类内相似性和类间差异性;3)通过决策融合的方式,同时考虑单模态特征和融合模态特征的相似性,对相似性列表进行重排序,进一步提升跨模态检索的性能;4)在Pascal Sentences、Wikipedia、NUS-WIDE-10K这3个广泛使用的跨模态图文数据集进行实验,验证该算法的有效性。
1 相关研究
1.1 基于公共子空间的跨模态检索
早期利用公共子空间方法的代表是基于无监督学习的CCA模型和KCCA模型,但由于缺乏对标签信息的利用,检索性能有所限制。为了充分利用标签信息,Zhai等人[8]提出JRL模型,同时结合不同模态的相互关系和类别信息,进行半监督表示学习,将不同模态的特征投影到公共子空间中,但由于只是利用线性组合挖掘相关信息,模型表达能力受到一定的限制。Peng等人[9]提出一种基于卷积神经网络和自然语言模型的两阶段多模态深度神经网络CMDN,先通过联合模态内和模态间的信息得到模态特征表示,然后通过堆叠网络得到不同模态特征的公共表示,但只考虑了相关样本,缺少对不相关样本距离的考虑。Wang等人[10]提出了ACMR模型,将对抗式学习与监督式表示学习相结合,使用三元组损失函数[11]同时考虑公共子空间中相关样本和不相关样本的距离,以最大程度地减少不同模态特征之间的差异。Zhen等人[12]提出的DSCMR模型则充分利用类别信息同时对公共子空间和类别空间的特征进行约束,以及通过网络参数共享的方式学习得到具有可区分性和模态不变性的公共空间特征表示,在多个数据集上达到了优异的表现。
为了充分挖掘模态间的关联信息,本文除了将不同的单模态特征投影到公共子空间进行模态对齐外,还利用模态融合方法生成融合特征投影到公共子空间中,利用标签信息进行相似性度量学习,使得模型生成更具判别性的特征,提升跨模态检索的性能。
1.2 模态融合方法
为了提升跨模态检索的性能,部分基于深度学习的模型采用模态融合方法[7-8],从多种模态中提取信息进行融合。按照融合的时机,可以分为早期融合方法、晚期融合方法和混合融合方法。早期融合也称特征融合,可以用于捕获特征之间的关系,缓解不同模态中数据不一致的问题;晚期融合也称决策融合,该方法主要是通过融合多个不同的训练模型输出结果,缓解过拟合问题;混合融合方法则结合了早期融合方法和晚期融合方法的优点,但也带来了一定的复杂性[13-14]。
本文采取的是混合融合方法,在公共子空间生成器中利用特征融合生成更具判别性的投影特征,同时在相似性打分阶段,通过决策融合综合考虑单模态特征和融合模态特征,使得模型能够更加充分地挖掘模态间的关联信息。
1.3 相似性度量学习
在对公共子空间特征进行度量时,往往涉及到各种样本对相似性损失函数,如三元组损失函数[10-11]、余弦嵌入损失函数[15]等。Wang等人[16]通过研究不同的相似性损失函数,提出GPW框架为样本对相似性损失函数提供一个统一的视角,即大多数基于样本对相似性优化的损失函数都可以通过GPW框架转化为样本对加权问题,并发现相似性学习的关键在于自相似性和相对相似性,但现有方法只关注了自相似性或相对相似性中的一部分因素,于是提出多重相似性损失函数(MS Loss)。除了考虑样本对的自相似性外,MS Loss还同时考虑周围正例样本的相对相似性和负例样本的相对相似性,在图像单模态检索领域取得可观的效果。
本文受MS Loss启发,在关注公共子空间多种特征对的自相似性和相对相似性的同时,尝试得到改进的跨模态多重相似性损失函数,充分利用语义融合特征进一步挖掘图文数据的关联信息,使得模型能够更好地判别样本对的相似性。
2 语义融合相似性学习方法
2.1 问题描述

2.2 模型设计
如图1所示,CFMSL的网络模型主要由2个部分构成,前半部分是一个双分支子网络,用于提取原始图像和原始文本的特征,后半部分由线性生成器和样本对相似性打分模块组成,线性生成器将不同模态数据映射到公共子空间进行特征的相似性学习。线性生成器使用网络参数共享策略[12]来消除不同模态间的差异性。不同于一般的公共子空间方法只将多个单模态特征分别投射到公共子空间中,本文还引入融合网络,对不同模态特征进行融合,得到语义融合特征投射到公共子空间中,进行单模态和融合模态之间相似性的学习。最后,基于决策融合策略,通过样本对相似性打分模块,综合考虑单模态特征和融合模态特征的相似性关系,计算得到不同模态样本对的相似性得分,用于后续检索结果的排序。
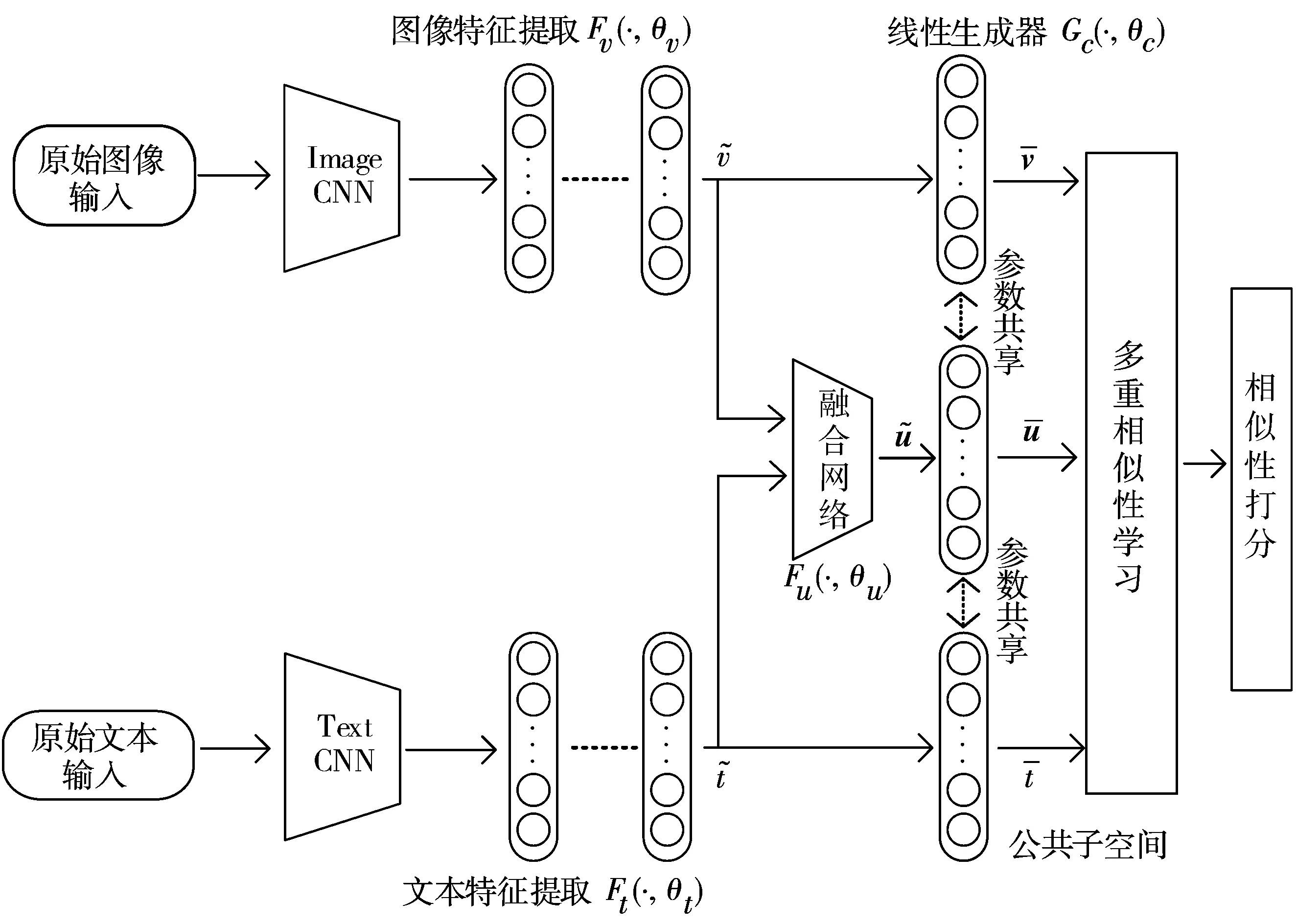
图1 CFMSL网络模型
2.3 基于语义融合的多重相似性学习
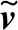

在公共子空间中,利用余弦距离来度量样本对之间的相似性,通过最小化相关样本对的余弦距离来减少同类别样本模态间的差异。同时,对查询模态特征和融合特征间的相似性进行计算,进一步利用不同模态特征间的交互,使得生成器生成更具有判别性的公共子空间特征。
受MS Loss[16]启发,本文提出公共子空间中图像特征到文本特征的模态间多重相似性损失函数如下:
(1)

类似地,引入文本特征到图像特征的模态间多重相似性损失函数如下:
(2)

为了确保公共子空间中的图像特征具有模态内可判别性,即通过线性生成器的映射后,模态内同类的图像特征相似性应该越大,异类的图像特征图像相似性应该越小,引入如下图像特征的模态内多重相似性损失函数:
(3)
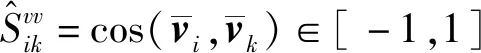
类似地,引入公共子空间中文本特征的模态内相似性损失函数,提升文本特征的模态内可判别性:
(4)

为了充分利用语义融合信息,需要对公共子空间中图像特征与融合特征的相似性关系进行度量学习,引入如下图像特征到融合特征的模态间多重相似性损失函数:
(5)
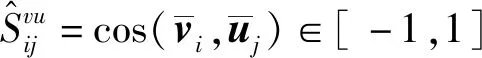
类似地,对公共子空间中文本特征与融合特征的相似性关系进行度量学习,引入文本特征到融合特征的模态间多重相似性损失函数:
(6)

综上所述,结合公式(1)~公式(6),基于语义融合和跨模态多重相似性学习的损失函数定义如下:
L=Lvt+Ltv+Lvv+Ltt+Lvu+Ltu
(7)
该损失函数充分学习特征对的自相似性和相对相似性信息,不仅考虑了单模态之间和模态内的相似性信息,还进一步通过语义融合充分挖掘模态之间的关联信息。
2.4 基于决策融合的相似性打分算法
为了充分利用单模态特征和融合模态特征在公共子空间的特征投影,本文利用决策融合方法,不仅考虑单模态特征之间的相似性得分Svt,还进一步考虑单模态查询特征到融合模态目标特征的相似性得分Svu和融合模态查询特征到单模态目标特征的相似性得分Sut的贡献,通过求和得到图像特征到文本特征的打分矩阵Svt计算如下:
Svt=Svt+Svu+Sut
(8)
显然,文本特征到图像特征的打分矩阵Stv可以通过打分矩阵Svt的转置得到,因此通过公式(8)即可以求出任意样本对之间的相似性得分,最终根据得分矩阵进行重排序得到检索结果列表。
2.5 训练过程
结合上述基于语义融合的多重相似性学习模块与基于决策融合相似性打分算法,可以得到CFMSL算法,如CFMSL算法伪代码所示。
CFMSL算法伪代码:
输出:训练好的网络参数θv、θt、θu和θc。
1.随机初始化网络参数:θv、θt、θu和θc
2.更新直到收敛
3.forkstep
4.从训练集随机选取大小为nb的样本对构建小批量数据集[(vi,ti,yi)]nb
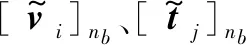
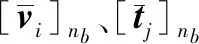
7.利用公式(7)计算梯度,通过随机梯度下降算法,分别更新θv、θt、θu和θc:
8.θv⟸θv-ηθvL
9.θt⟸θt-ηθtL
10.θu⟸θu-ηθuL
11.θc⟸θc-ηθcL
12.更新学习率η
13.end for
3 实验结果与分析
3.1 实现细节
3.2 数据集
本文使用跨模态检索中广泛使用的数据集进行有效性验证,即:Wikipedia数据集[4],Pascal Sentences数据集[23]和NUS-WIDE-10K数据集[24]。在训练集和测试集的划分中,本文采用了与文献[25-26]相同的划分方法,具体划分方式如表1所示,其中Ntrain是训练集大小,Nval是验证集大小,Ntest是测试集大小,C是类别数。

表1 数据集的统计信息
3.3 实验对比与分析
本文选取了3种近年来的跨模态检索模型作为基准方法进行比较,分别为:1)ACMR方法[10];2)DSCMR方法[12];3)DRSL方法[7]。表2显示在相同环境下,Wikipedia、Pascal Sentences和NUS-WIDE-10K这3个数据集上不同实验方法的结果对比,包括2类跨模态检索任务Img2Text(输入查询图像,检索得到相似的文本列表)和Text2Img(输入文本查询,检索得到相似的图像列表)的mAP指标,以及它们的平均值(Average)。可以观察到,mAP指标平均值相比最佳基准模型分别提高了2.02%、0.54%和1.12%,表明在综合性能指标上,本文方法具有一定的优越性。ACMR方法使用生成对抗方法消除模态间差异,利用三元损失生成具有类别判别性的特征,但缺少了对相对相似性信息的利用;DSCMR方法使用网络参数共享策略消除模态间差异,进一步考虑模态内和模态间特征的相似性,利用3种损失函数生成更具类别判别性的特征,跨模态检索性能得到提升,但仍不能充分挖掘模态间信息。相比这2种方法,本文增加了特征融合和多重相似性优化的方法,说明进行语义融合能够更好地捕获不同模态的相关性信息;相比DRSL模型使用特征融合的方式和全连接网络来学习相似性得分矩阵,本文利用样本对的自相似性和相对相似性信息进行优化,能够更加有效地针对不同模态特征的相似性进行判别。
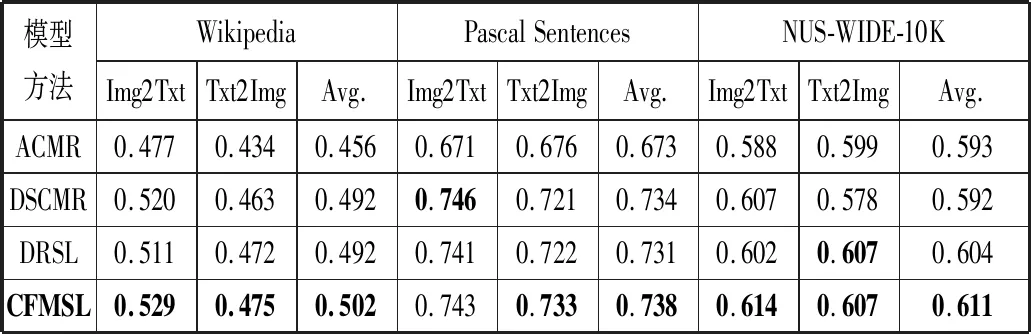
表2 实验结果对比
近年来,随着BERT[27]和GPT-2[28]等基于Transformer预训练模型的出现,模型对于自然语言的分析和理解能力得到充分提升。在上述CFMSL模型中,对文本特征提取网络(即Sentence CNN网络)所使用的是word2vec词向量,本文进一步进行实验,尝试将word2vec词向量替换为BERT或GPT-2模型所使用的上下文预训练词向量。如表3所示,在Wikipedia数据集上的实验结果表明,直接使用BERT或GPT-2的上下文预训练词向量替换word2vec词向量并不能提升实验结果,这是它们所适用的模型不同导致的,BERT或GPT-2模型更适合大量训练样本的场景。同时,在替换上下文预训练词向量的情况下,本文方法仍优于其他方法,这也表明本文提出的方法具有鲁棒性。另外,如表4所示,与BERT或GPT-2模型参数相比,CFMSL模型的文本特征提取部分用到的模型参数明显更少。综上所述,本文提出的CFMSL模型具有一定的优越性。
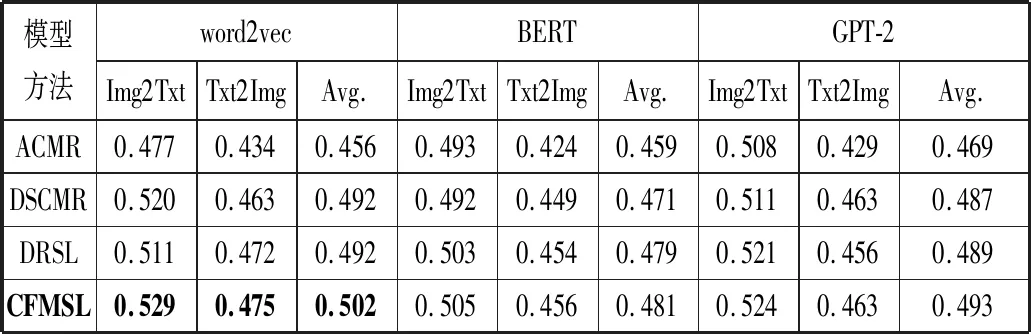
表3 Wikipedia数据集上不同词向量实验结果对比

表4 模型参数量对比
3.4 超参选取
公式(7)的计算包含超参数缩放因子γ,本文通过大量实验在验证集上确定超参数γ的最优取值,实验设置γ的取值范围为{1,8,16,32,64,128,256}。如图2所示,显示了Wikipedia数据集上不同γ取值对应的mAP平均值,不难看出当γ=32时,mAP平均值在验证集和测试集上都取得最高的mAP值,此时模型达到最优。

图2 Wikipedia数据集上超参数γ的实验结果
3.5 消融实验
为了分析本文方法中不同模块的有效性,设置如下6组消融实验:
1)CFMSL-F表示移除语义融合模块,验证进行语义融合的必要性。如表5所示,与移除语义融合模块前相比,CFMSL-F平均mAP下降2.05%,表明语义融合有助于优化跨模态特征的相似性比较。
2)CFMSL-I表示移除单模态特征的模态内多重相似性判别,验证对单模态特征相似性进行约束的重要性;如表5所示,与移除单模态特征的模态内多重相似性判别前相比,CFMSL-I平均mAP下降1.15%,表明进行单模态特征的模态内多重相似性判别有助于公共子空间生成器生成更具相似判别性的特征。
3)为了验证决策融合策略的有效性,设置实验Dxyz(如表5中的D011、D101、D110和D100)分别表示只计算公式(8)中的一部分来进行相似性打分,即使用如下公式计算相似性得分:
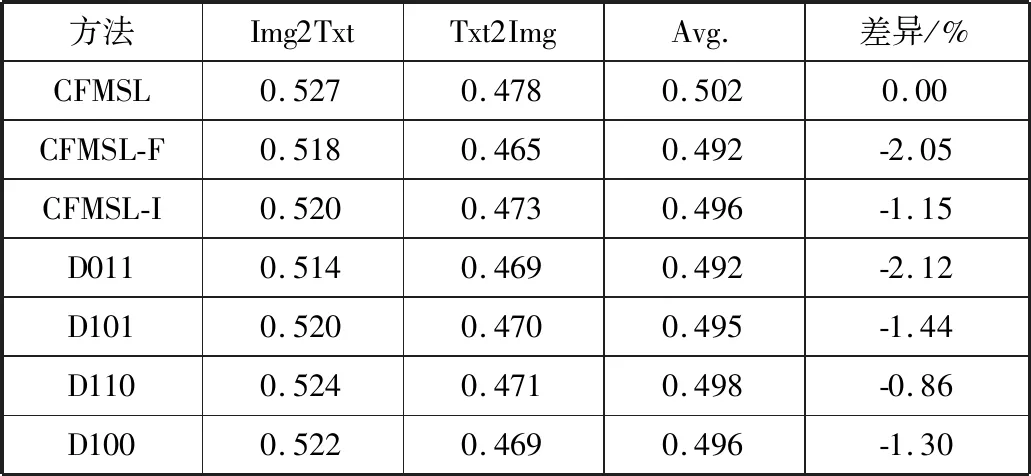
表5 在Wikipedia数据集上的消融实验mAP
(9)
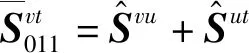
4 结束语
本文提出了一种基于语义融合和多重相似性优化的跨模态检索方法CFMSL,用于解决有监督学习方式下的跨模态检索问题。该方法利用基于语义融合的相似性学习模块生成公共子空间中更具判别性的特征,同时基于决策融合方法充分利用单模态特征和融合模态特征信息进行相似性打分,对检索结果进行重排序。最终,通过在3个广泛使用的跨模态检索基准数据集上进行实验,评估本文提出方法的有效性,实验结果显示,CFMSL方法能够有效提升跨模态检索的性能。
然而,本文在对原始样本进行特征提取时,尚未进一步考虑对细粒度特征信息的利用,比如针对图像的显著区域、文本的显著词汇等进行信息提取和交互。在未来的研究中,笔者可能会进一步考虑细粒度层面上的跨模态信息交互,从而提高跨模态检索性能。
