一种采用机器阅读理解模型的中文分词方法
2022-08-18周裕林陈艳平黄瑞章秦永彬林川
周裕林,陈艳平,黄瑞章,秦永彬,林川
(1.公共大数据国家重点实验室,550025,贵阳;2.贵州大学计算机科学与技术学院,550025,贵阳)
中文分词是中文信息处理中的首要任务。与英语使用分隔符来分割单词不同,汉语是一种由本族语素(汉字)发展而成的多合成语言[1]。在汉语中,语素也可以独立成词。语素和复合词的模糊导致了汉语中对词的概念比较弱。另外,与英语使用分隔符来分割单词不同,汉语句子采用连续书写。词与词之间没有分隔符。因此,在中文文本里,经常存在分词歧义。单个句子会产生多种可能的切分路径。例如,“世界冠军”“抽象概念”“银行流水”等,这些词既可单独成词,又可以切分成粒度更小的多个词语,例如“世界/冠军”“抽象/概念”“银行/流水”等。
中文分词作为中文信息处理的第一步,直接用于支撑多种下游任务,如文本分类、机器翻译等。分词结果的不同将会对下游任务产生不同的影响。错误的分词结果会产生错误扩散,直接影响下游任务的性能。所以,中文分词是中文信息处理中一项重要任务。
现有的神经网络模型很难捕获句子中的长距离语义依赖,使得模型对文本语义特征理解不够充分,从而对文本中的歧义词边界识别性能较差。然而,在序列标注任务中,歧义词的边界样本又相对较少,存在样本不平衡问题。例如,“世界冠军”“抽象概念”等歧义词属于难分类样本,文本中存在着的歧义词与大量的非歧义词样本造成了难易样本不平衡。传统的序列标注模型(如LSTM、CRF、Transformer的双向编码器(BERT)等)在歧义词上识别性能都较差,不能很好地解决难易样本不平衡问题。尽管在解决中文分词歧义性上提出了各种解决方案,但仍然存在不足。目前,主流的中文分词模型主要采用序列标注模型。序列标注模型只依赖每个字周围的局部特征对字的分类标签进行预测。该模型存在输入特征使用不充分、难易样本中难分类样本得不到重点关注的问题,使得模型识别歧义词性能较差。
针对中文分词模型输入特征使用不充分、难易样本不平衡的问题,本文提出了基于机器阅读理解的中文分词模型。本文设计模型的动机是构建问题信息作为先验知识以丰富模型输入特征。针对中文词组的歧义性带来的难易样本不平衡问题,本文改进了损失函数。在Bakeoff2005语料库的4个公共数据集上进行验证,实验结果表明了本文方法的有效性。本文的主要贡献如下。
(1)采用基于机器阅读理解模型的方法,通过构建问题信息作为先验知识以丰富模型输入特征,增强模型对文本语义特征的理解,实现歧义词的更好识别。
(2)在充分分析中文词组特点的基础上,改进损失函数以缓解歧义词所带来的难易样本不平衡问题。
(3)本文首次将机器阅读理解模型应用于中文分词任务中,为中文分词提供了一种新思路。
1 相关工作
目前,主流的中文分词方法是基于神经网络模型。许多方法都将中文分词作为序列标注任务进行处理,然而这些方法都存在输入特征使用不充分和无法缓解难易样本不平衡问题。
随着深度神经网络模型不断发展[2],出现了许多应用于各项自然语言处理任务的神经网络模型[3]。Collobert等[4]提出将神经网络的方法应用于序列标注任务。此后,许多方法相继应用于中文分词。Chen等[5]提出用长短记忆(LSTM)神经网络来解决传统神经网络存在的长期依存关系的问题;Yao等[6]在Chen等的基础上,提出双向长短记忆(Bi-LSTM)神经网络来充分利用上下文信息进行分词;Chen等[7]提出带门结构的递归神经网络(GRNN)来保留上下文;Chen等[8]使用对抗神经网络来使用多个语料库进行联合训练;Ma等[9]在Bi-LSTM上引入预训练、dropout、超参数调参这3项深度学习技术,以简单的模型实现复杂模型的性能;Yang等[10]利用外部知识提高中文分词的准确率;Gong等[11]提出一个将每个标准分割成若干标准的Swich-LSTM结构;Zhou等[12]引入多种汉字Embedding来增强语义;He等[13]提出利用多标准进行中文分词;郭振鹏等[14]提出结合词典的CNN-BiGRU-CRF网络中文分词模型。
大规模预训练模型BERT[15]和ELMo[16]的出现刷新了NLP领域各项任务的记录。Diao等[17]提出基于BERT的N-gram增强中文文本编码器,以方便识别出可能的词组合;Tian等[18]提出基于双通道注意力机制的分词及词性标注模型;Tian等[19]提出基于键值记忆神经网络的中文分词模型;Chen等[20]提出在基于全局字符联机制的神经网络模型GCA-FL,通过联邦学习的方式增强模型在中文分词上的性能。
以上模型尽管在公共数据集上取得了不错的效果,但还存在以下的不足:①传统的序列标注模型对文本语义特征使用不充分;②中文分词文本存在难易样本不平衡问题无法得到有效缓解。近年来,有把序列标注任务转换成智能问答(QA)任务的趋势。Li等[21]将实体识别任务转换成机器阅读理解(MRC)任务,每个实体类型R(x,y)都能被参数化为带答案y的一个问题q(x);Li等[22]将关系抽取任务转换为一个多回合的问答任务。此外,构建问题信息作为先验知识,能使输入特征更加丰富。然而,以上模型无法缓解难易样本不平衡问题。Lin等[23]在目标检测中通过降低易分类样本的损失权重,从而更加关注难分类样本,能够有效缓解难易样本之间的不平衡;Liu等[24]引入密度函数,在目标检测中既抑制了易分类样本损失权重,又不太过于关注难分类样本。
2 机器阅读理解模型
2.1 BERT预训练模型
Vaswani等[25]最早提出Transformer的模型架构。它能够更好地学习到句子当中单词与单词之间的联系,并完全依赖于自注意力机制来计算其输入和输出从而结合上下文语境来提高模型的性能。自注意力机制的公式为
(1)
式中:Q、K、V表示3个矩阵向量;d为Q向量的维度;通过softmax对得到的分数归一化。由于BERT的目标是生成语言模型,只需要用到Transformer编码器的机制,所以对Transformer的解码器部分不再作过多叙述。
BERT预训练模型中的Embedding层是由3种Embedding求和得到。其中,Token Embeddings是词向量。Segment Embeddings是用来区分两种句子,因为预训练不只做语言模型,还要做以两个句子为输入的分类任务。Position Embeddings是用来表示句子中单词的位置。BERT预训练模型通过3个Embeddings相加能更好地提取句子语义特征。
2.2 阅读理解分词标注
本文是在大规模预训练BERT模型上构建的机器阅读理解模型。给定一个输入句子X={x1,x2,…,xn},其中,n代表句子中第n个字,然后在X中发现每一个词组。首先,需要将数据集转换成(QUESTION,ANSWER,CONTEXT)的三元组形式,其中,QUESTION表示问题生成模板,ANSWER使用xstart,end来表示在句子中词组的开始和结束下标,CONTEXT为整个句子的文本。对于词组,产生一个问题q={q1,q2,…,qm},其中m代表问题中第m个字。通过产生一个问题qy就能获得一个三元组(qy,xstart,end,X),也就是先前定义的三元组(QUESTION,ANSWER,CONTEXT)。由于构建了关于词组先验知识的问题,生成问题的内容对最后的结果有一定影响。Li等[22]采用基于规则的过程来构建问题。在本文中,采用问句和词定义的方式来构建问题。词定义表示为词概念的描述,它描述得尽可能通用、精准且没有歧义。两种问题的构建方式如表1所示。

表1 问题的构建方式
问题内容构建的不同,与文本拼接输入模型时会带有不同的先验知识,从而对最后的预测结果产生一定的影响,如图1所示。本文给定文本“学生会组织义演活动,他马上从南京市长江大桥过来”。由于词定义构建的问题内容相较于问句式产生的输入特征更加丰富,使得对“学生会”“南京市长江大桥”上分词更加准确。

图1 不同问题内容构建对分词结果的影响
2.3 机器阅读理解
机器阅读理解分词模型结构如图2所示。在BERT预训练模型的基础上,加入已构建问题词组的先验知识,输入BERT编码器后得到隐藏层特征,最后通过解析特征输出结果。

图2 机器阅读理解分词模型
输入包含了问题和文本两个部分,通过BERT预训练模型获得隐藏层表征矩阵
(2)
式中:f为BERT编码函数;Q为问题信息;C为文本信息;E为BERT编码器输出的表征矩阵。
通过多层感知向量机(MLP)[26]得到预测的词组索引。在MLP中,获得句子中每个字是词组的开始和结束索引的概率
(3)
式中Tstart和Tend是学习权重。对Pstart和Pend每一行使用arg max函数,得到预测的每个词组的开始和结束索引
(4)

Pistart,jend=sigmoid(mconcat(Eistart,Ejend))
(5)
式中m是学习权重。将获得的结果合并得到范围概率分布矩阵
式中pij表示句中索引i到索引j组成词组的概率。最后,通过人工设定阈值,输出匹配的词组结果。
2.4 改进损失函数
尽管机器阅读理解模型通过编码问题信息丰富了输入特征,但在数据集中存在着很多易分类样本和难分类样本。这使得难易样本之间存在不平衡,从而降低了分词的准确度。为了解决上述问题,本文改进了交叉熵损失函数
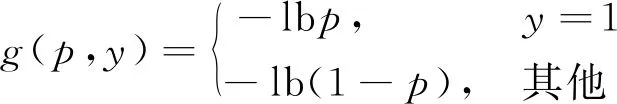
(6)
式中:y∈{-1,1}是一个真实类;p∈[0,1]是模型对标签为y=1的类的估计概率。交叉熵函数在机器阅读理解模型使用为
(7)
式中Ystart,end表示每个起始索引的真实标签。总的损失函数为上述3个损失函数之和。然而,即使是容易识别的样本也会因为交叉熵损失而遭受非显著程度的损失。这些微小的损失值在大量容易识别的样本中汇总起来,可以淹没稀有类。通常,在样本不平衡问题上,普遍存在着的是正负样本不平衡,即正(负)例太多、负(正)例太少。一个解决正负类别不平衡的常用方法是为类别引入一个权重因子α∈[0,1][27]。最后,权重之和重写为
L=αtLstart+βtLend+γtLspan
(8)
在本文实验中,训练机器阅读理解中文分词模型时会遇到普遍不平衡现象压倒了交叉熵损失。易分类样本占了损失值的大部分,并主导了梯度。尽管αt、βt、γt能够平衡正负样本不平衡,但是无法平衡难易样本。因此,需要降低易分类样本权重并关注难分类样本。本文借鉴目标检测中平衡正负难易样本的方法,对交叉熵函数引入一个平滑因子[23]
(9)
式中θ≥0是关注度参数。因此,定义新的损失函数
F(p,y)=ptg(p,y)
(10)
在式(10)中可以通过参数θ来平滑地调整易分类样本的损失权重。例如,在θ=2和样本概率p=0.9时,可计算出与没有平滑因子相比,这个样本对损失的贡献权重降低为原来的1%。在p=0.1时,这个样本显然是难分类样本,计算出的平滑因子要比易分类样本要高,意味着模型在梯度更新过程中应该更加关注这个样本。合并式(7)~(10),得到最终的损失函数
L=αtF(Pstart,Ystart)+βtF(Pend,Yend)+
γtF(Pstart,end,Ystart,end)
(11)
通过改进交叉熵函数缓解了难易样本间的不平衡问题。
3 实验与结果分析
3.1 数据集
进行基于机器阅读理解模型的中文分词任务,实验所用数据集来自Bakeoff2005语料库中的4个公共数据集PKU、MSRA、CITYU、AS。因机器阅读理解任务不同于序列标注任务,需将原本的训练集和测试集转换成MRC所需格式(MRC所用训练集和测试集均与原数据集相同),转换后数据集样本数详细信息如表2所示,表中显示了未登录词(out of vocabulary,OOV)在测试集中的比例。
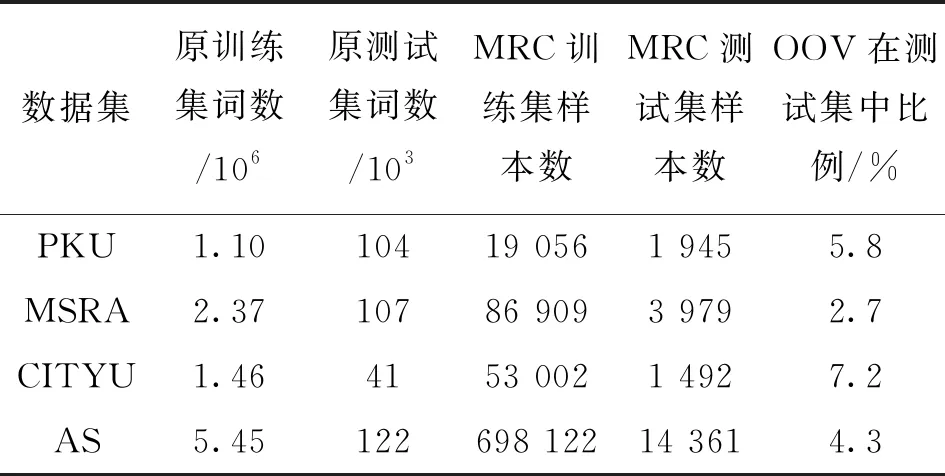
表2 训练集、测试集和OOV样本数的统计信息
3.2 评测指标
实验采用精准率P、召回率R、F1值为评测指标,其中主要以F1值为主要评测指标。P、R、F1值的计算公式分别为
(12)
(13)
(14)
式中:Wc为正确分词样本数;Wa为全部样本数;Wt为测试集中正确的样本数。
未登录词是指已知词典中不存在的新词,识别出未登录词也是评价中文分词模型性能优劣的重要指标之一。未登录词召回率计算公式为
(15)
式中:Ws为数据集中正确的分词答案;Wp为模型预测分词的结果;V(Ws)为Ws中的词组未在词典中出现的词数。
3.3 超参数及训练设置
超参数的选择对模型训练结果有很大影响,超参数设计如下:优化算法使用Adam,初始学习率为0.000 05,以0.05速度进行衰减;每个batch_size为16,Dropout为0.2,迭代20轮;概率分布矩阵阈值为0.5。本文选择BERT中的base版本。
3.4 实验结果及分析
将本文模型与中文分词常用的经典模型CRF、LSTM、ELMo、BERT以及近年来其他中文分词模型等进行实验对比,结果如表3所示。

表3 中文分词模型实验结果对比
从表3可以看出,本文模型尽管在PKU数据集上效果略差,但与近年深度学习的中文分词模型相比还是取得了不错的结果。这主要缘于以下3点。一是本文模型在构建时区别于序列标注任务,将模型的构建分为3个步骤:首先,将序列标注数据集格式转换成机器阅读理解格式;其次,构建问题信息以丰富输入特征;最后,改进损失函数缓解难易样本不平衡,从而提高模型的性能。二是问题内容构建上采用词定义的方式,比问句式所获得的输入特征要更加丰富。三是本文模型适用于中文分词中结构明确、词组边界清晰、存在歧义词等特点的特定领域数据。
为验证改进损失函数对于平衡难易样本的有效性,改变改进损失中的参数θ进行实验,结果如表4所示。

表4 不同θ下的实验结果对比
当θ=0时,交叉熵损失函数与改进的损失函数相等。从表4可以看出,相比于不加平滑因子,加入平滑因子后性能都有提升。在PKU、MSRA、CITYU、AS数据集上,F1分别提升了1.46%、0.89%、0.7%、1.04%。式(9)以及实验结果表明,当θ=1时,模型对易分类样本的损失抑制和对难分类样本关注度变化较小,使得在缓解难易样本不平衡上效果较弱。θ=2时模型性能最好。这是因为θ=2时,本文模型能够较好地抑制易分类样本损失和关注难分类样本。但是,当θ=5时,过度的抑制易分类样本损失和关注难分类样本,使得模型性能反而下降。这是因为过度抑制易分类样本损失反而会造成模型对易分类样本识别错误。若在模型已经收敛的情况下去过度关注那些非常难分类的样本,也会使模型产生误判。上述两种情况会导致模型的准确度降低。
未登录词是影响中文分词准确性的关键问题之一。为验证阅读理解分词模型在OOV上的表现,对比了阅读理解模型和表3中的经典模型在OOV上的性能,结果如表5所示。可以看出,本文方法在OOV识别效果上均优于经典模型。其原因在于:①大规模预训练模型BERT通过海量数据进行预训练,掌握更好的通用语言能力,下游任务只需微调即可获得优异性能;②OOV中也包含歧义词和难分类样本。本文在预训练模型BERT基础上丰富输入特征和改进损失函数,在提高歧义词识别的基础上,也增强了OOV的识别。尽管如此,由于新词的不断出现,中文分词中OOV的识别仍具挑战性。

表5 不同模型的OOV召回率实验结果对比
在对实验过程进一步分析后,发现本文方法在样本数较少的情况下也呈现出不错的结果。本文将4个公共数据集按10%、20%、40%、80%、100%的比例划分训练集,测试集保持不变,实验结果如图3所示。可以看出:4个公共数据集按比例划分训练集,送入模型训练20个epoch后,在测试集上得到的实验结果相差不大;随着训练集规模的增大,实验结果提升较小;本文提出的机器阅读理解模型能够在样本数较少的情况下,达到较好的中文分词结果。
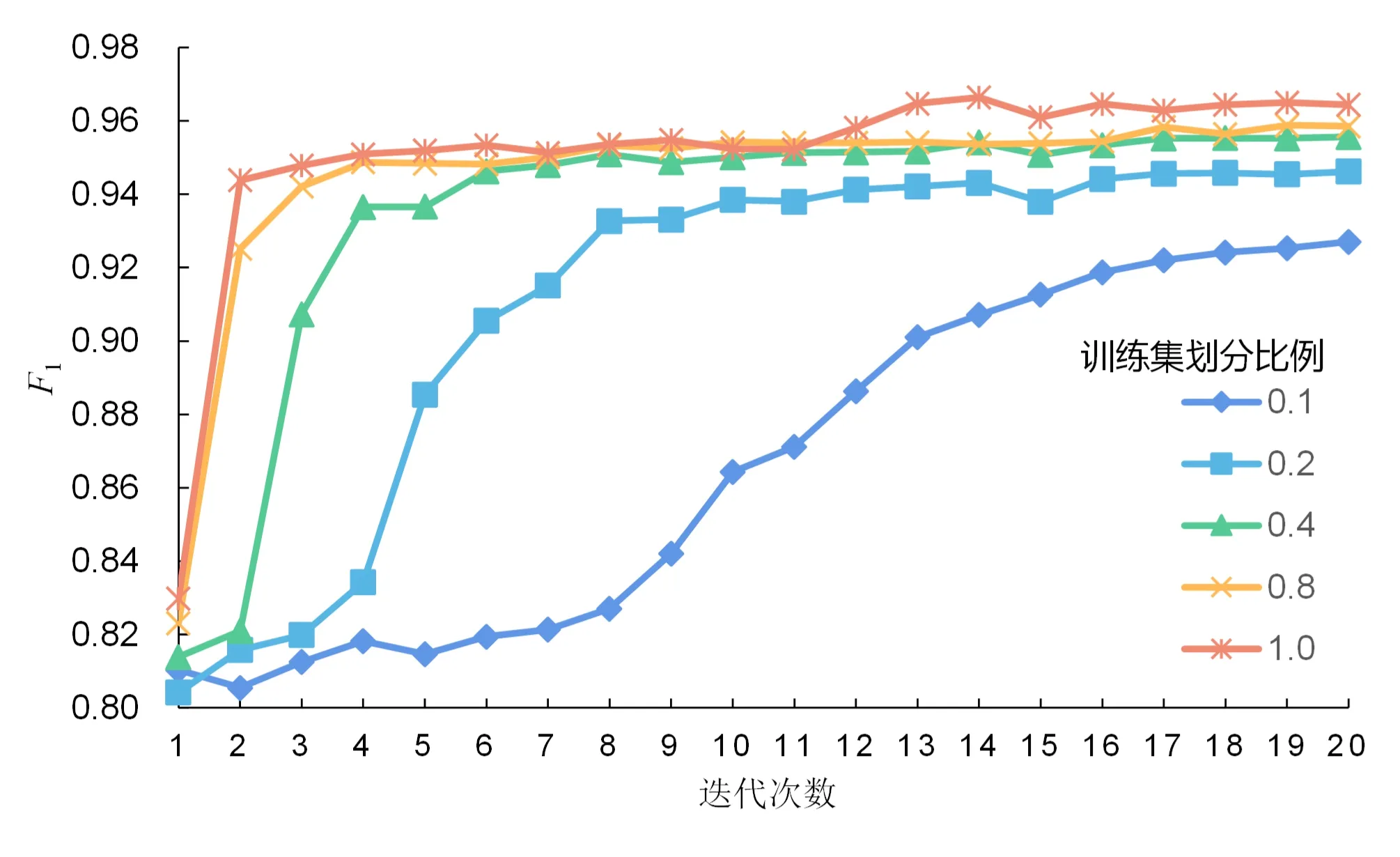
(a)PKU数据集
最后,对本文模型进行消融实验分析。表6对原始MRC方法[21]和本文方法进行了实验对比,并在问题信息构建上采用了表1中的两种方式。
从表6可以看出,改进损失函数和问题信息构建的不同会带来明显的提升。在PKU、MSRA、CITYU、AS数据集上,比原始MRC方法[21]分别提升了1.52%、1.05%、0.91%、1.29%。由此说明对基础的MRC模型改进损失函数后,能更好地缓解难易样本的不平衡。在问题信息构建上,词定义的方式比问句的方式能带来更加丰富的特征,使得模型在4个数据集上都获得了一定的提升。
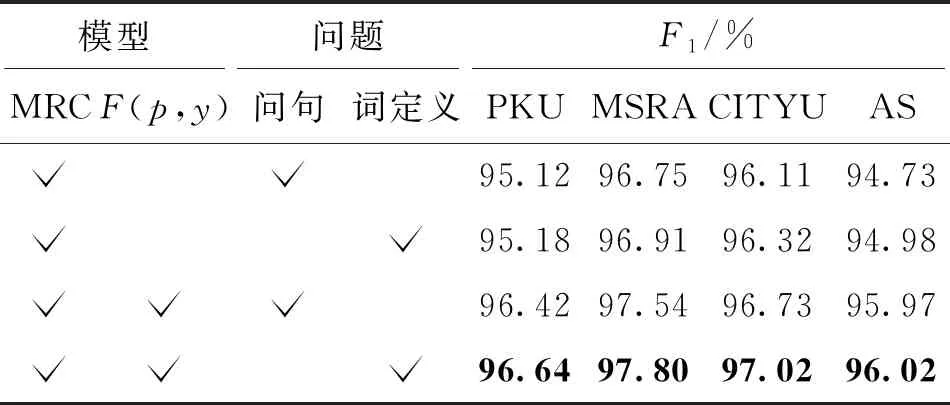
表6 消融实验结果
综上所述可知,本文提出的基于机器阅读理解的中文分词方法可以有效解决中文分词领域的分词问题。
4 结 论
本文提出了一种机器阅读理解模型的中文分词方法,解决了序列标注模型很难获取句子长距离依赖导致输入特征使用不充分、边界样本少导致数据不平衡问题。本文将序列标注任务转换为机器阅读理解任务并改进损失函数,进而有效地增强输入特征使用和缓解数据不平衡。实验结果表明,本文提出的方法相比于序列标注模型的中文分词方法具有明显优势。
本文是机器阅读理解模型在中文分词上的初步探索,该方法还有进一步改进的空间。在下一步工作中,可以使用不同的预训练模型和改进注意力机制来更好地捕获上下文信息。通过探索新的模型架构、设计新的问题构建方式,进一步提升机器阅读理解模型在中文分词上的应用。
