基于近红外光谱的条斑紫菜菌落总数快速检测技术
2022-08-16孙文珂沈照鹏权浩严徐锡明乔乐克杜春影
孙文珂,沈照鹏,权浩严,徐锡明,乔乐克,杜春影,王 鹏,
(1.中国海洋大学食品科学与工程学院,山东青岛 266104;2.中国海洋大学医药学院,山东青岛 266104;3.青岛海洋生物医药研究院,山东青岛 266071)
紫菜(Porphyra)属于红藻门(Rhodophyta)红藻纲(Rhodophyceae)红毛菜亚纲红毛菜目红毛菜科[1]。我国常见紫菜品种有条斑紫菜(Pyropia yezoensis)和坛紫菜(Pyropia haitnensis)、圆紫菜、甘紫菜等,其中条斑紫菜和坛紫菜是我国主要的栽培物种[2]。条斑紫菜是北太平洋西部特有种,在韩国、日本等国广泛栽培,为我国引进日本紫菜品种,主要产区在江苏等地[3]。条斑紫菜含有丰富的营养物质如蛋白质、氨基酸、多不饱和脂肪酸、EPA、维生素等[4],因此条斑紫菜具有预防高血压及冠心病、降低血脂水平、预防动脉粥样硬化等生物活性[5-8],具有较高的商业价值。
目前,中国、日本、韩国为世界紫菜生产量前三的国家,产量之和占世界总产量的96%,贸易量占世界的98%以上[9],中日韩三国在紫菜贸易方面的竞争也日益激烈。因缺少国际标准,三国在国际紫菜标准的制定上出现分歧,尤其在水分、重金属、农药残留及微生物等方面。他国为保护本国紫菜相关贸易优势,借助技术优势,遏制我国紫菜国际贸易发展[10-11]。因此,加强相关检测技术的研发,有利于在国际标准制定中占据主导地位。对于微生物这一质量指标,目前仍采用传统方法检测,存在检测样品批量大、周期长、时间成本高等问题。因此,革新紫菜微生物质量指标检测技术,建立快速检测方法,有利于提高我国紫菜产业生产与监管能力,提高国际竞争力,使我国紫菜产业在世界市场上占据优势地位。
近红外谱区是波长范围在780~2526 nm 的电磁波[12],近红外光谱技术则是在这一波长范围内,以光谱学、化学计量学、基础测量学和计算机等技术为基础的综合技术[13],具有快速、无损检测等优势,目前广泛应用于食品、医药等领域。Marques 等[14]测评了两种手持式近红外光谱仪对乌姆布果质的分析性能;Hadi 等[15]将便携手持式近红外(NIR)光谱技术与分类算法相结合;开发了一种预测鸡肉的真实性的方法。除此之外,近红外光谱也被应用于微生物快速检测中,闫思雨等[16]通过傅里叶变换近红外光谱仪及偏最小二乘回归(PLSR)方法建立了冷藏鲜切猕猴桃片微生物污染水平的快速检测模型[16]。本研究结合近红外光谱技术、化学计量学与机器学习等手段,构建了条斑紫菜菌落总数的预测模型,实现了条斑紫菜品质的快速评价,建立了针对条斑紫菜微生物这一质量指标的快速检测方法。
1 材料与方法
1.1 材料与仪器
紫菜 于2020 年江苏赣榆采集条斑紫菜干样品155 组(每张紫菜样品尺寸为19 cm×21 cm,每组共采集10 张条斑紫菜样品作为平行)包含按照江苏省地标DB32/T 1021 定义的五级二十二等,来自赣榆、秦皇岛、青岛、威海等地;PCA 培养基 青岛海博生物技术有限公司;NaCl(分析纯)国药集团化学试剂有限公司。
MicroNIR 1700ES VIAVI 近红外光谱仪 美国VIAVI;LDZX-30KBS 型高压灭菌锅 上海申安医疗器械厂;LRH-70 型恒温干燥箱 上海一恒科学仪器有限公司;ME203E 型电子天平 上海梅特勒-利特多有限公司;HWS24 型恒温水浴锅 上海元析仪器有限公司等。
1.2 实验方法
1.2.1 紫菜样品菌落总数检测 方法参照GB 4789.2-2016 《食品安全国家标准 食品微生物学检验 菌落总数测定》。
1.2.2 光谱采集 所采用仪器参数为:波长范围为900~1650 nm、光谱分辨率为6.2 nm、样品工作距离(即样品与探头距离)为3 mm、信噪比为23000(扫描次数为100 次,采集后取平均值)、工作温度为25 ℃。预热设备15 min,采用漫反射积分球模式采集紫菜样品(紫菜样品图片如图1 所示,均为交易干制紫菜样品)的近红外光谱,校正暗电流并以四氟乙烯白板为参比,调整仪器后采集条斑紫菜样品的近红外光谱数据。在采集光谱时,将样品竖立放置,每张紫菜样品分为20 等份,采集对角线上8 份区域的光谱数据(具体采集方式见图1)。

图1 条斑紫菜样品光谱采集区域Fig.1 Spectral collection area of Pyropia yezoensis
1.2.3 样本集划分 利用进行近红外光谱分析的对象大多数需要采集大量的实际样本数据,但会有许多重复样本,所以需要从中选择具有代表性的样本用于校正模型数据集的建立。常见的样本选择的方法有,随机选取法、K-S 法、SPXY 法等[17]。本研究选用SPXY 法,该方法在计算样品间欧氏距离时,同时考虑样品光谱信息和理化参数信息,达到充分选择具有代表性样本的目的,从而改善校正模型预测能力。
将所测得样本集划分为测试集与校正集,通过校正集的校正结果和预测集样本的预测结果来判断所建模型的质量。采用SPXY 算法以4:1 的比例分成校正集和预测集,其中校正集为124 个样本,测试集为31 个样本。校正集用于训练校正模型,测试集用于评估校正模型。
1.2.4 近红外光谱数据预处理 为消除误差,提高建模准确性和稳定性,采用标准正态变量变换(Standard Normal Variate trans-formation,SNV)、多元散射校正(Multiplicative Scatter Correction,MSC)、一阶/二阶导数(导数程度参数为2,drop 参数设置为True)、S-G 平滑(平滑点数为5,多项式次数为3)等方法进行光谱数据预处理。其中SNV 主要是用来消除固体颗粒大小、表面散射以及光程变化对NIR 漫反射光谱的影响;MSC 主要是消除颗粒分布不均匀及颗粒大小产生的散射影响;导数算法则主要可以消除样品背景的干扰、分辨重叠峰、提高灵敏度[18]。在本研究中通过建立相同算法模型(卷积神经网络CNN),比较各预处理后所得模型预测均方根误差和皮尔逊相关系数评价预处理效果。
本研究开源Python 3.8.2 与相关数据科学包进行模型建立及数据分析。
1.2.5 不同的算法预测模型建立与对比分析 光谱数据经预处理及特征波长筛选后,将光谱数据分为测试集和验证集,应用不同的算法建立预测模型。应用非线性拟合(mixed logistic regression,MLR)、支撑向量回归(Support Vector Regression,SVR)、人工神经网络(Artificial Neuro Network,ANN)等方法建立模型。与卷积神经网络建立的校正模型进行对比,探究建立表现优秀的条斑紫菜菌落总数含量定量校正模型。
卷积神经网络(Convolutional Neural Networks,CNN)是一类深度神经网络,是机器学习中常见的模型结构。其基本架构由输入层、卷积层、池化层、全连接层和输出层堆叠而成[19],其中卷积层和池化层常以先卷积后池化的形式多组存在。卷积神经网络在图像识别领域应用较为广泛,其可以通过深度学习使机器准确的识别图像特征信息[20]。本研究中采用CNN 的结构由3 层一维卷积层(conv1d)、2 层最大池化层(maxpooling1d)和2 个全连接层(dense)组成(架构图如图2 所示)。
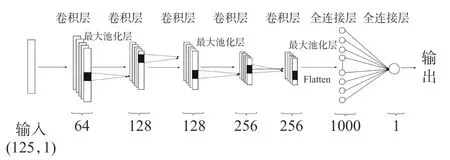
图2 卷积神经网络(CNN)架构图Fig.2 Convolutional Neural Network(CNN)architecture diagram
1.2.6 模型评价与优化 本研究以预测集的相关系数r和预测均方根误差(root-mean-square error of prediction,RMSEP)为指标评估各模型。通常RMSEP值越小,且r值越大,模型的预测效果越好。
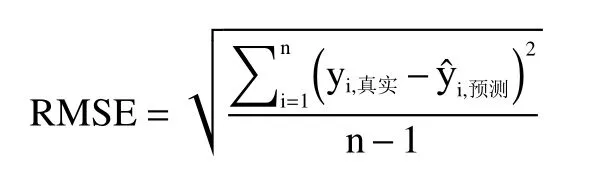
式中,yi,真实代表第i 个样品的指标真实值;为第i 个样品的指标预测值;n 表示样品数量。
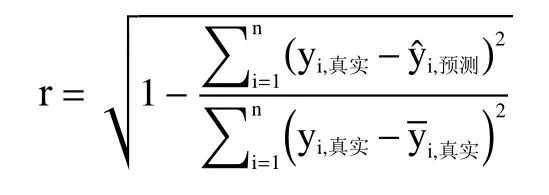
式中,yi,真实为第i 样本的指标真实值;为第i 个样品的指标预测值;为校正集或测定集中所有样品真实值的平均值;n 表示样品数量。
在CNN 模型优化阶段,对CNN 模型的迭代次数和学习率超参数进行优化,并以预测均方根误差(root-mean-square error of prediction,RMSEP)和皮尔逊相关系数(Pearson correlation coefficient,P)为指标评估优化后模型,且P值越小,表示相关系数越显著。
2 结果与分析
2.1 紫菜样品菌落总数检测结果
按照上述方法对紫菜样品进行菌落总数测定后,最终统计如下:菌落总数最大值为7.38 lg(CFU/g),最小值为4.65 lg(CFU/g),平均值为6.19 lg(CFU/g)。将其菌落总数测定结果进行可视化后发现,其数据符合正态分布规律(见图3),可以作为数据集进行进一步模型的建立。
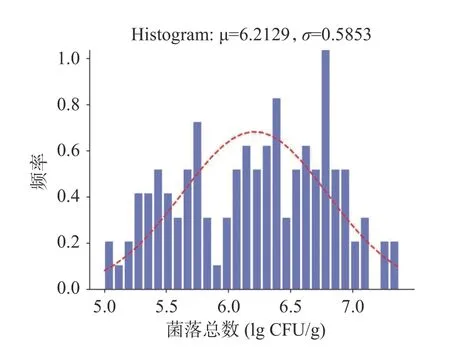
图3 条斑紫菜样品菌落总数分布图Fig.3 Total number of colonies distribution of Pyropia yezoensis samples
2.2 近红外光谱数据采集
本实验对155 组条斑紫菜样品进行近红外光谱数据采集结果如图4 所示,光谱数据较为杂乱且噪声影响、样品背景影响较大,无法直接用于建模分析。因此需要对光谱数据进行预处理,识别特征波长信息,提高所建模型的准确性和可靠性。
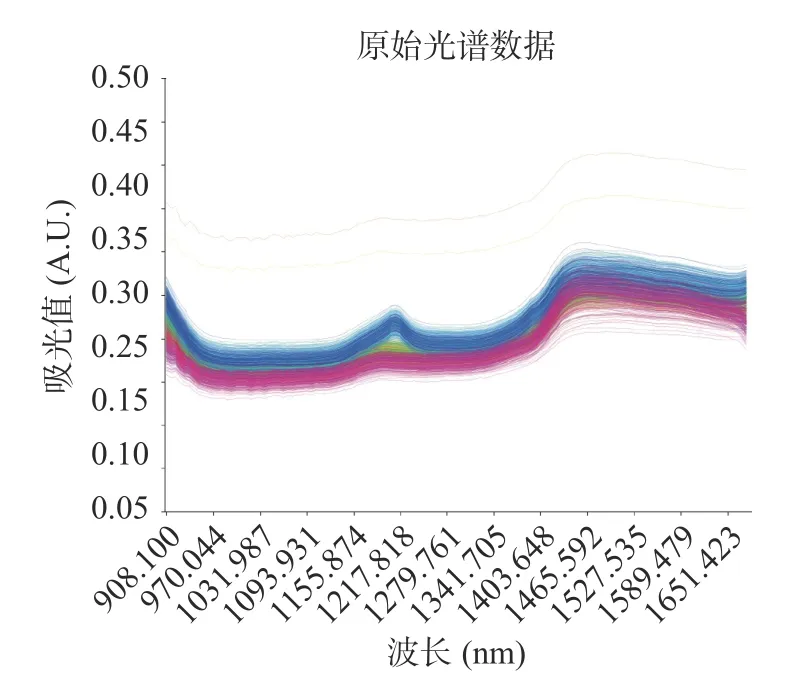
图4 155 组条斑紫菜近红外光谱采集Fig.4 Raw near infrared spectra of 155 groups of Pyropia yezoensis samples
2.3 近红外光谱数据预处理
由于直接利用近红外光谱仪扫描得到的近红外光谱数据受基线漂移、噪声等信号的影响,会导致之后建模准确性和稳定性下降。因此在进行建模前,为了消除样品的不均一性带来的误差及样品背景的影响,均需要对光谱数据进行合理的预处理[18,21]。光谱数据预处理是近红外分析中至关重要的一步,不同的预处理方法对校正模型的建立产生的影响也不相同。在本研究中,选用SNV、MSC、导数和平滑等多种预处理方法以单一或组合的方式处理原始光谱,从而消除因样品本身以及环境因素对近红外光谱的影响,各方法分析结果见图5。从图5 中可以看出,在用SNV 及MSC 方法对光谱数据进行处理后,光谱平移被消除但趋势并为改变,无法突出特征光谱波长段,因仅用SNV 和MSC 处理光谱数据并不足以建立较为准确的光谱数据集(图5A,图5B)。用一阶导数处理后的光谱数据可以明显的反映特征光谱数据波长阶段,而二阶导数处理后的光谱数据则导致峰较为混乱、噪声增大且无法突出光谱特征波段(图5C,图5D)。在评估了这四种光谱数据预处理方法后,发现其中一阶导数对于光谱数据的处理效果较为优秀,因此在一阶导数对光谱数据的处理基础上进行了SG 平滑处理(图5E),由图可见,相对于未经S-G 平滑处理的一阶导数处理光谱数据,经过S-G 平滑处理后,光谱数据噪音减少且有效信息及特征波长段保留,处理效果较好。
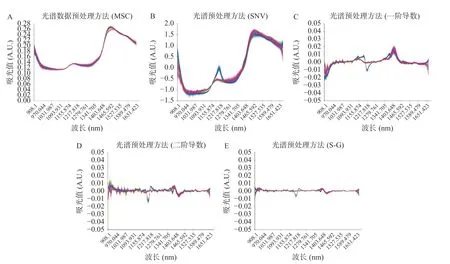
图5 经过不同预处理方法处理后的近红外光谱Fig.5 Near infrared spectra after different pretreatment methods
为进一步验证几种光谱数据预处理方法对光谱数据的处理结果,基于这几种预处理方法(MSC、SNV、一阶导数、二阶导数、S-G 平滑)处理原始光谱后,分别建立CNN 模型,模型的表现见表1,从表中可以观察得出,二阶导数作为预处理方法的效果最好,校正模型表现为Rp=0.558,预测集的Rp相比于未进行预处理的组,提升了0.048。为进一步通过预处理方法提升菌落总数校正模型的表现,将SNV 和导数处理结合进行模型表现提升的探究,结果如表2。发现SNV 与二阶导数共同处理光谱后建立的CNN 模型RP为0.543,模型表现相比一阶导数预处理后的模型表现(RP为0.518)有少量提升,所以将二阶导数和SNV+二阶导数两种方法都用于后面探究最优预处理和模型组合的研究中。
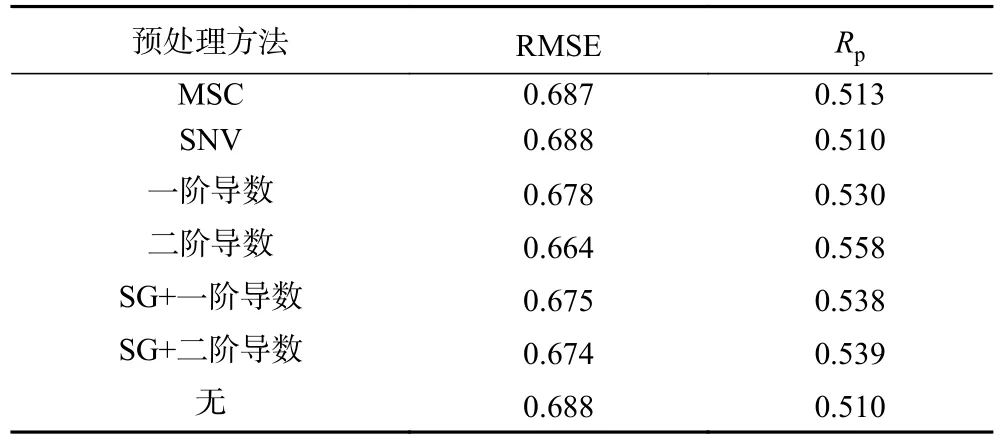
表1 不同预处理方法对建立菌落总数预测模型的结果Table 1 Results of different pretreatment methods on the establishment of the total number of prediction model

表2 不同组合预处理方法对建立菌落总数预测模型的结果Table 2 Results of different combinations of pretreatment methods on the establishment of total number of colonies prediction model
2.4 预测模型建立
在确定合适的光谱数据预处理方法后需要建立合适的模型进行预测。对于近红外光谱数据分析任务来说,主要分为定性和定量两种,在本研究中为定量任务,模型输出的结果为连续值。本研究在2.3 分析得到光谱数据预处理较优方法的基础上,对经预处理得到的光谱数据进行模型建立,三种传统定量校正模型(MLR、SVR、ANN)与预处理方法建立模型结果见表3。表中观察得到,表现最好的模型组合为用SNV+二阶导数进行光谱数据预处理后用SVR 进行建模,由此组合建立得到的模型RP值最高,为0.724。
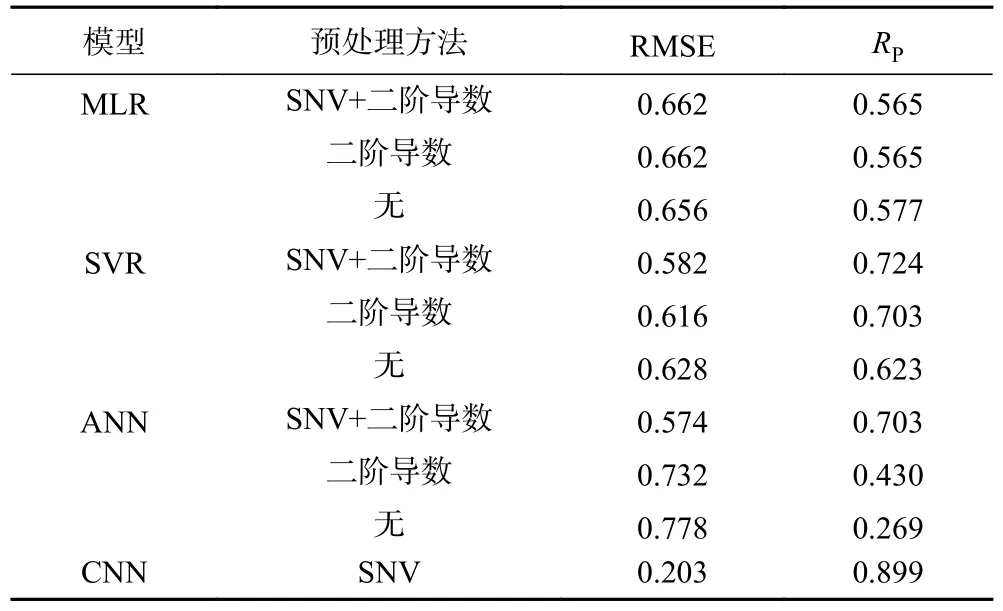
表3 最佳预处理方法和建模方法建立菌落总数校正模型的结果Table 3 Results f the best pretreatment method with modeling methods to establish total number of colonies calibration model
近年来也有众多研究报道有关微生物的预测模型,如刘鹏等[22]采用多元散射校正(MSC)的预处理方法。先通过主成分分析(PCA)提取主要数据并排除异常值,再通过判别分析(DA)对培养四个阶段的花生生长状况进行区分;最后通过偏最小二乘回归分析(PLSR)对花生中菌落总数进行定量分析,最终所得模型R值为0.8741,RMSE 为0.276;刘建学等[23]对原料乳中大肠菌群建立了偏最小二乘回归模型、逐步回归模型等,其中效果最优模型R 值为0.9126、Pereira 等[24]采用S-G 平滑、一阶导数、二阶导数对光谱数据进行预处理后,建立偏最小二乘判别分析(Partial least squares Discriminant Analysis,PLSDA)模型,对牛奶中沙门氏菌的污染程度进行了定量分析,所建立模型RMSE 为0.1639。相对于其他报道中对于微生物的预测模型,本研究基于传统计量学的预测效果相对较差,因此又考虑通过建立深度学习模型进行数据处理分析。
相较于传统计量学模型,深度学习模型则具有较优的非线性数据拟合能力,其对于特征提取的能力表现也更好。除此之外,深度学习在巨大数据集上的表现要优于传统计量学学习,更适合处理高维度的数据。目前已有研究将CNN 应用到近红外光谱分析上,如Zhang 等[25]用CNN 来处理近红外光谱数据集(玉米、片剂、小麦和土壤)从而评估预处理效果。在本实验中,CNN 模型表现如表3 所示,RP为0.899,比传统计量学方法建立的最佳模型(SNV+二阶导数)表现(RP=0.724)相对最优,其R2为0.810 大于0.8,说明模型建立成功且具有一定实际意义,同时说明了CNN 可以更好地从光谱中特征提取相关特征,而且建立的校正模型表现要比传统计量学方法更加优秀。
为获得表现最优秀的校正模型,继续对校正模型进行优化,优化的对象为CNN 的两个超参数,分别是迭代次数和学习率。结果如表4,合适的模型超参数设定为:迭代次数为500、学习率为0.001,此时模型RMSE 由未优化的0.530 降低到0.290,P从未优化的0.146 降低到0.068,R值则升高至0.940,在所有CNN 优化模型表现最优。
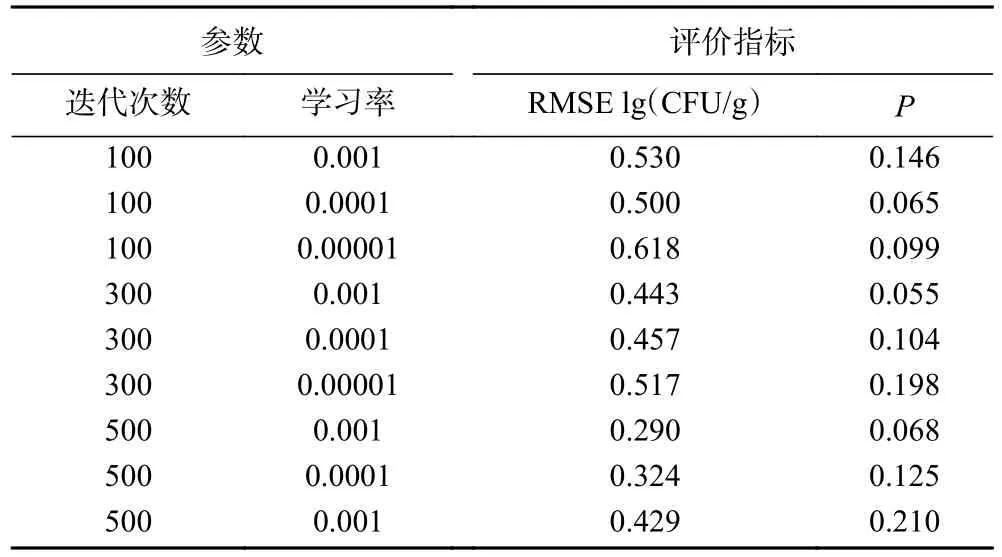
表4 CNN 建立菌落总数校正模型的结果Table 4 Results of CNN model hyperparameter optimization
虽然与Cristina 等[26]对于医疗产品、Achata 等[27]对于牛肉、曾思杰等[28]对于青金桔果粉、闫思雨等[16]对于猕猴桃建立的菌落数校正模型表现仍有较大差距(>0.95),但相比于这些研究中采用的较为复杂的预处理方法,本论文仅通过采集条斑紫菜片表面的光谱简单预处理就建立了效果较为理想的条斑紫菜菌落总数定量模型,且CNN 模型本身是基于TensorFlow建立的,所以模型相比于其他商业软件建立的模型拥有更好的应用场景,可以将模型部署于移动智能设备上[29],随时结合便携式光谱仪设备用于现场评价条斑紫菜质量,效果较优。
在对比了不同模型的预测效果后,最后选择了20 组非数据集内条斑紫菜样品光谱,进行模型的外部验证,验证结果如表5、图6,模型预测结果与真实样品的菌落总数偏差很小,说明该CNN 模型可以在实际使用场景中拥有较好的预测效果,可以实现快速准确地预测条斑紫菜菌落总数。
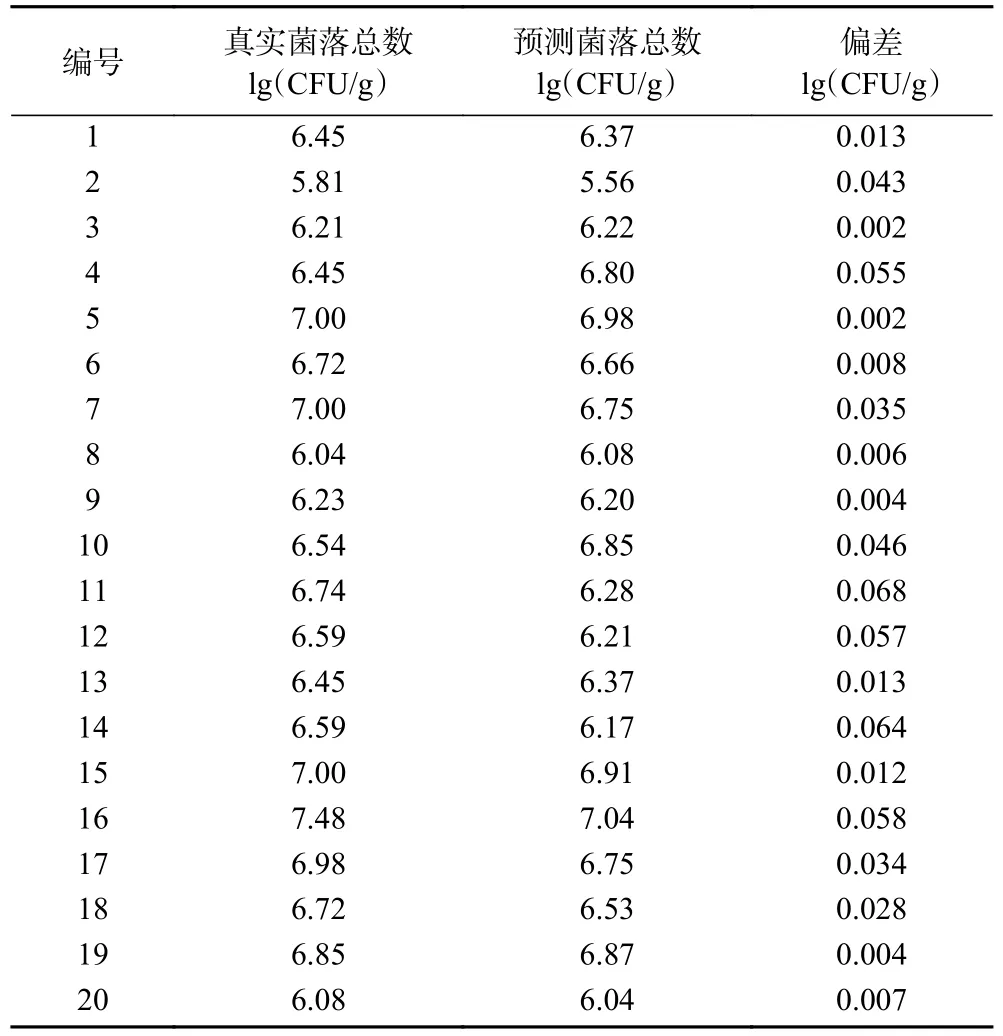
表5 外部样本模型验证结果Table 5 Results of Model verification by external samples
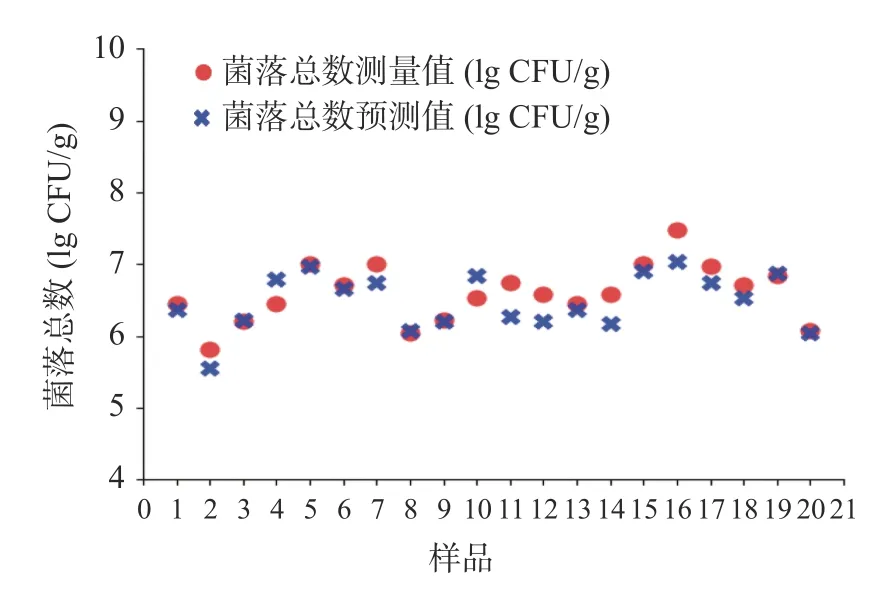
图6 外部样本模型验证结果Fig.6 Results of Model verification by external samples
3 结论
本文采用非线性拟合、支撑向量回归、人工神经网络、卷积神经网络对条斑紫菜中菌落总数含量建立了模型和优化,在建模过程中对不同光谱预处理方法进行筛选。结果表明,在同种模型情况下,SNV 与二阶导数的组合预处理效果最优。在最优的预处理方法下,又对比了不同模型的预测效果,其中深度学习模型CNN 预测效果最好,进一步将其进行优化后RMSE 值为0.290,P值为0.068,R值为0.940,同时外部验证效果良好,能够快速准确地预测条斑紫菜菌落总数。由此可以说明,CNN 作为一种深度学习模型,可以实现针对条斑紫菜微生物品质的快速评价,为丰富紫菜微生物质量指标检测技术奠定理论基础。
