强化类间区分的深度残差表情识别网络
2022-08-16葛洪伟
黄 浩,葛洪伟+
1.江苏省模式识别与计算智能工程实验室(江南大学),江苏 无锡214122
2.江南大学 人工智能与计算机学院,江苏 无锡214122
面部表情是人类情绪的最直接外部表现之一,同样的信息配合不同的表情可能有完全不同的涵义。要达到高效的人机交互,机器准确理解人类表情至关重要。除了追求未来科技上的进步,在各种现实问题上,表情识别也有广泛的应用前景。在心理学研究、疲劳驾驶检测、自闭症行为研究等现实问题上已经有了部分应用。其分支微表情识别也具备成为公共安防和刑侦审讯的重要工具的潜力。
在实际的课题研究中,数据是表情识别任务中的关键。根据数据的来源,可以将数据分为室内(lab-controlled)数据和野外(in-the-wild)数据。前者是邀请志愿者拍摄给定的表情,后者多是网络上收集数据交由专业人士标注。一般而言,网络数据要比实验室摆拍更贴近真实生活中的场景,人的表情更加自然。同时,网络数据也更能涵盖不同国家、不同种族、不同肤色、不同信仰的人物数据,因而近年来的多数研究都集中在野外表情识别上。野外数据集拥有海量的数据,数据的量级和复杂程度导致传统方法表现不佳,基于深度学习的表情识别已是现阶段表情识别研究的最热门也是最有效的方法。
如图1 所示,深度人脸表情识别系统一般由三个部分组成:数据预处理、深度特征学习、深度特征分类。数据预处理包括人脸对齐、数据增强、数据清洗等方面。受益于人脸识别的多年发展,数据预处理阶段的多数问题有了成熟的解决方案。多数的研究都是在后两个主题上做修改,通过修改网络结构或者损失函数来学习到更准确的数据模型。

图1 深度表情识别通用流程Fig.1 General pipeline of deep facial expression recognition system
将表情视为动态过程更契合事实,这一方面也有了很多研究工作。然而,无论是处理成图像序列还是视频数据库,都存在着计算量大、标签成本高等实际问题。静态的图片用于情感识别虽有不合理之处,但由于其数据较易获得、较易标记、便于研究等特点,是现阶段表情识别的重点。同时,从静态图像中研究出来的成果也可以较为方便地移植到图片序列的识别任务中。
不同于其他的模式识别任务,人脸表情识别数据中的有用信息相对较少。具体而言,识别表情主要依靠分辨五官和整体面部的几何特性,人脸的毛发、纹理、装饰物往往起到的是负面作用。大量的冗余信息使得表情识别问题的精度严重受限,即使是深度学习方法也需要引入部分先验知识作为辅助。2016 年,Barsoum 等提出使用众包算法可以提高人脸表情数据库的标签可靠性,同时达到节约成本的目的。通过重标签引入了更多信息,提供了Ferplus数据库;2019 年,Barros 等提出了一种基于传统对抗性自编码器的神经网络模型来学习如何表示和编辑一般的情绪表达,通过一个PK(prior-knowledge)模块引入唤起/效价(arousal/valence)表征和面部分布信息。2020 年,Takalkar 等提出了一种集成多种特征进行微表情识别的方法,引入了LBP-TOP 手工特征信息,结合CNN(convolutional neural network)深度特征,在大规模数据上取得了良好效果。
目前,国内在这一方向上的研究也已经走到了世界前沿。其中,北京邮电大学的邓伟洪教授小组发表了多篇高水平论文,邓教授小组主要研究了野外(相对以前长期的实验室研究)表情识别问题,更贴切现实世界的情况,对于表情识别技术走向成熟和实际应用有重要意义,提出了DLP-CNN(deep locality-preserving CNN)模型,引入了深层特征的K近邻聚类损失;中国科学院计算技术研究所的山世光研究员所领导的小组在有遮盖的人脸表情识别方面取得了目前最好的结果,提供了有部分遮盖的人脸数据集,提出了pACNN(convolution neural network with attention mechanism)方法,引入了人脸特征点局部信息。
为了解决人脸表情识别精度较低的问题,本文引入了类间关联信息,提出了一种强化类间区分的深度残差表情识别网络RMRnet(recall matrix distinguished residual net),通过归一化召回矩阵的分析,得出类间联系,融合类间联系到残差网络的设计中,通过强化强联系类别的区分和适度平衡弱联系类别的区分为网络引入类间关联信息。在多个大型数据库上的实验表明,本文模型性能卓越,在精度上优于基础模型,在与先进方法的比较中也有良好的表现。
1 残差网络简介
残差网络(residual net,Resnet)由何凯明等提出,引入残差块概念来代替重复的卷积层,将一层卷积层的特征提取能力描述为(),那么对应的残差块为()=()-。由于采用了下采样跳层,一个残差块在反向传播时梯度递减的幅度仅相当于一层卷积。残差网络用来处理网络退化问题,有着强大的特征提取能力,并且有相对较少的参数。图2 展示了一个[[3×3,64],[3×3,64]]×2 残差块的结构(即Resnet18 中的第一个残差块),本文使用Resnet18 作为深度特征分析工具,也用作本文的骨干网络。
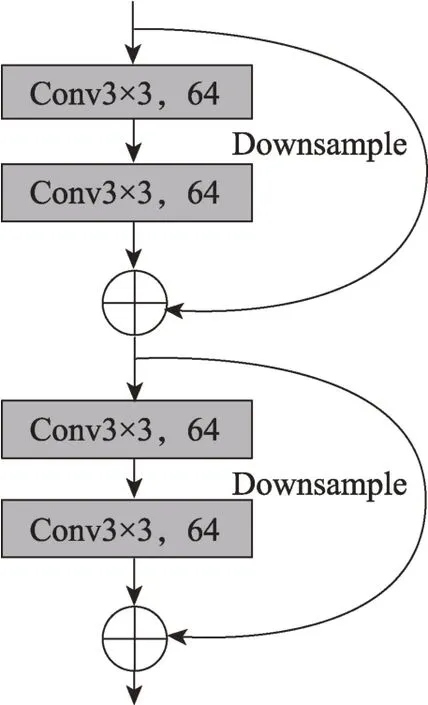
图2 一个[[3×3,64],[3×3,64]]×2 残差块Fig.2 A[[3×3,64],[3×3,64]]×2 residual block
2 RMRnet
2.1 利用Resnet18 分析类间关系
通常来说,评价一个表情识别模型的优劣主要依据总体分类精度(overall sample accuracy)。如果探究类间关系,利用CM(confusion matrix)。直接使用CM 矩阵,各次实验的数据之间会出现数值波动,也不够直观。为了下一步进行定量分析,对CM 矩阵做以下归一化:
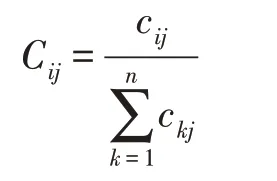
其中,c表示未归一化混淆矩阵(CM)的第行、第列的值,表示真实分类为第类却被划分为第类的样本数量,进一步可以求得CM 对应的RM(recall matrix)矩阵,RM 矩阵中的元素表示为:
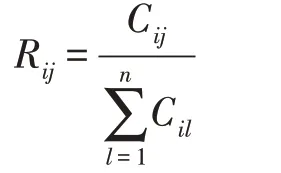
用RM 来对各类表情做定量分析,探究类间联系,如果各类数据之间确实关联程度不尽相同,那么联系更为紧密的类之间应该更难区分。本文在RAFDB 数据库上做了如下先验实验。
本文使用Resnet18 作为先验实验的网络模型,为了减少数据的长尾问题带来的影响,对RAF-DB 数据库做随机欠采样实现数据平衡:以最短类的数量为基准,在其他类中随机选择相同数量的图片(以后简称为平衡集)。图3 展示了在平衡集上的实验结果。由于平衡数据库的数据量较少,为了避免数据量的影响,还取了与此平衡数据集数量相等的符合原数据库分布的图片数据作为对照组(以后简称同分布集),对照实验结果如图4 所示。

图3 平衡数据集的Resnet18 实验(精度为58.6%)Fig.3 Resnet18 experiment of balanced dataset(accuracy is 58.6%)
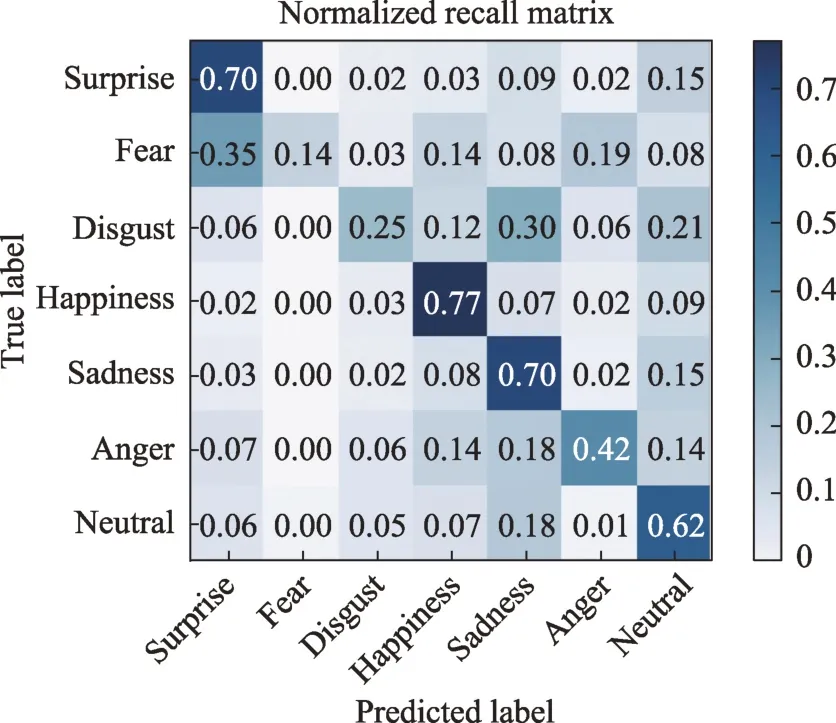
图4 原数据集同分布的Resnet18 实验(精度为65.6%)Fig.4 Resnet18 experiment with codistribution of original dataset(accuracy is 65.6%)
由于数据的长尾效应,在数据模型中的各类数据有着不同的权重,表现在对照组中就是如图4 所示的各类数据精确度的极度不平衡。例如图中的恐惧(fear)和快乐(happiness),恐惧(有26%的精确度)是原数据库中数量最少的类,仅仅有281 张图片,而快乐(有86%的精确度)作为原数据中最多的类,包含了4 772 张图片。
在经过数据平衡之后,由于数据的长尾效应引起的各类权重不一致被消除了。但由于测试集也有着和训练集类似的数据分布,就整体精度而言,Resnet18 在同分布集上的表现优于平衡集上的表现。通常情况下,并不希望一个网络模型对两个类识别精度有较大的差异,本文的网络模型设计也是基于平衡集给出的信息。并且,同分布集的数据被识别为大样本类的概率更大,从它的实验结果中也不可能得到公平的类间关系。使用以下的公式得到两个类之间的关联程度:

其中,(,)为true 时表示类和类相关度高,构建强关联集{,},反之,相关度低;R表示RM 矩阵中类被错误识别为类的概率,表示相关系数阈值,依经验设定。对于类,本文只考虑它的最大强关联集。例如:∈{,}且∈{,,}时,为了避免类的分类权值被高估,也为了避免设定过小时类间关系过于复杂,本文将只考虑包含类的最大强关联集{,,},舍弃强关联集{,}。最后将不属于任何一个强关联集的类别划分到弱关联集中。应用这样的方法,可以得到两个强关联集{fear,anger},{disgust,sadness,neutral}以及一个弱关联集{surprise,happiness}。
2.2 整体网络结构
融合上文中获取到的类间关联信息,本文的网络模型如图5所示。RMRnet模型接受RGB图片信息作为输入预测图中人物表情,网络由三部分组成:骨干网络Resnet18,强联系分支branch1、branch2和补充分支cp-branch。最后得到两个输出主干输出out和类间区分汇总信息b_out。对目标图片的预测值表示为:
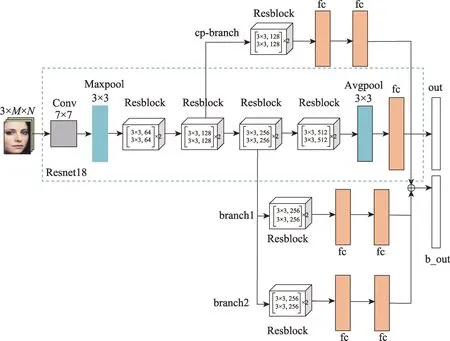
图5 RMRnet整体网络结构Fig.5 Pipeline of RMRnet network
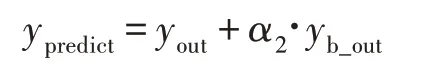
其中,表示类间信息参数,一般取0.1。对于骨干网络输出,选择交叉熵函数作为损失函数:
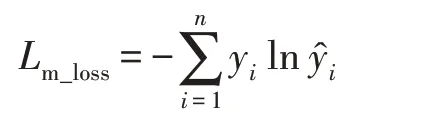
2.3 网络支路设计
相较于弱关联类,强关联类更难区分,需要更深层网络提取差异信息。出于对特征层次的考虑,本文将强联系分支branch1、branch2 放置在Resnet18 的第三个残差块与第四个残差块之间,将弱联系分支cp-branch 放置在Resnet18 的第二个残差块和第三个残差块之间。
每一个强化支路设计为一个残差块和两层全连接层的组合,分支的目的是为了进一步区分关联集中的类别组合。如果经过第个残差块得到的特征向量记为x,自然可以得到:

例如:要设计7 分类表情中{fear,anger}类别组合的分支(即第二和第六类),该支路将会输出一个二维而非七维的特征向量y,该向量只包含第二和第六类的高维特征。但为了实现的便利,在其他位对应的位置填充零值,依然将它处理为一个七维特征向量,以便进行后续的向量加法运算。
补充支路与分支支路设计的模式基本相同,都是一个残差块与两个全连接层的组合,唯一不同的是,将除去有关类别的剩余类别作为该支路的目标输出。这样的考量是基于以下推断,对于分类支路所得的特征向量y做加权后,该分支所涉及的类别对最终的高维特征有了影响,如果不设计补充支路,相当于其余维度的额外影响置零,在复杂的现实情况中,可能会带来误差。
补充支路与分类强化支路的输出汇总表示为:
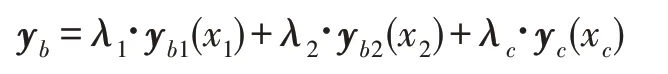
其中,y表示第个分支的特征向量,y表示补充支路得到的特征向量,表示各自的权重。同样使用交叉熵函数作为损失函数,支路误差表示为:


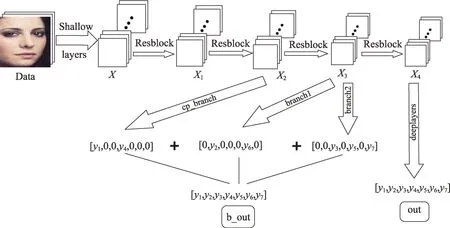
图6 数据流图Fig.6 Data flow diagram
2.4 差值约束损失
数据经过网络得到支路汇总输出y和骨干网络输出,两者都有分类能力,但是信息的侧重点不同。要利用支路信息辅助骨干网络进行分类,两者之间在数量级上不能有太大的差异。同时,要保证支路信息的完整性,两者也不能完全相同。为此,定义了差值约束损失如下:
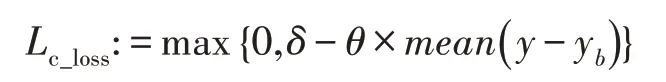
其中,表示约束参数,用于约束双方差异;为抑制参数,用于抑制梯度爆炸。整体网络模型的损失函数为:

由差值约束损失的定义可得,的三个构成部分有一定的联系,不能独立存在。作为本文结构中的关键部分,进一步消融是受限制的,也没有必要性。
3 实验与分析
实验部分,本文将简单地介绍用到的几个大型数据库,详尽地描述本文的实验环境,展示本文的模型与基准方法的对照,最后展示本文与现存的先进深度学习方法在各个数据集上的对比。由于各个数据库制作标准的客观差异,在不同数据集上的预处理方法各有不同。数据结果方面,除去基准方法Resnet18和本文模型的精度,其余提到的文章精度均取信于各自的论文精度。
3.1 数据库
文中选用的野外(in-the-wild)数据库是RAF-DB数据库、AffectNet 数据库和Ferplus 数据库。RAF-DB 数据库包括了29 672 张图片,每张图片由40 人标注。用到其中经过Face++定位过人脸的单标签类,包含12 271 张图片的训练集和包含3 068 张图片的测试集;AffectNet 是目前最大的公开表情识别数据库。它包含了超过100 万张图片,图片数据从互联网上收集。本文使用其中的已经人工标注过的图片,包括414 801 张图片的训练集和5 501 张图片的验证集,相较于RAF-DB,AffectNet 的标签要模糊许多。Ferplus 数据库是在Fer2013 数据库上重标签而来,一张图片有10 个标注者,图片为48×48 的灰度图,采用最大投票法,将十维标签转化为单标签。
3.2 实验设置
本文实验设定如下参数:网络模型接受224×224尺寸的RGB 三通道图片作为输入,批处理大小设定为16,动量设定为0.5,学习率设定为0.01,迭代次数为40。采用权重衰减和学习率衰减策略,权重衰减系数为10,学习率衰减方法为指数衰减。网络模型部署在单张Nvidia 2080Ti 显卡上,使用pytorch 深度学习框架。模型的骨干网络Resnet18 在ImageNet 数据库上做预训练。文中提到的各个参数设定如下:相关系数阈值∈(0,0.33),根据实际情况取值;类间信息参数一般取0.1;、、λ均取1;约束参数取值0.25;抑制参数视实际情况将×(-y)整体控制在(0,10)量级即可,实验中取10。
正如前文提到的,本文用到的各类数据库有不同的制作标准,实际上,几乎所有的表情数据库制定标准都不尽相同。RAF-DB 数据库为研究者提供了一个裁剪好的人脸图像,而AffectNet 数据库提供的图片甚至尺寸、格式也不统一,Ferplus 则仅仅提供了48×48 的灰度值矩阵。本文使用dlib 开源工具裁剪AffectNet 数据库中的原始图像。对于所有图片采用最邻近插值法,将图像尺寸调整为224×224。对于单通道图片,通过复制法将其转化为三通道图片。
3.3 实验结果
与基准方法Resnet18 进行对比,如果本文方法有效,各类数据被错误分类的情况不会再出现在某些类上较多,其他类上较少,应当是均匀的,表示本文方法中类间联系信息起到了作用。图7 和图8 展示了本文模型和基准模型在RAF-DB 数据库上预测结果的混淆矩阵,可以看出除happiness 类型以外的各类数据识别率,相较于基准模型,本文方法都取得了更好的效果。本文方法不仅仅在整体精度上超过了基准方法,类平均精度上也高于基准方法(图7 对应的实验类平均精度为80.55%,图8 对应的实验类平均精度为76.80%)。也如预期的,各类数据的误识别率相对均匀,被本文处理为强关联类的{fear,anger}和{disgust,sadness,neutral}没有再出现10%以上的误分类情况。
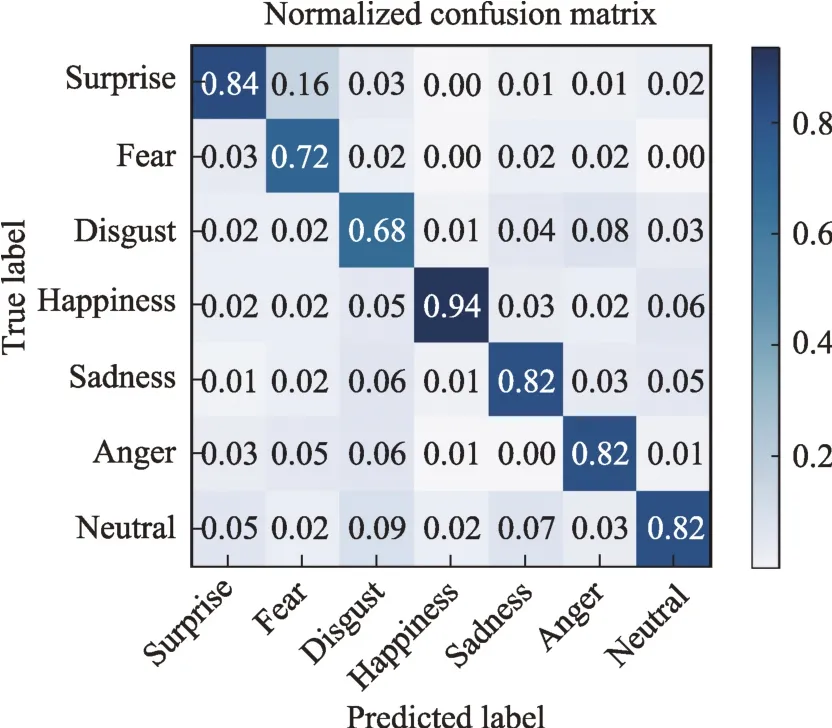
图7 RMRnet在RAF-DB 上的预测值Fig.7 Predicted value of RMRnet on RAF-DB
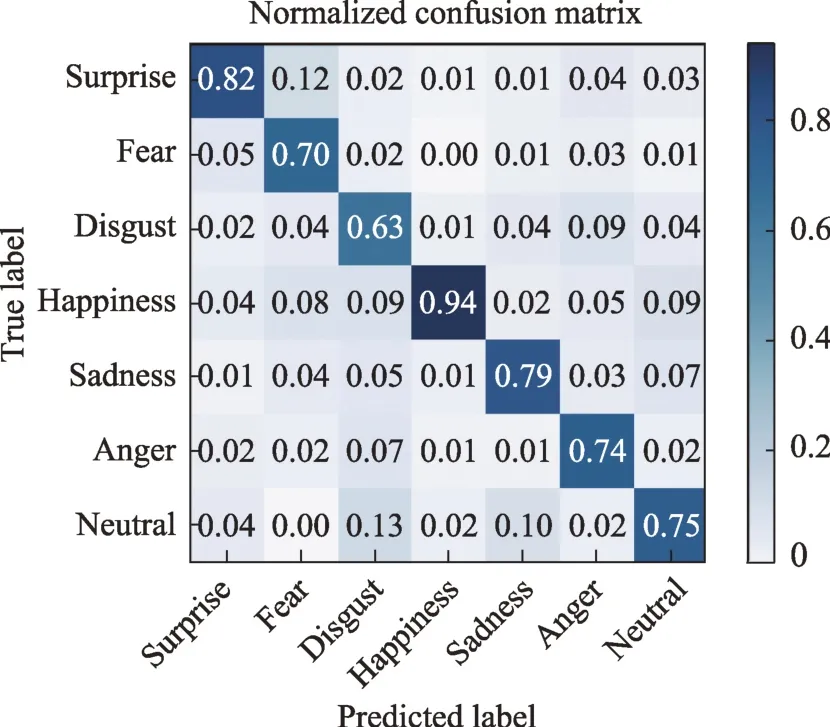
图8 Resnet18 在RAF-DB 上的预测值Fig.8 Predicted value of Resnet18 on RAF-DB
本实验结果与多个近年表现优异的网络模型在多个大型数据库上进行了对比。相比较基准方法Resnet18,在平均精度上,本模型在RAF-DB 上提高了3.26 个百分点,在AffectNet 上领先了3.91 个百分点,在Ferplus 上领先了4.16 个百分点。如表1 所示:在AffectNet 上,本文与DLP-CNN、EAU-Net、pACNN、IPA2LT 等方法进行了对比,本文的整体效果仅次于EAU-Net,对AffectNet 数据库做随机欠采样之后,网络的预测精度最高达到了59.29%,平均精度达到了58.43%。如表1 所示:在RAF-DB 上,本文与DLPCNN、EAU-Net、pACNN、DeepExp3D 等方法进行了对比,在一众先进方法中本文效果达到了最优,甚至最高精度达到了86.66%。如表1 所示:在Ferplus 上,本文与SHCNN、TFE-JL、VGG13-PLD、ESR-9 等方法进行了对比,取得了最优效果,在Ferplus 上的最高精度可达87.45%。
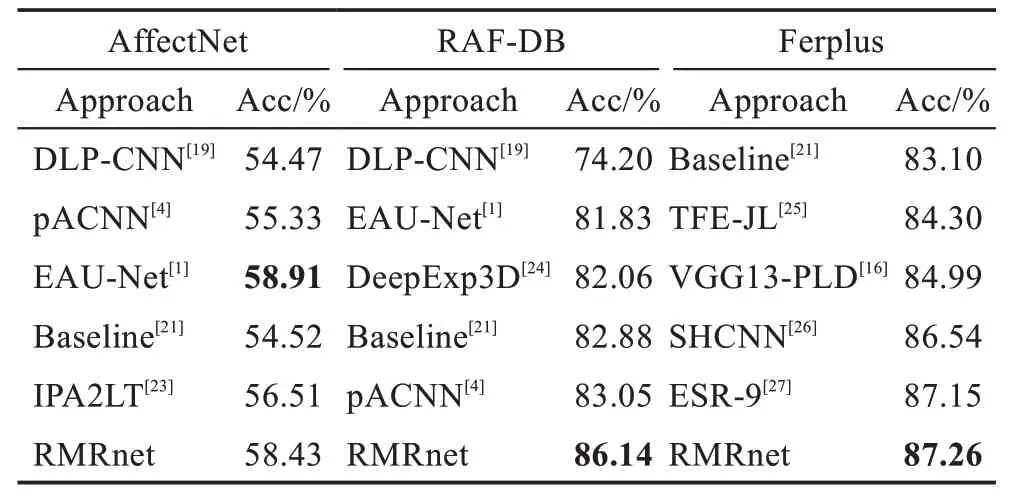
表1 在AffectNet、RAF-DB、Ferplus上的对比实验Table 1 Comparative experiment on AffectNet,RAF-DB,Ferplus
显然,各种网络模型在各个数据库上的表现有较大差异。AffectNet 上极低的精确度是由于表情标签的主观性,而RAF-DB 和Ferplus 两个数据库都由多人标记,标签的置信度高。Ferplus 是谷歌公司团队对Fer2013 数据集再标记得到。目前,在Fer2013上的模型精度一般也较低,远远达不到80%的精度。或许,从再标记上解决数据问题也是表情识别进一步提升精度的重要手段。
4 结束语
本文提出了一种研究表情识别的新角度,从各类表情的类间关系出发,通过观察分类之后的RM 矩阵结合本文的筛选算法来构建分类支路。通过分析类间关系,可以获取各类表情之间的关联程度,相当于获取了表情识别问题理论情况下的客观规律。将这样的规律设计到网络模型之中,模型就获取到了特定的先验知识,而这样的先验知识在一般的深层神经网络中能否被学习到有着不确定性。本文方法在神经网络的深层上固定了参数,实验表明,这样的方法效果显著。
本文方法存在着一定的缺陷,本意是通过客观的类间关系引入类间信息,然而由于数据处理和人工分类上的模糊性,本该清晰的类间关系并非总是不变的。可以通过多次分析来得到不同的网络结构,针对数据差异应用本文的分析方法可以达成这样的目的,但是这样的设计不够智能,下一步研究方向是让网络自己学习到这样的类间关系。
