知识图谱推理问答研究综述
2022-08-16萨日娜李艳玲
萨日娜,李艳玲,2+,林 民
1.内蒙古师范大学 计算机科学技术学院,呼和浩特010022
2.内蒙古纪检监察大数据实验室,呼和浩特010015
随着大数据时代的到来,人们从海量数据中准确、快速地获取信息已成为迫切需求,而智能问答可以解决此类问题。智能问答可以通过非结构化数据或结构化数据获取信息进行回答,这两种数据各具优点,非结构化数据中知识覆盖范围较广,而结构化数据更具组合性,可用于处理复杂的推理问题,如今也有许多方法将非结构化数据与结构化数据相结合完成问答任务。
知识图谱(knowledge graph,KG)属于结构化数据,通常以三元组的形式将事实存储。因其具有直观、丰富的知识,所以被广泛应用于自然语言处理(natural language processing,NLP)任务中,例如知识问答、对话系统、推荐系统、信息检索等。其中知识图谱问答(knowledge graph question answering,KGQA)应用最为广泛,旨在利用现有知识图谱回答自然语言问题。然而现有的大型知识图谱大多不完整,使得一部分问题找不到答案,而知识图谱推理技术可以挖掘或推断知识图谱中缺失的实体以及实体之间的隐含关系。因此将知识图谱推理技术应用于KGQA,可以有效解决知识图谱不完整问题,进一步提升答案预测的准确性。
本文首先介绍了知识图谱推理问答概念以及相关数据集,其次介绍了知识图谱推理技术在问答任务中的应用研究,最后对研究现状进行总结与展望。
1 知识图谱推理问答概述及挑战
1.1 知识图谱推理与知识图谱问答
知识图谱推理是知识图谱构建以及下游任务中非常重要的模块,在实际工程中同样有着广泛的应用。KG 通常由各种来源获得的事实组成,其中每个事实通常以三元组(,,)形式表示,表明实体与实体之间存在关系。由于KG 大多存在信息缺失问题,会对下游任务产生影响,知识图谱推理的一个基本任务是利用KG 中现有事实,推理出缺失的事实或隐含的关系。
知识图谱问答则是利用存储在KG 中的三元组回答自然语言问题。KGQA 任务的一般定义为:给定KG 作为知识源,对于自然语言问题,目标是通过KG 获取其答案实体,答案可以为单一实体或实体集合。其中,问题按照难易程度分类,可分为简单问题与复杂问题。简单问题指包含单一实体和单一关系的问题。复杂问题指多跳问题与约束问题,其中多跳问题是考虑关系路径得到答案的问题;约束问题指包含多个语义约束的问题,复杂问题实例如图1 所示。在KGQA 中,答案通常是KG 中的节点,而回答问题可能需要单一事实或需要对多个事实进行多跳、比较、聚合等推理。
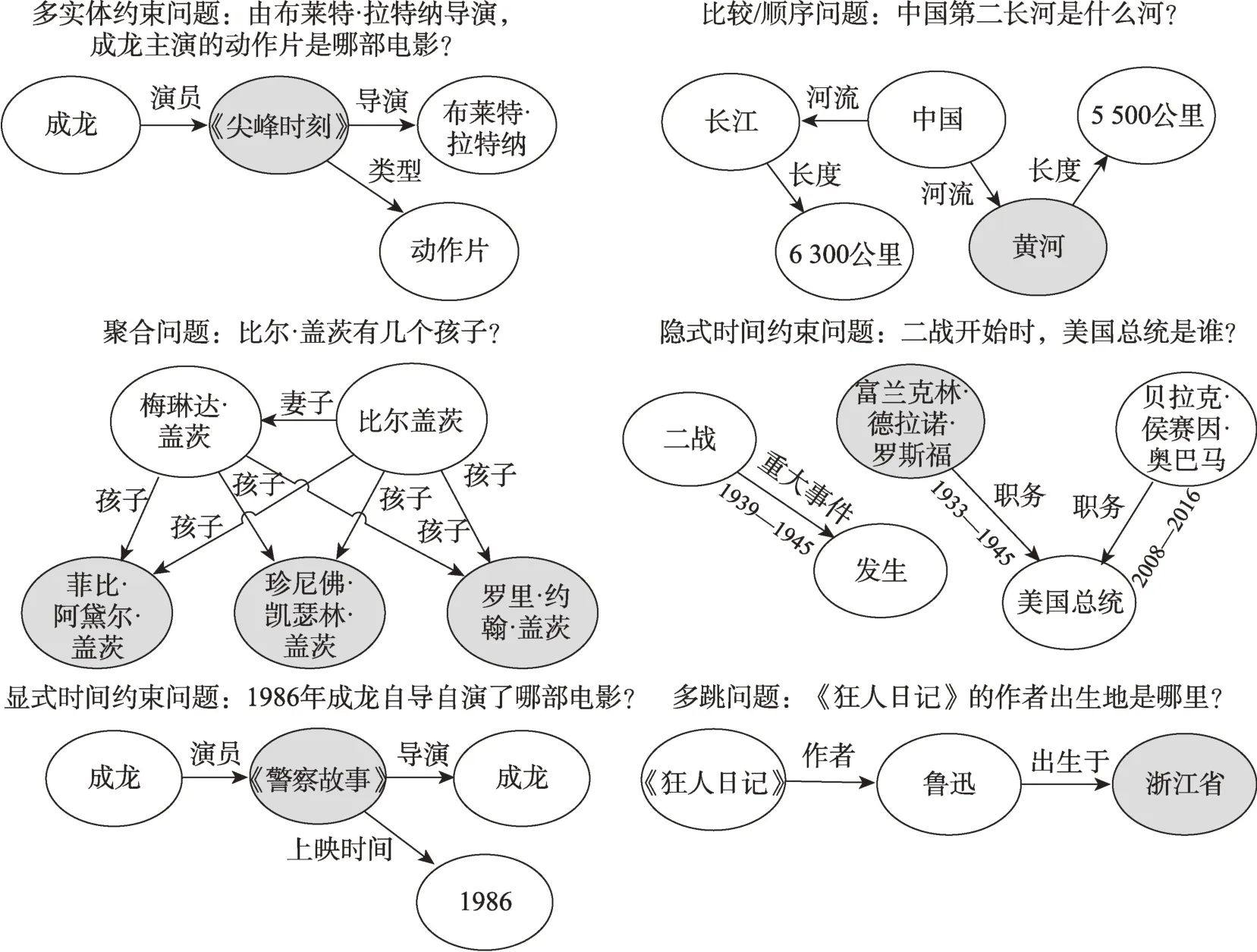
图1 复杂问题实例Fig.1 Examples of complex questions
而知识图谱推理与KGQA 的关键区别在于:知识图谱推理技术是通过处理KG 中的实体和关系,从而找到目标节点;KGQA 则需处理自然语言问题,其问题通常会涉及复杂的语义信息,因此对知识源的推理过程必须以问题为条件,不同的问题会导致KG不同的表示和不同的推理过程。
1.2 知识图谱推理问答
近年来,随着人们提出问题的复杂性逐渐提高,KGQA 从简单问题逐渐转向对复杂问题的研究。当前,KGQA 大多将问题理解作为主要研究,并且假设KG 为完整图谱,以执行问答任务,然而在真实世界中,大型知识图谱通常存在知识不完整的情况,并含有大量噪声,将知识图谱推理技术应用于KGQA 中,可以有效缓解此类问题,但通常面临以下挑战:
(1)推理缺乏可解释性。KGQA 系统通常输入自然语言问题,输出问句答案,但其结果缺乏可解释性,其推理过程缺乏透明度,如何得到具有可解释性的推理结果是KGQA 所面临的难题。
(2)自然语言的灵活性和模糊性。在KGQA 中,一个重要的步骤是将自然语言问题的实体与关系短语映射到知识图谱的顶点和边,然而实体名称的模糊性会造成大量的候选答案。即使假设实体名称能够准确识别,名称的歧义性仍然使找到正确实体变得困难。因此对KGQA 算法的鲁棒性提出了要求。
(3)问题的复杂语义信息。与简单问题相比,复杂问题具有更丰富的语义信息,使得问题的每个部分对三元组的选择都会有所影响。因此,如何处理复杂的语义信息同样是研究难点。
(4)时间复杂度高。KGQA 通常需要考虑每个问题以主题实体为中心的子图,但随着跳数的增加,会使得候选答案的数量呈指数增长,如何过滤无关事实,减少搜索空间是该研究的重点。
目前已经有研究人员撰写了有关知识图谱问答的综述,如王智悦等人从手工构建方法到深度学习方法对知识图谱问答进行介绍;Yani 等人侧重对简单问题的KGQA 方法进行综述,对其中存在的挑战、各类技术和研究趋势进行全面介绍;Lan 等人对复杂KGQA 方法进行综述,重点归纳了基于语义解析与信息检索的KGQA 方法;Steinmetz 等人为研究自然语言到SPARQL 查询的转换问题,详细分析KGQA 数据集并说明了构建KGQA 系统所要面临的挑战;Chakraborty 等人发表了基于神经网络的KGQA 综述,重点归纳了基于分类的方法、基于排序的方法以及基于翻译的方法。陈子睿等人对开放域的知识图谱问答进行综述,介绍了基于模板规则的方法与基于深度学习的方法。目前,还没有文献对基于知识图谱推理的问答方法进行综述,并且上述文献大多是对开放域问答进行综述,而本文是对知识图谱推理技术应用于开放领域问答、常识问答、时序知识问答中的方法进行介绍,详细分析了各类方法的优劣以及存在的挑战。
2 知识图谱问答数据集
KGQA 中开放域问答大多使用Freebase、YAGO、DBpedia、Wikidata等大型知识图谱作为知识源检索答案进行回答。常识问答通常使用ConceptNet作为知识源进行回答。研究者针对不同的问答任务构建了形式多样的问答数据集,有效推动了KGQA 的发展。本文将数据集分为开放域问答数据集、常识问答数据集以及时序知识问答数据集。表1 展示了KGQA 数据集间的对比。
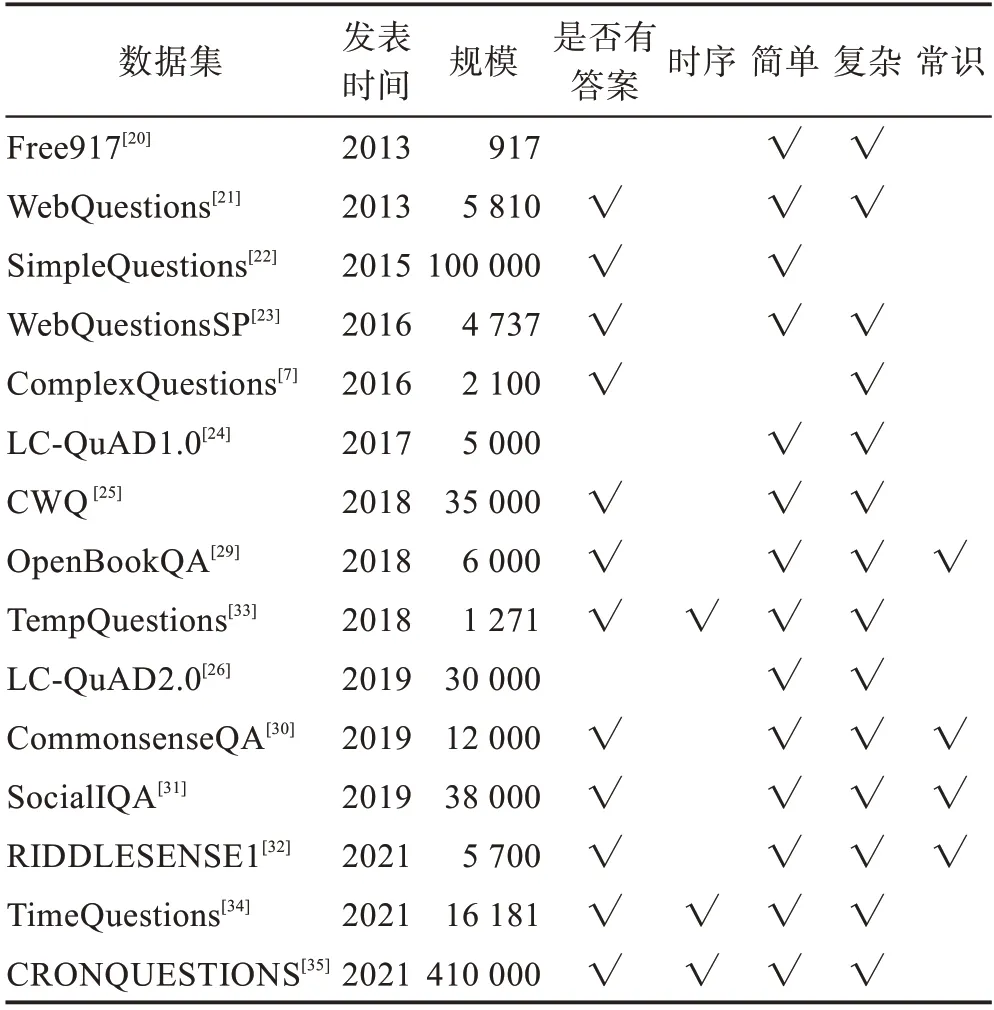
表1 知识图谱问答数据集Table 1 Knowledge graph based on question answering databases
2.1 开放域问答数据集
早期问答系统是通过将问题解析为逻辑表达式在知识库中查询答案,Cai 和Yates针对语义解析任务,构建了开放域数据集Free917,其中包含917 个问题、635 个Freebase 关系,使用lambda 演算形式注释,由问题及逻辑表达式构成。然而对Free917 的注释需具备专业知识,使得数据难以扩展。因此,Berant等人构建了WebQuestions 数据集,通过Google Suggest API 随机获取仅含一个实体的问题,并由人工进行回答。但WebQuestions 数据集仅包含5 810个问答对,所能涵盖的问题种类较少。Bordes 等人扩大问题覆盖范围,从Freebase 抽取事实,并由人工创建与事实相对应的问句,构建了SimpleQuestions数据集,用于大规模简单问答任务,数据集由问句和Freebase 事实组成。Yih等人针对WebQuestions 数据集只有答案而没有查询语句的问题,对WebQuestions 中的每个问句增加了相应的SPARQL 查询,并删除了其中表达不清晰的问句,构建了WebQSP 语义解析数据集,还提供了标准Freebase 实体标识符,这些标识符在Freebase 上可直接执行。但以上数据多为简单问题。
为了评估KGQA 系统处理复杂问题的能力,Bao等人与Trivedi 等人分别构建了ComplexQuestions数据集与LC-QuAD 数据集,其中ComplexQuestions数据集包含多实体约束、类型约束、显式时间约束、隐式时间约束、顺序约束以及聚合约束六类约束问题,这类问题需要对多个三元组推理得到答案,该数据集仅由问答对组成。另一个复杂语义数据集LCQuAD则包含问题及其相应的SPARQL 查询。但上述数据集中问题数量较少。Talmor 等人针对复杂问题数据集中问题数量较少的情况,扩大了问题数量,构建了CWQ 数据集。他们通过对WebQSP 中的SPARQL 查询采样,将其自动构建为具有比较级、最高级等更复杂的查询语句,并将查询语句重组为复杂的自然语言问题。CWQ 数据集由问题、答案及SPARQL 查询组成。Dubey 等人构建了LC-QuAD 2.0 复杂问答数据集,其与CWQ 数据集中问题数量的范围相同,但相比CWQ 数据集,SPARQLs 的变化更大,含有如多意图问题、时间约束问题等更多种类的复杂问题类型。
2.2 常识问答数据集
现有许多研究人员关注于常识问答推理,例如在回答“当艾伦听到羊的叫声时,他在哪里?”,可以推断出可能是在草原或者在街道上。这个问题对人类来说很简单,但对机器来说会难以理解。最早Cyc以谓词逻辑的形式建立了常识知识本体,相比于Cyc,ConceptNet常识知识图谱更加接近自然语言描述,重点关注自然语言中单词的常识意义。ATOMIC是以事件为中心的大型知识图谱,由超过30 万个事件组成,其中的每个三元组包含一个事件短语,并提出了九种if-then 关系类型。在大型常识知识图谱的基础上,有研究者构建常识问答数据集,大大促进了该领域的发展。
Mihaylov 等人构建了OpenbookQA 数据集,以增强机器对问题的理解。该数据集由多项选择题和基础科学事实组成,需结合外部语料库得到答案,因数据集以科学事实为主,需具备专业的科学知识回答问题。Talmor 等人针对人类常识知识问题,构建了CommonsenseQA 数据集,该数据集是由问题和五个选项组成的多项选择问题。Sap 等人针对人类在社交环境中的常识问题,构建了SocialIQA 数据集。该数据集由上下文、问题与候选项构成,其中使用ATOMIC 中的基本事件生成自然语言上下文。最近Lin 等人构建了谜语数据集RIDDLESENSE1,例如对于问题:“我有五根手指但不是活物,猜我是什么?”答:“手套”。回答这样一个谜语式的问题非常具有挑战性,因为它需要复杂的常识推理能力、对比喻语言理解的能力以及反事实推理的能力。RIDDLESENSE1 是第一个用于回答谜语式常识性问题的大型数据集,需从给定谜题的五个选项中选择一个作为预测答案。
2.3 时序知识问答数据集
时序问题是带有时间约束的问题,Jia 等人给出时序问题的定义是:任何包含时间表达式、时间信号或其答案具有时间性质的问题均称为时序问题。时间表达式具有四种类型,分别为日期表达式、时间表达式、集合表达式、Duration 表达式。其中日期与时间表达式都指时间点,其根据时间点的细粒度而有所不同,如“2019 年6 月1 日”与“9 点”;集合表达式指具有周期性的时间,如“每周三”;Duration 表达式指时间间隔,如“一年”;时间信号指实体之间的时间关系,如“before”或“during”等。近几年时序数据集的提出,有效推动了时序知识推理的研究。
Jia 等人针对时序知识问答,构建了TempQuestions数据集。该数据集是从WebQuestions、Free917和ComplexQuestions数据集中抽取与时间相关的问题子集组成,这些问题分别标记为带有显式、隐式、顺序约束问题以及答案为时间的问题。然而,Temp-Questions 数据集只包含1 271 个问题,且仅用于评估。Jia 等人扩大了问题数量,通过搜索8 个KGQA数据集中与时间相关的问题,构建了TimeQuestions。上述数据集都基于非时序KG(如Freebase)。Saxena等人构建了目前已知最大的时序知识问答数据集CRONQUESTIONS,该数据集由两部分组成,分别为需要时间推理的自然语言问题以及具有时间注释的知识图谱,其中时序知识图谱由约12 万个实体和32万个事实组成。
3 知识图谱推理问答方法分析
大型知识图谱通常存在缺少事实的情况,使得一部分问题找不到正确答案,而将知识图谱推理应用于KGQA 中可以解决信息缺失问题。在KGQA 中知识图谱推理技术主要运用于候选答案的选取、问题相关子图的推理及关系路径的推理中。
本章针对知识图谱推理技术在不同问答任务中的应用分别进行介绍。
3.1 开放域问答推理方法
开放领域问答是使用Freebase等大型知识图谱作为KGQA 知识源,用于解决开放领域问题的问答。本章将开放域问答推理方法分为三类,分别为基于图嵌入的方法、基于深度学习的方法以及基于逻辑的方法。
基于嵌入表示知识图谱推理方法中典型的模型是Bordes 等人提出的TransE 模型,其通过对低维空间中的向量进行平移操作预测缺失的实体或关系。因TransE 泛化能力强,所以在KGQA 中广泛使用,但是该模型存在以下几个问题:首先对复杂关系的处理效果较差,其次没有充分考虑语义信息。后续许多学者提出TransE的衍生变体,解决上述问题,有部分学者将此类KG 推理模型应用于下游任务中,解决实际问题。
通过将TransE、ComplEx等KG 推理模型应用于KGQA 中,可以学习到KG 的低维向量表示,使得KG 中相似的实体与关系在向量空间中接近,并在此向量空间中进行运算得到问题答案。基于图嵌入方法的流程如图2 所示。
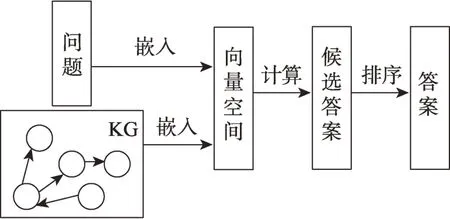
图2 基于图嵌入的方法流程图Fig.2 Flow chart of graph embedding methods
Wang 等人针对用户在使用SPARQL 查询时因不当的查询,导致返回空答案的问题,提出基于RDF(resource description framework)图嵌入的模型。首先,他们利用在TransE 基础上加入实体上下文信息的嵌入方法,将RDF 图嵌入至向量空间;然后,对于返回空答案的SPARQL 查询,将其中的变量与查询项在向量空间中表示;最后,计算并返回相似答案。实验表明,在TransE 基础上加入实体上下文信息能够增强实体间语义联系,相较于直接使用TransE 的方法有着更好的表现。但模型只能利用SPARQL 查询语句进行问答,不能对自然语言问句进行回答。针对上述问题,Wang 等人提出将自然语言问句转化为图结构查询的框架KemQA。首先,该框架在TransE 基础上加入实体上下文信息,并将KG 与关系短语词典编码至相同向量空间;其次,对于给定的问句,利用学习到的嵌入向量解决歧义性问题,以得到精确的候选节点和边;最后,将候选节点和边构造为图结构查询以预测最终结果。KemQA 的短语映射和消歧在嵌入空间中进行,因此能够避免大规模搜索,使得其计算效率更高。但逻辑查询通常只能查询数据库中存在的事实,不能推断缺少的信息。针对该问题,Sun 等人提出查询嵌入方法(embedding query language,EmQL),将知识图谱中事实与查询一起嵌入至向量空间中,从而解决缺少信息的问题。
为直接利用知识图谱中的事实回答问题,有学者提出利用问句信息,从知识库中选取候选答案,将问句和候选答案映射到相同低维空间,计算问句与候选答案之间的相似度。此类方法主要通过对问句和候选答案进行训练,预测最终的结果,因此无法解决自然语言问句的模糊性问题。Huang 等人针对上述问题,提出了基于知识嵌入的问答框架(knowledge embedding based question answering,KEQA)。首先,该框架使用TransE 模型将KG 嵌入至两个低维向量空间中,得到谓词嵌入空间和实体嵌入空间;其次,对于给定的问句,在嵌入空间中分别得到该问句实体以及谓词的嵌入表示,并使用头实体检测模型在KG 中找到候选事实;最后,通过联合距离度量计算问句实体和谓词与所有候选事实的距离,返回距离最小的事实作为答案。实验表明,首先将KG 嵌入得到低维表示,然后执行KGQA 任务的方法,其预测准确性可以得到有效提升,但KEQA 无法回答多跳问题。Saxena 等人针对多跳推理问题以及KG 信息缺失问题,提出EmbedKGQA 模型。首先,该模型利用ComplEx方法将KG 嵌入至复数空间,以捕获全面的特征信息,从而得到实体、关系及候选答案的向量表示;其次,使用RoBERTa 模型对问句进行编码,并映射至与KG 相同的嵌入空间中;然后,将关系替换为问句向量,使用打分函数以及损失函数训练数据的嵌入表示,得到与之间关系为向量的表示;最后,对于给定问句及实体,利用知识图谱对所有可能的候选答案进行打分,将分数最高的实体作为最终答案。实验表明,该方法在不完整知识图谱上具有较好的表现。
基于图嵌入的方法具有较强的鲁棒性,能够有效解决KG 不完整的问题以及自然语言问句的模糊性问题。但这类方法中,大多推理能力以及可解释性较差,并且KGQA 的准确率易受到KG 嵌入模型的影响。
基于神经网络的知识图谱推理方法能够利用循环神经网络(recurrent neural networks,RNN)捕捉路径信息,以预测实体对之间的隐含关系;能够利用强化学习(reinforcement learning,RL)方法通过策略的代理顺序扩展其推理路径,得到目标答案;能够利用图神经网络(graph neural networks,GNN)捕捉邻域信息以及图谱结构信息,对缺失信息进行预测。
通过将基于神经网络的知识图谱推理方法应用于KGQA 中,可以深入学习知识图谱中语义信息以及结构信息,实现对答案的预测,并且能够解决图嵌入方法无法对关系路径建模的问题。
Zhang 等人针对自然语言问句中语义模糊问题,提出端到端的概率建模框架。首先,该框架识别出主题实体,将相邻跳数内的实体作为候选答案,并获得与每个候选答案之间所有路径构成的子图;其次,采用前向传播的方法,通过父节点递归地嵌入每个候选答案子图;最后,计算问题表示和子图嵌入表示之间的相似度以预测最终答案。但随着跳数增加,候选实体会呈指数级增长,其性能也会受到限制。Sun 等人针对KG 中信息不完整的问题,提出GRAFT-Net 方法,首先根据主题实体从知识库获取子图以及百科中搜索对应文档,将子图与文档中相同实体链接构成异构图,然后通过GNN 以迭代的方式对异构图中的节点表示和更新,并在更新过程加入问句信息以选择最终的答案实体。但GRAFT-Net抽取子图的方法是启发式的,这会引入许多无关实体。针对上述问题,Sun 等人提出PullNet 方法,该方法对GRAFT-Net 中子图构建方法进行了改进,通过从文本和KG 两个知识源中以迭代的方式构建子图,从而减少与问题无关的子图数量。实验表明,其结果优于GRAFT-Net 方法。Xiong 等人为进一步提升问答效率,提出了一种端到端的模型。首先,该模型根据主题实体从KG 中获得相应子图,并将子图嵌入表示与问题语义信息相结合,得到问题与子图的联合语义信息;其次,模型通过条件门控机制获取文本中的语义信息;最后,对两个语义信息进行相似度计算得到最终答案。
但基于子图推理的方法通常考虑整个主题实体为中心的子图,会引入噪声信息,并导致KGQA 系统复杂程度提高。其次,由于数据标注的成本较高,精确对每一步推理过程进行标注是不切实际的,只能对最终答案进行标注,导致可解释性差与弱监督的问题。因此有研究人员提出结合强化学习的方法,解决上述困难。
Das 等人提出MINERVA 方法,通过结合强化学习方法有效地搜索路径,以对具有单一关系的简单问题进行推理。该方法受奖励函数驱动,在知识图谱上寻找相关推理路径进行答案预测,但存在两种问题:(1)随着路径数量的增长,导致大多数的路径得不到奖励,造成稀疏奖励问题;(2)模型可能会通过无意义路径(或称为虚假路径)得到正确答案,从而对推理产生负面影响。Lin 等人针对上述两种问题,提出奖励形成的RL 模型。该模型通过引入预训练的嵌入模型对未观察到的事实形成奖励,并且对每条路径上的中间实体关系随机进行dropout,从而探索不同的路径集,以缓解虚假路径产生的负面影响。但该方法无法解决复杂问题,因此Qiu 等人提出逐步推理网络(stepwise reasoning network,SRN),并将复杂问题归结为顺序决策问题。首先,该网络使用双向GRU(gated recurrent unit)对自然语言问句编码,并通过单层感知器得到当前时间步的问题表示,同时使用另一个GRU 对决策历史进行编码;其次,通过注意力机制将每个候选动作与问题交互,生成关系感知的问题表示,解决虚假路径的问题;另外,提出基于势函数的奖励形成策略,解决稀疏奖励问题;最后,将决策历史和问题表示串联,并基于语义得分预测下一步动作,其示意图如图3 所示。He等人为进一步缓解虚假路径问题,提出多跳KGQA的师生方法。其中学生网络由神经状态机实现,以寻找到问题的正确答案,教师网络是利用双向推理增强对中间实体分布的学习。实验表明,教师网络能够学习到可靠的中间监督信号,并缓解虚假路径问题,增强学生网络的推理。

图3 基于强化学习的方法框架Fig.3 Methods framework of reinforcement learning
通过关系路径进行推理,对解决多跳问题具有较好表现,并且具有较好的可解释性。但关系路径的扩展会使节点数以指数级别增长,如何减小计算空间,并且增强其预测能力仍然是当前研究面临的巨大挑战。其次单一路径可能会存在表达单一的问题。
基于逻辑规则的知识图谱推理方法是利用专家定义的规则或者KG 中学习到逻辑规则进行显式推理,以得到新的事实,其具有较强的可解释性。而基于语义解析的KGQA 方法与基于逻辑规则的知识图谱推理相似,此类方法首先将自然语言问题转换为可执行查询或中间逻辑形式,然后对KG 执行查询,获得答案实体。然而大多传统基于语义解析的KGQA 方法需要特定领域的语法、规则或细粒度注释,其语法结构和KG 结构之间的不匹配限制了性能。为了在问句解析时更加紧密地利用知识库,有研究人员提出查询图方法。
Yih 等人给出查询图定义,并提出分阶段生成查询图的方法(staged query graph generation,STAGG),可以总结为以下步骤:(1)利用实体链接工具识别问句主题实体,然后探索主题实体和lambda 变量之间的核心关系路径。(2)在核心关系路径上添加约束,约束由一个带关系的固定实体或者聚合函数组成,能够解决具有比较的约束问题。(3)计算上述各步骤生成的候选查询图与问题的相似度,从而对查询图进行排序。(4)执行最优查询获取答案。但STAGG仅适用于单一关系问题,后续许多学者在此基础上进行改进。为解决多约束的问题,Bao 等人提出MulCG 方法,通过在STAGG 的基础上增加类型约束与时间约束等约束类型,解决具有比较、聚合、时间约束等类型的问题。Luo 等人同样遵循STAGG 的查询图生成方法,但重点对问题和查询图的编码方法进行改进,通过集成各语义组件的向量,显式编码查询图的语义信息,并利用依赖解析丰富问题向量,进一步提高预测性能。类似的Sorokin 等人与Maheshwari 等人同样对编码方法进行了改进,Sorokin 等人使用门控图神经网络(gated graph neural networks,GGNN)对查询图的语义结构进行显式建模,学习其向量表示。Maheshwari 等人则提出槽位匹配模型,将核心链划分为多个跃点,并根据每个跃点创建问题的多个表示形式,进行细粒度的比较。
有学者认为上述查询图生成方法存在引入噪声信息以及表达能力有限等问题,因此,对查询图生成步骤进行改进。如Hu 等人提出利用扩展、折叠、连接、合并四个基本操作生成语义查询图,提升查询图的语义表达能力。Ding 等人提出基于频繁查询子结构的查询生成方法,该方法利用神经网络预测问题中包含的查询子结构,然后使用组合函数对现有查询结构排序或构建新的查询结构,能够有效解决具有复杂长尾问题的查询。Lan 等人提出一种改进的分阶段查询图生成方法,该方法通过束搜索机制和语义匹配模型指导剪枝,有效减少搜索空间。Chen 等人提出抽象查询图生成方法,首先预测出查询图的正确结构,然后生成候选集,该方法可以规避噪声查询图。
查询图方法将问题解析成与KG 结构紧密匹配的图结构逻辑形式,对于解决具有约束的复杂问题有较好的表现,同时具有较高的可解释性。但这类方法的缺点之一是没有端到端的训练,依赖于复杂的自然语言处理流水线(命名实体识别、实体链接、关系检测等),可能会导致错误级联。其次,知识图谱通常不完整,并具有大量噪声,因此通过查询可能无法返回正确答案。近几年,有学者将逻辑推理方法中可解释强、准确率高的优点与嵌入方法中泛化能力强的优点相结合,通过在嵌入空间中执行逻辑运算,有效解决KG 不完整问题以及具有约束的复杂逻辑问题。这类方法的重点在于处理复杂逻辑查询。
Hamilton 等人为解决不完整知识图谱上的复杂逻辑推理,提出图查询嵌入框架(graph query embedding,GQE)。首先,GQE 将查询语句表示为查询图,如图4 中(1)所示,并将其嵌入到低维空间中,如图4 中(2)所示;其次,从查询的锚节点开始,迭代地应用映射算子与合取算子,生成对应于查询的嵌入;最后,利用预测可能的答案。其中映射算子是将头实体表示通过关系类型连接得到新的嵌入表示,而合取算子是用于计算两个集合嵌入的交集,流程如图4(a)所示。但该方法只能解决合取(∧)问题不能解决析取(∨)问题。Ren 等人认为GQE方法将实体集合表示为单点是不合适的,因此提出Query2box 方法,将查询编码为box 的形式,通过执行逻辑运算得到包含答案实体的box,并能有效解决合取与析取问题,具体流程如图4(b)所示。但该方法只支持具有存在量化(∃)、合取和析取的一阶逻辑查询(first order logic,FOL),不支持否定(¬)。然而,否定是一种基本操作,也是完整一阶逻辑操作集中必需的部分。针对否定(¬)问题的解决,Ren 等人提出概率嵌入框架BetaE。该框架可以回答知识图谱上任意一阶逻辑查询,如合取、析取和否定。BetaE的核心是使用有界支持的Beta 概率分布,通过转换Beta 分布的参数,使高概率密度区域成为低概率密度区域,从而有效对否定进行运算。并且BetaE 使用德摩根定律,将析取(∨)近似为合取(∧)与否定(¬),从而支持任意一阶逻辑查询。但上述方法无法对查询中未相连部分之间的复杂依赖关系建模,对此Kotnis等人提出双向查询嵌入方法(bidirectional query embedding,BIQE),通过连接查询嵌入到双向注意机制模型,捕获查询图中所有元素的交互,能够有效处理复杂图查询。

图4 逻辑推理方法框架Fig.4 Logical reasoning methods framework
当前嵌入表示与逻辑查询相结合的方法越来越多,但更多是针对复杂逻辑查询问题的解决。其次,基于逻辑的推理方法能有效解决带有否定的问题,但目前对该方面的研究较少,因此如何结合逻辑规则解决KGQA 中带有否定词的问题是值得研究的内容。
表2 对上述研究进行了总结。基于图嵌入的方法首先通过学习问题以及知识图谱中实体和关系信息,然后在低维向量空间中运算以获取答案,但该方法对多跳问题的解决并不理想,并且可解释性较差。而基于深度学习的方法,可以解决图嵌入方法中可解释性差的问题以及多跳推理问题,但是存在搜索空间大、计算量大等缺点。以上方法均不能解决带有否定的问题,以及对带有约束的复杂问题预测效果不佳。而基于逻辑的KGQA 方法能够解决此类问题,通过人工定义规则或自动生成规则模版,可以有效解决带有复杂约束的问题,但是大多基于逻辑的方法将KG 视为完整知识图谱进行推理运算,这使得其KGQA 系统的鲁棒性有所欠缺。近几年,有学者将逻辑运算与嵌入方法相结合,从而在嵌入空间中执行逻辑运算以处理具有多个主题实体和逻辑操作的复杂问题,并有效解决KG 不完整以及KGQA可解释性差的问题,这为问答方法提供了新的思路。
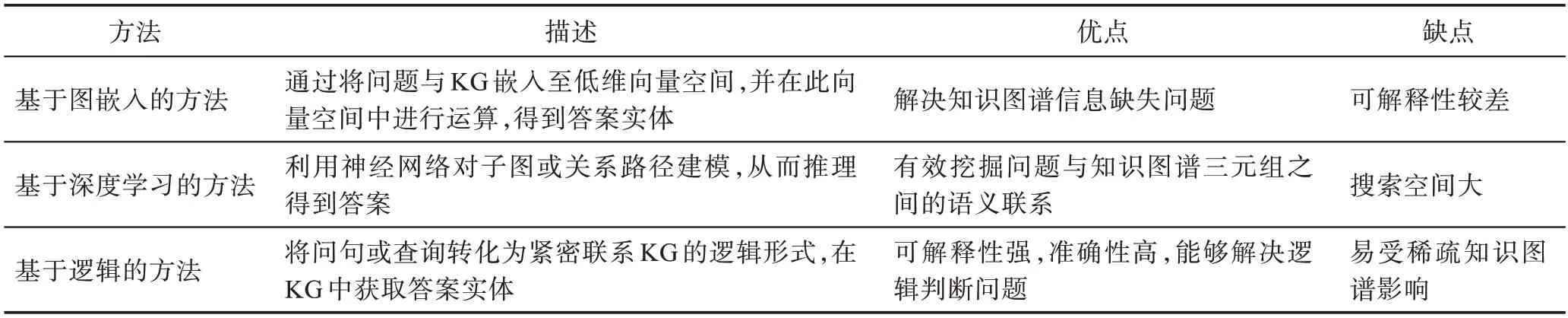
表2 KGQA 推理方法总结Table 2 Summary of KGQA reasoning methods
3.2 常识问答
常识是人们在生活中所得到的经验知识,对于一些常识问题,人类可以根据自身经验和所学知识进行回答。然而对于机器来说,则需具备先验知识及较强的推理能力作为支持。随着常识问答数据集的出现,例如CommonsenseQA、SocialIQA等,推动了常识问答的研究。常识问答与开放域KGQA 的区别在于,常识问答需要背景知识,而这些背景知识不在给定上下文中,因此许多研究从外部知识源中获取知识;其次常识问答数据集通常由选择题构成,因此更加关注问题与候选项间的隐含关系。



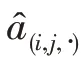
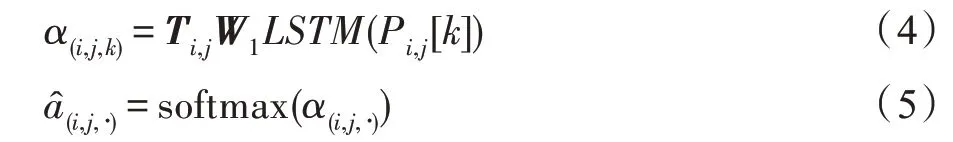

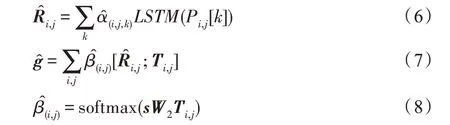
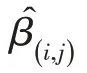
最后,计算问题与候选项的得分,如式(9)所示,从而对多跳关系进行显式建模。

实验表明,KagNet与仅使用预训练语言模型的方法相比,有较高的提升,证明加入KG 路径信息的有效性。然而,路径节点会随跳数增加而呈指数级增长,因此KagNet 方法难以扩展。Feng 等人为赋予GNN 直接建模路径的能力,对图编码器进行了改进,提出多跳图关系网络(multi-hop graph relation network,MHGRN),通过结合GNN 和路径信息,并加入结构化的关系注意机制,用于多跳推理路径的高效、可解释的建模。但MHGRN 方法复杂度较高,并且将QA 与KG 独立表示对结构化推理有影响。因此,Yasunaga 等人针对上述问题,提出了端到端的QA-GNN 模型。首先,该模型将子图节点与问答对拼接,使用语言模型RoBERTa计算节点与问答对的相关性得分;其次,将问答对视为一个额外的节点加入到子图中,并利用相关性得分增强节点表示,以提高推理能力与可解释性。实验表明,该方法与上述方法相比,能够充分利用KG 结构信息,有助于结构化的推理。
Wang 等人认为上述方法在抽取子图的过程会引入噪声,因此提出了一种路径生成器(path generator,PG)。他们通过在采样路径上微调GPT-2 预训练语言模型,引导PG 生成与问答对相关的推理路径,从而去除噪声干扰。实验表明,GPT-2 中存储的非结构化知识有助于补充KG 中缺失的知识,其生成的路径接近静态KG 已有的知识。但是PG 方法忽略了图结构信息。针对该问题,Yan 等人提出混合图网络(hybrid graph network,HGN),对于给定的子图,通过边加权及传递信息,有效过滤掉子图中的无关事实,并生成新的有用事实以提升推理能力。实验表明,该方法与PG 方法相比有显著提升。
综上,上述方法也可称为KG 增强方法,KG 增强模型通常具有三个组件,分别是文本编码器、图形编码器和评分函数,其示意图如图5 所示。在KG 增强模型中,文本编码器倾向使用预训练语言模型得到问答对的向量表示,评分函数通常使用多层感知机(multi-layer perceptron,MLP),大多研究方法在图编码器和子图构造方面进行改进。
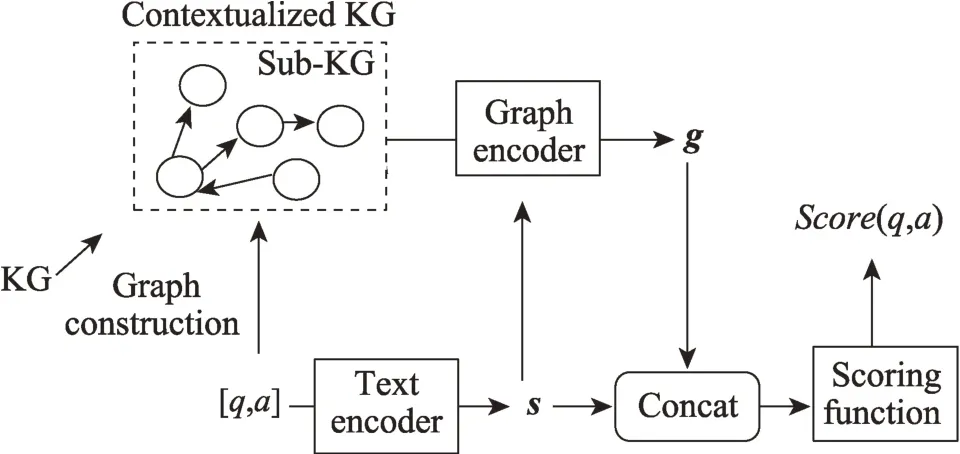
图5 KG 增强模型示意图Fig.5 Schematic of KG-augmented model
表3 对上述常识问答方法进行了总结,可以看到充分利用关系路径信息有助于模型性能的提升,并且对图编码器进行改进,增强问答对与KG 实体之间的交互信息同样能够提升模型性能。但是子图抽取会引入噪声,增加模型的计算量。HGN 方法是通过补全子图信息,过滤无关事实预测答案实体,其准确率在此类方法中达到最优,因此增强图谱信息对于KGQA 提升性能有很大的帮助。从表3 各结果中可以发现,知识图谱推理技术与常识问答结合的方法还有很大的研究空间。
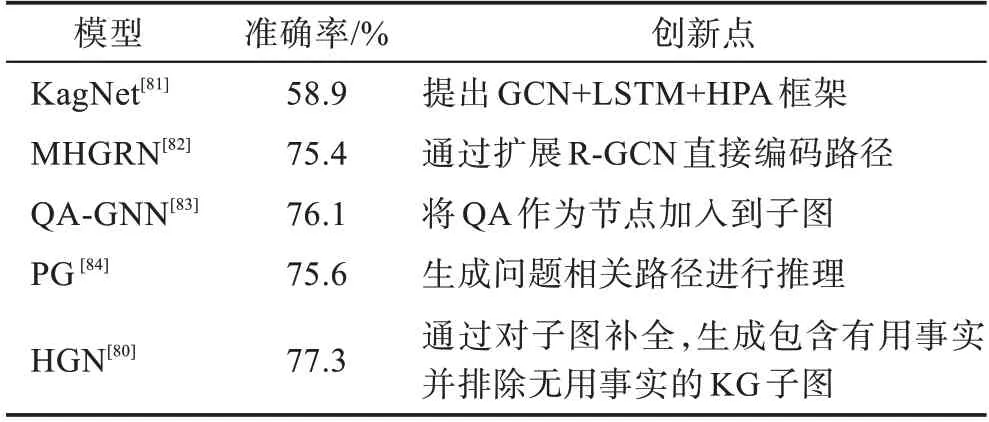
表3 模型在CommonsenseQA 测试集上准确率及创新点Table 3 Accuracy and innovation points of models on CommonsenseQA test set
3.3 时序知识问答
自然语言问题中有些词语具有时态信息(例如,before 和after),并在问题中发挥限制作用。然而,现有的大多KGQA 方法无法有效解决带有时间约束的问题。为了能够更准确地回答用户问题,有部分学者开始转向时序问题的研究。
Jia 等人为解决KGQA 中包含时间信息的复杂问题,提出时序知识问答方法TEQUILA。TEQUILA首先要识别问句是否带有时间信息,然后使用规则方法将复杂问题分解为简单子问题,在知识图谱中查询子问题的答案集,最后使用具有时间信息子问题的时间约束与答案集进行推理合并,得到最终答案。TEQUILA 可以与知识图谱问答系统结合使用,但其主要缺点是使用专家预先指定的模板进行分解,因此无法处理复杂的问题。Jia 等人为进一步解决复杂时序问题,提出端到端系统Exaqt,该系统首先使用Steiner 树和BERT 模型,获取与问题紧密相关的子图,并利用相关时序事实扩充子图,其次利用不同种类的时序信息扩展R-GCN(relational graph convolutional networks),并使用该R-GCN 进行答案预测,实验表明该方法可以有效解决具有时间意图的问题。然而上述方法在非时序KG 中使用,因此不能直接应用于时序知识图谱,时序知识图谱是一种多关系图,这与没有时间注释的常规知识图谱不同。一个常规知识图谱可能包含一个事实,例如(Barack Obama,held position,President of USA),而时序知识图谱包含开始和结束时间,例如(Barack Obama,held position,President of USA,2008,2016)。目前关于时序KG的研究重点在于对图谱的补全工作。Saxena等人则使用时序KG 解决时序问题,通过在Embed-KGQA方法上进行改进,提出了CRONKGQA 方法。首先,该方法使用时序知识图谱嵌入模型TComplEx分别对时序知识图谱中的时间与实体生成嵌入表示;其次,使用BERT 对问题中的实体及时间信息生成嵌入表示;然后,将获取的嵌入表示融合,得到实体与时间的得分向量;最后,将所有实体和时间的分数串联起来,使用softmax 计算组合分数向量的答案概率。CRONKGQA 在简单的时间推理问题上达到了很高的准确性,但在复杂推理问题上效果并不理想。
表4 对上述时序知识问答方法进行了总结,可以发现,现对于时序知识问答的研究较少。其中TEQUILA 与Exaqt 是以非时序KG 为知识源,解决KGQA 中的时序问题。上述方法的实验结果表明,增强时序信息对于提升答案预测性能有显著作用。CRONKGQA 是在时序KG 上进行推理,回答自然语言问题,这是一个相对未被研究的领域。目前时序KGQA 方法没有使用统一的数据集,因此无法对各类时序方法的性能进行比较,但从表4 可以发现,时序知识问答方法的预测性能有待进一步提升。

表4 时序知识问答方法总结Table 4 Summary of temporal KGQA methods
4 总结与展望
本文重点对知识图谱推理方法在问答中的应用研究进行介绍,并详细分析了各方法的优劣,可以发现,现存知识图谱推理问答方法仍然存在尚未解决的问题,本文将其归纳为以下几点:
(1)现有多数知识图谱推理方法主要针对大型知识图谱补全的工作,通常存在参数多、复杂度高的问题,因此难以应用于KGQA、推荐系统等下游任务中。
(2)目前中文KGQA 数据集较为匮乏,尤其是具有复杂问题的数据集,而构建相关数据集可以推动中文KGQA 的发展。因此,针对中文KGQA 任务构建数据集是未来需要关注的内容。
(3)KGQA 中针对复杂问题的推理是当前的研究热点,但多数方法利用关系路径以及问题相关子图,因此存在搜索空间大、算法复杂度高等问题,对问答的推理效率有所影响。未来如何提高复杂推理问答的高效性是待解决的问题。
(4)目前,有研究人员提出将嵌入与逻辑运算相结合的方法解决复杂逻辑问题以及知识图谱不完整问题,但此类方法主要用于解决复杂逻辑查询,如何将其扩展至自然语言问题中,也是未来需要解决的问题。
(5)现有KGQA 方法大多只适合在静态知识图谱中使用,伴随时间的推移,知识图谱中的知识需要结合时序信息,以解决含有时序信息的复杂问题,这将是知识图谱问答未来需要面临的问题。
