面向《方志物产》的自动断句深度学习模型构建研究
2022-08-15王东波陆昊翔彭运海徐晨飞
王东波 陆昊翔 彭运海 包 平 徐晨飞
(1. 南京农业大学信息管理学院,南京 210095; 2. 菏泽广电传媒集团,菏泽 274003;3. 南京农业大学数字人文研究中心,南京 210095; 4. 南通大学经济与管理学院,南通 226019)
1 引言
中国浩如烟海的古籍承载着璀璨的文化,如何对其进行全面整理和理解,是新时代传承和发扬中华传统文化的重要方向。但由于传统古籍距今已有千百年历史,时间跨度大、语体丰富和各历史阶段的语言风格差异等问题成为目前处理古籍资料的重大阻碍。其中“古文句读”给目前的文献处理和数字化工程带来了较大的困难,古人追求的因声求气以及涵咏情性文化方式,促使古文献中极少出现标点符号对文章进行断句分隔,直到现在,仍有不少的古代文化仍以连续的字符串形式沉睡在古书籍中,后世需要花费大量的人力物力对其进行句读理解。
传统的古文句读需要专业的古代文化研究者反复阅读文献,在理解全篇文章语义和揣摩情感大方向的前提下,对文献进行标点分隔,使其符合现代文的阅读和理解方式,该模式不仅对研究者的古文学术素养有很高的要求,同时需要耗费大量的时间,且长文本的断句准确性仍有不小的提高空间。随着计算机技术的不断发展,具备自然语言处理和语言学背景的学者,开始考虑将计算机技术和古文断句联系起来,提出了不少的机器学习方法解决古文断句问题,取得了不错效果,但训练数据构造难度大、识别时间长和识别准确度低等问题也需要重点考虑。
深度学习的出现为古文句读带来了新的解决模式,与传统机器学习方法相比,深度学习方法和模型不需要人为构造训练模板和匹配模式,极大提高了训练速度和准确度,但该方法没有解决关键的语料处理问题,即深度学习同样需要针对不同的古文数据构造出足够的训练数据集合,该过程同样费时费力。与此同时,许多学者和研究人员在使用深度学习方法解决古文断句问题时,主要采用直接调用开源深度学习模型的方法,该方法过度依赖开源深度学习模型,而目前的开源深度学习模型主要是基于现代汉语语料训练出来的,对古文的语义感知度不及现代汉语,导致了很多古文断句模型无法在新的语料上进行重复使用。为了优化古文自动断句结果,解决训练数据构造等问题,基于原始BERT模型,并在繁体中文版的《四库全书》全文数据集合上训练得到了SikuBERT系列模型[1],该模型以古汉语为训练语料,对古代文献数据的识别效果要优于原始BERT模型。为进一步研究SikuBERT模型的断句识别效果,并实现对《方志物产》进行断句研究,本文将训练得到最优的SikuBERT模型迁移到《方志物产》数据集上,探究古汉语断句模型与迁移学习结合的相关内容,进一步减少模型训练中的数据清洗、数据标注、数据增强和引入字典等繁琐工序。
2 相关研究
2.1 《方志物产》文本研究
《方志物产》是上世纪六十年代,在中国农业遗产研究室著名农史学家万国鼎先生领导下查抄、整理、汇编国内七千余种宋至民国方志而成的物产专题性资料,在学界具有重要影响力[2]。该书数据规模庞大,蕴含着重要的历史研究价值,如何对其中的物产知识信息进行有效整理,是后续基于《方志物产》文本资源进行深度组织、挖掘与利用的前提。目前,针对《方志物产》文本数据的研究主要集中在数据库建设和数字人文环境下的文本命名实体识别提取。前者主要以构建关联知识系统为目标,如朱锁玲将《方志物产》中的广东、福建和台湾三个省份的农业数据作为研究对象,基于命名实体识别技术,对文本中的地名进行自动识别,并挖掘了物产与地名间的关系[3]。这类研究主要基于已有的机器学习技术实现数据的整理和组织,并未涉及对机器学习方法和文本资源提取的进一步探究,但是为后续进行机器学习模型改进提供了方向和目标。而数字人文框架下的结合《方志物产》数据和诸多数据识别提取技术的研究是本文的重要灵感来源。由于《方志物产》文本具有书写方式、文本结构和历史跨度等特殊性,针对其数据识别和提取,研究经历了基于规则的方法、基于传统机器学习方法和基于深度学习方法三个阶段,朱锁玲、包平基于规则和统计的方式,对《方志物产》广东分卷中的地名数据进行提取,准确率达到了71.83%[4]。李娜在规则和统计的基础上,采用条件随机场模型分别对《方志物产》山西分卷中的物产别名进行了抽取,取得了不错的识别效果[5];徐晨飞等则在实验中基于深度学习技术中的Bi-RNN、Bi-LSTM、Bi-LSTM-CRF、BERT等四种模型,实现了对《方志物产》云南分卷语料中的物产别名、人物、产地及引书等实体的自动识别,该研究表明深度学习模型和方法相较于传统的机器学习模型,对古籍方志文本实体识别任务具有一定的优越性[6]。
2.2 古代文本断句研究
古代文献中极少出现标点符号用以区分句子和段落,这为后世对文献进行学习和整理研究造成了极大的困扰,如何为古文献段落断句成为了重要的研究方向之一。目前针对古文断句方法的研究主要以机器学习方法为主,而基于规则和统计方式的句读效果有限,且耗时费力。如黄建年等基于规则匹配的方式构造正则表达式,对农业古籍中的句子和标点进行识别,最终断句正确率为48%,标点符号的识别准确率为35%[7],这距离实际应用还有一定的距离。针对这一问题,后续研究者尝试使用机器学习方式解决该问题,常用的机器学习识别模型有条件随机场模型、隐马尔可夫模型(BioTrHMM)和最大熵模型,张开旭等基于条件随机场模型,运用序列标注思想解决古文断句问题,并在《论语》和《史记》数据集上进行了断句识别实验,识别结果F值接近80%[8];黄瀚萱比较了条件随机场模型和隐马尔可夫模型在古文断句问题上的识别效果,在《论语》《孟子》等古文献数据集合上的断句识别实验得出条件随机场模型的识别效果更优[9]。传统机器学习模型需要人为构建特征模板,实验人员的数据感知力和古代文学素养极大影响了模型的识别效果。因此,越来越多的研究人员开始将深度学习技术和古文句读任务结合起来,王博立等采用基于GRU的双向神经网络模型进行古文断句实验,最终实验F值达到了75%[10];俞敬松等在BERT预训练模型的基础上根据具体任务进行适配微调,在单一文本类别和复合文本类别测试集上的F1值分别达到89.97%和91.67%[11]。
2.3 迁移学习相关研究
迁移学习指的是将某个领域或任务上学习到的知识或模式应用到不同但相关的领域或问题中。在自然语言处理领域,迁移学习的主要应用即将基于某领域数据训练得到的模型或算法,通过简单适配调整直接应用到相关领域数据集合中,极大地减少了工作强度。杜伦(Thrun S)提出了终身学习(Life Learning)理念,指出在终身学习过程中,大量的学习和成果均来自少量训练数据,并基于该少量数据不断推广和迁移获取大量新知识,因此学习迁移已有知识具有重要的作用,为后续的迁移学习理论发展做出了一定的贡献[12]。陆杰(Lu J)和瓦希德·贝博德(Vahid B)等在传统机器学习方法的基础上,研究了基于计算智能的迁移学习技术,并将相关技术的发展分为四大类,为本文的迁移学习理论构建和方法选择提供了重要借鉴[13];高冰涛等基于权值学习模型,构建了基于迁移学习的隐马尔可夫模型,并在GENIA语料库的数据集上的实验表明,基于迁移学习的隐马尔可夫模型比传统的隐马尔可夫模型算法具有更好的性能[14];钱诚(Qian C )等人使用集成学习策略设计了称为异构集成在线迁移学习(HetEOTL)的算法,并在开放数据集上对该算法进行测试和评价,实验结果表明HetEOTL 比其他一些现有的在线学习和迁移学习算法具有更好的性能[15];徐志杰(Xu Z)和孙世亮(Sun S)将多视图学习理论融入到迁移学习中,并提出了一种基于自适应提升算法的多视图迁移学习模型(Multi-View Transfer Learning with Adaboost),并在多视图角度下证明了该算法具有不错的迁移学习效果[16];武惠等针对中文命名实体识别问题,提出了一种基于迁移学习和深度学习的长短期记忆神经网络模型(TrBiLSTM-CRF),实验结果表明,该模型在小规模数据集上进行中文机构名命名实体识别时具有较好的识别效果[17];安藤(Ando)等人提出了一种新的学习预测框架,并较为详细地解释了传统机器学习和迁移学习方法间的联系和区别,后者对本研究的深度学习模型选择和迁移学习数据构建部分有较大帮助[18];王红斌等在命名实体识别任务中,提出一种基于实例的迁移学习算法,该算法比传统的条件随机场模型具有更优的性能,且极大降低了数据标注量[19]。
从上述相关领域的研究可以发现,针对古文断句任务,基于统计规则的方法和基于传统机器学习的方式取得的实验效果有限,且实验复杂度高,模型推广性和复用性不足,而基于深度学习模型的方式仍然没有摆脱标注数据和构建训练数据集的问题。本文总结以上经验,并结合目前的迁移学习理论知识,对基于迁移学习理论和Siku-BERT自主训练预训练模型的《方志物产》断句任务进行了研究。
3 总体流程和预训练模型介绍
3.1 实验流程
本文进行的实验主要包括两个主体部分,即自主预训练模型构建部分和模型迁移部分(图1)。第一部分主要是基于《四库全书》数据和双向编码模型(BERT)训练自主预训练模型,并在不断优化反馈中得到最优的实验结果;第二部分主要是基于《方志物产》数据构建开放测试集合,结合第一部分得到的最优模型对文本进行断句识别,并对结果进行评价。

图1 实验总体流程
3.2 预训练模型数据集
预训练模型所用数据来源于繁体中文版的《四库全书》全文数据。《四库全书》共收书3503种,79337卷,36304册,近230万页,约8亿字。《四库全书》可以称为中华传统文化最丰富最完备的集成之作。
在构造训练数据集合和测试数据集合之前,先以句子为划分依据将数据切分,同时保留古文原文数据,去除现代文注解部分,最后按照99∶1的比例划分训练集和测试验证集。
3.3 预训练模型构建
实验以BERT-base-Chinese预训练模型和Chinese-roberta-wwm-ext预训练模型作为基本模型,在训练方法的选取上采用了掩码语言模型任务(MLM),通过预测遮罩部分词汇的方式完成深度双向表征的训练,采用困惑度(PPL)作为评价指标。实验中设置序列最大长度为512,每个序列随机遮罩15%的字符。
经过验证,SikuRoBERTa在验证集上的困惑度达到1.4,SikuBERT的困惑度达到16.787,初步验证表明,经过领域化语料上的二次微调,SikuBERT和SikuRoBERTa具有较低的困惑度。从评价语言模型的角度来看,在《四库全书》语料下,相比原始BERT模型和Roberta模型,其性能有所提升。
3.4 预训练模型的断句任务验证
为验证SikuBERT和SikuRoBERTa预训练模型对于古文断句的识别效果,我们在《左氏春秋传》《春秋公羊传》和《春秋谷梁传》三本古文著作数据集中进行断句识别实验(表1)。

表1 模型断句识别结果指标平均值
实验结果显示SikuBERT和SikuRoBERTa模型效果均超过85%,SikuBERT的最优F值最高达到了87.53%,同时这也是多组对比实验中的最好实验结果。guwenbert-base模型的识别调和平均值在各组实验中表现最差,仅有28.32%,远低于其他识别模型的识别效果。基础的BERT-base-Chinese和基于原始BERT模型训练得到的Roberta识别效果一般,其调和平均值分别只有78.70%和66.54%,低于我们自主预训练的识别模型。
3.5 《方志物产》数据介绍
《方志物产》是从6,170种地方志中辑录、摘抄物产资料,最终辑成431册,约23,225,659万字,具有极高的农业史、自然资源史和经济史料价值。本实验选取其中约68万字方志物产数据构建数据集,清洗其中无法被机器处理的符号,对无法被机器读取和辨识的繁体文字进行查阅、校对和简化替代,并将最终的22,067个句子,共683,628个字符存入数据库中,该数据集中不包含标点符号。
4 基于样本的迁移学习分析
迁移学习的核心思想即将基于已标注的数据训练得到的模型迁移到新的数据和模型中,帮助模型训练。通过迁移学习,我们可以将模型学到的数据间的高纬度特征通过某种方式直接分享给新模型,从而加快并优化模型的学习效率,避免每次训练模型都需要从数据标注开始。
在迁移学习中,已有的数据或知识叫源域(Sourcedomain),需要模型学习的新知识叫目标域(Targetdomain)。迁移学习研究如何将源域的知识或深层特征迁移到目标域上,在机器学习领域,迁移学习主要研究如何将已有的模型应用到新的、不同的但有一定关联性的领域中。基于传统机器学习模型的迁移学习效果有限,主要问题集中在机器学习模型获取的特征和知识维度较低,特征间的关联性较弱,在对新数据进行识别标注时往往出现“负迁移”的情况。越来越多的学者在不断实验中发现基于深度学习模型的迁移学习能够取得更好的效果,深度学习算法和模型能够在数据分布、特征维度以及模型输出变化条件下,有机地利用源域中的知识来对目标域更好地建模,在有标定数据缺乏的情况下,迁移学习可以很好地利用相关领域有标定的数据完成数据的标定。
迁移学习按照学习方式可以分为基于样本的迁移、基于特征的迁移、基于模型的迁移和基于关系的迁移。基于样本的迁移通过对源域中已标注的样本数据进行加权和特征提取利用实现知识的迁移,本文所进行的实验中,源域知识来自《四库全书》繁体中文版数据,目标域知识集中于《方志物产》,二者均为系统性知识库,语言风格和内容知识存在较强关联性,符合迁移学习思想的基本要求。同时,本文的实验主要目的为以下两点:(1)探究基于大规模古文数据集《四库全书》训练得到的SikuBERT模型在古文数据中的断句识别迁移效果;(2)探究《方志物产》文本断句任务是否能够通过计算机直接完成,加快内容信息挖掘进度。所以,基于样本的迁移学习方法符合实验目的,且具有实施可行性。
5 迁移学习实验与结果
5.1 评价指标
本实验为断句识别实验,只有当整个句子的所有标签全部识别正确时,才能够判断该句子识别成功。对实验数据中的句子长度进行统计分析,可以看出数据中的句子长度主要分布在8—20之间。为更好地对数据内部句子长度分布进行表示,采用“BME”三位标签对数据进行标注,其中“BIE”对句子进行标注,如“可B 以I □I 而I 不I 及I 福I 產E”,其中I标签为内部循环标签。
如表2数据所示,数据集合中出现次数最多的句子长度为4,共有15,455条,占全部句子数量的29.03%;同时,长度为5和3的句子分别出现8,091次和7,487次,占总体的15.20%和14.06%,三者共出现31,033次,占总体比例达到58.30%,超过了全部句子的一半。占比超过5%的句子长度均在序号2到7之间,这些句子共出现45,812次,占全部句子数量的86.01%,模型在提取断句特征时,长度为序号2到7之间的句子特征将对模型性能和识别结果起到关键性作用。

表2 句子长度分布示例
使用精确率(Precision)、召回率(Recall)和F值(F-score)能够对该类型的标注格式进行较合理的评价。
(1)
(2)
(3)
在对识别结果进行评价时,遵循整体性原则,即从句子整体层面计算准确率、召回率和F值,只有句子的所有标签全部识别正确,才判定为识别成功一次,单个标签的准确率、召回率和F值不做单独计算和评价。
5.2 实验环境和模型参数
本文所有实验的硬件配置和软件环境配置相同,主要配置如表3所示。

表3 主要硬件和软件参数
本文主要进行了四组对比迁移实验,所用深度学习模型分别为BERT-base-Chinese、Roberta、SikuBERT和SikuRoBERTa,后三组模型均基于BERT模型框架进行配置和训练,故在实验中采用相同超参数配置进行迁移断句识别任务。主要超参数配置如表4所示。
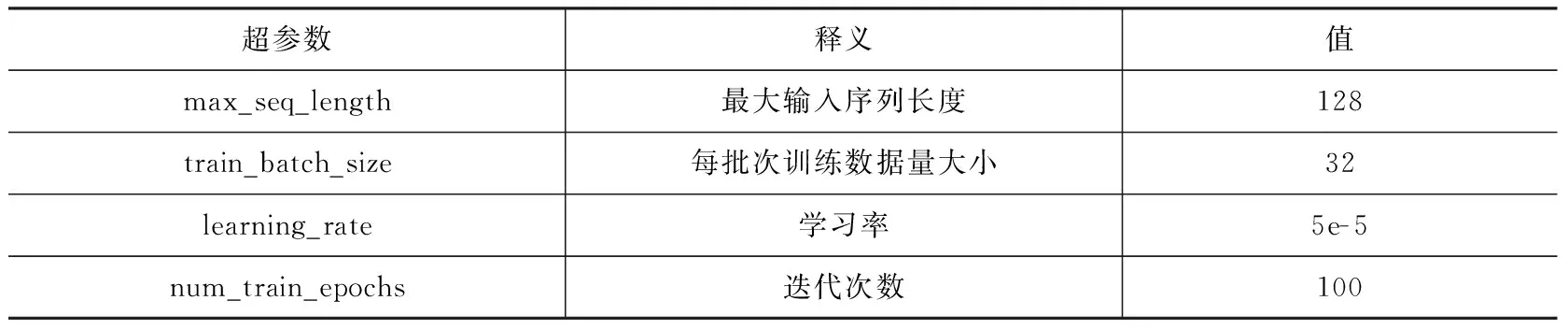
表4 四组对比实验主要超参数
5.3 实验结果
为保证实验结果的准确性,最大可能地避免实验数据分布不同对识别结果的影响,四组对比实验均进行了十折交叉验证,对每组实验的十次识别结果取平均值和最优值作为该模型最终的识别效果。如表5所示。
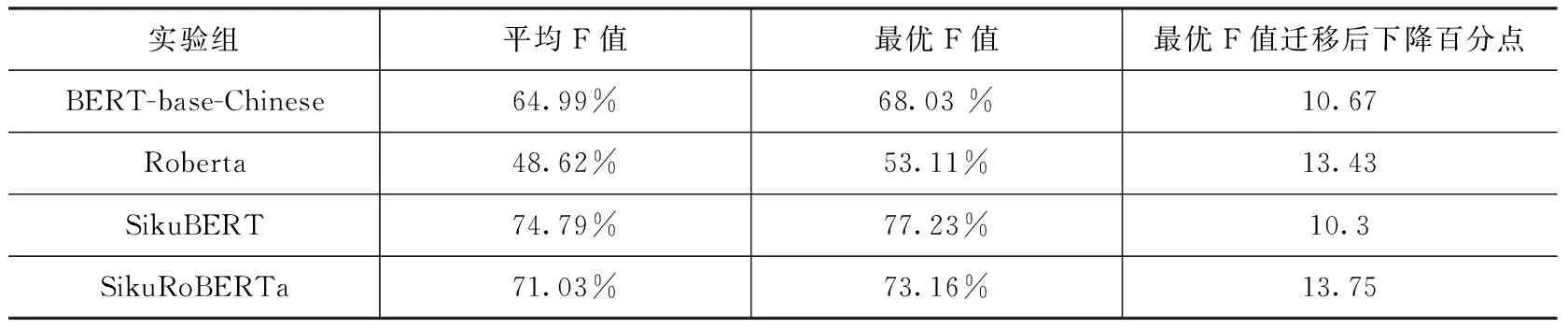
表5 对比实验结果
四组对比实验结果显示,基于《四库全书》繁体中文数据和源BERT模型训练得到的SikuBERT自主预训练模型在迁移训练实验中表现优于其他模型,平均F值达到74.79%,最优F值达到77.23%,而基于大规模现代白话文语料训练得到的BERT-base-Chinese预训练模型在处理古文断句任务时仍具有较大的改进空间,最优F值为68.03%。与此同时,通过对基于源数据训练得到模型F值和迁移训练后得到的F值进行比较,发现SikuBERT模型的F值下降最少,仅为10.3个百分点,这也说明SikuBERT模型的可迁移性较好,在不同数据集合上的表现较为稳定。
对模型输出结果进一步统计,基于信息计量的数据统计方法对模型输出进行分析,主要研究句子长度对识别结果是否有影响。
对模型输出结果进行统计分析,在所有识别正确的句子中,出现频率位于前十位的句子长度如表6所示。

表6 识别结果中句子长度分布情况

续表6
统计结果显示,识别正确的句子中,从识别长度频次角度来看,出现次数最多的为4字长度的句子,频次达到了1,279次,高于5字长度的句子频次和3字长度句子频次之和,在总体中占据最高比例,具体例子如“木髙数尺”“晝伏夜動”和“秋末晚菘”等。同时,出现次数超过100的句子长度均分布在2字至9字之间,符合“方志”和“物产”类古文的书写风格。
从不同长度句子的识别准确率来看,长度为11字的句子识别效果最好,达到了92.50%,具体实例如“又一種結椒向上者曰天椒”“凡海菜皆療瘤癭結氣等疾”和“本邑农人多种于车棚左右”等;在测试语料中句子数量较多,且识别正确频次较高的句子中,长度为2和3的句子的识别准确率较低,仅为66.86%和76.42%,低于总体识别效果的77.23%。长度为3的句子主要分布在两种语言环境中:第一种是三字句作为独立段落,如“嘉靖志”“猛獸類”和“晚穫者”等情况,该类型的三字句识别效果较高,识别效果接近97%;第二类三字句位于多句段落中,该语境中的三字句总体识别效果较低,经过分析发现该类数据被识别错误的情况主要分为两类:(1)出现于多短句并列句式中,如在“即枸杞根皮〈/〉苦寒〈/〉无毒〈/〉退热〈/〉补正气〈/〉凡使根〈/〉掘得以东流水透刷去土〈/〉捶去心〈/〉以熟甘草汤浸一宿〈/〉焙干用”和“豆之總名〈/〉有五色〈/〉又有莞豆〈/〉赤小豆〈/〉扁豆”中,“补正气”“凡使根”“捶去心”“有五色”和“赤小豆”的识别效果较低,识别错误类型主要是无法被识别,起始字和结尾字均无法被识别,被识别前后句子的一部分,全部标注为“I”标签。(2)出现于有多句的长段落中间部分,如“一名肥鮀〈/〉頭大嘴微尖在頷下〈/〉眼作紅絲圈〈/〉耳竅通於腦〈/〉無鱗少刺〈/〉鬆脆鮮好〈/〉古曰鳟〈/〉不易得”和“即元鳥也〈/〉古今注謂能與波祈雨〈/〉月令〈/〉二月元鳥至〈/〉色黑〈/〉故稱鳥衣客〈/〉此地最多〈/〉有二種〈/〉紅襟聲大者越燕斑襟〈/〉聲小者此燕〈/〉春社來秋社去〈/〉為巢避戊巳〈/〉則一也”中的“古曰鳟”和“有二種”,识别准确率较低,主要识别错误类型是三字词的起始字常被当做前一句的结尾,常被标注为“鬆B 脆I 鮮I 好I 古E 曰B 鳟E”,或者整个三字句被当做前一句的一部分,全部被标注为“I”。
长度为2的句子主要分布情况与长度为3的句子分布情况类似,主要有单独成段落形式和存在于段落中两种。单独成段落的情况下,主要是对该物产或地名等信息进行简单性状介绍,或针对多名称物产指示至其他同名条目下,实例如“口尖”“性凉”和“即鵕”等,识别效果达到100%。当存在于段落中间时,多短句并列句式对两字句的识别有重要影响,如“有白秥〈/〉紅秥〈/〉晚秥〈/〉鼠牙秥〈/〉六月秥〈/〉畬禾秥”和“凡六種〈/〉赤莧〈/〉白莧〈/〉人莧〈/〉紫莧〈/〉五色莧〈/〉馬莧〈/〉春三月種葉如蘭”中,“白秥”“紅秥”“晚秥”“赤莧”“白莧”“人莧”和“紫莧”的识别准确率较低。
对模型的识别效果进行评价时,不能独立看待识别成功频次和识别准确率以判断句子的识别效果优劣,一方面出现频次较高长度的句子占总体比例高,识别效果对总体性能的影响较大,但另一方面这类长度的句子识别效果不能明显低于平均水平。从综合识别频次和识别准确率两个方面的数据来看,长度为3至7的句子占全部句子的比例较高,模型对这些句子的识别准确率也都贴近平均水平,所以可以得出模型对长度为3至7的句子的识别效果较为优异。而长度为2的短句在测试语料中共出现519次,被识别正确的句子有347句,所占比例较高,但总体识别效果仅为66.86%,远低于平均识别效果,严重地影响了总体识别性能,尤其是位于段落中的两字句识别准确率不足50%,识别效果有待进一步提升。
为深入探究“补充解释性”标点符号对模型识别效果的影响,在进行四组对比实验的基础上,在迁移目的数据中还原“补充解释性”标点符号。本实验数据中的“补充解释性”标点符号全部为“(”和“)”两种符号,如“葉可食〈/〉清明節搗汁和粉為果餌祀先〈/〉一名夾麥青(新城縣志)”。不排除在扩大数据集合过程中出现的其他标点符号,如“〈〉”和“[]”等,该类符号的语言功能相同,仅在形式上存在差异,故在机器处理和识别过程中被视为同一类型数据。除源数据不相同外,其余软硬件配置、模型参数配置和操作步骤不做任何改变,得到以下识别结果(表7)。
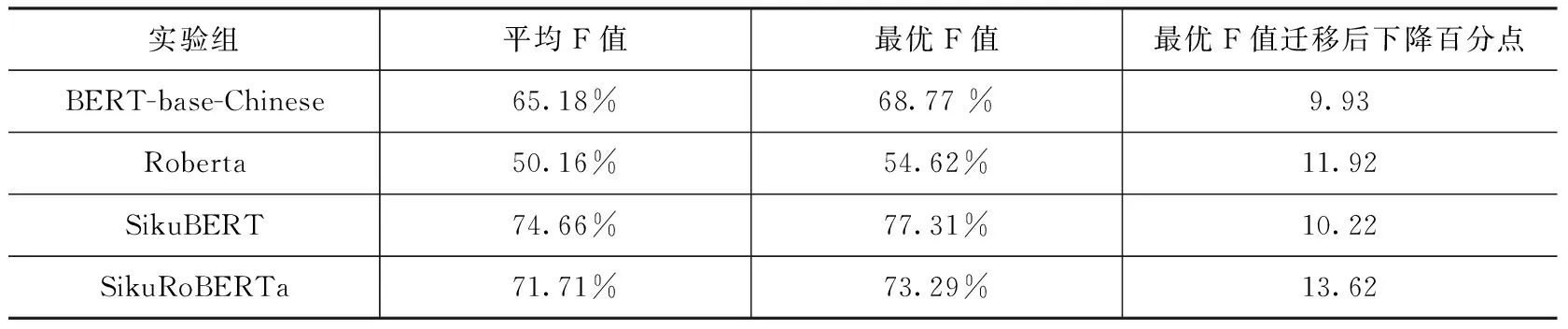
表7 带标点的数据迁移断句结果
实验结果显示,在源数据中添加“补充解释性”标点符号后,实验结果并未出现较大波动,四组实验的最优F值均有了较小的提升。对模型识别结果进行分析,发现添加进数据的“(”和“)”符号均识别成功,识别准确率达到了100%,且以“(”符号为开头和以“)”符号为结尾的句子识别准确率有一定的提升,但提升效果有限。综合以上分析可得结论,最终添加“补充解释性”标点符号对实验结果有一定的提升作用,但提升效果不佳。
总体来看,SikuBERT模型的迁移效果最优,在无标点数据上的最优F值达到了77.23%,相较于源BERT模型的迁移效果提升了9.2个百分点;在有“补充解释性”标点符号的数据上取得了77.31%的最优F值,比源BERT模型提高了8.54个百分点。但两部分对比实验结果并未达到可实际应用的层面,后续仍有较大的改进空间。基于《四库全书》繁体中文数据训练得到的SikuBERT预训练模型的迁移性值得肯定,且《方志物产》数据断句任务可在机器断句的基础上加以人工核对,极大地减少和降低了工作量和工作难度。
6 总结
本文基于迁移学习理论和深度学习模型,在解决古文领域的断句难问题时,提出“自动断句迁移模型构建”这一研究点。实验核心内容集中在基于《四库全书》繁体数据的SikuBERT预训练模型构建、《方志物产》目的域数据构建、迁移学习理论与任务结合探究和最终的断句任务迁移学习实验。本文在迁移学习理论基础上,提出了古文断句任务与深度学习方法的结合,在源数据集合上训练得到最优模型、学习数据的高纬度特征关系,并将该特征知识迁移到相关领域数据上,一方面验证了实验构建的SikuBERT自主预训练模型的古文断句能力和迁移识别能力,另一方面证明了《方志物产》断句任务可在机器断句的基础上极大地简化人工标注任务量。
实验结果表明,SikuBERT自主预训练模型在《四库全书》和《方志物产》断句任务中表现较为出色,相较于源BERT模型有较大提升,间接说明了古文相关处理任务的最终落脚点还是古文本身,基于现代汉语的机器学习和深度学习模型不能够有效解决古文识别任务。同时,本实验的《方志物产》迁移断句识别效果表明,以《方志物产》为代表的旧方志文献文本挖掘任务可以在SikuBERT模型的基础上进行迁移,通过“人机结合”的方式减少和降低数据挖掘任务量和难度。
在接下来的工作中,笔者将主要从数据关联度和标点可用性两个方面,探讨如何提高古文断句和断句迁移效果。数据关联性方面,主要探讨源域数据特征和目的域数据特征间的相关性,主要从语言语体风格和数据量等方面进行探讨。标点可用性方面,主要验证在不同数据量和不同句子长度条件下,非断句符标点对最终的识别效果是否总是起负向推动作用。
