《方志物产》素材库集外字特征及整理研究
2022-08-15白振田
左 亮 白振田 包 平
(南京农业大学数字人文研究中心,南京 210095)
我们在进行古籍数字化时往往会遇到集外字的问题。集外字作为工程化概念,并没有严格意义上的学术定义[1],主要是指特定字符集以外的不使用特殊手段无法输入、处理和显示的文字[2]。集外字的存在给古籍文本的整理、校正、编辑、检索带来诸多不便。由于时代因素、地方背景以及人为因素的干扰,集外字具有多样性、时代性、复杂性、特殊性、地方性等特点。较为典型的集外字类型有:异体字、讹字、避讳字、人造字和重文符号等。
部分集外字在逐步构建和完善字库过程中得以解决,但仍有一大部分集外字无法在计算机当中得到有效显现。《方志物产》作为研究动植物史、农业史、经济史、环境史的重要史料,在对其进行整理和信息挖掘利用的过程中,发现其数据文本中存在大量集外字的情况且独具特色。目前已经整理完成《方志物产》条目数据共计1,523,239条,其中含特殊符号的条目达到221,510条,占比达到15%。对待这部分字符不能弃若敝履,为了让《方志物产》全文数字化并保持原本原貌,亟需一套科学的解决方案。
1 研究对象概述
地方志文献当中的“物产”章目详细地记载了一地的动物、植物和矿物资源,并且“极为详细,在别的书里面是见不到的”[3],“对于农业科学史实在是非常重要的、无法取代的价值”[4]。从1955到1958年三年间,时任中国农业遗产研究室(为现在中华农业文明研究院前身)主任的万国鼎先生,组织一百多人次,以《全国方志总目》(1)《全国方志总目》:万国鼎先生依据《中国地方志综录》修正稿编印而成。为蓝本,在全国范围内对7,532种地方志中的物产史料展开查抄工作,并分类整理装订成册。
《方志物产》在内容收录上秉持应收尽收原则,查抄了自北宋熙宁九年(1076)至民国三十八年(1949),包括新疆、西藏、台湾在内的26个行政区域(2)行政区域按方志记载时间划分。其中河北含北京、天津,甘肃含宁夏,四川含重庆,江苏含上海,广东含海南。的地方志资料[5]。查抄志书来源除传统总志、通志、府志、州志、县志、乡土志之外,还查抄了一些罕见方志,如里坊志、民国调查资料表、文献志、风土志、岛志、山川志、河流志、采访册、关隘志、疆域志等。半个多世纪后的今天,少数方志已经散佚,《方志物产》则很好地保存了众多方志物产记载,个别疑成海内孤本。
《方志物产》在查抄时尊重摘抄志书原貌,按照原有志书类目、体例、行文,原封不动地抄录下来,保持繁体竖版排列风格(图1)。在编纂过程中,书上刻板错字,一般照抄不改,只用眉批注明“疑作某字”或“应作某字”。查抄完成后按照资料性质、省府州县乡的区域位置、方志编纂年代的先后,分类编排,每册正文第一页均配以悉心撰写的目录,让读者一目了然。手抄本《方志物产》的集成并不是简单的资料罗列,而是对查抄的内容进行精心的编排分类,时空经纬,查找便捷,让零落于地方志不同门类中的物产资料不再秦越相隔,而是荟萃镕铸,专备有识者探微采撷。

图1 手抄本《方志物产》资料(局部)
2 《方志物产》数字化历程及存在问题
为了更好地保护和利用《方志物产》手抄本资料,中华农业文明研究院的专家学者们开始对《方志物产》进行数字化保存与整理工作。
2.1 《方志物产》数字化历程
《方志物产》数字化是指利用现代信息技术,将《方志物产》资料数据中的“语言文字转化为能被计算机识别的数字符号”[6],并通过计算机、网络等介质对《方志物产》文献进行保存、利用、共享,让《方志物产》文献资料“突破时空的限制,成为取之不尽、用之不竭的资源”[7]。《方志物产》数字化工作总共经历了文本数字化、数据格式化、素材库三个阶段:
(1)文本数字化阶段:2000年,中华农业文明研究院依托科技部“中国农业典籍的搜集、整理和保存”项目,对《方志物产·江苏卷》进行了全文扫描,以图像方式进行保存,迈出了《方志物产》数字化进程的第一步。2005年,借助科技部“中国科技农业遗产数字化保护与利用项目”的契机,对手抄本《方志物产》开始了全文数字化工作(图2),是《方志物产》数字化进程中的里程碑事件[8]。对《方志物产》文本数字化,实现了对《方志物产》资料的保护、利用与资源共享,为之后的物产史、栽培史、环境史研究提供了数字文本,同时为《方志物产》深度利用奠定了基础。

图2 《方志物产》目录及内容(局部)
(2)数据格式化阶段:2018年,中华农业文明研究院承担了“方志物产知识库构建及深度利用研究”国家社会科学基金重大项目,在前期(2014—2017年)中央高校专项业务费重大招标项目工作的基础上,开始构建《方志物产》知识库并开展深度利用。为了更好地实现《方志物产》知识库的构建,就需要对数字化之后的文本进行数据格式化处理。其中李娜博士通过计算机辅助技术及人工标注方法构建了一套基于文本特征的格式化标准,给每一个字段都设计了一个特征字母,分别为B、D、H、Z、N、Y、P、Q、J、C、X、W、S、L[9],依据此种元数据编码格式形成的数据源能够更好地通过对应的ID被计算机识别并保存到素材库当中,从而实现数据的结构化转换。例如:嘉靖《陕西通志》凤翔府物产语料格式化后为:
B方志物产114
D陕西1
H
Z陕西通志(鳳翔府)
N明·嘉靖21年(1542)
Y46- 47
P46- 47
Q98- 99
J35∶14
C物產
X
W
S
商陸/本草鳳翔有之註見咸陽
骨碎補/一統志出鳳翔註見西安
秦芁/一統志出鳳翔註見秦州
芎藭/本草云今鳳翔有之味辛溫無毒一名胡窮一名香果
……
……
蔓荊實/味苦辛微寒平溫圖經云舊不載所出今隴州多有之
榛子/唐宋鳳翔府貢之一統志出隴州
P47
Q99
絨獸/一統志出隴州似猴而大行毛長黃赤色人取其皮作鞍褥
鳥蛇/一統志出隴州宜療疾註見商州
石魚/一統志出涆陽西四十裡有魚隴掘地破石得之状若鰍鯽鱗鬛俱備可辟衣蠹
L
(3)素材库阶段:2018年,课题组针对格式化后的全文文本数据开发了“方志物产知识组织与挖掘系统”,构建了全文素材库,并实现了素材导入、志书管理、全文检索、分类导出等功能。为了保证用户在使用数据时的准确性,系统提供了图文对照功能,用户可以将系统检索的文字内容与《方志物产》原文图片进行对比,确保利用信息时尊重原文原貌。其中的全文检索,配以关键词和聚类等检索入口,可在海量文本中精准检索,为领域专家进行物产史和农业史等相关研究提供计算机辅助手段。
2.2 《方志物产》数字化存在的问题
文字的出现、演进有着悠久的历史,其中的繁体字、异体字甚至是民族文字不知凡几,《方志物产》中除了这些文字之外,还存在着大量的特色物产和农业术语。对《方志物产》数字化处理实质上就是对其中文字进行整理,虽然所有的文字都是用汉字进行描述,但是部分文字写法与正字有所差异,无法用字符集内文字显示。这部分文字诚然反映了当时当地在文字使用上的特点,但对后续在线阅读、知识挖掘、人文研究等均会带来困难和障碍。前人在《方志物产》数字化整理进程中,对出现的问题文字并没有进行深入研究,而是以特殊符号或后加描述性语言来指代,这部分特殊符号指代意义多样,其中包含了该处文字为集外字的可能性,因此有必要将这些问题文字提取出来进行分析,厘清其具体的指代意义,以便能够梳理出其中的集外字并进行针对性的解决。
在对《方志物产》数字化时,部分文字或由于原稿缺失,或由于原稿辨识不清,便以传统的符号“□”“■”对其进行指代。在对《方志物产》数字化文本进行筛选汇总整理后,发现除“□”“■”传统特殊符号外,还增加了部分现代符号对集外字进行表示,如“?”“”“※”等,并且不同的特殊符号指代不同的含义(表1)。如《增修乾隆定安县志》4卷(董兴祚)当中描述的“東風”,其描述信息为“先麻而生□□□上有細毛□□□□”;如清康熙三十年(1692)《义乌县志》中物产竹之属当中“紫竹,黯色、黝然,可為籥*管”。该类字符在整个《方志物产》条目中占到164,182条,比例为10.78%。
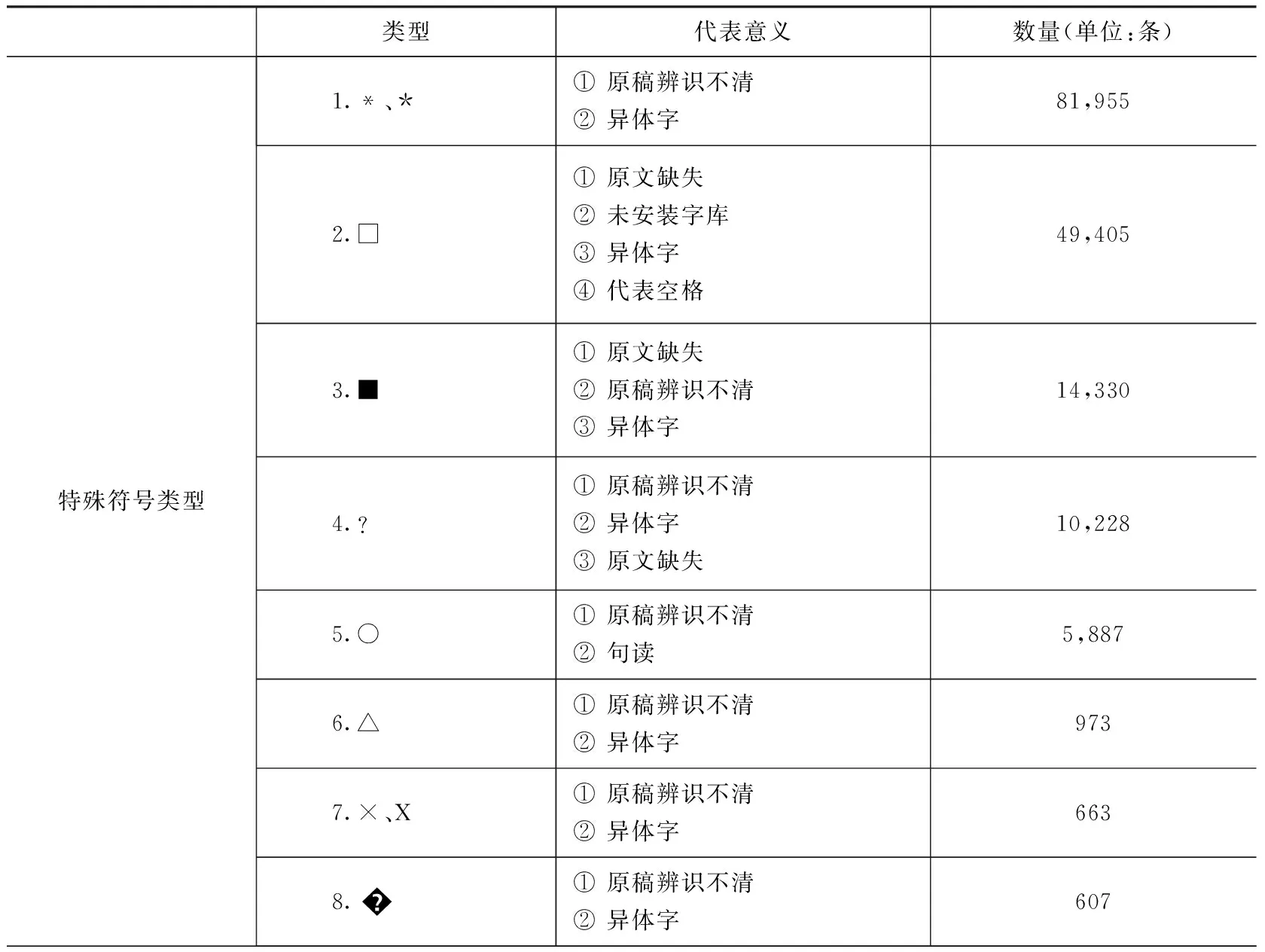
表1 集外字特殊符号类型一览表
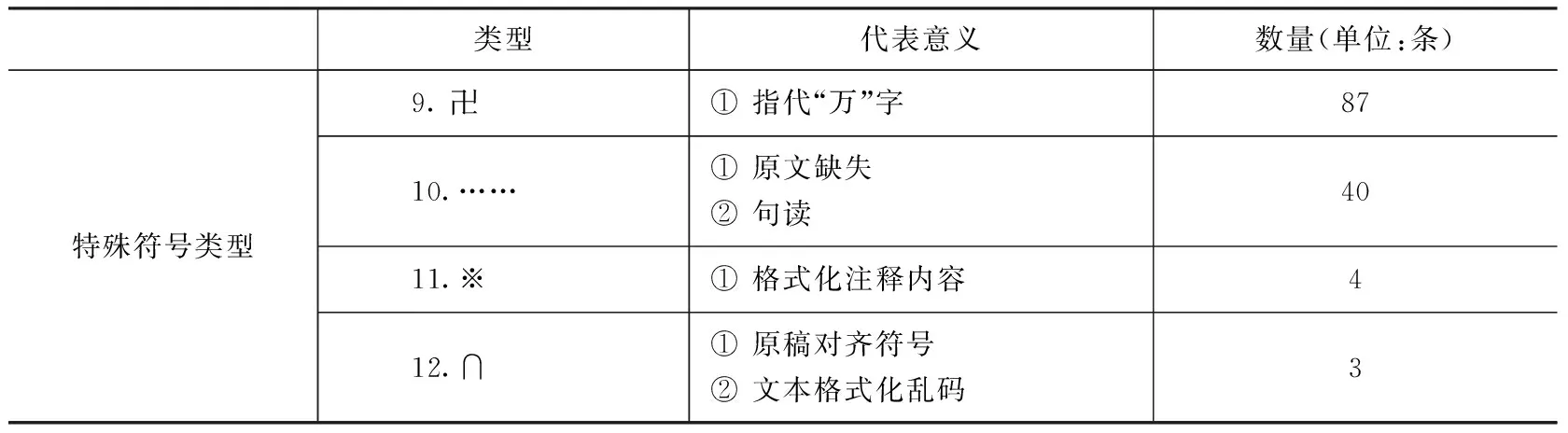
续表1


表2 集外字描述信息类型一览表
3 《方志物产》集外字产生动因及类型
3.1 《方志物产》集外字的产生动因
集外字处理是《方志物产》数字化的重要一环,因此必须根据《方志物产》文献的特点找到集外字产生的根本原因,有针对性地解决《方志物产》中存在的集外字问题。在对《方志物产》中出现的221,510条含有特殊符号的条目分析后发现,其中集外字数量占到总条目的十分之一以上,出现集外字的原因主要有以下几点:
(1)历史因素:《方志物产》主要摘抄自明清时期的地方志,在明清时期由于当时尚奇美学、复古思潮的影响,再加上表现主义书风[10],导致了异构字和异写字两大类[11]异体字盛行,这部分异体字未进行规范,成为了今天的集外字。这部分文字与集内字或是偏旁部首不同,或是笔画有些许差异,或是为了书写方便,变化笔画或缩减笔画而成,如:“鱠-脍”“鯯-”等。《方志物产》无论是当初的查抄还是现今的数字化过程,对该部分文字并不更正,而是原样录入。


图3 民国五年崇祯《常熟县志》[抄本]


(3)版本因素:在地方志的保护过程中,一方面由于一些不可抗力,如虫蛀、战乱等,会导致地方志中出现缺字、缺页等内容缺失的现象。另一方面传统印刷以木活字或者刻板为主,在岁月的更迭当中,这些底版由于保存不当,或者在印刷过程中油墨量控制不均,往往会出现缺字或者印刷不清的情况。这种情况下,很难对原本志书的内容进行还原,只能以“*”“□”“■”“?”等特殊符号替代。
如清康熙四十一年(1702)永昌府志[刻本](图4)、清乾隆三十八年(1773)《奉化县志》[刻本](图5)中就存在印刷不清的问题。

图4 清康熙四十一年永昌府志[刻本]

图5 清乾隆三十八年奉化县志[刻本]
(4)字库因素:为了适应发展变化的时代需要,地方志每隔若干年或者一定时期就需要重修、续修、新修或鼎修。时代的更迭又导致语言文字不断发展演变,不同时代的人们对于同一文字往往会形成各种各样的书写符号,其中除了字形之外意义完全相同的纯粹意义上的异体字,大多数字在字形、组成上都或多或少存在些微差异。《方志物产》手抄本资料是从各地图书馆所藏地方志中摘抄而来,其中文字今日无论有无、讹误与否,只要是字,都能抄写出来。
数字化文献受字符集所限,只能显示字符集以内的文字,并且由于近年不断推广规范字,很多学者本着“统一、不错”的编辑原则,将部分异体字或者繁体字舍去,这就导致字符集所收录的汉字不甚完备。《方志物产》数字化,是用一个有限子集(字符集以内的文字)去处理一个规模庞大的全集(手抄本所有文字),必然有许多文字不能重现。在对《方志物产》进行数字化处理、深度利用过程中发现,在录入的23,225,659字中,仍然存有大量集外字的情况。
(5)人为因素:集外字实质上就是跟正字对比之后,写法有区别的字符。从实践角度来看,集外字的出现往往存在人为因素干预,在古籍传播过程中,书写者、刻板者、誊抄者往往会因为自身的主观原因,对原本当中的字形误判、误写、误刻、误录,从而用自身认为正确的字或者音义相近的字对原文字进行替代。这就导致了这些集外字“以讹传讹”进入到典籍或是数据库当中。
《方志物产》数字化过程是个不断衍变的过程,从古籍到现在的素材库,其中经历了古籍原本到手抄本阶段、手抄本到图像扫描本阶段、图像扫描本到电子文本等阶段。不同的转录人员受囿于自身的古汉语水平、专业知识素养,在各个阶段中都会由于人的因素而产生讹误。如民国三十七年(1948)《醴陵县志》当中关于米酒和鳖甲的记载,就存在录入人员误读的现象。“米酒:行药势、通血脉、散湿气、除风御寒、杀恶虫毒。”当中行药势的“势”字由于录入时未能有效辨别,便被记录为“*{上執下力}”。“鳖甲,治久疟、阴毒、腹痛、劳复、食复、斑痘、烦喘、惊厥、难产、阴脱、血瘕、石淋、陰頭瘡、潰瘡。”其中的血瘕便被记作了“*{疒內段}”(图6)。

图6 民国三十七年(1948)醴陵县志
3.2 《方志物产》集外字的特点



4 《方志物产》集外字的解决方案
《方志物产》知识库的构建可以将孤立的信息通过规则关联起来,能够极大地加强人们对于物产数据的理解和感悟。如果不能将“数据世界”中的集外字进行有效呈现,对于《方志物产》的字词分布特征、知识发现与考证、物产数据的聚合等研究将缺乏真实性和完整性。除了加强基础设施建设与相关研究之外,可根据志书成书规律、连续记著的特点,并结合相互引证的内容及其他数据库,查梳《方志物产》素材库构建各个过程中存在的错误,找到科学的路径对集外字勘误辩正、对比研析、悉厘正之,使其不断趋于客观准确,还原为更为合理的历史形态。
4.1 完善字库,丰富输入方式
字库组织的依据为字库的编码方式,作为文本数字化的关键,不同的语言文字所占字符数、字长、编码方式、编码标准均不一致。《方志物产》中收集、整理的异体字字符属于大字符集,占位为两个字节长度。《方志物产》数字化项目开始于2005年,当时所采用的Unicode字库辑录汉字不足6万字,双字节字符集采用的是大五码,除此之外无其他大字符集和输入方法可供选择,这就导致数字化过程中大部分文字被判定为集外字并且无法录入。
“中华字库”工程的实施,为我们解决部分集外字问题提供了可能。2006年,国家新闻总署立项“中华字库”工程,该工程尽可能地将我国所有出现的汉字形体汇聚起来建立字迹联系,并根据发展需求制作出符合各类应用需要的字符库,可编码汉字古文字符40余万字,楷书汉字30余万字,少数民族文字10余万字。依托“中华字库”工程,并且通过对计算机字库进行升级,将Unicode升级至13.0版本、UniFonts升级至6.0版本。部分集外字可以通过手写输入方式直接键入计算机中,并且可以在不同的终端进行呈现。如光绪七年《归安县志》所载“*{上圭下黽}:一作蛙,《吴兴志》*{上圭下黽}類不一,惟色青而肱長者為人所食,今鄉土惟貧乞取以貨名田雞,本郡每歲夏初揭榜禁捕)”,其中的“*{上圭下黽}”通过手写输入法可以在计算机中直接键入“鼃”。
4.2 推勘法
推勘法主要由辞例推勘法和文献比较法两种方法构成,是古文字考释的一种基本方法。辞例推勘法是将文字置于特定语境中联系上下文进行推理以便能够知道该字所表述的含义,文献比较法是通过对存疑文字与其他文献记载的比较印证,得出最稳妥的字[15]。处理过程秉承“多闻阙疑,择善而终”原则,一方面对古籍记载错误以及格式化过程中出现的错字,按照“校雠四法”的理论,通过对校、本校、他校和理校的手段,结合上下文语境、字形走向和文字具体意义严格加以字斟句酌,审慎从事;另一方面,本着对古籍本身讹字“博考以证其失”“参酌而寤其非”“于所不知,益阙如也”[16]的原则,发现错误,也不更正,而是保留原字,在其后注释出认为稳妥的正字。
民国三十七年(1948)《醴陵县志》中米酒和鳖甲描述信息中存在的集外字采用了文献比较法的考释方式。数字化之后记录的米酒和鳖甲描述内容为“米酒,行藥*{上執下力}、通血脈、散濕氣、除風、禦寒、殺惡蟲毒”“鳖甲,治久疟、阴毒、腹痛、劳复、食复、斑痘、烦喘、惊厥、难产、阴脱、血*{疒內段}、石淋、陰頭瘡、潰瘡”。其中的米酒和鳖甲通过对原志书比对可以看到原字走势,并结合李时珍《本草纲目》谷部中记载:“米酒,【主治】行药势,杀百邪恶毒瓦斯(《别录》)。通血脉,浓肠胃,润皮肤,散湿气,消忧,发怒,宣言畅意(藏器)。”《本草纲目》介部中记载:“鳖甲,【主治】心腹症瘕,坚积寒热,去痞疾息肉,阴蚀痔核恶肉(《本经》)。疗温疟,血瘕腰痛,小儿胁下坚(《别录》)。”便可知*{上執下力}、*{疒內段}分别为“势”“瘕”。
清雍正十三年(1735)《陕西通志》及清道光九年(1829)《东阿县志》中的部分集外字采用了辞例推勘法和文献比较法相结合的考释方式。首先需根据上下文推测该集外字疑似为何字,同时查看该志书版本,根据志书版本、年代查找同版本志书,比对“爱如生数字方志库”“籍古轩《中国数字方志库》”,届时再从天头、地脚、鱼尾、界行、版框等细节处着手进行比对。确定为同一本志书后,根据查找出的内容对集外字进行替换。如“詩經■風”,在文本化的《方志物产》所载清雍正十三年《陕西通志》中,记录为“壺盧,八月斷壺(詩經■風)”,经过查找中国数字方志库发现,记录为“壺盧,八月斷壺(詩經□風)”;又如清道光九年《东阿县志》“菜瓜,與越瓜同,形而色青,可以作*(上艹下殂)”。通过比对《东阿县志[道光]》可以得知该字为“菹”,可以直接输入为“菹”。
4.3 集内字替换+IDS描述
在解决集外字问题时,有部分文字经过不断演变已经不再使用,如昙花一般短暂的存在于某个时代当中,对这部分文字我们需要“泛时化”,“从‘共时’和‘历时’两个角度”归纳集外字“同用现象”、探讨集外字的“产生与演变”[17]。修纂历史悠久和自成系列的志书成果为我们从“泛时化”角度解决集外字问题提供了有力抓手。地方志的编修随着地域情况变化、行政区划变更、新事物出现不可能一劳永逸,而是代代相传,构筑起绵密悠长、连续不绝的修志传统。地方志编纂办法是以旧志作为基础,不断进行核实补充的,上承前志下限,以时间上的连续记载构成志志相续的序列。
因此在处理《方志物产》集外字时,根据志书关联连续的特性,既要查阅该地不同年代志书记录的相同物产信息,又要查阅相同物产在其他版本志书,甚至是其他地域志书的记载。从物产名、别名、产地、用途等描述信息中对考证出的文字进行文字认同,并且在认同的文字后添加IDS描述,这样既能够保持文本原意,又能够还原文字原貌。如“芣苢,亦名車轱(車+魯)?菜”,经考证光绪十年(1884)版《荣昌县志》,得知“車前子,一名芣苢,詩采采芣苢,卽車前也”。在民国四年(1915)版《盘山县志略》中记载“車前子,即詩所稱芣苢。多生道旁,布葉如輪,俗呼曰車轂轆菜”。依此便可基本明确的将“(車+魯)”替换成“轆”,为了增加保真度和可信度,在其后增加IDS描述信息,即“芣苢,亦名車轱轆(原文为:車+魯)菜”。
4.4 字符编码映射法
字符编码映射法包含两部分内容:一是通过造字法将古籍当中的集外字通过特定的造字程序创造出来。二是根据古籍特点制定编码规则,将造出来的文字一一编码,最终形成集外字字典。字符编码映射法可以通过该编码节点查询其对应的实体内容在编码规则表中的引用情况。
《方志物产》的部分集外字采用字符编码映射法予以处理,《方志物产》的编码规则为取“方志物产”首字母“FZWC”作为编码表词头,以代表该编码映射表针对《方志物产》所建立,用“00001—99999”表示集外字顺序(图7)。如“菽/(豆總名,青、黃、黑、白、紅、菉數種,又有豇豆、豌豆、*{上卄左下耒右扁}豆、赤小豆、白小豆、扒山豆之類)”,该集外字“*{上卄左下耒右扁}”就可以通过专用字符编辑程序进行造字,在程序当中分别输入“艹”“耒”“扁”,按照描述的方位进行组合,便可以得到“”。通过编码映射法上述语料即可表示为:“菽/(豆總名,青、黃、黑、白、紅、菉數種,又有豇豆、豌豆、FZWC00001豆、赤小豆、白小豆、扒山豆之類)”。

图7 编码映射规则与部分字码对照表
5 讨论与展望
5.1 加强集外字处理的标准化和规范化
纵观集外字的处理历程,还有很多问题尚未解决。文化和旅游部于2020年9月起草了《汉文古籍集外字描述规范》并于2021年1月正式实施。但是该规范仅仅是针对汉字集外字处理过程中如何对集外字进行IDS描述而制定,只规定了汉文古籍集外字描述的基本原则、拆分流程和如何描述数据结构,未能对集外字处理及字库的建设提供相应的准则。因此在集外字的处理上学者们采用的标准、模型和理论并不统一。
在集外字的处理上,大多数学者造字时采用的编码为Unicode编码,该编码对使用者的身份未做任何限制,虽然其可以提供137,468个码位供用户使用,但是用户使用时没有统一的标准和规范,在使用的过程中不同古籍的项目成员完全按照自己的喜好,对古籍中出现的只要与字符集中的字形有差异的文字就进行造字。如此就会导致同一个编码位在不同的古籍项目中甚至不同的设备中代表不同的字符,产生编码冲突,显示出来的文字不符合原文,并且肆意使用,编码资源会很快耗尽。
在字库构建上,元数据会涉及原始资料的图文采集、对采集后的图文数据进行编码、对编码完成之后的数据进行存储、对存储之后的数据进行调研和可视化呈现等方面。这部分过程必须严格遵循统一的建库标准才能保证字库建设的质量和规范。但是在构建字库的过程中,学者们所采用的方法和流程莫衷一是,这就导致字库建设完成之后可移植性较差。
5.2 构建基于地方志特色的集外字字库
目前,在地方性文献的数字化处理过程中,大都基于地方特色形成了专属的文字字库。如西南民族大学的学者们结合广西彝文的字符特征,依托OpenType技术对广西彝文文字设计了彝文古籍文献字库[18]。华中科技大学的学者借助“字位”的概念,创建了13个甲骨文子字库和24个金文子字库的通用古文字字库[19]。
与上述文献类似,地方志文献资料在编撰时往往遵循的是当地的文风,在部分文字的使用上还会使用当地的方言俚语,这部分文字与官方所使用的文字略有出入,但正是这部分内容的存在彰显了地方志资料的地方属性,也应对其搜集整理。对其中的文字运用大数据技术和协同工作平台,从海量的文本当中提取物产集外字的原字图和字形,保留每个文字的原貌和样例,以便回溯核校。对该部分文字要提供属性库和关联关系表,提供考释过程,对横向的异体关系和纵向的传承演变进行系统整理。将该部分文字整理核校之后,按照国际标准化要求,设置地方志文献集外字字库建设标准,提交国家相关机构。
5.3 基于智能化考证手段进行集外字工程化处理
当前,自然语言处理技术已渐趋成熟,数字技术的发展促进了传统集外字处理的转型与拓展,通过数字技术来检校因果关系以及字词之间的相关性,利用数据关联、文本映照、模式识别、算法模型等帮助辅助处理集外字问题已变得可能。华中科技大学中国语言研究所尉迟治平教授在对《广韵》的异体字处理研究中,提出要将数字化的古籍看做成一种全新版本,根据数字化研究处理原则,对存在的汉字异体字进行先期处理,关联集外字的码点,整理异体字的字形[20],选择出代表字。吴琴霞通过对集外字字形进行矢量描述,构建动态描述库,用户可以根据自己的意愿通过对动态描述库对错别字、异体字以及合体字进行设计和输出[21]。
在《方志物产》集外字处理实践中,可以假设全国《方志物产》关于同一物产注释的描述有类似之处,A处的物产规范不含集外字,同一物产在B处出现集外字现象。借助诸如编辑距离计算、杰卡德系数计算、TF计算等自然语言处理中句子相似度算法,发现A、B两处的物产注释相似度达到一定阈值,则可证明A、B两处物产为同一物产,经人工再判断,即可相互代换。此举作为解决集外字手段的一种设想,后续将另行撰文研究。
