基于大规模自动标注语料的AMR-to-Text生成性能研究
2022-08-15付叶蔷李军辉
付叶蔷,李军辉
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
近年来,随着大规模语料的发布使用,抽象语义表示[1]在自然语言处理任务中得到了广泛应用,例如事件抽取[2]、问答系统[3]等。AMR-to-Text生成是一种从抽象语义表示图生成自然语言句子的任务,AMR作为一种语义表示对句子意义至关重要,因此AMR-to-Text生成受到了广泛关注。AMR是一种新的语义表现形式,其将自然语言文本以句子为单位抽象成单根有向无环图。如图1所示,其中图中的“want-01”“dog”等节点表示语义概念,而“:ARG0”和“:ARG1”表示节点间的语义关系。
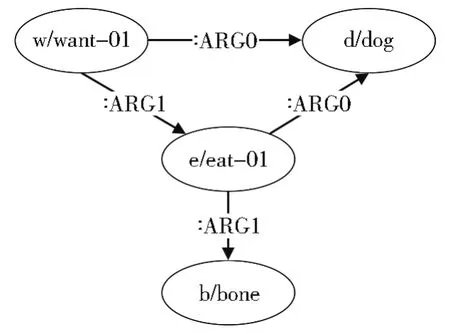
图1 句子“The dog wants to eat the bone”对应的AMR图Fig.1 AMR graph for sentence "The dog wants to eat the bone"
AMR-to-Text生成也可以当成一个序列到序列(Seq2Seq)的翻译任务,其中源端是AMR图,目标端是文本。与当前成熟的神经机器翻译任务[4]不同的是,AMR-to-Text生成可使用的已标注标准数据集样例较少、规模较小。如表1所示,LDC2015E86(AMR1.0)数据集中,训练集为16 833条样例;在LDC2017T10即AMR2.0数据集中,训练集仅有36 521条训练样例;在 LDC2020T02(AMR3.0)数据集中,训练集增加到了55 635条样例,而该三份AMR标准数据集中开发集和测试集样例更少。受AMR小规模标准数据集的影响,AMR-to-Text生成性能受模型影响较大。如Zhu等[5]实验结果所示,AMR-to-Text生成使用序列到序列(Sequence-to-Sequence,Seq2Seq)的Transformer基准模型,在AMR2.0测试集的性能为27.43BLEU值,而在基准Transformer编码端对图结构进行建模后,性能提高了4个BLEU值。受此启发,本文设计不同的方案探索在大规模自动标注语料的基础上,AMR-to-Text生成在基准模型和先进模型间是否仍有显著的性能差异,先进模型是否能够保持其生成文本的性能优势。实验结果表明,在仅使用AMR已标注标准数据集时,先进模型在AMR-to-Text生成任务中的性能优势显著;而在大规模自动标注语料的基础上,先进模型与基准模型生成文本的性能相当,其性能优势不明显。
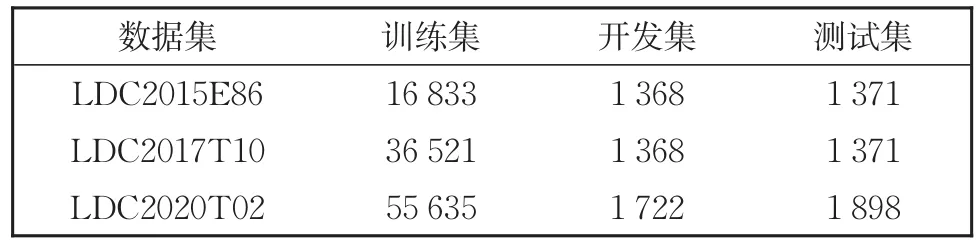
表1 三个AMR数据集的统计信息Table 1 Statistics on three AMR datasets
1 相关工作
早期,AMR-to-Text生成常用基于统计的方法。目前,该任务常用的方法大致可分为序列到序列和图到序列方法。
在基于统计的方法中,Flanigan等[6]首先将AMR图转换为树,再采取一种规则提取方法将转换得到的树结构翻译为句子。Song等[7]利用同步节点替换语法,在训练过程中,使用启发式提取算法学习图到字符串规则,在测试时,用图形转换器输入AMR产生输出句子。
目前常用基于序列到序列和图到序列的方法。Cao和Clark[8]通过两个步骤进行AMR-to-Text生成:先生成句法结构,再生成表层形式,其可以生成与AMR图具有相同意义的句法释义。Konstas等[9]将 Seq2Seq模型应用在 AMR-to-Text生成任务中,利用数百万未标注句子对AMR图进行处理。Pourdamghani等[10]将AMR-to-Text生成视为基于短语的机器翻译(phrasebased machine translation,PBMT),在该任务中,将AMR图线性为序列的形式。目前性能最优的AMR-to-Text生成模型,多采用图到序列的形式,这样可以更好地解决AMR图线性化后信息丢失的问题。例如:Song等[11]采用LSTM模型,引入AMR图结构,构造一种新的LSTM模型进行图结构编码,该方法可对AMR图节点利用向量单元保存历史信息。目前越来越多的研究通过不同方式提高AMR-to-Text生成的性能。例如:Jin 和 Gildea[12]针对 AMR 图编码提出了两种基于广义最短路径的算法,此方法可以有效地利用上下文信息将AMR图生成文本。Na和 Min[13]在 Cai和 Lam[14]提出的联合模型基础上,仅更新单个联合状态节点,不保留双状态向量。Fan和Gardent[15]采用跨语言的方式,通过预训练和多语言模型提高AMR-to-Text生成性能。Zhang等[16]利用图卷积网络对输入的AMR端进行编码,并引入了一种动态融合机制,提出轻量级动态图卷积网络(Dynamic Graph Convolutional Networks,LDGCNs),通过从输入的AMR图中获取更多的全局信息提高文本生成的性能。Bai等[17]使模型的解码端在文本生成过程中对输入的AMR图进行反向预测,通过将预测的AMR图和句子相结合,减少了解码时信息的丢失。Xu等[18]提出了一种基于多任务学习的预训练方法,用于零资源跨语言的AMR文本生成任务。Liu等[19]通过在目标端随机引入噪声,并添加一个辅助任务去还原噪声前的单词提高模型的健壮性,有效提升了AMR文本生成的性能。
2 AMR-to-Text生成
本文使用OpenNMT框架作为Transform⁃er的基准模型[20],选取两个基于该基准 Trans⁃former模型的先进AMR-to-Text生成模型与基准模型生成文本的性能进行比较。
为了将Transformer模型更好地应用于AMR-to-Text生成任务,本文对AMR图进行线性化处理。针对数据稀疏这一问题,本文使用子词化方法将低频词汇单元分割为小粒度的高频子词单元。同时结合该任务源端和目标端存在大量相同词汇这一特点,本文采用了将源端和目标端共享词表的策略。
2.1 模型介绍
本文的基准模型为当前主流的Seq2Seq模型Transformer,该模型在神经机器翻译领域得到了广泛应用[21-23]。Transformer模型可分为解码端和编码端两部分,每端由多个相同层次组成,在本文中层数设置为6。解码端和编码端的每层都含有自注意力(self-attention)层和前馈(feed-forward)神经网络层,不同的是,解码端的自注意力机制和前馈神经网络层之间还有一个注意力层。值得一提的是,为了更好地学习词序信息,Transformer模型在解码端和编码端均对单词的位置信息进行编码,本文的基准模型使用绝对位置编码,如式(1)和式(2)所示:

其中,PE为二维矩阵,pos表示词语在句子中的位置,dmodel为词向量的维度,i指词向量的位置。
先进模型(Relative-Transformer):受 Shaw等[24]工作启发,将本文基准 Transformer模型的绝对位置编码方式更改为相对位置编码(Rela⁃tive Position Representations)。该先进模型中,对于线性序列,边可以捕获有关输入元素之间相对位置差的信息,假设序列中两个元素间的相对位置距离超过最大值k是无效的,则相对位置编码可以表示为和。
先进模型(Graph-Transformer):本文使用当前AMR-to-Text生成性能最优的图到序列模型[25],其在基准Transformer模型的编码端对图结构进行建模。该先进模型在编码端对输入的线性化AMR图结构进行编码,如式(3)、(4)和(5)所示:

其中,h为编码端的隐藏层状态,αij表示权重矩阵,eij为连接两个节点vi和vj的边,γij向量表示图中节点vi和vj间的关系,WP、WR1、WQ、WK和均为模型参数。
2.2 子词化处理
神经机器翻译领域存在低频词翻译数据稀疏的问题。Konstas等[9]通过匿名化策略解决该问题,但此方法需要人工制定规则,成本较高。Song等[11]在charLSTM的基础上加复制机制解决低频词数据稀疏的问题,但由于模型需要学习从源端复制词汇,增加了模型复杂度。受神经机器翻译领域解决低频词翻译问题的启发,本文使用字节对编码(Byte Pair Encoding,BPE)[26]方法解决 AMR-to-Text生成中数据稀疏的问题。BPE方法可以将低频词汇单元拆分成小粒度的高频子词单元,在翻译前使用脚本对数据进行BPE处理,翻译后将结果去掉“@@”符号即可。该方法简单有效,不需对模型做任何修改。
2.3 线性化处理
本文借鉴Ge等[27]使用的方法对AMR图进行线性化预处理。该方法首先通过删除变量和wiki链接获得简化的AMR图,由于AMR图中的变量只是表示共同节点,本身不携带任何语义信息,因此再通过删除变量并复制共同引用节点,将AMR图转换为AMR树。最后用空格替换AMR树中的换行符得到AMR序列,实现AMR图的线性化转换。如图2为一个AMR图线性化序列。对于目标端的句子,本文使用斯坦福工具对句子进行分词化处理。

图2 AMR图线性化示例Fig.2 Example of linearization of AMR graph
3 实验
3.1 数据集
本文实验中使用LDC2017T10即AMR2.0标准数据集,数据集的规模如表1所示。数据集中的每个样例都由一个AMR图和其对应的句子组成。
本文使用的大规模自动标注数据集来自WMT14英语到德语翻译的news-commentrayv11,从该语料中获取其训练集的英文文本数据,共包含3 994 035英语句子。本文先使用AMR2.0标准数据集训练得到基于序列到序列的AMR解析模型,再根据解析模型在测试集的性能选取模型,最后将获取到的英语句子通过该模型进行解析得到对应的AMR图序列。
3.2 大规模自动标注语料的应用
参考徐东钦等[28]使用自动标注语料的方法,本文采取两步训练法训练模型。如图3所示,本文先将获得的大规模AMR-to-Text生成自动标注语料对模型进行预训练,其次根据预训练模型在AMR2.0开发集的结果选取模型;再使用AMR2.0标准数据集对所选的预训练模型参数进行微调优化,在微调时对模型的共享参数进行调整,例如,使用较低的学习率可以保留预训练时模型所捕获的一些语言特征信息,最后获取AMR-to-Text生成模型。特别地,在进行子词化处理时,将AMR2.0标准数据集与自动标注语料合并,且将操作数设置成20 000。

图3 基于大规模自动标注语料的两步训练法Fig.3 Two-step training method based on large-scale automatic annotation Datasets
3.3 模型设置
本文实验中所使用的Transformer模型参数参照文献[20]设置。模型中多头注意力机制设置为8,词向量和隐藏层大小设置为512维,批处理大小为4 096,以token为单位处理。本文在使用大规模自动标注语料预训练模型时,将模型学习率大小设置为2.0,在使用AMR2.0标准数据集对预训练模型微调优化时,学习率设置为0.25,模型的其余参数保持一致。先进模型(Relative-Transformer)中的相对位置距离最大值k设置为16。
3.4 评价指标
本文分别从BLEU值、候选词相似度和句子向量相似度对模型生成文本的性能进行比较。其中,使用BLEU测评工具[29]测试模型生成文本的性能。对于候选词的比较,本文先将模型中生成的每个单词的候选词概率从大到小排列,再获取该单词的前10个候选词,比较先进模型与基准模型对应的每一个单词的候选词并计算重复率。候选词重复率表示候选词相似度,相似度越高则表明模型间生成文本的性能差异越小。如式(6)中,b和h分别表示基准模型和先进模型产生的每个单词的候选词,n表示所取的候选词个数,此处取n=10。例如,假设“looking over to the flag.”为数据集目标端的一个句子序列。对于looking这一单词,从基准模型获取到的前10个候选词为“look,watch,like,i,voice,give,my,to,lost,and”,从先进模型获取到的前10个候选词为“looking,look,see,watch,gaze,glance,voice,lost,i,give”,其中,重复候选词为“look,watch,i,voice,give,lost”,则候选词相似度为
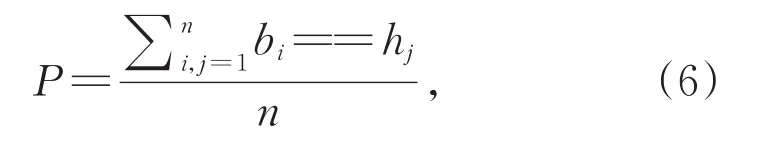
即P=60%。本文分别获取基准模型和先进模型产生的句子级向量其中,ti表示模型生成的词级别的向量,l表示句子序列的长度。对每个句子序列的词向量求平均来获得句子级别的向量,并对获取到的基准模型和先进模型的句子向量计算欧式距离。欧式距离越小则说明句子向量相似度越高,模型间生成文本的性能差异越小。
3.5 实验结果与分析
本文实验在AMR2.0测试集的BLEU值如表2所示。其中,None表示仅使用AMR2.0人工标注数据集训练模型,10%、20%、40%、60%、80%和100%表示分别从含3 994 035条样例的大规模自动标注语料中随机抽取相应比例预训练模型,再使用AMR2.0标准数据集对预训练模型进行微调。

表2 基于大规模自动标注语料BLEU值Table 2 BLEU value based on large-scale automatic labeling Datasets
观察表2基准模型和两个先进模型的BLEU值可知,在仅使用AMR2.0标准数据集时,Relative-Transformer先进模型与基准模型相差3.77,Graph-Transformer先进模型与基准模型相差6.82。而在使用了大规模自动标注语料时,两个先进模型与基准模型性能相当,没有显著差异。如使用了大规模自动标注数据集的20%作为预训练数据集时,Relative-Transformer与基准模型仅相差0.38,使用60%数据集作为预训练语料时,两个模型仅相差0.37。同样,在使用10%大规模自动标注数据集时,Graph-Transformer与基准模型仅相差0.16,使用80%数据集时,两个模型仅相差0.32。特别地,我们观察到,在仅使用AMR2.0的人工标注数据下,基于图结构的Graph-Transformer先进模型较本文基准系统取得更好的性能,然而,随着大规模自动标注语料的使用,本文使用的基于序列的基准模型和Relative-Transformer先进模型较图结构模型BLEU值提升更明显,由此可见复杂图模型在大规模自动标注语料情况下的优势变得不明显。
本文分别计算了两个先进模型与基准模型的候选词相似度。如表3所示,P1表示Rela⁃tive-Transformer先进模型与基准模型的候选词相似度,P2表示Graph-Transformer先进模型与基准模型的候选词相似度。

表3 基于大规模自动标注语料候选词相似度Table 3 Candidate word similarity based on large-scale automatic labeling Datasets
本文通过计算句子向量的欧式距离来比较两个先进模型与基准模型生成文本的性能。如表4所示,dist1表示Relative-Transformer先进模型与基准模型句子向量的欧式距离,dist2表示Graph-Transformer先进模型与基准模型句子向量的欧式距离。

表4 基于大规模自动标注语料句子向量的欧氏距离Table 4 Euclidean distance of sentence vector based on large-scale automatic labeling Datasets
表3和表4分别从候选词和句子向量角度探索先进模型和基准模型文本生成的性能差异,由实验结果可以看出,在大规模自动标注语料的基础上,先进模型与基准模型的候选词相似度和句子向量相似度均远高于仅使用标准语料时的结果。如表3结果所示,在使用了大规模自动标注语料时,Rela⁃tive-Transformer先进模型与基准模型候选词相似度均达到了60%及以上,而在仅使用AMR2.0标准数据集时,两个模型的候选词相似度仅为32.78%。表4中,在大规模自动标注语料的基础上,先进模型与基准模型句子向量的欧式距离均远小于仅使用人工标注语料时的距离。表3和表4同样验证了本文的结论,在大规模自动标注语料的基础上,先进模型与基准模型生成文本的性能差异大幅度缩小,先进模型性能优势不明显。
为了更充分验证本文得出的结论,即在大规模自动标注语料的基础上,先进模型性能优势不明显,与基准模型生成文本的性能没有显著差异。本文将上述实验中所使用的大规模自动标注语料的句子端通过性能更优的AMR解析模型进行解析,得到更高质量的AMR图序列,再使用该更高质量的大规模自动标注语料进一步基于上述实验的方法对本文结论进行验证。结果分别如表5−7所示。

表5 基于大规模高质量自动标注语料BLEU值Table 5 BLEU value based on large-scale high-quality automatic labeling Datasets

表6 基于大规模高质量自动标注语料候选词相似度Table 6 Candidate word similarity based on large-scale high-quality automatic labeling Datasets

表7 基于大规模高质量自动标注语料句子向量的欧氏距离Table 7 Euclidean distance of sentence vector based on large-scale high-quality automatic labeling Datasets
表5−7的实验结果同样说明在使用了大规模自动标注语料的基础上,先进模型的性能优势不明显,与仅使用AMR2.0标准数据集相比,先进模型与基准模型生成文本的性能没有显著差异。表5中,在使用了40%的大规模自动标注数据集时,先进模型Relative-Transformer与基准模型的BLEU值仅相差0.48。而在使用了10%大规模自动标注语料时,先进模型Graph-Transformer与的结果同样表明,在使用了大规模自动标注语料的基础上,先进模型与基准模型的候选词和句子向量相似度均高于仅使用AMR2.0人工已标注标准数据集的结果。
3.6 案例分析
观察表2和表5模型的BLEU值发现,本文使用了大规模自动标注语料对模型进行预训练后,不仅有效降低了模型间生成文本的性能差异,而且,三个模型的BLEU值均有大幅度的提高。表8分别对三个模型在仅使用AMR2.0标准数据集训练模型和使用含3 994 035条训练样例的高质量大规模自动标注语料基于两步训练法得到的句子文本进行展示。

表8 AMR-to-Text生成案例Table 8 Example of AMR-to-Text generation
观察表8中的结果可以发现,在仅使用AMR标准数据集训练模型时,三个模型生成的句子文本较输入的AMR图对应的标准句子文本误差较大,如先进模型Graph-Transformer在三个模型中生成的句子质量最高,但仍将标准结果中的“on land,on sea,and in the air”表示为“in land,sea and air”。而在先使用大规模自动标注语料进行预训练模型,再使用标准数据集对预训练模型进行微调优化后,三个模型生成的句子文本质量均有提高,例如先进模型Graph-Transformer对单词“land”正确使用了介词“on”表示。
4 结论
本文在大规模自动标注语料的基础上,探索AMR-to-Text生成任务的先进模型是否能够保持其性能优势。分别从BLEU值、候选词相似度和句子向量相似度比较了在使用大规模自动标注语料时,先进模型与基准模型生成文本的性能差异。实验结果表明,在大规模自动标注语料的基础上,先进模型与基准模型生成文本的性能没有显著差异,先进模型性能优势不明显。同时,本文基于大规模自动标注语料预训练模型的方法显著地提高了模型生成的句子文本质量。
