“用户兴趣—算法推断—内容呈现”模型*
——微博推荐流的运作机制探析
2022-08-12陈逸君
—陈逸君—
近年来,Google、Facebook、微博和今日头条等技术公司转型而来的“平台媒体”①(platish⁃ers)正在成为用户获取资讯的重要渠道。面对海量信息,即便平台媒体也无法将全部内容提供给所有用户,技术公司转而通过算法完成对内容的取舍与适配。然而,比起传统媒体时代以记者编辑为代表的“把关人”严格遵循组织机构一套章程标准②,平台媒体对信息的处理更像一个不可接近的“黑箱”③,商业秘密保护和防止恶意入侵是此类科技公司拒绝公布“把关”过程的常见做法。④
如若不能及时打开“黑箱”,也就无法对平台媒体的价值标准予以修正。目前,对Face⁃book、Twitter等西方平台媒体的运作机制,学界已积累了较为丰富的研究成果,而非西方语境下除少数面向今日头条⑤、微博热搜⑥的实证分析外,对平台媒体的解读大多基于主观判断,较少采用量化或田野调查的方式进行验证。本文选取微博“推荐流”作为平台媒体的代表,通过98名微博活跃用户的近10万条数据结合他们的问卷调查结果,揭示微博推荐流的核心运作机制。微博是中国社交媒体的超级平台之一,2021年微博月活跃用户达5.73亿,日活跃用户2.49亿⑦,网民通过微博获取新闻的比例达35.6%⑧,高于新闻客户端获取新闻的比例。作为中国舆论风向标的社交媒体,微博引入内容推荐的时间较早,其算法核心产品——微博“推荐流”,在经历数次代码迭代后也相对走向成熟。
一、算法推断:搭建从用户兴趣到内容呈现的新路径
如今人们身处高度可选择的媒介环境之中,用户拥有自由获取感兴趣内容的权利。相关研究也证明,兴趣主导了用户的信息选择⑨,网络化媒介为用户搭建起一个“兴趣决定内容”的信息世界(见图1的“直接模型”部分)。

图1 “用户兴趣—内容呈现”的直接模型和“用户兴趣—算法推断—内容呈现”的间接模型
随着平台媒体在讯息分配过程中占据主导地位,不具备预先获取用户喜好能力的平台媒体只能依托算法根据各类可挖掘、可计算和可测量的“数字痕迹”(digital trace data)对用户兴趣作判断。笔者将上述环节称为算法推断,并假设算法推断扮演了介于用户兴趣与内容呈现之间的角色。据此,构建“用户兴趣—算法推断—内容呈现”的间接模型,用户从原来“主动获取感兴趣内容”变为被动接收由“算法推断用户可能感兴趣的内容”(见图1中“间接模型”部分)。
传统观点认为,在信息自治的环境中,个人选择对内容呈现起决定作用,因此用户对什么感兴趣就会获取怎样的内容。平台媒体打破这一格局,伴随算法推断过程的介入,用户兴趣不再由用户的天然属性决定,而是外化为转评赞、停留时长等一系列可能被算法标记为有效计数的表征向量。那么此时算法判断的用户兴趣与用户的真实兴趣是否保持一致?如不一致,用户兴趣与算法推断谁决定了内容推荐?回答上述问题是“开箱”平台媒体运作机制的前提。
二、算法推断的影响因素
根据间接模型假设,决定内容呈现的未必是用户兴趣,而是算法推断的用户兴趣,那么又有哪些因素决定了算法推断?
用户的发布/转发、收藏和点赞行为数据是后台最易获取且可能被解读为用户对该内容感兴趣的信号。本文将上述用户产生的行为数据统称为用户自主行为,并猜测用户自主行为是算法推断用户兴趣的重要依据。
大量研究表明,个体倾向与那些具有相同社会人口特征⑩、行为/价值观的人交往并保持联系。根据用户好友的兴趣反推用户兴趣,这一思路已经证实被多个平台媒体所采纳,如一项针对Facebook公开专利的文本分析显示,其系统会从用户朋友发布的动态以及朋友的兴趣出发推断用户兴趣所在。同样作为社交媒体的微博,曾经在多个公开场合强调社交关系对于算法推荐的重要性。微博AI Lab资深算法专家张俊林表示,“亲密的社交关系往往蕴涵着潜在的兴趣关联”。本研究猜测社交关系是算法推断的另一个重要依据。
综上,笔者搭建了微博“推荐流”运作机制的完整模型(如图2所示)。首先是“用户兴趣—算法推断—内容呈现”部分(H1—H3),由于用户通过微博展现自我兴趣的空间有限、算法存在错误描绘用户肖像的几率,可能出现用户的真实兴趣与算法推断的用户兴趣不符的情况,因此提出:
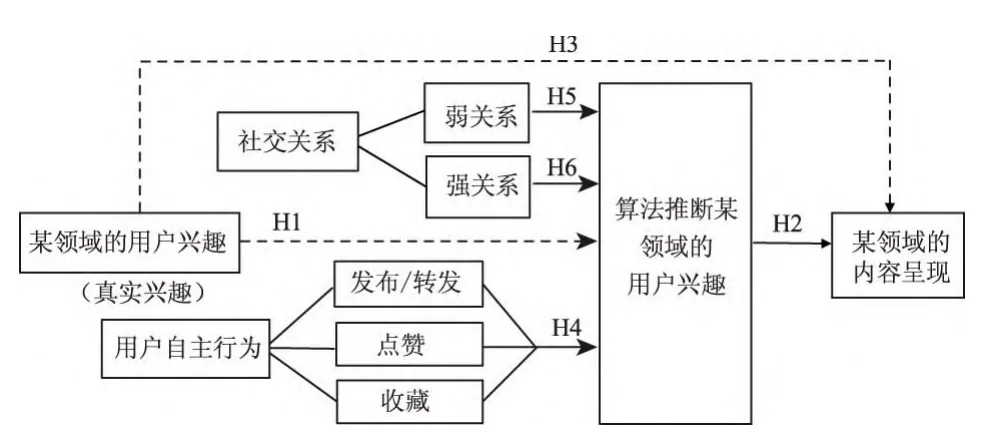
图2 “用户兴趣—算法推断—内容呈现”完整模型
H1.用户的真实兴趣与算法推断的用户兴趣并非在所有兴趣领域都呈现显著相关。
根据间接模型,算法参照“数字痕迹”对用户兴趣作判断后,“推荐流”依托算法推断而非用户的真实兴趣进行内容推荐,因此提出:
H2.算法推断某领域用户兴趣与某领域的内容呈现存在显著相关性;
H3.用户真实兴趣与内容推荐并非在所有兴趣领域都呈现显著相关性。
其次是算法推断的影响因素部分(H4—H6),猜测影响算法推断的第一个因素是用户自主行为,提出:
H4.用户对某领域内容进行的发布/转发、点赞和收藏,与算法推断用户对某领域的兴趣存在显著相关性。
猜测第二个影响因素是“社交关系”。格兰诺维特(Granovetter)将社交关系划分为“强关系”和“弱关系”,认为用户的关系强度体现在用户间的亲密程度和接触频率。本研究将微博中与用户相互关注的好友视作“强关系”,与用户呈现单向关注的大V则更符合“弱关系”,同时考察“强关系”与“弱关系”对算法推断的影响提出研究假设:
H5.与用户呈“弱关系”的人对某领域的兴趣情况,会显著影响算法推断该用户对相关领域的兴趣;
H6.与用户呈“强关系”的人对某领域的兴趣情况,会显著影响算法推断该用户对相关领域的兴趣。
三、研究方法
(一)数据与样本描述
本研究采用深度访谈、问卷调查与抓取98名微博用户的99476条数据相结合的方式,共同揭示微博推荐流的运作机制。出于数据隐私保护,微博不会向他人或机构展示任何用户的后台数据,尽管用户发布的内容、关注列表、点赞等信息作为公开数据可被直接获取,但本研究中最为关键的内容呈现即微博为用户推荐了什么是除用户外,任何人都无法获取的。面对内容呈现的采集困难,有学者采用问卷调查通过受访者“自我报告”(self⁃report)过去一周在平台媒体上看到有关某领域话题的频率(1=从不,5=经常)得到内容推荐的情况。鉴于不同受访者对频率的认知差异,这一形式易受主观因素干扰。本研究在征得用户知情同意的基础上获取他们的微博账号及密码,经由用户注册时绑定的手机验证后登录,通过八爪鱼抓取“推荐流”的实时内容,较好地避免了用户主观作答带来的不准确性。
自2020年10月至11月,笔者发动亲友并依托“滚雪球”的方式共征集108个微博账号,在排除非活跃用户后得到98名活跃用户的微博账号使用权(n=98)。分别于10月31日、11月1日、11月28日(三日均无重大事件,排除该时间段内微博集中推荐某类特定内容)登录账号,并对每个账号抓取包括:推荐广告(不少于50条)、热门推荐(不少于400条)、推荐关注的人列表(不少于100位)、转发/发布的微博(全部或不少于100条)、点赞(全部或不少于100条)、收藏(全部或不少于100条)和关注的人所发布的微博(不少于100条)。98个账号共抓取广告4971条、热门推荐38755条、关注的人15822位(其中与用户呈现“弱关系”11352人)、转发/发布的微博9561条、点赞4999条、收藏2569条、关注的人发布的微博11447条,共获得有效数据99476条。此外,所有用户完成一份问卷星平台的调查问卷。
在“推荐流”中大部分推荐内容和博主的兴趣领域都被微博打上了自带标签,笔者对微博中所有出现的标签进行记录,一共52类兴趣标签,按相同主题合并同类项后划分为9大类别(1=新闻消息类,2=金融科技类,3=教育卫生类,4=人文艺术类,5=娱乐明星类,6=娱乐产业类,7=体育竞技类,8=日常生活类,9=时尚美妆类)(见表1)。参照内容编码表对所抓取的98名用户数据进行编码后,按四分位数法将连续数据转换为等级资料,通过有序Lo⁃gistic回归分析证明各变量间的关系。
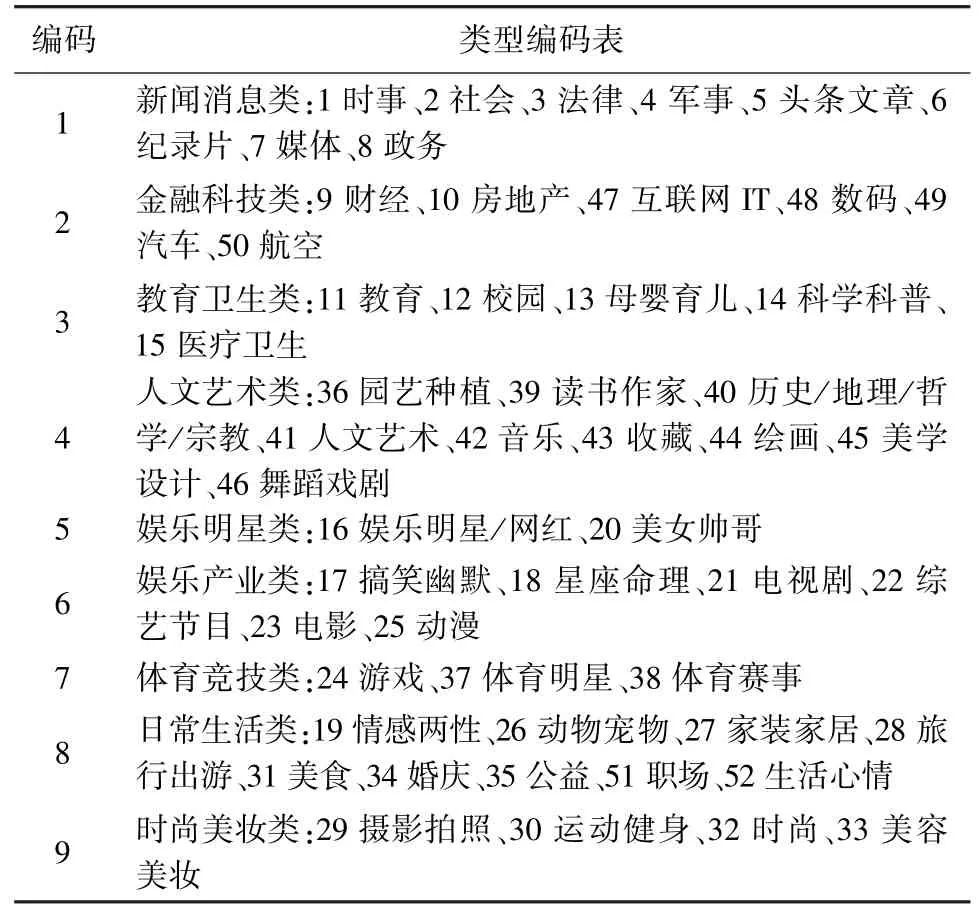
表1 微博内容编码表
(二)测量
1.问卷部分
(1)人口统计学
本研究调查样本来自98名微博用户,受访者中男性占48%,女性占52%。受访者的年龄段集中于26—30岁(SD=0.0774),受教育程度中位值为“硕士”。受访者主要为在校学生(37.7%)、专业技术人员(20.4%)和企业管理人员(19.3%)。
(2)用户兴趣
为测量用户对某领域的真实兴趣,调查问卷要求受访者对时事、社会、财经等不同领域的兴趣进行评分(采用五级量表测量,1=完全不感兴趣,5=非常感兴趣)。参照编码表将问卷中涉及的领域合并为9个类别,按四分位数法换为等级资料,从而得到98名用户对9个类别的真实兴趣情况。9个类别问卷Cronbach′sα系数值分别为0.82,0.76,0.68,0.84,0.67,0.81,0.75,0.82,0.84及总体量表的Cronbach′sα系数值为0.94。
2.用户数据部分
(1)算法推断
算法推断的过程与结果被严格保密,虽然无法从科技公司手中获取后台为不同用户打上的兴趣标签,但我们可以从其他途径得到启发。一项公开专利指出,为帮助广告商精准寻求潜在买主,扩大社交媒体的商业价值,微博主要根据当前系统为用户标识的兴趣标签来确定他们的广告主题。微博会把算法推断的结果用于广告投放,因此通过观察用户接收的广告类型,可逆向判断该用户被后台打上了什么兴趣标签。抓取用户的推荐内容并从中筛选出广告部分进行分类。
除了考察广告,“可能感兴趣的人”(后改名为“推荐关注”)是反映算法推断用户兴趣的另一途径。由于其推荐依据是“用户可能感兴趣”,因此通过观察“推荐关注”的类型,也可逆向判断该用户被后台打上什么兴趣标签。抓取每位用户的“推荐关注”并进行分类。
(2)内容呈现
内容推荐是微博“推荐流”在某个时刻呈现给用户的内容,抓取用户推荐流中的内容并进行分类。
(3)用户自主行为
微博可直接获取的用户自主行为包括:点赞、收藏和该用户发布/转发的内容,分别来自微博中“我的赞”“我的收藏”和“我的微博”。抓取上述内容进行分类。
(4)社交关系
本研究将与用户相互关注的人定义为与用户存在“强关系”。笔者在对98名用户匿名编号后随机抽取13名用户,登录其微博账号并手动记录每一位与该用户存在相互关注关系的好友的兴趣领域。微博会自动根据用户好友的关注列表生成一张他的兴趣领域分布图(见图3)。对每位用户所有好友的兴趣领域进行分类统计。
图3 微博为每位用户好友标识的兴趣领域
接着,笔者抓取每位用户的“关注的人”所发布的微博,手动排除非大V账号(转评赞数量均<5,粉丝数量<5000,且经验证不带大V认证的用户)后,获取的就是与该用户存在“弱关系”的博主发布的内容,同样对其进行分类处理。
四、研究结果
本研究旨在探讨微博“推荐流”的运作机制,并猜测它与互联网为用户搭建的“兴趣决定内容”这一高度自由的信息环境不同,用户从原来主动获取感兴趣的内容变为被动接收由算法推断用户可能感兴趣的内容。鉴于此,笔者在“用户兴趣—内容呈现”这一直接模型的基础上,建立了“用户兴趣—算法推断—内容呈现”的间接模型。本文首先对间接模型的猜想进行论证,其次探索哪些因素会对算法推断产生影响。
(一)“用户兴趣—算法推断—内容呈现”部分的论证
1.用户兴趣与内容呈现
问卷调查显示,41.8%的受访者表示“微博经常会推送一些用户不感兴趣的内容”。从受访者的主观作答中,可明显感知“用户兴趣”与“内容呈现”之间存在断裂。笔者以“用户兴趣”(即通过问卷获取的用户真实兴趣)为自变量,“热门推荐”作为因变量进行Logistic回归分析发现:9个类别中只有金融科技类(β=0.690,p<0.001)、娱乐明星类(β=0.945,p=0.009)和体育竞技类(β=0.912,p<0.001)的用户兴趣与内容呈现存在显著正相关性,其余6类的用户兴趣均与内容呈现之间不存在显著相关关系(如表2所示)。用户对某领域的真实兴趣与该领域的内容呈现不存在必然联系,H3得到验证。
2.用户兴趣与算法推断
如前所述,算法推断的测量方式有两种:一是根据用户的广告推送类别推测算法对用户兴趣的判断,二是根据微博“推荐关注”的分类来反映算法对用户兴趣的判断。笔者对这两种途径都进行了检验。在广告抓取过程中我们发现:第一,同一用户的广告内容存在大量重复,去重后每位用户收到的广告种类有限,现有广告类型不能全面地反映用户特征;第二,同一时段内不同用户都收到如“铂金钻戒”“兰蔻粉水”“防脱生发”等无差别广告投放,与原先设想的精准投放有所出入。
推荐流的非个性化广告投放也得到了多数受访者的验证。问卷调查显示,63.3%的受访者表示微博广告推送不太符合个人需求。统计结果也佐证了这一观点,以“用户兴趣”为自变量,受访者接收的广告作为代表算法推断的因变量进行Logistic回归分析发现:在用户接收的广告类型中,除金融科技类(β=0.563,p=0.003)和时尚美妆类(β=-1.461,p=0.007)外,其他7个类别的广告推送均与用户的真实兴趣无显著相关性。其中时尚美妆类的回归系数为负,说明即便对时尚美妆不感兴趣的用户,也同样可能会被投放化妆品、潮流服饰等广告,消费单品类广告已经成为推荐流中的普遍现象(见表3)。上述结果说明,用户的真实兴趣与广告推送的关联性不强。

表3 有序Logistic回归:用户兴趣与算法推断
为何会出现这一现象?在对新浪首席信息官王巍的访谈中,他承认“微博存在广告竞价”(2020年10月28日),广告的投放量与广告商的投入密切相关,这是造成无差别广告的重要原因之一。更微妙的是,2019年微博向美国证券交易委员会递交的财报显示,阿里巴巴目前作为微博的第二大股东,持股30.2%且拥有15.8%的投票权。因此不排除具有高度话语权的阿里系在广告投放过程中对微博施压。
一方面是微博“推荐流”并未完全根据用户特征来确定广告主题,另一方面目前所能收集到的广告类型十分有限,难以描绘用户完整的兴趣维度。鉴于上述原因,我们认为用户的广告分类并不适用于衡量算法推断,因此在本研究中笔者以“推荐关注”的分类情况作为反映算法推断的变量。“推荐关注的人”本质上就是基于算法推断的用户兴趣的结果,王巍也承认“用户(兴趣)标签是作为‘推荐关注’最为重要的依据(2020年12月15日)”。以用户兴趣为自变量,算法推断(推荐关注的人)作为因变量进行Logistic回归分析后发现:只有在体育竞技类(β=1.020,p<0.001)和时尚美妆类(β=0.735,p=0.022)中用户兴趣与算法推断之间存在显著正相关关系,其余7个类别均未表现出显著相关性(见表3)。这一结果说明,用户的真实兴趣与算法推断的用户兴趣之间存在一定的“间隙”,算法在判断用户偏好时可能出现误判,H1得到验证。
为何会产生误判?笔者根据问卷梳理了一些可能造成用户真实兴趣与算法推断用户兴趣差异的原因:人情面子(51.9%的受访者表示,更倾向浏览或为“与自己密切相关的人,如亲人或好友发布的微博”点赞)、微博的类型(54.1%的受访者对“娱乐八卦类的软资讯都不太点赞”;43.9%的受访者在看到体现社会价值、人生意义的微博时会转发点赞)和微博的实际效用(34.7%的受访者表示“看到教育培训相关的资讯会浏览收藏,以更好地应对升学和职场”;39.8%的受访者“会收藏深度好文以增加谈资”)都可能成为自身兴趣之外,用户转评赞等行为产生的原因,而正是通过“解读”这些行为,微博对用户兴趣的判断产生了偏差。
3.算法推断与内容呈现
在对算法推断和内容呈现进行Logistic回归分析后发现:所有9个类别即新闻消息类(β=0.422,p<0.001)、金融科技类(β=0.487,p<0.001)、教育卫生类(β=0.425,p<0.001)、人文艺术类(β=0.331,p=0.007)、娱乐明星类(β=0.523,p<0.001)、娱乐产业类(β=0.407,p=0.001)、体育竞技类(β=0.859,p<0.001)、日常生活类(β=0.616,p=0.002)和时尚美妆类(β=1.032,p<0.001)的算法推断均与内容呈现之间存在显著正相关关系(见表2),提示算法一旦判断用户对某领域感兴趣,那么用户将看到更多有关该领域的内容推荐,H2得到验证。
综上,笔者搭建了微博“推荐流”的“用户兴趣—算法推断—内容呈现”间接模型:用户的真实兴趣与算法推断的用户兴趣之间存在“间隙”(H1成立),算法推断某领域用户的兴趣与某领域的内容呈现存在显著正相关性(H2成立),用户的真实兴趣与内容呈现不存在必然联系(H3成立)。该模型说明,“推荐流”打破了“兴趣决定内容”这一传统认知,最终决定内容推荐的不是用户的真实兴趣,而是算法所推断的用户兴趣,并且“微博认识的你”与“你认识的你”之间存在差异。
(二)算法推断影响因素部分的论证
以算法推断为因变量,发布/转发、收藏、点赞三种用户自主行为作为自变量进行Logistic回归分析发现:所有9个类别中,除日常生活类(p=0.447)外,其他8个类别即新闻消息类(p=0.003)、金融科技类(p=0.001)、教育卫生类(p<0.001)、人文艺术类(p=0.001)、娱乐明星类(p<0.001)、娱乐产业类(p=0.003)、体育竞技类(p<0.001)和时尚美妆类(p=0.001)的用户自主行为均与算法推断呈现显著相关性(见表4),提示用户对某领域的发布/转发、收藏和点赞行为会影响算法判断用户对该领域的兴趣,证明用户自主行为是微博“推荐流”进行用户兴趣推断的重要依据,H4得到验证。
以“弱关系”为自变量,“算法推断”作为因变量进行Logistic回归分析发现:在与用户呈现“弱关系”的人发布的微博内容中,所有9个类别即新闻消息类(β=0.811,p<0.001)、金融科技类(β=0.527,p<0.001)、教育卫生类(β=0.395,p=0.003)、人文艺术类(β=0.415,p=0.001)、娱乐明星类(β=0.475,p=0.011)、娱乐产业类(β=0.646,p<0.001)、体育竞技类(β=1.075,p<0.001)、日常生活类(β=0.467,p=0.002)和时尚美妆类(β=0.635,p<0.001)与算法推断均存在显著正相关性(如表4所示)。可见当用户关注的大V发布越多有关某领域的内容时,算法越倾向于判断该用户也会对这一领域感兴趣,由此证明“弱关系”也是微博推荐流进行用户兴趣推断的重要依据,H5得到验证。

表4 有序Logistic回归:用户自主行为、弱关系与算法推断
最后考察“强关系”对算法推断的影响。在对98名用户进行匿名编号后,随机抽取其中13名作为样本(编号:11、26、27、28、30、31、32、39、41、42、46、51、53)。记录13个账号中每一位与用户存在“相互关注”的好友的兴趣领域。取每行频率最高的类别,组成该用户所有好友最感兴趣的项目列表。根据编码表将项目合并同类项,得到该用户所有好友在9个类别中最感兴趣的项目列表。重复此操作,获得13名用户的所有好友在9个类别中最感兴趣的项目情况并将其百分比化(如表5所示)。
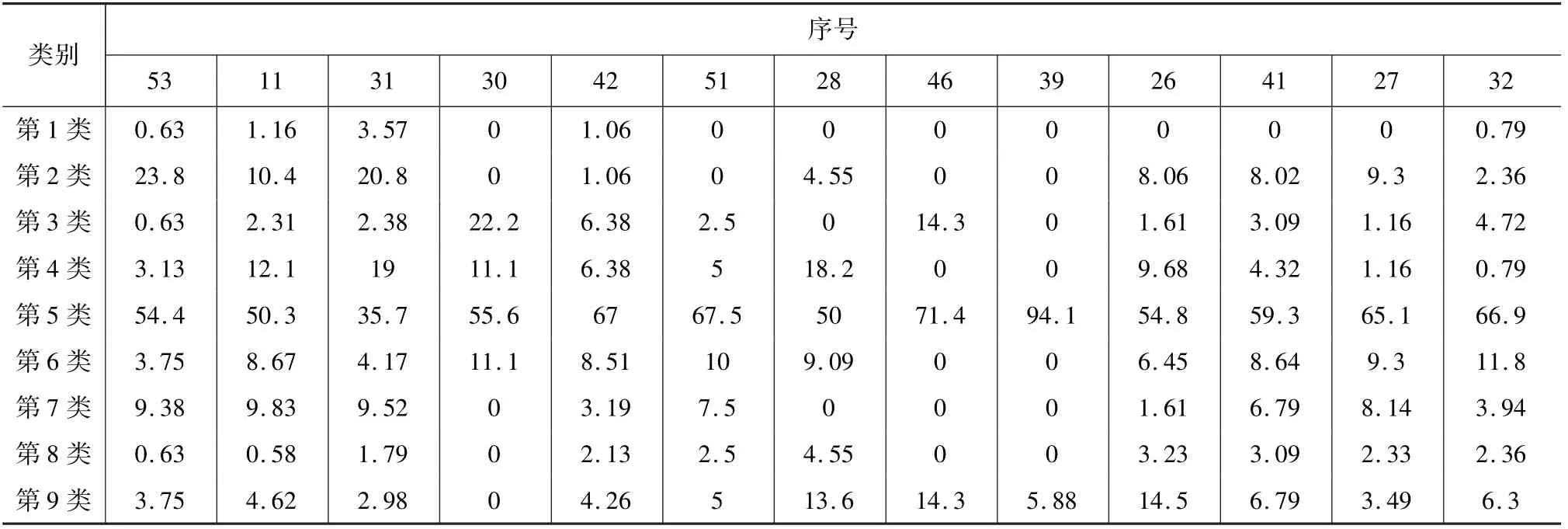
表5 用户好友的最感兴趣项目百分比统计表(%)
将用户好友最感兴趣的项目分类结果与算法推断进行相关性分析,结果显示:在与用户呈现“强关系”的人所最感兴趣的项目类别中,大部分类别与算法推断无显著相关性,只有人文艺术类(r=0.71,p=0.007)、娱乐明星类(r=0.63,p=0.022)和时尚美妆类(r=0.71,p=0.006)的用户好友最感兴趣的项目与算法推断存在显著正相关关系。此外,娱乐产业类(r=-0.56,p=0.048)中的用户好友兴趣与算法推断呈现显著负相关关系,说明即便用户好友对娱乐产业不感兴趣,系统仍然可能判定该用户对娱乐产业感兴趣(如图4所示)。可见,用户好友的兴趣与算法推断仅呈现部分相关性,H6不成立。
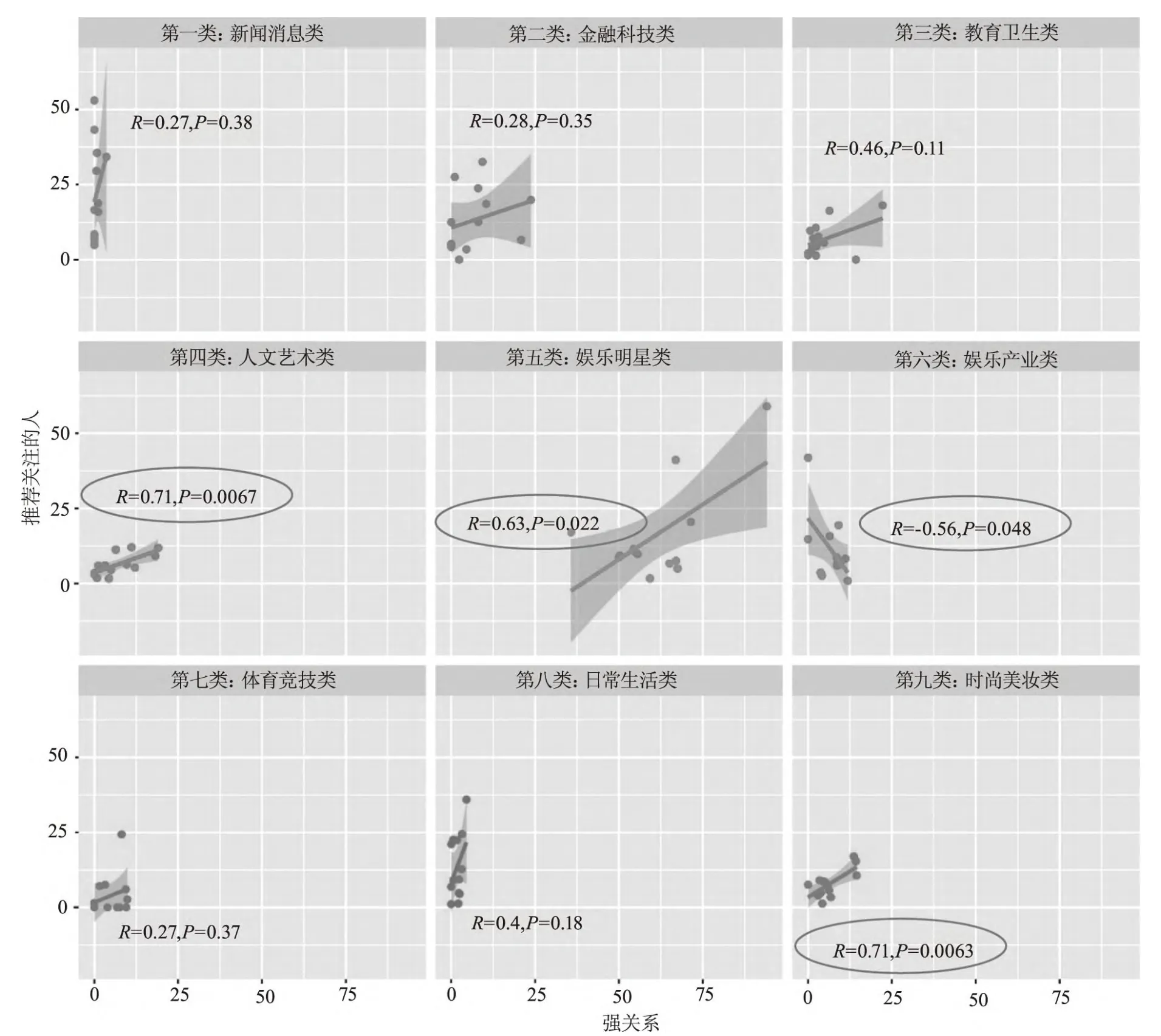
图4 用户好友(强关系)最感兴趣类别与算法推断的相关性分析
五、总结
本研究旨在考察微博“推荐流”的运作机制,在明确提出算法推断这一中间步骤的同时,对影响算法推断的各类因素进行了探究。根据分析结果可知。第一,微博“推荐流”打破了“兴趣决定内容”这一传统认知,决定内容推荐的不是用户的真实兴趣,而是算法所推断的用户兴趣。算法在判断用户偏好时可能出现误判,“微博认识的你”与“真实的你”之间存在差异。
第二,算法推断作为影响推荐流内容呈现的核心要素,同时受到社交关系和用户自主行为的影响。值得注意的是,在社交关系维度中与用户呈现“强关系”的亲友群组对于内容类别的喜好并未显著地影响算法推断,相反由大V构成的“弱关系”群组成为决定微博推荐流如何判定用户兴趣的关键。在微博眼中,那些具有较高领域权威的明星、名人、机构企业比起与用户关系密切的好友或大部分普通用户而言,更能影响甚至最终主导用户所接收到的内容。当领域权威成为用户获取内容推荐的重要参考指标时,“身份”“资本”和“权力”等现实社会中的划分方式,在平台媒体中被重新加以实践。这种基于“关键少数法则”(vital few rule)所进行的算法推断可能会进一步造成网络空间中对弱小声音、新声音的抹除。
需指出,由于微博账号的获取难度较大,本研究以98名用户和抽样的“强关系”作为研究样本,研究结果的代表性可能有限,更为确切的结论需要更大规模的样本予以支撑。
注释:
① Glick,J.Rise of the Platishers.http://www.recode.net/2014/2/7/11623214/rise⁃of⁃the⁃platishers.2014-2-7.
② Gieber,W.News Is What Newspapermen Make It.In A.Lewis&D.M.White,(Eds.),People,Society and Mass Communication.New York:The Free Press.1964.pp.160-172.
③ Diakopoulos,N.Algorithmic Accountability Reporting:On the Investigation of Black Boxes.Tow Center for Digital Journalism.https://academiccom⁃mons.columbia.edu/doi/10.7916/D8ZK5TW2.2014-2-12.
④ Pasquale,F.A.Restoring Transparency to Automated Authority.Journal on Telecommunications and High Technology Law,vol.9,2011.pp.235-256.
⑤ 王茜:《打开算法分发的“黑箱”——基于今日头条新闻推送的量化研究》,《新闻记者》,2017年第9期,第7-14页。
⑥ 王茜:《批判算法研究视角下微博“热搜”的把关标准考察》,《国际新闻界》,2020年第7期,第26-48页。
⑦ 每日经济新闻:《微博发布Q4及全年业绩:2021营收22.6亿美元 同比增长34%》。https://weibo.com/ttarticle/p/show?id=230940474 3007546245214.2022年3月3日。
⑧ 中国互联网络信息中心:《2016年中国互联网新闻市场研究报告》,http://www.cac.gov.cn/2017-01/12/c_1121534556.htm.2017年1月12日。
⑨ Strömbäck,J.,Djerf-Pierre,M.,Shehata,A.The Dynamics of Political Interest and Newsmedia Consumption:ALongitudinal Perspective.International Journal of Public OpinionResearch,vol.25,no.4,2013.pp.414-435.
⑩ McPherson,M.,Smith⁃Lovin,L.,Cook,J.M.Birds of a Feather:Homophily in Social Networks.Annual Review of Sociology,vol.27,no.1,2001.pp.415-444.
