基于双流残差网络的视频异常事件检测研究
2022-08-11王梓旭金立左苏国伟陈瑞杰
王梓旭, 金立左, 张 珊, 苏国伟, 陈瑞杰
(1.东南大学,南京 210000; 2.西安电子科技大学,西安 710000)
0 引言
随着深度学习相关理论的不断发展,基于计算机视觉技术的视频异常事件检测方法得到了积极的研究与探索,然而异常事件本身的多样性、模糊性和复杂性,使得该领域依然面临诸多挑战。尽管当前许多异常事件检测模型准确率较高,但是可用性较差,在目标密集、背景复杂或有遮挡的情况下效果并不理想。针对上述问题,近年来提出了许多基于深度学习的视频动作识别方法,主要分为两类,即基于3D卷积网络的方法和基于双流网络的方法。
2012年提出的3D卷积网络[1]直接同时提取空间和时间维度的特征。后来为了降低训练3D卷积网络的复杂性,又提出了如P3D[2],R(2+1)D[3]等卷积核分解以及FstCN[4],MiCTNet[5]等2D与3D卷积同时进行的方法。
基于双流网络的方法[6]将视频动作识别任务解耦为空间特征提取和时间特征提取两个子任务,从多个模态中提取视频特征,其又分为网络融合与视频长时序信息建模两个研究方向。网络融合主要负责关键时空信息关联,如文献[7]通过实验验证了时空特征关联性学习对于网络融合的重要性,有效的跨流交互方式能够提升双流网络的性能。视频长时序信息建模主要有以下3类方法:基于LSTM[8-10]的时空特征聚合;基于段的长时间序列建模,主要采用TSN模型[11],后衍生出TRN[12],TSM[13]等模型;基于时空卷积网络构建时序连接,如ST-ResNet[14]和MulResNet[15]通过引入一维的时间卷积构建时序连接,扩展了网络的时间建模能力。
本文针对人群暴动等公共场所异常事件,提出一种基于双流残差网络的视频异常事件检测算法。
1 检测算法介绍
本文所使用的双流残差网络结构如图1所示。

图1 双流残差网络结构图Fig.1 Structural diagram of two-streamresidual network
使用ResNet-34作为双流网络的基础网络,时间流网络的输入为LK光流法得到的连续多帧光流图。网络由特征提取块和特征融合块组成:特征提取块负责提取视频中的时空特征;特征融合块负责将高维时空特征进行融合,得到最终的检测结果。
图2为本文基于双流残差网络的异常事件检测算法流程图。该算法在网络训练时采用分段时序网络中稀疏视频帧采样方式,从15帧图像中每5帧随机抽取1帧RGB图像和2帧光流图像,分别输入空间流网络和时间流网络,使得网络能够处理更长时间的视频,充分提取视频中丰富的时序特征;同时,采用具有34层卷积层和全连接层的ResNet-34残差网络[16]作为双流网络的基础网络,通过加深网络深度,进一步扩展双流网络对长时间运动信息的建模能力;最后,在网络全连接层前将高维图像静态空间特征和光流图像时序运动特征进行融合,充分挖掘视频中的时空关联关系,并得到最终检测结果。
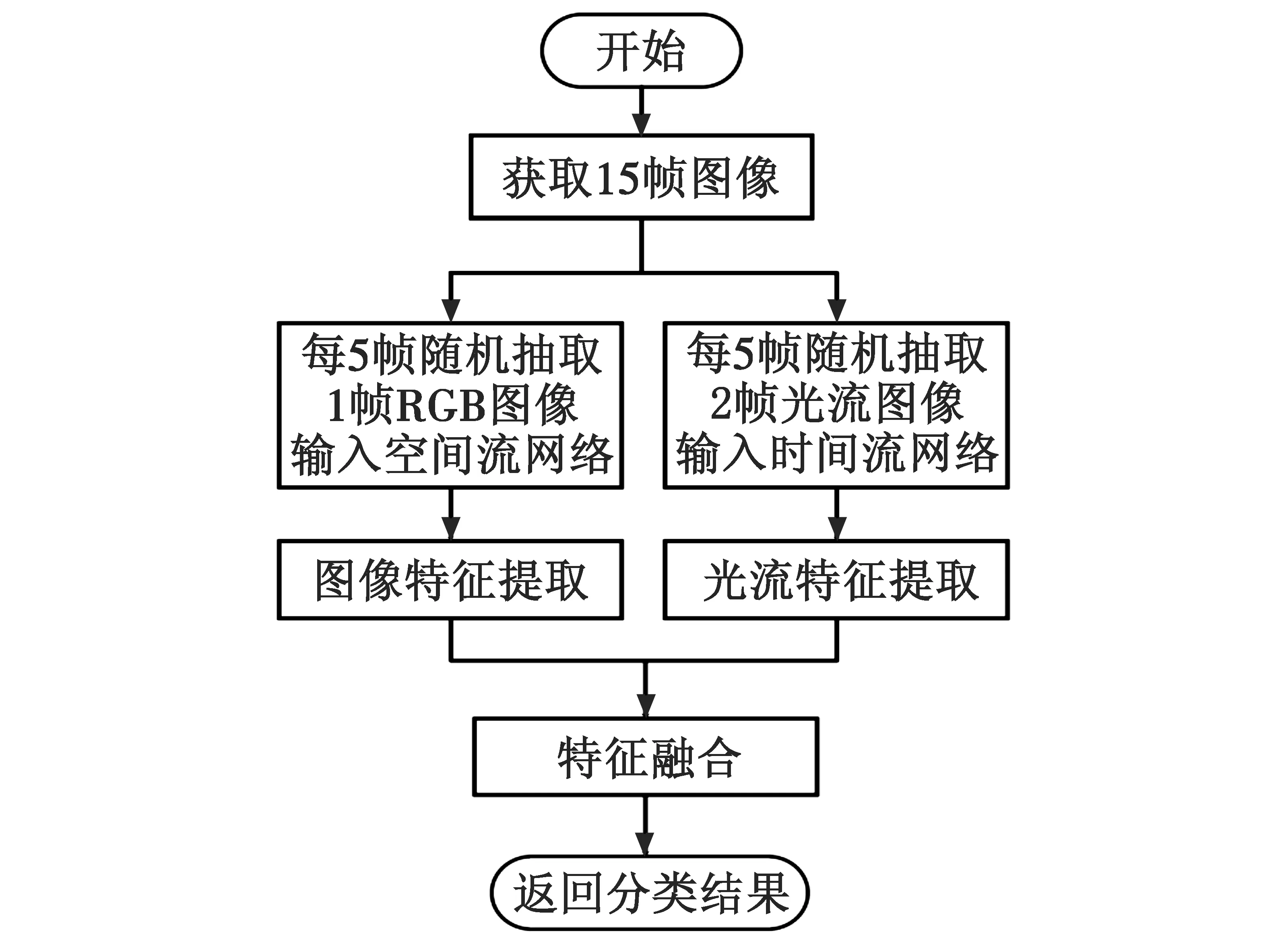
图2 基于双流残差网络异常事件检测算法流程图Fig.2 Flow chart of anomaly event detection algorithmbased on two-stream residual network
以下将从视频帧采样、特征提取和特征融合3个方面详细阐述本文算法设计思路和实现过程。
1.1 视频帧采样
事件检测系统通常处于长时间监控场景中,人群暴动等异常行为事件通常时间跨度较长,因此,视频帧采样方式对于视频中的长时序特征信息学习尤为重要。尽管采用视频帧密集采样方式对于长时序行为的识别效果较好,但是间隔较短的图像之间往往存在大量冗余信息,过多的网络输入数据使得训练成本大幅增加,并且在实际应用时也会导致检测过程耗时较长。因此,采样方式的选择应当切合实际,使网络能够充分学习视频中长时序特征的同时,尽可能减少网络输入数据,降低训练成本。
为了进一步提高训练速度,使网络能够充分学习长时序特征,本文借鉴TSN网络结构中的视频帧采样思想,采用分段采样方式从视频中抽取图像帧。相对于传统双流网络,TSN通过将整段视频分段然后采样的方式,每个片段都将给出其本身对于行为类别的初步预测,从这些片段的“共识”来得到视频级的预测结果[17]。这使得网络能够在保持合理计算成本的同时处理更长时间的视频,从而使得到的时序特征更加丰富,大幅提高了传统双流网络的性能。其中,分段采样的方式能够充分提取长时间尺度的时空特征,并且在一定程度上避免数据冗余。图3给出了视频帧采样过程,首先将视频分为3部分,然后从每一部分中随机抽样单个视频帧和2帧光流图像,分别作为空间流网络和时间流网络的输入。

图3 视频帧采样过程示意图Fig.3 Diagram of video frame sampling process
1.2 特征提取
HE等[16]提出的ResNet残差网络相比传统的CNN网络,网络深度更深且能够避免网络层数过多导致的网络退化问题,相比VGG-16等网络具有更好的性能,因此,本文将ResNet残差网络作为双流残差网络的基础网络,用于提取视频中的时空特征。
表1给出了ResNet-34的网络结构,其由33层卷积层和1层全连接层组成,在第1个卷积层conv1之后有1个最大池化层,第2~5层卷积层都由若干Basic Block残差单元组成,其个数分别为3,4,6,3,每个单元进行两次卷积操作,在第5层conv5_x之后有1个平均池化层和全连接层。

表1 ResNet-34网络参数
根据表1中的描述,可以将整个网络分为4部分,即conv2_x,conv3_x,conv4_x和conv5_x。其中,conv2_x中共有2个BasicBlock残差单元,此部分的输入与输出的通道数和特征图尺寸均相同,因此可以直接相加,无需在捷径分支(shortcut)中添加1×1卷积。而conv3_x,conv4_x和conv5_x中的输入与输出的通道数和特征图尺寸不同,因此需要在第1个BasicBlock残差单元中设置步长为2,将特征图缩小2倍,并且在捷径分支(shortcut)中添加一个1×1的卷积,使输入与输出的通道数能够匹配。
本文基于PyTorch搭建网络模型,空间流网络SpatialStreamNet和时间流网络TemporalStreamNet分别继承自torch.nn.Module,并分别在构造函数中声明所使用的ResNet-34网络,然后在forward方法中定义前向传播逻辑。而双流网络TwoStream-FusionNet同样继承自torch.nn.Module,在构造方法中声明空间流网络和时间流网络对象,并在forward方法中定义融合逻辑,将2个网络在conv5_x层后的输出结果进行卷积融合,经过池化、全连接后,输出Softmax得分。
ResNet-34最后经过平均池化层和全连接层后,Softmax输出的是1000维的向量,表示对于各个分类的检测概率结果。而本文重点针对人群暴动等5类公共场所异常事件,因此将全连接层的输出特征(out_features)设置为5,表示对于这5类异常事件的检测概率结果。
1.3 特征融合
融合方式和融合位置是影响时空特征融合结果的重要因素。早期针对双流网络融合的研究工作[7]讨论了不同融合方式对网络性能的影响,如最大值、加权融合等,研究表明,对空间流网络与时间流网络中高度抽象特征的关联性学习对于网络性能至关重要。因此,为了充分利用视频中的时空特征关联关系,本文借鉴了文献[7]提出的“堆叠融合法”和“卷积融合法”,在ResNet-34网络中较深的位置——conv5_x卷积层后将双流网络中的时空特征进行融合。
图4给出了特征融合原理图,在空间流网络和时间流网络中的conv5_x卷积层后加入1个大小为3×3×512,stride和padding均为1的卷积核。通过训练卷积核,使其能够学习到空间特征图和时间特征图之间的时空关联关系。

图4 特征融合模块原理图Fig.4 Schematic diagram of feature fusion module
特征融合计算过程如下。首先采用堆叠融合法,将两幅具有相同通道数的特征图进行堆叠,算式如下
(1)
(2)

然后采用卷积融合法,对堆叠融合得到的特征图ycat进行卷积融合,并加上偏置b,算式为
yconv=ycat*f+b
(3)
其中:yconv为卷积融合得到的特征图;ycat为堆叠融合得到的特征图;f∈R1×1×2D×D,为卷积核;b∈RD,为偏置常数。
2 实验验证分析
2.1 实验参数设置
1) 实验环境。
本文提出的视频异常事件检测算法模型在Ubuntu 20.04操作系统中采用深度学习框架PyTorch进行训练,利用GTX 1080Ti GPU加速训练过程。
2) 数据处理。
本文事先从UCF-Crime[18]和XD-Violence[19]数据集中提取并保存视频帧图像,同时采用LK光流法得到光流图像集合,训练时将图像和光流集合作为输入,从而避免训练时额外的视频处理操作。
在训练时,将视频分为3部分,从中随机抽帧进行训练。ResNet网络输入图像尺寸为224像素×224像素。空间流网络输入图像的张量尺寸可表示为(3,3,224,224),其中第一维表示分别从3段视频中抽取1帧RGB图像,输入图像数量为3,第二维表示输入图像的通道数为3。时间流网络输入的是两个随机抽取的视频帧堆叠到一起的光流图,其张量可表示为(6,2,224,224),其中第一维表示从3段视频中分别抽取连续两帧光流帧,输入图像数量为6,第二维表示光流帧由x和y方向的光流组成,通道数为2。
本文采用ResNet-34作为双流网络的基础网络,其中,空间流网络采用在ImageNet数据集上的预训练模型来初始化权重参数。
3) 超参数设置。
在网络训练时,采用随机梯度下降法(Stochastic Gradient Descent,SGD),动量系数(momentum)设置为0.9,批尺寸(batch size)设置为64,时期(Epoch)设置为250,初始学习率设置为0.001,通过PyTorch中的ReduceLROnPlateau方法调整学习率,当损失值不再降低或准确率不再提高时降低学习率,其函数参数mode设置为min来检测metric是否不再减小;factor设置为0.1,学习率到达该值后触发;patience设置为1,使得累计次数不再变化;cooldown设置为1,使得触发一次条件后,等待一定Epoch再进行检测。
4) 测试设置。
本文按照7∶3的比例划分训练集和测试集,在测试网络性能时,每10帧进行一次采样,并计算平均测试准确率Top-1和Top-5。
2.2 实验结果分析
本节对基于双流网络的异常事件检测算法进行仿真实验验证。实验采用 UCF-Crime 数据集[6],并将准确率Top-1、准确率Top-5作为模型的客观评价指标,分别探究了视频帧分段采样方式、特征融合方式、预训练初始化对双流网络性能的影响,并与传统双流网络进行了对比实验。
图5给出了实验过程中准确率的变化情况。
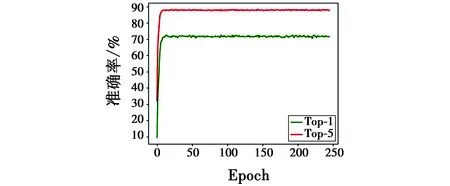
图5 网络识别准确率Fig.5 Network recognition accuracy
图6给出了UCF-Crime数据集中Fighting事件的视频图像帧和光流图像,以及模型的检测结果。从图6可以看出,光流去除了图像中的静态背景信息,从而能够有效描述动态运动目标的时序特征。将视频帧和光流图像输入网络,经过卷积融合后通过Softmax得到各异常事件的概率,从检测结果中可以看出,准确率Top-1的事件为Fighting事件,即检测结果正确。

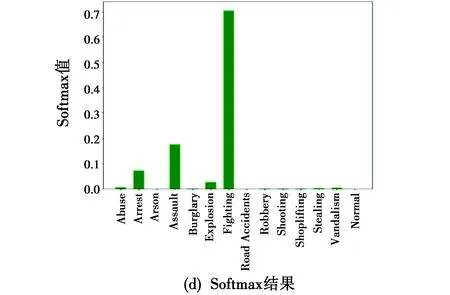
图 6 Fighting事件视频帧及检测结果Fig.6 Video frames and test results of Fighting
图7给出了本文算法模型在UCF-Crime数据集中对于各类异常事件的检测准确率。
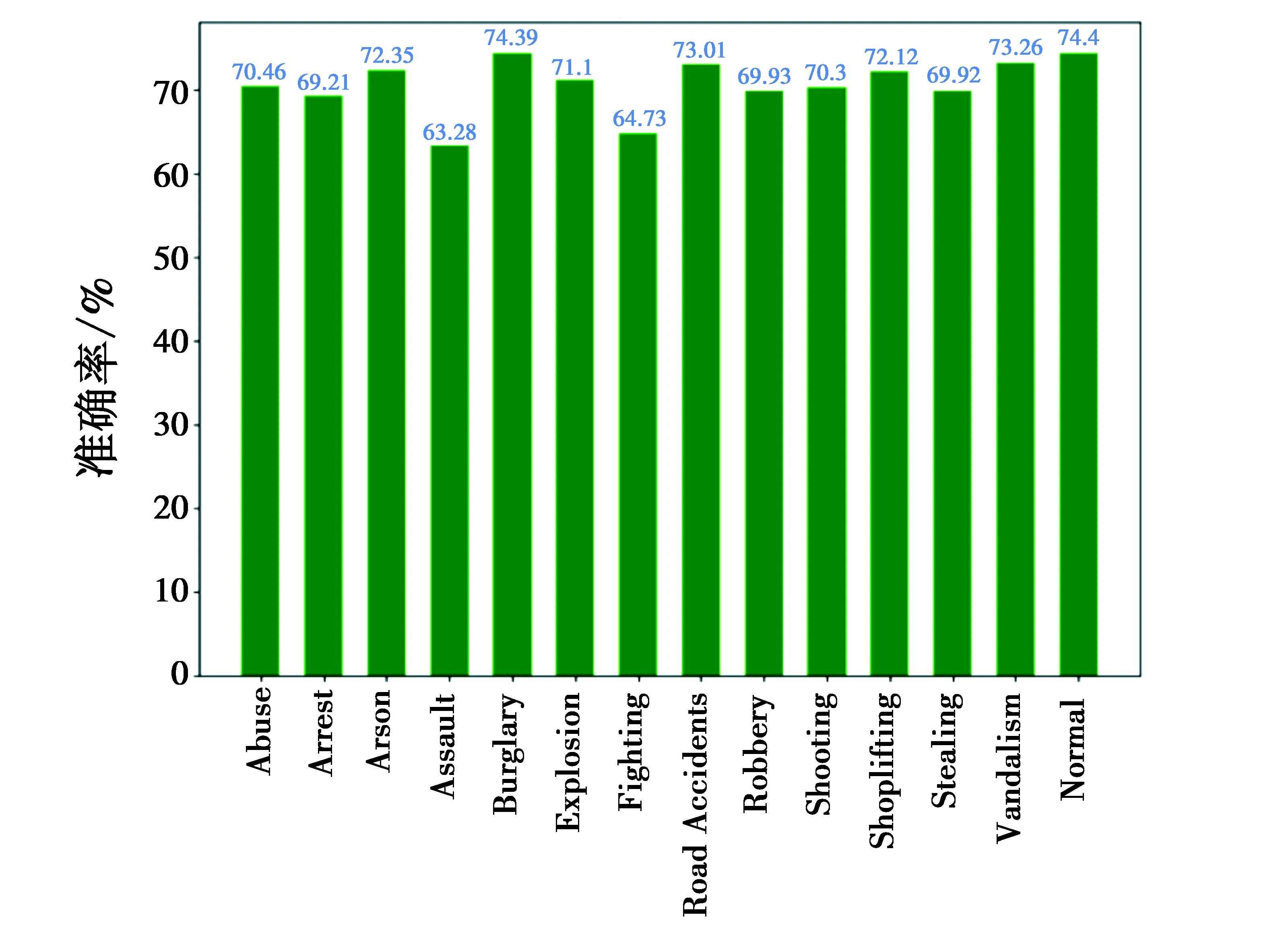
图7 各类异常事件准确率Fig.7 Accuracy of all types of anomaly events
从图7可以看出,大部分异常事件的检测准确率均在70%左右,而Assault,Fighting事件的检测准确率较低,主要原因是Assault事件和Fighting事件中目标的行为特征比较相似,容易引起混淆。
在验证分段采样方式对网络性能的影响时,当视频分段数在1~3时,其对应的双流网络准确率分别为71.6%,72.7%和73.6%。其中,对于分段数为1的情况,相当于传统双流网络中的单帧采样方式,即从整个视频片段中提取一帧图像作为空间流网络的输入。从实验结果中可以看出,采用更加密集的视频帧采样方式来获取视频的长时序特征信息是比较有效的方法。
表2给出了特征融合方式对网络性能的影响情况,分别采用加权融合、最大值融合和卷积融合3种方式对双流网络提取的图像特征和时序特征进行融合。其中,传统双流网络采用的是平均值融合方法,即权重为1∶1的加权求和融合方法。
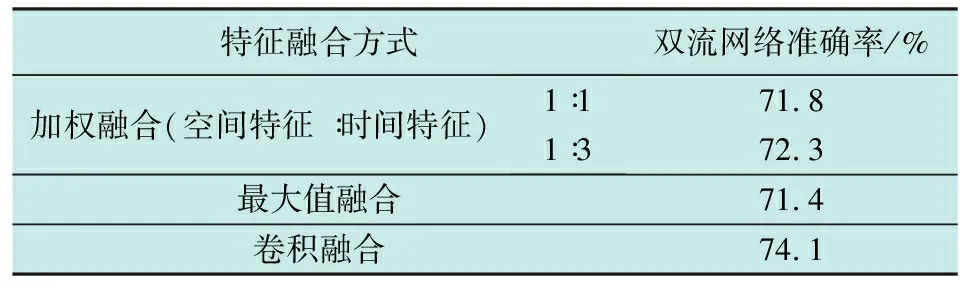
表2 特征融合方式对网络性能的影响
从实验结果中可以看出,采用卷积融合方式的模型准确率较高,主要原因在于卷积核经过训练能够学习到2幅特征图之间的关联关系,使视频中的时空特征得到充分融合。
表3给出了算法模型准确率对比结果。其中,本文网络模型在传统双流网络的基础上,采用分段视频帧采样方式进行训练,将 ResNet-34 残差网络作为双流网络的基础网络,最后采用卷积融合方式进行特征融合。

表3 算法模型准确率对比结果
从表3可以看出,本文基于ResNet和卷积融合的双流网络模型相比单模态网络(即空间流网络和时间流网络)和传统双流网络具有更好的性能;在UCF-Crime与XD-Violence数据集上,与本文空间流网络相比,准确率分别由65.3%和60.7%提升至74.2%和71.3%,各提升了约10%。
3 结束语
本文提出了一种基于双流残差网络的视频异常事件检测算法。首先分析了视频异常事件检测任务的解决思路,并从视频帧采样、网络深度和融合方式3个方面分析了视频异常事件检测任务的解决思路,在传统双流网络的基础上进行改进;然后详细阐述了本文视频异常事件检测算法的网络结构和流程,通过分段视频帧采样方式充分提取长时间尺度的时空特征,将双流网络的基础网络替换为深度更深的ResNet-34网络,并基于卷积融合方式实现双流网络中时空特征的交互融合;最后为验证算法有效性,进行仿真实验,将本文所提算法与传统双流网络进行实验比较。实验结果证明,本文采用分段采样方式训练的、基于ResNet残差网络和卷积融合的双流网络模型相比传统双流网络具有更好的性能。
