面向小目标检测的改进YOLOv3算法
2022-08-11徐思源储开斌冯成涛
徐思源, 储开斌, 张 继, 冯成涛
(常州大学,江苏 常州 213000)
0 引言
近年来,无人机以其灵活机动、操作简单等优点在军事和民用领域迅速发展,伴随着无人机技术的日益成熟,无人机的应用场景也不断增加,同时也促进了许多现代技术与无人机技术的融合,无人机加目标检测也是当前的热点方向。
传统的目标检测算法,如VIOLA等[1-2]提出的基于滑动窗口的VJ检测器等,算法冗余,且设计窗口时还需要考虑物体长宽比,手工设计的特征鲁棒性较差,效率低下,不适用于对实时性要求较高的检测任务。而基于深度学习的目标检测算法主要分为Two-stage和One-stage两种。Two-stage代表性算法有R-CNN[3],Fast R-CNN[4],Faster R-CNN[5]等,其特点是生成的锚框会映射到特征图的区域,然后将该区域重新输入到全连接层再进行分类和回归,每个锚框映射的区域都要进行这样的分类和回归,会耗费大量的时间;One-stage代表性算法有YOLO[6],SSD[7],YOLOv2[8],YOLOv3[9]等,与Two-stage的不同在于锚框是一个逻辑结构,只需对这个数据块进行分类和回归即可,因此拥有更高的检测帧率。但是YOLOv3对小目标的识别能力有限,目前已有许多学者对此展开了研究:由ZENG等[10]提出的改进型YOLOv3模型充分利用浅层网络,在第2次下采样后额外引出这一层的特征图,并与上一个尺度中特征图进行拼接,增加一个小目标检测能力更强的尺度,提高对小目标的检测能力;戴伟聪等[11]利用YOLOv3进行单目标物体检测时,对特征提取网络进行裁剪,另根据数据集特性对网络结构进行调整,使改进后的YOLOv3 模型检测精度与速度都有所提升;文献[11]还指出,简单的卷积神经网络模型具有更好的泛化性,尤其是在数据集较小、数据复杂多变的情况下,且YOLOv3参数量大,在较小数据集的检测任务中容易过拟合。
针对YOLOv3对高空视角下的小目标检出率低、检测精度差的问题,本文提出了一种在高空视角下基于YOLOv3的小目标检测改进算法。改进算法在提升小目标检测精度的同时,帧率无明显下降,保证了网络检测的实时性。
1 YOLOv3概述
YOLO算法最初是由REDMON等于2015年提出的一种基于回归的目标识别方法[6]。YOLO算法只需要做一遍前向运算即可对多种物体进行检测,将目标识别转化为回归任务来解决,以端到端的方式极大地提高了计算效率,绕开了候选区域的生成与评估,使得YOLO系列算法的检测速度很快。
YOLOv3主体部分是由特征提取网络与多尺度检测器两部分组成,其特征提取网络结构如图1所示。
特征提取网络主要用于提取图像特征,而多尺度检测器在特征提取网络的基础上进一步抽象和融合后得到3个尺度的预测特征,在3个尺度上进行检测,最终输出图像中的物体类别与检测框坐标。
在YOLOv3算法中,将一幅图像划分成S×S个网格,如果待检测目标存在于某网格中,那么此网格就负责检测该目标。每个网格负责检测B个预测框信息,具体包括5个信息,即x,y,w,h,Cdeg,其中,(x,y),w,h分别代表预测框的中心坐标与宽高值相对于所在网格的相对值,Cdeg为置信度,算式为
Cdeg=Pr(Obj)*IoU
(1)
式中:Pr(Obj)表示该网格中是否存在待检测物体,存在为1,不存在为0;IoU为预测框与真实框的交并比。
YOLOv3的目标损失函数由坐标预测损失、置信度预测损失、类别预测损失3部分组成。其中,置信度预测损失和类别预测损失均由YOLOv1,YOLOv2的误差平方和改为对于类别以及置信度预测效果更好的交叉熵。损失函数为
(2)
式中:I为网格中的第I个锚框;C为物体的真实值;classes为不同物体的分类。
相较于其他算法,YOLOv3的网络参数更少、检测速度更快,更适合在计算资源有限、实时性要求更高的无人机平台上应用。但YOLOv3对浅层网络利用不充分,对于高空视角下出现的小目标存在检测精度低、检出率低的问题。本文从两个方面着手,在提升小目标检测精度的同时减小网络计算量,达到与原始YOLOv3相近的帧率。
2 改进的YOLOv3小目标检测
2.1 基于K-means的锚框聚类
K-means是机器学习中的非监督学习,是一种典型的基于距离的聚类算法,该算法将相似的数据划分为一个集合或称为“一簇”。YOLOv3模型是基于锚框尺寸微调实现对边界框预测的,其在COCO数据集上得到了9个初始的锚框,并平均地分给3个尺度,用于加强模型对不同大小目标的检测能力。其中,小尺度的特征图对应大的锚框,大尺度的特征图对应小的锚框。
但是,由于所有的锚框尺寸都是在COCO数据集上聚类计算得到的,并不一定适用于其他数据集(如本文的飞机遥感数据集)的尺寸,因此需要对锚框尺寸进行重新聚类。本文测试了4~16个聚类中心对应的平均IoU,结果如图2所示。可以发现,平均IoU随着聚类中心个数的增加而提升,这表明增加聚类中心的个数能提高锚框与数据集标注的一致性。但是过多的聚类中心也会让网络的计算量增大,从而影响检测的实时性。本文选择在曲线变平缓的区间内选择网络的聚类中心个数,因为在这一区间锚框数量的增加对于平均IoU的提升幅度开始减小,继续增加锚框数量反而会影响检测速度,另外,考虑到本文将原有YOLOv3的3个输出尺度改进为4个,所以聚类中心个数最好是4的倍数,使得锚框平均地分配在4个尺度上。综合考虑以上因素,本文选择12个锚框,并对本文的训练集进行重新聚类,得到的12个锚框尺寸分别为(14×29), (20×34),(21×47),(28×43),(26×54),(27×66),(34×56),(33×72),(41×70),(36×87),(47×89)和(57×113)。

图2 不同的聚类中心数量对应的IoU变化Fig.2 IoU changes with the number of cluster centers
2.2 特征提取网络改进与多尺度输出
卷积神经网络在结构上的特点是,最开始浅层网络卷积得到的特征图较大,维度较小,随着网络越来越深,特征图会越来越小,维度较大。因此,在卷积神经网络中,浅层网络主要用于提取待检测目标物体的细节特征,每个像素点对应的感受野重叠区域较小,能保留更多的小目标信息,而深层特征图反映的是抽象的语义信息,主要用来检测大目标物体。
为了提升对小目标的检测能力,本文进一步充分利用YOLOv3浅层网络,设计的网络结构如图3所示。初始YOLOv3的特征提取网络由5次下采样组成,每次下采样后的残差块分别为1,2,8,8,4,本文继续沿用这一经典的特征提取结构,但是对残差块的数量进行重新配置,在小目标信息更丰富的第1,2次下采样各增加1个残差块,从而使浅层卷积层的特征提取更加充分。第3,4次下采样因为不涉及到小目标尺度,为了使模型能更好地适应小数据集,拥有更好的泛化性,残差块数量减少为4,6。第5次下采样保持不变,依然设置为4个残差块。
除了改进特征提取网络的小目标提取能力,本文还利用到了更多小目标信息。从第2次下采样引出一个特征图输出,并与上一个尺度融合。相比于拼接前,特征拼接后待检测目标的细节信息更加丰富。
卷积网络参数Ppara算式为
Ppara=(Kh*Kw*Cin)*Cout+Cout
(3)
式中:Kh与Kw分别为卷积核的高和宽;Cin与Cout分别是输入通道数与输出通道数。改动浅层网络对网络总参数的影响较小,所以本文在特征提取网络上修改对帧率的影响也较小。

图3 改进后的框架可视化结构图Fig.3 Visualization structure of the improved framework
3 实验对比
3.1 测试环境
本文实验所采用的操作系统为Ubuntu18.04,GPU为NVIDIA GeForce RTX3090,以及Python3.8.5,Open CV3.4等工具包,采用的深度学习框架为Darknet。
3.2 算法对比和检测可视化
本文采用平均检测精度PmAP、精确率P、召回率R、交并比IoU、帧率以及F1作为检测模型的评价指标。其中
(4)
P=PT/(PT+PF)
(5)
R=PT/(PT+NF)
(6)
式中:PT为真正例,PF为假正例,NT为真反例,NF为假反例;Nclasses为类别个数;PclassAve为不同类别的平均精度。
(7)
式中:X表示预测框;Y表示真实框。
(8)
本文使用遥感飞机数据集UCAS-AOD[12],共900幅遥感飞机图像,其中,700幅用于制作训练集,200幅为测试集。训练过程中损失函数可视化图如图4所示。
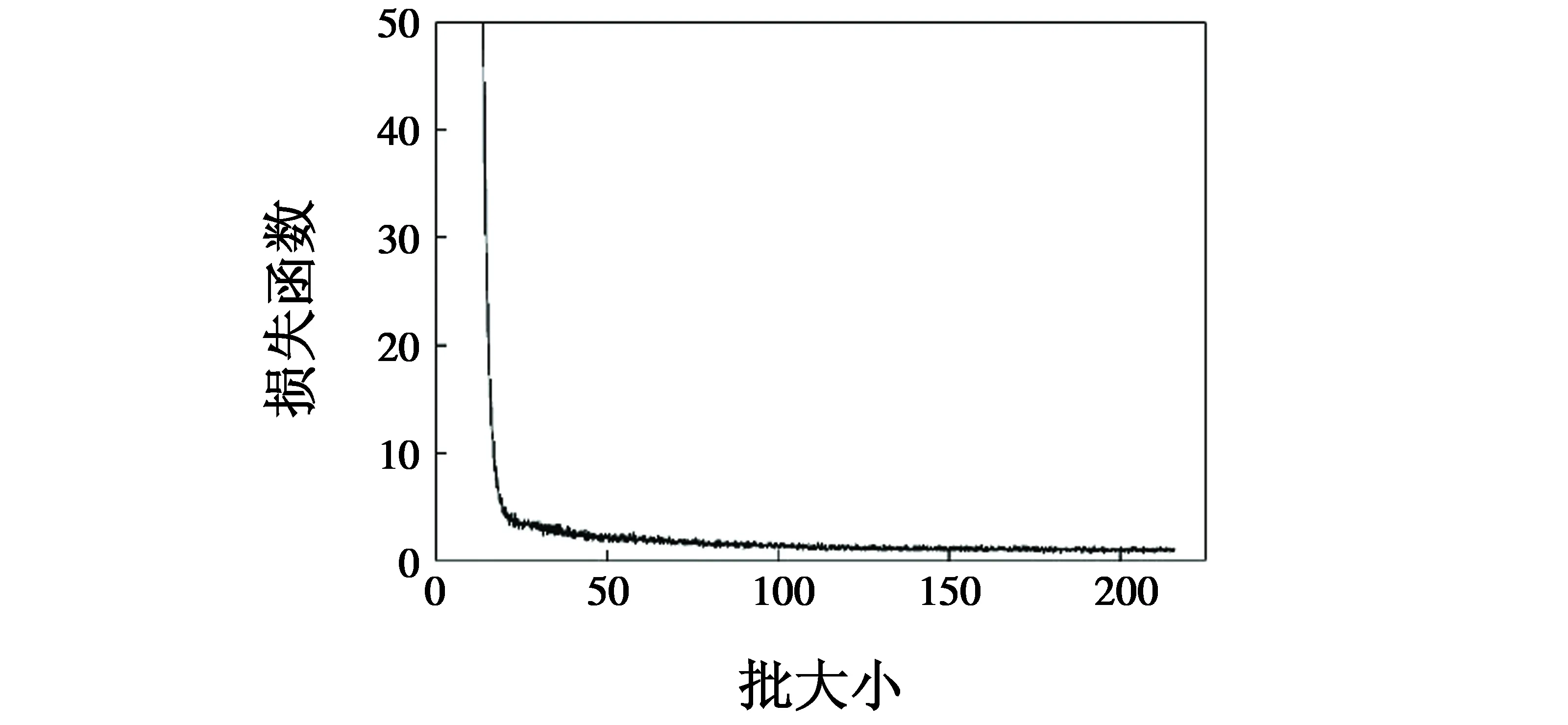
图4 模型训练中的损失函数可视化图Fig.4 Loss visualization in model training
表1对比了本文算法和YOLOv3以及一个未对特征提取网络做改进,但使用了与本文相同的4个尺度输出思想的文献[13]算法。

表1 3种检测算法对比
可以看出,本文算法因为对特征提取网络中浅层网络使用了更多的残差块,保留了更多的小目标信息和边缘信息,除帧率指标外对比其他两种算法都有提升。其中,mAP的提升最大,对比YOLOv3提高5.84%。除帧率稍低于YOLOv3外,各项模型评估指标都有提高,帧率有略微的降低是因为模型加强了小目标检测能力的同时,增加了一个完整的输出尺度,不可避免地加深了网络,使得总参数量增加,降低了模型的检测速度。但是因为本文算法简化了特征提取网络,使其实时性下降得并不明显,对比YOLOv3帧率仅下降1.3帧/s。
为验证本文算法对小目标检测能力的提升,将其与原YOLOv3算法、文献[13]算法对测试集部分图像做可视化检测,如图5所示。

图5 3种算法检测结果对比
在图5所示3组图像中,共含有待检测目标16个。图5(a)为YOLOv3的检测结果,漏检数为6,可以看出YOLOv3对于部分小目标会出现比较严重的漏检;图5(b)为文献[13]算法的检测结果,漏检数为4,相较于YOLOv3有提升但不明显,对于靠近登机桥的目标仍然会出现漏检,原因是其仍然沿用原YOLOv3的特征提取网络,即使从浅层网络引出输出尺度,检测效果提高的程度也很有限;图5(c)为本文算法的检测结果,没有出现漏检的情况,验证了改进特征提取网络并从浅层网络引出输出尺度,可以有效提升YOLOv3对于小目标的检测效果。
为验证本文算法的泛化性,选用了4类低质量图像做测试,共含有待检测目标20个,检测结果如图6所示。图6(a)为YOLOv3的检测结果,漏检数为2且模糊环境图左侧出现了误检;图6(b)为文献[13]算法的检测结果,漏检数为1;图6(c)为本文算法的检测结果,漏检数为0。实验证明本文算法有更好的泛化性,在恶劣环境下、图像欠曝光和过度曝光等情况下的检测任务中也有更好的表现。
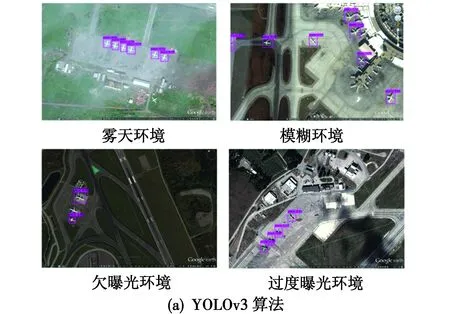


图6 3种算法在低质量图像上的检测结果Fig.6 Detection results of three algorithms on low-quality images
4 总结
本文针对原有YOLOv3特征提取网络进行改进,重新配置每次下采样残差块数量,并且在输出端融合一个浅层的尺度特征以获得更多小目标信息,用于遥感图像中飞机小目标的检测。在数据集UCAS-AOD上的实验表明:本文算法相比YOLOv3在检测速度几乎不变的情况下,大幅提升了检测精度,同时对于特殊场景下的图像(雾天、模糊、欠曝光、过度曝光)也有很好的检测效果。
