GAN网络的红外与可见光图像融合方法研究
2022-08-11刘砚菊宋建辉刘晓阳
刘砚菊,崔 洁,宋建辉,刘晓阳,池 云
(沈阳理工大学 自动化与电气工程学院,沈阳 110159)
图像融合是指对两个或多个图像传感器获得的互补或冗余图像信息进行集合的过程,以得到清晰度高和信息丰富的融合图像,为后续的图像目标定位、识别、检测等提供支持[1]。红外传感器是利用物体发射的红外辐射成像,可以在光照条件较差时反映出隐藏目标,但红外图像无法表现细节信息,图像的清晰度较低;可见光传感器是利用物体的反射光成像,可见光图像具有丰富的细节信息,但在光照条件不好的情况下无法获得清晰图像。将红外与可见光图像进行融合,能够保证得到的融合图像目标清晰且突出、纹理细节清晰,能够增强对场景的理解,便于准确识别目标,利于系统全天候工作。
在红外与可见光图像融合过程中,将图像分割为目标图像和背景图像,再采取不同的损失函数分别对目标图像和背景图像进行融合,既可以突出目标又可以保留背景信息。常见的传统图像语义分割包括阈值分割方法、区域分割方法、边缘分割方法[2]。传统的分割方法提取的是图像的大小、纹理、颜色等低级语义,在复杂环境中的应对能力和精准度都不够。近年来,基于深度学习的图像语义分割方法越来越多[3]。在图像分割领域中,语义分割可以将目标图像从源图像中分割出来,将目标转换为带有语义信息的掩膜。Long J等[4]提出的全卷积神经网络在卷积神经网络的基础上,将网络中的全连接层替换为上采样,使输入的图像可以为任意大小,但随着网络层次的逐渐增加,图像丢失原图中的空间结构信息,使分割结果不够精准,输出图像模糊。Yu C等[5]提出双向分割网络BiSeNet,该网络包含的空间路径结构解决分割图像的空间信息缺失问题,包含的上下文路径结构解决感受野缩小的问题,但模型中含有的U形结构在高分辨率特征图上引入额外的计算,会降低模型速度。Lin G等[6]使用链式残差连接网络(Re-fineNet),在解码器结构中加入金字塔池化模块,形成的远距离残差连接能将底层和高层语义特征采用上采样进行融合,由于中间结果均为分辨率很大的特征图,训练和推理过程对内存的要求很高。Chen L C等[7]提出Deeplabv3+,采用编码解码网络结构,加强了图像边缘分割效果,优化了分割后图像完整性。
常见的传统红外与可见光图像融合方法较多,包括多尺度变换法、稀疏表示法、小波变换法等[8],传统方法对图像进行多尺度分解,将图像分为不同频率的区域,再进行区域的区分和筛选融合,该方法在方向性上有较大限制,对边缘特征提取不足。随着深度学习的广泛应用,程永翔等[9]将卷积神经网络首次应用于红外与可见光图像融合,输入源图像分别由不同类型传感器获得,同一位置像素值强度可能差别很大,直接采用空间域的像素融合效果不好。Li H等[10]利用VGG-19作为特征提取器对分解后的图像进行特征提取与融合,该方法虽然有利于得到细节丰富的融合图像,但对输入图像要求较高,需预先配准对齐。He K等[11]提出残差网络(RestNet),其模型简单且易于优化,但模型容易发生过拟合问题和梯度消失问题,导致反向传播无法进行。Li H等[12]提出了密集融合(DenseFuse),可根据不同的情况设计灵活的融合策略将编码后的特征进行融合,缺点是此方法使用密集连接块进行图像特征提取与复用,存在信息丢失的问题。 Goodfellow I J等[13]提出生成对抗网络(Generative Adversarial Network,GAN),其通过生成器与判别器协同训练产生融合图像,无需预训练,网络的训练和测试均直接在融合图像的数据集上进行,可以更好地保留融合信息。
为使融合后的图像目标对比度更高,背景细节信息更多,本文提出基于GAN网络的红外与可见光图像分割后融合方法,既可解决背景信息不足的问题,也可解决融合后目标图像不清晰的问题,使得融合后的图像背景细节纹理清晰、目标突出、视觉效果更好。
1 GAN网络的图像融合
为使融合图像既有突出的目标又有细节信息更丰富的背景,本文使用deeplabv3+网络分割的红外和可见光图像融合方法,融合框架如图1所示。
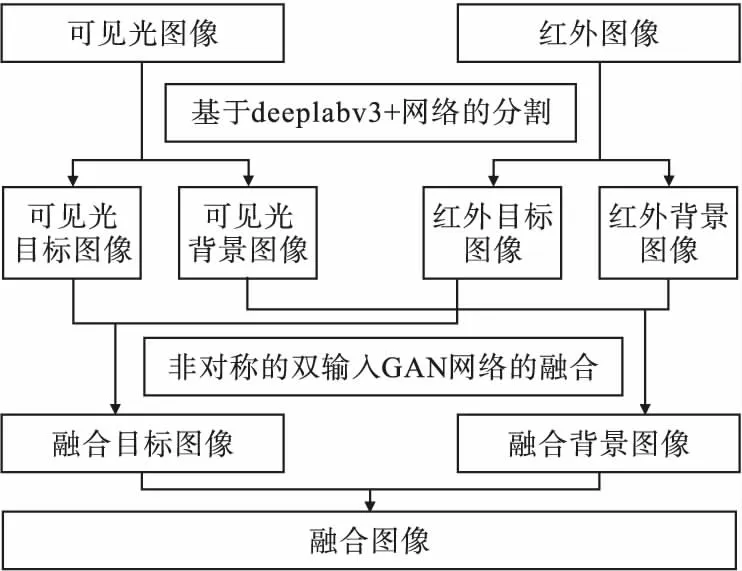
图1 融合流程图
融合过程通过deeplabv3+网络对红外图像进行语义分割,得到带有语义信息的红外目标图像,该图像称为掩膜;再根据掩膜带有的语义信息来分割红外图像和可见光图像,得到红外目标图像和背景图像,以及可见光目标图像和背景图像;再将不同区域的图像输入到不对称的双输入GAN网络得到不同区域的融合图像;最后两张融合图像加权得到最终融合图像。
1.1 deeplabv3+网络的图像语义分割方法
图像分割是将图像分离成互不交叠的有相同性质的区域。为应对不同区域的融合要求,将图像分割为目标区域和背景区域。采用图像语义分割网络deeplabv3+,其结构如图2所示。图中Conv表示卷积层。

图2 图像语义分割网络结构图
由于红外图像目标对比度较高,有利于图像进行语义分割,故由红外图像对网络进行训练,得到带有语义信息的掩膜,再根据掩膜将红外与可见光图像分割为目标图像和背景图像[14],计算方法为
(1)
式中:Ir1表示红外目标图像;Im表示掩膜;⊙为哈达玛乘积;Ir为红外图像;Iv1为可见光目标图像;Iv为可见光图像;Ir2为红外背景图像;Iv2为可见光背景图像。
1.2 GAN网络的图像融合
1.2.1 GAN网络的设计
为获得不同区域的融合特征,在传统的GAN网络基础上,生成器G的单输入改为双输入,具体网络结构如图3所示。
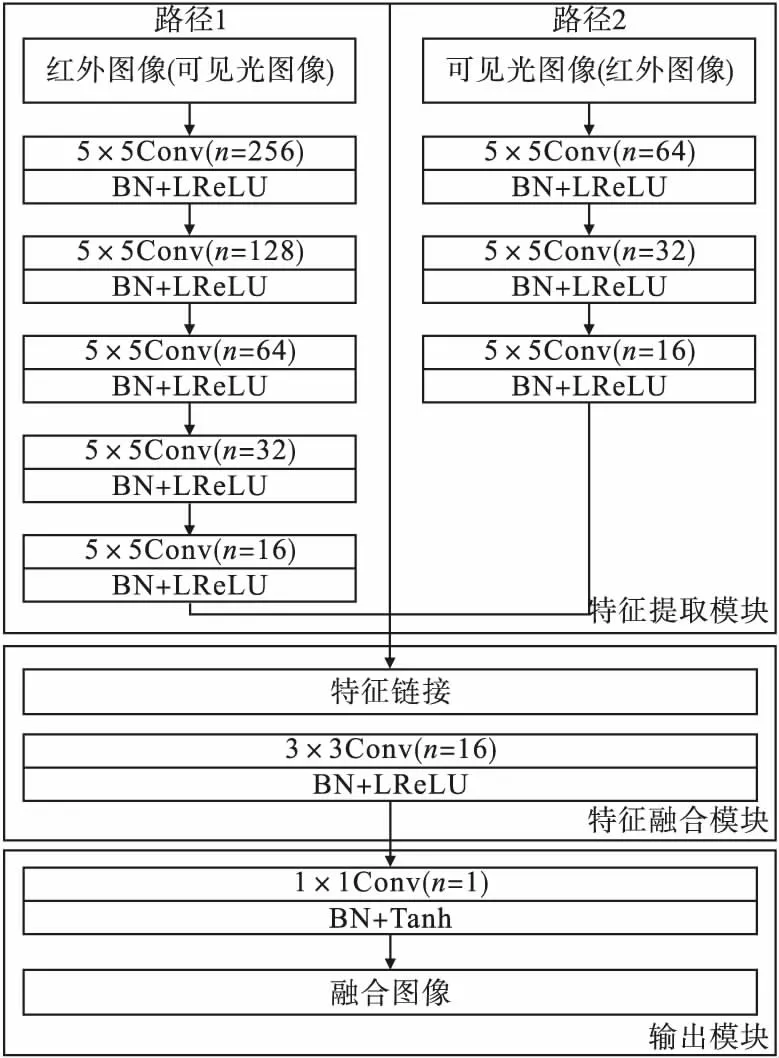
图3 GAN网络的生成器G结构图
该网络由特征提取模块、特征融合模块和输出模块组成。特征提取模块有两个路径,其中输入路径1由5个卷积层、批量归一化层(Batch Normalization,BN)和激活函数LReLU层组成,其中卷积层的卷积核分别为5×5、5×5、5×5、5×5和3×3,卷积核个数n分别为256、128、64、32和16。输入路径2由3个卷积层、批量归一化层和激活函数LReLU层组成,其中卷积层的卷积核分别为5×5、5×5和3×3,卷积核个数n分别为64、32和16。路径1相对于路径2可以更深入提取特征,两个特征提取路径的不同结构对应目标图像和背景图像的不同融合需求。特征融合模块由1个卷积层、批量归一化层和激活层组成,其中卷积层的卷积核为3×3,卷积核个数n为 8,其将提取的特征融合后输出。输出模块由1×1卷积层、批量归一化层和激活层组成,其中卷积层的卷积核为1×1,卷积核个数n为 1。
判别器D结构如图4所示,该网络由4个卷积层和1个激活层组成,其中卷积层的卷积核均为3×3,卷积核个数n分别为32、64、128和256,步长s为2,最后一层用于判别,并输出判别结果。

图4 GAN网络的判别器D结构
1.2.2 损失函数
将源图像输入到生成器G得到融合图像。生成器G整体的损失函数为
LG=LAdv+λ1LCon
(2)
(3)
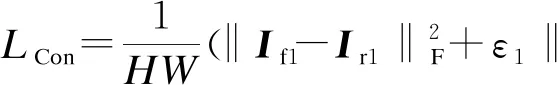
(4)
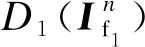
判别器D的损失函数为
(5)
式中:b和c分别代表Iv1和If1的标签;D1(Iv1)和D1(If1)分别代表Iv1和If1的判别结果。
1.3 目标图像融合
为使目标图像对比度更高,生成器输出的融合目标图像保留更多红外图像的对比度,则路径1的输入为红外目标图像Ir,路径2的输入为可见光目标图像Iv,目标图像融合的过程如图5所示。
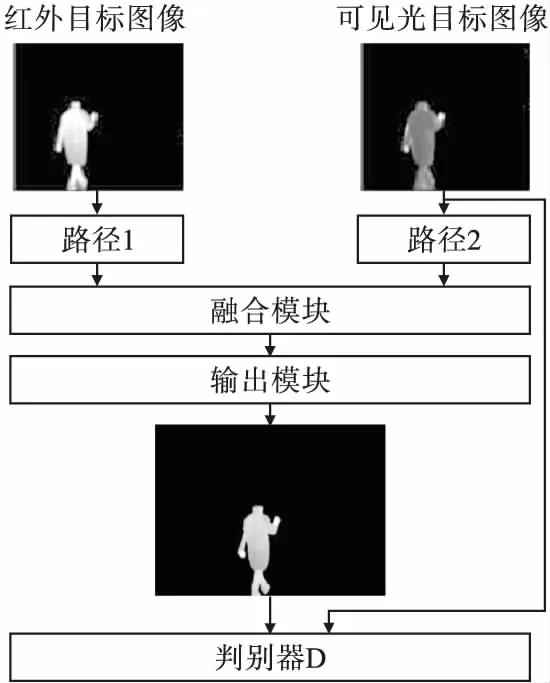
图5 目标图像融合
1.4 背景图像融合
为使融合图像的背景具有更好的细节信息,生成器输出的融合背景图像保留更多可见光图像的细节信息,则路径1的输入为可见光背景图像,路径2的输入为红外背景图像,背景图像融合过程如图6所示。

图6 背景图像融合
1.5 目标和背景的融合
通过网络分割后的图像存在许多不带有语义信息且像素值为0的区域,对分割后的图像进行融合时,融合图像会在像素为0的分割区域产生少量像素值。为减少对融合图像的影响,采用掩膜提取目标图像的方法[14],利用掩膜将目标融合图像的目标和背景融合图像中的背景分割。分割方式如式(6)、(7)所示。
I1=Im⊙If1
(6)
I2=(1-Im)⊙If2
(7)
式中:I1为目标图像;I2为背景图像;If2为背景融合图像。
经过语义分割后的图像I1只在目标区域有像素值,背景区域的像素值均为0,图像I2只在背景区域有像素值,目标区域的像素值均为0,由此最终融合图像If可通过像素直接相加得到,如式(8)所示。
If=I1+I2
(8)
2 实验结果及分析
为验证本文GAN网络的红外与可见光图像融合算法的有效性,实验中deeplabv3+网络的训练与测试采用公开的数据集TNO,图像尺寸为450×450,网络分割生成的目标图像和背景图像作为训练非对称的双输入GAN网络的数据集。在分割网络相同的基础上,选取以残差块连接的RestNet的图像融合、以生成器为单输入的FusionGAN(简称FGAN)的图像融合及以GAN网络的语义分割图像融合作为对比实验,通过主观评价和客观评价两方面对融合图像进行对比。
2.1 主观评价
主观评价是基于人眼的视觉效果来评价融合图像质量,选取的图像及融合结果如图7所示。

图7 选取图像及融合结果
本文采用基于GAN网络图像分割后融合,将分割后不同区域的图像输入到双输入的GAN网络中,不同输入路径可以提取不同深度的图像特征。图7a和图7c的融合图像对比中,本文GAN网络的图像融合,相较于RestNet、FGAN和基于语义分割网络的融合,左侧框内桥的边界清晰,右侧框内桥与外侧的边界更清晰,更接近于可见光图像,人像相较于背景具有更高的对比度。图7b和图7d的融合图像对比中,本文GAN网络的图像融合,相较于RestNet、FGAN和基于语义分割网络的融合,左侧框中草丛的轮廓和边缘更清晰,更好保留细节信息,雨伞图像的整体和边缘更清晰,视觉效果更好,人像相较于背景具有更高的对比度。
图像融合结果中,本文的融合方法中融合图像的目标对比度更高,能有效地突出目标,有利于目标检测。背景区域保留的纹理细节更好,通过主观评价,本文融合图像效果优于其他用于比较的图像融合方法。
2.2 客观评价
客观评价是通过数学建模对图像的特性进行评价,相比于主观评价具有更好的准确性和高效性。本文选用信息熵(Entropy,EN)、互信息(Mutual Information,MI)、结构相似性(Structural Similarity,SSIM)、标准差(Standard Deviation,SD)4种客观评价标准。
使用EN、MI、SSIM、SD客观参数对2组图像进行客观性能评估,实验结果如表1所示。

表1 各算法融合结果客观评价
由表1可见,本文的图像融合方法中4个客观参数的值均最高。
信息熵的值越大,融合图像包含源图像的信息量越多,说明本文的融合方法能更好地保留源图像的目标和背景信息;互信息的值越大,融合图像与源图像的关联性越强,说明本文的融合方法能更好地加强融合图像与源图像的关系;结构相似性的值越大,融合图像与红外及可见光图像的空间结构相关性越大,说明本文的融合方法可有效地保留图像的亮度、对比度和结构特性;标准差的值越大,融合图像的对比度更高,说明本文的融合方法可以有效保留目标图像的对比度,对融合后的图像进行目标检测和定位更有利。
3 结论
使用deeplabv3+网络将红外目标图像分割为掩膜,利用掩膜的语义信息将红外与可见光图像分割为目标图像和背景图像,再使用非对称的双输入GAN网络,得到最终的融合图像。非对称的双输入GAN网络对目标图像和背景图像采用不同路径,提取不同深度的特征,解决特征提取不足和梯度消失问题,使融合图像的目标具有更高的对比度,背景具有更好的细节信息,融合后图像的质量更高。在主观评价和客观评价方面与基于FGAN网络、RestNet网络的融合相比,图像均具有更好的融合效果。
