颅脑损伤患者肺炎发生风险预测模型的系统评价
2022-08-10向黔灵江智霞胡汝均袁晓丽杨晓玲张芳张习莹
向黔灵,江智霞,胡汝均,袁晓丽,杨晓玲,张芳,张习莹
肺炎是颅脑损伤(Traumatic Brain Injury,TBI)患者住院期间常见的感染并发症,发生率为30%~60%[1-3]。TBI患者继发肺炎不仅影响疾病的恢复速度,延长住院时间、增加医疗费用[4],而且会加重病情进展,严重者可造成呼吸衰竭和休克,增加患者病死率[5]。因此,早期识别TBI患者肺炎发生的高危人群,及时预防和治疗尤为重要。预测模型能使用疾病预测因子来估计患者发病的概率[6]。颅脑损伤患者发生肺炎的风险预测模型,能显著提高肺炎的诊断效率[7],以便采取相应的预防和治疗措施,减轻患者及家庭的负担。目前已有学者开发了颅脑损伤患者肺炎发生的风险预测模型,但模型的构建方法、预测效能等各方面不一。因此,本研究旨在全面检索国内外相关研究,进行系统性地分析与评价,以期更好地为颅脑损伤患者肺炎发生风险预测模型的构建与应用提供依据。
1 资料与方法
1.1文献检索策略 计算机检索PubMed、Web of Science、Cochrane图书馆、Embase、万方数据库、中国知网、维普数据库、中国生物医学文献数据库中有关颅脑损伤患者肺炎发生风险预测模型的文献,检索时限为建库至2021年8月2日。以traumatic brain injury,craniocerebral trauma,head trauma,brain injuries;pneumonia,pulmonary infection,respiratory tract infections,hospital-acquired pneumonia;prediction model,risk prediction model,risk assessment,predictor为英文检索词。以颅脑损伤,颅脑创伤,颅脑外伤,创伤性脑外伤;肺炎,医院获得性肺炎,肺部感染;预测模型,风险预测模型,模型,预测因子,风险评估为中文检索词。采用主题词和关键词相结合的方式进行检索,并对纳入文献的参考文献进行手工检索。
1.2文献纳入与排除标准 纳入标准:①研究对象为颅脑损伤患者;②研究内容为颅脑损伤患者肺炎发生风险的预测模型;并描述了预测模型的建立过程;③具体说明诊断(评估)肺炎发生的诊断标准;④研究类型包括队列研究、病例对照研究和横断面研究等。排除标准:①仅为危险因素研究,没有构建预测模型;②研究未排除入院时已发生肺炎患者或未具体说明患者入院时是否发生肺炎;③会议摘要、灰色文献等非正式发表文献;④综述、基于系统评价/Meta分析建立模型;⑤无法获取全文,非中英文文献;⑥模型包含的预测变量<2个。
1.3文献筛选与数据提取 由2名研究者按照纳入和排除标准独立筛选文献,若2人意见存在分歧且经过讨论不能达成共识,则寻求第3位研究者意见并达成一致。文献筛选首先阅读文题和摘要,在排除不符合文献后,进一步阅读全文,以确定最终是否纳入。确定纳入文献后,提取资料包括文献发表年份、第一作者、研究地区、研究设计类型、研究对象、预测结果、候选变量、缺失数据、建立模型的方法、样本量、变量选择、模型性能、验证方法、最终包含的预测因子、模型呈现形式、适用性和局限性等。
1.4文献质量评价 由2名研究者采用适用于病例对照研究及队列研究的纽卡斯尔-渥太华量表(Newcastle Ottawa Scale,NOS)对纳入文献进行质量评价,如有分歧则通过讨论或由第3位研究者裁定。NOS分别从研究对象的选择、组间可比性以及结果/暴露因素这3个方面进行评分,NOS总分为9分,根据评分标准给分,0~4分为低质量文献,5~9分为高质量文献。
1.5纳入文献的偏倚风险和适用性评估 由2名研究者使用预测模型研究的偏倚风险评估工具(Prediction Model Risk of Bias Assessment Tool,PROBAST)从研究对象、预测因子、结果和统计分析4个领域,进行纳入文献的偏倚风险评估;从研究对象、预测因子和结果3个领域进行适用性评估。
2 结果
2.1文献筛选流程和结果 通过检索得到相关文献674篇,其中英文文献594篇,中文文献80篇。去除重复文献83篇,阅读标题和摘要排除579篇,阅读全文排除6篇(1篇中文未构建模型、1篇英文未构建具体模型、2篇英文结局指标不是肺炎、1篇全文非英文文献、1篇结果与已纳入文献重复),最终纳入6篇文献[7-12]。
2.2纳入文献的基本特征、建模情况及质量评价 6篇文献NOS评分总分均为6分,为高质量文献。文献的基本特征及建模情况见表1。
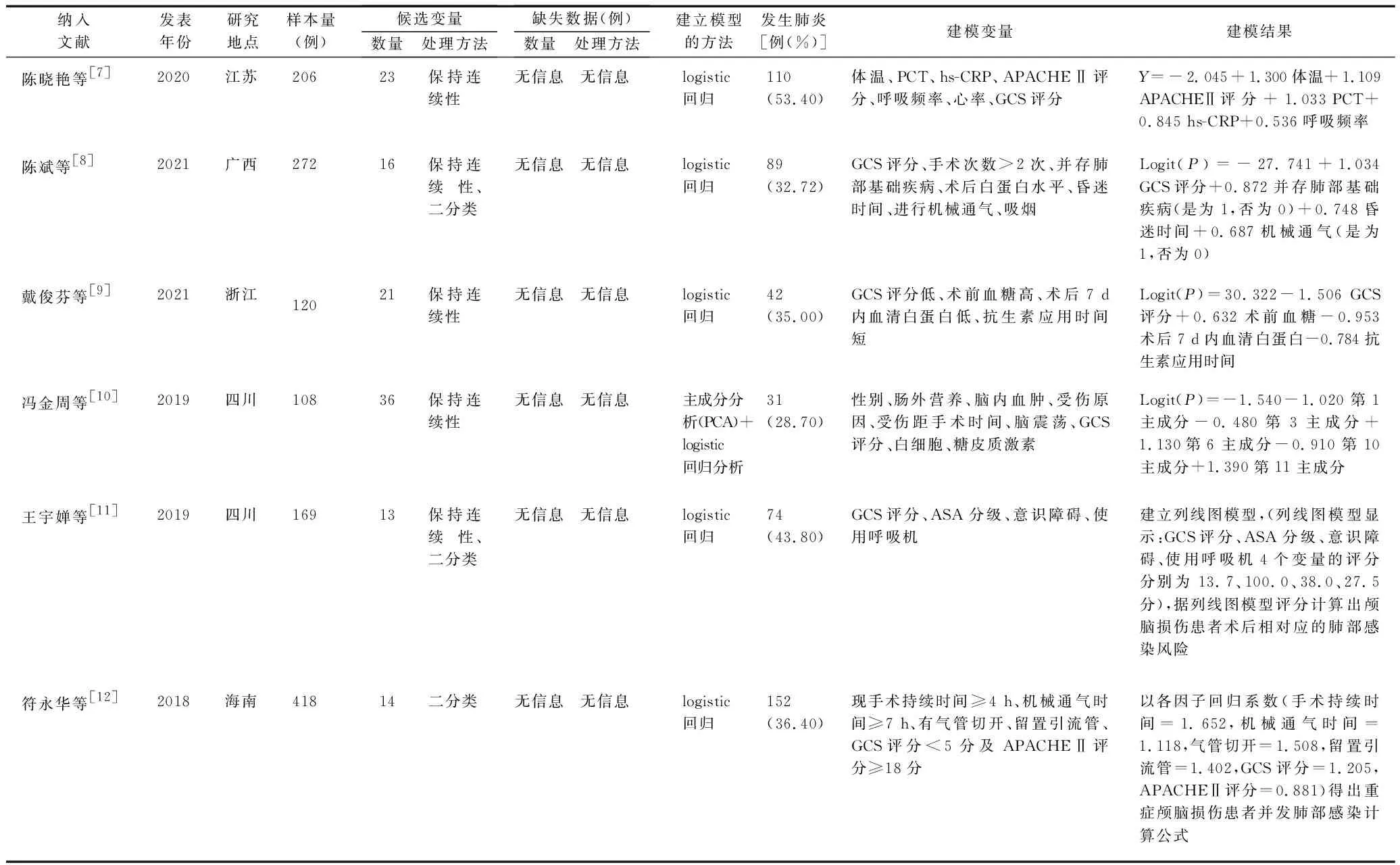
表1 纳入文献的基本特征及建模情况
2.3模型性能及验证情况 有5项研究[8-12]报告了区分度指标;仅2项研究[8-9]报告了校准度指标,校准方法为Hosmer-Lemeshow检验。1个模型[7]未报告受试者工作特征曲线下面积(Area Under the Curve,AUC),5个模型[8-12]的AUC为0.806~0.949;模型[7]的Kappa系数为0.815,预测一致性较高。在模型验证方面,有1项研究[8]进行了外部验证,2项研究[9,11]进行了内部验证,其中1项[11]采用Bootstrap法重复抽样1 000次进行内部验证,另1项[9]随机选择研究中50%样本进行模型验证。
2.4偏倚风险和适用性评价
2.4.1与研究对象有关的偏倚 如果纳入研究选择的数据来源不合适,或未按原先制订的纳入、排除标准选择研究对象,可能会造成选择偏倚[13]。经过评价,纳入的6项研究与研究对象有关的偏倚风险均较低。
2.4.2与预测因子有关的偏倚 6项研究在预测因子领域偏倚风险均不清楚。虽然6项研究均为单中心研究,但未提及是否按照统一标准评估预测变量,因此问题“所有研究对象的预测因子是否以类似的方式定义和评估”的回答是“没有信息”。6项研究均为回顾性研究,无法得知预测指标的评估是否是在不了解结果的情况下进行的,因此问题“预测因子的评估是否在不了解结果数据的情况下进行的”回答是“没有信息”。
2.4.3与结果有关的偏倚 6项研究在结果领域偏倚风险均不清楚。6项研究分别有结果的诊断标准,但并未详细描述是否与所有研究对象的结果确定有关,因此问题“结果的定义和确定方式是否相似”的回答是“没有信息”。6项研究未报告结果确定时是否不清楚预测因子的信息,因此问题“是否在不知道预测因子信息的情况下确定结果”的回答是“没有信息”。
2.4.4与分析有关的偏倚 6项研究在分析领域的偏倚风险均较高。6项研究中除了符永华等[12]的因变量事件数(Events Per Variable,EPV)和样本量达到要求外,其余研究样本量均不足。有研究指出,对连续变量进行分类会降低预后模型预测能力[14]。本研究中有2个模型[8,11]对部分连续变量进行了二分类,1个模型[12]对全部连续变量进行了二分类。在缺失数据及处理方面,6项研究均没有提供有关信息。在变量选择上,有3项研究[7,9,11]在进行单变量分析后直接多变量分析,未应用恰当的变量选择方法;此外,均未提及数据的复杂性。在模型性能评估方面,仅2项研究[8-9]同时报告了校准度和区分度。
2.4.5适用性评价 在适用性方面,纳入的6项模型在研究对象领域、结果领域适用性风险低,在预测因子领域适用性风险不清楚;6项研究的整体适用性均不清楚。
3 讨论
系统评价可通过循证的方法帮助研究者全面检索、客观评价颅脑损伤患者肺炎发生风险预测模型,评估其整体质量,为模型的构建及应用提供依据。指南推荐使用PROBAST风险评估工具对预测模型进行系统评价和Meta分析,有助于解释预测模型的潜在适用性和普遍性,也有助于规范模型的开发[15]。本研究系统检索了颅脑损伤患者肺炎发生风险预测模型的相关研究,逐层筛选最终纳入6项研究,其中1个模型未报告AUC,其Kappa系数为0.815,预测一致性较高。余下5个模型的AUC为0.806~0.949,预测性能较好。但纳入的6项研究均存在偏倚风险,主要原因包括:未报告盲法、样本量不足、模型过度拟合、未报告或未处理缺失数据、模型性能缺乏评估。
本系统评价纳入的6项研究,整体偏倚风险普遍较高,整体适用性均不清楚,若考虑到模型的推广应用,尚缺乏可以广泛应用于此类患者临床实践的预测模型,接下来需要开发偏倚风险较低、适用性较高的预测模型。从现有的研究中,得出几点今后对相关预测模型研究的启示:①GCS评分、机械通气、术后白蛋白水平、APACHE Ⅱ评分是纳入的6个模型中包含最多的预测因子。应注意对这些变量进行评估,可以开展知识培训,保证医护人员能够准确评估患者GCS评分、APACHEⅡ评分,密切关注患者机械通气情况及血清学指标。②在建模样本量方面,有5个模型研究样本量不足,可能会导致参数估计准确性受到影响。针对模型的开发研究, EPV>20会让研究更有说服力;如果EPV<10可能会造成过度拟合[16-17];而针对模型的验证研究,结果事件数<100可能会造成偏倚[18]。因此,在今后的模型开发中,需要纳入足够的样本量,最好能开展多中心研究。③6个模型中,冯金周等[10]的模型运用了PCA分析法,其余模型使用logistic回归分析法建立模型。PCA是机器学习算法中的一种,可以处理复杂的临床数据,在保留数据特征的同时,通过计算机进行原始变量降维,将高维空间数据转换为低维,建立相应的线性方程组[19]。从模型预测性能来看,PCA分析法建立的模型AUC=0.949,与纳入的其他模型相比,其预测性能更佳。提示大数据与人工智能时代的到来,计算机科学与临床医学的结合日益紧密,对于一些复杂数据的处理,需要找寻新的分析方法,选择预测性能更佳的模型来指导临床。因此,建立模型除了运用传统的回归分析外,还可以探索运用其他机器学习方法,如决策树(Decision Tree,DT)、随机森林(Random forest,RF)、支持向量机(Support Vector Machines,SVM)、朴素贝叶斯(Naive Baye-sian Model,NBM)、梯度增强算法(Gradient Boosting,GB)、人工神经网络(Artificial Neural Networks,ANNs)等方法构建模型。④纳入的6个模型,仅2项采用了内部验证,1项进行了外部验证。临床研究中重模型开发而轻验证是目前常见问题,大多研究仅停留在建模阶段,导致仅少数模型可用于临床实践[20]。内部验证能够防止模型过度拟合[21];外部验证关注模型的可移植性和可泛化性[22],使用新的数据再次评估模型的性能,提高模型质量。有研究指出,尽管一些模型因未进行内外部验证而被评为高风险偏倚,但并不能否定其预测价值,可以视情况合理选用[23]。⑤6项研究在缺失数据上均未提供有关信息,可以看作研究者忽略了缺失数据的处理。研究表明有效处理缺失数据,才能准确地反映研究群体的特征,数据缺失可能会影响数据分析的质量,正确处理数据可以减少偏倚[24]。目前常用的缺失值处理方法有加权法、删除法、插补法3大类[25]。针对不同原因及形式造成的数据缺失,需要采取合适的方法进行处理。⑥纳入的研究中有4项[7-9,12]研究通过计算颅脑损伤患者继发肺炎的公式、1项[11]以列线图模型、1项[10]以PCA-logistic回归模型对应的影响系数呈现结果。为了提高医护人员使用风险预测模型时的依从性,并减少临床工作耗时,今后研究需同时关注模型的预测精准度与使用便捷性,通过恰当形式呈现预测模型,建议研发操作界面简便的自动化信息平台,便于临床实际操作应用。
4 小结
本研究共纳入6项颅脑损伤患者肺炎发生风险预测模型的研究,对模型的各方面特征进行了系统评价,研究结果提示相关模型研究尚处于发展阶段,今后研究者可以开展多中心、大样本研究,结合大数据分析方法,开发预测性能优良、使用简便的预测模型,在使用过程中不断校正模型,使模型研究趋于成熟。本研究仅纳入了中、英文文献,可能存在发表偏倚;且纳入患者年龄跨度较大,模型中的预测因子是否适用有待进一步探究。
