人工智能的法律风险和解决途径
2022-08-10蔡晓淇付嘉伟田笑宇
蔡晓淇 付嘉伟 田笑宇
东北大学文法学院,辽宁 沈阳 110169
当今社会,人工智能技术高速发展,伴随着人工智能技术不断市场化、产品化、普及化,它将渐进地改变人们的生活,也将改变传统社会的各行各业。但是,万物皆有两面性,人工智能技术也是一把双刃剑,它造福社会,提高整体社会的劳动效率,便捷人们的生活;伴随着其智能程度的上升,未来可能难以被人类所掌控,会造成许多风险。我们应该正视其好与坏,也应该未雨绸缪,关注它的变化,适时而变,促进其朝向好的方向发展。综上,我们的当务之急就是要对人工智能进行合理可行、高效的风险评测、防控以及未来用法律的手段去解决它的风险。
一、人工智能技术的法律风险的定义
根据《巴塞尔新资本协议》,法律风险是一种特殊类型的操作风险,包括但不限于因监管措施和民商事纠纷解决而产生的罚款或惩罚性赔偿所带来的风险敞口。在本文章中人工智能技术法律风险的定义为:人工智能技术在飞速发展中,由于弱人工智能在逐渐向强人工智能、超人工智能进化,从而让人工智能技术徘徊于法律边界周围更有甚者超出法律边界而造成的一系列法律问题,这其中包含着人工智能法律风险发生的可能性及危险性,也包含着这种法律风险导致的不确定性后果。
二、人工智能技术的法律风险的主要形式
(一)侵权责任风险
人工智能技术为了提升自身的发展速度并与此同时不断完善自己,尽可能减少自身可能产生的错误,将人工智能技术市场化、产品化是必由之路。但是,在其市场化、产品化、普及化的过程中,它侵权责任的法律风险则随之而来,其中有人工智能技术产品自身质量不合格而侵权,也有在使用者层面造成的不当使用而侵权。不同的方式促使着我们必须对其侵权而造成的法律风险进行进一步的分类以便更好地预防。(见表1)

表1 人工智能技术的法律风险的主要形式
1.难以确定人工智能的法律地位
目前我国民法对民事主体的界定为:有独立的名义,独立的意志,独立的财产,包括自然人、法人和其他社会组织。显然根据民法的定义,人工智能产品不算是民事主体。但是由于人工智能技术有自我学习的特性,会在不断学习中产生自己的独立行为,进而难以控制、难以判断、难以预测。基于此种特性,一个问题摆在我们面前:一旦人工智能产品侵害他人权益时,是否可以用现有的法律地位将其类比为独立的民事主体,从而承担应该承担的侵权责任?
2.难以确定人工智能侵权行为
我国《民法典》规定侵权责任的一般构成要件,即:(1)违法行为;(2)损害事实;(3)因果关系;(4)主观过错[1]。因为人工智能的法律地位目前尚未有一个明确的答案,也就不能明确人工智能侵权主体。同时人工智能可以通过后天的不断学习,拥有独立决策、独立行为的能力,不能判断其行为的初衷,这也就很难看出是否其行为受到算法设置者的干预。据《民法典》,只拥有违法行为和损害事实,并不能判断其因果关系和主观过错的情况,是不能轻易追究其侵权责任的,也就存在着相对应的法律风险。
3.难以确定人工智能的归责原则
《民法典》规定的过错责任以侵权人存在主观过错为前提要件[2]。如今,没有法律承认人工智能可以作为侵权人,即人工智能并未拥有法律意义上的主体地位,所以即使人工智能侵害他人权益也很难套用哪套过错的责任法案来惩罚人工智能。没有相对应人工智能的法律规则来审判也是目前的法律风险。
(二)个人信息与个人隐私泄露风险
1.个人信息和隐私数据的不正当收集风险
在现在的大数据时代,人工智能正在不断地以不正当的手段收集每个上网人的信息和隐私。过去,我们主要通过注册个人账户来以主动的方式被互联网收集个人信息和隐私数据,现在人工智能的生活化发展让我们的个人隐私更轻而易举地被获取,更甚者是在我们并不在意甚至毫不知情的情况下,人工智能就将我们个人的信息和隐私数据收取了。就像:自动驾驶汽车技术,它从某种程度上可以作为人工智能收集我们的移动地点的工具,这使得私家车这一本为很私人的空间,变成无论去哪里都会被记录下来的“笔记本”。[3]
2.个人信息和隐私数据的泄露扩散风险
2012年云存储公司Dropbox泄露几千万用户邮箱账号信息;2016年全国30个省份约270名的艾滋病患者信息泄露受到不法分子打来的骚扰电话[4]。许多例子告诉我们,我们的个人信息并不安全,也没有相关的法律来切实地保护我们的利益。这样的隐私数据都会被大范围的泄露,我们又如何去谈论隐私权呢?我们又怎么去保护我们的个人信息和个人隐私不被泄露呢?
(三)劳动者就业风险
在现在的自然界,能够比人类更强的也就只能是未来的人工智能科技了。当真正的强人工智能时代到来之时,人类的各行各业也将经历一次人工智能侵入的大洗牌,人工智能大批量、高质量地涌入劳动力市场必将占据大量劳动力席位,使得劳动力市场的结构大变,从而减少大量原有的工作岗位,引发劳动者大批量失业。
三、人工智能技术的法律风险的解决途径
(一)侵权责任风险的解决途径
当我们想要给人工智能侵权行为进行责任划分时,由于人工智能的智能程度不同决定着其是否能拥有法律意义上的主体地位,就必须针对这进行分类讨论、区别对待。
1.弱人工智能:此类人工智能产品只会一味地按照设定好的算法运算,只是辅助人类工作的工具,没有自主的意识,在这样的前提条件下,弱人工智能没有条件去具备法律意义上的主体地位,“也就是说,人类对人工智能的态度还处于人工智能薄弱的阶段。大数据虽然在发挥作用,但本质上仍处于工具化阶段,与传统产品并无区别”[5]。正因为这样,即使这样的人工智能产品造成了侵权行为,它的设计者、研发者也并不应该承担相应的责任,而应该判定是否与使用者有关。若有,则使用者承担主要责任;若无,这应该追究生产方与销售方的责任。此时各方应遵守“谁的行为谁承担”的原则。
2.强人工智能和超人工智能:人工智能产品可以通过大量数据的分析、处理与学习,拥有独立决策、独立行为的能力,拥有独立的自我思维和意识。拥有智慧的前提使得其脱离了单纯的“物”的范畴。此类人工智能产品应当获得法律主体地位。此时的区别则是,相比超人工智能,强人工智能的主体地位相对较低。强人工智能侵权时,设计者和研发者负主要责任,使用者更像是“监护人”起到监管的职责。若使用者并无过错则无需承担责任。而超人工智能,应具备完全的法律地位,此时对于使用者来说,二者相互独立。追究过错时应当追究设计、研发人员,让他们与人工智能产品共同承担侵权责任。
(二)个人信息与个人隐私泄露风险的解决途径
1.明确个人信息与个人隐私的保护范围
在《民法典》中对隐私权和个人信息的内容分别给予了详细的规定。个人信息和个人隐私并未被等同,而是对个人信息的定义加以扩展,将这样的定义明确,能辅助我们更好地保护个人隐私,我们更应该明确它们受保护的范围。
2.完善个人信息与个人隐私保护的法律体系
如今我们国家并未建立起完善健全的保护个人信息和个人隐私的法律体系。近十年来,国家才一点点地加强对公民个人信息和隐私权保护的重视。国家应该针对时势,出台一部针对新时代人工智能等高科技窃取公民个人信息和隐私的劣迹行为。而制定在相关法律中应当着重注意以下方面:完善用户同意机制[6],即在使用公众信息目的正当且必要的大前提下,充分告知公众相关信息使用和用途并得到公众个人的自愿同意。这也就要求数据控制者必须经过数据拥有者的本人同意才能够处理其信息。这样设置能够给予用户更多的权利,如知情权、拒绝权等,减少个人信息与个人隐私的泄露风险。
3.提高个人对于自身信息和个人隐私的掌控能力
在人工智能产品化、市场化、普遍化的今天,储存时间长、收集方式多等词汇成了个人的信息的标签,个人的隐私也具有持久性、易得性等特性。为了解决个人信息泄露的问题,可以依靠法律的力量,给予自然人对于自己的个人信息和个人隐私更多的掌控能力,例如:彻底删除、控制个人信息传播等。与此同时,当信息所有者在合理合法的前提下行使这种权利,任何人不得干涉与拒绝,这样可以提高个体对于个人信息和隐私的控制能力和主动防御能力,也可以有效减少人工智能对于个人自身的信息和隐私的控制强度。(见图1)
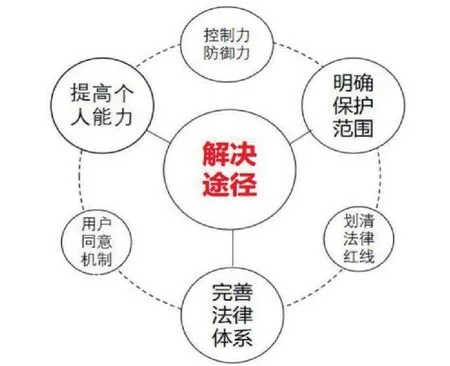
图1 个人信息与个人隐私泄露风险的解决途径
(三)劳动者就业风险的解决途径
人工智能技术不断涌入劳动力市场,在资本家以利益为前提的视角下,劳动者的劣势地位会逐渐被放大。故若人工智能大批量、高质量地进入劳动力市场,需要通过法律层面来维护劳动者的利益,着重关心劳动者自身工作的稳定性以及劳动者和资本方的利益和视角的协调。
我们应重塑和谐价值,在从前的劳资关系之中,和谐的价值也仅仅在于不起矛盾,互相体谅,和睦相处。可当人工智能时代到来之后,为了减少人工智能对于劳动者就业方面的法律风险,社会应该重塑出一个新的和谐价值。这个和谐代表着建立劳动者和资本方的协调的利益“命运共同体”。在法律的制定角度,应该将劳动者和资本方当做“和谐”关系的两端终点,人工智能技术仅仅是二者相互共通、相互合作的工具,给予劳动者足够的尊重,并不能够替代劳动者的存在。重塑和谐价值,有助于让劳资双方共赢:劳动者通过学习、利用人工智能技术从而更好地服务于资本方,获得自我价值;资本方可以通过人工智能技术降低成本,更好地获得劳动者的价值。
四、未来启示
人工智能的应用对于人类社会是存在于各个方面。例如,日常的信息处理、自动驾驶汽车的进入市场、代替简单重复劳动的人工智能机器人等。面对这些智能化、创新化的事物,现有的法律体系难以面面俱到,人工智能出现法律风险的可能性很大。这种风险,有人工智能技术对现存法律的挑战,还有人工智能给社会带来的不可预测性等。对于我们人类来说,对于人工智能发展的底线就是人工智能的存在应该是服务于人类,当人工智能的行为越过法律的边界,损伤了人类的利益,那么我们就需要对这种技术进行限制甚至停止使用。
