中文核心期刊目录自动化检索工具的设计与实现
2022-08-09邢明钢冯静康岩
邢明钢,冯静,康岩,林 斌
(新疆师范大学 图书馆,新疆 乌鲁木齐 830017)
自《教育部办公厅关于开展清理“唯论文、唯帽子、唯职称、唯学历、唯奖项”专项行动的通知》(教技厅函〔2018〕110号)发布后,“破五唯”在引导教育评价导向中起到重要作用,科研界进一步改进评价制度,对以中文核心期刊目录收录的期刊上发表论文作为标志性成果,并据此肯定其成果的质量、贡献和影响达成较高共识。
不同的中文核心期刊源目录收录的期刊各有侧重,互为补充、相对独立。但这也给专业技术人员和科研机构带来一些问题:在进行检索时,不同中文核心期刊目录源收录领域不统一、比对不便利、检索不高效。以“中文核心期刊目录”为主题查询中国知网(CNKI)数据库,全网有150篇论文涉及该主题,均为对核心期刊目录编制的方法、不同目录的比较等进行探讨,没有发现对中文核心期刊检索的方式或工具进行研究的论文。若将各核心期刊统计源目录的数据进行转化、整合,则可建成统一格式的中文核心期刊目录数据库;再针对性选择开发软件,查询比对用户需要查询的期刊目录数据与此数据库的匹配情况,对显示界面进行组织,实现检索结果信息迅速、准确、清晰地向用户呈现,从而研发出中文核心期刊目录检索自动化工具。
1 中文核心期刊目录源数据的构成
当前我国主要有7 个中文核心期刊遴选体系,分别是:(1)中国科学引文数据库来源期刊(CSCD)[1];(2)中文社会科学引文索引来源期刊(CSSCI)[2];(3)中国科技论文统计源期刊(CSTPCD,中国科技核心[3]);(4)中文核心期刊要目总览(北图)[4-5];(5)中国核心期刊目录(RCCSE)[6];(6)中国引文数据库(CCD);(7)中国人文社会科学核心期刊要览(CASS)。这7种文核心期刊统计源目录是研究人员运用文献计量学的原理,对中文期刊通过研究分析进行定量、定性评价,不仅考察期刊的学术性,还考察期刊编辑的规范性;既召集学科专家评审,还进行同行评议[7];强调严谨性,鼓励创新性,通过参考期刊影响因子、被引量、他引量、被索量、被重要检索系统收录等多项要素而建立起来的学术评价指标[8]。
其中,在国内影响力最大、检索最为广泛的中文核心期刊统计源目录有4 种:CSCD(中国科学引文数据库),CSSCI(中文社会科学引文索引),CSTPCD(中国科技核心),北京大学中文核心期刊要目总览(北图),这些是提供基本的信息检索服务和针对特定领域、特定人群的高水平信息检索服务的主要中文核心期刊统计源目录[9]。本研究重点面向这四大核心期刊统计源目录。
1.1 研发自动化检索工具的缘起
在专业技术人员职称晋升评审、科研项目申报、高校(科研机构)水平评估或申请基金等工作中,为查询相关论文被中文核心期刊录用的情况,需要使用关键字进行检索查询,进一步了解掌握存储在论文内不同部分的作者创造性研究成果[10]。目前采用人工的方式,以论文题名、作者姓名或期刊名称为关键词,在四大中文核心期刊统计源目录电子数据库或纸质版材料中进行检索;或交由具有论文认定资质的高校图书馆、科研机构进行查询认定,检索方式较为繁琐,耗时较长,效率不高,在操作环节中有时还会出现失误。当同一期刊被不同核心期刊统计源目录收录时,人工检索还需要分别到各统计源目录中查询,每次查询到的信息不全面,比对不便利。
为此,在设计自动化检索时首先要考虑建立四大核心期刊统计源目录收录期刊的源数据库。该源数据库的关键字段有三个,分别是:(1)期刊名称,即被收录的核心期刊的具体名称,如《黑龙江高教研究》;(2)期刊类型,即核心期刊被收录到的统计源目录名称,如中国科学引文数据库(CSCD);(3)涵盖时段,即该期刊被收录到相应核心期刊统计源目录的具体年代,如2008—2009年。
本研究进行了自动化检索工具的设计。主要是设计出一种应用软件工具,通过其软件中的函数调用,将用户输入的检索目标期刊名称数据导入到源数据库中比对,最后向用户返回查询比对的结果,提高查询认定效率,降低乃至完全避免失误率。
1.2 自动化检索工具拟面向的统计源目录
中国科学引文数据库(CSCD)由中国科学院文献情报中心研制,1989 年首次遴选,每两年出版一次,至今已出版18版。
中文社会科学引文索引(CSSCI)由南京大学中国社会科学研究评价中心研制,1998年首次遴选,每两年出版一次。2008年起每年增设扩展版,至今已出版25版(含扩展版8版、集刊4版)。
科技核心(CSTPCD)由中国科学技术信息研究所根据国家科技部委托研制,1987年首次遴选,每年出版一次。2016年起,每年出版自然科学卷、社会科学卷各一版,至今已出版35版。
中文核心期刊要目总览(北图)由北京大学图书馆联合在京十几所高校图书馆研制,1992 年首次遴选,每4年出版一次。2008年起每3年出版一次,至今已出版9版。
中文核心期刊统计源研制单位出版及发布数据情况如表1所示。

表1 中文核心期刊统计源研制单位出版及发布数据情况
1.3 汇集收录中文核心期刊目录数据
2007年起,中国科学引文数据库(CSCD)实现与Web of Science的跨库检索,成为ISI Web of Knowledge平台上第一个非英文语种的数据库,具有重要意义。
2008年起,中文社会科学引文索引(CSSCI)增设扩展版,业界简称CSSCI(扩)。
2008年起,中文核心期刊要目总览(北图)由每4年出版一次改为每3年出版一次。
综合以上因素,该研究以2007年1月至2021年12月为时间跨度,面向四大中文核心期刊统计源目录在该时间段内收录的核心期刊目录数据,研发自动化检索工具;如有必要,亦可扩展各统计源目录2007 年之前、2021 年之后的期刊目录数据到源数据库内。如表2 所示,汇集收录的CSCD(中国科学引文数据库)、CSSCI(中文社会科学引文索引)、科技核心(CSTPCD)、中文核心期刊要目总览(北图)2007 年至2021 年版4库合一的源数据库,共有58421条核心期刊目录。

表2 汇集收录中文核心期刊目录数据
1.4 源数据的转化整理
资源库是最底层的数据库,既包括图书、期刊、标准、报告、专利等文献资源,也包括数据、网站、音频、视频、动画等[11]。本研究中,对下载收录的PDF 等格式核心期刊文件目录进行格式转化,形成新的资源库,以便目录数据的组织、调用。将目录数据的内容转化为统一格式后,去掉“学科名称”(CSSCI 设置)、“ISSN”(CSCD 设置)等字段,保留“期刊名称”字段,增加“序号”“核心期刊统计源”“涵盖时段”字段,为程序调用奠定数据基础。
2 自动化检索工具的功能与实现
2.1 开发软件的选择
本研究在选择易建易用的系统开发环境与确保相关技术需要的原则下[12],考虑软件设计、软件编程能力[13],以计算机Windows10 操作系统、Office 办公软件、Adobe Acrobat Pro Dc 为开发环境和开发软件,研发中文核心期刊目录自动化检索工具。
2.2 系统设计
自动化检索工具的研发宜于作为一个系统来设计,包含数据层、业务层和显示层。
(1)数据层:对CSCD(中国科学引文数据库)、CSSCI(中文社会科学引文索引)、科技核心(CSTPCD)、中文核心期刊要目总览(北图)近15年的数据进行收集、整理、转化、组织,形成包含“期刊名称”“核心期刊统计源”“涵盖时段”的拥有58421 条数据的新资源库,在用户输入需要检索的信息时作为对比源使用,实现完整性、即时性和历史性的统一。
(2)业务层:用户提交要检索的信息后,传导到数据层进行比对,主要是精确比对“期刊名称”“核心期刊统计源”信息,按范围比对“涵盖时段”是否符合用户输入的要检索的“年代”,并将所有比对结果返回到指定位置。
(3)显示层:将业务层生成的比对结果传导到显示界面,以直观的方式反映到用户面前,同时显示层也是数据层获取用户输入检索信息的导入界面。
2.3 功能模块设计与检索工具各项功能的实现
2.3.1 用户功能模块设计
用户功能通过用户使用界面直观表达,此模块在设计上应遵循设计出既吸引用户又具有高可用性的界面的原则[14],故将交互式人机检索查询界面设计为两部分。一部分展示当检索核心期刊目录数据功能实现后,在界面上进行何种显示的情况,主要显示指定年代的指定期刊被核心期刊统计源目录收录的情况。另一部分则集合了指定期刊及指定年代的输入、查询检索情况的输出两大功能,是主要的,也是唯一需要用户进行输入操作的功能性区域。
特别考虑了要采用“对结果进行查询检索并显示”的思路来组织用户使用界面,突出对检索过程中生成数据的充分引用,如图1所示,这些考虑有利于面向用户的界面更趋简洁、清晰、美观。
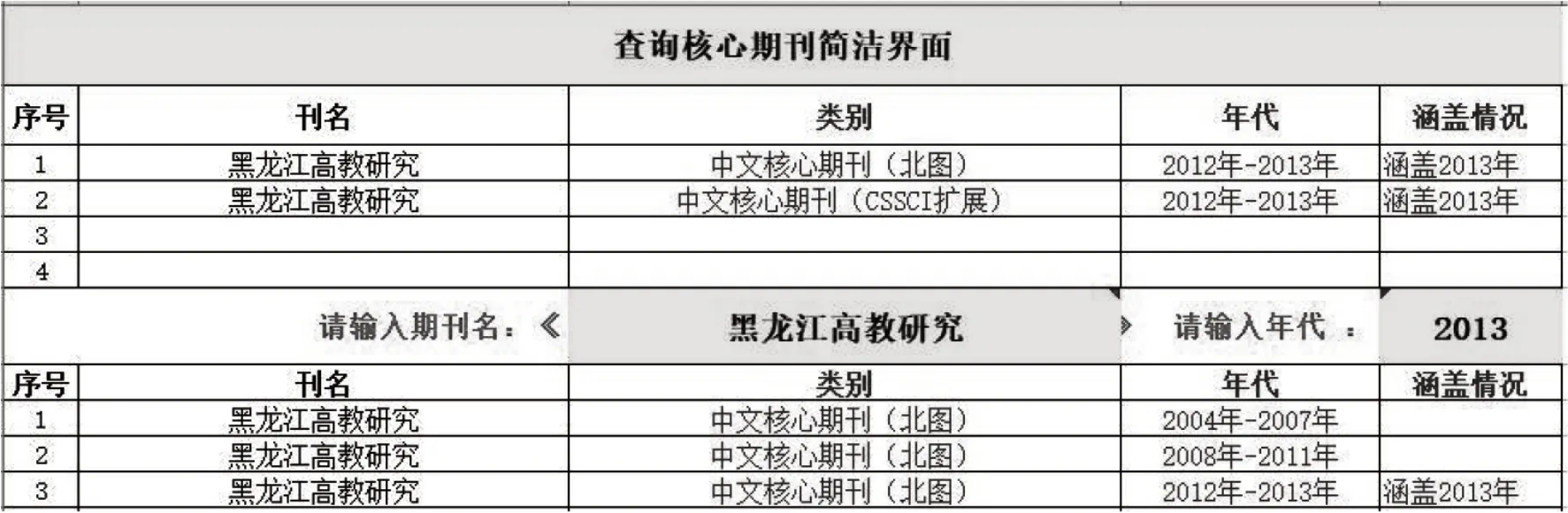
图1 用户界面
2.3.2 数据库模块设计
(1)字段类型。用作对比源的源数据库中的各字段除“序号”外,均为在检索期刊名称时的关键字,其字段类型为字符型。因期刊名称相差一个字即很可能是另一种期刊,故在进行数据库与用户输入的关键字进行比对时必须是精确匹配,否则即返回未检索到的信息或报错信息,供系统处理。
(2)数据导入。用Adobe Acrobat Pro Dc 读取四大核心期刊统计源目录研制单位在本单位官网或发布会上发布的各年度核心期刊目录数据,将PDF 等不同格式的目录信息统一导出为Excel表格格式,形成新的源数据库。
(3)数据更新。系统在进行检索操作时,会调用数据库里的数据进行比对、计算,因此源数据越丰富、更新越及时,检索的结果就会越准确、全面,因此管理人员就要定期进库,根据四大核心期刊统计源新发布的数据对数据库进行扩充。
期刊目录源数据库中数据字段的设置如表3所示。

表3 期刊目录数据库字段设置
2.3.3 业务功能模块设计
(1)构建检索工作表。首先需要创建工作簿和工作表,并将表起名为“检索工作表”。在“检索工作表”第一行设计出用户输入区域,在第一行前部的单元格预先录入“转录的期刊名:”,提示用户在同行的下一个单元格内输入要查询检索的期刊名,如《黑龙江高教研究》;在随后的单元格内预先录入“转录的年代:”,提示用户在同行的下一个单元格内输入用户要查询检索的该期刊的年代。用户预先录入信息的单元格所在位置是固定的,为表内进行数据调用奠定了基础。查询的顺序基于存储数据的方式,确保了检索的准确性[15]。
如图2所示,检索工作表内除设“刊名”“类别”“涵盖时段”外,在“序号”旁增设“过渡统计”字段。
根据需要留出足够多数的行。在本系统数据库的58421 条目录中检索统计,最多出现的核心期刊次数为39次,因而“检索工作表”预留的期刊目录数据行为39行。此表字段见图2检索工作表。

图2 检索工作表
(2)以期刊名作为关键词。以期刊名作为关键词进行检索,是一种主题检索[16]。在“检索界面”的“刊名”字段下进行函数调用,即在“刊名”字段下的同列每行单元格内,录入公式“=$D$1”,即绝对调用本表D1单元格内的用户输入的期刊名称并在本单元格内显示出来,为检索提供关键词。
(3)检索核心期刊统计源目录类别。如图3所示,在“类别”字段下,录入公式“=IFERROR(VLOOKUP(C$3&ROW(目录详情!B5),目录详情!B$1:目录详情!E$58421,3,FALSE),"")”,实现用户输入的期刊名称与“目录详情”工作表中数据的比对,如果数据精确匹配,则在“类别”字段下的单元格内显示该期刊被收录到的四大核心期刊统计源目录之一的名称,如“中文核心期刊(北图)”。

图3 检索核心期刊统计源目录类别
其中,VLOOKUP 函数实现的是期刊名称的数据比对、精确返回数值;IFERROR 函数实现的是在工作表中对正常的返回报错信息(如未在源数据库中找到所输入期刊名)进行屏蔽,简化界面上的非必要信息显示;ROW 函数与工作表调用函数“目录详情!B1”共同实现了对一个期刊在不同年代多次被收录情况的显示。此功能的实现,使得“用户界面”下有条件在检索结果的显示区域取消“过渡统计”字段,这是通过对“检索界面”的“过渡统计”字段下的检索结果再检索做到的。
(4)判断被收录次数。如图4所示,为配合实现ROW 函数的功能,在“目录详情”工作表中增设了一个空字段,命名为“空字段”,其下每个同列单元格内录入公式“=C2&COUNTIF(C$2:C2,C2)”,作用是先将多次被收录的期刊统计出来,并在期刊名称后加缀是第几次出现,如“全球定位系统4”,则数字“4”为在查询过渡界面下的“类别”“年代”等字段下显示4次被收录情况奠定基础。
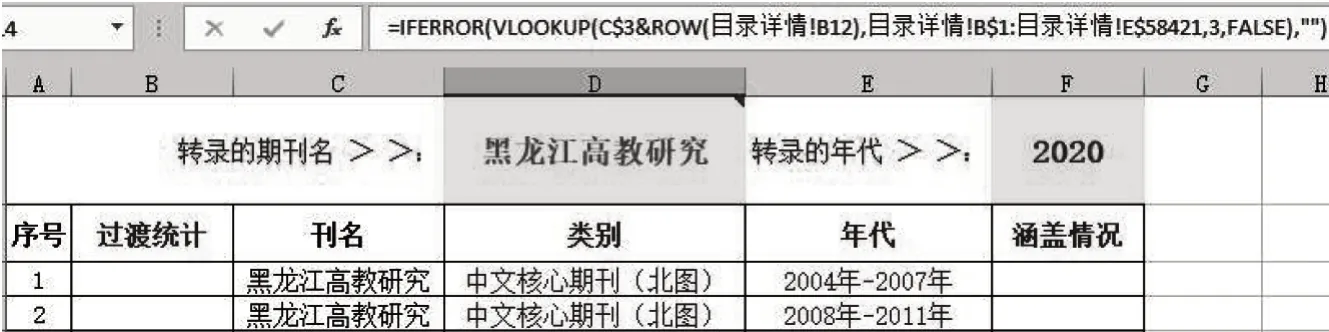
图4 判断被收录次数
(5)检索被收录年代。在“年代”字段下,于同列单元格内则录入公式=IFERROR(VLOOKUP(C$3&ROW(目录详情!B6),目录详情!B$1:目录详情!E$58421,4,FALSE),""),如图5 所示,多个函数共同作用,对输入的期刊名称在“目录详情”工作表中能够查询检索到的,则可以显示出相应被收录到该核心期刊统计源目录的“年代”信息。
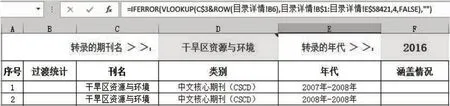
图5 检索被收录年代
(6)检索特定年代被不同目录收录情况。在“检索工作表”中增设“不同目录收录”区域,亦设“过渡统计”字段,其下同列单元格内录入公式=IFERROR(VLOOKUP("涵盖"&F$1&"年"&ROW(B1),B$1:F$41,1,FALSE),""),如图6所示,在本表检索区域“过渡统计”字段下COUNTIF函数配合下实现了对特定年代(用户输入)被收录进不同核心期刊统计源目录的次数,又为在单独区域开辟界面,向用户更加集中地显示指定年代被各核心期刊统计源目录收录的数据奠定基础。

图6 检索特定年代被不同目录收录情况
3 功能的开放性
3.1 数据源内容的更新
对于四大核心期刊统计源目录研制单位2021 年12 月31 日后新发布的版次,本研究对存量数据库与增量数据库的关系进行了处理[17],每年只需要将新数据导入到本系统的源数据库的末端,并将相关查询检索公式、函数中的范围作相应增加即可,无需作任何结构上的调整。
3.2 数据源范围的扩展
目前我国有三大期刊数据库,即中国知网(CNKI)、万方数据、维普期刊的期刊数据库,这三大期刊数据库均构建了各自的核心期刊库。实现数据源范围扩展的意义在于,将三大期刊网站核心期刊库所收录的核心期刊目录作为新的源数据,扩展并构建中文核心期刊目录查询检索的自动化,为用户提供更多样、更便利的信息选择。
3.2.1 期刊数据库核心期刊目录数据转化的可行性
以三大期刊数据库中影响力最大的中国知网(CNKI)为例来分析,其网站提供了以学科分类的核心期刊导航栏目,并可用详情(图片)、列表(文字)两种方式展示核心期刊信息。经网站首页的“出版物检索”,沿“出版来源导航”“期刊导航”到达“核心期刊导航”,再从“第一编 哲学”等至“第七编工业技术”,共计1986条收录的核心期刊中查询信息。如图7所示,可以获取列表方式显示的核心期刊目录数据,并利用计算机应用程序将其转化为excel表格格式。可将数据中的“期刊名称”字段作为关键词,为新类型源数据的转化提供操作性和可能性。
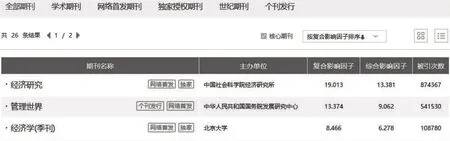
图7 中国知网(CNKI)核心期刊目录信息
3.2.2 期刊数据库核心期刊目录数据可检索信息的扩展
根据三大期刊数据库核心期刊目录信息的特点,应从两个方向进行研究,实现核心期刊目录可检索信息的扩展。一个方向是在现有数据库中增加“复合影响因子”“综合影响因子”“被引次数”三个字段,为以此进行检索提供新参考。另一个方向是在源数据库中,增加“学科分类”字段,提供以学科为关键词的检索新类型。为实现这些检索,本研究设计的自动化检索工具除相关计算机应用的框架、程序以及使用的具体函数公式等思路可以延续外,在界面的组织上还需要进行相应的调整,在网络信息安全的保障上[18]还需要加强,为本研究的深入拓展预留了空间。
4 总结
文章以当前中文核心期刊目录检索方式繁琐、检索效率较低、比对不便利等为问题驱动,以简洁、高效、全面为目标,研究了中文核心期刊目录自动化检索工具的设计与实现。作为对比源,汇总整理并转化生成了涵盖历史时间段长、权威性高的中文核心期刊统计源目录数据库,为检索工具的运用奠定了目录数据的基础。开发软件的选择,体现了检索工具环境要求简单、友好的特点,在实践中容易实现,用户易于掌握。基于期刊名的主题检索,是中文核心期刊目录检索的最关键检索;基于年代的检索,反映了核心期刊在不同年代被收录的变化情况;基于同一期刊被收录次数的检索,则实现了直观向用户集中呈现同一年代被不同核心期刊统计源目录收录的情况,它们共同完成了中文核心期刊自动化检索的信息服务任务。
