基于时序感知的动态知识图谱补全方法
2022-08-09李凤英范伟豪
李凤英,范伟豪
桂林电子科技大学 广西可信软件重点实验室,广西 桂林 541004
知识图谱是知识工程的最新产物,作为一种可存储和计算的信息载体,在以知识驱动的人工智能领域有诸多实践,如信息检索[1]、推荐系统[2]、智能问答[3]。知识库通过三元组(s,r,o)构成。每个三元组反映一个知识事件,该事件包含头实体(subject)、尾实体(object)以及两者间关系(relation)。这三者分别对应图结构中的两个节点及相连的有向边。目前较大的百科知识库如Freebase[4]、YAGO[5]、DBpedia[6]都来源于大量的网页信息。然而这些知识图谱并不完整,一部分原因是源数据所含的知识并不充分,另一部分则与提取实体和关系的算法能力有关[7-8],在处理各类非结构化数据效果并不理想。不完善的数据会导致以知识驱动的应用效果下降,因此补全完善知识库对于知识图谱的利用十分必要。
知识图谱补全(knowledge graph completion,KGC)是通过学习知识库内在结构和相关语义信息,对实体间潜在的关系进行补全。相关研究通常给定一种刻画实体关系相关性的建模理论,通过训练得到实体向量和关系向量。实体间缺失的关系链接可通过计算实体和关系之间的相似性进行评估预测,从而达到补全的目的。
传统KGC的研究工作是在三元组构成的静态知识图谱下对多关系建模。自TransE[9]方法的提出以来研究者们尝试了多种建模方式:一部分工作是利用关系的语义特征,设计出满足关系间多种性质的相似性理论,其性质涵盖对称性、反对称性、自反性和组合性[10];另一部分研究是利用了知识图谱中的结构信息对实体关系建模,如基于关系路径的方法[11]以及基于节点邻域特征的方法[12]。
在知识应用过程中,历史事件必须限定在特定时间才具有参考价值,即知识存在时效性。近年来出现了带有时间标签的动态知识图谱(dynamic knowledge graph,DKG),也有部分研究人员称作时序知识图谱(temporal knowledge graph,TKG)。其基本单元是在三元组的基础上加入时间信息(time)的四元组(s,r,o,t)。随着事件的不断演进,动态知识图谱可以不断更新,提供时间维度的知识内容,更具研究价值。图1举例了静态和动态知识图谱表示国家建交事实的异同。静态知识图谱叠加了所有历史事实,通过图谱结构能够利用相对完整的全局信息。而动态知识图谱则以演化的视角,展示事件的发展变化。从知识的利用角度,通过聚焦多个时间事实,动态知识库相比静态知识库能够反映出更加丰富的信息。

图1 静态知识库和时序知识库对比Fig.1 Comparison between static KG and dynamic KG
由于传统KGC方法是面向三元组建模,其相似性评估计算仅涉及实体和关系,缺乏时间维度信息,因此并不适用于动态知识库的补全。动态知识图谱补全方法除了对实体关系建模,更重要的是在四元组相似性评估中充分利用时间特征。
目前该领域的部分工作是将时间特征内嵌于实体和关系之中。此类方法将不同时间看做彼此互不重叠的时间空间,通过将实体和关系映射在不同的时间超平面,将四元组转化成三元组,以沿用传统KGC方法对实体和关系进行相似性评估。然而在现有的动态知识库中,关于时间信息的描述包含时间点、时间起止、时间段三种形式,且时间分布的稀疏程度影响映射效果。不规则的时间描述以及时间分布的稀疏性都限制了补全动态知识库的实际效果。而其他面向动态知识图谱的补全研究尝试将时间维度进行独立建模,将时间向量引入相似性评价过程。但实际上仅在代价函数中作为参数使用,并没有充分考虑时间特征对于四元组更深层的含义。表1对比了现有补全方法在相似性理论和知识维度建模的差异。通过对比可知,适用于动态知识库的补全方法应该具备能够对知识各维信息实施建模,且必须利用时间特征以及充分体现时间维度与其他相关维度的深层联系。

表1 用于知识图谱的补全方法对比Table 1 Comparison of approaches for knowledge graph completion
为了解决四元组中时间维度利用不充分的问题,设计出的时序感知编码器(temporal aware encoder,TAE)将四元组中的时间与其他实体和关系建模为规模相同的嵌入向量。TAE改进了图卷积神经网络[21],利用注意力权重有侧重地学习邻域时序信息。同时设计的时序卷积解码器(temporal convolutional decoder,TCD)用于对编码后的时序四元组进行全局相似性评价。这样的方式可以学习到更精确的时间维度特征,提升补全时序图谱的性能。通过在ICEWS14、ICEWS05-15、Wikidata12k和YAGO11k数据集上的实验,验证了时序感知补全方法的有效性。对比相关研究性能指标,时序感知补全方法在链接预测表现较优。
1 相关工作
1.1 静态知识图谱补全方法
静态知识图谱补全研究重点在于如何刻画实体与关系的相关性。根据知识来源、静态知识图谱可以分成百科类知识图谱和垂直领域知识图谱。百科类知识由于来源于大量网页信息,关系数量相对较多。缺乏统一的内容规范,百科知识图谱存在相对复杂的语义关系,表现于两个实体同时存在多种关系。这要求补全方法能够充分表示实体的多维特征。而垂直领域知识图谱来源于行业专家编写和鉴定的细分知识,事实内容描述简洁,关系种类相对较少。大量的实体仅通过较少的关系联系,这要求建模关系需要克服一对多和多对多的难点。
早期Bordes等人发现三元组中的实体和关系在向量空间中满足几何向量加的特点s+r≈o,设计出翻译方法TransE[9]。Yang等人借鉴张量分解理论提出DistMult[13]方法。实体映射为低维向量后,再计算与每种关系的相似性。在二者开创性工作的基础上,研究工作不断改进完善。从关系语义角度出发,Sun等人分析了关系存在的多种性质,如对称性、反对称性、自反性和组合关系,利用欧拉恒等式,提出将实体和关系映射到复数向量空间,并将每个关系定义为头实体到尾实体的旋转。除此以外,知识图谱的结构信息也被利用到多关系建模。PTransE[11]扩大了建模视野,对整条实体关系组成的路径建模表示。R-GCN[22]将关系赋予不同的权重,通过图卷积神经网络实现邻域特征学习表示,并采用DistMult作为解码器进行相似性评估。
1.2 动态知识图谱补全方法
动态知识图谱补全研究对于时间维度知识的思考更多[23-24],除了考虑静态知识图谱补全中的实体和关系,更需要注重时间维度的信息建模。相比“头实体—关系—尾实体”的指向性联系,时间信息是更加全局性的知识维度,能够从更多角度解读,有着更灵活的建模方式。按照时间信息的利用方式,现有动态补全方法可以分成时间内嵌补全方法和时间独立补全方法。二者区别在于是否将时间维度同实体关系一样表示学习得到特征向量。
时间内嵌补全方法是把时间信息内嵌于实体和关系中,仅建模实体关系。本质上该类方法是把四元组降维成三元组后使用静态补全方法。Dasgupta等人把特定时间中的实体和关系看成一个静态知识图谱,提出的HyTE[16]方法将不同时间视作不同的时间超平面,四元组的实体和关系通过映射函数在某个超平面中得到三元组(Pt(s),Pt(r),Pt(o))表示,再利用翻译思想补全。García-Durán等人将时间和关系合并成一个维度。合并后的文本序列通过LSTM计算得到含时间特征的关系rseq,由此将四元组转化为带有时间特征的三元组(s,rseq,o),结合三元组建模思想,设计出TA-DistMult和TA-TransE[17]。Zhang等人通过注意力机制将时间信息融合进实体当中,同样结合三元组建模思想,设计出ST-TransE、ST-DistMult和ST-ConvKB[18]。DySAT[25]方法同时关注图结构和时间演进过程。按时间划分的事件通过自注意力学习邻域信息,再通过联合注意力学习时间推演下的三元组相似性。
时间独立补全方法则是学习四元组的四个维度向量表示,方法中相关计算引入时间向量。TTransE[19]延伸了TransE方法,将时间加入到实体关系在几何向量空间中的运算f=|s+r+t-o|。相同地,TComplEx[20]延伸了Compl Ex[14]方法,将时间加入到复数域下进行张量计算以评估四元组相似性。TeLM[26]方法利用线性时间正则化器和多向量嵌入进行四元组张量分解评估相似性。
2 时序感知补全方法
现有对于动态知识图谱的补全工作,大都将时间特征内化到实体和关系当中,仅对实体和关系建模,时间维度没有得到建模表示。忽略了时间向量在下游任务中被利用的可能。与此同时适用于三元组的相似性理论并不能直观地反映动态知识库各维度信息的相关性。因此时序感知补全方法借鉴时间独立补全方法中对于时间维度独立建模,同实体和关系表示成规模相同的嵌入向量。根据表1中面向四元组的补全方法,TTransE[19]和TComplEx[20]虽然能够对时间维度建模,但未能考虑到时间特征与实体和关系间的关联性。因此时序感知补全方法在时间独立建模外还将时间特征融合参与到其他维度,以更充分表示四元组各维度,达到更佳补全效果。
时序感知补全方法整体框架如图2所示,包含时序感知编码器(temporal aware encoder,TAE)和时序卷积解码器(temporal convolutional decoder,TCD)。TAE改进了图卷积神经网络(graph convolutional network,GCN),将四元组中的各维度嵌入为规模相同的向量,每个节点通过改进的图注意力机制[27]达到有侧重地学习邻域特征。TCD将所有四元组(s,r,o,t)在k维空间下嵌入表示为一个k×4的输入矩阵,改进卷积神经网络,采用1×4的不同卷积核来提取嵌入四元组的全局关系,从而评估四元组整体的相似性。
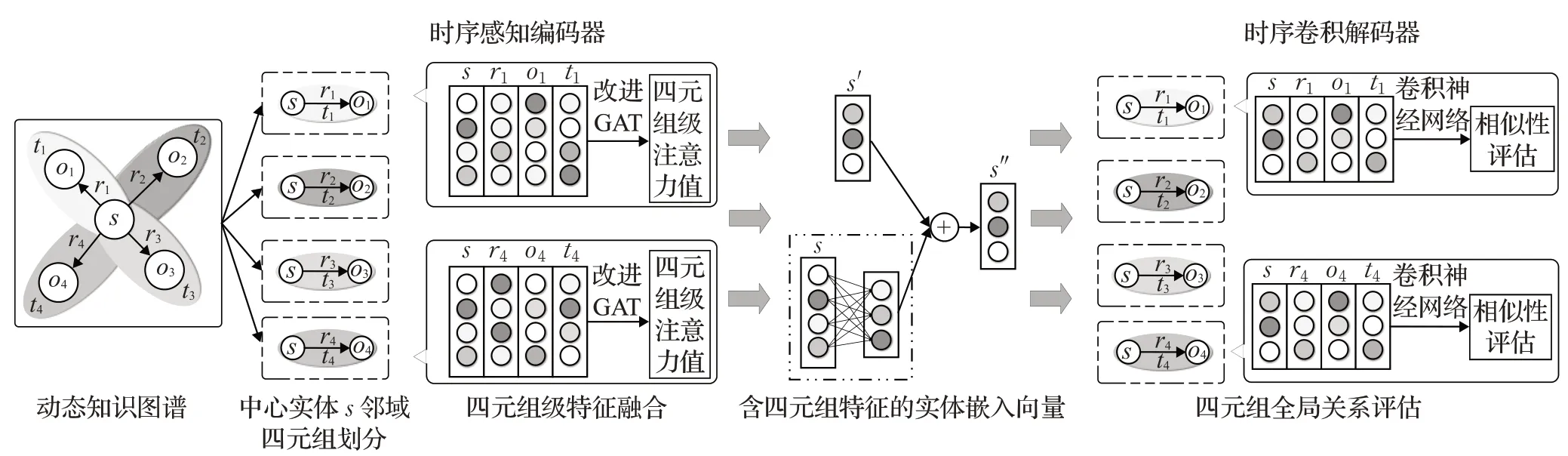
图2 用于动态知识图谱补全的时序感知方法整体框架Fig.2 Structure of temporal aware approach for dynamic knowledge graph completion
2.1 时序感知编码器
动态知识图谱定义为G=(E,R,T),其中E={e1,e2,…,ea}、R={r1,r2,…,r b}和T={t1,t2,…,t c}分别为实体集合、关系集合以及时间集合。基本单元为四元组tp ijkm=(ei,r k,e j,t m),表示在时间t m下,两个相连的实体e i和e j,通过关系r k连接构成的事件。
TAE将时间维度同实体关系相同处理,建模为一个嵌入向量,即四元组的嵌入表示为x i、y k、x j以及t m。TAE借鉴了图卷积神经网络的特性,以充分学习动态知识库中实体、关系以及时间三者间的交互特征。图卷积神经网络因其能够汇聚邻域节点特征到中心节点,已成功应用在各类图表示学习任务中。而图注意力网络[24]将邻域权重进一步改进为注意力值。相比无向图,动态知识库的图结构中关系和时间维度有着独特的含义,因此TAE改进了图注意力网络的特征学习过程,中心节点通过汇聚邻域四元组特征进行表示学习。具体步骤如下:
如图2所示,首先以同一中心节点s为头实体的邻域四元组划分。将每个知识单元中头实体s、关系r、尾实体o、时间t对应的向量x i、y k、x j以及t m,拼接成一个四元组矩阵。如公式(1)所示,得到该四元组的嵌入向量表示z ijkm:

其中,A为线性变换矩阵,用于降低四元组矩阵维度。
邻域中不同四元组特征对于中心节点的影响并不相同。为了有侧重地学习中心节点的邻域特征,TAE将注意力值作为涉及的四元组对中心节点的贡献程度。根据每个四元组嵌入向量,分别计算注意力值p ijkm:

其中,W为权重矩阵,LeakyReLU是选用的激活函数。为了调整注意力值的大小避免出现较大的差值,针对公式(2)计算的注意力值进行归一化处理,得到四元组级注意力值为q ijkm:
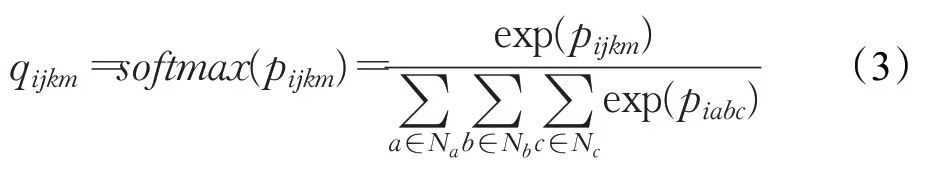
其中,归一化函数采用softmax,exp表示以e为底的指数次幂。N a表示邻域四元组中尾实体集合,Nb表示邻域四元组中包含的关系集合,N c表示邻域四元组涉及的时间集合。公式(1)~(3)相关计算如图3所示,经过上述步骤得到了四元组级注意力。

图3 时序感知编码器中四元组注意力计算过程Fig.3 Process of computing 4-tuple feature in TAE
结合注意力值,中心节点s通过汇聚邻域四元组特征更新其嵌入向量x i,如图2中“四元组级特征融合”所示。其邻域四元组嵌入向量与归一化后的注意力权重聚合后相加,如公式(4)通过激活函数得到更新后的嵌入向量x′i:

为了防止实体本身特征在迭代更新中丢失,TAE引入网络层输入,如公式(5)所示每次注意力学习到的邻域信息与原实体向量共同更新实体矩阵X”:

其中,X表示实体向量组成的矩阵,X′为本次迭代更新的实体向量矩阵,B为线性变换矩阵用于匹配矩阵规模。经过多次迭代,实体矩阵学习到了时序知识库的多维特征,为了保持输出的规模相同,通过权重矩阵实现关系矩阵R′和时间矩阵T′的输出:

其中,R表示关系向量组成的矩阵,W R为关系的权重矩阵,T表示时间向量组成的矩阵,W T为时间的权重矩阵。
训练的优化目标采用TTransE[19]的思想,使用铰链损失来优化TAE,单独四元组损失为dist(tpijkm)=,全体四元组优化目标为:

其中,S为原知识库存在的四元组集合,而S′为负采样生成的四元组集合,目的是为了增加训练样本。S′是通过置换存在四元组的头尾实体得到的污染的四元组。γ表示误差边界。
2.2 时序卷积解码器
动态知识库经TAE编码后,中心实体通过聚合邻域特征,捕获了四元组中多个维度的特征。特别包含了表1提到的此类方法未能充分利用的时间维度特征。为了补全动态知识库,需要评价四维信息的相似性。ConvKB[15]方法利用卷积神经网络能够在卷积核视野下对三元组相似性评估。设计的TCD改进了其网络结构针对四元组相似性评估,如图4所示。针对嵌入后规模为k×4的四元组作为输入矩阵,卷积层采用多种规模为1×4的卷积核,从多个角度提取四元组特征。计算得到的特征向量通过矩阵转换成数值来评价四元组的相似程度。TCD评分函数为:

图4 时序卷积解码器相似度评估过程Fig.4 Process of computing similarity in TCD

其中,ωm表示第m个卷积核,Ω表示超参数,*表示卷积操作,C为线性变换矩阵。
TCD采用软边界损失训练网络参数,同样通过负采样增加训练样本。损失函数如下:
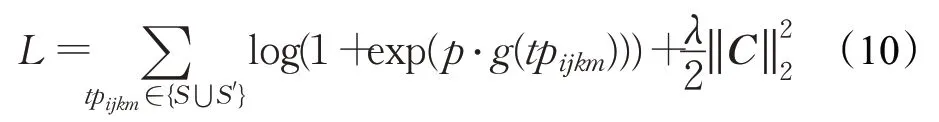
其中,p的取值与tp i jkm的关系为:当tpijkm∈S时,p=1;当tp ijkm∈S′时,p=-1。
3 实验及分析
为了验证所提出的时序感知编码器以及时序卷积解码器的有效性,在4个公开的数据集上进行了链接预测实验。在多项数据指标上观测补全效果并给出相应分析。
3.1 数据集
综合危机预警系统(ICEWS)是目前公开的最大动态知识库。已有198个国家为该数据集提供自1995年至2018年的1 700多万次政治事件。其主要来源于社交媒体和新闻媒体等。García-Durán等人将ICEWS划分为多个子数据集。其中ICEWS14[17]记录的是2014年内的政治事件,时间稠密。而ICEWS05-15[17]的时间跨度较长,从2005年至2015年近10年的政治事件。YAGO11k[16]是截取静态数据集Freebase15k的实体,通过YAGO知识图谱的实体对应,提取关系,最后根据yagoDateFacts中相关记录提取时间信息。Wikidata12k[16]是从维基百科知识库中提取的时序事件,但该数据集中增加了时间修饰语“occursSince”及“occurUntil”。数据集涉及实体关系和时间统计信息如表2所示。

表2 动态知识图谱数据集信息统计Table 2 Statistics of dynamic knowledge graph datasets
3.2 评价指标
知识图谱补全的测评任务为链接预测,它的目标是根据已知的节点和边,得到新的边(的权值/特征)。其评价指标有命中率(Hit@1/3/10)、平均排名(mean rank,MR)和平均倒数排名(mean reciprocal rank,MRR)。训练集中对所有三元组训练方法参数,测试集验证真实三元组的排名情况,进行记录统计。共有Ttest个测试集三元组,rank i表示打分后的排序名次,Hit@X、MR及MRR的计算如下:
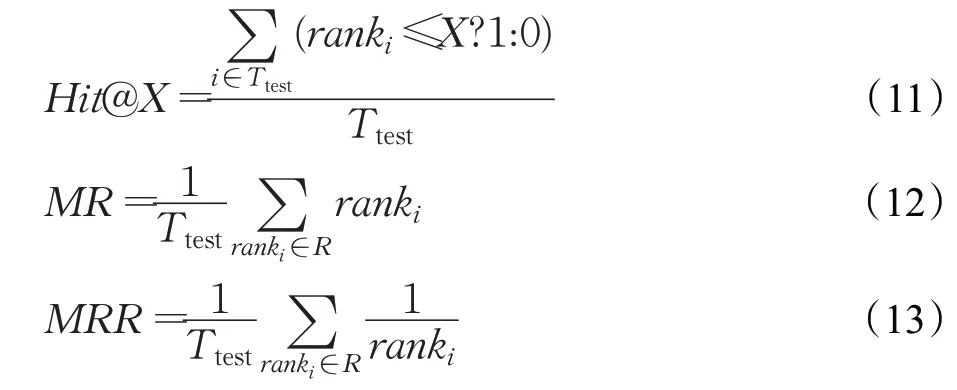
其中,Hit@X表示真实三元组在前X中出现。
Hit@1得分高说明方法对原本的实体关系学习较好,在当前知识库中命中率高,补全效果佳;Hit@10得分高说明实体关系学习潜在表现较好,在多个数据集上Hit@10较高分数则说明方法的泛化能力强;Hit@3介于Hit@1和Hit@10之间。方法的全局表现通过MR和MRR体现,与MR相比,MRR在遇到异常数据的情况下数值变化不大,即对个别异常数据不敏感,所以目前研究工作更多采用MRR评价补全方法的综合表现。
3.3 实验结果及分析
为了分别验证时序感知编码器(TAE)和时序卷积解码器(TCD)对于动态知识图谱补全的有效性,在四个公开的数据集上进行了链接预测实验,结果如表3和表4所示。其中“TCD”的数据是仅采用时序卷积解码器的补全效果,其输入为随机初始化的四元组向量;而“TAE+TCD”的数据则是联合了时序感知编码器和时序卷积解码器的实验效果,此处TCD的输入是经TAE训练得到的四元组向量。为了与相关动态知识图谱补全研究分析,实验中列举了相关工作中提到的动态知识图谱补全工作,其数据来源于TeLM[26]及ST-ConvKB[18]。在ICEWS14、ICEWS05-15、Wikidata12k和YAGO11k数据集上,仅TCD补全方法在Hit@3和Hit@10指标上超越了其他工作,说明仅TCD补全方法的泛化能力较强,能够适用于不同动态知识图谱补全。然而在MRR及Hit@1指标上,仅TCD补全方法未能超越相关工作,这是因为TCD虽然对四元组的各维度统一建模,但四元组内部的相互联系并未充分利用。
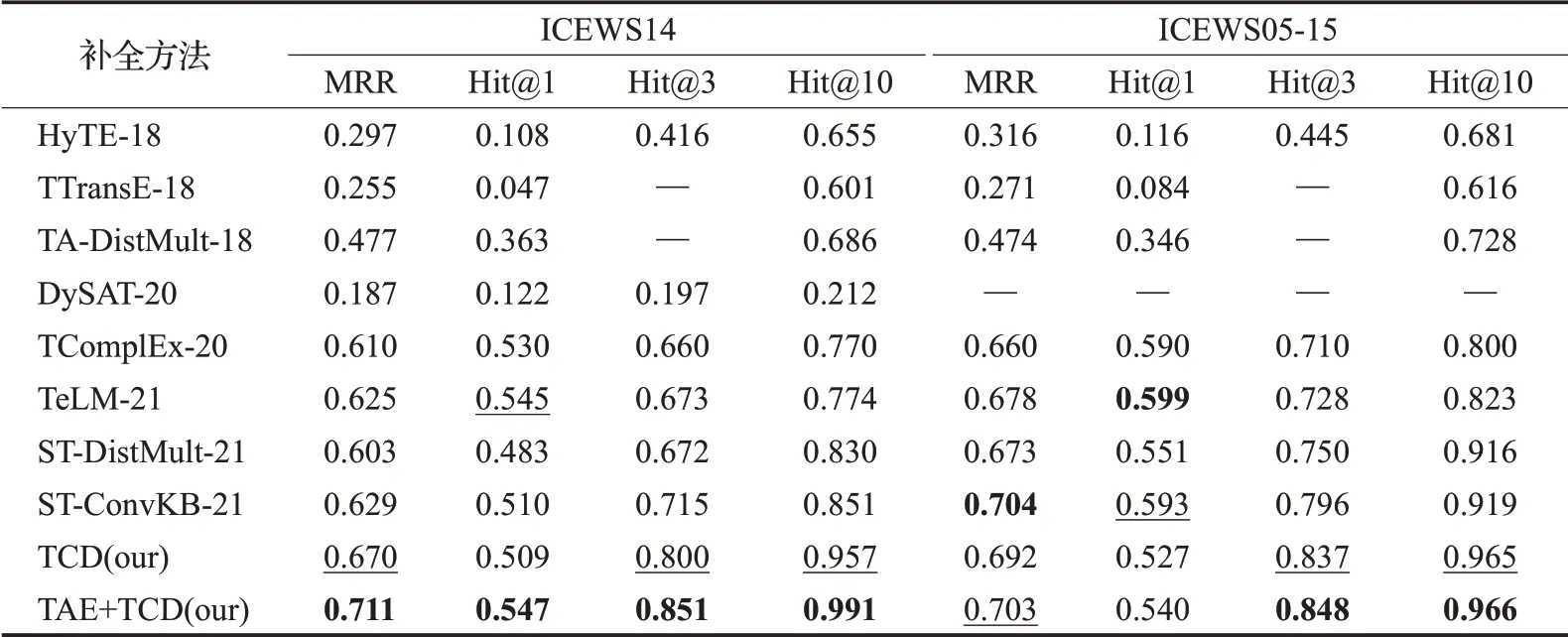
表3 在ICEWS14和ICEWS05-15上的测试效果Table 3 Experimental results on ICEWS14 and ICEWS05-15
通过对比“TCD”和“TAE+TCD”的实验数据,“TAE+TCD”方法在相同数据集下,MRR、Hit@1、Hit@3和Hit@10各项指标都有提升。这说明了TAE通过聚合四元组邻域特征,捕获了四元组内部信息,从而提升TCD的补全性能。这同时验证了TAE作为编码器的有效性。
在ICEWS14、Wikidata12k和YAGO11k数据集上“TAE+TCD”方法在MRR和Hit@1指标上均高于其他方法,在ICEWS05-15数据集的MRR得到次佳的结果,说明了提出的时序感知补全方法对于动态知识图谱补全的有效的。然而在ICEWS05-15数据集的Hit@1指标上,同类时间独立补全方法TeLM和TComplEx效果更好。根据表2的数据集统计信息,ICEWS05-15相比其他3个数据集,实体关系数量差别不大,但时间数量最多,这是因为数据来源时间跨度较大。在多时间建模问题上,TeLM方法通过设置时间约束,降低了时间信息建模的难度;而TComplEx方法对四元组的相关性计算是在复数域空间,相比实数域空间,能够更充分表示时间特征。本方法虽然也对时间信息单独建模,但提取多时间特征仍存在提升空间。
4 总结与展望
本文提出了用于动态知识图谱补全的方法,由时序感知编码器和时序卷积解码器两部分构成。本方法能够对时间维度单独建模,且充分考虑了时间维度与实体关系的相关性。通过链接预测实验,分别验证了时序感知编码器以及时序卷积解码器的有效性。与目前动态补全工作相比,时序感知补全方法在多项衡量指标上获得提升,取得较好的动态知识图谱补全效果。但在更复杂的动态知识库中,提出的方法仍存有提升空间,未来将改进方法,以适用于补全多时间的动态知识图谱。除了解决动态知识库补全任务,时序感知编码器也提供了将四元组建模思路。未来将尝试融合本方法,适用于动态知识图谱的推理及问答等应用。
