基于改进关联规则挖掘的变压器油中溶解气体分析模型
2022-08-09邓佳乐孙辰昊岳一石易洲楠李绍龙
邓佳乐,孙辰昊,胡 博,岳一石,易洲楠,李绍龙
(1.国网四川省电力公司天府新区供电公司,四川 成都 610213;2.长沙理工大学电气与信息工程学院,湖南 长沙 410114;3.国网河南省电力公司,河南 郑州 450000;4.国网湖南省电力有限公司长沙供电分公司,湖南 长沙 410015;5.国网湖南省电力有限公司电力科学研究院,湖南 长沙 410007)
电力变压器作为输电线路系统中最重要的设施之一,其稳定运行至关重要。任何类型的变压器故障都可能导致电力供应的中断,进而对电网造成极大的损失。考虑到变压器故障通常发生在运行期间,因此,依据变压器内部特性进行及时有效的故障诊断,就能够在第一时间实施针对性的应对措施,从而大大减少潜在故障风险。
同电气参数一样,变压器所含绝缘油中溶解气体的含量也能够提供变压器运行状态的有效信息,但不同之处在于其基本不受变压器内电磁环境变化的影响。因此,变压器油中溶解气体分析(dissolved gas analysis,DGA)常被用于变压器的故障诊断[1]。
目前,许多研究者提出了大量关于DGA的研究思路,也取得了可观的成果。第1类是基于优化算法的DGA方法。文献[2]采用基于改进量子粒子群优化支持向量机算法实施变压器故障诊断,能够进一步提高方法的全局搜索能力;针对变压器故障诊断,文献[3]基于征兆子集筛选效果设计了一种征兆优选方法,筛选出的征兆子集相较于传统比值方法具有优势;文献[4]通过结合遗传算法和支持向量机,实现针对DGA特征量的优选。基于优化算法的DGA方法往往能够获取直观的故障概率,但必需统计时段较长的大容量数据,对输入数据的要求较高。第2类是采用神经网络的DGA方法。文献[5]在变压器振动机理的基础上,利用自组织特征映射神经网络,提高了变压器故障诊断效率;文献[6]针对传统深度信念网络方法中存在的误判,构建组合DBN故障诊断方法,提高了故障诊断效果;文献[7]将卷积神经网络应用在变压器故障诊断中;文献[8]基于模糊神经网络和局部统计提出了一种变压器状态评估方法。基于神经网络的DGA方法一般拥有较强的稳定性和容错性,但一般需要较大容量的输入数据。第3类是基于向量机的DGA方法。文献[9]通过BP神经网络为基于支持向量机的变压器故障检测选择输入特征,提高了准确率;文献[10]结合AdaBoost算法和二次映射支持向量机,提出了变压器故障诊断模型;文献[11]应用支持向量机实现对变压器故障的分类与判别。尽管基于向量机的DGA方法结果一般为全局最优,但较难解决多分类问题。针对以上这些问题,关联规则挖掘(association rule mining, ARM)由于可根据需求选择输入特征或状态,常被应用于DGA方法中。文献[12]搭建一种基于关联规则和变权重系数的变压器状态综合评估的模型;文献[13]为诊断变压器故障,提出了一种结合集对分析和ARM的集成算法;文献[14]将概率图像模型应用到ARM算法之中,进一步提升了效率。尽管上述文献取得了一定进展,但依然存在一些可改进的地方。首先,传统ARM算法通常采用固定统一的重要度评估标准,故一些出现频率较低的数据将被直接筛除。但在这些罕见数据中同样存在能够引起故障的高危数据,所以也应该予以分析;其次,输入数据的风险权重应该由其所产生的风险决定,而非出现频率;最后,这些ARM方法的运算效率还可以进一步被提升。
针对上述问题,本文提出一种基于加权关联规则挖掘(weighted association rule mining, WARM)模型的DGA方法。在该模型中,针对罕见数据改进重要度评估标准计算方式,从而从罕见数据中筛选出罕见高危数据并加入后续分析中,而非直接舍弃。首先基于组件重要度测量(component importance measure, CIM)提出一种基于输入数据自身影响程度的风险权重计算方法;然后应用Relim挖掘流程进行运算,比传统Apriori算法运算速度快;最后基于某实际系统变压器运行状态数据实施实例仿真,验证所提方法能够同时改善变压器故障诊断的正确率、运行效率以及现实应用中的可信度。
1 加权关联规则挖掘模型
1.1 关联规则挖掘原理
ARM算法最早由Agrawal等提出[15],其主要目标是挖掘数据库中各个变量之间的隐含关系。
假设I为一个包含所有物品的集合,X与T是I的子集,X被称为物品集,T被称为目标集。假设D={t1,t2,…,tm}为包含所有记录的数据库,其中每一条记录均由物品集和目标集组成。若X与T之间不存在交集,且挖掘结果显示:若X出现时目标T也会发生,则一条关联规则可以被表示为X→T。
通过对输入数据进行判别,能够获取相应高频物品集,并进一步构建出关联规则。目前,通常采用重要度评估标准实现高频物品集和关联规则的筛选。
支持度(Support)[16]用于挖掘高频物品集,可被写为包含物品集X记录的基数在所有记录的基数中所占比例,即
(1)
置信度(Confidence)[16]用于验证所挖掘的规则是否为关联规则,可由数据库中所有同时含有X与T记录的基数在含有X的记录的基数中所占比例来表示,即
(2)
关联规则挖掘的过程通常可概括为2步:①使用预设的支持度阈值挖掘数据库中的高频物品集;②基于选出的高频物品集,采用预设的置信度阈值筛选出相应的关联规则。
1.2 输入数据的预处理
参照行业标准[17],本文选取7种变压器中溶解气体作为输入特征,其中包括:氢气(H2)、甲烷(CH4)、乙炔(C2H2)、乙烯(C2H4)、乙烷(C2H6)、一氧化碳(CO)的相对产气速率及二氧化碳(CO2)的相对产气速率。所研究的7种变压器状态包括正常工作、低温过热、中温过热、高温过热、低能放电、高能放电及局部放电。
为方便后续数据挖掘,需要将数据进行预处理并实现整合。
假设{t1,t2,…,tm}为一个包含D中各条记录编号的向量。假设C={c1,c2,…,cj,…,c7}为一个包含7种输入特征的向量,其中cj为其中任意一个特征。对于cj,假设{vj,1,vj,2,…,vj,k,…,vj,l}为其中包含所有特征量数值的向量。假设T={T1,T2,…,Ti,…,Tm}为包括所有记录中变压器状态的向量,其中Ti为其中任意一条记录中的变压器状态。Ti可能属于所有7种变压器状态中的一种,即Ti=T(o)∈{T(g1),T(g2),…,T(g7)}。综合以上假设,能够构建数据的整合空间矩阵为
(3)
式中iij为第i行记录中的一个物品,即所在列对应的特征cj中的任意一个特征量数值vj,k。
1.3 重要度评估标准的改进
作为输电线路系统中最重要的组件,变压器的正常稳定运行需要得到首要保障。不可否认的是,对于一些出现较少的溶解气体数值的分析与诊断将在一定程度上增加运维检修成本,但能够将现实中所有可能出现的情况设计相应预案,从而将变压器的潜在故障风险降至最低。因为当这些罕见高危特征量数值导致变压器故障时,同样将引起严重的损失。因此,对出现频率较少的罕见数据进行诊断,能够从中挖掘出真正的罕见高危数据。如此,一方面能够在将来这些罕见高危数据再次出现时,保证快速应对,另一方面也能有效地改善整体诊断准确率。
目前对于所有的输入特征,传统ARM算法中通常采用预设且相同数值的重要度评估标准计算公式计算重要度得分。由文1.1节中的背景介绍可知,对于含有出现罕见数据的记录,由传统重要度评估标准计算公式所计算的得分一般较低,容易低于所设置阈值从而被直接筛除。为改进这一不足,本文对原有重要度评估标准计算公式进行改进,基于式(1)、(2)提出了一套可变的状态重要度评估标准计算公式。通过应用这一套状态重要度评估标准计算公式,包含各个特征中的罕见数据的记录将被单独提出,并由为该特征所专门生成的状态重要度评估标准计算公式计算相应得分,再与所设阈值相比较。这样便能够得出基于该特征中罕见数据的高频物品集和关联规则。
首先,将所有记录中的物品集划分为两部分,并重新写为
Xc+Xs→T
(4)
式中Xc、Xs分别为含有常见数据的物品集和含有罕见数据的物品集。
由此,对于含有任意特征cj中罕见数据的记录,相应的状态重要度评估标准计算公式为
(5)
(6)
式中 |·|为同时满足其中所有条件的故障记录的基数;T(o)为7种变压器状态中的一种;H为一个数值区间,取值2~8。
由式(6)可知,对于置信度,a表明存在7种不同形式的置信度计算公式,对应含有7种不同状态的记录,即含有不同故障类型的记录的置信度计算公式也不相同。
1.4 风险权重计算方法的改进
在通过状态重要度评估标准计算公式并基于各个特征进行高频物品集和关联规则的求解后,需要将这些基于不同特征的结果进行汇总。考虑到不同特征量与变压器故障之间的关联程度也不相同,故对于各个输入特征中所有数值的风险权重进行分析。当前大多数研究一般采用特征量在数据库中的占比或出现频率来求解权重。但在现实中,特征量与变压器故障之间的关联程度与该特征量的数据占比或出现频率并没有直接联系。因此,本文为实现更加精确地计算风险权重,采用CIM计算各个特征量数值对于整体故障风险的影响程度作为其风险权重。
(7)


(8)

(9)
通过pivotal分解,式(7)能被线性表示为
IB(k)=h(1k,p)-h(0k,p)
(10)
式中h(1k,p)、h(0k,p)分别为当特征量vj,k确定与变压器故障相关或无关时的整体故障风险。
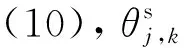
(11)
式中k为共计l个特征量中的任意一个。
1.5 Relim算法原理及优势
目前最为常用的ARM算法是Apriori算法[15]。Apriori算法首先从数据库中筛选出单项高频物品,并采用连枝和剪枝的方法将其逐渐扩展为更多项的物品集,直到这些物品集满足相应要求成为高频物品集。最后通过确定高频物品集进而求解出相应的关联规则。
尽管结果准确,但Apriori算法运行过程中将产生较多的候选物品集,从而导致生成大量冗余规则,降低了运行效率。针对这个问题,Relim算法在运行过程中无需候选物品集,具有结构简单、运行速度快的优点。Relim算法主要通过建立相应的记录链表组求解相应高频物品集。因此,Relim算法无需诸如高频模式树等复杂数据结构,其中所有挖掘过程能够在一个简单的递归函数中完成,加快了挖掘速度。Relim算法的基本流程如下:
1)由数据库中搜索单项高频物品集,按支持度大小排序;
2)将转换后的数据库设为记录链表组,其中各记录链表按头元素支持度大小排序;
3)按顺序依次对每个记录链表进行搜索,挖掘出高频物品集;然后将该记录链表删除,并构建以该链表中头元素为前缀的新记录链表组;将原记录链表组和新记录链表组合并;
4)将所有记录链表挖掘完毕。
1.6 基于WARM的DGA方法的构建
根据上述讨论,本文构建基于WARM的DGA方法,基本流程如图1所示。

图1 基于WARM的DGA方法流程Figure 1 Flow chart of the WARM-based DGA method
基于WARM的DGA方法流程具体如下:
1)对训练数据库中的第一个输入特征中的所有特征量数值采用预设重要度评估标准阈值挖掘出相应罕见数值;
2)将含有该特征中罕见数值的记录集中于数据库子集中,并通过相应特征的状态重要度评估标准得分计算公式挖掘出高频物品集和关联规则;
3)将训练数据库中所有特征依次重复进行前两步;
4)分别计算常见和罕见物品集的风险权重,并汇总;
5)基于风险权重,将测试数据库中的记录依据其所含有的各个特征的特征量数值计算相应的故障风险指数;
6)将故障风险指数与记录的真实结果对比。
2 算例分析
2.1 实验数据
本文采用中部某省区域内高压线路系统中变压器记录进行实验验证。样本数据共计564条,涵盖文1.2节中所引述的7种气体的含量(H2、CH4、C2H2、C2H4、C2H6)和相对产气速率(CO、CO2),以及7种变压器状态(正常工作、低温过热、中温过热、高温过热、低能放电、高能放电及局部放电)。
2.2 实验验证方法
本文采用3∶1的比例划分实验数据,即423条记录作为训练数据,141条记录作为测试数据。
在将诊断结果与测试数据对比时,本文通过接收者操作特征曲线(receiver operating characteristic,ROC)和准确—召回曲线(precision-recall,PR)共同衡量相应对比结果。在这两类曲线的基础上,采用线下包围面积(area under the curve,AUC)为诊断方法效果的检验参数,其中AUC的数值越高则证明诊断越准确。
2.3 整体故障诊断结果
首先,本文将输入数据库涵盖的所有类型变压器故障作为整体,并采用基于WARM的DGA方法对变压器是否故障进行诊断,即变压器的状态仅有故障和正常工作2种。
为验证所提出DGA方法(WARM(Relim))的有效性,加入2种DGA方法作为对比。其中,一种是同样采用改进后的重要度评估标准和风险权重计算方式但挖掘时应用传统Apriori算法的DGA方法(WARM(Apriori)),另一种是采用传统重要度评估标准和风险权重计算方式及Apriori算法的DGA方法(ARM(Apriori))。3种DGA方法基于整体故障诊断结果的ROC曲线及PR曲线对比如图2、3所示,3种方法的运行时间如表1所示。

图2 基于整体故障诊断结果的ROC曲线对比Figure 2 Comparison of the general diagnosis case by the ROC curve

图3 基于整体故障诊断结果的PR曲线对比Figure 3 Comparison of the general diagnosis case by the PR curve

表1 整体故障诊断的运行时间对比Table 1 Comparison of the processing time of the general diagnosis case
由图2、3可知,采用基于改进重要度评估标准和风险权重计算方式的WARM方法相比传统ARM方法,能够实现更为精确的变压器故障诊断。其中,基于WARM和Relim的DGA方法相较基于ARM和Apriori的DGA方法,分别在ROC和PR曲线的AUC数值上提升了17.3%和13.8%。此外,还可以得出应用Relim和Apriori算法得到的诊断结果精确性较为接近,即Relim算法并不能显著改善诊断精度。但由表1可知,应用Relim算法的运行时间相较应用Apriori算法减少了12.3%。因此,本文所提出的基于WARM和Relim的DGA方法能够在减少运行时间的基础上有效地提升诊断精度。
2.4 各类型故障诊断结果
本文对所有7种变压器状态实施分类诊断,所得出的诊断精度与运行时间对比如图4~6所示。
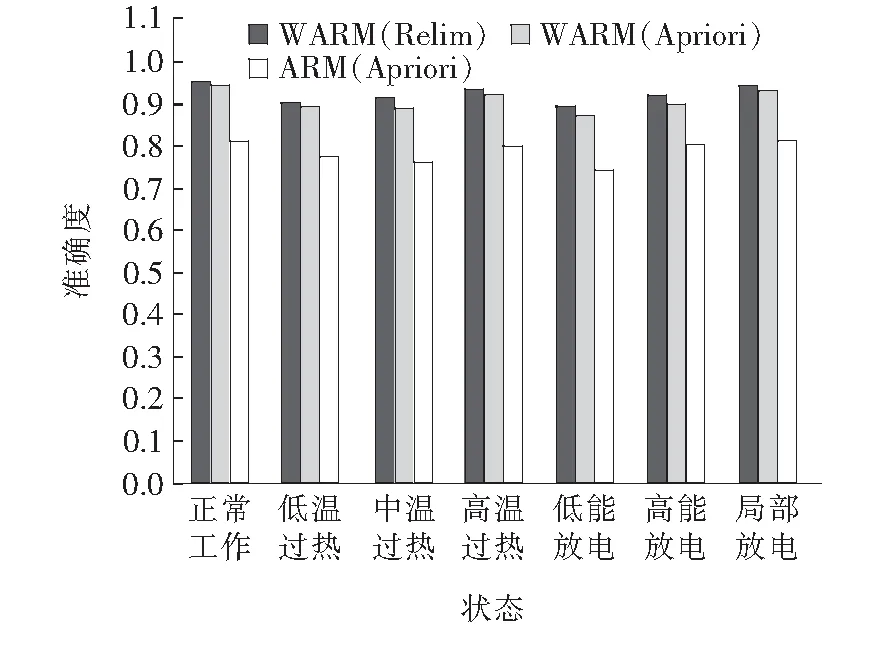
图4 基于各类型故障诊断的AUC(ROC)对比Figure 4 Comparison of the fault diagnosis case by the AUC (ROC curve)
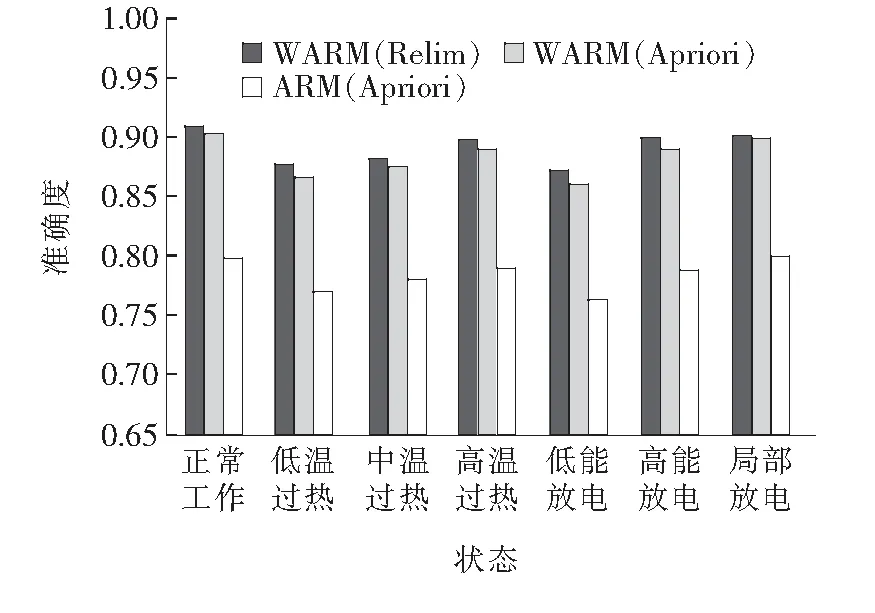
图5 基于各类型故障诊断的AUC(PR)对比Figure 5 Comparison of the fault diagnosis case by the AUC (PR curve)

图6 各类型故障诊断的运行时间对比Figure 6 Comparison of the processing time of the fault diagnosis case
由图4、5可知,对重要度评估标准和风险权重计算方式的改进均能够有效地改善针对所有7种变压器状态诊断的精度。其中,基于WARM和Relim的DGA方法相较于基于ARM和Apriori的DGA方法,分别在7组ROC和PR曲线的AUC数值上平均提升了15.6%和12.7%。由图6可知,应用Relim算法的运行时间相较于应用Apriori算法平均减少了10.7%。因此,对于变压器的不同运行状态,本文所提出的基于WARM和Relim的DGA方法同样能够在减少运行时间的基础上有效地提升针对每一种变压器状态的诊断精度。此外,该方法也能够分析可能出现的罕见高危特征量和变压器故障类型,从而进一步减少变压器出现故障的风险。
3 结语
针对目前基于关联规则挖掘算法的DGA方法中所存在的直接忽略罕见高危数据、特征量权重计算过于简单以及挖掘所需时间较长,本文提出了一种基于WARM的变压器DGA诊断方法,主要研究如下:
1)为将各个特征中的罕见高危数据纳入分析,对重要度评估标准计算公式进行了改进,能够在提升诊断精度的同时涵盖现实中可能出现的极端情况;
2)基于CIM直接求解各个输入特征量导致变压器故障的风险程度,相较基于出现频率能够更加准确地衡量相应的故障风险权重;
3)采用Relim算法进行关联规则挖掘,相较传统Apriori算法能够有效地改善挖掘效率。
实验结果表明,本文所提出的变压器故障诊断方法能够同时改善诊断的正确率、实用性和运行效率。
