基于多典型场景采样的微网可靠性计算方法
2022-08-09徐明忻邢敬舒金国锋刘自发
徐明忻,石 勇,邢敬舒,王 姣,金国锋,刘自发
(1.国网内蒙古东部电力有限公司经济技术研究院,内蒙古 呼和浩特 010011;2.华北电力大学电气与电子工程学院,北京 102206)
为充分发掘和利用海岛藏量丰富的风电和光伏等新能源资源,解决偏远地区和海岛输电困难问题,在中国东部沿海地区的海岛,含有新能源并网的微网已得到广泛应用[1]。这对于基础设施建设相对薄弱的岛屿地区来说,有助于推进海洋事业。但由于独立型微网远离大电网,并且其含有的光伏或风力发电机组出力具有随机、波动特性,其在孤岛模式下的供电可靠性需要进行特别分析。对孤岛微网的供电可靠性进行更准确地评估,对改善供电质量、提升海岛居民电力用户满意度具有重要意义。
当前针对微网的可靠性研究多集中于并网运行的微网以及微网并网对配电系统的影响。文献[2]在分析源荷双侧的不确定性的基础上,对含有风光柴储的孤岛微网进行了优化配置方面的研究,通过对源端模型与负荷端模型不断迭代协调,以达到系统综合成本最小,并以此提高其可靠性;文献[3]对考虑电动汽车充电需求的孤岛微网提出了微网运行策略和负荷分块削减策略,提出了考虑电动汽车的新型可靠性评估体系,对独立海岛上微网的可靠性进行了多方面考虑;文献[4]针对微网内元件的关联属性,利用分时段方法求解微电网的可靠性指标,通过贝叶斯网络的2种逻辑推理方法建立了微网孤岛运行模式下的电源—负荷结点的“动态—供给”模型;文献[5]研究微网对外供电的配电网可靠性,考虑了负荷和光伏发电系统的时序波动特性,提出了2个新的可靠性指标,算例验证了所提方法和指标的合理性;文献[6]在传统解析方法的基础上,改进提出了一种停电序列多状态模型,可用于计算停电序列的概率用以评估岛上用户的停电情况;文献[7]建立了风光储元件的时序模型和状态转移模型,对于不同元件采用不同的抽样方法,讨论不同故障效果对可靠性评估的影响;文献[8]对DG出力随机特性进行了研究,并采用蒙特卡洛时序模拟法评估DG和储能联合运行的微网的配电网可靠性。然而,上述文献均没有考虑到分布式电源与负荷的时间关联性,对于原件或系统状态进行抽样时仅采用单一相同的频率,并不能满足更精准的微网可靠性评估要求。
目前,一些学者尝试利用大数据技术提高可靠性评估计算的准确性[9-10]。文献[11]提出了通过大数据方法的城市低压配电网可靠性指标计算方法,通过大数据技术统计各可靠性指标,从而计算城市配电网可靠性,结论表明利用大数据技术进行可靠性评估比传统可靠性评估方法较准确。然而该方法需要通过处理大量数据,并且其本质仍是统计分析法,因此该方法尚存在一些缺陷。文献[12]提出了利用大数据技术进行配电系统可靠性预测评估的方法,先通过大数据建立神经网络模型,再根据相关数据利用神经网络模型来评估可靠性,该方法需要利用海量数据来保障神经网络模型的正确性,仅仅是数学上的关联,忽略了电网本身的物理特性。文献[13]提出了基于多场景技术的配网可靠性评估方法,通过建立风机出力多场景模型,对风机出力进行场景的提取,采用全概率公式进行综合计算可靠性指标。该方法对风机的出力建立较准确的场景模型,却忽略了电网负荷与风机出力的关联,计算得到的可靠性指标仍有一定的误差。
针对目前评估方法的不足,本文提出基于多典型场景采样的微网可靠性计算方法。首先,建立基于大数据的电网运行典型场景提取方法;然后,提出各典型场景的可靠性计算方法;最后,采用全概率方法计算综合可靠性,并对某微电网系统进行算例分析。
1 基于大数据的电网运行典型场景提取方法
1.1 基于大数据的电网典型场景提取方法
分布式电源出力与负荷具有很强的时间关联性,在计算时应该采取相应时刻的出力,但现有的关于典型场景提取的研究未考虑“出力—负荷”时间关联性。
本文采用k-means算法对电网运行大数据进行典型场景提取。适用于可靠性计算的电网运行典型场景,其核心特征量为电源出力与负荷。将“出力—负荷”看作聚类中心或粒子的信息,以负荷和分布式电源出力2个变量作为数据提取的特征变量,以此体现模型对2个变量时间关联性的考虑。在采用k-means算法对电网运行大数据进行典型场景的提取时,每一个聚类中心都是一个典型场景,而该类中所包含的粒子数量即为适用该场景的时间长度。因此,各典型场景的概率分布,即算法的畸变函数和聚类中心的更新公式为
(1)
(2)
对于聚类个数的确定,本文采用Validity(k)指数来寻找最优的聚类个数[14]。计算公式为
(3)
式中Ck为第k个类。
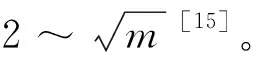
根据上述方法,电网运行典型场景提取模型计算流程如下:
1)输入聚类中心个数K和待分类数据集;
2)初始化k个聚类中心;
3)计算各粒子与各聚类中心的距离,将每个粒子归类到距离最近的类中;
4)根据式(1)计算畸变函数;
5)判断2次迭代的畸变函数变化值是否满足收敛条件,若是,则跳到步骤7;
6)按照式(2)更新聚类中心,跳到步骤3,进行下一次迭代计算;
7)根据聚类结果,按照式(3)计算Validity(k)指数;
8)判断K取值是否达到上限,若否,则更新K值并跳到步骤2;
9)根据Validity(k)值,选取Validity(k)值最小的K值及其聚类结果作为最终的典型场景集合。
1.2 基于场景概率分布的拉丁超立方样本抽样
场景的准确度与各采样点的相关性有关,不同场景之间样本相关性越小准确度越高。传统样本抽样方法不同场景之间的采样频率相同,导致计算结果缺乏科学性、准确性。基于此,提出基于场景概率分布的拉丁超立方抽样方法。在采样时令样本采样频率与各对应场景的概率一致,即根据各场景的出现概率对采样样本进行抽样,降低不同场景之间样本的相关性,确保采样频率与各场景概率一致,提高场景结果的准确性,减小不必要的误差。
拉丁超立方抽样定义[16]:设在s维单位空间Cs=[0,1]s中抽取n个样本,首先,将各维度坐标均n等分,得到若干个小区间((k-1)/n,k/n],其中k为小区间标号,将第i维坐标的n个小区间进行随机组合,用(π1i,π2i,…,πni)′表示;然后,设s维中的各随机组合之间互相独立,得到随机矩阵π=(πki),令xki=(πki-0.5+uki)/n(k=1,2,…,n,i=1,2,…,s),其中样本uki在区间[-0.5,0.5]内服从均匀分布,且与π相互独立,则称这n个点xk=(xk1,xk2,…,xks)(k=1,2,…,n)为一个拉丁超立方样本。具体流程如图1所示。
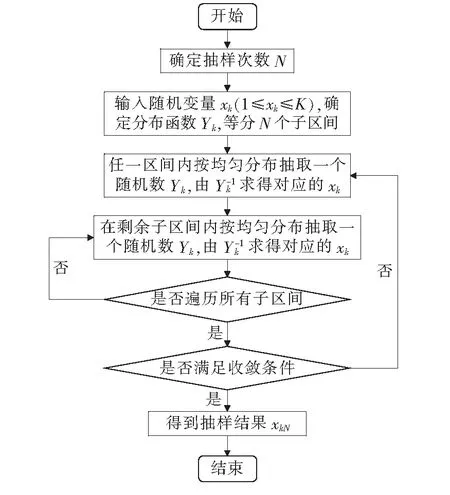
图1 拉丁超立方抽样流程Figure 1 Latin hypercube sampling flow chart
令抽样次数N为所得场景数,x′k为本文基于场景概率抽样法得到的抽样点,计算方法为
x′k=xkpK
(4)
式中pK为该采样点所处场景K的场景概率。
2 可靠性指标计算方法
基于文1.2节中提取的典型场景,提出可靠性指标的计算方法。首先,采用状态时间抽样法获得系统状态时间序列;然后,根据系统状态时间样本序列,提出多场景负荷削减策略;最后,确定各可靠性指标及其计算方法。
2.1 状态时间序列生成方法
本文采用状态持续时间抽样法[17],其原理如图2所示。对各场景中每一个元件的状态时间序列进行抽样,最后得到各场景的状态时间序列,从而计算各个可靠性指标。计算系统可靠性指标需要各元件的状态时间序列以及负荷、分布式电源的功率时间序列。
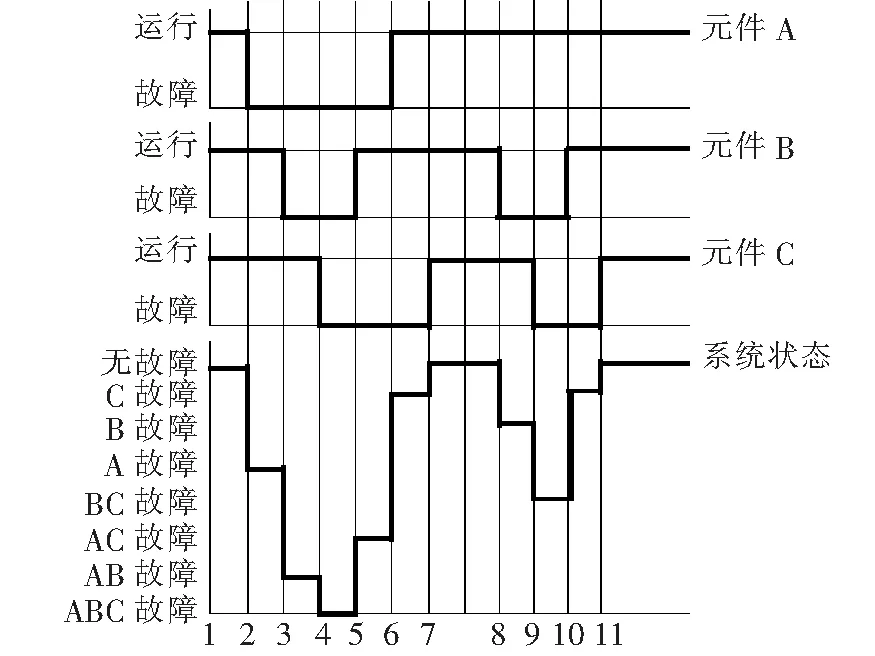
图2 状态持续时间抽样法原理Figure 2 Principle of state duration sampling
本文采用两状态模型表示元件状态,每个元件都有其故障率λ和修复率μ,元件的状态持续时间受这二者影响,抽样得到元件的正常工作时间τ1和故障修复时间τ2分别为
(5)
(6)
式中U1、U2为[0,1]上的均匀分布随机数。
通过抽样获取U1、U2,从而根据式(5)、(6)计算得到元件的状态持续时间,进而得到元件状态时间序列,最后综合所有元件的状态时间序列,可以获得系统的状态时间序列,具体步骤如下:
1)确定元件的初始状态,无特殊情况时假定所有元件在初始时刻均处于运行状态;
2)在保证各元件处在当前状态的情况下,根据式(5)、(6)对该情况的持续时间进行抽样处理;
3)在给定的模拟总时间段T内,根据元件的正常工作和故障修复时间计算得到各元件的状态时间序列;
4)综合每一场景内各元件的状态时间序列,可以得到各场景的状态序列和持续时间,且在每一场景状态内,各元件状态不变。
2.2 多场景负荷削减策略
负荷和分布式电源出力情况取决于典型场景中的功率。在各场景下计算可靠性时,负荷和分布式电源的出力取该场景中相应的值。当出现系统故障时,如果电源出力小于负荷,则需要进行负荷削减。
根据系统状态时间序列可以判断出系统是否故障。系统故障包括变压器、馈线、断路器以及电源故障。尤其对于微电网来说,电源故障会导致大量负荷损失。对于固定的电量损失,本文采用的负荷削减策略可以使因停电造成的损失最小。
将负荷分为1、2、3级,每一级负荷的停电损失都不同,其中3级最少、1级最多。所以,理论上停电时应优先停3级负荷。
对于固定的停电量,所占比重应为3级负荷最大,其次2级,再1级负荷。最后停电量应该大于等于因电源故障造成的失电量或者实现1级负荷用户全部停电。
2.3 可靠性计算指标
在得到系统状态时间序列和负荷分布式电源情况之后,根据数据统计可以计算各种可靠性指标,本文采用的可靠性指标如表1所示,各指标计算公式分别为

表1 可靠性指标Table 1 Reliability index
(7)
(8)
(9)
(10)
(11)
(12)
(13)
式(7)~(13)中λi为负荷点i的年故障停运率;at为t时刻负荷点i的状态,故障为1,正常为0;Ui为负荷点i的年平均停运时间;Δt为元件状态序列中每个状态的时间间隔;γi为负荷点i每次停电平均停运时间;SAIFI为系统平均停电频率;Ni为负荷点i的用户总数;SAIDI为系统平均停电时间;ASAI为平均供电可用率;ENS为电量不足指标;Lai为负荷点i的平均负荷。
3 基于多典型场景的可靠性计算方法
本文提出基于多典型场景的可靠性计算方法。首先,根据k-means算法中各类集的粒子个数建立典型场景概率分布模型,然后,根据全概率计算公式提出基于多典型场景的可靠性计算方法。
3.1 多典型场景概率分布模型
对一年内的电网大数据进行典型场景提取,每个典型场景代表该电网一年内的一段时间的潮流情况。因此,在进行计及多个典型场景的可靠性计算时,各场景的出现概率为该场景所占时长占全年时间的比值。在采用k-means算法对电网运行大数据进行典型场景的提取时,每一个聚类中心都是一个典型场景,而该类中所包含的粒子数量即为适用该场景的时间长度。因此,各典型场景的概率分布为
(14)
式中Pk为第k个典型场景的出现概率;tk为第i个场景所占时长;T为全年总时长。式(14)中最后一部分的分子表示属于第k个类的粒子个数。
3.2 基于多典型场景的可靠性计算方法
由于不同典型场景内各元件状态、负荷大小以及分布式电源出力不尽相同,如果仅采用一种场景对电网的可靠性进行估算,则将忽略其他状态下系统可靠性的变化[18]。为了更加准确地评估电网的可靠性,应该根据全年的数据综合计算。本文根据建立的典型场景提取模型、单个典型场景可靠性计算方法以及典型场景概率分布模型,采用全概率计算公式,提出基于多典型场景的可靠性计算公式为
(15)
根据式(15)可知,各个典型场景下的可靠性指标和其出现概率相乘后累加得到的综合可靠性指标,理论上可代表全年该电网的可靠性。基于多典型场景的可靠性计算流程如图3所示。
4 算例分析
4.1 算例及参数
为测试本文所提的微网可靠性指标计算方法,以某改造微电网系统为例,将本文提出的基于典型场景采样的可靠性计算方法和传统的多状态法进行对比分析。该微电网由300台风力发电机组、500个光伏电池板、10台柴油机以及100个超级电容器组成,包含馈线2条、断路器10个、配电变压器8台、负荷点8个,各负荷点所占总负荷比例稳定,微电网系统如图4所示。
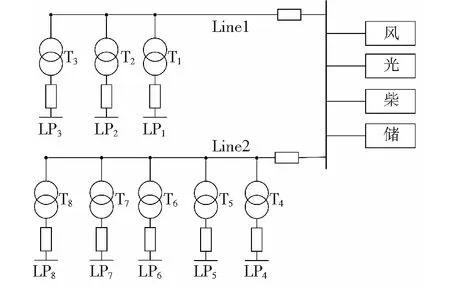
图4 城市微电网系统Figure 4 Urban micro-grid system
该微网中风力发电机组、光伏电池板、储能装置等参数参考文献[19]。元件可靠性参数如表2所示;负荷点1~8所占总负荷比例以及用户数如表3所示。
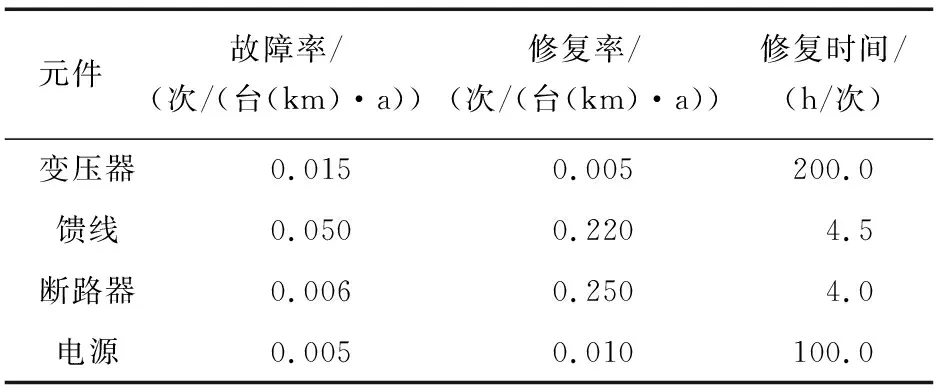
表2 元件可靠性参数Table 2 Component mid reliability parameter
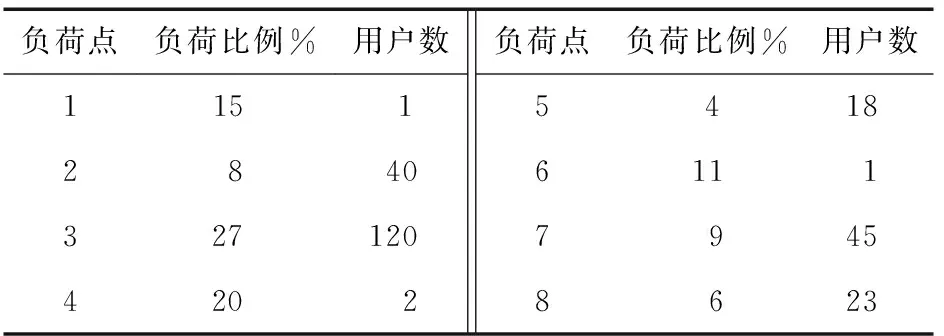
表3 负荷点负荷比例及用户数Table 3 Load point load ratio and number of users
选取台湾省马公市(119°33′ 19″E,23°34′ 02″N)风速、光照强度数据为本文算例数据。
根据文1所述的基于大数据的电网运行典型场景提取方法,对负荷及分布式电源出力8 760 h的数据进行典型场景提取。首先为确定最佳的典型场景分类数,从2~94逐一设置聚类数并进行聚类计算,计算得到的Validity(k)指数曲线如图5所示,当聚类数为11时,聚类效果最好。因此,本文根据负荷及分布式电源出力大小,将全年划分为11个典型场景,同时设定拉丁超立方抽样中的抽样次数N=11。每个典型场景内分别计算可靠性指标,最后得出全年综合可靠性指标值。
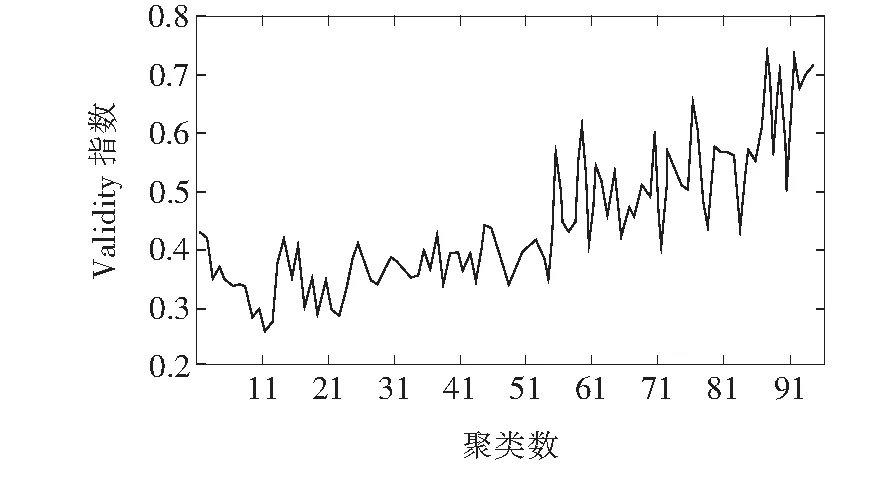
图5 Validity指数曲线Figure 5 Validity curve
4.2 基于典型场景的可靠性指标计算
各典型场景负荷及分布式电源出力情况如表4所示;根据文1.2对样本进行抽样提取,根据文2、3的计算方法对每一个场景进行可靠性指标计算,结果如表5~7所示。

表4 典型场景Table 4 Typical scenario
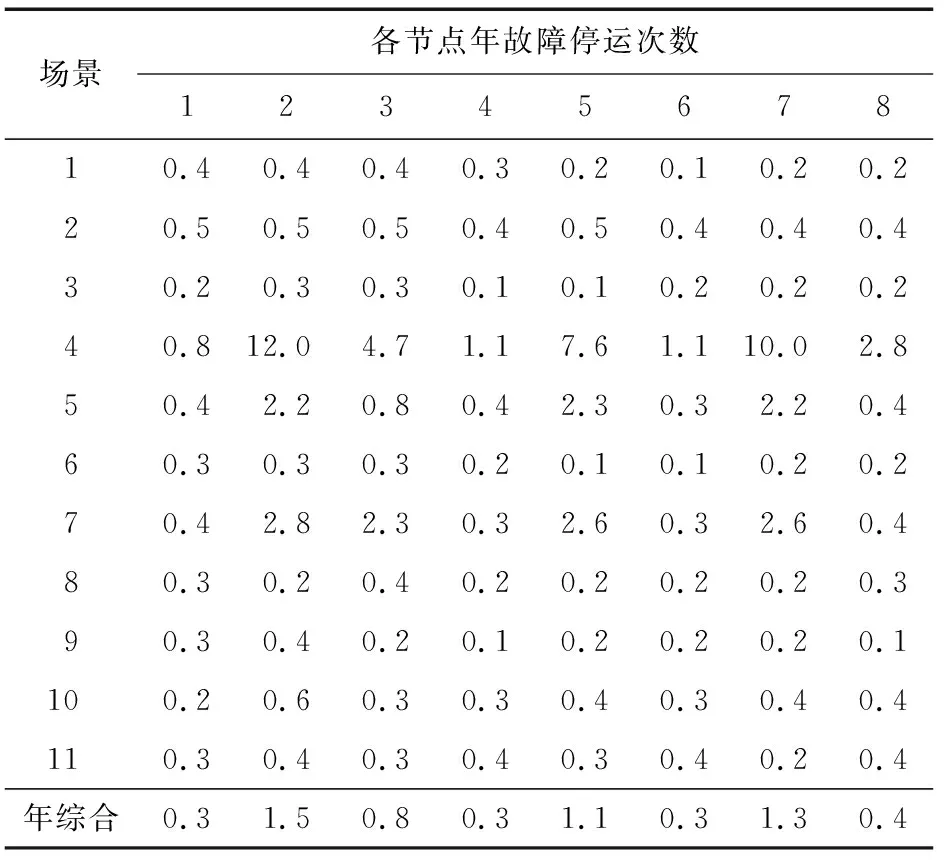
表5 各节点年故障停运次数Table 5 Annual outage of each node

表6 各节点年平均停运时间Table 6 Average annual outage time for each node h
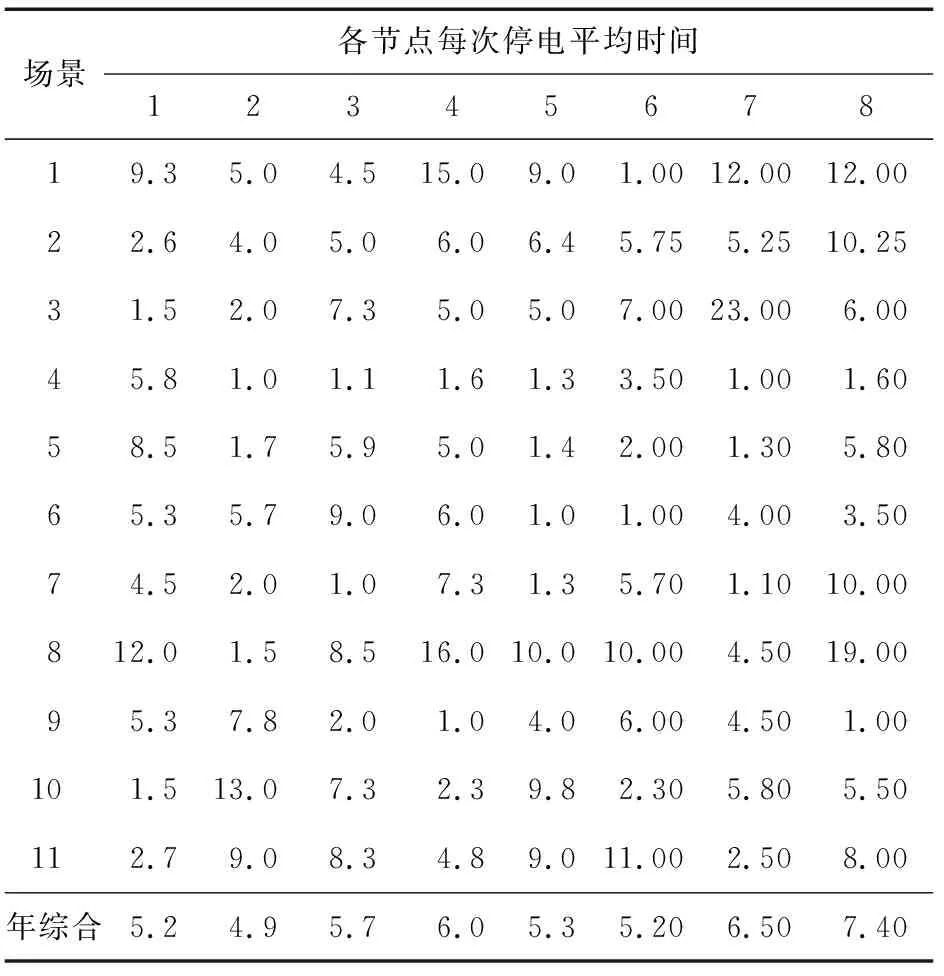
表7 各节点每次停电平均时间Table 7 Average outage time of each node h
根据式(9)~(12)得出各场景系统可靠性指标,最终结果如表8所示。为了验证基于多典型场景采样的可靠性计算方法的快速、精准的特点,采用基于传统样本提取的可靠性计算方法对本算例进行计算,结果如表9所示。
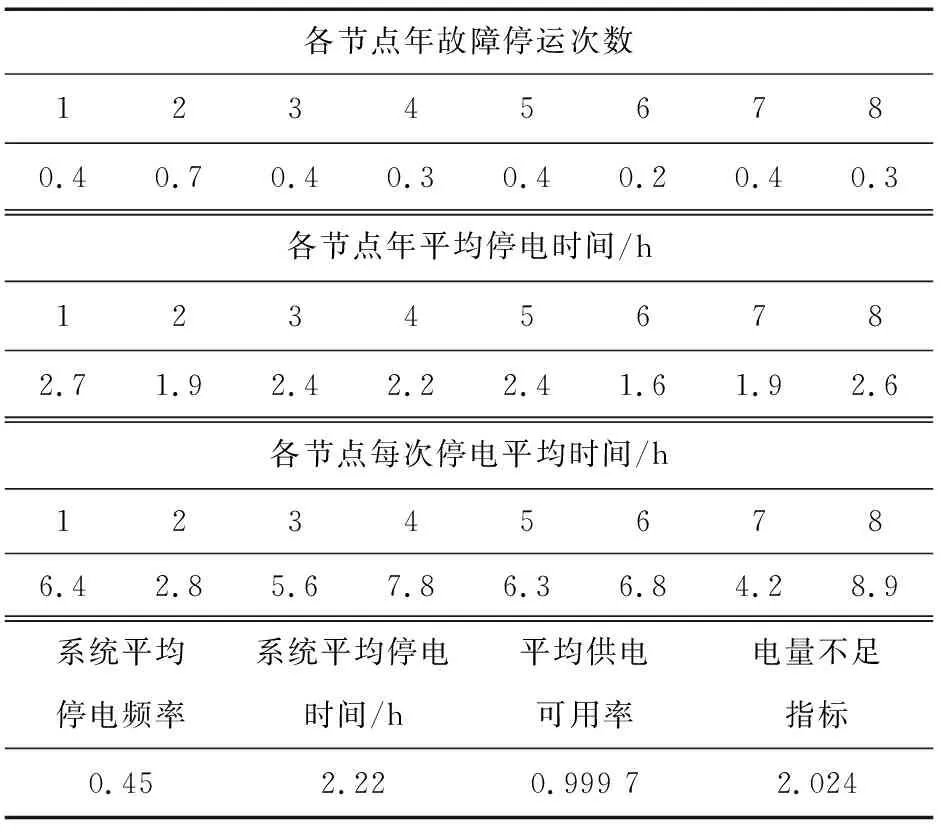
表9 传统样本提取法可靠性指标结果Table 9 Reliability index results of traditional sample extraction method
同时,采用文献[20]中的蒙特卡洛法计算本文所提到的可靠性指标,将最终的结果与本文方法对比分析,3种方法计算得到的电网可靠性指标值如图6所示,可以看出本文所提方法的精确性。
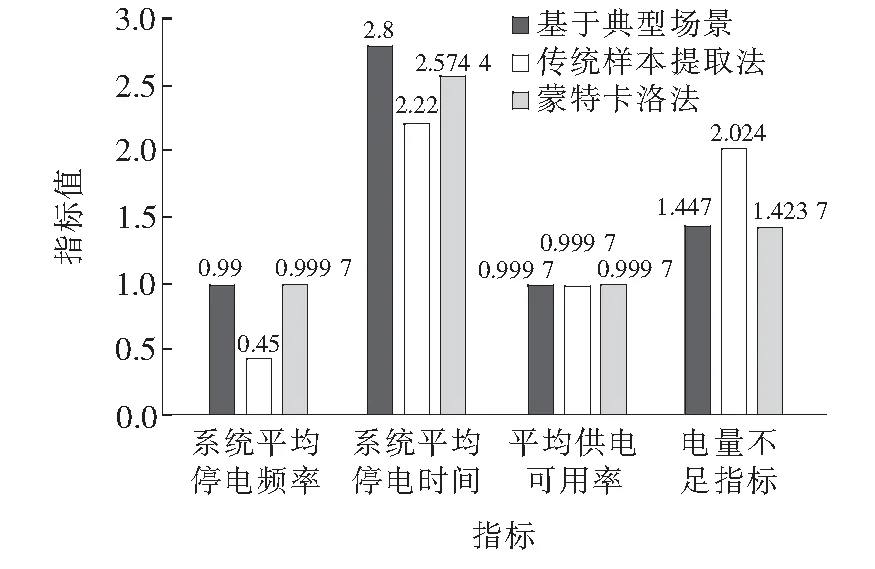
图6 3种方法结果对比Figure 6 Comparison of the results of the two methods
本文方法与较为成熟的蒙特卡洛法相比较,最终计算结果的误差控制在允许范围内;本文方法与传统样本提取法相比,在准确度上有明显的优越性。在快速性方面,Matlab运行环境下采用本文方法计算用时290.61 s,而采用蒙特卡洛法则需要328.52 s,表明本文方法在保证运算精度的情况下,能够有效地提升运算速度,减小运算难度及时间。因此,通过算例分析证明,本文所提出的基于典型场景采样的可靠性计算方法,在降低运算难度、提高运算效率的同时,可以较为精确地表征该电网的可靠性指标,证明了本文方法的有效性、可行性。
5 结语
本文所提方法的创新点:①考虑了负荷与分布式电源出力的时间关联性,在进行场景聚类时,将负荷和分布式电源出力2个变量同时看作粒子的数据点;②抽样时保证了样本采样频率与各对应场景概率一致,降低了不同场景之间的相关性以提高结果准确性;③利用大数据技术提高了可靠性评估的准确性,最终采取全概率公式得到了综合可靠性指标。
在大数据应用背景下,为了更加准确地计算独立型微网的可靠性指标,本文提出了基于多典型场景采样的可靠性计算方法。经过算例验证分析,可以得到以下结论:
1)根据Validity指数曲线确定典型场景最佳分类数,能够在有效地减少计算量的同时,准确表征电网全年运行场景;
2)相比传统样本提取法,本文提出的基于多典型场景采样的可靠性计算方法地计算结果更加准确;
3)相比于蒙特卡洛法,本文提出的基于多典型场景采样的可靠性计算方法,能够在保证准确性的前提下,使运算时长更短、运算更加快速。
因此,本文方法可以在一定程度上实现对微网可靠性指标高效精准地计算。未来可以在典型场景分布模型的建立上做进一步研究,使可靠性计算结果更准确。
