基于LDA模型的学术次生衍生舆情传播的演化分析
2022-08-09蔡政群李诗轩吴玉敏杨斯涵
蔡政群,李诗轩,吴玉敏,杨斯涵
(1.武汉理工大学 安全科学与应急管理学院,湖北 武汉 430070;2.中南大学 资源与安全工程学院,湖南 长沙 410083;3.东北大学 资源与土木工程学院,辽宁 沈阳 110819)
近年来,高校学术话题是网民关注度最高的话题之一,与此同时,有关高校学术不端的事件也层出不穷,在“翟天临事件”爆发之后,媒体和公众对学术界新闻的关注不断走高,由此引发的舆论也持续发酵。此后,越来越多的学术不端事件出现在公众的视野,如中国人民大学章胜玉的硕士学位论文全文抄袭华东师范大学李洁论文、江苏大学理学院教授戴美凤刊发于Nature杂志旗下知名期刊《科学报告》(Scientific Reports)的论文被撤稿等事件均引发了激烈的讨论,形成了高校学术不端事件的原生舆情。
原生舆情的出现往往伴随或引发次生、衍生舆情[1]。次生舆情是指舆情事件在互联网中因某一因素触发的再生或演化的新舆情[2];衍生舆情,是指由原事件网络舆情演变而产生的新舆情[3]。由于两类舆情概念与性质相似,文章中不再对两类舆情进行区分,统称为次生衍生舆情。
目前,国内外对原生舆情的研究已较为成熟,但对次生衍生舆情的研究较少,而次生衍生舆情往往在事件爆发后难以预测和评估。因此,掌握次生衍生舆情的发展规律有利于相关部门预测与治理次生衍生舆情。鉴于此,文章以三起具有代表性的高校学术不端事件的次生衍生舆情为研究对象,基于LDA主题模型进行主题提取,利用困惑度指标确定最佳主题数,揭示次生衍生舆情的发展方向与演化规律。
1 文献综述
1.1 次生衍生舆情相关研究
目前国内外针对网络次生衍生舆情的研究主要集中在衍生舆情的形成要素、传播方式、治理对策和预警研究四方面。单晓红[4]等通过采集微博话题数据,构建以舆情主体和客体为核心的衍生话题分析框架,利用模糊集定性比较分析法,探究了衍生话题形成路径;DONG等[5]提出了在线/离线社交网络环境下的衍生舆情动力学模型,研究了衍生舆情动力学模型中形成共识的分析条件,为网络舆情的管理提供了科学的依据;范晓萌[6]立足于文献调研法、Matlab数值仿真等研究方法,建立基于Logistic模型的分析微分方程,进一步阐明出现衍生舆情扩散时所传播的基本规律以及预警的必要性;GURBUZ等[7]用数值方法研究了衍生舆情传播模型的动力学,解释了参数模型的敏感性分析,最后通过数值模拟证明了该方法的有效性;刘文强[8]利用子系统分析次生舆情的因果关系,提出基于系统动力学模型和三角模糊数的移动社交网络次生舆情动态预警方法;ZHANG等[9]鉴于新闻在微博上传播时会产生衍生话题,开创性地提出了一种包含原始话题层和派生话题层两层耦合的SEIR舆情传播模型。
综上所述,网络次生衍生舆情等相关问题的研究已经成为新时代互联网背景下,相关研究人员重点关注的课题之一。热点事件引起的网络舆情能够反应公众的态度和心声,而原生舆情引发的次生衍生舆情会更直接影响原生事件的发展或引发其他事件。因此,能否正确把握次生衍生舆情的发展与演化规律并进行合理的引导,将直接影响社会的发展和稳定。
1.2 学术不端网络舆情相关研究
学术不端是指高等学校及其教学科研人员,在科学研究及相关活动中发生的违反学术准则、违背学术诚信,以及以学生为主体的学业上的非道德行为。近年来,国内学术不端类事件频发,相关研究人员也渐渐对学术不端网络舆情保持较高的关注度。田秀秀等[10]以梁莹学术不端舆情事件为例,运用内容分析法对微博平台上媒体、意见领袖、公众三者之间的议题与框架进行量化统计分析,得出意见领袖和公众更容易达成趋同性意见和框架;张柳等[11]以新浪微博“高校学术不端”话题为例,基于朴素贝叶斯分类器进行高校舆情情感演化图谱研究,为微博环境下高校舆情情感的演化规律提供新的理论支撑;侯治平等[12]通过语义关联分析发现学术网络舆情信息传播的规律,为社交网络环境下学术舆情的传播提供了新的视角和分析方法;李娟[13]通过计算对微博用户节点进行影响力分析,结合用户情感倾向与用户节点影响力展示社交媒体中高校舆情情感图谱。
总体而言,现有学者已对学术不端网络舆情的主体、形成要素及传播形式和特点进行了丰富的研究,但对学术不端次生衍生舆情的研究较少,且现有研究中没有明确的次生衍生舆情判定规则。鉴于此,探索学术不端次生衍生舆情的发展规律,对舆情监管部门及时准确地监控、预测和引导高校舆情的走向具有重要意义。
2 研究框架与方法
2.1 研究框架
文章基于LDA主题模型进行学术次生衍生舆情传播演化分析的研究框架如图1所示。
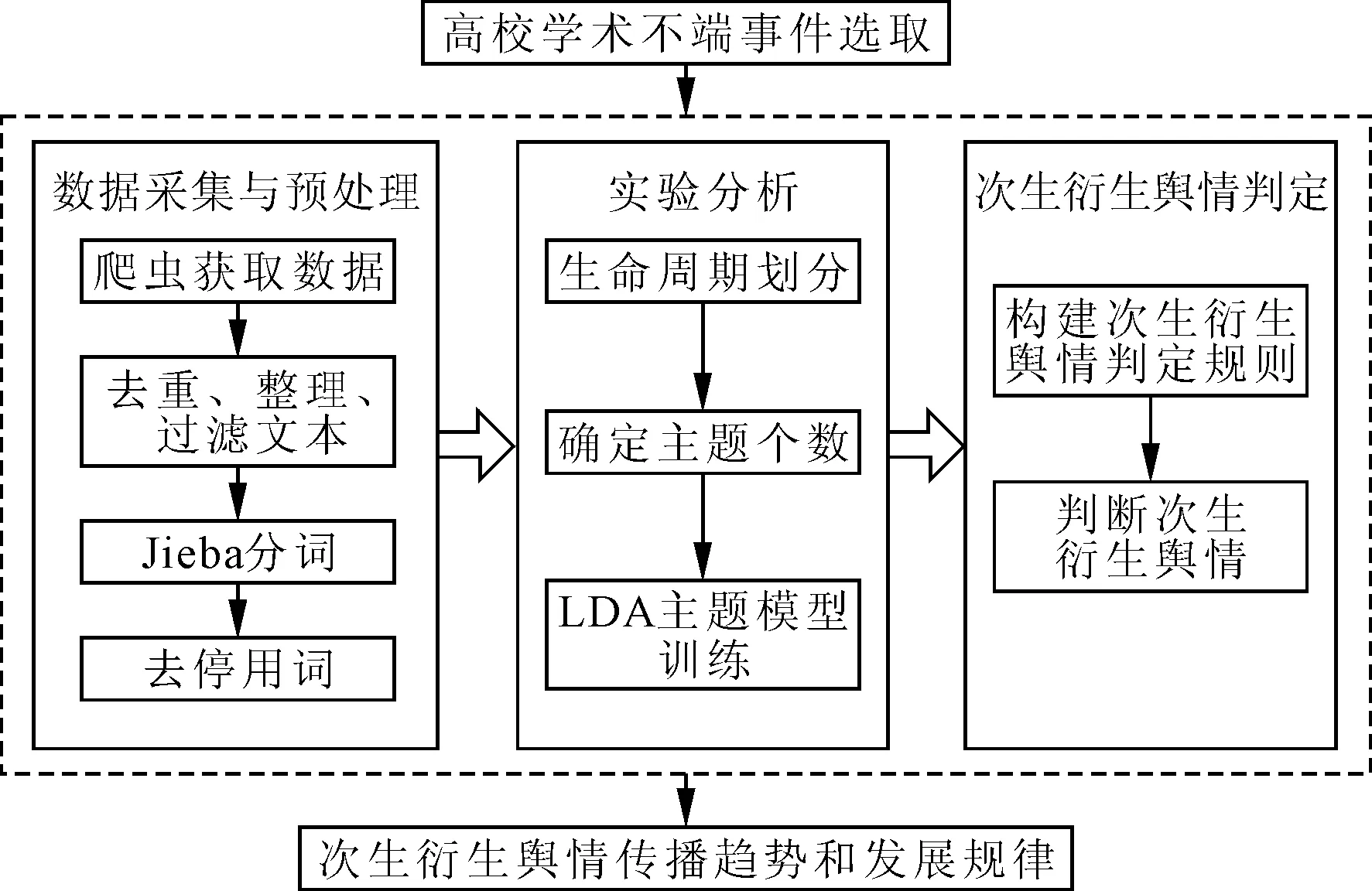
图1 次生衍生舆情传播演化研究框架
2.2 LDA主题模型
LDA(latent dirichlet allocation)主题模型,是由BLEI等[15]人在2003年提出的三层贝叶斯概率模型,LDA是一种基于词袋模型的无监督机器学习文本分析方法,可以用来识别大规模的语料库或文档集中的潜在主题信息。LDA组成结构包含文档、主题和词三种粒度,在不考虑词汇出现顺序的情况下,构成“文档-主题分布”和“主题-词分布”[16]。因此,可借助LDA模型进行高校学术舆情主题识别和聚类等基于文本的分析过程。
作为无监督机器学习,需要事先确定三个超参数α、β、k(最优主题数),α、β选取默认值为α=0.37、β=0.02,最优主题数k通过困惑度(perplexity)计算确定。困惑度常用来度量一个概率分布或概率模型预测样本的优劣程度,可用于调节主题个数,困惑度的计算公式如式(1)所示。
(1)
式中:D为文档中所有词的集合;M为文档的数量;Wd为文档d中的词;Nd为每个文档中d的词数;P(Wd)为文档中词出现的概率;log底数为10。困惑度为文档d所属主题的不确定性,困惑度越小,模型性能越好,困惑度最低或处于拐点时所对应的k值为最优主题数。
2.3 数据获取及预处理
根据中国互联网络信息中心(CNNIC)在京发布第48次《中国互联网络发展状况统计报告》的数据显示,截至2021年6月,我国网民规模达10.11亿,其中微博用户规模达5.66亿[17]。新浪微博也成为众多社交平台中活跃人数最多和影响力最为广泛的社交媒体之一,因而在社交网络的样本选择上,选择新浪微博作为数据采集的平台。
文章分别以“湖南大学刘梦洁抄袭”“翟天临学术造假”“天津大学张裕卿”作为三起事件的关键词,利用网页数据爬取工具“八爪鱼采集器”爬取相关微博数据,包括博文内容、评论内容、评论时间、转发数等,获得微博评论数据26 723条。
在数据预处理阶段,爬取到的微博评论中含有各种与主题无关的干扰因素,为得到规范的文本数据集,首先对获取到的数据进行去重、清洗和整理,利用正则表达式将文本内容仅为“@用户名”“#”等各种特殊符号以及不能表达主题的文字删除,以降低数据噪声,再调用Jieba中文文本分词,并默认使用精确模式对微博评论进行分词,根据去停用词词表去除停用词,最终获得微博评论数据20 286条。
3 实验结果与分析
3.1 生命周期划分
生命周期是指生物体从出生、成长、成熟、衰退到死亡的全部过程,泛指客观事物的阶段性变化及规律。网络舆情的发展和演化过程也符合这一规律,鉴于此,笔者参照刘国威和成全将舆情生命周期划分为三阶段的方法[18],将网络舆情生命周期划分为酝酿期、爆发期和衰退期三个阶段。在知微事见平台中分别搜索三起学术不端案例,得到它们随时间变化的传播趋势图,根据不同时段微博舆情的发文量、发文增量和发文增长率,三起学术不端事件的次生衍生舆情生命周期如表1所示。
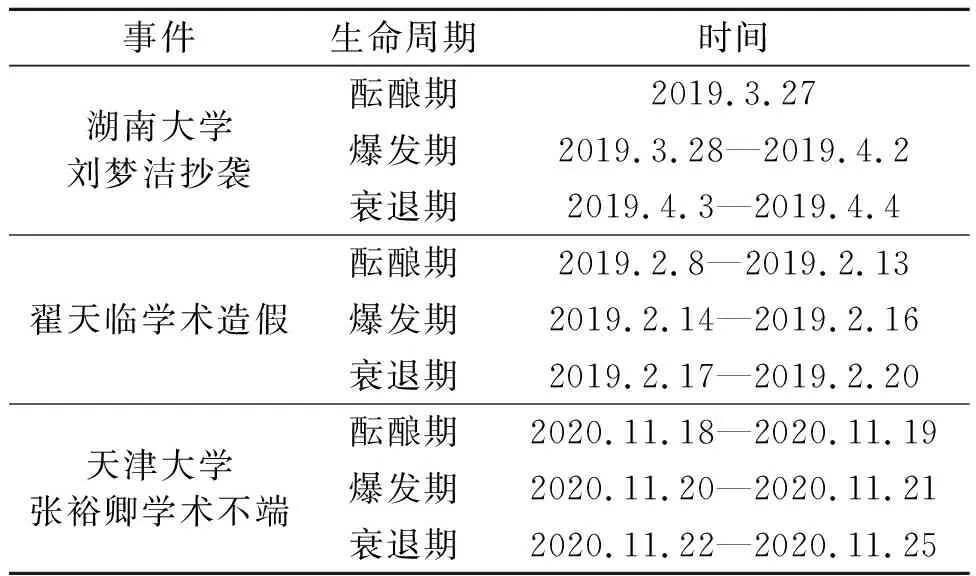
表1 学术不端事件次生衍生舆情生命周期划分表
(1)酝酿期。即网络舆情的发生期,这个时期的舆情正处于萌芽阶段,互联网上出现零散化的相关信息,浏览量和关注度有限。一小部分网友开始点赞、评论和转发,因此网络舆情的关注度和热度较低。
(2)爆发期。即网络舆情的成长期,这个时期的舆情处于发酵阶段,媒体报道纷纷加入进来。网友开始群体性的转发和评论,与此同时,学术界专家学者们也纷纷加入进来,网络舆情开始广泛传播,爆发范围迅速扩大,因此网络舆情的关注度和热度达到最高水平。
(3)衰退期。即网络舆情的消退期,这个时期的舆情处于消散阶段,舆论事件的处理结果已经被公众知情并且接受,此时只有一小部分网友在关注此事,因此网络舆情的关注度和热度都达到最低水平。
3.2 确实主题聚类个数
文章选用gensim包中的LDA主题模型对预处理后的文本进行训练。设定0~20区间内的整数为最优主题数,通过计算不同主题数下的困惑度得出局部最小值,从而确定最优主题数。三个事件主题困惑度随主题数变化如图2中的(a)(b)(c)所示。
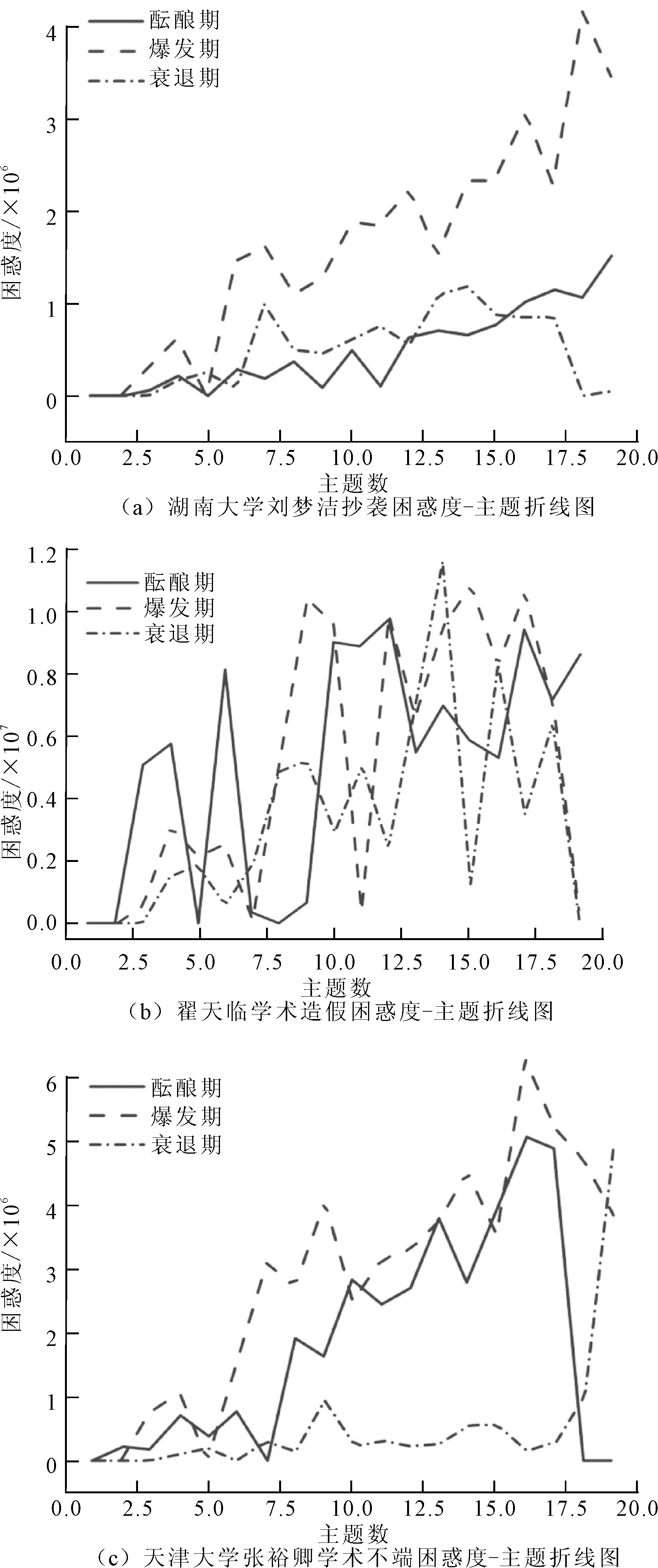
图2 困惑度—主题折线图
由图2可以看出,湖南大学刘梦洁抄袭事件酝酿期、爆发期和衰退期的困惑度局部最小值点出现在主题数分别为5、5、6时。翟天临学术造假事件酝酿期、爆发期和衰退期的困惑度局部最小值点出现在主题数分别为5、7、6时。天津大学张裕卿学术不端事件酝酿期、爆发期和衰退期的困惑度局部最小值点出现在主题数分别为7、5、6时。
3.3 主题模型训练
在确定最优主题数后,对分词后的文本进行LDA主题模型训练得到高频词,结合这些高频词进行主题归纳。利用LDA主题模型训练得到的湖南大学刘梦洁抄袭事件酝酿期主题与关键词如表2所示;翟天临学术造假事件主题与关键词如表3所示;张裕卿学术不端事件主题与关键词如表4所示。

表2 湖南大学刘梦洁抄袭事件主题与关键词
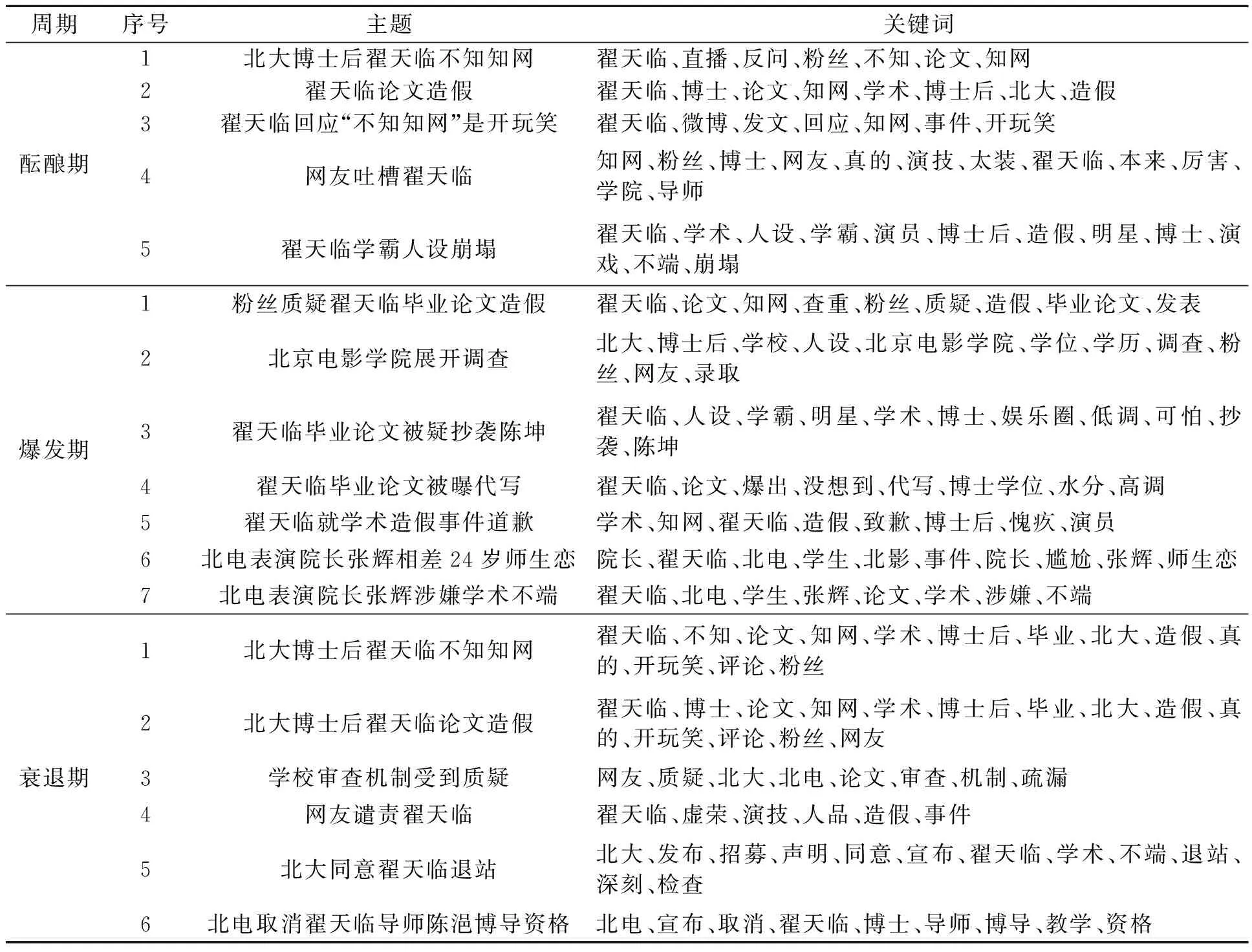
表3 翟天临学术造假事件主题与关键词
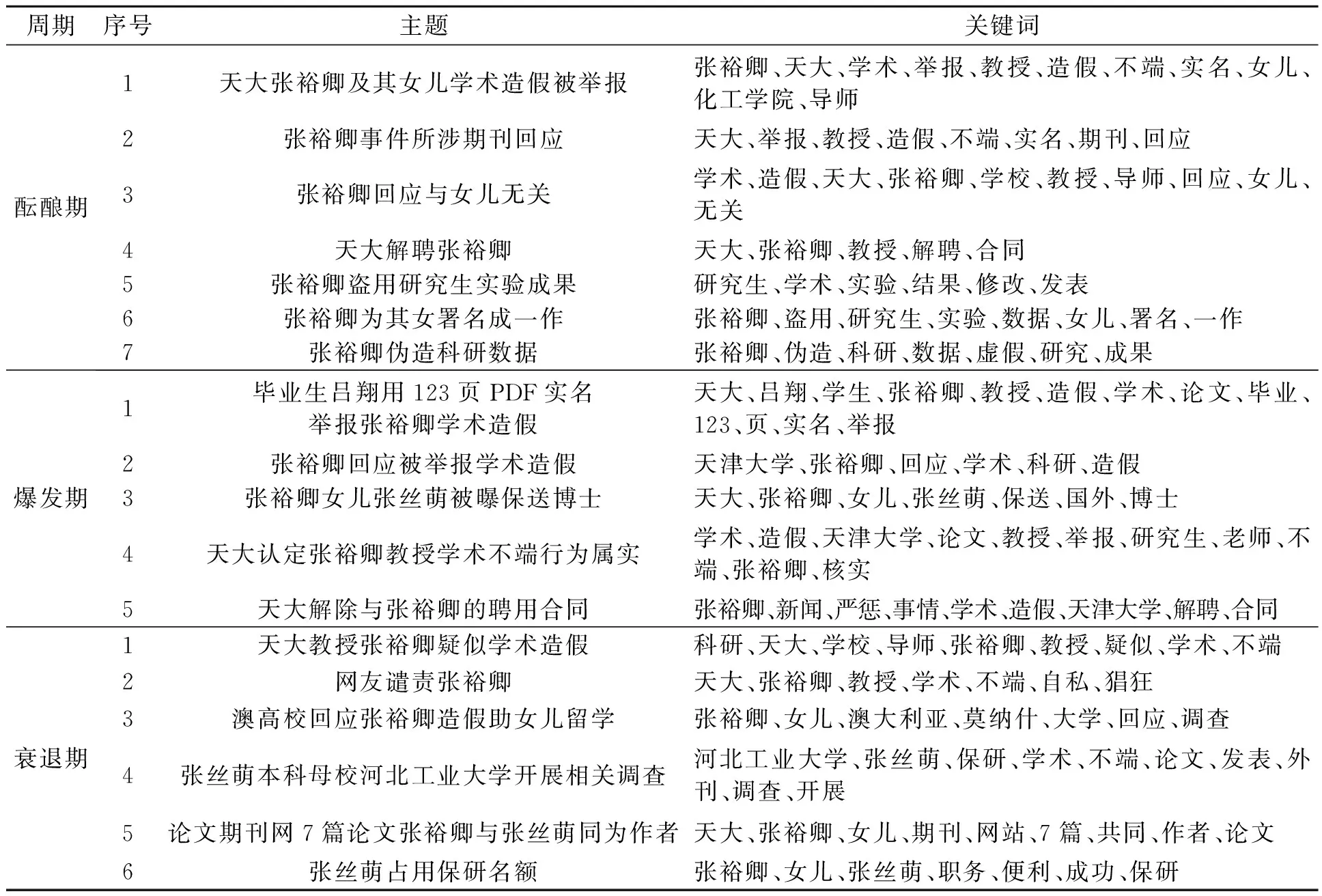
表4 张裕卿学术不端事件主题与关键词
3.4 构建次生衍生舆情判定规则
文章主要研究高校学术次生衍生舆情的形成与演化规律,三起高校事件存在多个次生衍生舆情。根据衍生舆情的基本特点、生成机制以及相关文献对次生舆情和衍生舆情的描述,结合笔者利用LDA主题模型对文本的处理结果,获取次生衍生舆情的判定规则如下:
(1)话题影响力,具有一定的影响力,不论是积极正面还是消极负面的影响;
(2)话题关键词差异,是原生话题的扩展或拆分,表现为脱离了原生话题相关关键词又出现新的关键词;
(3)话题出现时间,在原生话题出现之后产生并独立于原生话题;
(4)话题导火索,事件有隐情或者事件应对不当;
(5)话题评价主体差异,原生话题的评价主体发生改变。原生舆情与次生衍生舆情的评价主题不同,且原生舆情的评价主题容易辨别,因此根据主体的不同,筛选出次生衍生舆情。将归纳总结出的主题根据以上判定规则进行判定,筛选出次生衍生舆情。
3.5 判断次生衍生舆情
根据次生衍生舆情判定规则,对三起高校学术不端事件的主题进行分析。将相同的主题合并为一个,对事件及主题进行编号:数字1代表湖南大学刘梦洁抄袭事件,2代表翟天临学术不端事件,3代表天津大学张裕卿事件;字母a代表酝酿期,b代表爆发期,c代表衰退期,最终得到表5所示的高校学术事件各生命周期的次生衍生舆情。
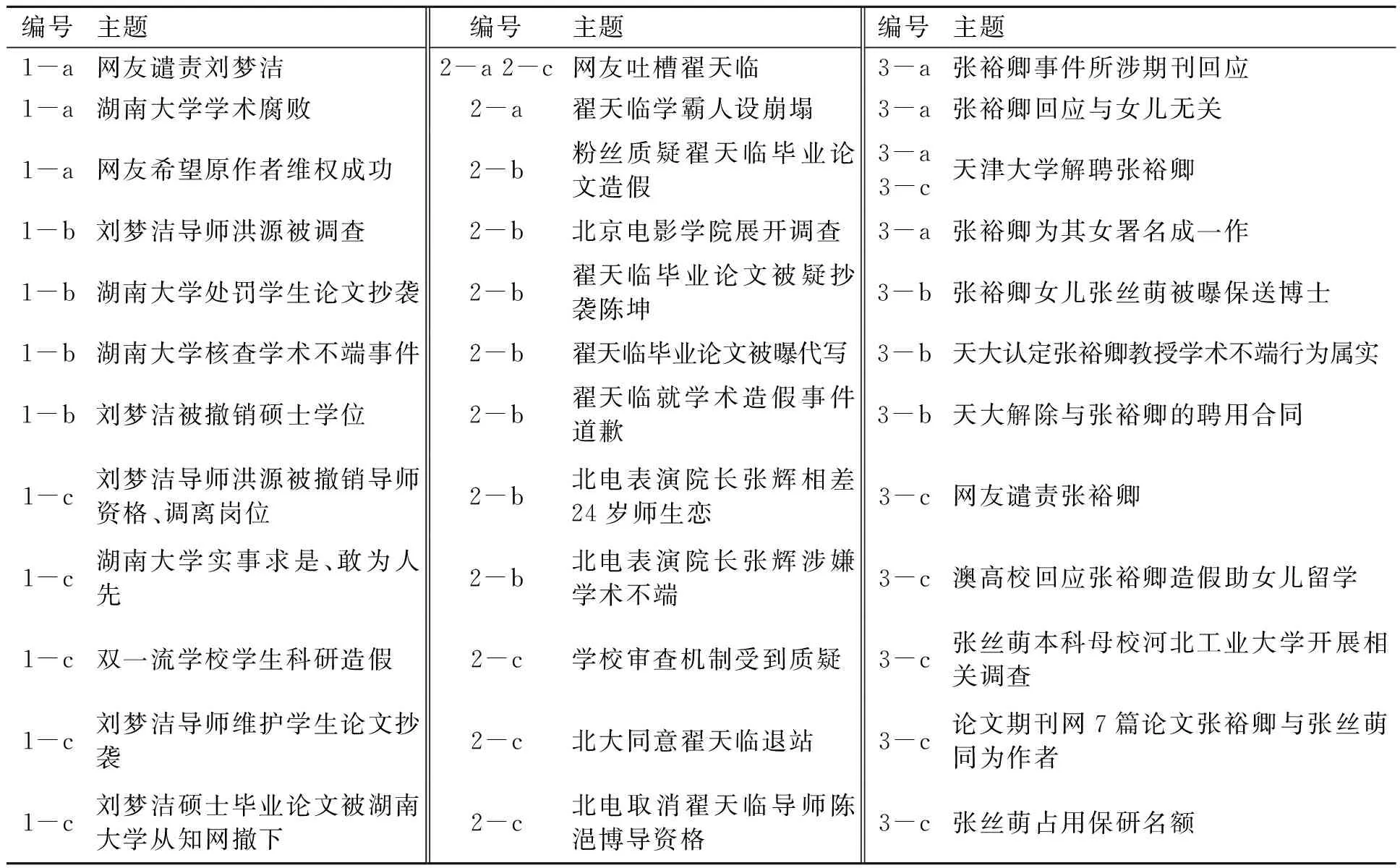
表5 高校学术事件次生衍生舆情
由表5可以发现,三起学术不端事件的次生衍生舆情均涉及当事人、公众和高校三种主体。其中,涉及当事人层面的次生衍生舆情最多,其次是高校层面,最后是公众层面。当事人层面的次生衍生舆情包括相关人员私生活被扒、被调查与革职、当事人科研成果被取消、当事人致歉;公众层面的次生衍生舆情包括公众谴责当事人、支持高校开展调查、质疑高校审查机制;高校层面的次生衍生舆情包括核查相关事件、处罚相关人员、取消涉事人相关科研成果。
(1)当事人。当事人包括抄袭者、被抄袭者以及相关人员。抄袭者通过不当手段和方法进行学术造假、剽窃来盗取学术成果,对社会和学术界造成了极其恶劣的影响;相关人员则对抄袭者的学术造假行为进行隐瞒,协助其获得非正规利益与学术成果;被抄袭者在发现自己科研成果被他人剽窃后往往选择在网络上进行公开,以求获得学者和机构的关注并进行调查与处理,以期能维护学术尊严,惩治学术腐败。
(2)公众。公众是舆情传播的核心主体,当学术不端事件发生,公众会关注学术事件的相关信息,试图了解事件真相。初步了解后,通过网络平台发表自己的观点和看法。由于广大网友的受教育水平、情绪状态和自身利益诉求各不相同,发表的言论出现信息不对称、信息异化等现象,不仅会关注原生舆情的起因和发展动态,还会讨论由学术事件引发的其他领域的话题,将舆论推向两极化,从而导致次生衍生舆情的形成与演化。
(3)高校。学术不端事件必然涉及高校,面对外界的质疑和公众的追问,若高校封锁消息,不出面给予回应,则会导致公众不得不通过其他渠道了解事件情况。而一些媒体为追求热度与时效性,往往会在传播过程中扭曲和歪解事件的真实性,此时的公众极易受其误导,造成公众的揣测和猜疑,更容易引发次生衍生舆情的形成。因此,高校及时公开信息和发表声明是遏制次生衍生舆情传播的必要手段,在发布声明的渠道上,要做到信息的多元性和覆盖的全面性,以提升信息公开质效,正向应对次生衍生舆情的传播演化。
4 结论与启示
(1)笔者通过选取三件高校学术不端的案例,将获取到的微博数据按照生命周期划分为酝酿期、爆发期和衰退期三个阶段,采用困惑度评价指标对每个阶段的数据进行最优主题数确定,基于LDA进行主题模型训练,得到相关事件的用户评论高频词并进行主题归纳。
(2)通过构建次生衍生舆情判定规则,判断出高校学术次生衍生舆情,及其涉及的主体有当事人、公众和高校。其中,涉及当事人的次生衍生舆情数量最多,高校层面的次生衍生舆情数量次之,公众层面的次生衍生舆情数量最少。
(3)学术不端次生衍生舆情的演化贯穿整个生命周期,大部分次生衍生舆情主要集中在爆发期和衰退期。在网络舆情的酝酿期,高校应做好舆情衍生的预警工作;在网络舆情的爆发期和衰退期,高校应积极回应群众的关注,及时发布调查真相,使群众能够合理地看待舆情事件,以防止次生衍生舆情的蔓延。
(4)本研究主要针对高校学术不端事件进行研究,为同类事件引发的次生衍生舆情提供参考。在事件的选取方面存在一定的局限性,不同事件进行实验得到的次生衍生舆情及其主体也会不同。因此,未来研究可以完善实验对象的选取,从而为预防和处理次生衍生舆情提供更好的方法。
