双视图三维卷积网络的工业装箱行为识别
2022-08-09胡海洋潘健李忠金
胡海洋,潘健,李忠金
杭州电子科技大学计算机学院,杭州 310018
0 引 言
人体行为识别由于其广泛的应用,一直是计算机视觉中的热门研究方向,例如智能视频监控、人机交互、虚拟现实和医疗影像分析(Cao等,2017;Wang等,2015;Kuanar等,2018,2019)。该领域的突破很大程度上归功于深度神经网络的出现,尤其是3D卷积网络的提出(Ji等,2013)。3D卷积网络是2D卷积网络的扩展,主要使用3D卷积来捕获时间信息。相较于2D卷积网络,3D卷积网络由于增加了时间维度,可以更好地提取视频的时空特征。Hara等人(2018)将C3D (convolutional 3D network)卷积网络与残差网络(residual neural network, ResNet)相结合,并在Kinetics数据集中进行预训练,相比C3D卷积网络,3D ResNet在UCF101(University of Central Florida-101)和HMDB-51(Human Motion DataBase-51)中取得了很大的进步,同时运行速度也快了2倍。Simonyan和Zisserman(2014)采用RGB图像和光流作为两个独立的2D 卷积网络流的输入,基于RGB图像的空间流从静止图像捕获空间特征以识别人的动作,而基于光流的时间流用于识别密集光流的运动,光流作为进一步表达运动信息并改善性能,是有必要的,如多种模型(Simonyan和Zisserman,2014;Liu和Hu,2019;Feichtenhofer等,2016;Carreira和Zisserman,2017)都通过结合光流取得了较好的效果。但是由于提取光流的过程非常耗时,在现有硬件条件下无法在实时场景应用,例如图1中所展示的需要实时检测的实际生产场景。Tao等人(2020)使用差分图像作为网络输入,用于获取额外的运动特征,并且取得了较好的结果。基于以上两个动机,本文引入差分图像,更好地获取运动特征。
与传统的行为识别研究工作相比,工厂环境下的行为识别有其复杂性和特殊性:生产制造环境中背景混乱、光线变化频繁以及人体被遮挡问题严重,给研究工作带来了挑战。现有的行为识别方法并不能很好地解决人体被遮挡的问题,如图1中装箱工人的右手动作被柱子和箱子遮挡。

图1 工厂中的装箱环境Fig.1 Packing environment in the factory
行为识别在生产场景中应用时,由于对产品合格率的要求,需要尽可能排查出不合格的产品,同时保证检测结果的高准确率和高真负率(true negative rate,TNR)。现有的行为识别方法中,还没有较好的优化真负率的方法。
针对在工业装箱场景中存在的上述问题,本文提出了一种基于双视图3D ResNeXt101的行为识别方法。首先,本文引入堆叠的差分图像作为模型的输入来更好地提取运动特征,替代实时场景中无法使用的光流。原始RGB图像和差分图像分别输入到两个并行的3D ResNeXt101中,基于差分图像的3D ResNeXt101模块用于更好地提取运动特征,基于3D ResNeXt101模块用于提取运动特征和弥补差分图像中缺失的外观特征。其次,采用双视图结构来解决人体被遮挡的问题,将3D ResNeXt101优化为双视图模型,使用一个可学习权重的双视图池化层对不同角度的视图特征进行融合,利用该双视图3D ResNeXt101模型进行行为识别。最后,为进一步提高检测结果的真负率,在模型中加入降噪自编码器和two-class SVM(support vector machine)模型。
1 相关工作
近些年,行为识别技术取得了非常大的进步。行为识别技术的主要方法可以分为两类,基于视频手工特征的方法和基于深度学习的方法。
基于时空兴趣点(space-time interest points,STIP)的方法作为手工特征的代表性方法,广泛应用于行为识别。该方法从视频中提取运动变化的关键区域来识别动作。STIP中的时空兴趣点通常是指时空维度上变化最大的位置(Das Dawn和Shaikh,2016)。3D-Harris时空兴趣点方法(Laptev,2005)是STIP最具代表意义的方法,主要思想是将局部特征检测技术从2维空间兴趣点扩展到3维时空兴趣点,然后计算特征描述符,统计像素直方图形成描述行为的特征向量。该方法不需要做运动物体分割,在背景复杂的场景也有较好的效果,但是在人体被遮挡和光线变化大时效果较差。基于运动轨迹提取的方法也同样受到许多研究者的关注, Wang和Schmid(2013)提出了改进的稠密轨迹方法(improved dense trajectories,IDT),综合HOG(histogram of gradient)、HOF(histogram of flow)和MBH (motion boundary histograms)的特征,对轨迹全局施加平滑约束,获得了很好的鲁棒性。此类方法的主要优点是不需要将运动物体分割,因此在光照变化和复杂背景下依然有较好的效果,但是时空兴趣点很容易受相机视图变化的影响,在视角变化和遮挡下效果不佳。使用IDT是基于手工特征中效果最好、应对场景最丰富的算法。但由于计算复杂度较高,该方法速度较慢。
与手动制作的动作特征不同,深度学习方法从图像中自动学习特征方面表现较好,目前许多研究人员已尝试使用深度学习方法从RGB图像、光流、差分图像和人体骨骼数据中提取动作特征(Simonyan和Zisserman,2014;Tao等,2020;Wu等,2018;Wu等,2021),深度学习可以从单模数据或多模融合数据中学习人体行为特征。Simonyan和Zisserman(2014)采用RGB图像和光流作为两个独立的2D卷积网络流的输入,空间流从静止图像捕获空间特征以识别人的动作,而时间流用于识别密集光流的运动。该体系结构能够从每帧以及帧之间的运动中提取互补特征。与2D卷积相比,3D卷积网络更能捕捉复杂的运动信息(Ji等,2013;Hara等,2018)。Feichtenhofer等人(2016)提出了双流3D卷积网络模型来学习时空特征,与在softmax层进行融合的传统方式不同,他们发现在最后的卷积层上融合时空流,在不损失性能的同时还可以节省大量参数。一些研究(Crasto等,2019;Peng等,2016;Hong等,2019)也是通过探索不同融合策略以显著提高行为识别的性能。另一方面,Carreira和Zisserman(2017)以及Ullah等人(2019)通过改善网络结构来提升行为识别的性能。Carreira和Zisserman(2017)将Inception-V1的网络结构从2维扩展到3维,并提出了用于行为识别的双流膨胀3D卷积网络,该方法在公共数据集UCF101和HMDB-51中都取得了非常好的结果。
在行为识别模型中加入自编码器成为提高准确性的一种有效方法(Ullah等,2019;Budiman等,2014),Ullah等人(2019)使用经过训练的降噪自编器来有效获取原始视频帧中的动作信息,将VGG-16(Visual Geometry Group layer 16)卷积网络模型中全连接层中的高维特征转换为低维,并学习相邻帧之间的信息变化。该方法通过在卷积网络中加入自编码器,较大提升了行为识别的准确率。
关于双视图行为识别,Su等人(2015)提出了双视图卷积神经网络(dual-view convolutional neural network,MVCNN),该网络成功实现了3D模型和CNN的结合,结合后的模型经过训练可以独立地对多个2D投影图像进行分类。Zeng等人(2019)针对双视图池化方法进行改进,提出一种基于学习的多池融合方法(learning-based multiple pooling fusion,LMPF),通过学习一组最佳权重以使多个不同视图的融合效果达到最佳。
2 本文方法
2.1 行为识别框架
图2展示了本文装箱行为识别模型。模型使用两个不同视角的RGB视频作为输入,两个RGB视频分别为不同视角的摄像头在实际装箱场景中获取的同一时间段的视频。然后使用差分法处理输入的RGB视频得到差分图像(residual frames,RF),作为模型的另一个输入。
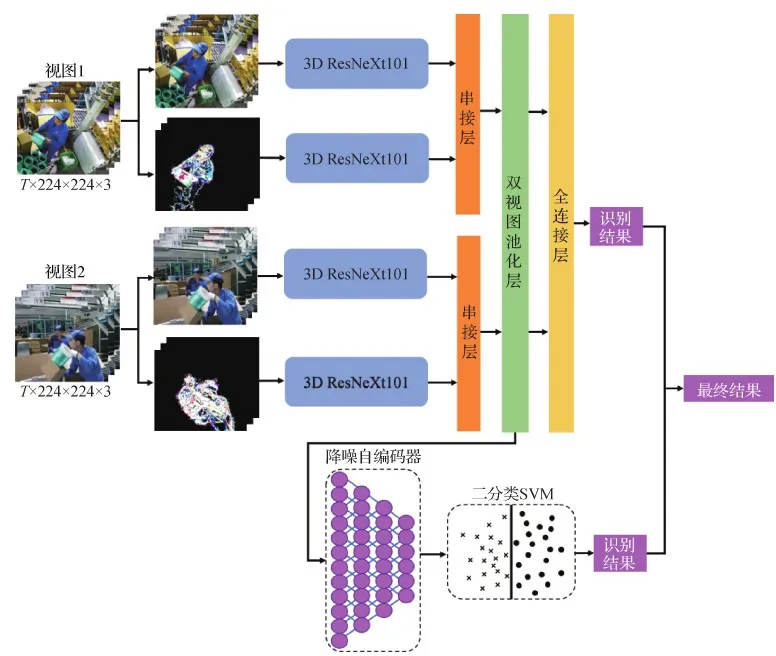
图2 装箱行为识别模型Fig.2 Packing action model
单个视图的每一批输入数据(原始RGB视频)的形状为T×H×W×C,也就是T帧高度为H、宽度为W且通道数C为3的RGB图像。每个3D卷积层同时在3个维度计算输入的数据。模型的每个视图都包含一个基于差分图像的3D ResNeXt101模块和一个基于RGB图像的3D ResNeXt101模块,本文将两个3D ResNeXt101的最后一个卷积层使用一个串接层(concatenation layer)进行融合,然后由一个可学习的双视图池化层将多个视图的特征融合,传递到一个全连接层,最后输出判别结果。在此基础上,本文引入降噪自编码器和two-class SVM来进一步排除不存在装箱动作的装箱过程,提高真负率。将模型经过双视图池化之后的特征作为降噪自编码器的输入,在经过降噪自编码器优化之后送入two-class SVM进行二次判别。通过两次的判别结果得到最终装箱行为识别的结果。
2.2 RGB和差分图像结合的网络结构
大多数行为识别方法通过对RGB视频进行特征提取来获得行为识别结果(Ji等,2013;Carreira和Zisserman,2017;Tran等,2015),本文在使用RGB图像作为输入的同时引入一个差分图像模块来优化模型性能。
通过相邻帧相减来获取差分图像,保留两帧间的不同。由于差分图像的特殊性,在单个差分图像中,运动信息存在于空间轴。将差分图像用于2D卷积中,已经证明是有效的(Wu等,2018)。但是较为复杂的动作持续时间相对更长,并不是单独一帧可以表示,需要连续的多帧差分图像。这时动作信息不单单存在于空间轴,还存在于时间轴上,相邻帧之间的联系也作为运行信息的一部分。
同时,相较于2D卷积网络,3D卷积网络由于增加了时间维度,可以更好地提取视频的时空特征,事实证明使用3D卷积网络具有更高的准确性(Tao等,2020)。3D ResNet是3D卷积网络与残差网络的结合,相比C3D具有更高的准确性和更快的运行速度。本文使用性能较好的3D ResNeXt101模型来处理输入的差分图像,从中获取运动特征。
本文使用Fi表示第i帧,Fi-j表示第i-j帧的连续堆叠帧,RFi-j表示第i-j帧的连续差分图像。图3所示为使用差分法获取差分图像的示意图,获取差分图像的过程可以表述为
RFi-j=|Fi-j-Fi+1-j+1|
(1)
与光流的计算成本相比,差分图像的计算成本非常低,甚至可忽略不计,可以应用在实时场景中。而且差分图像中只包含运动物体的信息,处于静止状态的背景不会出现在差分图像上,可以剔除工厂复杂背景对识别效果的影响。但是差分图像只显示运动的部分,特别是在工人装箱过程中运动主要集中在双手,除工人双手以外的外观信息有时不会出现在差分图像上,只使用差分图像作为模型的输入,可以一定程度地区分出工人的投放动作,但同时外观信息的丢失也会降低结果的精度。Carreira和Zisserman(2017)使用3D卷积中在Kinetics数据集上的实验表明,同样的3D卷积模型在只使用RGB图像作为输入时效果相对只使用光流更好,RGB图像仍然是3D卷积模型获取时空特征的主要途径。因此,本文使用另一个基于RGB图像的3D ResNeXt101模块来获取差分图像中缺失的外观特征和RGB图像中额外的运动特征。使用基于差分图像的3D ResNeXt101的目的是用来获取RGB图像中没有的运动特征,进而提升模型的准确性。在行为识别领域,多个网络框架的融合一般使用直接得到各个框架的得分,然后通过加权或者平均得分的方式得到最终结果的方法(Simonyan和Zisserman,2014),或者通过一个串接层(concatenation layer)将各个模块提取到的特征进行融合(Rastgoo等,2020)的方法。为了更好地利用多视图之间互补的特性,便于多模块特征融合之后的双视图特征融合,本文使用串接层将RGB和差分图像模块提取的特征融合。

图3 差分图像获取过程Fig.3 The process of obtaining residual frame((a) front RGB;(b) latter RGB;(c) residual frame)
本文使用两个并行的3D ResNeXt101模块,两个模块分别接收原始RGB图像和差分图像作为输入。在两个3D ResNeXt101模块的最后一层卷积层之后加入一个串接层将两个模块的特征串联到一起,用于后续的双视图特征融合。
2.3 多视图学习
由于实际生产环境的限制,装箱工人身体的关键运动部位易被遮挡,只使用单个视图进行检测会由于缺失关键的运动信息导致识别准确率下降。为了使本文模型在训练和测试阶段可以获取到完整的运动信息,本文使用双视图的方式,使用两个不同视角的摄像头来获取装箱过程的图像,作为模型的输入。利用3D卷积网络和双视图的学习能力对装箱过程中的工人进行装箱行为识别。
相比单视图,多视图数据还包含额外的一致信息和互补信息,可以在这些额外的信息中学习到有意义的输出。其中,一致信息用于平衡多视图信息,互补信息用于不同视图之间的信息互补。利用多视图学习的一致信息和互补性信息,使图像信息得到最有效的提取和表示。使用两个并行的3D ResNeXt101模型对不同视图进行特征提取,然后采用一个视图池化层来融合双视图信息。直接采用最大池化和平均池化是融合过程中较为常用的方法,但是最大池化方法容易出现过拟合,网络的泛化能力差;平均池化不能很好地反映池化区域的特征,较小的元素会削弱较大元素对激活值的贡献,两者都会导致部分信息丢失。针对这个问题,本文使用一种可学习权重的视图池化层来融合多个视图的特征(权重学习视图池化层)。其计算为
OL(p,q)=w1×Omax(p,q)+w2×Omean(p,q)
(2)
式中,w1和w2分别是最大池和平均池的权重,初始值分别为1和0,权重优化过程中保证两个权重的总和为1。具体来讲,权重学习视图池化层在对位置(p,q)做双视图特征融合时,分别计算一个使用最大池化方法做特征融合的结果Omax(p,q)和一个使用平均池化方法做特征融合的结果Omean(p,q)。最后使用学习到的权重w1和w2,计算出最终位置(p,q)的双视图特征融合结果OL(p,q)。本文使用BP(back propagation)算法实现整个训练阶段的最佳权重搜索,本文使用的双视图池化方法如图4所示。
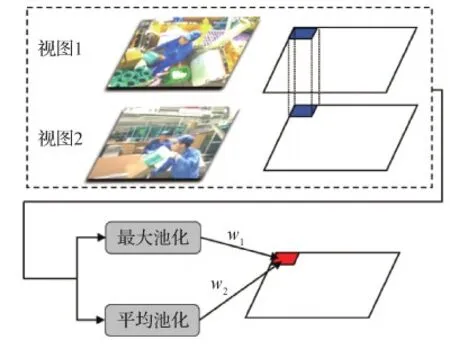
图4 双视图池化方法Fig.4 Dual-view pooling fusion
本文双视图池化层是针对多个特征图的最大池化策略和平均池化策略的融合,通过端到端的训练,可以学习到一组最佳池化权重w1和w2。使用该方法能将最大池化和平均池化有效地结合起来,从而减少双视图池化阶段的信息丢失。
2.4 二分类SVM模型
使用双视图和差分图像相结合的模型,在识别装箱动作上已经有了较好的表现。但是,实验显示在一些复杂工业场景的影响下,本文模型仍会将一部分不存在装箱动作的装箱过程错误判断为存在装箱动作。为满足生产场景需求,尽可能排查出不合格装箱产品,保证产品合格率,这样的错误需要尽量避免。针对这个问题,本文加入降噪自编码器和two-class SVM来进一步排查没有出现装箱动作的装箱过程,提高装箱行为识别的真负率。本文将模型中经过双视图池化后的特征经过一个降噪自编码器优化、降维之后得到的特征向量作为two-class SVM的输入,然后对输入的特征样本进行分割,将结果分为存在装箱动作和不存在装箱动作两类。
two-class SVM的主要方法是将训练数据通过核函数映射到一个高维的特征空间,然后在这个高维的特征空间寻找一个最佳超平面将这些特征向量分割为存在装箱动作和不存在装箱动作。具体而言,给定训练样本集{(x1,y1),(x2,y2),…(xn,yn)},其中,xi∈Rd为d维样本输入,yi∈(+1,-1)为样本输出。为了确保超平面以最优的边界将样本进行分类,需要优化问题,即

(3)
式中,xi为训练样本,yi为类别标号,b是一个偏移量,w∈Rd是需要学习的权重向量,第i个训练样本的拉格朗日系数αi>0。其最终决策函数计算为

(4)
式中,αi通过优化式(3)得到;sign()为符号函数。当pw,b(x)<0时,表示two-class SVM模型将特征判定为存在装箱动作;否则pw,b(x)>0时,SVM模型判定为不存在装箱动作。

2.5 三层堆叠的降噪自编码器
降噪自编码器(Vincent等,2008)是一种有效的无监督特征表达技术。它具有多个可学习的隐藏层,隐藏层的参数不是手动设置的,而是根据给定的数据自动学习的。已有工作表明(Budiman等,2014),经过训练的降噪自编码器可以有效表现视频帧中的原始动作信息,并且学习到相邻帧之间的信息变化。同时降噪自编码器还可以利用编码、解码的特点,将高维特征压缩到低维,这解决了双视图池化之后特征维度过高的问题。本文引入降噪自编码器来优化从双视图池化层中获取到的特征,用于two-class SVM的输入,从而使two-class SVM模型更好地将有装箱动作的视频片段和无装箱动作的视频片段分隔。
自编码器包括两个阶段,即编码阶段和解码阶段,这两个阶段共享一个隐藏层。在编码阶段,数据从输出层到隐藏层,即
h(x)=sigm(Wx+b)
(5)
在解码阶段,数据从隐藏层到输出层,即
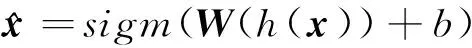
(6)
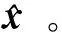
(7)
在训练过程中,降噪自编码器通过最小化损失函数来学习参数(W,b)。为了提升收敛速度和获取更高级的特征,本文使用由3个降噪自编码器构建而成的一个3层的堆叠降噪自编码器。
本文的堆叠降噪自编码器如图5所示,训练阶段以逐层方式进行。在测试阶段,去掉堆叠自编码器的解码部分,通过编码部分的3个隐藏层对输入的特征进行优化。3个隐藏层分别将2 048维特征向量编码为1 024维、512维、256维。然后直接使用瓶颈隐藏层(bottleneck hidden layer)输出的256维的特征向量作为two-class SVM的输入。

图5 堆叠降噪自编码器Fig.5 Stacked denoising autoencoder
2.6 装箱行为识别
针对工业装箱场景中的装箱动作,本文提出了双视图3维卷积网络的工业装箱行为识别方法,通过识别是否出现装箱动作来判断装箱工人是否投放配件。主要工作包括:1)针对人体遮挡问题,设计了双视图结构,使用两个不同角度摄像头同一时间获取到的RGB视频作为双视图模型的输入,并使用一个可学习权重的双视图池化层融合两个视图的时空特征。2)针对光流的巨大计算成本,本文使用堆叠的差分图像作为模型的输入来更好地提取运动特征,替代实时场景中无法使用的光流。原始RGB图像和差分图像分别输入到两个并行的3D ResNeXt101中。3)为提高模型的真负率,满足装箱场景需求,在模型中加入堆叠降噪自编码器和two-class SVM。
本文提出的装箱行为识别方法具体流程如下:将两个视图的每次装箱过程的RGB视频作为模型的输入,连续RGB图像和对RGB图像做差分计算得到的连续差分图像作为输入数据,分别输入到4个3D ResNeXt101中,经过模型计算后得到初步识别结果。为了进一步排查无装箱动作的装箱过程,提高真负率,将模型中经过双视图池化后的特征输入到降噪自编码器,通过训练好的降噪自编码器对特征优化和降维,然后利用two-class SVM模型进行二次判断,得到二次识别结果。只有两个识别结果都表明这次装箱过程中存在装箱动作,才最终判定这次装箱过程存在装箱动作,认为装箱工人在这次装箱过程中投放了配件。否则判定这次装箱过程不存在装箱动作,认为装箱工人在这次装箱过程中没有投放配件,装箱行为识别模型流程可形式化表述为图6所示。总结来讲,通过两次的装箱动作判别,只有两次的识别结果都判定存在装箱动作时,最终结果才为“装箱成功”,否则“装箱失败”。

图6 装箱行为识别模型执行流程Fig.6 The execution process of packing action model
该判别策略是在模型中加入了降噪自编码器和SVM的基础上制定的,会将没有装箱动作的装箱过程尽可能识别出来,进而提高真负率。但由于经过两次判别,部分存在装箱动作的装箱过程会被误判为不存在装箱动作,可能导致准确率下降。
3 实 验
3.1 双视图装箱动作数据集
双视图装箱动作数据集(dual-view packing action data,MPAD)由7个装箱工人在实际装箱过程中执行,包含2个不同视角,3个不同的装箱场景,共2 400个RGB视频。每个RGB视频就是装箱工人的一次装箱过程,视频帧率为25帧/s,视频时长约为5 s。根据实际生产过程,数据集中包含为两个类别:有装箱动作的装箱过程(70%)、没有装箱动作的装箱过程(30%)。本文将数据集MPAD随机划分为训练集(80%)和测试集(20%)。数据集中的装箱动作为装箱工人投放配件的动作。在该数据集上,对单视图行为识别方法进行评估,本文将两个视图的RGB视频拆分成两个独立的RGB视频,作为单视图行为识别方法的输入。
3.2 实验细节
使用Pytorch作为深度学习平台,并使用2个NVIDIA RTX 2080Ti来评估本文方法。数据在输入网络之前,会先执行水平翻转,在训练阶段中应用时间抖动。批尺寸(batch size)设置为32,使用随机梯度下降作为优化策略,动量(momentum)设置为0.9,学习率初始值设置为0.1,每50轮训练减小为初始值的1/10。本文模型共进行400轮训练。为了验证模型中双视图结构的作用,加入了单视图模型进行比较。通过将双视图模型的视图池化层删除并由串接层直接与全连接层相连,完成本文的单视图模型,单视图模型的输入也从两个视图修改为一个视图。
引入降噪自编码器和two-class SVM来提高真负率,在不需要分析真负率,只需评估准确率的实验中,不使用降噪自编码器和two-class SVM,剔除降噪自编码器和two-class SVM对模型准确率的干扰。在UCF101数据集中的实验中也使用去除降噪自编码器和two-class SVM的单视图模型来和主流行为识别方法进行对比,原因为UCF101是单视图数据集且由于UCF101包含多个动作类别无法使用二分类支持向量机。
3.3 MPAD实验结果分析
在数据集MPAD上,对主流的行为识别方法和本文方法进行比较。表1展示了实验结果,从实验结果可以看出,本文方法获得了最高的准确率和真负率。表2评估了基于RGB图像和基于差分图像的两个3D ResNeXt101的效果,只使用差分图像作为输入使大量的外观信息丢失,导致较低的准确率。基于RGB图像的3D ResNeXt101相比差分图像取得较好的效果,RGB图像和差分图像结合的方法可以捕获到更丰富的特征,在数据集MPAD上取得了最高的准确率。

表1 在MPAD中与主流行为识别方法的比较Table 1 Comparison with mainstream action recognition methods on MPAD

表2 基于RGB和差分图像的3D ResNeXt101评估结果Table 2 Evaluation results of 3D ResNeXt101 based on RGB frames and residual frames
为了分析本文模型中各个模块的必要性,对不同模块组合策略进行了评估,并额外加入光流来和差分图像进行对比,表3展示了组合策略评估实验的结果。结果表明,使用双视图加光流的方法具有最高的准确率,但是对应的帧率只有6.2帧/s,在实时场景应用时会出现视频延迟的情况。同时使用双视图加差分图像的方法得到了较高准确率且帧率达到49.8帧/s,可以在实时场景应用。进一步说明差分图像是网络捕获运动特征的有效方法,通过使用差分图像替代光流,可以避免光流的复杂计算,解决无法在实时场景中应用的问题。另一方面,表3显示了本文引入的差分图像模块和双视图结构都能有效提升行为识别精度。
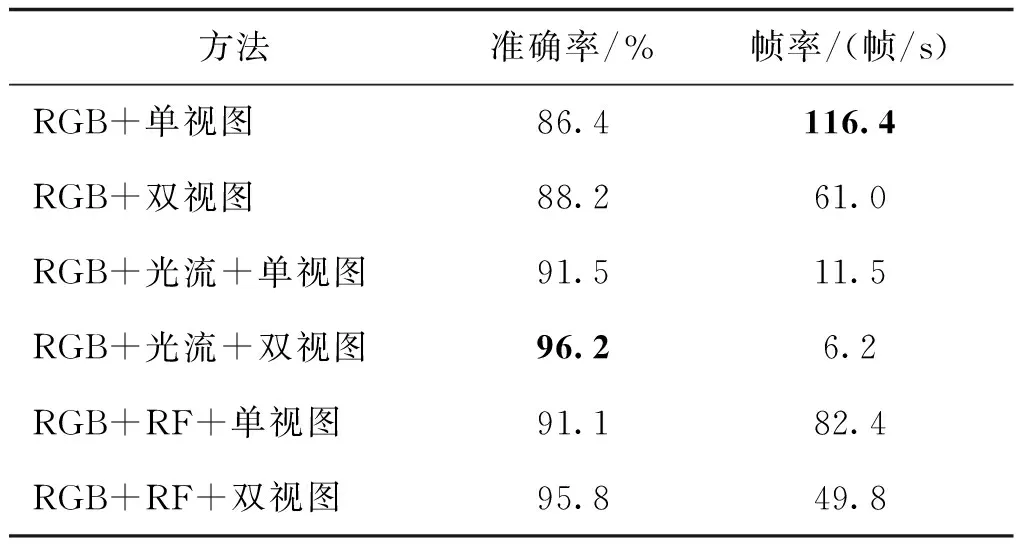
表3 在MPAD中不同组合策略评估结果Table 3 Evaluation results of different combination strategies on MPAD
为了提升模型的真负率,引入了降噪自编码器和two-class SVM,图7分别展示了只使用双视图模型、只使用降噪自编码器和two-class SVM以及两者结合的识别结果。图中的“双视图模型”是指不使用降噪自编码器和two-class SVM的方法;“DAE+SVM”表示3D ResNeXt101提取到的高层特征经双视图池化后直接由DAE+SVM来得到识别结果的方法。需要强调的是,图中的“双视图模型+ (DAE+SVM)”为两者结合的方法,即本文使用的装箱行为识别方法。该方法只有在双视图模型和(DAE+SVM)的识别结果都为“有装箱动作”时,才判定识别结果为“有装箱动作”,否则都判定为“没有装箱动作”,从而尽可能识别出所有没有装箱动作的装箱过程。
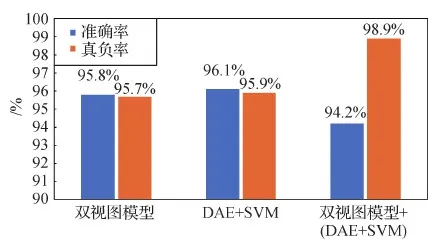
图7 在MPAD中对双视图模型和DAE+SVM的评估结果Fig.7 Evaluation results of DAE+SVM and dual-view model in MPAD
图7中双视图模型的准确率和真负率稍低于DAE+SVM。双视图模型和DAE+SVM的组合方法的准确率相较其他两种方法,下降了约2%,但仍然保持在一个较高的水平,同时该方法将真负率提高到了98.9%。造成准确率下降和真负率大幅提高的原因是在原双视图模型的基础上增加了DAE和SVM,并在此基础上修改了识别结果的判别方式,由于经过两次判别,将没有装箱动作的装箱过程尽可能识别出来,从而提高了真负率。但同时,在数据集MPAD中正样本占比70%的情况下,部分存在装箱动作的装箱过程被误判为不存在装箱动作,会导致准确率下降。
表4评估了在双视图模型中加入降噪自编码器和two-class SVM对真负率和准确率的影响,实验结果中,只加入two-class SVM而没有降噪自编码器的组合准确率只有91.5%。由于降噪自编码器对特征向量的优化和降维,同时加入降噪自编码器和two-class SVM的组合准确率达到94.2%,并获得最高真负率98.9%。使用降噪自编码器和two-class SVM与本文模型结合可以在有效提升真负率的同时保证较高的准确率,这样的组合更加符合实际装箱行为识别场景。

表4 对降噪自编码器和two-class SVM的评估结果Table 4 Evaluation results of denoising autoencoder and two-class SVM
3.4 UCF101实验结果分析

4 结 论
提出一种用于实际生产场景的装箱行为检测方法,该方法使用双视图3D ResNeXt101模型进行有效的装箱行为识别。使用两个并行的3D ResNeXt101,分别从RGB图像和差分图像中学习时空特征,以获得更丰富的特征,并使用可学习的视图池化层做双视图特征融合。此外本文训练了一个堆叠的降噪自编码器对双视图3D ResNeXt101模型提取的特征进行优化和降维,并使用two-class SVM模型进行二次检测来提高真负率(TNR)。实验结果和分析表明,本文装箱行为识别方法在数据集MPAD中得到的准确率和真负率分别为94.2%、98.9%,均优于其他6种主流行为识别方法。在人体频繁被遮挡的实际装箱场景中,本文方法可以精确识别出装箱工人的装箱动作,且同时保证识别结果的高真负率,满足实际生产场景需求。

表5 在UCF101中与主流行为识别方法的比较Table 5 Comparison with mainstream action recognition methods on UCF101
在实验过程中发现,本文模型中的双视图结构能够有效降低人体遮挡的干扰,但由于人体遮挡导致的运动信息不足,仍会有部分样本的装箱行为识别会受到遮挡的影响。未来的研究工作将致力于解决人体遮挡问题,通过增加视图数量来获取更多不同角度的运动信息,同时加入使用双目视觉得到的3维人体骨架作为模型的输入,进一步降低人体遮挡的干扰。
