自然光普通摄像头的眼部分割及特征点定位数据集ESLD
2022-08-09张俊杰孙光民郑鲲李煜付晓辉慈康怡申俊杰孟凡超孔江萍张玥
张俊杰,孙光民,郑鲲,李煜,付晓辉,慈康怡,申俊杰,孟凡超,孔江萍,张玥
北京工业大学,北京 100024
0 引 言
眼睛是心灵的窗户,已有研究表明,瞳孔大小的变化可以反映用户的健康状态、心理状态、情绪波动以及认知水平的变化(Kawai等,2013)。在医学领域,瞳孔状态对疾病的预防和诊断具有重要意义。比如通过测量患者瞳孔位置可以判断斜视程度。可以通过观测瞳孔大小对出现中毒现象或患有某些疾病的患者进行初步诊断(Wong等,2019)。但是当前对于瞳孔状态的判断需要医生通过经验进行自主诊断,主观性较强。在教育领域,通过对学生学习时瞳孔变化的分析,可了解学生们的兴趣点(Magill和Roy,2010)。近年来,随着在线教育的发展,传统课堂逐渐向线上教育发展。线上教育具有一对多的特点,当学生过多时,教师无法实时观测到所有学生的学习状态。通过采集学生上课时的视频,对视频进行分析,从而判断学生的上课状态以及知识的掌握情况。表情可伪装性较强,即使学生不能理解所学内容也可以做出具有迷惑性的表情,从而影响老师的判断。相比于表情,瞳孔的可伪装性较弱。因此,通过结合眼部信息,可以更加准确地对学生的上课状态进行判断(张俊杰 等,2020)。如何在无专业设备和附加光源辅助情况下对瞳孔变化进行分析成为亟待解决的问题。
尽管对瞳孔状态的研究已经进行了相当长的一段时间,但是相关应用却一直难以实现。主要原因是瞳孔仅在脸部占有很小的一部分,在实际生活中佩戴眼镜、反光以及睫毛的遮挡更增加了瞳孔观测的困难。特别是瞳孔与虹膜颜色接近,更是增加了观察的难度。已有的瞳孔数据集与实际生活中的图像相差较大。大部分的数据是在理想条件下采集得到的。如CASIA.V1(Chinese Academy of Sciences Institute of Automation Iris Image Database version 1.0)(Ma等,2004)、CASIA.V2(Chinese Academy of Sciences Institute of Automation Iris Image Database version 2.0)(Sun和Tan,2009)。这些数据集中的图像去除了影响图像质量的噪声因素,虹膜均匀地分布在图像中,瞳孔清晰,图像质量高。但是在真实环境下,影响图像质量的因素很多,该种类型的数据不能在实际中得到应用。为了解决上述问题,出现了许多增加噪声因素的数据集。

此外,瞳孔大小的变化可以为判断情绪变化提供数据支持。但是,已有数据集无法提供瞳孔位置变化的信息。面部特征点的运动可以用来表征面部表情的变化,从而反映用户情绪的变化。研究机构提出了不同的特征点检测模型,如表1所示。通过表1可以发现,已有特征点检测模型仅对眼周区域进行特征点的标定,如PUT和HELEN数据集分别对每张图片中左、右眼周围标定了20个特征点。少部分数据集包含了对瞳孔的标定,如BioID数据集对每只眼睛的内眼角、外眼角以及瞳孔进行了标定。但是还没有数据集对自然光下普通摄像头采集到的眼睛部位的瞳孔周围以及虹膜周围进行精细的特征点标定。这在一定程度上制约了基于普通摄像头对眼睛状态分析的发展。
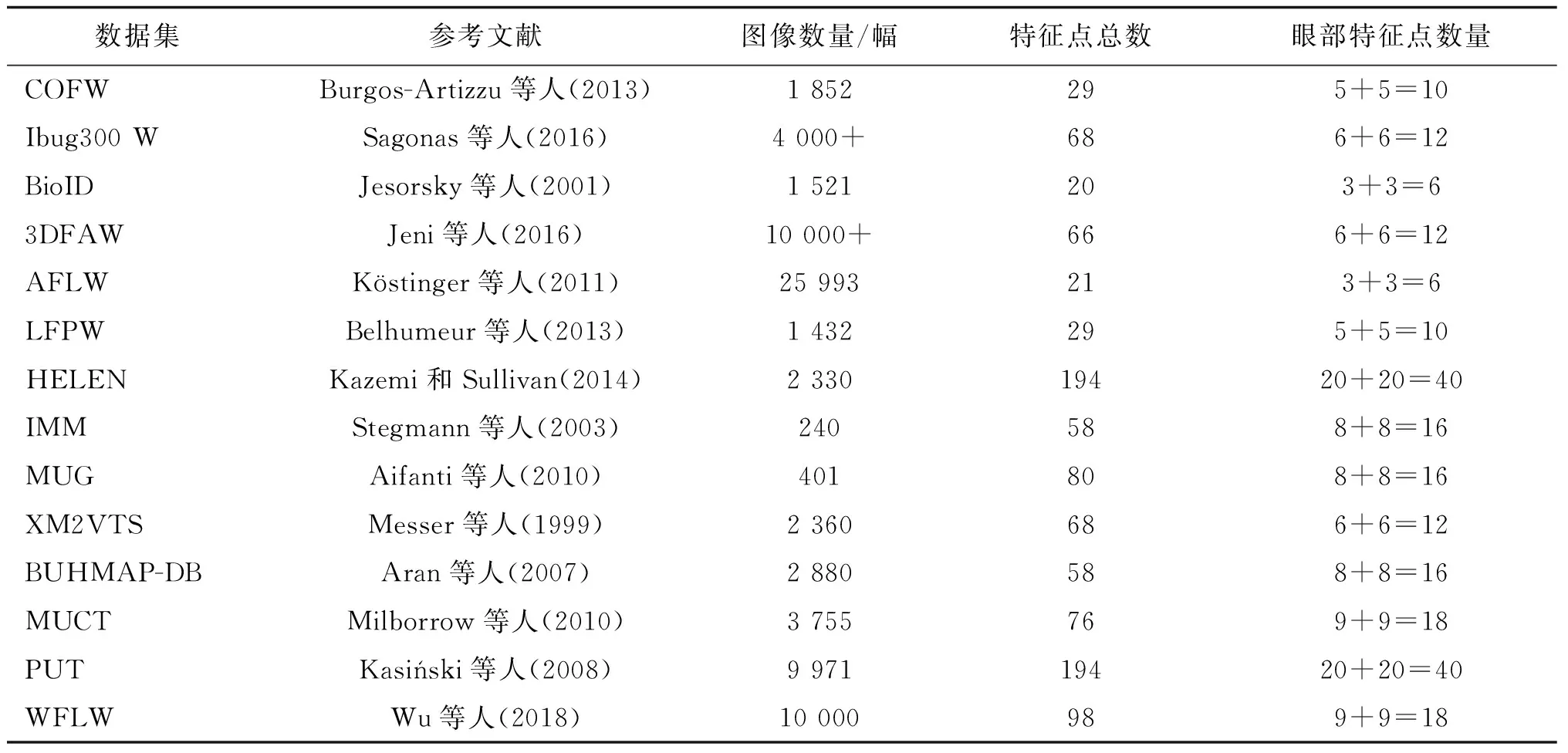
表1 特征点标定数据集Table 1 Landmark detection datasets
根据对已有虹膜检测数据集和特征点定位数据集分析可以发现,当前还没有数据集可将眼睛结构分割和眼部特征点的精细定位进行统一。本文提出一个建立在自然光环境下利用普通摄像头采集得到的眼部图像分割和特征点定位数据集(eye segment and landmark detection dataset, ESLD)。该数据集包含用户浏览网络信息时的图像、人工合成的眼部区域图像以及筛选出的当前已有数据集中满足自然光和普通摄像头两个条件下的图像。对所有满足条件的图像汇总后进行处理,提取眼部区域。ESLD数据集包含真实眼部图像以及合成眼部图像,因此该数据集是一个可以进行真、假图像检测的数据集。另外,该数据集中包含用户实际使用电脑过程中的数据,因此包含多种真实噪声,如佩戴眼镜、眼镜反光、佩戴美瞳和光线暗淡等。这更符合实际应用的需要,从而可以提高模型的泛化性和鲁棒性。
1 数据集
1.1 数据收集
数据集通过3种方式获得。第1种方式为分别在白天和傍晚两个时间段,采集6名学生使用电脑浏览屏幕内容时的视频,每段视频时长为5 min,共计12段视频。利用深度学习训练模型需要大量的数据,由于隐私等原因,大量获取到用户的眼部数据比较困难。因此,Wood等人(2016)开发了UnityEye(Park等,2018),用于生成带有标签信息的眼部结构数据。第2种方式为利用UnityEye生成的模拟眼部结构图像。利用该种方式可以生成具有不同分辨率、不同光照强度、不同脸部朝向和不同瞳孔位置的图像。第3种方式为在已有数据集中,选择能够满足在自然光下使用普通摄像头采集到的图像。将以上3种方式获取到的图像进行汇总,形成ESLD数据集。
1.2 生成眼部图像
通过以上3种方式可以获得不同编码方式的视频与图像两种格式的原始数据,因此需要对视频进行相关处理。首先利用opencv将视频进行分帧处理,将每个视频帧保存为jpg格式的图像。由于不同视频在采集时帧率以及采集时间存在差异,因此将会得到不同数量的图像。
1.3 数据预处理及眼部图像分割
不同方式获取到的图像之间存在一定的差异性。因此需要利用不同的方式提取图像中的眼部区域。原始图像包括以下4种类型,如图1所示。


图1 原始图像类型Fig.1 Different original image type((a)type 1;(b) type 2;(c)type 3;(d)type 4)
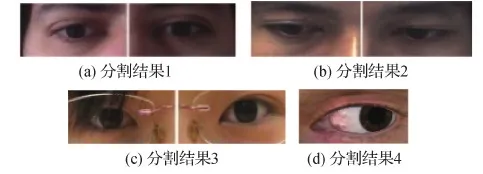
图2 眼部图像分割结果Fig.2 Eye region segment results((a)segment result 1;(b) segment result 2;(c) segment result 3;(d) segment result 4)
第2种类型的图像仅包含眼部区域。由于未提供眼部特征点标定文件,因此不能根据特征点的位置去除周围黑色背景信息。实验中发现,图像中黑色背景像素不为0,并且像素值会发生变化。因此在对图像进行遍历时,通过设置阈值的方式筛选出眼部区域。对于Multi-view Gaze(Lian等,2019)数据集中的图像,设置阈值为50,通过列表保存像素大于阈值时的坐标。图像是按照从左至右、从上至下的方式进行遍历,因此通过列表中记录的第1个和最后1个坐标可以确定眼部区域。此时眼部区域的长和宽分别为XB-XT和YT-YB,其中(XT,YT)为左上顶点坐标,(XB,YB)为右下顶点坐标。得到眼部图像后,以图像宽度的一半为界,分别对左、右眼部区域进行分割。分割结果如图2(b)所示。
最后利用UnityEye自动生成图像,可以通过修改参数生成具有不同亮度、姿态以及瞳孔位置的眼部图像。在生成图像的同时会生成对应的参数文件,根据文件中的特征点坐标分割图像,分割结果如图2(d)所示。不同分割方式得到的图像大小不同,因此所有图像被归一化为256×128像素。
1.4 数据标注
在图像中分割出眼部区域后,使用labelme(Russell等,2008)对归一化后的眼部图像进行特征点标定。为了避免个人判断带来的标定误差,由实验室多人共同进行标定工作。进行标定的人员共有6名,为了减少由于个体差异造成的标记差异问题,每名标记者在4种类型的图像中分别随机选择4幅进行标定,标定完成后,由一名标定经验丰富的人员对标定图像的质量进行判断。达到标准后,接着对剩余的图像进行人工标定。特征点标定位置如图3所示。包括编号为1—16的眼周部位特征点(红色点),编号为17—28的虹膜边缘特征点(黄色点)以及编号为29—40的瞳孔周围特征点(天蓝色点)。每幅图像标记完成后,标定结果保存成json文件。使用labelme根据json文件生成眼部分割结果,如图3(c)所示,其中绿色为瞳孔,红色为虹膜,黄色为巩膜。

图3 特征点标定及分割结果Fig.3 Eye region labeled and segment results((a)landmarks location;(b) an example of landmarks location;(c)an example of eye segment)
2 数据统计

图4 ESLD数据集中每种类型的眼部图像与已有数据集对比Fig.4 Comparison of each type of images in ESLD dataset with existing datasets((a)ESLD;(b)exiting datasets)
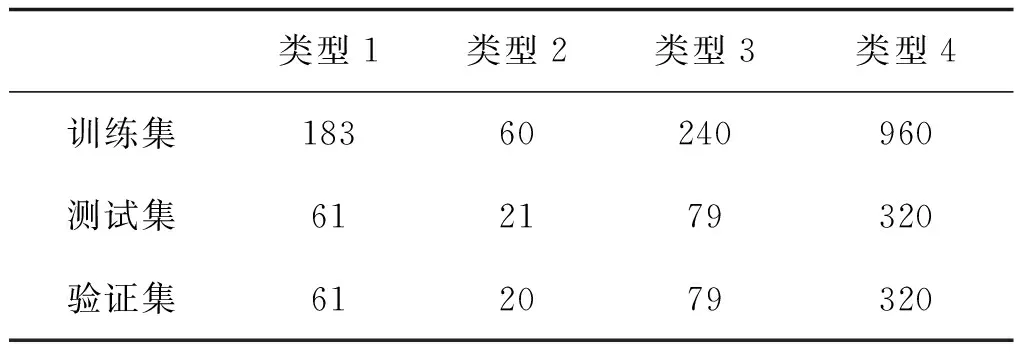
表2 每种类型图像数量在训练集、测试集和验证集中的分布Table 2 Distribution of sample size of each type of images in the training set,testing set and validation set
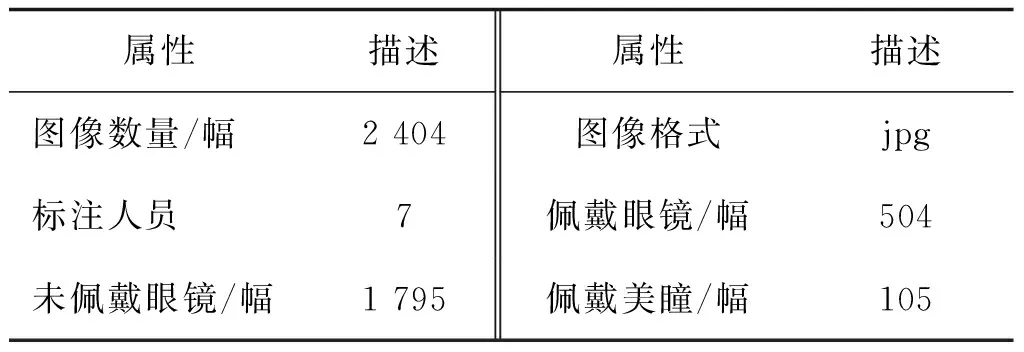
表3 ESLD数据集属性Table 3 ESLD dataset attributes
3 数据集基线
本文提出了ESLD数据集上的特征点定位和眼部结构分割的基线方法。根据ESLD数据集中图像种类的不同,将图像进行分类后可用于多种实际场景。
设计了3项具有实际应用价值的基准实验:1)数据集包含有真实眼部以及合成眼部图像,真实图像具有隐私性,生成逼真的眼部图像用于深度模型的训练,可以弥补训练数据不足的问题,给出了真假图像识别的基线。2)眼部状态的变化是多种因素共同作用的结果,利用眼部特征点的运动来表征眼部的变化,进行了特征点定位实验。3)眼部结构分割实验可为研究瞳孔变化与情绪变化提供数据支持。
实验使用python语言对图像进行预处理和深度学习模型的搭建。硬件配置为Inter(R) Core(TM) i7-8750H CPU, 主频2.21 GHz, NVIDIA GeForce GTX 2080显卡,16 GB内存,操作系统为Ubuntu, 集成环境为Anaconda Navigator,深度学习框架为Tensorflow。
3.1 真实与合成眼部数据基线
利用精准率(Eprecision)、召回率(Erecall)、准确率(Eaccuracy)以及F1值(Ef1)测试模型的分类性能,计算为
(1)
(2)
(3)
(4)
式中,TP为被正确划分为正例的个数,FP为被错误划分为正例的个数,FN为被错误划分为负例的个数,TN为被正确划分为负例的个数。
表4展示的是ESLD数据集真假眼部图像分类的基线。通过表4可以发现,模型的分类准确率小于50%,由此表明,模型不能准确地识别出生成眼部图像以及真实眼部图像。因此,仅通过准确率不能证明合成图像与真实图像接近,有可能将真实眼部图像识别为合成图像。接下来,分别计算模型的精确率和召回率。精确率是指预测为真实的眼部图像数量与所有预测结果为真实图像的比值。召回率是指预测为真实的眼部图像的数量占实际真实眼部图像的比率。通过分析精确率和召回率可以发现,模型将部分生成图像预测为真实眼部图像,结果表明生成图像与真实眼部图像在眼部结构具有相似性,生成是有效的。因此可以在训练数据中补充一定的生成图像解决训练数据不足的问题。

表4 真实与合成眼睛图像分类结果Table 4 Classification results on real and synthesis image
3.2 眼部结构分割实验
Mask R-CNN(region convolutional neural network)是多任务网络模型,可以实现目标检测、目标分类、目标分割和特征点定位任务,具有很好的通用性。ESLD数据集包含有眼部结构以及特征点,因此可利用Mask R-CNN完成以上两个任务。Mask R-CNN具有很强的灵活性,可以通过更换不同的特征提取网络从而提取不同的特征信息。同时,网络中融入了特征金字塔,使得网络可以提取不同尺度的信息。在眼部结构中,与虹膜和巩膜相比,瞳孔较小,不易检测。因此,包含有特征金字塔结构的网络模型适合于眼部结构分割任务。在模型的训练过程中,网络深度的增加会加大内存的消耗,为了适应不同的训练平台,分别选择ResNet34, ResNet50和ResNet101 3个模型作为特征提取网络,网络层数分别为34,50和101层。通过均值平均精度EmAP、精准率Eprecision、召回率Erecall、均值平均召回率(EmAR)、均值平均F1值(EmF1)以及单幅图像的检测时间(T)等指标对模型的分割性能进行评价,即
(5)
(6)
式中,AP为平均精确度,N为样本总数,QR为类别,recall(i)为第i类的召回率。
模型训练60轮(epochs)。为了研究图像类型的差异对模型分割效果的影响,分别测试4种类型下模型的分割效果。将4种类型的数据进行整合,对ESLD数据集中的所有数据进行训练。为了验证生成眼部图像对模型性能的影响,分别将生成的眼部图像与其他3种类型的图像进行混合,在相同训练轮次下得到模型的分割结果。分割结果如表5所示。实验结果显示,对于不同类型的图像,随着模型深度的增加,可以学习到不同类型图像间的差异,基于单一类别的模型对该类别具有相似的性能。混合类别可以提高模型的性能,特别是对浅层模型性能提升较大。进一步表明了合成眼部图像可以提升模型的性能。通过以上实验表明,增加数据的丰富性有助于提高模型的分类性能。对ESLD数据集中的所有数据进行训练的分割基线如表6所示。
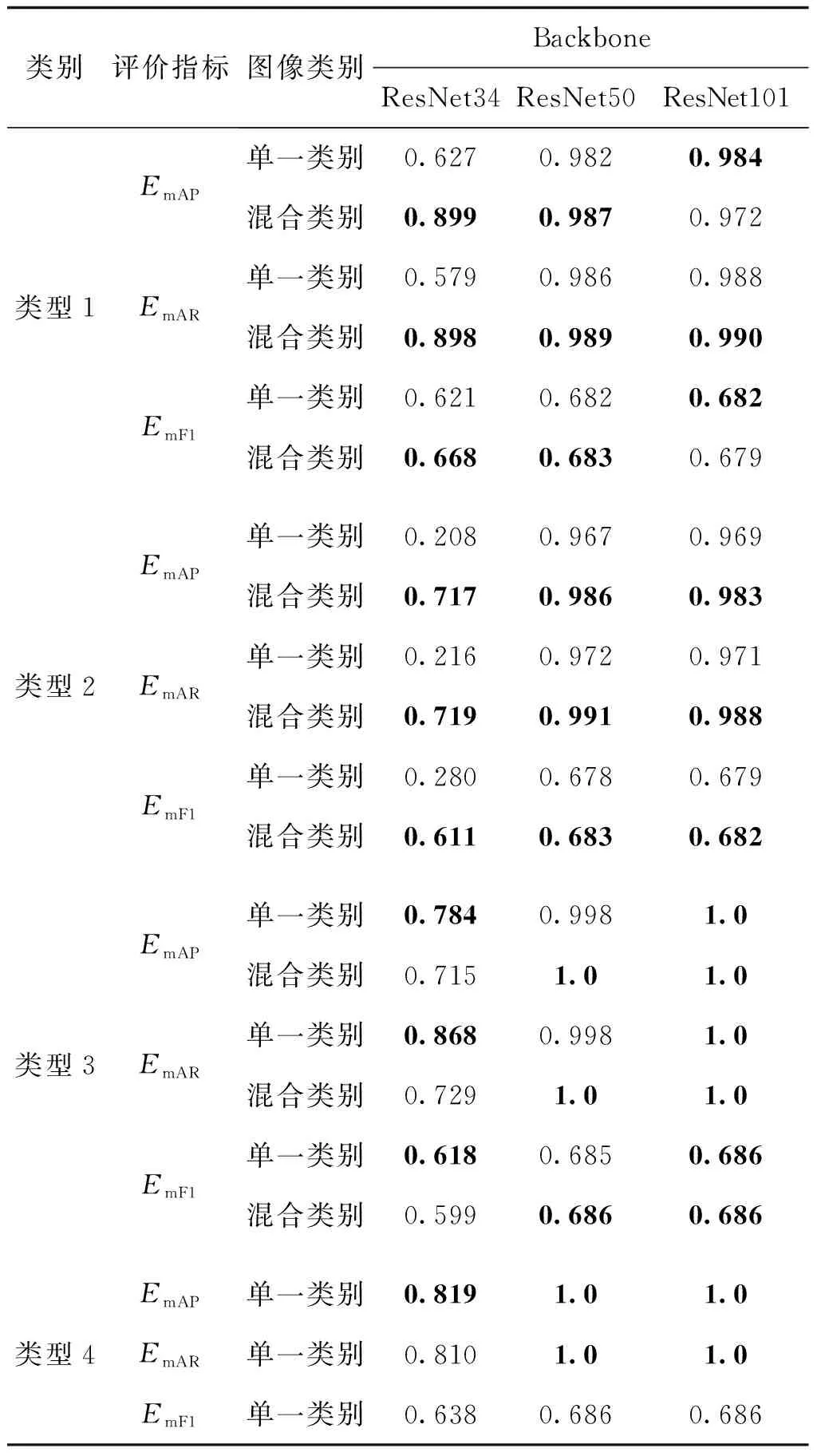
表5 不同类型下模型分割结果及合成图像对模型性能的影响Table 5 Segmentation results on different type of images and the influence of synthetic images for model
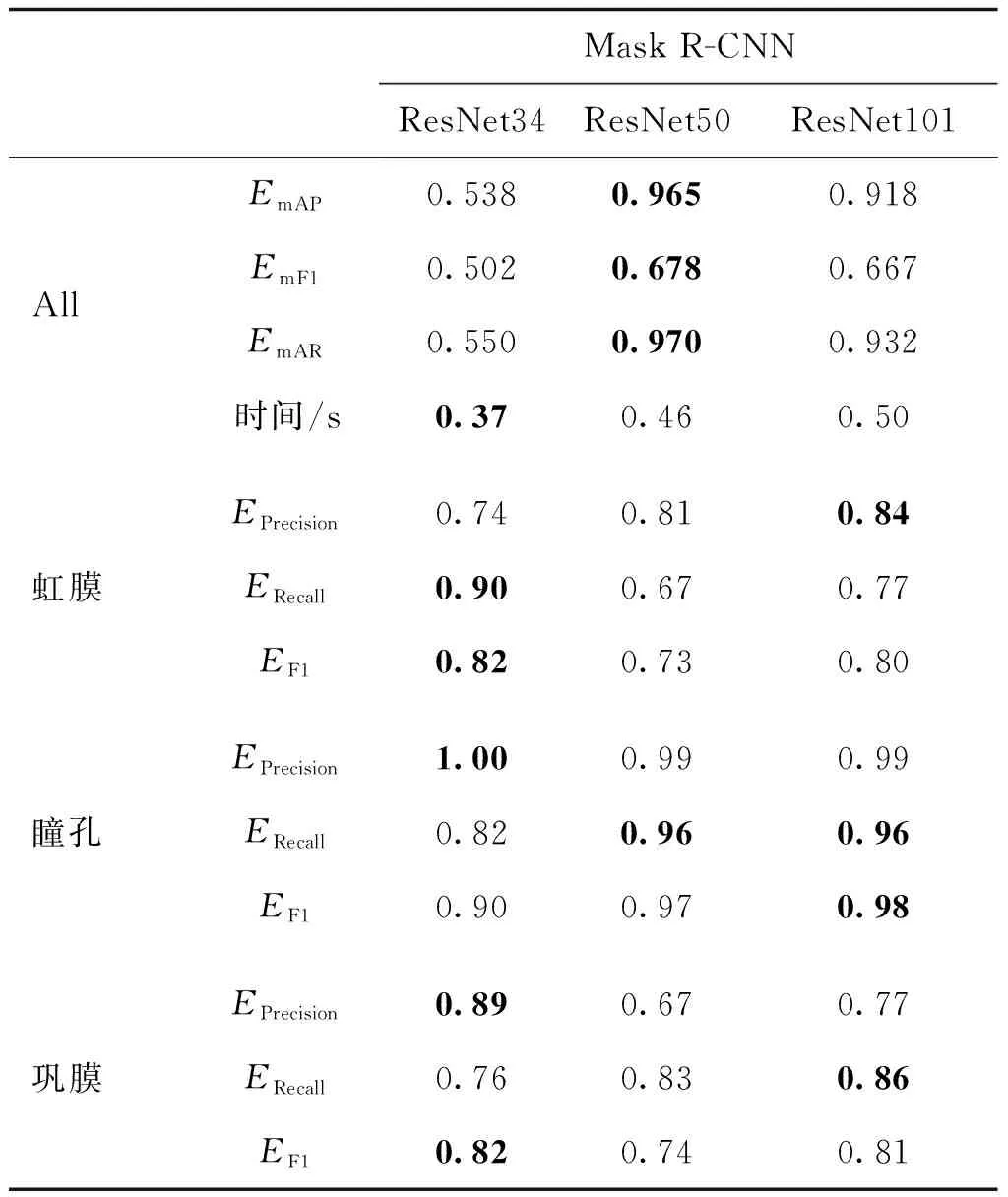
表6 ESLD数据集分割结果Table 6 Segmentation results on ESLD dataset
通过表6可以发现,随着模型深度的增加,对眼部结构的分割准确率得到提升,模型的鲁棒性更强。但是模型深度的增加使得单幅图像预测的时间更长。分别对瞳孔、虹膜以及巩膜的测试结果进行分析,对于瞳孔的分割效果最好,在该分割精度情况下,可以满足实际的需要。综合分割准确率、训练时间和预测时间3个因素,ResNet50为最优的特征提取网络。部分分割结果如图5所示。其中,第1行为原始眼部图像,第2行为标定分割结果,第3—5行分别为基于不同特征提取网络情况下Mask R-CNN的分割结果。采用ResNet101作为特征提取网络得到的分割结果与标注结果最接近,同时错分割以及多分割的情况较少,而ResNet34作为特征提取网络得到的分割结果中,出现错分割以及多分割的情况较多。因此,在相同训练轮数情况下,特征提取网络模型的深度越深,最终得到的loss值越小,图像的分割效果越好。模型训练曲线如图6所示。图6(a)—(c)分别为ResNet101、ResNet50和ResNet34作为特征提取网络情况下模型的损失曲线结果。
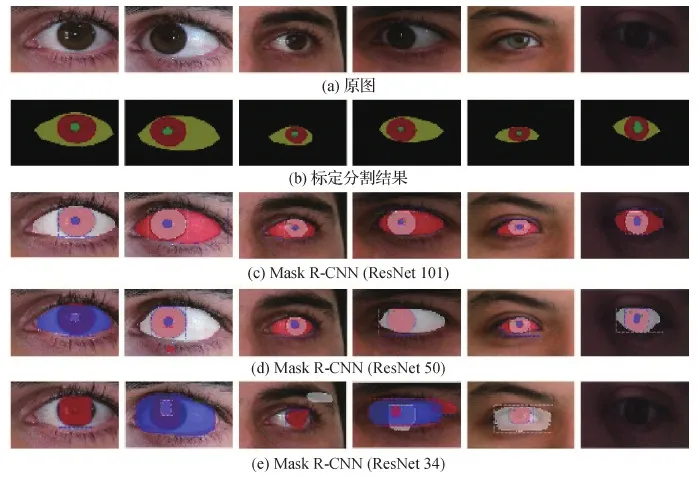
图5 眼部结构分割结果Fig.5 Sample results of eye region segment((a)original images;(b)ground truth;(c)Mask R-CNN(ResNet101);(d)Mask R-CNN(ResNet50);(e)Mask R-CNN(ResNet34))
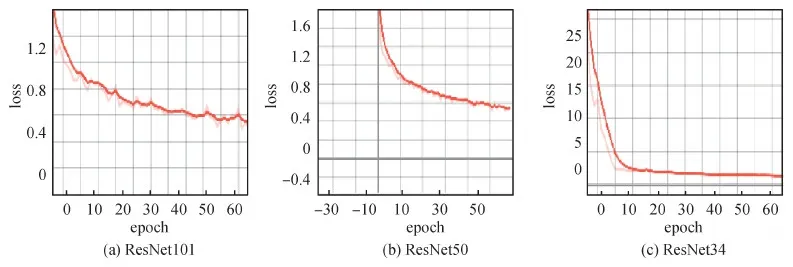
图6 分割模型训练曲线Fig.6 Training curves on segment model results((a)ResNet101;(b)ResNet50;(c)ResNet34)
3.3 眼部特征点定位实验
已有特征点检测数据集仅在眼周区域以及瞳孔中心进行特征点的标记,如LFPW(labeled face parts in the wild)和HELEN数据集。本文提出的ESLD数据集在眼部区域进行了精细的特征点标定。在眼部区域中包含有16个巩膜特征点,12个虹膜特征点以及12个瞳孔特征点。由于眼部区域很小,因此在小范围内对密集的特征点进行定位更具挑战性。
大数据是指规模巨大、结构复杂的数据集合,技术特点一般被称为“4V”,即体积大(Volume)、速度快(Velocity)、种类多(Variety)和实时性(Virtual)。大数据技术作为信息智能领域的核心技术之一,在城乡规划应用中有着巨大的优势:
已有特征点检测工作多基于深度学习方法。与传统算法相比,深度学习算法对特征点检测具有更准确的定位结果。因此。在基准实验中,使用深度学习的方法对特征点进行检测。利用Mask R-CNN可以在最小限度修改的情况下从实例分割任务转化为特征点检测任务。在2017年,Mask R-CNN在相同运行速率(5 帧/s)的情况下,在COCO(Microsoft common objects in context)特征点检测数据集上的准确率超过了2016年的冠军团队成果。通过提取每一个特征点的位置作为一个独热编码(one-hot)的二元掩膜,使用Mask R-CNN预测K个掩膜,此时每一个特征点分别对应于K个掩膜。特征点检测任务分为两种方式进行,第1种方式为仅利用原始特征点的位置对模型进行训练,第2种方式为结合特征点的掩膜对模型进行训练。特征提取网络为ResNet101和ResNet50。采用迁移学习的方式对模型进行训练。首先保持特征提取网络的其他结构参数不变,对head结构进行训练,训练批次为15。然后,保持特征提取网络stage 1到stage 3的结构参数不变,对其他部分结构进行训练,训练批次为10。最后,对整个特征提取网络进行5批次的训练。使用平均误差(mean error,EMD)对模型进行评价,即
(7)
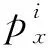

表7 不同图像类型下特征点定位结果及合成图像对模型性能的影响Table 7 Landmarks detection results on different type of images and the influence of synthetic images for model
实验结果显示,基于单一类别图像特征点的定位误差较大,由于类型3中包含了较多姿态变化的眼部图像,因此该种类型图像的定位误差最大。通过在单一类别眼部图像数据集中增加合成眼部图像,可以有效提高特征点定位的准确性。
将4种类型图像进行混合,从而增加训练数据的丰富性,特征点定位结果如表8所示。
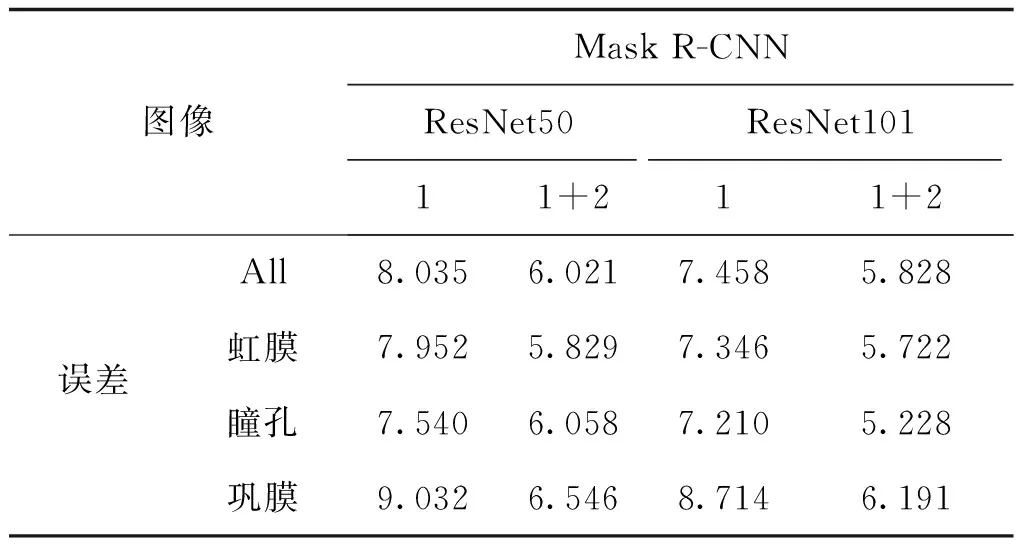
表8 ESLD数据集特征点定位结果Table 8 Landmarks detection results on ESLD dataset
通过对表8进行分析可以发现,特征提取网络的层数越多,特征点的定位结果越好,增加图像的类别可以有效地提高特征点的定位准确率。另外,通过结合图像的掩膜特征可以有效地提升特征点定位的准确性。因此结合图像的掩膜,采用更深的网络模型,可以提升特征点定位的准确性。眼部定位结果如图7所示。通过模型训练结果曲线图(图8)可以发现,结合图像的掩膜信息,可以使网络更容易收敛。在相同训练批次情况下,定位更加准确。

图7 眼部特征点定位结果Fig.7 Sample results of landmarks detection((a)original images;(b)ResNet101 mask;(c)ResNet50 mask;(d)ResNet101;(e)ResNet50)

图8 关键点定位模型训练曲线Fig.8 Training curves of landmarks detection((a)training curve based on ResNet101;(b)training curve based on ResNet50;(c)training curve based on the combination of ResNet101 and mask;(d)training curve based on the combination of ResNet50 and mask)
与眼部结构分割任务相比,特征点定位任务更加具有挑战性。眼部区域较小,特征点分布集中,另外,瞳孔边缘与虹膜边缘不明显,增加了特征点定位的难度。
4 结 论
眼部外观变化对分析用户的情感、心理等具有十分重要的现实意义。真实环境下的眼部图像数据得到研究人员越来越多的关注。然而,当前还没有对普通摄像头采集到的眼部图像进行精细的特征点标记和分割的数据集。本文基于收集实际采集、合成的眼部图像,以及现有数据集中的图像,精细标记了一个眼部特征点定位和分割数据集ESLD。ESLD是一个多类型眼部结构数据集,包含自然光下普通摄像头采集到的眼部图像以及合成的眼部图像,通过ESLD数据集可进行多种实验。视频以及图像是在自然环境下采集得到的,因此包含多种眼部角度的变化、环境光照的变化、用户与采集设备间距离的变化以及多种条件的遮挡。实验表明生成眼部数据可以有效地克服训练数据不足的问题,与眼部结构分割相比,眼部特征点定位具有更大的难度。因此,在自然光下对普通摄像头采集到的眼部图像进行情感分析、身份识别具有很大的困难。建立一个自然环境下的眼部图像数据集是十分必要的。该数据集可为通过眼部状态对用户的身份进行识别以及对情感以及心理状态的研究提供数据支持。
ESLD数据集通过3种采集方式得到4种类型的面部图像。通过多种方式得到眼部图像,特别是选择出在自然光下普通摄像机采集到的人脸数据集,可以在一定程度上弥补眼睛全面性有限的问题。但是,本文提出的数据集仅采集健康用户眼部的图像,缺乏对患有眼部疾病患者眼部图像的采集,如眼颤和斜视,限制了模型的使用范围。在以后的工作中,可以采集更多健康用户不同眼部形态和不同光照等情况下的眼部图像,以及增加对于患有眼部疾病患者眼部图像的样本收集。
