基于工业互联网体系架构的矿井大数据平台设计与实现
2022-08-09张晓霞李首滨苏上海
张晓霞,李首滨,苏上海,李 昊
(煤炭科学研究总院有限公司 矿山大数据研究院,北京 100013)
0 引 言
物联网、大数据和人工智能、云计算是智慧煤矿的三大支撑[1],随着煤炭行业工业化和信息化的逐步深度融合,采用先进的信息化技术解决煤炭行业在智能化、智慧化转型中的问题成为迫切需求。智慧煤矿物联网技术与装备是智慧煤矿关键核心技术之一[2],随着物联网技术的发展和快速应用,现有煤矿各类监控系统已经实现了对于煤矿生产关键信息的基本感知,并通过综采工作面自动化系统的应用大幅促进了智能化开采技术的创新发展[3]。然而不同厂家的产品基于本企业标准生产,其数据接口与平台各异,数据独立进行处理,相互之间缺乏通信与融合,数据孤岛与数据碎片化现象严重,因而难以形成有效的数据分析模型与算法,分析结果也就缺乏准确性,难以指导生产[2]。
针对智慧煤矿建设中面临的上述挑战,行业专家和学者指出,需要研究通过边缘计算和云计算服务实现设备数据互联[3]。同时基于分布式计算技术,通过大数据计算框架构建智慧矿山多源异构信息大数据服务平台,对井下各类通信协议进行转换、对各类传感器采集的信息进行数据格式统一、数据抽取、数据清洗、数据转换与校验、数据建模、数据挖掘与深度融合,并通过建立统一的数据服务接口,为上层应用提供统一的数据服务,实现数据的共享[4]。
首先阐述了工业互联网、工业互联网平台、边缘计算和边缘云平台的基本概念和技术体系,研究不同层级煤炭工业互联网平台的功能和定位,然后运用工业互联网平台体系架构和技术,借鉴工业互联网平台在其他行业的落地经验,进行了解决方案设计、相关技术研究和试验验证,提出了矿井工业互联网平台设计方案,以及矿井工业互联网PaaS平台的核心支撑大数据平台技术实现方案。为智慧矿山建设提供大数据基础平台能力、数据管理和分析能力、数据建模和应用支撑能力。
1 工业互联网技术体系和发展
1.1 工业互联网概述和技术体系
工业互联网是新一代信息技术与制造业深度融合的产物,通过实现人、机、物的全面互联,构建全要素、全产业链、全价值链全面连接的新型工业生产制造和服务体系,成为支撑第四次工业革命的基础设施[5]。工业互联网的核心是通过更大范围、更深层次的连接实现对工业系统的全面感知,并通过对获取的海量工业数据建模分析,形成智能化决策。
可以看出,工业互联网的核心要素是数据,从感知控制、数字模型、决策优化3个基本层次形成数据核心功能,通过自下而上的信息流和自上而下的决策流形成了工业数字化应用的优化闭环[6]。从体系架构发展上,工业互联网产业联盟在2016年8月发布工业互联网体系架构1.0,到2020年4月发布工业互联网体系架构2.0,基本形成平台、网络、安全三大系统,网络是基础,安全是保障[6],工业互联网平台是整个工业互联网的核心。通过网络、平台、安全三大功能体系构建,全面打通设备资产、生产系统、管理系统和供应链条,基于数据整合与分析实现IT(Information Technology)与OT (Operation Technology)的融合和三大体系的贯通[6]。
1.2 工业互联网平台构成及应用现状
工业互联网平台是面向制造业数字化、网络化、智能化需求,构建基于海量数据采集、汇聚、分析的服务体系,支撑制造资源泛在连接、弹性供给、高效配置的工业云平台[7]。
工业互联网平台包括边缘层、平台层和应用层3个关键功能组成部分。边缘层通过大范围、深层次的数据采集,以及异构数据的协议转换与边缘处理,构建工业互联网平台的数据基础。平台层包括IaaS层和工业PaaS层,IaaS层提供云计算基础设施,包括服务器、存储、网络资源和虚拟化,工业PaaS层基于通用PaaS叠加大数据处理、工业数据分析、工业微服务等创新功能,构建可扩展的开放式云操作系统。应用层形成满足不同行业、不同场景的工业SaaS和工业APP,形成工业互联网平台的最终价值[7]。
国内工业互联网平台发展迅速,IT企业和OT企业根据自身的背景和优势从不同的切入点进行发展,形成了一些典型的工业互联网平台。目前各类型平台数量已有数百家[5]。由于不同行业的诉求差异比较大,各行业的工业互联网平台侧重点和应用场景也各不相同。
相比传统的工业运营技术和信息化技术,工业互联网平台的复杂度更高,部署和运营难度更大[5]。工业互联网平台是一项长期、艰巨、复杂的系统工程,整体上尚处在发展初期,技术水平还不能满足全部工业应用需求,还需要很长时间才能真正达到成熟发展阶段[5]。
1.3 边缘计算及边缘云
边缘计算是指在靠近物或数据源头的网络边缘侧,融合网络、计算、存储、应用核心能力就近提供边缘智能服务的开放平台[8],可以缓解网络传输、减轻云端压力。工业互联网边缘计算从2016年开始研究,发展迅速,目前已有产业化应用。
边缘云的概念是相对云计算提出的,是结合云计算技术的核心和边缘计算的能力,构筑在边缘基础设施之上的云计算平台,提供边缘位置的计算、网络、存储、安全等弹性服务,并与中心云和物联网终端形成“云边端三体协同”的端到端的技术架构。
边缘计算目前的探索中,有IT厂商、终端领域厂商和通信领域厂商,由于既有积累和行业经验的不同,给出的方案各有不同,实现方式上也采用不同的开源框架和底层技术,存在各自的局限性。
2 矿井级工业互联网平台设计
2.1 煤炭行业数据特点
智慧矿山建设中,从技术层面,煤矿数据的获取利用、智能决策是需要重点突破的方向之一[9]。煤矿数据按照数据来源可以分为智慧感知、生产执行、安全保障、生产经营、综合决策5个业务域[10]。按照数据特点来看,“非实时、长周期数据、业务决策型数据”主要集中在煤矿的设计管理、供应链管理、生产计划制定、外销管理、成本分析等经营管理领域,而“实时性、短周期数据、本地决策数据”则主要集中在智能化工作面、智能化掘进工作面和基于视频识别的联动控制等生产系统领域[11]。
根据上述两类煤炭业务数据特点,非常适合采用工业互联网平台云-边-端体系架构进行一体化设计和部署。低延时、实时响应运算用边缘计算技术进行数据采集及处理。长周期、运算量大的模型训练、数据分析等通过云计算进行集中处理分析。
2.2 不同层级煤炭工业互联网平台定位
工业互联网平台实施框架贯穿设备、边缘、企业和产业4个层级,通过实现工业数据采集、开展边缘智能分析、构建企业平台和打造产业平台,形成交互协同的多层次、体系化建设方案[6]。在煤炭行业,根据数据特点和矿井、集团、行业不同层级的业务目标,工业互联网平台的落地应该是多级分布式、混合云的架构模式,通过设备层、边缘节点、边缘云与中心云构成端-边-云一体化协同平台。设备层和边缘节点组成边缘系统,在矿井层和集团层构建企业级工业互联网平台,在全行业层构建煤炭行业级工业互联网平台。整体部署层级如图1所示。
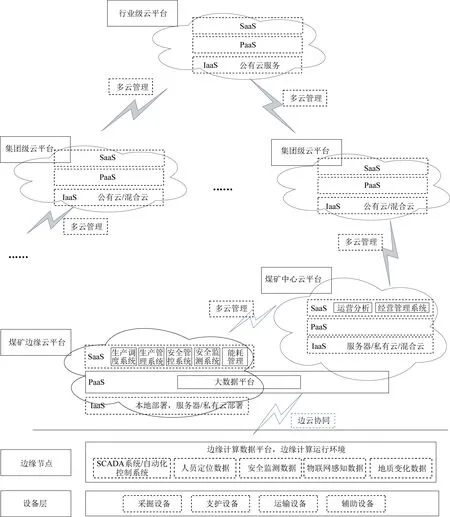
图1 煤矿工业互联网平台部署层级Fig.1 Hierarchical view of mine industrial internet platform
设备层包括矿井采掘运等各类生产运输设备,是在物物、物人信息集成中需要被感知的对象,通过部署大量传感器和摄像头等感知设备获得设备信息和生产过程信息。
边缘节点主要解决煤矿井下各种设备通信协议不一致的问题,提供煤矿井下设备、生产、环境、人员等数据的采集、实时接入,并负责协议解析和预处理。
矿井边缘云平台实现生产数据的汇聚,通过大数据平台进行数据整理加工、分析利用,支撑智能安全生产类应用系统。
矿井中心云平台进一步整合设计数据、运营数据、管理数据、服务数据等,实现生产数据与管理信息化系统数据的互联互通和深度共享,打通设计、生产、运营、管理等各个环节,实现全矿井的安全生产、高效管理。
集团级工业互联网平台汇聚来自不同矿井的数据资源,在更高层级进行数据互通,满足集团级综合运营、管理、指挥调度等业务需要。
煤炭行业级工业互联网平台的主要目的是构建产业工业互联网平台,打通产业上下游资源,促进生态体系建设。
可以看出矿井边缘云平台是整个煤炭工业互联网平台体系的桥梁,是OT和IT的融合点,通过边缘云平台可以实现综采工作面、掘进工作面等生产过程控制数据、环境、安全监测数据与已有ERP等运营、管理数据之间的打通,充分发挥煤矿企业级大数据平台数据综合分析挖掘能力,实现生产效率、经营管理能力的提升。从技术上,通过边缘云平台可把大量已有先进IT技术和平台软件应用于全矿井。
重点研究矿井级工业互联网平台,聚焦边缘云平台PaaS能力建设,通过大数据平台提供大数据存储计算、数据治理、数据建模、可视化分析等核心功能。
2.3 矿井工业互联网平台技术方案
面向矿井级的工业互联网平台,设计上分为井下边缘侧平台和地面边缘云平台两级平台。平台整体技术方案如图2所示。
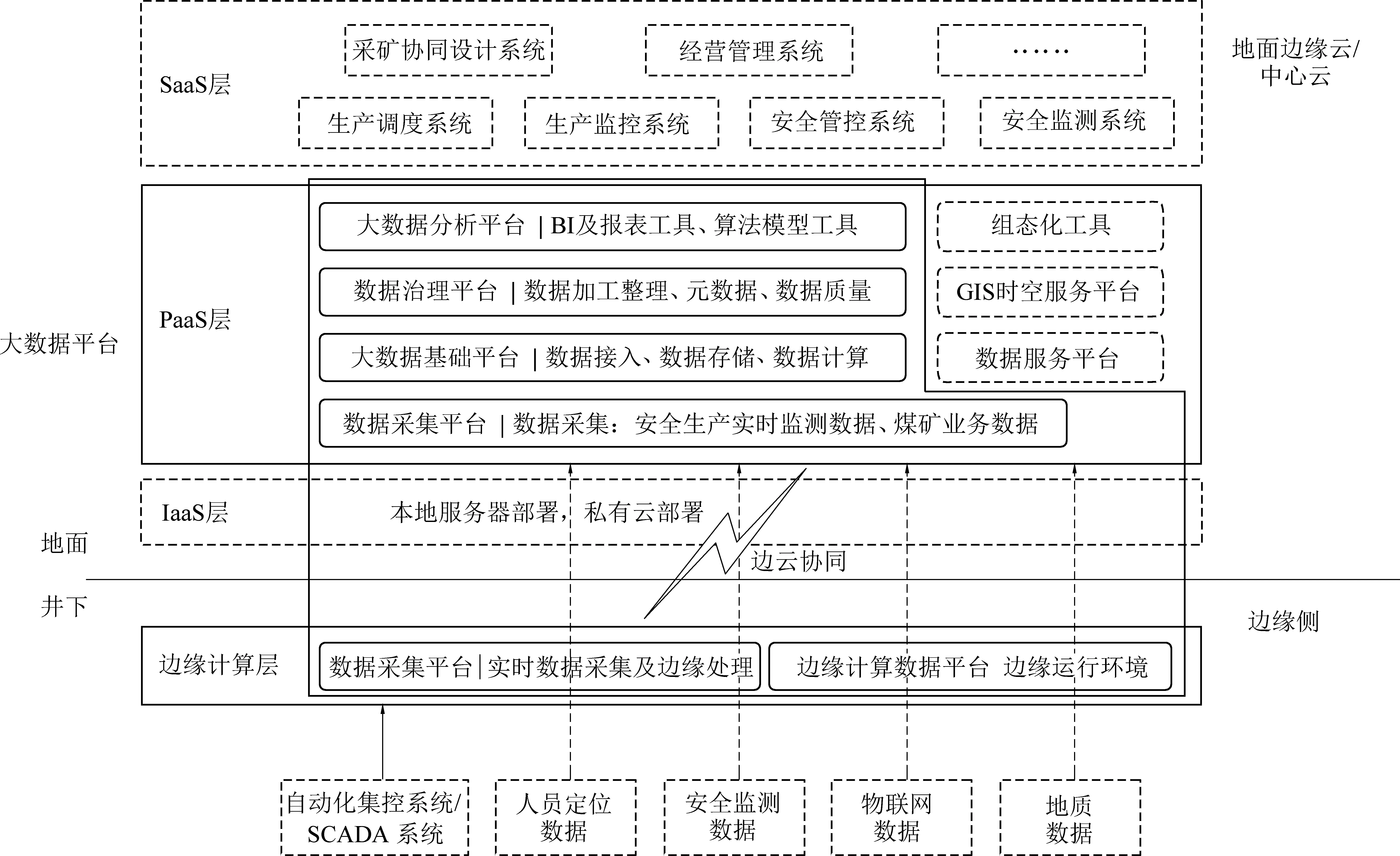
图2 矿井工业互联网平台技术方案Fig.2 Technical architecture of mine industrial internet platform
井下边缘侧平台由边缘侧数据采集平台和边缘计算环境两部分组成。数据采集平台负责接入来自综采工作面、掘进工作面等自动化控制系统的设备数据、生产过程数据、通过感知技术和物联网技术获取的安全监测数据、环境感知数据、视频监控数据、工程数字化信息如地质变化数据等全矿井实时数据,主要功能为设备接入、协议解析、边缘数据处理及缓存。边缘计算环境负责支撑数据和智能应用运行,完成推理决策等智能服务,用于矿井生产现场的实时控制反馈。边缘侧平台对采集到的数据进行必要的预处理后同时上传到边缘云平台,用于统一存储和分析利用。技术实现上,边缘侧主要以智能网关方式来实现,在合适的硬件资源和操作系统之上,通过软件方式实现各种工业总线协议的接入和转换,通过容器等技术提供数据和智能应用运行环境,选用开放式边缘计算框架如KubeEdge提供云边协同运行环境,进行大规模边缘设备的管理等。
地面边缘云平台在PaaS层构建大数据平台,支持全矿井生产、安全、环境、地质变化等相关异构数据接入汇聚和处理分析,是整个生产执行系统运行的核心支撑。同时负责进行模型算法的离线训练和迭代更新,并将更新后的模型算法反馈到边缘侧。边缘云平台的IaaS层根据实际应用场景可选择传统的服务器部署方式,或者采用虚拟化等技术提供计算、存储等资源的灵活调度。
边缘云平台向下与边缘侧平台构建边缘云端协同;而它本身已经是云平台,向上可以与矿井中心云平台构建多云/混合云协同框架,实现与煤矿经营管理系统、办公系统、企业管理等信息化系统之间的信息互联互通。从而进一步与煤炭行业工业互联网平台实现数据互联互通,促进产业协同。
3 矿井工业互联网大数据平台架构
3.1 大数据平台功能架构
大数据平台整体设计借鉴互联网领域及其他行业建设数据中台的理念,采用分布式存储和计算技术,从功能上提供“数据+智能”的平台和能力,实现全矿井多源异构数据的一体化访问、处理和管理。整体功能架构如图3所示。
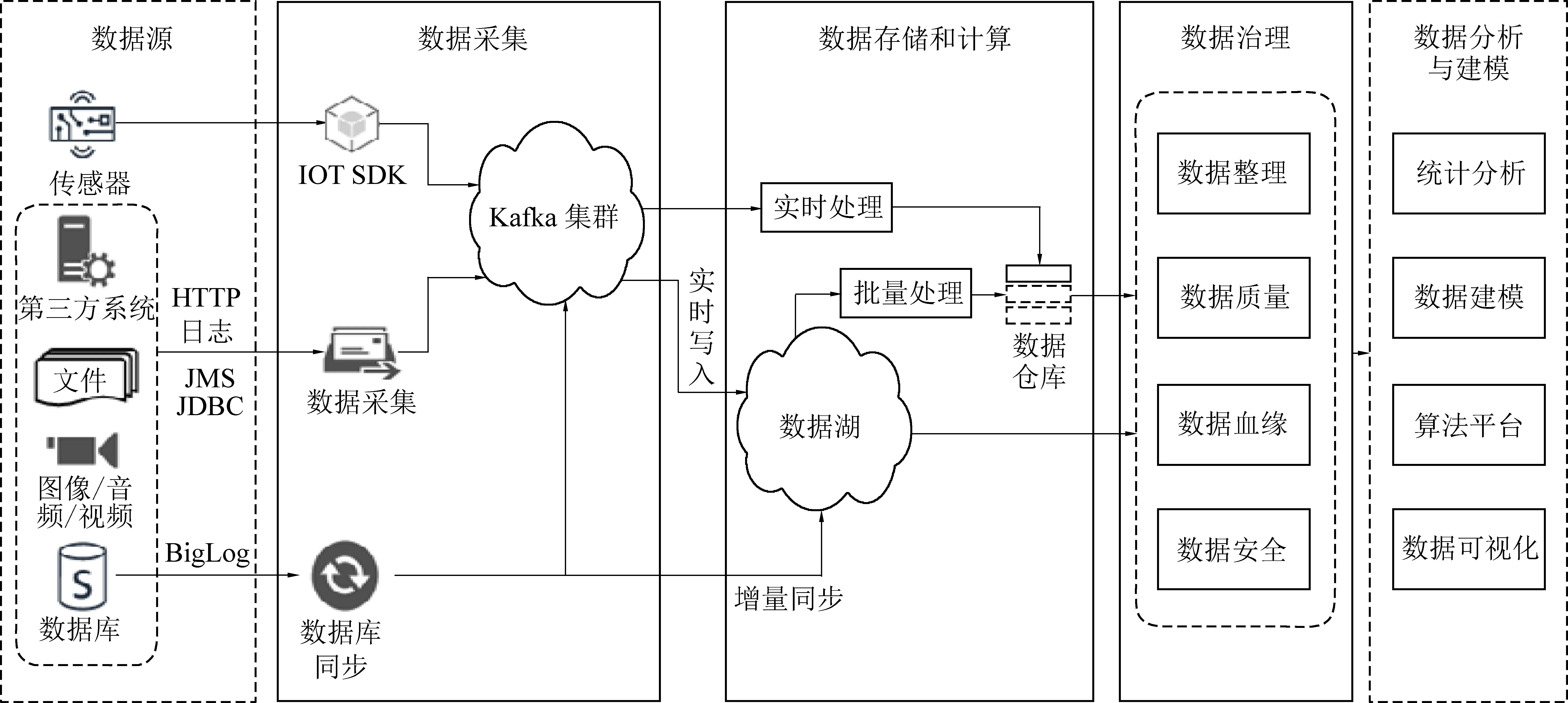
图3 矿井工业互联网大数据平台功能架构Fig.3 Functional architecture of mine industrial internet bigdata platform
数据采集平台从数据时效性上,提供来自传感设备、自动化控制系统的实时数据获取,同时提供井下和地面各种业务系统非实时数据的接入;从数据类型上提供结构化数据、半结构化数据和非结构化数据接入;数据接口上支持关系型数据库、NoSql数据库、文件系统、消息队列等多种接入方式。
数据存储和计算平台采用分布式存储和计算,融合数据湖和数据仓库技术,提供统一的海量数据存储和管理,并能够随着数据体量的增长,随需进行扩展。
数据治理平台负责数据整合和管理,通过系统化的方法体系和相应的工具,进行数据加工处理,解决数据准确性、质量、共享、安全等问题,逐步为企业形成大数据资产。
数据分析与建模提供数据查询统计分析、算法模型服务,从简单的统计汇总到利用人工智能技术进行建模,可逐步形成AI开发管理能力。
3.2 大数据平台技术架构
基于Hadoop的大数据技术在全球各大公司及技术爱好者的支持下,形成非常庞大也非常复杂的开源体系和生态。矿井工业互联网大数据平台在技术架构设计和组件选型上主要围绕煤炭业务需求,采用业界比较成熟稳定的开源技术框架,辅以必要的商用基础套件,兼顾技术的成熟度和前瞻性。整体技术架构和组件选型如图4所示。
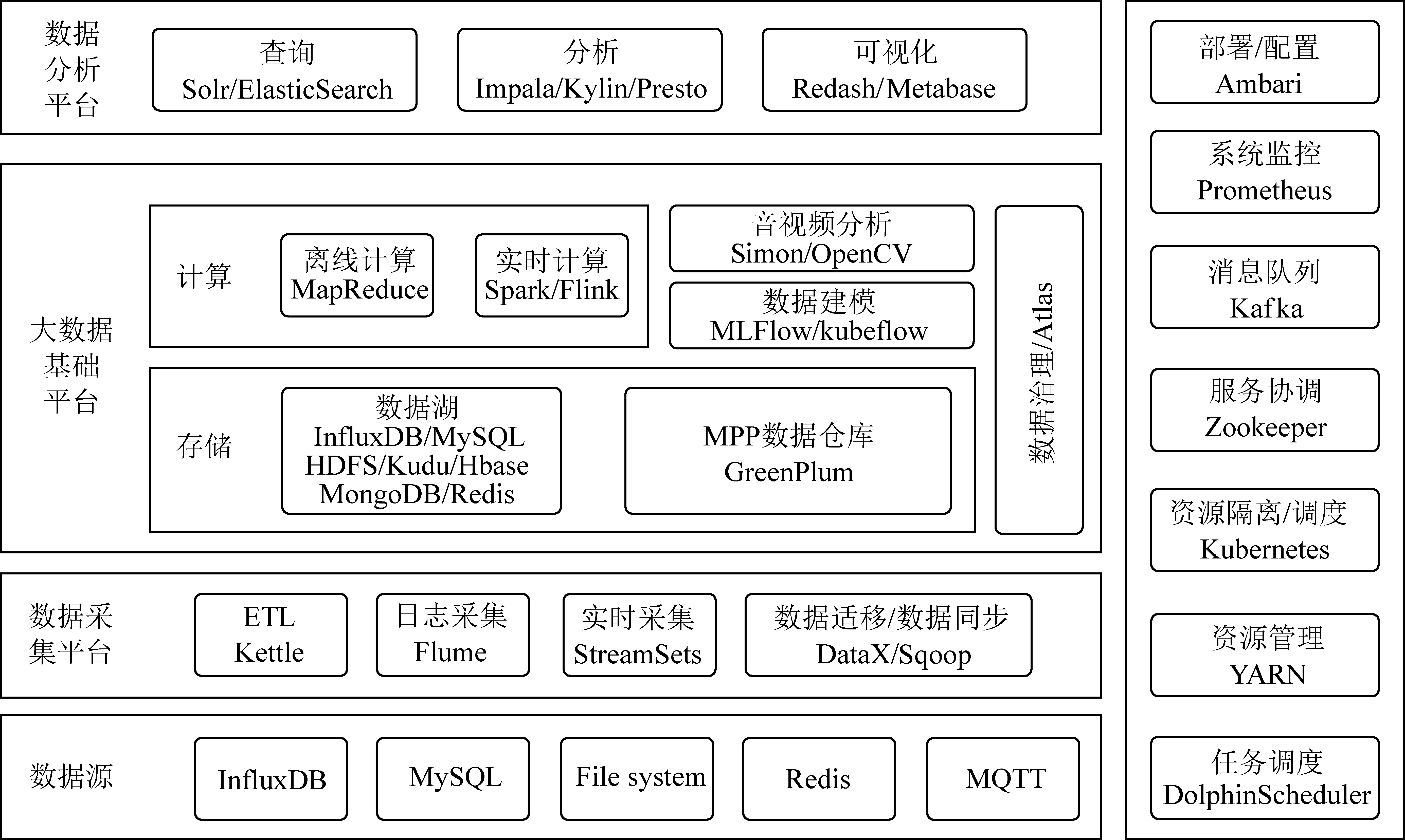
图4 矿井工业互联网大数据平台技术架构Fig.4 Technical architecture of mine industrial internet bigdata platform
采集平台需要覆盖到各种类型数据的接入方式,技术选型上主要从组件架构的合理性、易于二次开发、应用广泛等方面进行考量。日志和文件采集使用Flume,可以直接写HDFS并支持压缩、方便扩展。实时采集使用StreamSets,支持可视化开发,不用编写代码即可完成数据的采集和ETL。离线数据同步使用在性能和资源利用率方面具有优势的DataX或Sqoop。ETL使用简单实用的开源工具Kettle。
大数据基础平台的选型,存储方面考虑到煤炭大数据的类型包括表、图、音频、视频、日志等多种形式[18],在HDFS基础上采用Kudu或HBase满足低延迟、快速随机读写需求的场景,时序数据使用InfluxDB,其高性能和高压缩比适合工业环境传感器数据的存储,关系型数据使用简单并易于扩展的MySQL,文档型数据使用查询性能优异、操作方便的MongoDB,key-value型数据使用Redis,具有极高的性能并支持丰富的数据类型。MPP数据仓库选用GreenPlum,主要基于其强大的并行计算能力和海量数据管理能力,非常适合作为OLAP数据仓库。计算方面,离线计算使用核心的MapReduce,流计算使用业界最前沿且经过实践验证的Spark、Flink;语音识别使用较常用的开源项目Simon,视频分析使用性能良好、应用广泛的OpenCV。机器学习数据建模使用MLFlow、Kubeflow,MLFlow优势在于提供了端到端的机器学习生命周期管理,且与具体的机器学习库无关,Kubeflow特点在于原生支持Kubernetes。
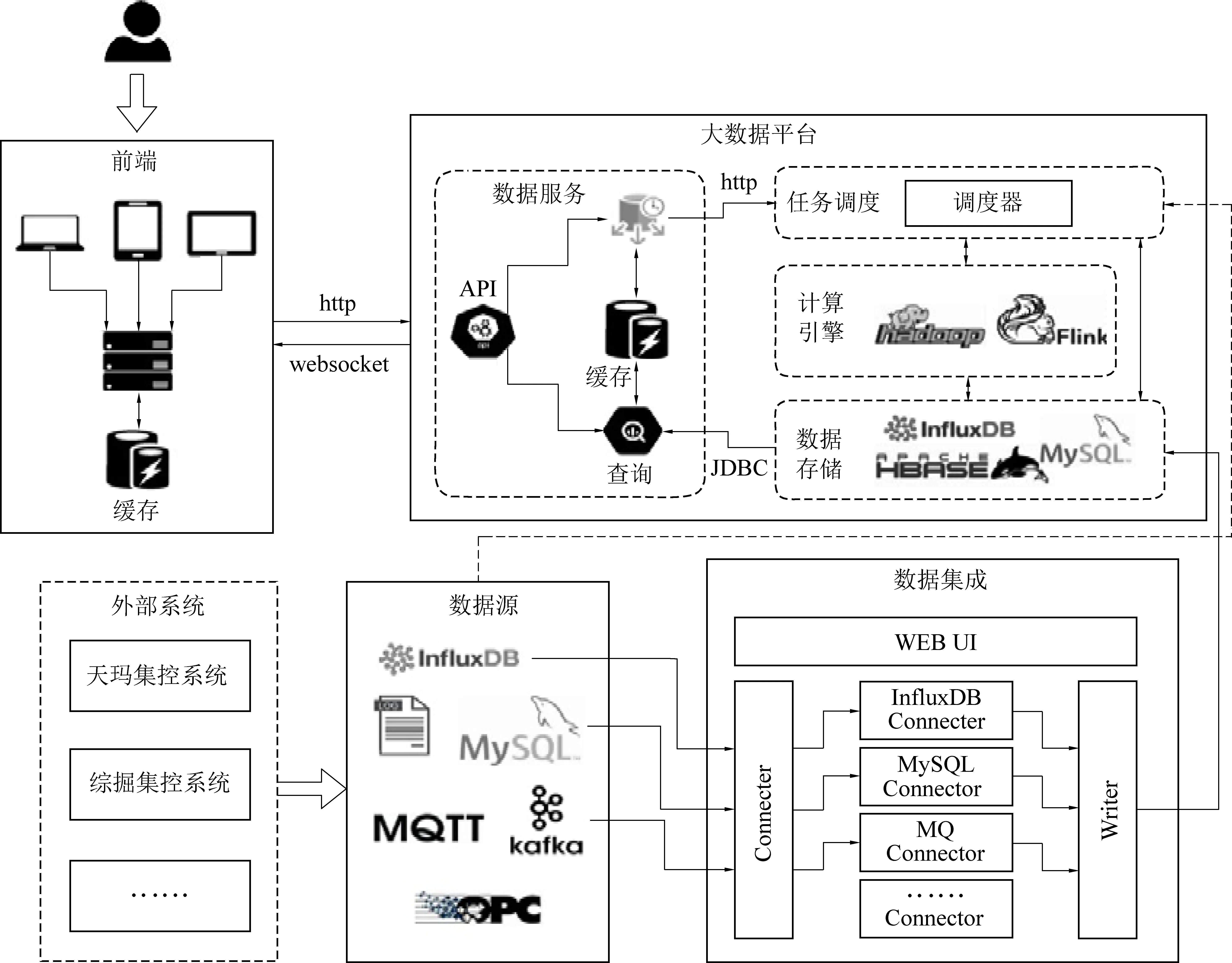
图5 大数据平台试验验证系统Fig.5 Experimental verification system of bigdata platform
数据治理以Atlas为基础,具有数据血缘、集中策略引擎、安全和生命周期管理等核心治理能力,可以基于此进行扩展,增加数据资产管理的相关功能。
数据分析平台的查询、分析、可视化根据不同场景选择不同技术方案。查询检索使用Solr或ElasticSearch,Elastic Search使用全文倒排引擎,检索速度快,分布式架构有很好的扩展性;数据分析可选择Impala、Kylin、Presto,其中Impala兼顾数据仓库、实时和批量等优点,适合海量数据实时查询分析;可视化展现使用Redash或Metabase,Redash简单易用,提供丰富的RESTful API接口,方便二次开发;Metabase界面漂亮友好,图表可视化选项丰富灵活。
其他无特殊需求采用Hadoop体系框架通用组件,如资源管理器YARN,分布式服务协调Zookeeper,资源隔离和调度Kubernetes等。
4 实验室技术验证
为了对大数据平台所选关键技术组件进行测试,搭建了如下实验室技术验证系统。
使用已部署至工作面的北京天玛智控科技股份有限公司的SAM综采工作面自动化系统(简称天玛公司SAM系统)中采集的数据为试验数据,对大数据存储、计算、查询能力进行试验。主要工作内容包括设计标准化接口从天玛公司SAM系统采集数据、进行数据集成、完成大数据平台入库存储、开发任务调度平台进行大数据任务编排和算法运行、通过数据服务接口供前端应用调用。
数据采集入库、查询性能测试结果如图6所示,平台选用的技术组件在数据入库性能、数据查询时间和并发数上均优于Hadoop传统的Hive组件,满足综采工作面写入和查询的场景需求。

图6 试验平台与原生Hadoop性能对比Fig.6 Performance comparison of experimental platform and original Hadoop
平台计算能力通过乳化液泵油温异常模式识别模型训练[20]进行测试,结果如图7所示。训练过程中原始数据为几万行,数据处理过程中需要对数据进行时间维度的“升采样”,数据量会扩大到几十万行,对于计算资源以及计算速度要求较高,可用于验证大数据平台计算支撑能力。从结果看,模型在训练及计算过程中达到了预期效果。
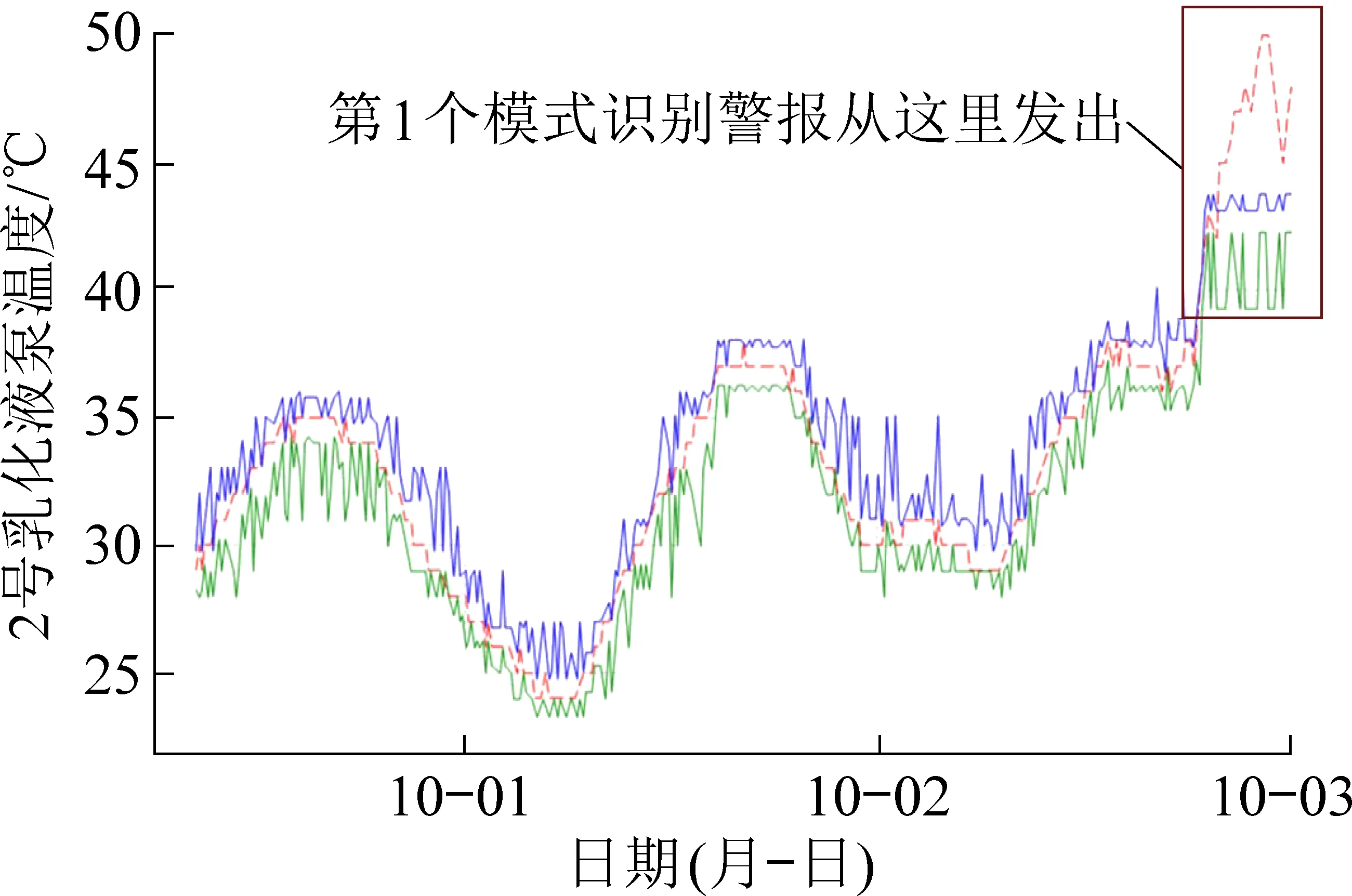
图7 算法模型训练验证Fig.7 Algorithm model training verification
5 结 论
1)从数据角度出发,用工业互联网体系框架设计了云边端一体化的煤矿矿井级工业互联网平台技术方案。
2)完成了矿井大数据平台架构设计和技术选型,提供数据的采集、治理、分析、挖掘,支撑矿井智能化安全高效生产。
3)以综采工作面自动化系统数据作为试验数据进行技术验证,整体方案可行,关键技术组件性能得到了验证。
从工业互联网平台特别是边缘云计算的架构、技术、应用场景来看,各行业都有适合自身的定制化方案,没有统一标准。虽然针对矿井生产自动化实际应用场景从总体框架、功能架构、技术架构给出解决方案,但仅仅是起步探索,还没有达到解决实际现场应用复杂场景的要求。特别是部署架构,需要结合现场网络条件、矿井已有信息化条件等在部署实施时进行进一步研究并寻找可落地方案。
