利用开源大数据的社会工作实时评估方法
2022-08-06欧文孝王寅森殷风景
张 鑫,欧文孝,王寅森,潘 岩,殷风景
(国防科技大学 系统工程学院, 湖南 长沙 410073)
当前,很多社会工作的评估评价还相对薄弱。以拥军优属工作为例,其评价主要存在三方面问题:一是尚无独立的针对性评估体系。已有的考评标准,如《全国双拥模范城(县)考评标准》(下文简称“考评标准”),同时涵盖(政府和群众)拥军优属和(军队)拥政爱民两方面,其中很多指标二者兼顾,难以剥离,只能算是“相关”评估,针对性不够强。二是现有相关评估的间隔长、成本高。一般两年或四年才开展一次,无法随时评、时时评,不利于依据评估或抽检结果及时改进工作,也容易引发“重评时、轻平时”的问题。而且,参评城市需要按标准整理提报材料,评审方还需要组织专班审核材料、打分评比以及开展平时抽检,双方都需要消耗大量人力物力,工作成本较高。三是相关评估的部分评价指标有待优化,具体表现在:①有些指标只考察有无,未衡量多寡,区分度不够,容易导致“干多干少一个样”;②很多指标需依据政府部门掌握的内部资料,导致详细评分不便公开,不利于显示评估结果的公信力;③部分指标比较综合,涵盖教育、文化、法律、医疗、住房等多领域,不便参评城市之间细化比较,各自发现优势和弱势领域,以便下步针对性地固强补弱。
在现今互联网时代,社会工作相关的通知公告、新闻报道、体验评价等大多能见诸网上,既给相关群体获取信息带来便利,也给利用开源大数据评估这些工作的推进力度提供了可能。鉴于此,研究人员从2014年左右开始尝试利用大数据完成不同评估任务,包括:风险评估[1-5]、信用评价[6-8]、传播或宣传效果评估[9-11]、政策评估[12-15]、保健水平评估[16]等。通常,评估对象不同,构建的指标体系就不同,所需的数据也不同。比如,评估消费者个人信用指数时,Jiang等[6]使用了消费者在信息咨询平台上的问询记录、跨平台失信信息、线上购物信息等;评估公共政策时,则可使用政策文件数据、互联网文本数据(包括新闻、社交帖文)、电子商务数据等[15]。但是,与传统利用领域(小)数据进行评估不同,大数据中噪声多、价值密度低,如何快速获取相关数据,并从中提取真正有用信息,是基于大数据的评估方法所面临的共同挑战,高效的数据采集获取和分析挖掘必不可少。值得一提的是,受困于这一挑战,有相当一部分现有研究(如[8-9, 13-15])还处于理论分析和方法构想层面,尚未实际获取大数据、针对所关注评估对象具体开展评估实证。另外,尽管现有研究已经探索了利用大数据来评估很多不同任务对象,但还未发现利用它们来评估拥军优属等社会工作的相关成果被公开报道。
为此,本文以拥军优属作为案例,提出一种利用开源大数据的社会工作实时评估方法,建立综合网络信息特点与指标可测性(即能否利用开源数据测量计算)的分层指标评估体系;设计开发了原型软件,针对给定的参评对象,通过持续爬取其网上信息,以增量方式实现指标得分与综合评分的快速计算。
1 评估模型构建与计算
定量评估是指依据统计数据,建立数学模型,并用模型计算评估对象各项指标得分来实现评估分析的方法。其中,“数学模型”即定量评估模型,其构建往往需要:首先确定左右评价的影响因素,其次建立指标体系(包括确立指标、定义指标测算方法、明确指标间的关系和权重等),最后定义相应的综合评分方法或公式。其中,指标筛选可用定性方法(如德尔菲法[17]),也可用定量方法(如主成分分析[18]或其改进方法[19]);指标测算方法和指标关系分析因任务而异,通常需要人工参与;指标赋权则可使用启发式方法(如层次分析法或其改进[20])或机器学习方法(如逻辑回归、支撑向量回归或其他神经网络[21]),前者往往离不开人工参与,而后者则需要训练样本,即事先获取的、通常由人工标注的评估样本(这些样本既有指标得分,又有综合评估结果)。此外,虽然机器学习中有增量学习[22-23](incremental learning)的相关研究,但主要关注如何针对新增样本,或类别、属性快速更新模型参数,而聚焦于新的数据不断获取之后,如何以增量方式快速计算指标得分与总评分的研究成果还比较少见。
以现实生活中的拥军优属工作评估为例,从现有相关考评标准中遴选拥军优属相关指标作为基础,针对网上开源信息的特点,重点从指标可测性和区分性两方面对它们加以调整,借此构建基于开源大数据的拥军优属工作评估指标体系。
1.1 评估指标筛选与体系构建
最新版考评标准一共设置了10大考评项目(共78个评分项),分别是:①组织领导坚强有力;②宣传教育广泛深入;③拥军工作扎实有效;④拥政爱民成果显著;⑤政策法规落到实处;⑥双拥活动坚持经常;⑦军民共建富有成效;⑧军政军民关系融洽;⑨群众满意度测评;⑩加分项目。其中,与拥军优属相关的评分项主要分布在①、②、③、⑤、⑥、⑨考评项目中,可归为四大方面:组织领导、宣传教育、政策制定与落实、相关活动开展。下面围绕它们来讨论本文评估指标体系建立。
考评标准中“组织领导”方面的评分项主要考察双拥办等机构设置情况和相关经费是否列入预算。对此,通过互联网检索结果可发现,几乎所有省(自治区)辖市州和(直辖)市辖区都设置了相关机构,并定期召开党委议军、双拥促进等会议;且从所公开的预算信息中也都能找到双拥和优抚专项预算。所以,考虑到区分性,本文不设立“组织领导”方面的拥军优属评估指标。
“宣传教育”相关评分项主要考察各地线上、线下宣传开展情况。网络时代,互联网已成为舆论宣传主阵地,无论从形式多样性、内容生动性、受众覆盖面,还是从成本控制、节能环保等角度,线上宣传都具有线下不可比拟的优势。因此,本文主要通过爬取各地相关单位的互联网信息,评估其宣传教育开展情况。
“政策制定与落实”方面,考虑到政府部门会在网上颁布相关政策制度,且一经公布通常都会得到较好执行。拥军优属政策往往涉及就业、教育、住房等不同领域,政策覆盖的领域越全,说明当地对优抚群体的照顾越周到,单个领域的政策越多,则往往反映当地在该领域的优抚力度越大。因此,本文从网上采集各地相关政府部门颁布的政策规范类文件,并通过考察它们的领域覆盖面和各领域的政策数量来评估当地拥军优属政策制定与落实情况。
“相关活动开展”与“宣传教育”类似,各地通常都通过互联网发布新闻动态,其中常包含拥军优属活动(如悬挂光荣牌、走访慰问、组织定向招聘等)开展情况。鉴于此,通过抓取各地相关单位的网上新闻,然后进行事件分析和计量以评估当地相关活动开展情况。
基于以上分析,本文围绕宣传教育、政策制定与落实、相关活动开展三方面,构建如图1所示的评估指标体系。其中,鉴于宣传教育和活动开展情况主要通过相关单位的网上新闻动态发布,所以将二者合并,设立一级指标“新闻动态”,其下不设立二级指标(或者说二级指标是它自身)。政策制定与落实方面,鉴于教育、医疗、住房、就业堪称最重要的民生领域,所以划分5个预定义领域,即上述4个和“其他”,后者涵盖不能划归前4个领域的所有政策文件。相应地,设置1个一级指标(“政策制度”)和5个二级指标(即“教育”“医疗”“住房”“就业”“其他”)。此外,通过与军人军属访谈了解到,各种优先优惠措施(包括车站、机场、医院等公共场所的优先通道设置,酒店、餐饮等民间优惠,以及景区的票价减免等),往往直接左右他们对一个地方拥军优属力度的观感评价。而且,这些优惠措施也是一种落实于行动的、广大民众更常接触的社会性拥军优属宣传教育。考虑到其重要性,本文单独设立1个一级指标“优先优惠”,包含“优先通道”“民间优惠”“景区优免”3个二级指标。
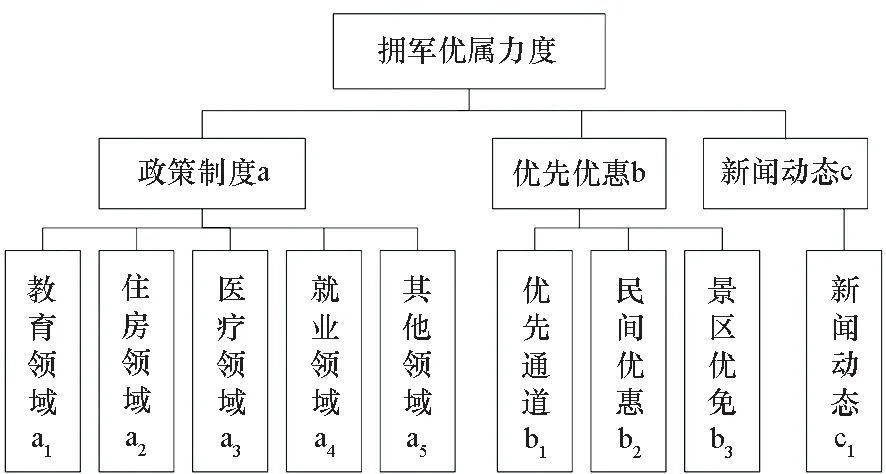
图1 模型评价指标树Fig.1 Hierarchy of the evaluation indices
1.2 指标赋权
由于上述指标体系中各类二级指标数量不多且相互关联性不明显,所以采用层次分析法(analytic hierarchy process, AHP)进行指标赋权。鉴于考评标准中考评大项和评分项(见1.1节)的赋分体现了双拥领域权威专家对这些项目重要性的集体评判,本文以它们作为确定指标权重的重要参考,考虑如下三方面:①政策制度是政府颁布的拥军优属法律文件,最能直接反映其拥军优属工作情况,也最具权威性,所以该一级指标权重最高。本文认为教育、住房、医疗、就业和其他这5个民生领域对于军人军属而言同等重要,所以设置相应各二级指标重要性相同。②优先优惠体现了企事业单位拥军优属落实情况和响应力度,往往让军人军属直接有感,不过拥军优属工作并不仅限于民间优先优惠,因此该一级指标应有较大权重,但应略低于政策制度。此外,一个地区的旅游景点数量受地理位置、资源环境等非人力因素限制,为降低其对评估结果公平性的可能影响,设定二级指标中景区优惠的重要性要略低于其他两个指标。③新闻报道活跃度既可反映当地政府对拥军工作的重视程度、宣传力度,也可反映其拥军工作落实情况。但上新闻的往往是当地一些相对重要的工作,而细微工作,包括很多基层活动(如某军供站为退休干部发放防疫物资)时常并未涵盖其中,因此,“新闻动态”的权重应比前两个一级指标更低。
基于上述分析,本文分别构建了一级指标和“优先优惠”下属的二级指标判断矩阵(判断矩阵中的数值表示行列对应指标的相对重要性关系)[4],计算各指标权重并分别进行一致性检验,结果分别如表1和表2所示。

表1 一级指标判断矩阵Tab.1 Comparison matrix of the 1st level criteria
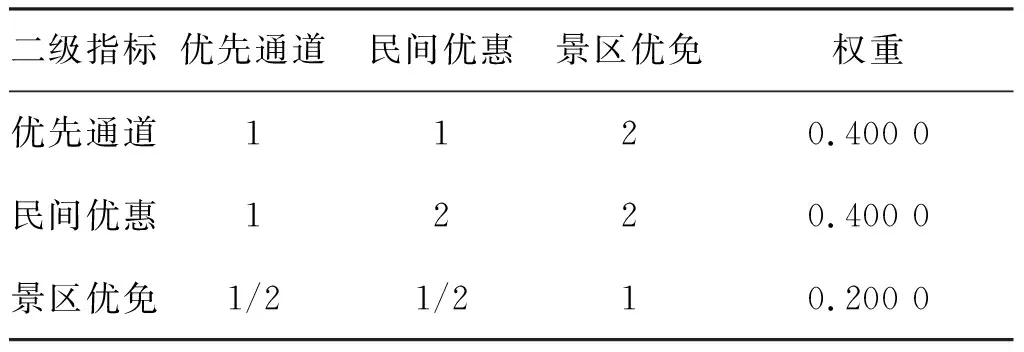
表2 二级指标判断矩阵Tab.2 Comparison matrix of the 2nd level criteria
经计算表1~2中两个判断矩阵的一致性比例(consistency ratio, CR)值分别为0.007 939和0,均小于0.1,一致性检验通过。进一步将两层评价指标判断矩阵计算的权重结果相乘,可算出所有二级指标的全局权重[4],如表3所示。
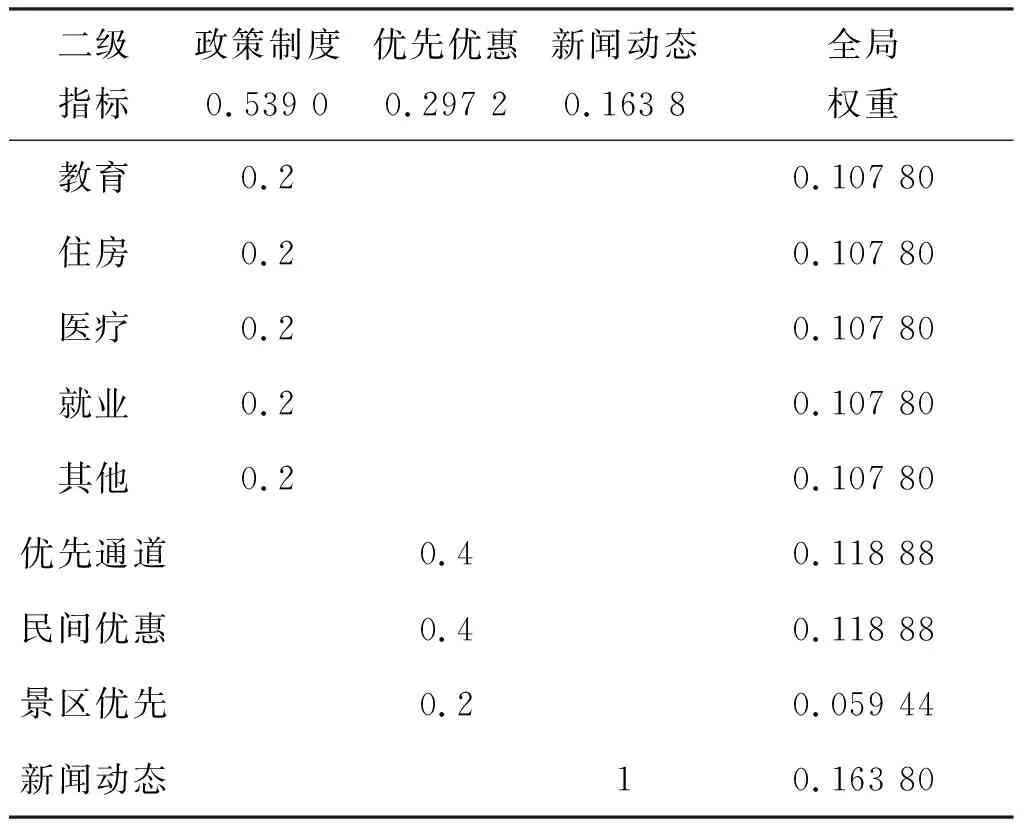
表3 二级指标全局权重计算表Tab.3 Weights of the second level evaluation indices
1.3 指标评分方法
考评时间点t和考评周期H不同,参评城市l的评估得分往往也不同。因此,如果对照图1中的顺序,将9个二级指标的原始得分分别记作N1,…,N9,则它们都应是t、H和l的函数。
1.3.1 政策制度类指标
指标得分N1~N5的测算公式定义为:
Ni(l,t,H)=PF(l,t,H,i),i=1,…,5
(1)
其中,PF(l,t,H,i)表示城市l在相应时段内颁布的属于第i个民生领域的拥军优属政策数量。这些政策制度通常发布在政府部门网站的“通知公告”和“规范性文件”栏目中,可分为两大类:一类是长期政策,在新版本出来前长期有效,且新版本通常是对旧版的部分修订而非颠覆性改变;另一类是短期政策,一般只在明确规定的时段内有效。通过数据观测发现,短期政策的显著特点是其标题中包含“年度”或“年”,且前面有数字或“本”字。据此,本文开发网页爬虫,从城市l的政府机构网站的“通知公告”和“规范性文件”栏目持续采集相关政策文件,去重后借助文本分类算法将每个文件划分到5个预定义领域中。同时,通过在标题中检测关键词组合“数字/‘本’ + ‘年/年度’”来判别文件是否为短期政策,其中单引号引起的是关键词。若为短期政策,则进一步提取其网页发布时间作为发布时间,并统计发布时间在从t开始倒推的H时间内属于第i个民生领域的短期政策数量。对于长期政策(即未被判定为短期政策的那些),则取最早版本时间作为发布时间,并统计截至时间t范围内属于第i个民生领域的所有政策数量,理由是:长期政策在理论上到任意时间t都有效,且同一政策的新旧版本已被去重。最后,两部分求和可得到PF(l,t,H,i),即
PF(l,t,H,i)=PFperm(l,t,i)+PFtemp(l,t,H,i)
(2)
其中,PFperm(l,t,i)是长期政策数量(i=1,…,5),与参数H无关;PFtemp(l,t,H,i)是短期政策数量,与H相关。实验中发现,短期政策多见于就业、住房和教育三个领域。
1.3.2 优先优惠类指标
由于优先优惠一经设立,就鲜有取消的情况(除非相应的公共设施关停),所以测算这3个指标得分时,不需要考虑时间段H,也即N6~N8分别对应于指定城市l到t时刻截止,其优先通道、民间优惠、景区优免的设置或实施情况。其中,优先通道和景区优免指标评分的思路是,辖区内公共场所或景区中设置优先通道或票价减免的占比越高,得分应越高,形式化定义为:
Ni(l,t,H)=Ni(l,t)=Pi(l,t)/Qi(l,t)
(3)
式中,i=6,8,第一个“=”是为了强调指标评分与参数H无关,右侧分式中分母Q6(l,t)表示城市l辖区内截至t的公共场所总数、Q8(l,t)表示景区总数,而分子P6(l,t)或P8(l,t)则分别表示设置了优先通道的公共场所数或有票价减免的景区数。为计算N6,本文一方面采集微信小程序“军人优先查询助手”上的优先信息,以城市l的名称作为关键词筛选其中相关部分,计算P6(l,t);另一方面以“l+ 机场/高铁站/地铁站/车站/医院”作为关键词检索百度,对检索结果去重后计量得到Q6(l,t)。对于景区优惠评分N8,本文从旅游网站“途牛旅游网”(http://www.tuniu.com)上检索和爬取城市l辖区内的景点信息,统计Q8(l,t),并通过匹配关键词“军人/军属/军官/士兵”筛选和统计其中有票价减免的景区数量P8(l,t)。
民间优惠评分N7略有不同:一方面很难找到相对统一的获取各地酒店饭店总量的途径;另一方面很多城市,特别是大城市的酒店饭店数量众多,且不时有新开和关闭的,总量波动很大。考虑到饭店酒店数量与当地人口数量(包括固定与流动人口)有较强相关性,本文定义如下公式测算民间优惠力度:
N7(l,t,H)=N7(l,t)=P7(l,t)/M(l,t)
(4)
同样地,N7与时段参数H无关。式中,分子表示城市l截至时间t范围内设有军人军属优惠的饭店酒店总量,本文通过从微信小程序“军人优先查询助手”中采集相关信息并匹配城市l后统计获得;而分母M(l,t)表示同期城市l的人口总量,该数据通过网络来源获取。
1.3.3 新闻动态类指标
由于新闻文章及所报道的言行活动具有很强的时效性,所以N9同时依赖于t、H和l。此外,在我国,现代化程度越高、网媒越发达的城市,通常人口总量也越大。而一些三四线城市,虽然其拥军优属工作干得不少,但可能因为网媒发达程度不及,导致网上新闻动态不多、宣传力度不够。为降低网媒发展不平衡可能给本指标测算带来的不利影响,本文定义N9的测算方法为城市l在从t开始倒推的H时间内的新闻动态总量再除以其相应时间的人口总量,即:
N9(l,t,H)=R(l,t,H)/M(l,t)
(5)
其中,R(l,t,H)表示相应时段的新闻事件计量,M(l,t)的含义和计算方法与式(4)相同。本文采用如下步骤测算R(l,t,H):①采集城市l及其下辖区县的政府和退役军人事务管理机构网站上“政务动态”或“工作动态”栏目下的文章;②利用“部队/驻军/官兵/拥军/军属/烈士/双拥”等关键词筛选其中与拥军优属有关部分;③对所选文本去重;④通过无监督聚类从去重后的文本中发现事件或者说话题(event/topic),并以每个事件聚簇中最早的文章发布时间作为事发时间;⑤统计在从t开始倒推的H时间内发生的事件数量,即R(l,t,H)。
1.4 模型实时计算
式(1)~(5)定义了各二级指标的原始分测算方法,显然它们的取值范围很不一样。为避免量级不同而影响各自在全局评分中的占比,需要对原始分进行归一化,折算为标准分。思路是,对每个Ni(l,t,H),取参评城市中的最高分和最低分,并按如下方式折算为百分制下的标准分,即:
(6)
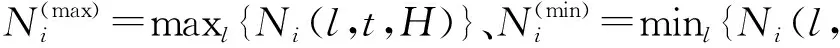
(7)
但是,直接按上述流程进行计算会导致参数t或H稍有变化,就需要从网上信息采集开始重来一遍,将非常耗时。 而事实上,改变这两个参数又非常必要。 因此,本文持续爬取各类网上数据,并定期(如每天或每月)计算和保存式(1)~(5)中PF、P、Q、R等统计量,然后利用这些定期统计结果,实现任意时间点和考评周期内评估分数的快速计算。 记固定统计间隔为T,设H=KT,则对于任意t和H,根据式(2)可得:
PF(l,t,H,i)=PFperm(l,t,i)+PFtemp(l,t,H,i)
kT,T,i),i=1,…,5
(8)
式中,PFperm(l,t,i)表示城市l截至时间t范围内颁布的属于第i个民生领域的长期政策的数量,PFtemp(l,t-kT,T,i)表示每个统计间隔内短期政策的数量。由于长期政策一直有效,所以其计算方法相对特别:
(9)
其中,i=1,…,5,PFperm(l,t-kT,T,i)是从t开始倒推的第k个统计间隔内发布的属于第i个民生领域的长期政策数量;求和上界为正无穷,表示从城市l可获得的长期政策文件中发布时间最早的开始统计(显然不早于新中国成立的1949年)。还需注意的是,若一个长期政策有多个版本,则只有最早版本应计入相应统计间隔的PFperm(l,t-kT,T,i)中,余下版本不再重复计入。这样,只要计算并缓存每个固定统计间隔T中的长、短期政策数量,即可通过查表后求和快速计算任意t和H下的指标得分。
余下4个指标(原始分)的快速计算方法与此类似,不再赘述。但要注意,优先优惠下的3个二级指标的计量方法应参照上面长期政策数量的计算过程,而新闻动态的计量方法则应参照短期政策数量的计算过程。
最后简析一下计算复杂度。实验中发现,能够获取的最早数据的发布时间为1999年,所以式(9)中的求和上界实际与考评周期内包含的统计间隔数K数量级相近。因此,设有m个城市参评,则按上述快速方法对它们进行综合评估的计算复杂度仅为O(Km)。K和m的取值通常均在万以下,对于现代计算机而言,很容易做到实时计算,即用户提出评估需求后,在秒以内返回所有参评城市的评估结果。
2 算例与分析
为验证上述模型方法的可行性与有效性,接下来首先选择若干城市作为评估对象,接着针对性设计和开发原型系统,实现所需数据的持续采集、处理与分析,然后利用这些数据实施评估,并对结果进行分析和讨论。
2.1 评估对象选取与原型实现
本文选取H省所辖14个市州作为评估对象,主要考虑两方面:一是同一省份的市州之间通常具有较好的可比性,二是课题组及周边对H省熟悉的人相对较多,有利于判断模型评估结果的合理性。接下来将以这些市州的首字母指代它们,当首字母相同时,则在后面加上数字加以区分。这样,H省14个市州分别为C1、Z1、X1、H1、S、Y1、C2、Z2、Y2、C3、Y3、H2、L市和X2州。
原型软件的模块构成及工作原理如图2所示(其中粗箭头线表示控制流、单线箭头表示数据流),除“评估计算”外各模块的技术途径见表4。其中,数据“预处理”包括两个子模块,“过滤”主要:①对政策文件,通过在标题中检测“转发”“‘转’+组织名+‘通知/文件’”等关键词组合,滤除非本级文件;②对新闻文章,利用“部队/驻军/官兵/拥军/军属/烈士/双拥”等关键词,筛选并保留与拥军优属有关的那些。“去重”旨在去除从多个不同来源采集的相同文章,本文以SimHash作为文本表示,通过在线Single-Pass无监督聚类实现去重[24]。“文本分析”模块:①基于关键词匹配实现短期政策文件识别,见1.3.1小节;②基于TextCNN模型[25]、通过有监督文本分类实现政策制度的领域划分;③通过构建H省的扩展地名词典(在其中纳入每个市州的名称、简称和别名)并利用它识别采自“军人优先查询助手”小程序和“途牛旅游网”优先优惠信息的城市归属;④以标题和正文中词条的word2vec预训练词向量[26]的加权平均作为文本表示,采用在线Single-Pass算法实现新闻动态中的事件发现[27]。需要强调的是,图2中“数据采集”“预处理”“文本分析”等3个模块,以及“评估计算”中的“定期计量”子模块,以定时运行方式(如每12小时一次),不断采集参评市州的最新数据,经预处理和文本分析后,定期(根据式(8)中参数T的设定,每天或每月一次)统计计算各二级指标的原始分。当需要评估时,再驱动“评估计算”中的“综合评分”子模块计算所有参评城市在指定时间点和考评周期上的评估得分。

图2 原型工作流程示意Fig.2 Workflow of the prototype
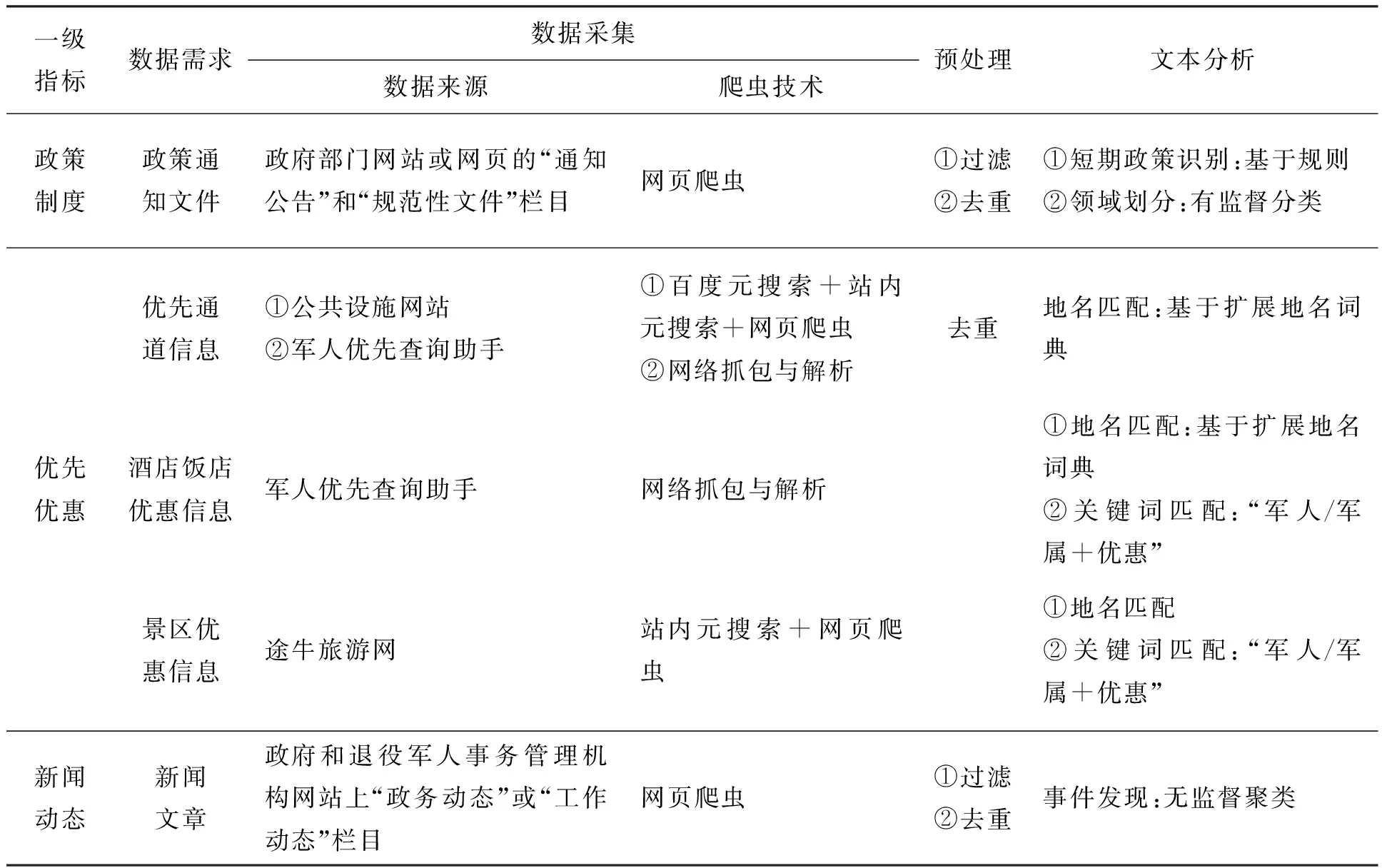
表4 原型模块技术途径一览表Tab.4 Techniques used by the components in the prototype
原型自2020年6月开发完成后即联网部署运行,截至本文完成时,共采集到H省相关信息97.23万条,这些信息中发布时间最早的为1999年11月17日,经过滤和去重后得到7 262条,远少于原始数据,这种量级差异正好符合大数据价值密度低的特点。
2.2 评估结果及分析
2.2.1 不同考评周期的评估结果
表5给出了H省14个市州以2020年12月作为考评时间点,考评周期分别为2年和4年的考评结果。下面从两个不同角度分析评判表5中结果的合理性:
首先是人的主观评判。本文从对H省拥军优属情况相对熟悉的身边人员(至少体验过或了解H省部分市州优抚待遇的才作为备选)中随机找出7名受访者,对表5中的两个评估结果“总体是否合理?”和“前6名是否合理?”进行无记名投票,候选答案设置“合理”“基本合理”“不合理”“不知道”四个选项,并要求四选一。投票结果为,3人认为评估结果总体上“合理”、4人认为“基本合理”;5人认为前6名“合理”、2人认为“基本合理”。由此反映,模型评估结果能够较好符合人的主观判断。
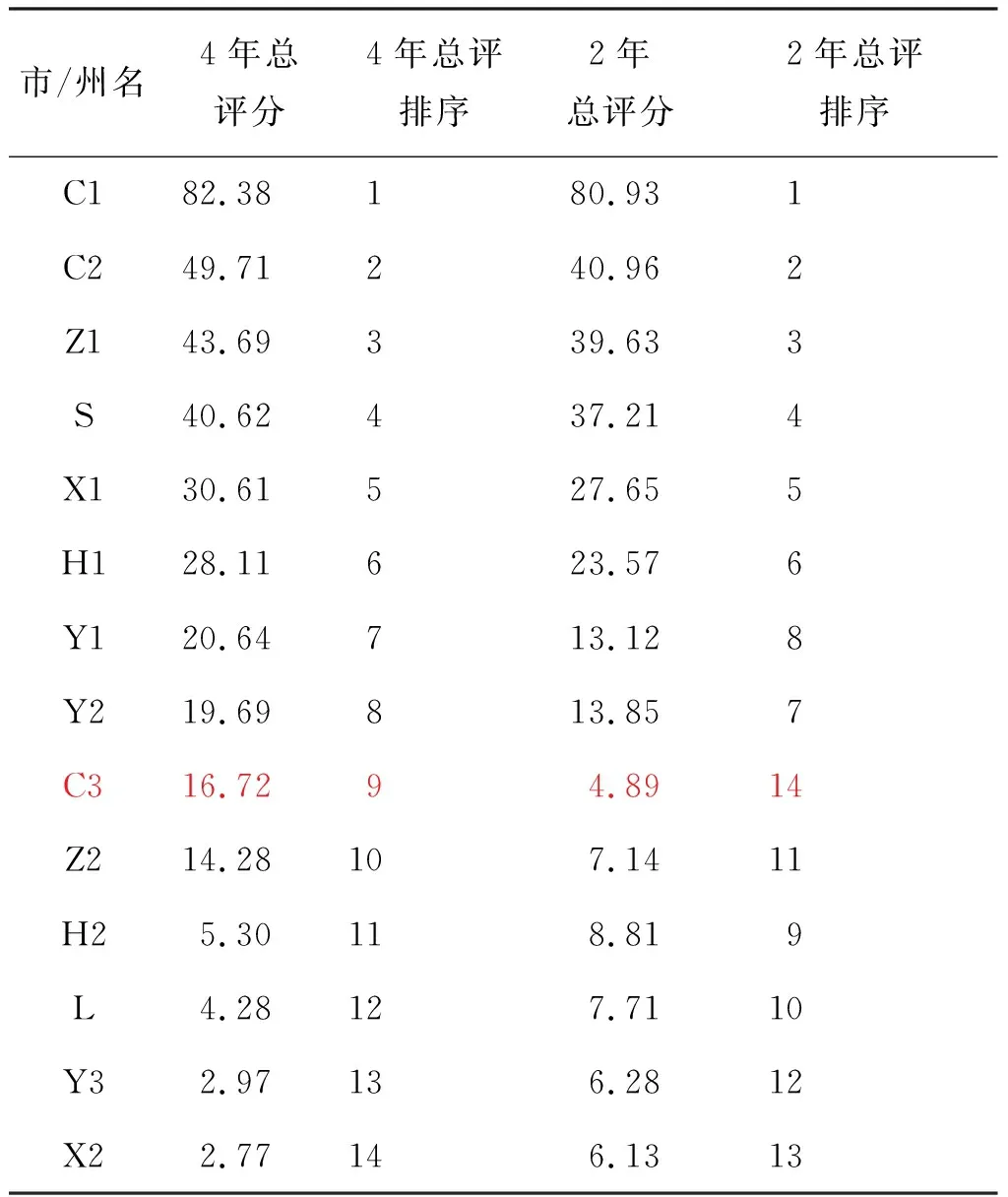
表5 H省各市州截至2020年12月的总评分Tab.5 Evaluation results of the cities in H province up to November, 2020
其次是与相关评比的对照。2020年10月公布了H省全国双拥模范城评比结果。该结果系2020年评估的过去4年H省各参评城市的双拥工作情况。共8个城市入选,排序为C1、C2、H2、X1、S、Z1、H1、L,它们可被视为过去4年H省双拥工作的前8名。与之对应的是表5第2、第3列给出的模型评估结果,其中8个全国双拥模范城的模型评估排序分别是1、2、11、5、4、3、6、12(见表5第3列)。对比可见,二者之间具有较好的一致性:模型评出的前6名均入选,且前两名顺序完全一致。但二者也有明显差异,特别是,模型排名11和12的H2、L两市,却进入了全国双拥模范城行列。经调研分析认为,导致这种差异的主要原因可能是:模型所评的是“拥军优属”,只是“双拥”的一个方面,以H2为例,该地区驻军部队数量众多,不排除其在“拥政爱民”方面有明显比较优势,而使其双拥排名跻身前列。
由表5中结果还可看到,考评周期不同时,相同城市的总评排序可能变得不同。比如表5中标红的C3市,4年总评排序第9,而近2年总评排序为14,表明相对于本省其他市州,该市近两年的拥军优属工作进步速度偏慢。
2.2.2 不同时间点上的评估结果
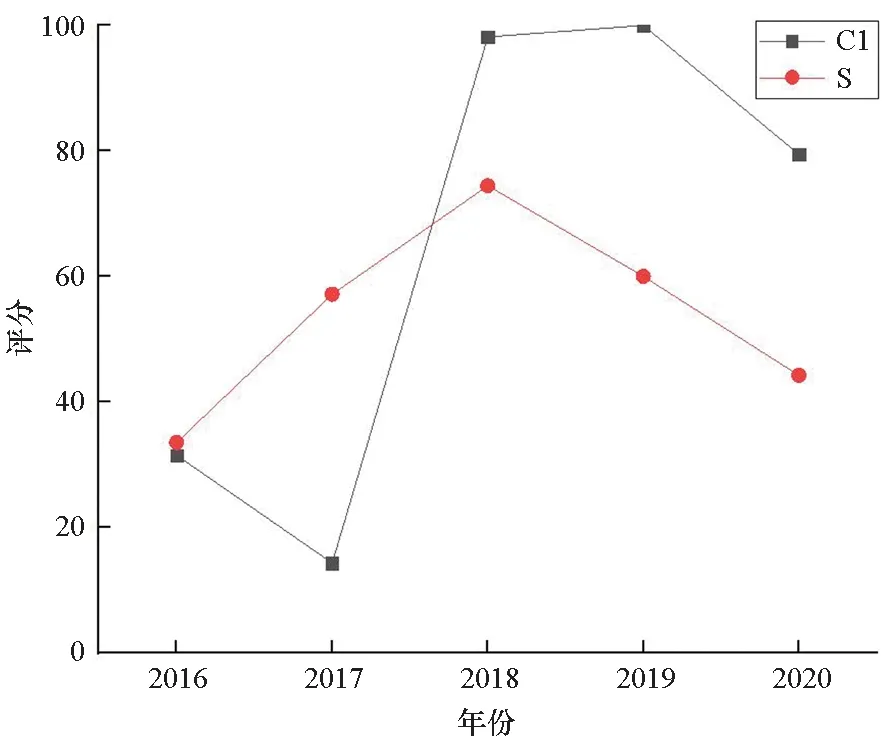
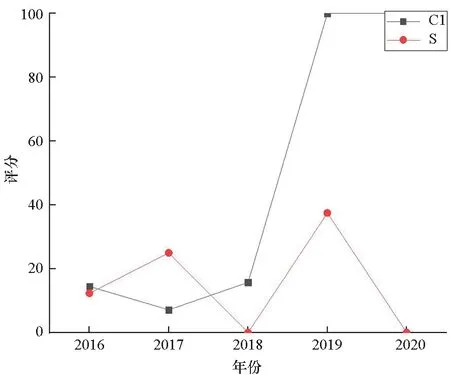
固定考评周期H,通过改变考评时间点t,可以跟踪评估各参评城市拥军优属工作的发展变化情况。图3给出了14个市州2016—2020年的跟踪评估结果,考评周期均为1年,考评时间点分别选在每年12月。图中结果直观反映了过去5年各市州推进拥军优属工作的成效。以C1和S市为例,C1的拥军优属工作可谓“节节高升”,S却先升后降、有些后劲不足。但要注意,这里给出的是两个城市的总评分,是相对分而非绝对分(见式(6)和式(7)),故图3反映的并不一定是S市的绝对分走低,而是表明新时期各地都在大力推进拥军优属,该市的进步没有别的市州快。

图3 对H省14个市州近5年的跟踪评估结果Fig.3 Dynamics of the evaluation results of the cities in H province in the recent 5 years
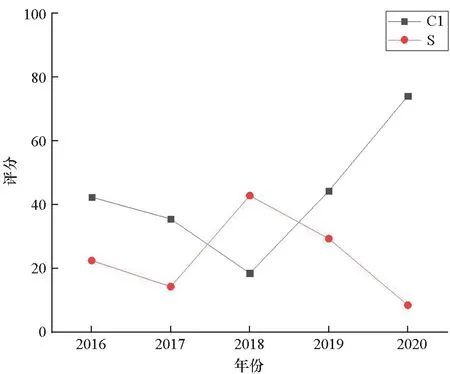
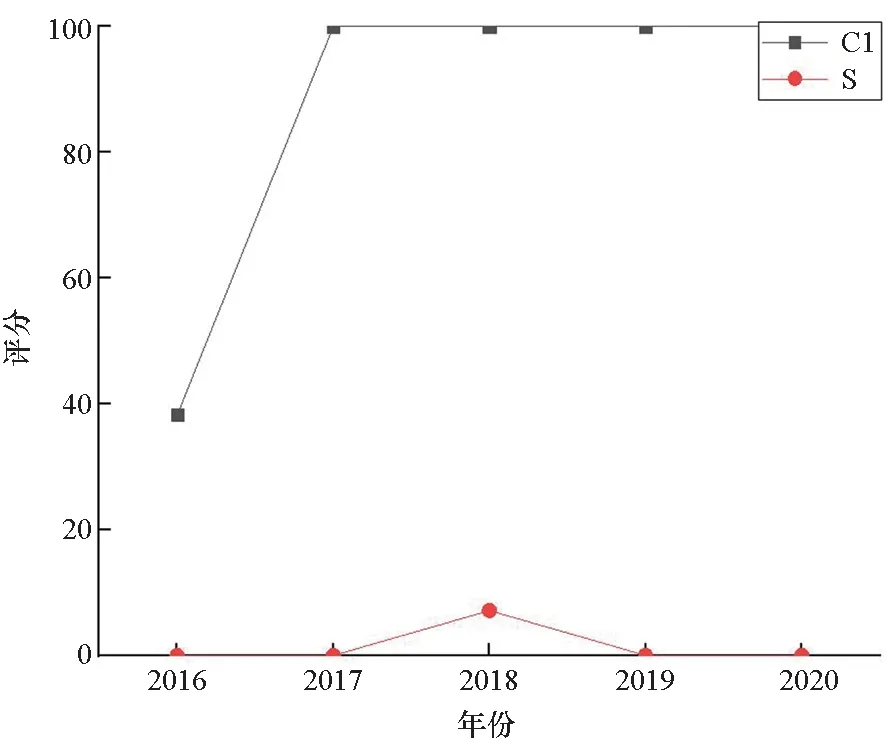
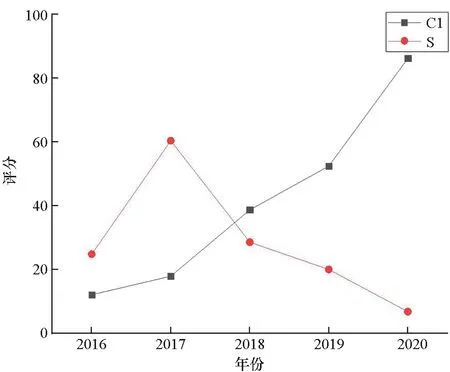
为进一步探究其中原因,图4给出了两个城市2016—2020年间6个时效性较强的二级指标的标准分(即政策制度类的S1~S5和新闻动态类的S9)变化和对比情况。可见,C1市几乎全方位领先;而S市在住房、就业和新闻动态等方面的标准分(相对分)呈下降趋势,导致整体排位下滑。此结果还反映出,如果S市想要改进工作、提升排名,下步应重点在住房、医疗、就业等领域的政策制度制定与落实,以及新闻宣传等方面加大力气、多花功夫。
由此可见,本文模型产生的评估结果可为参评城市改进工作、争先创优指明方向,提供决策参考。除图4给出的结果外,还可任意设置模型参数t和H,实现随时评、时时评,密切跟踪参评城市的工作推进发展情况。
(a) 教育(a) Education
(b) 就业(b) Employment
(c) 住房(c) Housing
(d) 医疗(d) Healthcare
(e) 新闻动态(e) Propaganda

(f) 其他(f) Others图4 两个参评城市的6个时效性较强的二级指标得分随时间变化情况Fig.4 Scores of two cities under consideration with respect to 6 heavily time-dependent second-level indices
3 结论
长期以来,针对拥军优属等社会工作的定量评估评价研究还显薄弱,存在无针对性指标体系,现有相关评比周期长、成本高等突出问题。为此,本文探索构建了利用互联网开源大数据实时评估各地社会工作推进情况的定量模型,建立了针对性指标体系,提出了评分快速计算方法,并研制原型软件,以拥军优属为案例,利用网上真实数据进行了模型实证。其中,针对某省各市州的评估排序结果得到多名受访者较一致的认可,且与2020年度该省“全国双拥模范城(县)”命名结果也基本吻合,验证了方法的有效性与合理性。原型已获软件著作权(登记号2021SR0480424),所提模型也已申报发明专利(公开号202011483170.1)。本文工作属于利用大数据支撑社会管理的范畴,综合运用管理科学和信息科学的理论技术,特别是层次分析法、文本分析处理、机器学习等方法技术,进行了社会工作评估方面的有益探索。
本文工作也还有很多需要改进和拓展之处,至少包括如下三方面:第一,受众反响是工作评价最重要的依据之一,而当前模型在这方面还有欠缺。下步,拟引入各类社交平台上的网民评论数据,借助情感分析技术进行观点分析,进而评估受众的态度反响,并纳入评估指标体系中。第二,体量大、噪声高、价值密度低是大数据的基本特点,因此本文借助算法自动进行数据过滤、去重和文本分析等,但这些算法都有其精度水平限制(本文实验中文本去重精度约0.9、相关性过滤精度约0.92、聚类精度约0.8、分类精度约0.87)。尽管实验反映,针对H省各市州的最终评估结果比较合理,貌似未明显受到数据分析处理误差的影响,但随着参评范围扩大、数据量显著增加,不排除一些算法的精度水平会明显下降,届时将给评估结果带来怎样的影响值得未来深入探讨。第三,目前原型只关注H省,如果未来扩展至全国所有省、自治区、直辖市,包括所辖市州和县区,那么数据量会增大数十倍、甚至数百倍。届时,本文标题中的“大数据”一词将变得更为贴切,但数据体量陡增带来的计算存储压力也必须考虑和应对。鉴于各参评城市的数据及其分析计算,至少在原始分计算结束前相对独立,而后则需要汇总统计,很符合Map-Reduce模型,故拟引入该模型进行评估计算的并行化,并将原型移植到Spark等支持流式大数据的支撑平台上。
