基于Transformer的图像分割研究
2022-08-05谭棚文向红朵
谭棚文 向红朵
(重庆师范大学,重庆 401331)
0 引言
脑胶质瘤是对神经系统胶质细胞肿瘤和神经元细胞肿瘤的统称,其发病率高,治愈率低。目前,对该疾病的诊断以及对手术后病人恢复效果的评估主要依赖于磁共振成像(Magnetic Resonance Imaging,MRI)技术,而脑胶质瘤的分割往往依靠医生根据临床经验进行手动分割,该方法不仅会耗费大量时间与精力,而且分割准确率难以得到保障。因此,设计一个采用自动或半自动方法且能够精准分割脑胶质瘤的方法十分重要,这不仅可以提供精确的治疗方案,而且还可以优化患者的预后。
该文的主要贡献有以下2点:1) 在每层的跳跃连接过程中引入senet模块进行处理后再进行拼接,以增强底层语义和高层语义的连接效果,从而为模型在进行多尺度预测和分割时提供更加精细的特征。2) 再引入一个基于Dice相似系数与交叉熵损失函数改进的损失函数,以解决训练时可能出现的梯度消失情况。
1 研究现状
目前,卷积神经网络(Convolutional Neural Networks,CNN)已经广泛应用于医学影响分割领域,并表现出较为优异的性能。例如TransUNet模型将Transformer作为完成医学图像分割任务的强大编码器,并借助UNet恢复localized空间信息,然而其无法在降低模型参数量的同时保持高分割精度。类似Unet的纯Transformer网络模型Swin-Unet,使用带有偏移窗口的分层Swin Transformer作为编码器来提取上下文特征,然而该方法无法充分利用图像的三维特征。3DUnet的诞生为医学影像分割提供了极大的帮助,在很大程度上解决了3D图像分割时需要将一个个切片输入模型进行训练的复杂问题,也大幅提升了训练效率。HATAMIZADEH A等人提出了UNETR网络模型,将三维数据分割任务重新设计为序列到序列的预测问题,以提高图像分割性能,但在分割过程中容易缺失图像的局部信息。还有一种Gated Axial-Attention模型,通过在自注意力模块中引入附加的控制机制来扩展现有体系结构,然而其在训练过程中引入了过多的冗余信息,导致其分割精度较低。
2 模型设计
相关研究显示,基于Transformer的相关方法具有更好的分割效果,该方法采用的Transformer模型具有“U”形编码器-解码器设计,可对输入体数据进行整体处理,其网络结构图如图1所示。
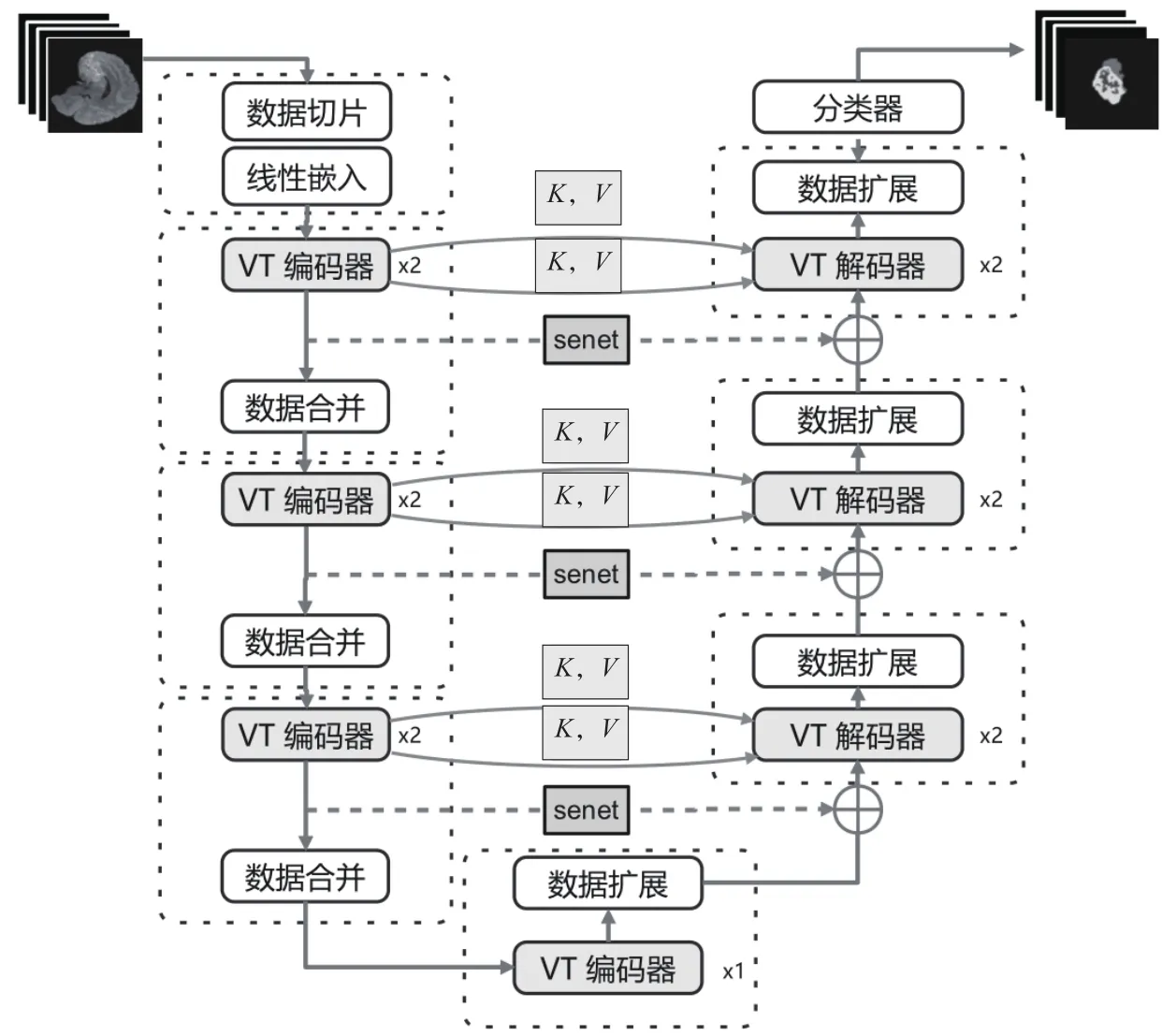
图1 网络结构图
在senet中,比较重要的就是压缩操作与自适应重新校正操作,与只在一个局部空间进行操作而无法获取足够信息的传统卷积相比,senet 设计了Squeeze操作,其每个通道的具体操作如公式(1)所示。
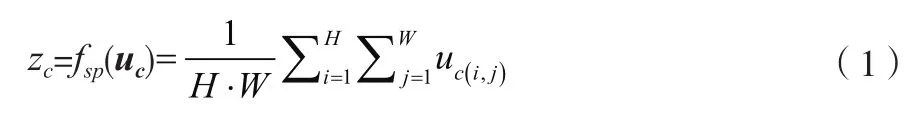
式中:f(u)为对u矩阵进行Squeeze 操作;为高度;为宽度;u为矩阵中的第行、第列元素;Z为压缩矩阵中的第个元素。
编码器有2个连续的自注意层来同时编码局部和全局信息,解码器基于并行移动窗口的自注意模块和交叉注意模块来捕获细节,同时接受同一阶段编码器生成的键()与值(),并通过傅里叶位置编码来细化边界,在网络跳跃连接时加入senet模块,尽可能通过通道的特征去关注全局的目标特征。
Squeeze操作将原始维度为(其中,为高度;为宽度,;为通道数)的数据压缩为11,也就是将三维数据压缩成一维数据。同时,为了利用通道间的相关性来训练真正的目标维数,为了限制模型的复杂度并增强其泛化能力,自适应重新校正部分在门限机制中使用bottleneck形式的2个全连接层,具体操作如公式(2)所示。
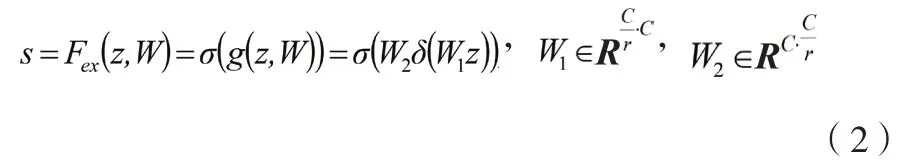
式中:为Squeeze得到的结果;为Sigmoid函数;为ReLU 函数;,()为全连接操作;F(,)为对压缩结果进行自适应重新校正操作;为加权后的结果;(,)为对其进行ReLu激活;为数据矩阵;为一个缩放参数;为数据维度。
在经过Squeeze操作与Excitation操作后,在Reweight操作中,将学到的各个通道的激活值乘以原始特征得到最后的结果。具体操作如公式(3)所示。

式中:u为1个二维矩阵;F(u,s)u与s进行逐通道相乘;X为升维后的矩阵中的第个元素。
3 试验及结果分析
3.1 试验环境与数据预处理
该文的试验环境为CUDA V11.2并行计算架构,GPU型号是显存为25.4 GB的RTX3090,采用Microsoft Windows 10操作系统与V1.10版本的开源PyTorch框架,运用Python3.7.4 在VSCode上对整体代码进行编写并运行。
该文的试验数据来源于MICCAI BRATS2021脑胶质瘤数据集。该数据集由形状为240·240·155的1 251次MRI影像组成,该文将这1 251次影像划分为3组(800次、225次以及226次),分别用于训练、验证以及测试。
该文的输入数据为四模态MRI影像,其影像数据会因采集设备的制造商、各影像的采集参数和序列的不同而产生差异。为了使网络更好地工作,需要对输入图像进行标准化处理。首先,对所有MRI序列影像进行线性归一化(Min-Max Scale)。其次,使用包括整个大脑的最小边界框,并通过移除不必要的背景将体积裁剪成128·128·128的固定大小,这样可以去除原始影像中大部分无用的背景,并保留有效影像。最后,为了防止过拟合,该文通过多种方法按照一定的概率进行动态数据增强。具体方法以及各自的概率如下:沿每个空间轴旋转(概率为60%)。加入高斯噪声,使用标准偏差为0.1的中心正态分布;输入通道重新缩放,将每个体素乘以0.9和1.1之间均匀采样的因子(概率为80%)。
3.2 损失函数
由于Dice损失函数()测量的是2个轮廓边缘的最大距离,如果单个体素远离参考分割,那么Hausdorff距离值将会偏高。为了解决这个问题,受Jiang Zeyu 等人在2019年Brats竞赛中解决方案的启发,该文决定使用进行训练,该损失函数不需要在前景和背景体素之间建立正确的平衡,也就是不用给不同类别的样本分配权重。其损失值是按批次和按通道计算的,没有加权,具体操作如公式(4)所示。
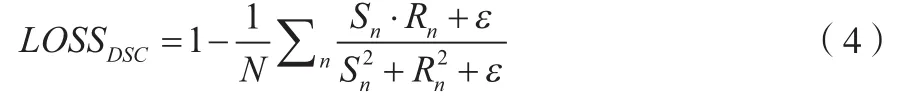
式中:为输出通道数;S为激活后神经网络的输出;R为基础真值标签;为平滑因子,在该文实验中的数值为1;LOSS为Dice损失函数。
最后混合损失函数的定义如公式(5)所示。

3.3 评价指标
该文采用Dice相似系数作为性能评价指标,其主要的评估指标是重叠度量和距离度量,具体定义如公式(6)所示。

式中:为真阳性;为假阳性;为假阴性。
Dice系数的范围为0~1,当Dice系数为1时,表示完全重叠。
3.4 模型训练与验证
该文采用了Liu Ze等人在ImageNet-1K图像分类中预先训练的权重来初始化模型。训练时采用了Adam优化算法,网络批大小设置为1,训练周期设置为200,训练时初始学习速率为0.000 1,采用余弦衰减速率调度器重新设置学习速率,衰减步数为每4个周期衰减1次。模型是通过五重交叉验证产生的,验证集仅在训练期间用于调整超参数,并在训练过程结束时对其性能进行基准测试。在模型训练过程中,损失函数的变化曲线如图2所示。由图2可知,随着迭代次数的增加,损失值在逐渐降低,当训练迭代次数大约为170时,网络损失已趋于稳定。
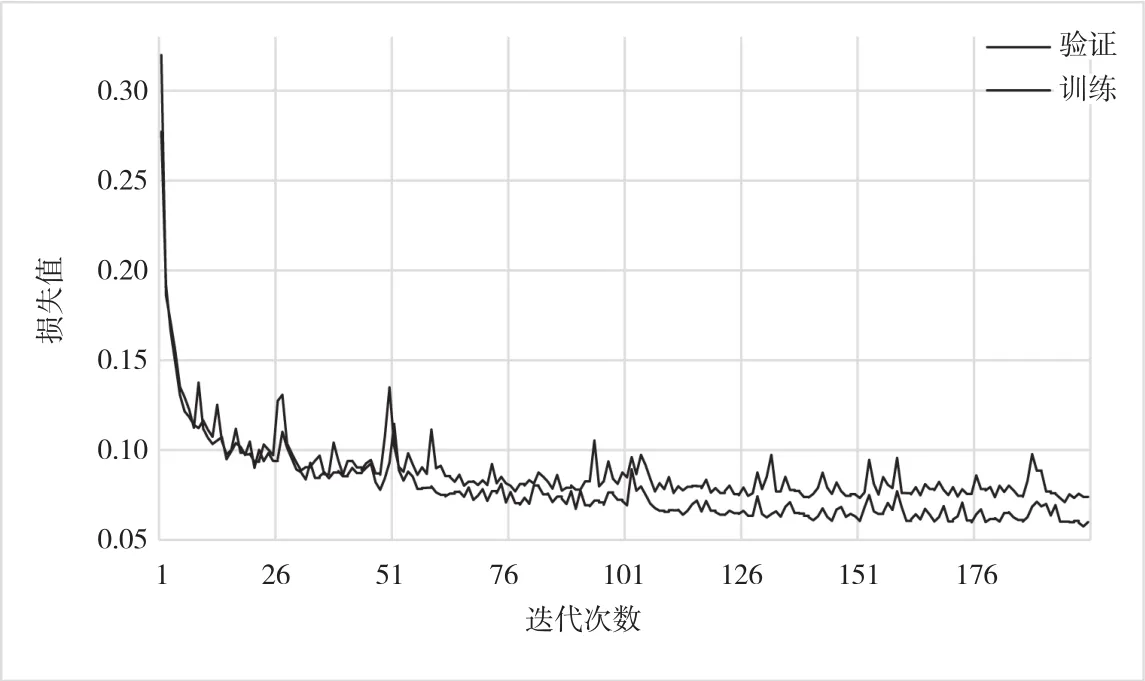
图2 损失函数变化情况图
3.5 实验结果
每个肿瘤类别在训练周期时的得分情况如图3所示。
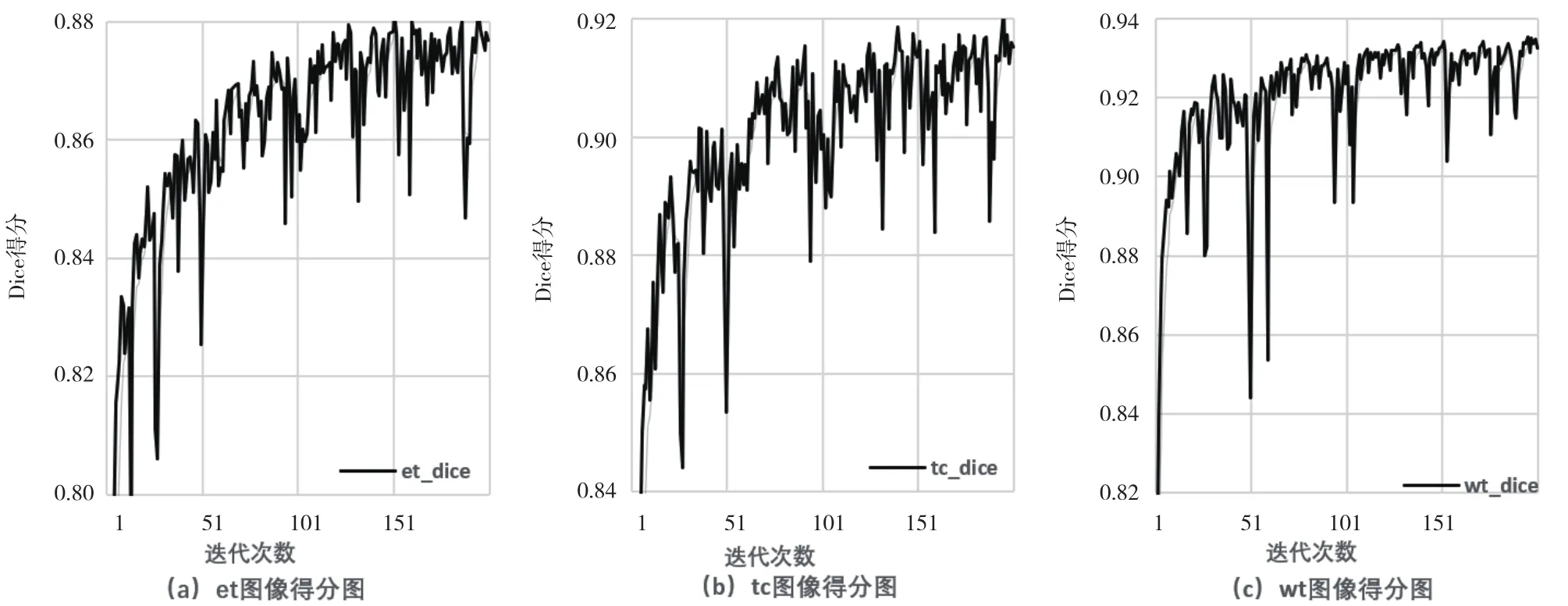
图3 Dice评分收敛图
在图4中,该文选取最近提出、效果较好且采用三维体数据作为输入数据的其他模型并进行对比。由图4可知,该文提出的方法与原始数据中的分割影响相近,具有良好的分割性能。
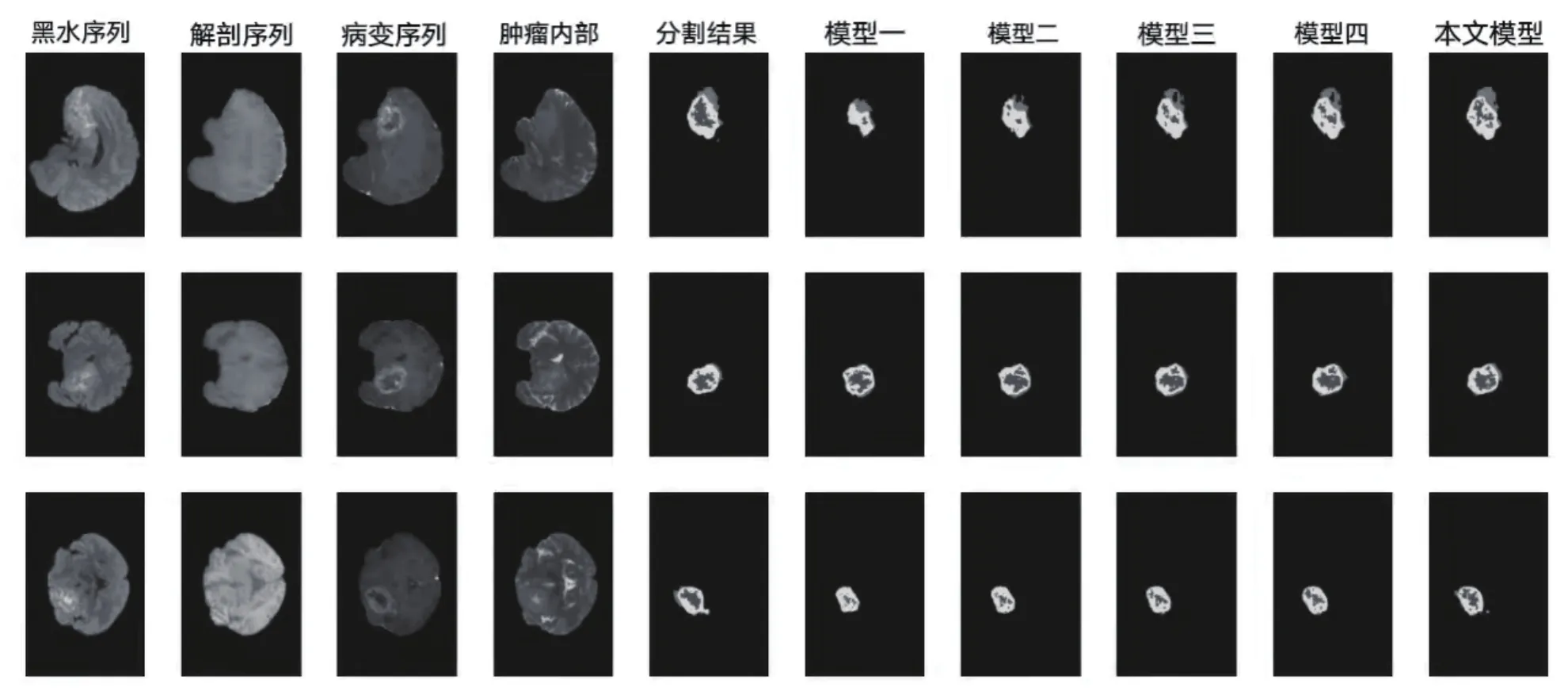
图4 原始数据与5种模型的分割结果图
表1将该文的方法与基于Unet的3D Unet(模型三)方法、EquiUnet(模型一)和Attention EquiUnet(模型四)方法以及TrasnBTS(模型二)方法进行对比。由表1可知,该文所提出的方法在分割脑胶质瘤上的表现均好于其他网络。
3.6 消融实验
为进一步研究各方法对整体性能的贡献,该文逐步将不同的组件集成到模型中去。由表1~表4可知,所有模块都有助于提高模型的性能,使用预先训练的权重在一定程度上可以提高模型的分割性能,与使用单个损失函数相比,混合损失函数的应用在一定程度上解决了网络训练过程中梯度消失的情况。同时,引入senet模块进一步加强了模型的分割性能。
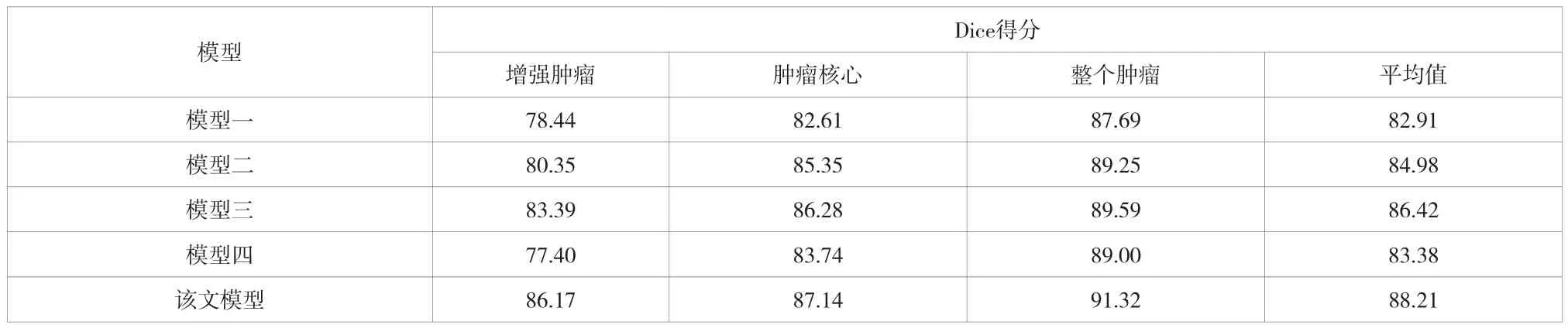
表1 5种模型的分割性能对比表

表4 senet模块的消融研究

表2 预训练模型的消融研究

表3 损失函数的消融研究
4 结语
准确地对脑胶质瘤进行分割对脑癌的早期诊断非常重要。在将注意力机制应用于模型中的跳跃连接过程中,采用改进的混合函数来优化模型,使其能够更好地帮助模型学习样本。该文的研究结果表明,与现有的传统分割方法相比,所做出的改进在脑胶质瘤分割方面有一定提升。然而该文所提出的算法具有一定的局限性,当训练数据集较少时,所得到的结果会较低。因此使用有限样本得到较好分割性能是下一步研究的重点。
