一种基于语义信息辅助的无人机视觉/惯性融合定位方法
2022-08-05赖际舟杨子寒
吕 品,何 容,赖际舟,杨子寒,袁 诚
(南京航空航天大学自动化学院,南京 211106)
0 引言
无人机凭借其成本低、体积小及机动灵活等特点,在军事和民事领域都有广泛的应用。目前,随着无人机智能化、微型化的发展,其应用领域也从室外逐渐向室内拓展。无人机常用的导航定位方案是全球卫星导航系统(Global Navigation Satellite System,GNSS)和惯性导航系统(Inertial Navigation System,INS)的组合导航方案,其中GNSS是决定其定位精度的关键性因素。与室外环境不同,无人机在室内场景中运行时,由于建筑物的遮挡,GNSS信号会严重衰减甚至完全消失,传统的GNSS/INS导航方法将无法提供持续可靠的导航定位信息。
同步定位与地图构建(Simultaneous Localization and Mapping,SLAM)是常用的室内导航方法,根据传感器的不同,可以分为视觉SLAM和激光雷达SLAM。视觉传感器能够获取环境的纹理、颜色与特征信息,利用视觉特征能够构建出稀疏或稠密的特征地图,无需先验信息就能完成自身位置的解算。而且,视觉传感器具有体积小、质量小及感知信息丰富等优点。因此,为了解决室内场景下无人机的自主飞行问题,越来越多的研究人员将视觉传感器应用于无人机室内自主导航定位。根据利用图像信息的不同,视觉SLAM中的前端里程计算法又可以被分为基于直接法的里程计(SVO、DSO)和基于间接法的里程计(ORB-SLAM2、ORB-SLAM3)。直接法直接利用图像的灰度信息进行帧间匹配以及运动估计,而间接法通过先提取出图像的特征,利用特征的匹配和跟踪进行相机的位姿解算。间接法使用的特征描述受光照影响较小,与直接法相比具有更好的鲁棒性。
传统的间接法视觉里程计(Visual Odometry,VO)算法多提取环境中的低级视觉几何特征,然后通过集束调整(Bundle Adjustment,BA)最小化重投影或光度误差。基于点、线特征的VO通过底层亮度关系进行描述匹配,抗干扰能力不足,会出现匹配错误甚至失败的情况。除了点、线这些环境中的低级特征,含有语义信息的物体也是环境重要的组成部分。提取环境中的物体并进行相应的语义信息映射,可以极大地提高无人机对环境的理解能力以及人机交互的智能性。此外,环境中的物体特征还可以提供额外的语义和几何约束,以提高相机位姿估计的精度。文献[10]提出了一种将语义信息整合到视觉SLAM系统中的方法,该方法利用语义信息在特征匹配环节进行外点的剔除,同时利用因子图进行位姿的优化求解,在动态环境中该方法比传统算法具有更好的鲁棒性。文献[11]提出了一种物体级别的SLAM算法,该方法基于Kinect fusion,使用MASK RCNN对图像进行实例分割,建立每个物体的截断符号距离函数,实现物体级别的跟踪、重建以及回环。文献[14]提出了一种面向特定类别对象的SLAM方法,通过目标识别建立相机与对象之间的观测约束,并通过图优化方法进行优化求解。目前,在语义辅助的视觉SLAM定位方法中,语义信息的使用具有多种形式,尚未形成统一的方法和架构。
虽然利用语义信息可以对传统的VO算法进行辅助的位姿优化,但语义的获取仍然依赖视觉传感器,而单一的传感器由于感知维度的匮乏,难以满足无人机在室内复杂环境下的鲁棒定位要求。惯性传感器具有完全自主的优点,对短时间内的相对运动估计精度较高,但长时间的递推估计会产生较大的累积误差。将视觉与惯性测量单元(Inertial Measure-ment Unit,IMU)信息进行融合,综合利用多维量测信息,充分利用数据的冗余及互补,弥补单个传感器的固有缺陷,可以提高系统导航定位的精度和鲁棒性。
由此可知,单独基于特征点的VO由于单一传感器以及低维特征的限制,在特征点稀疏、机动特性较大等挑战性室内场景运行时,难以满足无人机的智能自主导航定位需求。针对该问题,本文提出了一种基于语义信息辅助的无人机视觉/惯性融合定位方法。创新点主要包括:1)针对传统VO算法提取低级几何特征抗干扰能力不足的问题,根据室内环境的特点,通过提取环境中的平面语义信息,并辅助VO系统进行位姿优化,提高位姿估计的精度及鲁棒性;2)针对单一视觉传感器感知维度匮乏、易受外界干扰的问题,将视觉传感器和惯性传感器信息进行融合,以提高整个定位系统的精度、鲁棒性和可靠性。
1 基于平面语义信息辅助的视觉/惯性融合定位方案设计
基于平面语义信息辅助的视觉/惯性融合定位方案以传统的VO为基础,辅助增加语义信息以及惯性信息的融合利用,从而提升传统基于特征点的视觉VO导航定位精度。如图1所示,其可以被分为前端处理与后端融合优化两个部分,每一个部分都可以被分为传统视觉VO、语义融合和惯性融合3个子处理模块。在图1中,传统视觉VO部分用蓝色进行标注,语义部分用橙色进行标注,惯性部分用绿色进行标注。本文在传统视觉VO的基础上,首先实现语义信息的提取和融合;然后在语义辅助的VO的基础上,实现惯性信息的预处理与融合;最终实现语义信息辅助的视觉/惯性融合定位方案。

图1 基于平面语义信息辅助的视觉/惯性融合定位方案框架Fig.1 Framework of plane semantic information aided visual/inertial fusion positioning
在语义信息的融合方面,通过提取的语义平面对环境中的语义信息进行特征表示,并建立对应的数据关联方法。在惯性融合方面,利用惯性预积分技术,获取两视觉关键帧之间的惯性信息约束。通过对语义特征以及惯性预积分的因子图建模,构建融合语义信息和惯性信息的VO因子图架构,实现语义和惯性对VO的辅助优化。
2 基于平面语义信息辅助的VO算法
语义信息通常需要与一些具体的特征相结合,为其提供相应的概念与约束,才能与传统的VO融合,辅助提高位姿优化精度。本文将语义信息与平面特征相结合,构建出语义平面,作为视觉VO额外的高维特征,为传统的VO增添除特征点之外的环境观测与约束。而后,对语义平面特征进行因子建模,构建相应的因子图优化方案,通过对传统视觉VO的因子图结构进行扩充与改善,以提高无人机的导航定位精度。
语义信息辅助的改进VO与传统VO因子图融合框架对比如图2所示。在图2中,圆圈表示因子图的优化节点,节点间的连线表示两节点之间存在相应的约束关系,这些约束关系通过连线上的方块进行表示;表示第关键帧时刻相机的位姿,表示构建的第个传统特征点,表示构建的第个语义平面特征;橙色方框表示语义平面观测约束,黑色方框表示VO得到的帧间相对位姿约束,灰色方框表示传统特征点的观测约束。

(a)传统VO因子图结构

(b)语义信息辅助的改进VO因子图结构
传统VO由于只提取低维的点特征,因此其构建的因子图模型中只包含特征点与相机位姿节点,且构建的约束只包括二者之间的观测约束,其结构如图2(a)所示。本文在传统VO的基础上实现了语义信息辅助的VO因子图结构,如图2(b)所示。在传统算法的基础上,本文首先根据VO量测,增添帧间相对位姿约束因子,为相邻两关键帧之间提供直接的相对位姿约束,而后通过语义平面的特征提取及数据关联,获取关键帧与语义平面特征之间的观测约束,并进行相应的因子构建。
2.1 语义平面特征构建及数据关联
在语义信息的提取上,为了实现对感兴趣语义对象的快速精确检测,本文采用基于卷积神经网络的视觉检测方法,实现对RGB图像语义对象的实时检测,获取室内感兴趣语义对象的二维BBOX。在点云分割及平面拟合方面,本文基于深度图像点云的结构化特性,在获取的语义对象二维BBOX内,使用基于连通域的点云分割与平面拟合方法,进行点云分割及平面拟合,获取感兴趣语义对象的三维平面。结合语义信息的提取及平面分割结果,可以构建具有语义属性的三维平面。通过上述过程,可以获取语义物体表面所在平面参数、平面类型、所属物体类别,利用这些属性以及三维几何空间信息,可以构建丰富的语义平面特征。
在室内场景中,本文关注的语义对象中的表平面通常为水平或垂直向。因此,在语义平面提取过程中,本文也对平面分割结果进行筛选,并构建语义平面特征。
2.1.1 平面筛选
首先,根据提取的所有平面的质心和法线,判断平面,如式(1)

(1)
其中,为提取的平面法线;为已知的地平面法线。如果与的差值小于设定的水平面法线差阈值,则以为法线的平面被标记水平面;而如果大于设定阈值,则检查平面是否为垂直平面。同样,设置垂直面法线差阈值。若平面为一垂直平面,则其法向量将与本文设置的标准水平面法向垂直,即二者点积为0。由此,可以通过点积的方式计算平面法线与垂直平面法线的差值,如式(2)
=·
(2)
如果小于设定的阈值,以为法线的平面被标记垂直平面。
2.1.2 语义平面特征构建
由上述流程步骤,可以获取平面的多种信息:语义类别、形心、法线方向、平面类别(垂直/水平平面)。由此构建语义平面特征,如式(3)

(3)
其中,为平面形心;为平面法线参数;为平面类别标签(水平垂直);为平面语义类别标签,其取决于平面所对应的语义对象类别。
2.1.3 语义特征关联

通过平面分割及语义特征构建,可以得到如式(4)所示的语义平面
={,,,}
(4)
其中,对于,其所有位置相关特征项均以相机系为参考系。
算法中第一个接收到的语义对象不用经过数据关联,直接映射为第一个语义路标,将其表示为
={,,,,}
(5)
其中,对于,及表示在世界坐标系下的语义路标质心及法向。其可利用和通过坐标变换求得,具体公式如式(6)

(6)
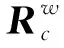
完成初始语义路标设置后,通过以下3个步骤实现每帧检测语义平面与语义路标图之间的数据关联:
1)首先,将从帧中提取的语义平面与语义路标进行类别及平面类型的匹配。匹配成功后,计算语义平面的点云个数及区域面积。本文为点云数据及语义平面面积分别设置了最小阈值:和,用于删除由于检测边界框不完全适合语义对象导致的质心坐标存在偏差的语义平面。经过上述检测,匹配成功的语义平面才能进行后续匹配,否则匹配失败。
2)而后,利用坐标变换,将语义平面的法线方向由相机坐标系转换到世界坐标系下,得到,将其与语义路标的法向进行匹配。若与间的偏差小于设定的阈值,则认为语义平面与路标法向一致,进入后续的坐标关联,否则匹配失败。
3)通过上述两步骤,将语义平面的形心由相机坐标系转换到世界坐标系下,计算语义平面形心与其相匹配的路标形心的马氏距离,若大于设定的阈值,则将检测到的语义对象映射为新的语义路标,否则语义对象与当前的语义路标相匹配。
利用语义平面特征构建及数据关联,可以得到补充的相机关键帧位姿帧间约束。
2.2 基于语义信息辅助的位姿非线性优化方法
本文所提方法的优化函数可以表示为
=

(7)
其中,Semantic部分代表语义路标观测的残差;,表示相机某帧观测到的语义路标位置误差;VO部分代表VO中相对位姿的观测残差;(·)代表鲁棒核函数;表示各误差量对应的信息矩阵,其为协方差矩阵的逆;VO的协方差矩阵与视觉相机标定后的重投影误差相关,语义残差的协方差矩阵与语义路标的不确定性相关。式中,、分别指第、图像帧,表示第个语义路标。对于构建的残差模型,本文中设定的优化状态变量为相机的位姿以及语义特征的位置,分别用与表示。
对于语义路标观测误差,如式(8)

(8)

对于VO位姿观测残差,如式(9)

(9)

采用L-M优化算法对优化代价函数进行优化求解,即可实现状态量的优化,即实现对相机位姿以及语义路标位置的同时优化。
3 基于惯性预积分的语义视觉/惯性融合算法
通过语义信息的提取与融合,可以提升传统VO算法的定位精度。然而,语义信息和点特征都利用视觉传感器进行提取,都属于视觉特征。在实际应用场景中,由于无人机的快速运动及角度的快速转变,视觉信息通常会受到一定的限制。在大机动情况下,基于视觉的位置解算很可能会存在较大的偏差。与视觉传感器不同,IMU是一种完全自主的导航传感器,其不依赖对外界环境的感知,与视觉传感器进行融合,可以得到更鲁棒的导航系统。
本文基于IMU预积分,建立相邻两图像帧之间的运动约束,利用该约束对相机位姿估计状态量进行辅助优化。本文构建的语义视觉/惯性融合系统框图如图3所示。IMU预积分在视觉关键帧之间进行,得到的是两关键帧之间的惯性预积分约束,在构建好约束之后,与语义VO联合进行优化量的优化求解。

图3 语义视觉/惯性里程计系统框图Fig.3 Frame diagram of semantic visual/inertial odometry system
结合IMU预积分,同时考虑IMU及VO、语义残差的后端优化函数如式(10)所示


(10)

融合惯性信息后,第时刻的系统状态变量为

(11)

式(10)中,IMU预积分误差的具体表示如式(12)所示

(12)

采用L-M优化算法对式(10)进行优化求解,得到系统状态变量的最优估计。
4 试验测试与分析
4.1 试验设置
为了验证本文所提方法的性能,开展了TUM-RGBD数据集试验和实际的无人机飞行验证试验,通过与传统VO方法定位精度的对比分析,验证了本文所提方法的可靠性和精度。
4.2 TUM-RGBD数据集试验与分析
TUM数据集包括不同场景的室内序列,用于评估视觉里程计的性能,其提供了RGB-D传感器在环境中的真实运动轨迹及采集到的RGB图像与深度图像。RGB-D传感器使用的是微软的kinect,采用结构光进行深度信息的获取,能够提供分辨率较高较为精细的深度图。RGB图像分辨率为640dpi×480dpi,频率为30Hz;深度图像分辨率为320dpi×240dpi,频率为30Hz。
本文选取TUM数据集中含有语义路标的室内场景Freiburg2视频序列进行验证,将所提的平面语义信息辅助VO算法与传统VO方法进行对比分析。在试验数据中,出现的典型语义对象为椅子、屏幕、书以及键盘等,本文算法能检测出这些典型的语义对象,并按需求将其设置为语义路标。Freiburg2视频序列场景如图4所示。

图4 Freiburg2 xyz视频序列场景图Fig.4 Scene image of Freiburg2 xyz video sequence
在该数据集视频序列中,相机动态沿着、和轴做平移和旋转运动。在相机的视野范围内,始终存在两个语义对象,一个电视监视器和一个键盘。在试验过程中,这两个语义对象在语义信息辅助的视觉VO中被检测出,并作为语义路标添加进因子图优化框架中,协助传统的基于特征点的VO进行辅助的位姿优化。图5显示了语义信息辅助的视觉里程计解算出的相机运动轨迹以及所构建的语义平面对象。其中,红色垂直向平面为对数据集中“电脑屏幕(TVmonitor)”的语义平面,紫色水平向平面为对数据集中“键盘(Keyboard)”的语义平面。

图5 语义信息辅助的VO定位及构图结果Fig.5 Semantic information aide VO positioning and mapping results
图6所示为TUM数据集试验轨迹对比图,绿线代表无语义信息辅助的RGB-D VO解算结果,红线代表语义信息辅助下的RGB-D VO结果,蓝线代表真值,蓝色圆圈所在处为相机的初始位置。由图6可以看出,使用语义信息辅助的视觉里程计解算得到的相机轨迹与真值间的偏移量更小,与传统的RGB-D视觉里程计相比具有更好的定位精度。图7所示为TUM数据集试验三轴位置误差对比图。从图7可以看出,经语义信息融合后,相机的三轴位置误差在一定程度上都有所修正。

图6 TUM数据集试验轨迹对比图Fig.6 Trajectories comparison diagram of TUM dataset experiment

图7 TUM数据集试验三轴位置误差对比图Fig.7 Comparison diagram of three-axis position error in TUM dataset experiment
图8所示为传统VO与本文所提语义信息辅助VO的误差统计箱线图。从图8可以看出,在统计意义上,改进算法的误差不管是从数值还是从误差范围的分布上,与传统算法相比都有更好的表现。表1对比了传统VO与本文所提语义信息辅助VO的定位误差,可以看出,本文所提的语义信息辅助的VO方法具有更好的精度。

图8 TUM数据集试验位置误差箱线对比图Fig.8 Comparison diagram of position error box-plot of TUM dataset experiment

表1 TUM数据集试验定位误差统计
4.3 无人机试验与分析
为了进一步验证本文所提方法的有效性,利用无人机平台进行实际试验验证,通过运动捕捉系统获取无人机的基准位置信息,其定位精度可达毫米级。飞行试验硬件平台如图9所示,选用的无人机为大疆创新(DJI)的Matrix 100四轴飞行器;视觉传感器型号为Intel RealSense D435i,可以同时获取RGB及深度图像信息;惯性传感器为Intel RealSense D435i自带的IMU,其型号为博世BMI055;机载计算机为DJI Manifold。

图9 飞行试验硬件平台Fig.9 UAV flight experiment hardware platform
试验场景如图10所示,在本次飞行试验室内场景中出现的典型语义对象主要为椅子、电脑屏幕等。为了验证语义信息的辅助效果以及惯性融合对定位结果的优化程度,检验整体的改进算法的性能,本次试验在场景中采集了多组测试数据,对无人机定位系统的整体性能精度及误差特性进行评估。在测试过程中,无人机围绕着语义对象进行无规律地平移以及旋转运动,试验中同时还设置了大范围转角等机动性较强的无人机飞行轨迹,以保证对算法的鲁棒性进行验证。在运动过程中,无人机始终保持视野范围内有语义对象的存在,每组数据无人机的运动过程持续约3min。试验过程中,无人机始终控制在动捕系统的追踪范围内。

图10 无人机飞行试验场景Fig.10 Scene image of UAV flight experiment
选取一组试验数据进行无人机轨迹绘制及定位误差分析。图11显示了在语义信息与惯性的辅助下,算法的相机运动轨迹解算结果以及构建的语义平面对象。其中,红色平面为对数据集中“电脑屏幕(TVmonitor)”的语义平面,绿色平面为对数据集中“椅子(chair)”的语义平面。

图11 语义信息辅助的视觉/惯性融合定位及构图结果Fig.11 Semantic information aide visual/inertial fusion positioning and mapping results
为了体现本文所提方法的改进效果,利用传统VO与本文算法的解算结果进行导航结果绘制,并将其与运动捕捉系统提供的参考基准轨迹进行对比,可以得到如图12所示的无人机轨迹对比图。其中蓝色为运动捕捉系统获取的无人机的真实飞行轨迹,红色为本文所提方法得到的无人机轨迹,绿色为传统VO算法得到的无人机轨迹,蓝色圆圈为试验中设置的无人机运动的起点。由图12可以看出,本文改进算法解算的无人机位置轨迹与真值的偏移量更小,相比之下,传统VO算法具有更大的定位偏差。在试验过程中,观测到同一语义对象的关键帧之间形成了十分紧密的共视关系,为位姿优化提供了一个全局约束。因此,在本次试验中,改进算法轨迹相对于无人机的真实轨迹漂移较少。在一些设置的转弯处,无人机机动性较大,传统VO算法在该处出现了较大的漂移,而本文算法通过惯性信息的辅助,在该处精度有所提升。

图12 无人机室内定位试验轨迹对比图Fig.12 Trajectories comparison diagram of UAV indoor positioning experiment

图13 无人机室内定位试验三轴位置误差对比图Fig.13 Comparison diagram of three-axis position error in UAV indoor positioning experiment

图14 无人机室内定位试验位置误差箱线对比图Fig.14 Comparison diagram of position error box-plot of UAV indoor positioning experiment
图13和图14所示分别为无人机飞行试验中的三轴位置误差对比图以及位置误差箱线对比图。图13更直观地显示了各算法的三维位置误差随时间的变化。从图13可以看出,经过语义信息辅助以及IMU融合的视觉里程计导航误差总体更小。从图14可以看出,在飞行过程中改进算法相对传统VO算法保持了更优的精度。
为了更加客观地评价本文算法的有效性,本文对采集的共三组试验数据的定位结果进行了定量统计,表2所示为定位误差统计结果。表2中包含了传统VO以及本文所提的改进惯性语义融合VO的三轴位置误差以及总定位误差,其中总定位误差由对三轴位置误差的平方和开根号求得,对应表中的位置误差项。

表2 无人机飞行试验位置误差统计
从表2可以看出,在无人机室内定位试验中,与传统视觉VO相比,本文所提算法具有更小的三轴定位误差以及总定位误差,总体定位精度相较于传统VO算法提高了约40.0%。因此,本文所提方法具有更高的定位精度和鲁棒性。
5 结论
针对传统VO算法抗干扰能力不足、定位精度及鲁棒性差的问题,本文提出了一种基于语义信息辅助的无人机视觉/惯性融合定位方法。该方法将语义平面表述为语义路标,利用VO信息构建位姿-语义路标图,并通过非线性优化进行位姿的优化求解。为了弥补单一传感器的不足,本文通过IMU预积分技术进一步融合了惯性传感器信息。通过实际的无人机飞行试验对所提方法进行了验证,以运动捕捉系统获取的定位结果为基准参考,结果表明,所提方法能够有效提高传统视觉里程计的定位精度。
