基于SN-GAN的大面积缺损图像修复算法研究*
2022-08-04贺佳馨吕晓琪张继凯李菁
贺佳馨,吕晓琪,2,张继凯,李菁
(1.内蒙古科技大学 信息工程学院,内蒙古 包头 014010;2.内蒙古工业大学 信息工程学院,内蒙古 呼和浩特 010051)
1 相关工作
图像修复算法根据技术手段可分为基于偏微分的图像修复方法[2,3]、基于纹理合成技术的图像修复方法[4,5]、基于结构的图像修复方法[6,7]和基于深度学习的图像修复方法4类.基于偏微分的修复算法最典型的是BSCB模型[1].BSCB模型主要是将缺损图像附近的像素延伸到破损区域来进行填充.因为等照度线容易交叉,所以BSCB模型需要将扩散和修复操作轮流进行.BSCB算法的特点是基于像素单位的修复,其修复效率较低且修复后的效果不理想,对于细节和图片整体的一致性修复较差.基于纹理合成的图像修复方法为代表的是Criminisi算法[4].Criminisi算法是基于块的修补并且针对较大的缺损图片,其以目标块为单位,在修复期间寻找最具有充足像素的目标为缺损区域进行填充,对比之前算法,Criminisi算法的修复速度得到大幅提升.此后许多学者在Criminisi算法基础上提出了改进算法[8-10].目前传统图像修复方法存在着训练不稳定、复杂场景或修复区域过大时修复效果模糊以及运算时间过长等一系列问题,传统修复算法无法像人的大脑理解图像中的内容,所以修复效果差强人意.现如今深度学习图像修复算法是通过神经网络来获取图像中重要特征,并且随着2014年Goodfellow等[11]提出了生成对抗网络(Generative Adversarial Networks, GAN), GAN网络一度成为图像修复研究的1个新方向.Pathak等提出的Context Encoder模型[12],是利用对抗损失来修复缺损图像.此模型可以预测出所缺失的内容,并且修复速度较快,但它对于细节修复和空白边界的修复效果不理想.Radford 等[13]将卷积神经网络与生成对抗网络结合,结合之后的网络DCGAN可使训练更稳定.Yeh等[14]通过深度卷积对抗网络结构进行破损区域的修复.Li等[15]在GAN模型的基础上提出改进,将语义解析网络和修复模型结合,并将模型生成器的重构损失、鉴别器的对抗损失以及语义解析部分的损失结合在一起来训练网络.Iizuka等[16]提出一种基于GAN的图像修复算法,使用多鉴别器进行图像的修复,多鉴别器[17]和上下文注意机制[18]的图像修复算法也开始盛行.Yu等[19]提出一种基于深度生成模型的新方法,不仅可以合成新颖的图像结构,而且可以在网络训练期间利用周围图像特征作参考,预测更好的修复区域.因此,将日益强壮的生成对抗网络引入图像修复的过程中,将取得令人意想不到的效果.
针对目前图像修复方法所存在的修复后连接处断裂明显、大面积缺损修复、效果模糊以及整体人脸图像不真实流畅等问题,提出一种生成对抗网络和孪生神经网络结合的算法,此算法对于大面积缺损图像有较好的修复效果.首先,将生成对抗网络模型的判别器用孪生神经网络代替,并且将均方差损失和对比损失引入模型;其次将原始图像和修复图像作为孪生神经网络的2个输入,孪生神经网络将2个输入图像进行特征提取映射到新的空间,并对2个输入特征向量进行相似度计算;最后,通过实验结果说明模型修复后的图像更加逼真,并且主观判断的视觉一致性和图像连贯性得到进一步提升.
2 SN-GAN模型
SN-GAN模型主要包括生成网络与孪生网络2个模块,生成网络模块主要的工作是通过缺损图像周围的信息将缺损部分修复,孪生神经网络模块的作用是将原始图像和修复图像进行比较,和判别器的作用一样.在人脸图像局部缺失情况下,修复依据是从完好区域提取特征.例如当缺损区域是一个眉毛或眼睛时,生成网络从完好的眉毛或眼睛部分提取特征进行学习,修复缺损眉毛与眼睛.本模型的优点在于如果缺损区域是整个五官,生成网络生成后的图像就有很大几率与原始五官不同,所以本模型孪生网络模块的作用就是让整个缺损五官图像修复后与原始图像更加接近,或让修复后的五官在整个人脸图像的视觉感受上更加协调和合理.整体的网络架构如图1所示.

图1 算法架构
2.1 生成网络模块
2014年,Goodfellow等[11]提出的生成对抗网络,由生成模型和判别模型2个子网络构成,是1个通过对抗训练提高自身能力的网络.与原始生成模型网络结构不同,生成网络模块采用的是编码器解码器结构,其网络结构图如图2所示.
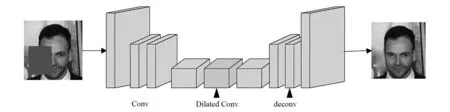
图2 生成网络模型
生成模块的编码器解码器结构通过输入图片经过特征提取将所有特征都汇聚到一起,然后进行反卷积操作,反卷积将汇聚的特征信息用于生成图片.编码器解码器结构的特征与输入图像、输出图像的尺寸是相等的,在模型内部编码器最后的输出成为解码器的输入.表1为生成网络模型的体系结构.
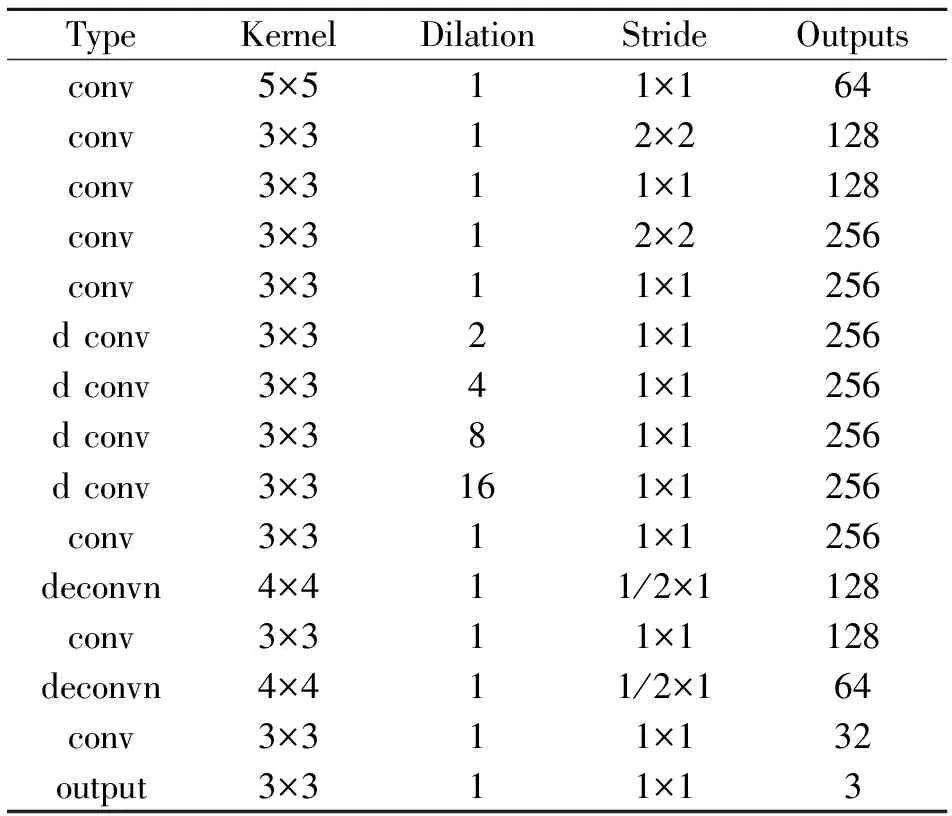
表1 生成网络模块体系结构
由表1可知,该模型在编码器和解码器之间并没有使用全连接层,而是直接将编码器和解码器相连,维持了特征像素之间的空间位置关系.并且还在网络结构中间使用了扩张卷积,扩张卷积在不损失特征图尺寸的情况下增大了感受野,且参数与计算量并没有增加,同时还可允许更大输入面积计算输出像素.如图3所示,扩张率为2的扩张卷积比33的普通卷积感受野更大.

图3 普通卷积与扩张卷积的区别
2.2 孪生神经网络模块
孪生神经网络(Siamese Network)由Bromley等[20]在1993年第一次提出,最开始提出时,此网络是用于验证美国支票上签名是否与银行预留签名一致.随后Chopra等[21]在2005年进行补充,近年来孪生神经网络多用于人脸识别、目标追踪以及相识度检测等[22,23]领域.
该热平衡方程为非齐次微分方程的形式,根据非齐次微分方程的通解形式和已知初始条件t=0,ΔT=ΔT0可求出微分方程的解如式(3)。
孪生神经网络模型是用于对比2张图片相似性的.孪生网络的网络结构配置了3个卷积层、2个最大池化层和2个全连接层.其模型的2个子网络结构相同,且参数和权重共用,这样只需创建一次模型和参数,节省时间与空间的使用.孪生神经网络模型如图4所示.
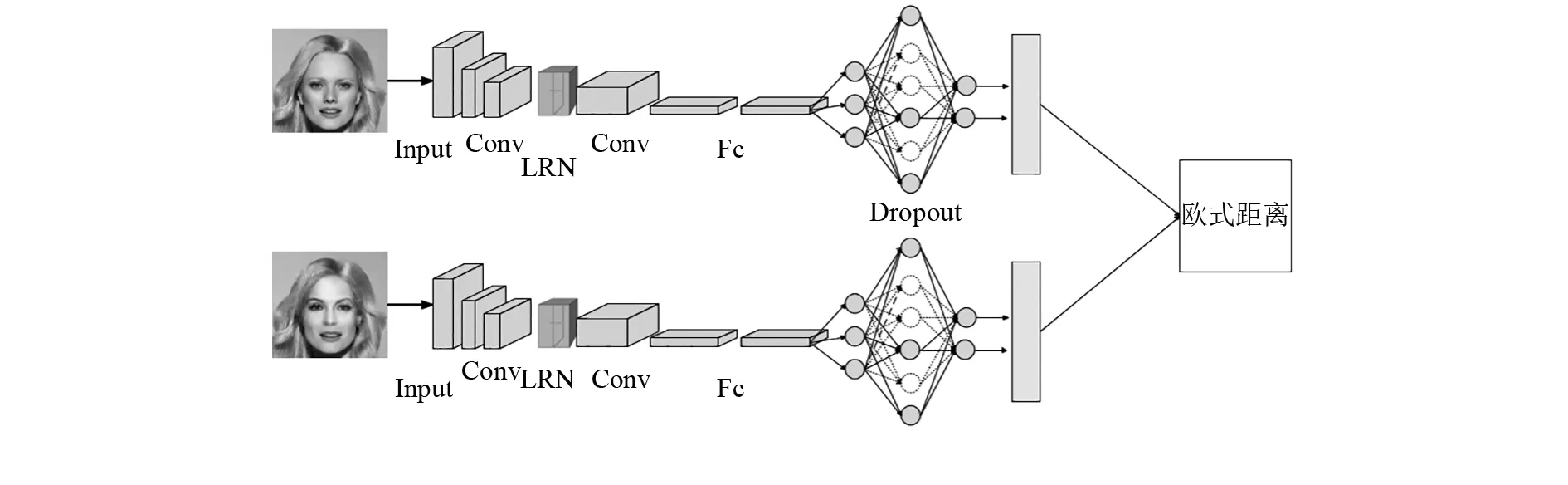
图4 孪生神经网络模型
此模型卷积层所用的ReLU激励函数在一段时间内只有部分的神经元被激活,对于计算效率有明显提升.但激活部分神经元不利于模型训练,所以在进入池化层之前加入了LRN(Local Response Normalization,局部响应值归一化),LRN将较大的值保留并进一步扩大,且抑制较小的反馈神经元,可以提升模型泛化能力.本模型为了防止过拟合,在全连接层之后加入Dropout机制,Dropout在每个训练过程中会随机忽略一些神经元,让其的隐藏节点为0,减少隐藏节点相互作用的同时优化了模型.如图5所示,是使用Dropout机制前后的区别.

图5 标准网络与使用Dropout机制后的区别
2.3 损失函数
为了训练网络的稳定性,模型联合使用加权均方误差损失和对比损失2个损失函数共同作用.均方误差可以将各个训练点到拟合线的距离优化到最小,是为了计算预测值和真实值之间的欧式距离.预测值和真实值差值越小,两者的均方差就越接近.对比损失要负责遮挡区域的细节修复和内容修复.将2种损失函数共同使用既可以使训练达到稳定,又可以使修复图的流畅性、合理性和真实性得到提升,并且可以训练高性能的网络模型.
首先在生成模型处采用均方误差损失,如公式(1)所示:
(1)

其次在在孪生网络模块中,采用的损失函数是contrastive loss,对比损失函数对样本的匹配程度可以表达的非常清楚,同时,也可以更好地训练提取特征的模型.contrastive loss的表达式如(2)所示:
(2)
DW(X1,X2)=‖X1-X2‖2
(3)
式中:DW代表2个样本特征X1和X2的欧氏距离,样本的特征维数是P,Y则是匹配的标签,Y=1时证明2个样本匹配,Y=0时代表不匹配,m是损失函数的阈值,N为样本数量.
综上所述,算法总体的损失函数可以定义为式(4):
L=λ1JMSE+λ2Lμ.
(4)
式中:λ1和λ2是衡量不同损失影响的权重.
3 实验结果与分析
3.1 实验环境与数据集
选用的是CelebA数据集,即名人人脸属性数据集,CelebA数据集由香港中文大学开放提供,为研究者们在人脸识别、图像修复以及图像分类等领域使用.该数据集中具有多达10 177个名人身份,共202 599张人脸图片.从中随机抽取60 000张图片做训练集,10 000张图片做测试集.表2为实验环境.
表2 实验环境
3.2 实验设置与评价指标
实验训练参数设置如表3所示.
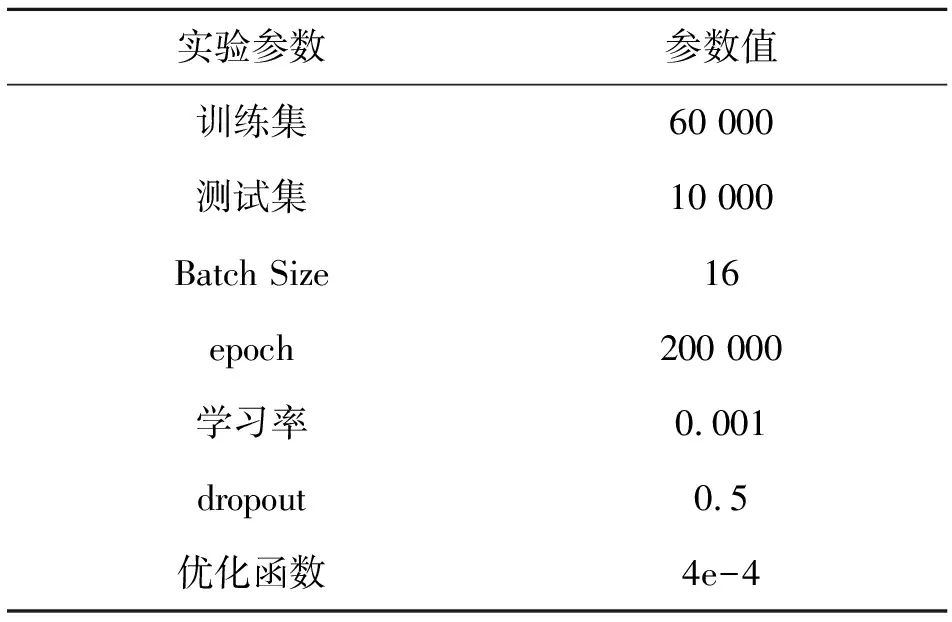
表3 实验参数
图像质量评价方法有很多种,但实验采用主观评价与客观评价相结合的方式,主观评价主要为展示修复效果图,文章客观评价采用结构相似性(SSIM).SSIM主要从亮度、对比度和结构3方面进行评价.在实际应用中,为考虑稳定性和局部信息.计算SSIM时,首先将图像分区域,之后对局部区域进行计算,最后将所有局部区域的SSIM值求平均数.结构相似性比峰值信噪比更符合人类视觉,且直观效果更好.将2个输入图像分别设为X和Y,其定义如式(5)所示:
SSLM(X,Y)=l(X,Y)×c(X,Y)×s(X,Y).
(5)
式(6)~(8)中,l(X,Y)为亮度比较,c(X,Y)为对比度,结构比较为s(X,Y),其公式分别为:
(6)
(7)
(8)
式(6)~(8)中:c1,c2,c3均为常数,主要作用是避免分母为0;X和Y的平均值为μx和μy,σx和σy分别代表了X和Y的标准差,σxσy为协方差.
3.3 实验结果与分析
人脸修复相比较简单的场景修复等比较具有难度,其中细节的修复如眼睛的对称性、眼角细节处以及鼻子等都是在修复领域中比较复杂的修复.实验与CE模型[12]和GLCIC(globally and locally consistent image completion)方法[16]的实验结果进行比较,如图6所示.对于CelebA数据集的人脸图像进行测验,实验在图像中间自动生成1个遮罩,将完整面部遮挡可以更加有效地比较效果,第一列(a)为原始图像,第二列(b)为缺损图像,第三列(c)是CE方法修复的效果图,第四列(d)为GLCIC算法修复效果图,第五列(e)是实验效果图.从图中可以看出,CE算法修复的图像在视觉效果上瑕疵最大,不能使整体和部分保持一致性并且无法实现边界的连贯性.GLCIC算法在加入局部判别器后,通过全局判别器和局部判别器联合训练修复效果较好,使得局部区域的修复效果和全局图像的一致性得到了有效的提升.而文章算法加入孪生神经网络之后,可以使缺损区域的修复更加合理,通过对比特征的相似性让修复效果更加连贯和合理,如在眼睛、眉毛和鼻子等细节处文章算法更能突出其作用,使修复后的图像被人从心理和视觉上所接受,细节处的修复效果使整体面部看起来更加真实.
图7为当局部人脸缺损大小不同时各类算法的修复效果,算法在图像右半脸部分生成缺损区域,缺损区域的大小分别为32*32,64*64 和80*80.第一列(a)为原始图像,第二列(b)为不同大小的缺损图像,第三列(c)是CE方法的修复效果图,第四列(d)为GLCIC算法的修复效果图,第五列(e)是本文算法的修复效果图.从图中第一行可看出,32*32大小的缺损图像修复后的效果都比较好,看不出有修复痕迹.第二行64*64大小的缺损图像修复后,可以看出在眉毛细节方面文章算法相比CE算法有较为明显的提升,CE算法修补后有明显的模糊.第三行80*80大小的缺损图像修复后,可以看出本文的算法在大区域缺损图像方面对比其它2个算法在视觉上的真实性和合理性更好,CE算法和GLCIC算法修复后的瑕疵较明显,文章算法修复后的图像与原图相比较更加相近且修复后的连贯性和视觉一致性都得到了提升,实验表明在大面积缺损图像修复上算法具有更明显的优势.

图6 完整面部缺损下不同算法的修复结果比较(a)原始图像;(b)缺损图像;(c)CE算法;(d)GLCIC算法;(e)本文算法

图7 局部人脸缺损大小不同时不同算法的修复结果比较(a)原始图像;(b)缺损图像;(c)CE算法;(d)GLCIC算法;(e)本文算法
结构相似性的数值范围为0到1之间,越接近数值1则代表修复图像效果越好,即图像质量越好.文章计算SSIM值的结果如表4与表5所示.

表4 完整面部缺损下不同算法的SSIM值结
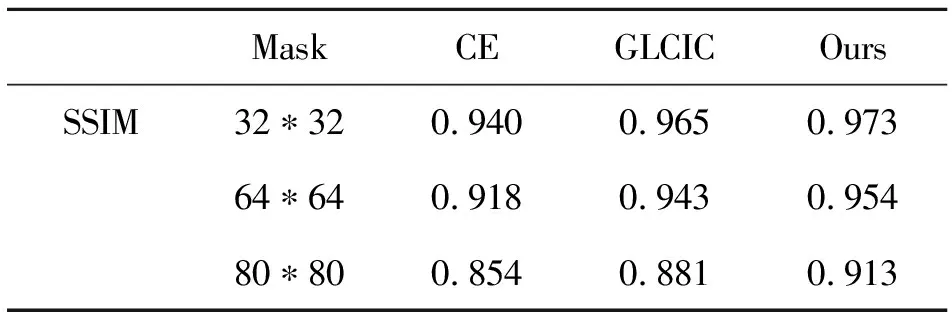
表5 局部人脸缺损大小不同时
由表4可知,在完整五官缺损情况下,本文修复方法的SSIM值较CE模型和GLCLC模型对比相对较高,达到了0.826.实验证明本文修复模型在大区域缺损修复的效果较其他2个算法有明显优势.由表5所可知,在缺损大小为32*32像素时,3种算法修复的效果没有明显的差别.在缺损大小为64*64像素时,CE算法与本文的差别较大,但GLCLC算法与本文的效果接近.在缺损大小为80*80像素时,可看出本文修复算法在大面积缺损图像修复上明显优于这2种算法,所以本文的修复算法更适合大面积缺损图像的修复.
4 结束语
针对目前算法遗留的细节修复效果差、视觉连贯性不佳和大区域修复模糊等问题.提出一种基于生成对抗网络为基础的SN-GAN网络,该算法主要将生成对抗网络和孪生神经网络结合,并且用孪生神经网络代替判别器的作用,来提升辨识真假图片的性能以及图像修复之后的合理性.并加入了两种损失函数共同作用,在提升训练稳定性的同时又提升了效果的真实性.实验表明本文算法在细节修复处有明显的提升,并且更加适合于大面积缺损区域的修复.因大面积缺损修复的视觉效果不完美,本文对于缺损区域边界还存在改进空间,未来将在缺损区域与图像连接方面继续展开研究.
