多视角视觉目标生成的空间机器人操作学习
2022-08-02李林峰解永春
李林峰, 王 勇,2, 解永春*, 胡 勇,2, 陈 奥
1. 北京控制工程研究所,北京 100094 2. 空间智能控制技术重点实验室,北京 100094
0 引 言
空间机器人操作具有时序长、阶段多、干扰强的典型特点,一般采用多视角相机为机械臂提供视觉信息反馈.多视角相机为航天器的捕获对接、宇航员的出舱行走、舱外硬件的维修重置、周围环境的监视检查等多类型任务提供了不可或缺的视觉信息导引.
相比之下,在地面机器人操作领域,利用深度神经网络进行视觉信息处理,提取深度视觉特征,进而引导机械臂进行自主操作,已成为一种典型的工作模式.基于“图像-特征-动作”这样一种分层的架构,已实现了4足机器人步态规划与翻滚恢复[1]、姿态摄动多形状孔插入[2]、浮动基座燃料补加[3]等多种类型的复杂操作任务,且具备较好的鲁棒性.
视觉运动控制方面:文献[4]利用本体运动为视觉特征学习提供监督信号;文献[5]研究了从物理环境交互中学习视觉特征,提出一种自监督动作条件化的视觉序列预测模型;文献[6]研究了SE(3)目标表示的机器人操作;文献[7]研究了多视角视觉观测问题,采用了强化学习控制器,但缺乏真实环境的验证.其他典型工作还包括MonteCarlo树规划器[8-9]、多物体匹配与修正[10]、时序逻辑合成[11]、图编码器[12]等.
分层任务学习方面:文献[13]较早研究了分层、模块化的策略网络,解决多机器人-多任务问题;文献[14]提出了卷积网络-混合密度网络的分层结构,并利用变分自编码器表示前向动力学模型,解决机器人操作任务的序列控制切换;文献[15]提出了异策略修正的分层强化学习,引入离线策略经验缓解了高层策略的非平稳问题;文献[16]基于文献[15],提出了分层虚拟-真实策略迁移,通过层级域随机化,以零样本代价实现了两个4足机器人行走、推动、合作的策略迁移;文献[17]建立了隐变量的技能分布模型.
针对空间机器人操作多视角相机的典型配置,提出一种多视角视觉目标生成的空间机器人操作学习新方法.首先,通过两阶段优化的形式,对多视角观测的空间机器人操作进行了严格定义.其次,用“目标生成+目标伺服”的思路,提出了一种分层策略新架构,高层策略根据图像输入,在SE(3)空间上生成多个视角的视觉目标,并重点构建了多视角目标决策、视触融合两个功能;最后,在真实物理环境中,开展了充分的实验研究,在视触融合、长序列复杂操作任务上验证了提出算法的有效性.
1 问题描述
简要介绍一般的空间机器人和操作对象的动力学方程,在此基础上引入多视角观测图像和位姿估计模型,形成整体优化问题.
1.1 动力学
以在轨道内运行的、表面安装有一个机械臂的航天器作为研究对象.考虑机械臂的控制自由度是n,则整体空间机器人的控制自由度为n+6.一般的空间机器人动力学方程可以写作

(1)

通过前向运动学,计算轨道坐标系下的机械臂末端工具速度ve∈R6
(2)
其中,Je(q)=[Aeb(q)Jeq(q)]∈R6×(6+n),Aeb(q)表示基座到末端工具的坐标转换矩阵,Jeq(q)表示末端工具的物体雅可比矩阵.
假设操作对象不含机械臂,则操作对象的动力学可表示为
(3)

1.2 多视角视觉观测
接下来,引入多视角相机,并通过参数化的模型估计操作对象在各相机坐标系下的6D位姿.定义相机c(i,j),其中(i,j)∈{0,1,2,…,n}×{1,2,…,ni},i表示与相机固连的机器人部件(0对应基座,1、2…n对应机械臂关节),ni∈N表示该部件上安装相机总数.
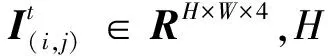

1.3 整体优化问题
以近距离操作为研究对象,暂不考虑自由飞行的情况,引入如下假设:
假设1.(自由浮动)空间机器人和操作对象距离较近,即
(4)
其中,po和pb分别表示轨道坐标系下操作对象和基座航天器的位置向量;与此同时,二者均处于自由浮动状态,即
Fo=0,Fb=0
(5)
此外,为了保证位姿估计模型的有效运行,需要对操作对象的真实位姿(i,j)To进行约束.
假设2.(可观测性)操作对象可以被至少一个相机观测到.即∃(i,j)∈{0,1,2,…,n}×{1,2,…,ni},使得下列不等式成立:
(6)

假设2限定了操作对象质心与相机成像中心的距离,但可能出现操作对象被末端工具、机械臂等物体遮挡的情况.提出的方法具备对遮挡的鲁棒性,只要保证操作对象的一部分可观测即可,实验结果将进一步说明这一点.
综上所述,多视角观测的空间机器人操作可以通过如下优化问题来严格描述:

(7)
2 方 法
2.1 多视角视觉目标生成
为了解决问题(P1),提出一种多视角视觉目标生成的分层策略架构,提升空间机器人在多视角相机引导下自主执行长序列任务的能力.其原理如图1所示.环境(图1右上部分)包含空间机器人和操作对象,它们的动力学描述已在1.1小节介绍.本小节中,将重点考察分层策略(图1左半部分)的原理与设计.

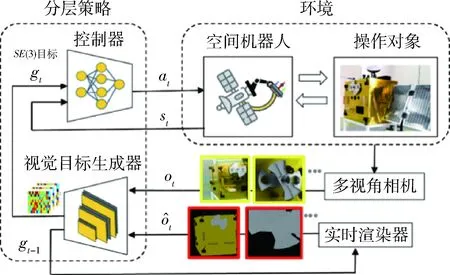
图1 方法原理:多视角视觉目标生成的空间机器人操作Fig.1 Overview on proposed framework of space robotic manipulation based on multi-view visual goal generation
第1步,构建视觉目标生成器.首先,考虑最简单的情况,直接通过线性变换得到目标信号gt∈SE(3)
(8)
式(8)的目标计算方式的主要问题是:它的输出是绝对量,当目标分布空间较大时,容易超出训练数据分布,导致预测失效.为了增加系统对于相对目标信号的跟踪能力,就需要一个输出相对目标的生成模型.这里,采用se(3)-TrackNet网络[18].模型结构上,se(3)-TrackNet采用多层卷积神经网络架构,设置两路输入,一路是当前时刻图像,另一路是根据前一时刻预测值生成的渲染图像,起到联合校正的作用;输出空间选择se(3)空间,再经过指数映射,得到在SE(3)空间表示的相对位姿变化.se(3)-TrackNet具有两方面的优势:首先是速度快,其次是输出相对量,可以有效应对较大范围的目标分布,和长时间的累积预测误差,适合解决多干扰、长时间周期的空间机器人操作问题.
具体地,基于se(3)-TrackNet表示的视觉目标生成器通过如下方式计算得到:
(9)

式中,Conv表示卷积层,FC表示全连接层,×表示向量的斜对称矩阵化.5个卷积层和2个全连接层的参数总体构成了θ(i,j),采用随机梯度下降进行优化.
第2步,设计控制器.这一步的目的是利用式(9)得到的目标信号gt建立机械臂控制at.先考虑无接触的情况(有接触的情况见2.3小节),此时环境状态st:=bTe.这里,采用基于末端位姿的伺服控制器,控制关节角速度.具体地,在机器人基座坐标系下末端工具与操作对象之间的位姿误差为
e=(gt)-1st
(10)
伺服控制器设计为
at=Jeq(q)-1Kvψ(e)
(11)
其中,ψ:SE(3)|R6是位姿表示的非线性变换,Kv∈R6×6是控制增益对角矩阵,Jeq(q)是末端工具的物体雅可比矩阵.相比于关节角度控制,关节速度控制的对目标浮动和基座浮动的反应能力更强.
2.2 多视角目标决策
回顾式(9)的形式,可以看出,尽管输入图像I(i,j)与相机相关,但最终的目标gt是不依赖于相机的.
在假设2的前提下,至少存在一个视角可以观测到操作对象.式(9)最后一行消去(i,j)的过程,实际物理意义上就是多视角目标决策的过程,即应该根据哪一个/哪几个视角提供的信息生成目标.
这里,采用相对误差最小的依据
(12)
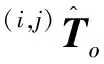
2.3 视触融合

基于式(9)构建的“视-位”关系,再基于“力-位”控制[19-20],就可以实现整体的视触融合.写出阻抗控制的二阶动力学关系
(13)
其中:xe:=ψ(bTe);xg:=ψ(gt);Md、Dd、Kd是阻抗控制参数,均设定为对角矩阵.假想负载的动力学为
(14)
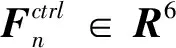
(15)
最后,综合式(11)定义的位置控制,形成最终的混合力-位控制
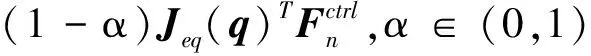
(16)
2.4 总体算法
将整体的算法流程归纳到算法1中.简要列出一些关键的算法实施细节:
在优化式(9)所示的视觉目标生成器时,选择直接在真实环境采集训练样本,相比于虚拟-真实环境迁移的方案更容易实施.
训练集:5000张图像,并应用高斯模糊、深度丢失等数据增广技巧,扩充5倍数据规模,增加模型鲁棒性
测试集:200张图像.实时渲染器采用Pyrender,可以实现GPU加速,且相比于Blender、VisPy等渲染器更加轻量.

算法1 多视角视觉目标生成的空间机器人操作1:输入:控制器增益Kv、Md、Dd、Kd、m,常数α,环境Env2:如果(i,j)∈{0,1,2…,n}×{1,2…,ni}循环执行:▷ 预训练位姿估计器3:D=∪{I(i,j),(i,j)To}▷ 采集训练数据4:θ∗(i,j)∈argmin‖(i,j)T-1oφ(I(i,j);θ(i,j))‖▷ 随机梯度下降优化5:i←i+1,j←j+16:结束循环7:t←08:如果t∈[0,T]循环执行:9:如果(i,j)∈{0,1,2…,n}×{1,2…,ni}循环执行:▷ 多视角并行采样10:I^(i,j)=ϕrender((i,j)T^t-1o)11:(i,j)ΔT^o=φ(I(i,j),I^(i,j);θ∗(i,j))12:(i,j)T^o=(i,j)T^t-1o(i,j)ΔT^o13:i←i+1,j←j+114:结束循环15:(i∗,j∗)=argmin(i,j)((i,j)T^o)-1(i,j)T^t-1o▷ 多视角目标决策16:gt=bT(i∗,j∗)(i∗,j∗)T^o▷ 目标信号17:e=(gt)-1bTe▷ 误差信号18:如果Fextn<η: ▷ 非接触情况19:at=Jeq(q)-1Kvψ(e)20:否则:▷ 有接触情况21:Fctrln=(mM-1d-I)Fextn+m¨xg-mM-1d[Ddxexg)+Kd(xe-xg)]22:at=αJeq(q)-1Kvψ(e)+(1-α)Jeq(q)TFctrln23:结束如果24:st+1~Env(st,at)▷ 环境动力学前推25:t←t+126:结束循环27:输出:机械臂末端轨迹{bTe}t=1:T
Kv=0.5·I,Md=diag{2,2,2,50,50,50},
Dd=20I,Kd=0.1I,α=0.8,m=I
其中:I为单位矩阵;Md的转动三分量设定为较大值,进而转动控制量更小,控制闭环对力矩测量噪声更鲁棒;权重系数α越大,视觉目标产生的控制量越大,过小的α将导致操作精度变低.
3 实 验
3.1 环境设置
通过地面物理仿真试验系统进行算法验证.该系统由一个服务卫星模拟器、一个通用化的目标卫星模拟器构成,整体结构如图2所示.

图2 地面物理仿真试验系统Fig.2 Overview of the experimental testbench
(1)服务卫星模拟器:由基座和机械臂构成.基座可产生3自由度运动(水平面内平移+绕竖直方向旋转),用以模拟基座浮动;机械臂选用UR10协作机械臂,有效工作半径1.3 m,含6自由度关节控制;机械臂末端带有2指机械手,可以控制手指间位移;机械臂末端和机械手之间安装有ATI 6轴力/力矩传感器;2个Intel D435相机分别固定在基座和机械臂末端关节,基座相机提供全局/远景视角图像,末端相机提供局部/近景视角图像.
(2)目标卫星模拟器:长0.6 m的立方体构型,可模拟在轨燃料补加、模块更换、帆板维修等,是一种通用化、多任务的算法验证平台.目标卫星模拟器同样可产生3自由度运动,用以模拟目标浮动.
算法验证涉及三个不同尺度的操作对象,分别是:目标卫星、可更换模块(见图2,位于目标卫星端面下部左侧,抽屉形状,带有把手)、加注被动端(见图2,位于目标卫星端面上部中心,3圆柱孔结构).
3.2 多视角视觉目标生成
在测试数据激上对视觉目标生成器进行性能评估,相机视角与操作对象的对应关系是:基座相机用于识别目标卫星,末端相机用于识别可更换模块、加注被动端.
3个操作对象的运行结果分别记录在图3~5中.各图的上半部分展示了预测值与真实值的对应关系,用以评估动态目标的响应误差,6个子图分别代表平移三分量(单位m)和转动三分量(轴角表示,单位rad);红色线是零误差线,距离红色线的距离越近误差越小;显示的样本总数为120.各图的下半部分是将物体的3D模型(显示为黄色均匀点云)投影到真实测试样本上的可视化效果.

图3 视觉目标生成器的运行结果:基座相机+目标卫星Fig.3 Test results of visual goal generator: robotbase camera+target satellite

图4 视觉目标生成器的运行结果:末端相机+可更换模块Fig.4 Test results of visual goal generator: end-effector camera+portable module

图5 视觉目标生成器的运行结果:末端相机+加注被动端Fig.5 Test results of visual goal generator: end-effector camera+refueling ports
由图3~5可以看出:1)响应误差方面,绝大多数样本点误差较小,存在一些野点,是由于相邻帧间的相对位姿变化较大,超过训练样本的范围,但误差会在几步预测之内被消除;2)响应速度方面,视觉目标生成器离线运行(图像从文件读取)速度在80~90帧/秒之间,在线运行(图像从相机实时获取)速度大于30帧/秒;3)鲁棒性方面,对多种类型的遮挡均具有较好鲁棒性,比如图3(b)所示目标卫星移出视场40%以上,图4(b)所示可更换模块插入方孔不同深度,和图5(b)所示加注被动端被工具遮挡50%以上.
3.3 多视角目标决策
验证2.2小节提出的多视角目标决策功能.
为了进一步评估目标引导精细操作的能力,设计了表1所示的任务序列,每个任务都调用了不同视角的相机.其中任务3和任务5调用两路视角的原因是:可更换模块占据末端相机视场的比例较大,目标卫星的有效信息较少,因此采用基座相机对目标卫星进行估计.图6和图7分别是体现任务执行结果的机械臂关节曲线和视频记录.可以看出,设计的方法在单视角独立运行、多视角协同运行、多任务切换3方面都表现出较好的性能,可以在60 s内完成“抵近、抓取、拔出、移动、插入”这样的长序列、视触融合复杂任务.
3.4 视触融合
验证2.3小节提出的视触融合功能.记录了“任务5-插入模块”过程的末端工具力/力矩曲线(x、y、z分别对应右、下、前方向),以及基座坐标系下末端工具位置曲线(-y对应前进方向),分别由图8和图9显示,时间轴与图7对齐.对比了有视觉目标/无视觉目标的情况,结果表明:利用视觉目标导引,插入过程中前进方向(Fz)的力峰值小于0.05 N,3方向扭矩峰值小于0.004 N·m,可以在4 s时间内将可更换模块(模块与矩形孔的间隙小于1 cm)柔顺地插入目标卫星;相比之下,无视觉目标导引时,前进方向(Fz)的力峰值大于0.1 N,姿态漂移较大,导致插入不成功.上述结果阐明了视觉目标在降低碰撞力、提高操作精细度方面的有效性.

表1 操作任务与调用相机视角的对应关系Tab.1 Corresponding relationship of manipulation task and applied camera view

图6 多视角目标决策结果:机械臂关节轨迹Fig.6 Results on multi-view visual goal decision: joint position trajectory

图7 多视角目标决策结果:视频记录Fig.7 Results on multi-view visual goal decision: video recording
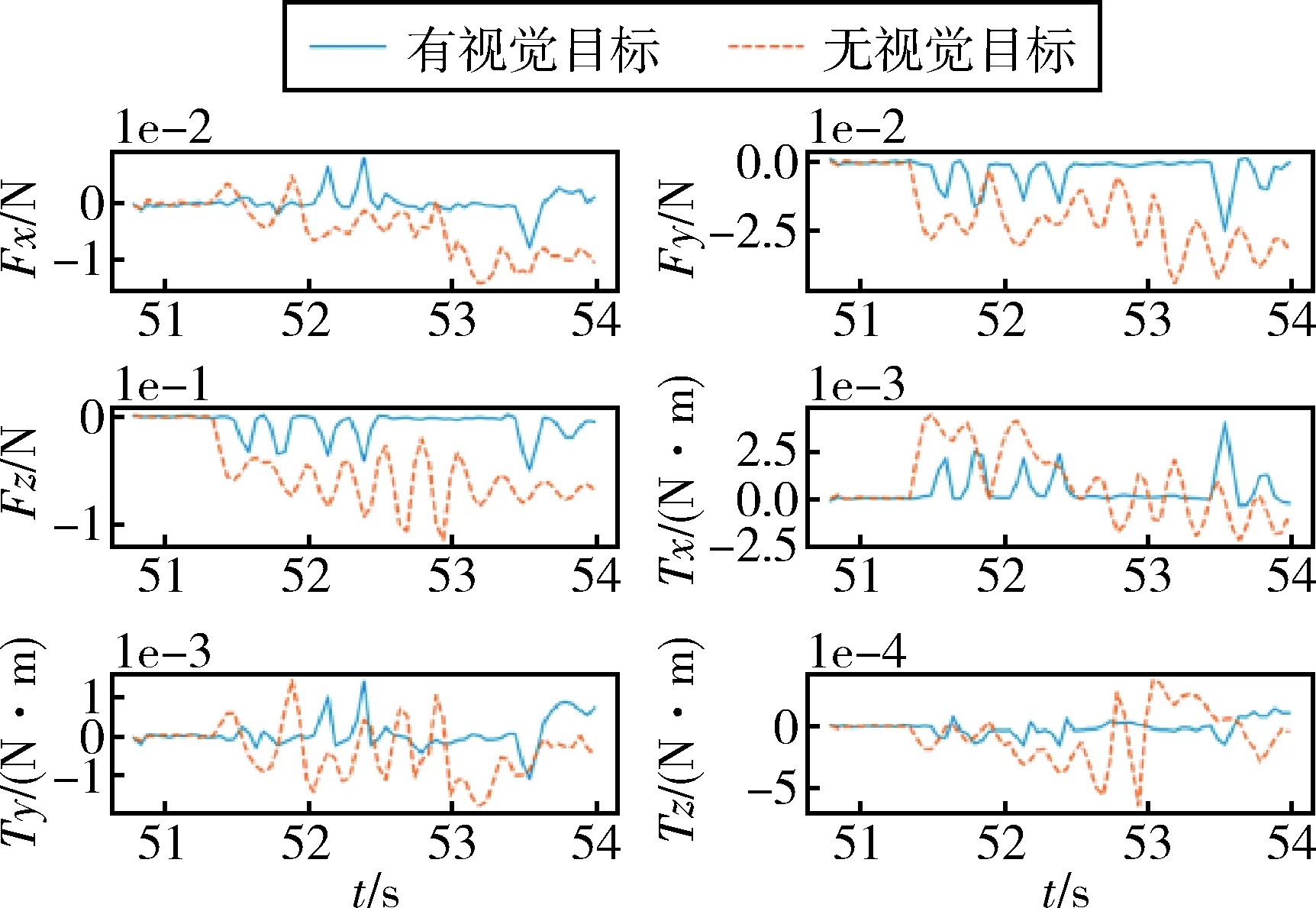
图8 视触融合结果:末端工具力/力矩测量曲线Fig.8 Results on visuo-tactile integration: measured curve of end-effector force/torque

图9 视触融合结果:基座坐标系下末端工具位置测量曲线Fig.9 Results on visuo-tactile integration: measured curve of end-effector position, expressed in the robot base coordinate frame
4 结 论
针对空间机器人系统多视角相机典型配置,提出一种多视角视觉目标生成新方法,该方法采用“目标生成+目标伺服”的分层策略架构,基于深度神经网络表示的视觉目标生成器,重点构建了多视角目标决策、视触融合两个功能.该方法的主要优势包括:1)实时性:视觉目标生成器的计算速度优于相机的图像采集速度,有利于跟踪浮动或机动目标,实现反应式操作;2)适用性:不局限控制器的实现形式,既可以是神经网络控制器,也可以是一般的PID控制器、逆运动学控制器.地面物理试验结果表明:视觉目标生成器能够快速响应(>30帧/秒)多类不同尺度的操作对象(目标卫星、加注被动端、可更换模块),且对静态、动态遮挡均具有较强鲁棒性;分层策略整体具备执行长序列复杂任务(抵近、抓取、拔出、移动、插入)的能力.
